The standard guidelines for building large language models (LLMs) optimize only for training costs and ignore inference costs. This poses a challenge for real-world applications that use inference-time scaling techniques to increase the accuracy of model responses, such as drawing multiple reasoning samples from a model at deployment.
To bridge this gap, researchers at University of Wisconsin-Madison and Stanford University have introduced Train-to-Test (T2) scaling laws, a framework that jointly optimizes a model’s parameter size, its training data volume, and the number of test-time inference samples.
In practice, their approach proves that it is compute-optimal to train substantially smaller models on vastly more data than traditional rules prescribe, and then use the saved computational overhead to generate multiple repeated samples at inference.
For enterprise AI application developers who are training their own models, this research provides a proven blueprint for maximizing return on investment. It shows that AI reasoning does not necessarily require spending huge amounts on frontier models. Instead, smaller models can yield stronger performance on complex tasks while keeping per-query inference costs manageable within real-world deployment budgets.
Advertisement
Conflicting scaling laws
Scaling laws are an important part of developing large language models. Pretraining scaling laws dictate the best way to allocate compute during the model’s creation, while test-time scaling laws guide how to allocate compute during deployment, such as letting the model “think longer” or generating multiple reasoning samples to solve complex problems.
The problem is that these scaling laws have been developed completely independently of one another despite being fundamentally intertwined.
A model’s parameter size and training duration directly dictate both the quality and the per-query cost of its inference samples. Currently, the industry gold standard for pretraining is the Chinchilla rule, which suggests a compute-optimal ratio of roughly 20 training tokens for every model parameter.
However, creators of modern AI model families, such as Llama, Gemma, and Qwen, regularly break this rule by intentionally overtraining their smaller models on massive amounts of data.
Advertisement
As Nicholas Roberts, co-author of the paper, told VentureBeat, the traditional approach falters when building complex agentic workflows: “In my view, the inference stack breaks down when each individual inference call is expensive. This is the case when the models are large and you need to do a lot of repeated sampling.” Instead of relying on massive models, developers can use overtrained compact models to run this repeated sampling at a fraction of the cost.
But because training and test-time scaling laws are examined in isolation, there is no rigorous framework to calculate how much a model should be overtrained based on how many reasoning samples it will need to generate during deployment.
Consequently, there has previously been no formula that jointly optimizes model size, training data volume, and test-time inference budgets.
The reason that this framework is hard to formulate is that pretraining and test-time scaling speak two different mathematical languages. During pretraining, a model’s performance is measured using “loss,” a smooth, continuous metric that tracks prediction errors as the model learns.
Advertisement
At test time, developers use real-world, downstream metrics to evaluate a model’s reasoning capabilities, such as pass@k, which measures the probability that a model will produce at least one correct answer across k independent, repeated attempts.
Train-to-test scaling laws
To solve the disconnect between training and deployment, the researchers introduce Train-to-Test (T2) scaling laws. At a high level, this framework predicts a model’s reasoning performance by treating three variables as a single equation: the model’s size (N), the volume of training tokens it learns from (D), and the number of reasoning samples it generates during inference (k).
“Train-to-test” combines the pretraining and test-time scaling laws into a unified framework (source: arXiv)
T2 combines pretraining and inference budgets into one optimization formula that accounts for both the baseline cost to train the model (6ND) and the compounding cost to query it repeatedly at inference (2Nk). The researchers tried different modeling approaches: whether to model the pre-training loss or test-time performance (pass@k) as functions of N, D, and k.
Advertisement
The first approach takes the familiar mathematical equation used for Chinchilla scaling (which calculates a model’s prediction error, or loss) and directly modifies it by adding a new variable that accounts for the number of repeated test-time samples (k). This allows developers to see how increasing inference compute drives down the model’s overall error rate.
The second approach directly models the downstream pass@k accuracy. It tells developers the probability that their application will solve a problem given a specific compute budget.
But should enterprises use this framework for every application? Roberts clarifies that this approach is highly specialized. “I imagine that you would not see as much of a benefit for knowledge-heavy applications, such as chat models,” he said. Instead, “T2 is tailored to reasoning-heavy applications such as coding, where typically you would use repeated sampling as your test-time scaling method.”
What it means for developers
To validate the T2 scaling laws, the researchers built an extensive testbed of over 100 language models, ranging from 5 million to 901 million parameters. They trained 21 new, heavily overtrained checkpoints from scratch to test if their mathematical forecasts held up in reality. They then benchmarked the models across eight diverse tasks, which included real-world datasets like SciQ and OpenBookQA, alongside synthetic tasks designed to test arithmetic, spatial reasoning, and knowledge recall.
Advertisement
Both of their mathematical models proved that the compute-optimal frontier shifts drastically away from standard Chinchilla scaling. To maximize performance under a fixed budget, the optimal choice is a model that is significantly smaller and trained on vastly more data than the traditional 20-tokens-per-parameter rule dictates.
The train-to-test scaling laws show that small overtrained models outperform Chinchilla-optimized models on reasoning tasks (source: arXiv)
In their experiments, the highly overtrained small models consistently outperformed the larger, Chinchilla-optimal models across all eight evaluation tasks when test-time sampling costs were accounted for.
For developers looking to deploy these findings, the technical barrier is surprisingly low.
Advertisement
“Nothing fancy is required to perform test-time scaling with our current models,” Roberts said. “At deployment, developers can absolutely integrate infrastructure that makes the sampling process more efficient (e.g. KV caching if you’re using a transformer).”
KV caching helps by storing previously processed context so the model doesn’t have to re-read the initial prompt from scratch for every new reasoning sample.
However, extreme overtraining comes with practical trade-offs. While overtrained models can be notoriously stubborn and harder to fine-tune, Roberts notes that when they applied supervised fine-tuning, “while this effect was present, it was not a strong enough effect to pull the optimal model back to Chinchilla.” The compute-optimal strategy remains definitively skewed toward compact models.
Yet, teams pushing this to the absolute limit must be wary of hitting physical data limits. “Another angle is that if you take our overtraining recommendations to the extreme, you may actually run out of training data,” Roberts said, referring to the looming “data wall” where high-quality internet data is exhausted.
Advertisement
These experiments confirm that if an application relies on generating multiple test-time reasoning samples, aggressively overtraining a compact model is practically and mathematically the most effective way to spend an end-to-end compute budget.
To help developers get started, the research team plans to open-source their checkpoints and code soon, allowing enterprises to plug in their own data and test the scaling behavior immediately. Ultimately, this framework serves as an equalizing force in the AI industry.
This is especially crucial as the high price of frontier models can become a barrier as you scale agentic applications that rely on reasoning models.
“T2 fundamentally changes who gets to build strong reasoning models,” Roberts concludes. “You might not need massive compute budgets to get state-of-the-art reasoning. Instead, you need good data and smart allocation of your training and inference budget.”
Silicon Valley startup Sabi is the latest entrant to suggest using the brain as an interface device. The company is developing a noninvasive device that translates internal speech into text. Rather than relying on implanted hardware, Sabi is building a wearable device – initially in the form of a beanie,… Read Entire Article Source link
Current systems emphasize sight and sound, with some progress in haptics. Smell remains largely absent, despite its unusually strong connection to memory and emotion. Read Entire Article Source link
Rare earth materials are a hot button topic these days. They’re important for everything from electric vehicles to defence hardware, they’re valuable, and everyone wishes they had some to dig up in their backyard. Lithium, too, is a commodity nobody can get enough of, with the demand for high-performance batteries grows each year.
When a material is desirable, and strategically important, we often start thinking of ways to conserve or recycle it because we just can’t get enough. In that vein, researchers have been developing a new technique to recover rare earth metals and lithium from waste streams so that it can be put back to good use.
Get It Back
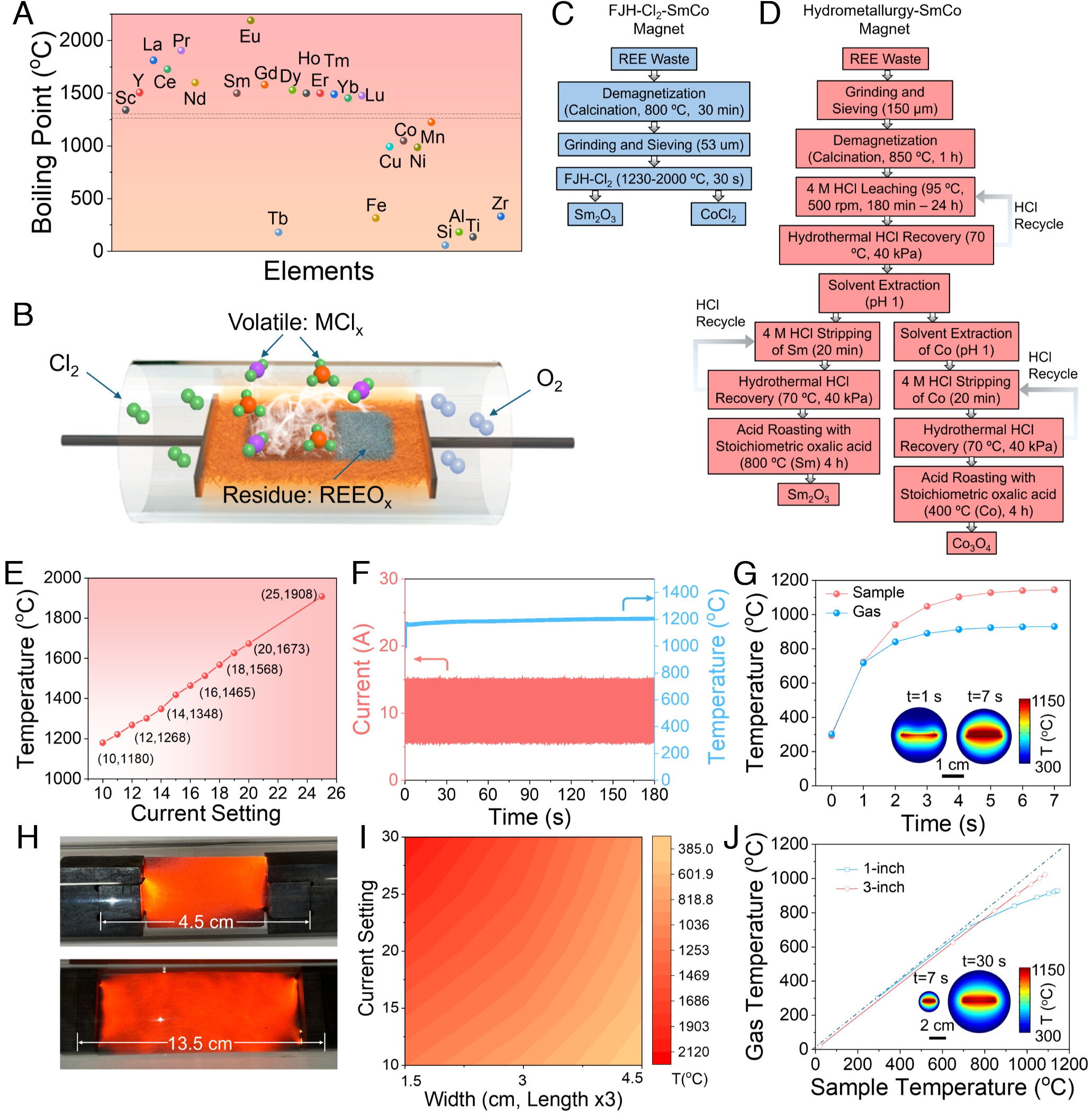
Enter the technique of flash joule heating. The method is relatively straightforward, in concept at least. It involves a high energy discharge from a capacitor bank, which is passed through a sample of material to be recycled or refined. The idea is that the rapid energy discharge will vaporize some components of the sample, while leaving others intact, allowing the desired material to be separated out and collected in a straightforward and economically-viable manner. It does this in a manner rather contrary to traditional techniques, which often involve large amounts of water, acids, or alkalis, which can be expensive and messy to dispose of or reprocess to boot.
A flash joule heating apparatus used to recover rare earth materials. Credit: Jeff Fitlow, Rice University
Researchers from Rice have developed this technique to recycle rare earth metals from waste magnets. Imagine all the magnets that get thrown away when things like hard drives and EV motors get trashed, and you can imagine there’s a wealth of rare earth material there just waiting to be recovered.
In this case, the high-energy discharge is applied to waste magnet material in an effort to vaporize the non-rare earth components that are present. The discharge is performed in the presence of chlorine gas, which would chlorinate materials like iron and cobalt in the sample, removing the volatile elements and leaving the rare earth elements behind in solid form. Laboratory experiments were able to refine the material to 90% purity in a single step.
Advertisement
In the rare earth case, the undesired material is vaporized and removed by the chlorine gas while the rare earths remain behind in the solid phase. For capturing lithium from spodumene ore, it’s the opposite. Credit: research paper
As per the research paper, lifecycle analysis suggested the technique could reduce energy use by 87% compared to contemporary hydrometallurgy recycling techniques, while also reducing greenhouse gas emissions in turn and slashing operating costs by 54%.
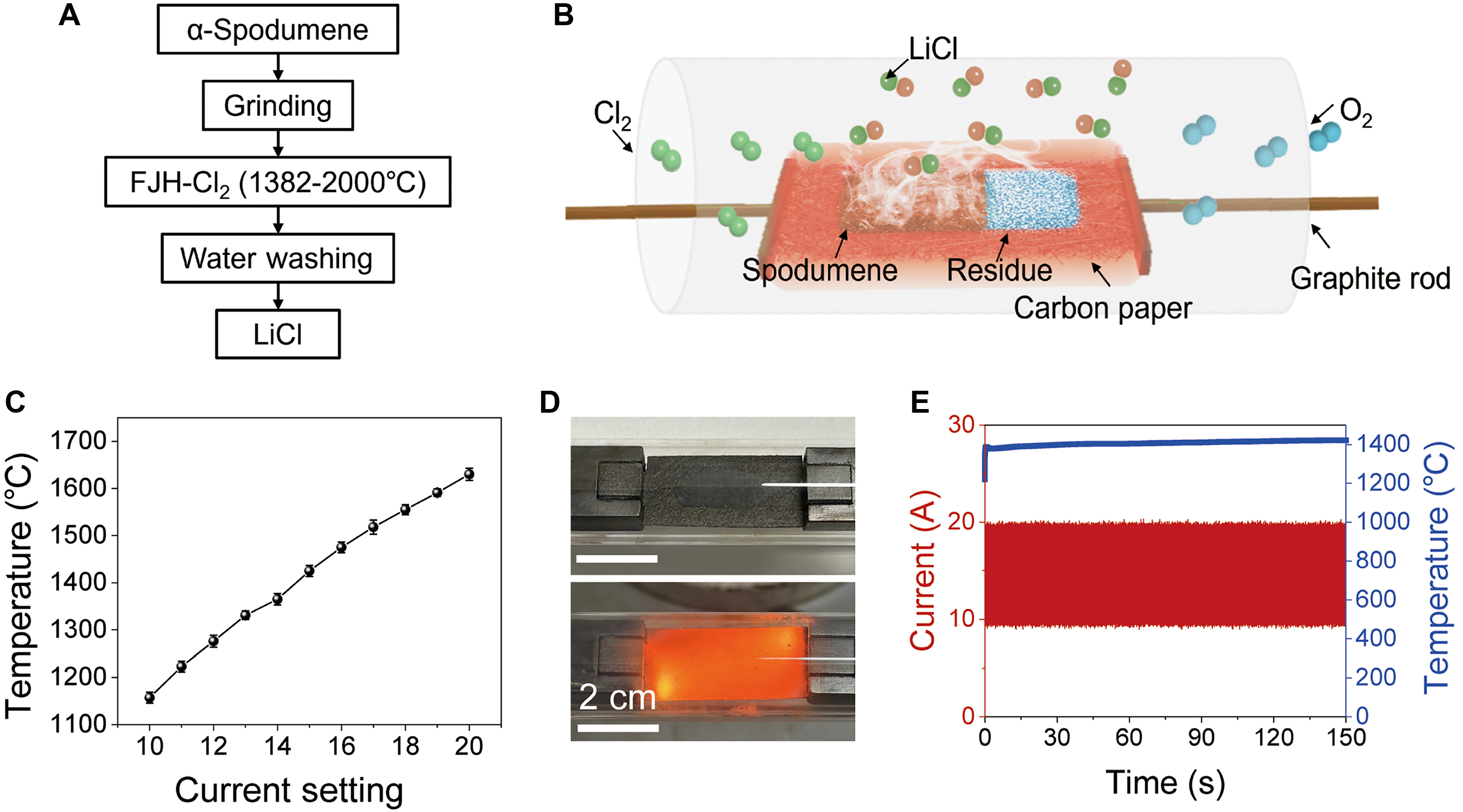
The technique can also be applied to separate lithium from spodumene ore. It’s an abundant material, particularly in the United States, and improved ways to process it could increase its value as a source of lithium. When it comes to processing spodumene with flash joule heating, the discharge of electric current makes the lithium in spodumene available to react with chlorine gas. The rapid heating causes the vaporized lithium to form lithium chloride which can be bled off, while other components of spodumene like aluminium and silicon compounds remain behind. It’s basically the opposite of the rare earth recovery method.
As outlined in the research paper, this method achieved recovery of lithium chloride with 97% purity and a recovery rate of 94% in a single step. It’s also a lot simpler than traditional extraction methods that involve long periods of evaporating brine or using acid leeching techniques. Indeed, the laboratory rig was built using an arc welder to achieve the powerful discharge. Other researchers are examining the technique too and achieving similar results, hoping that it can be a cleaner and more efficient method of recovery compared to traditional hydrometallurgy and pyrometallurgy techniques.
The lithium recovery process using flash joule heating. Credit: research paper
These methods remain at the research stage for the time being. Pilot plants, let alone commercial operations, are still a future consideration. Regardless, the early work suggests there is economic gain to be had by developing recycling plants that operate in this manner. Assuming the technique works at scale, if it makes financial sense and recovers useful material, expect it to become a viable part of the recycling industry before long.
The New York startup has built AI that reads handwritten fax forms, processes prior authorisations, and completes patient intakes in under five minutes, all without asking providers to change how they work. It has reached multiple millions in revenue in under a year and is targeting 4x growth by end of 2026.
Coral, the New York-based AI startup automating administrative workflows for specialty healthcare providers, has raised $12.5 million in a Series A led by Lightspeed and Z47.
The company was founded in 2024 by Ajay Shrihari, a robotics and AI researcher, and Aniket Mohanty, who has a background in medical image processing.
In under a year of commercial operation, Coral has reached multiple millions in annual revenue and is targeting 4x growth before the end of 2026.
Advertisement
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The problem Coral is solving is not technological complexity, it is administrative volume. In American healthcare, every appointment generates a trail of prior authorisation requests, referral packets, insurance eligibility checks, and discharge paperwork.
Much of this flows through fax machines, which remain deeply embedded in clinical workflows despite being a technology from a previous era.
Advertisement
Rather than attempting to replace fax infrastructure, an approach that would require providers to rebuild systems they cannot afford to rebuild, Coral connects to existing EHR systems, fax lines, and payer portals and automates around them.
Providers do not change how they work. Coral changes what happens inside that workflow.
The company began in the durable medical equipment sector, one of the most fax-intensive corners of outpatient care, where a single order can require multiple rounds of documentation before approval.
DASCO, a home medical equipment provider, has been an early customer, describing turnaround times dropping from hours or days to minutes.
Advertisement
Coral then extended the same model into infusion centres, where a delayed authorisation means a missed dose, not a delayed appointment, and into specialty pharmacy.
In each new vertical, the same administrative bottleneck appeared in the same shape. The product’s core capability is document understanding at healthcare’s specific level of messiness: handwritten fax forms, scanned insurance cards, prior authorisation templates, and payer portal screens.
Coral’s models have reached 99.7% accuracy across these document types, a threshold the company describes as the minimum viable standard for healthcare, where errors have clinical and financial consequences.
Complete patient intakes, including complex cases, now run in under five minutes. When information is missing, which is frequent in this environment, the platform coordinates with payers, patients, and referral sources to resolve the gap without requiring staff intervention.
Advertisement
The strongest signal in the commercial story is not the revenue figure but the payment behaviour. A portion of Coral’s customers are paying the full contract value upfront, an unusual dynamic in enterprise software, and a striking one in a sector where vendor evaluation cycles are typically slow and risk-averse.
The explanation is mechanical: when a workflow that previously took hours completes in under five minutes at high accuracy, the return on investment is immediate and visible. Commit now, stop the queue now.
Coral recently shipped AI-powered voice and text workflows that automate follow-ups with payers, patients, and referral sources, replacing calls that previously required a staff member to pick up the phone.
The next phase of product development includes an AI workflow builder that will let providers design and deploy their own administrative processes without involving IT, and a co-pilot layer that surfaces operational intelligence from the data already flowing through the platform: which payers have the highest denial rates and why, where cases are stalling in the authorisation process, which referral sources convert reliably and which do not, and what changes would improve outcomes on insurance claim resubmissions.
Advertisement
Rohil Bagga, investor at Lightspeed, described the company as “delivering real outcomes at scale” in an environment where legacy automation has historically failed.
Ashwin KP, investor at Z47, framed the investment thesis around the specific characteristics of healthcare administration: over a trillion dollars in annual overhead, chronically underserved by technology, and requiring deep vertical expertise to crack.
The Series A funds team growth and product development, with Coral adding engineering talent alongside people who have spent careers inside healthcare operations.
Apple is expected to introduce its first foldable iPhone later this year, and early reports suggest it may be called the iPhone Ultra. Newest leaks from tipster Jon Prosser suggest the device could bring one of the biggest changes to the iPhone lineup in years, especially in terms of design and usability. Here are six major upgrades that the iPhone Ultra is expected to offer.
Foldable Design with a New Look
Image: FPT
The iPhone Ultra is expected to come with a completely new foldable design. Instead of a regular smartphone shape, it may open like a book, giving users a much larger screen when unfolded. It will also have a wider design instead of the usual tall shape seen in other foldables. For example, while using the outside screen, the user will have a smaller screen measuring 5.3 to 5.5 inches. Once unfolded, the second screen will expand up to 7.8 inches, bringing the user experience closer to that of an iPad mini.
The use of a titanium frame may help make it durable while keeping it lightweight. Another key highlight is the expected crease-free inner screen, which could improve the overall viewing experience. In terms of looks, the device may be limited to black-and-white color options.
Like other folding phones, TouchID will probably find its way back. It’s much easier to use a fingerprint sensor on the power button than to integrate Face ID sensors into both displays.
Software & Camera Configuration
Image: FPT
One of the key differences between the iPhone Ultra and Pro models is the camera configuration. Unlike other models, the iPhone Ultra will have only two cameras. One will be a primary camera with a 48 MP sensor, while the other will be an ultra-wide camera with a 48 MP sensor. Unfortunately, since there won’t be a telephoto lens, zooming options may be limited for the users. Besides, the dual screen will require two front-facing cameras.
The iOS 27 is likely to introduce new multitasking features designed for the iPhone Ultra. Among the expected improvements are multi-app functionality, where users can perform multiple functions simultaneously, and app designs that more closely match what the iPad offers, particularly when used on the inner display. It is not going to be iPadOS but rather selected elements from the operating system.
Advertisement
Everything will be handled by the new A20 Pro chip, which may work on the 2nm manufacturing process. It’s very early to judge the performance numbers, but we are expecting the iPhone Ultra to feature 12 GB RAM and use the new C2 modem.
Expected Price
Apple is expected to position the iPhone Ultra as a premium product. The device is expected to start at around $1,999, making it Apple’s most expensive iPhone yet. However, since it offers both phone- and tablet-like experiences in a single device, some users may find the premium pricing justified.
When Asus launched the Drop Zone program last year, it was seen as a commendable gesture to make repairs less taxing for consumers. Now, keeping in the same vein, Asus is expanding its Drop Zone initiative in India by adding 22 new stores to the network. The program, which allows users to submit laptops for servicing at ASUS Exclusive Stores instead of dedicated service centers, is now being rolled out across multiple regions, including Delhi NCR, Haryana, Karnataka, Kerala, Maharashtra, Tamil Nadu, Uttarakhand, Uttar Pradesh, and West Bengal.
What is Asus Drop Zone Service?
The Drop Zone initiative is designed to simplify the repair process by allowing customers to drop off and collect their devices at nearby ASUS stores. This eliminates the need to travel to service centers, which can often be inconvenient—especially for users in tier-2 and tier-3 cities.
With this expansion, ASUS is clearly trying to address common pain points like accessibility, turnaround time, and service transparency. Customers also get multiple service options, including carry-in support for immediate consultation, on-site servicing by technicians, and the Drop Zone model for easier logistics.
ASUS says it already has a wide after-sales network in India, with over 200 service centers and on-site support covering more than 17,000 pin codes across 761 districts. The Drop Zone expansion adds another layer to this ecosystem, bringing services closer to users. The company also offers 24/7 support through calls, chat, email, and remote troubleshooting. Speaking on the matter, Arnold Su, VP, Consumer and Gaming PC, System Business Group, ASUS India, said
Advertisement
At ASUS, our focus has always been on delivering a reliable and consistent ownership experience that extends well beyond the product itself. The expansion of our Drop Zone initiative into 22 additional stores marks a significant step towards making after-sales support more accessible and transparent for our customers. Guided by our 4A framework, we remain committed to building a service ecosystem that is responsive, convenient, and aligned with evolving customer needs.
At current market prices, the hardware appears valuable. Comparable SK hynix registered DDR4 modules currently sell for about $287.95 each, putting the total value at more than $20,000. However, that figure reflects today’s pricing, not what the hardware was worth when it was removed from service. Read Entire Article Source link
Klipsch is returning to Milan Design Week 2026 with something that goes beyond another product launch; it’s a continuation of one of the more interesting collaborations in modern hi-fi. Following the limited-run kO-R1 in 2024, Klipsch and OJAS have officially unveiled the kO-R2, a new loudspeaker created with Devon Turnbull, the artist and acoustic designer behind OJAS, as part of Klipsch’s 80th anniversary.
That matters more than the usual show-floor debut. The first kO-R1 wasn’t just a speaker, it was a statement about where heritage audio could go when handed to someone outside the traditional engineering echo chamber. Turnbull approached Klipsch’s horn-loaded DNA with a minimalist, almost gallery-first mindset, and the result landed somewhere between serious hi-fi and functional art. It sold out quickly and didn’t need a stack of Audio Science Review graphs to justify itself. Turns out art and musical enjoyment still carry more weight than rigid objectivism.
The kO-R2 builds directly on that foundation. Klipsch and OJAS describe it as a blend of minimalist design, advanced acoustic thinking, and bespoke materials, with an emphasis on form that’s meant to live as comfortably in a design exhibition as it does in a listening room. There are no performance specifications or pricing details yet, which feels intentional. This isn’t being positioned as a spec war product; it’s being framed as a continuation of an idea.
Klipsch OJAS kO-R2
And that’s the real story. At a time when much of the industry is chasing incremental upgrades and feature checklists, Klipsch is doubling down on a collaboration that prioritizes identity, experience, and cultural relevance. Bringing the kO-R2 to Milan Design Week instead of a traditional audio show makes that point clear: this is as much about design language and audience expansion as it is about sound.
Whether the kO-R2 ultimately delivers on the acoustic side will come later. For now, Klipsch and OJAS have done something more difficult; they’ve made people outside the usual audiophile bubble pay attention.
Advertisement
Unveiled at Milan Design Week 2026
Set against the backdrop of the Fondazione Luigi Rovati, in partnership with USM Modular Furniture and Karimoku, Klipsch and OJAS are hosting curated, appointment-only listening sessions during Milan Design Week through April 26, 2026. Those who get access are encouraged to bring their own music, turning the kO-R2 preview into something more personal than the usual show-floor demo.
After its debut in Milan, a broader launch for the kO-R2 is expected in June 2026.
“Working with Klipsch continues to be an exploration of how we can strip audio down to its most essential, emotional core,”said Devon Turnbull. “With the kO-R2, we focused on creating something that feels immediate and human—where the technology disappears, and the listener is left with a pure, physical connection to the music.”
kO-R2 Design Concept
The kO-R2 is a two-way, sectoral horn-loaded loudspeaker positioned as the next step in the Klipsch x OJAS collaboration. It’s handcrafted in Hope, Arkansas, by the same team behind Klipsch’s legacy designs, and features an OJAS-developed multisectoral horn paired with Baltic birch cabinetry. The goal is clear: deliver the dynamic, low-distortion traits horn systems are known for, while presenting something that looks just as considered as it sounds.
Advertisement
Klipsch OJAS kO-R2 Loudspeaker in Hammertone Silver.
The core of the latest speaker design is the OJAS 1506 multisectoral horn, fabricated from heavy cast aluminum and finished with electrophoresis and a flat black powder coat.
The exponential horn pulls from classic Western Electric and Altec Lansing design cues, but it’s not a straight throwback. The square, isosceles trapezoidal mouth is doing real work here, controlling dispersion in both planes rather than just looking the part. The result should be more even frequency distribution and a wider, more stable listening window, which is exactly what these older horn concepts were chasing in the first place.
Advertisement. Scroll to continue reading.
The kO-R2 leans into a restrained, material-first design without skimping on the hardware. It uses a high-quality compression driver, anodized aluminum binding posts, and anti-vibration feet—nothing flashy, just components that make sense for a horn-loaded design like this.
Details like the laser-engraved metal ID plate add a layer of exclusivity without turning it into a gimmick, and the five-step high-frequency attenuator is there for a reason: dialing in top-end energy to match the room and placement, which matters more with horns than most speaker types.
Advertisement
Calling it a “museum piece” isn’t entirely off base, but the real goal here isn’t to redefine audiophile expectations. It’s to bridge two worlds that don’t usually overlap this cleanly: serious acoustic design and industrial design that people actually want to live with.
“The kO-R2 represents a powerful intersection of heritage and forward-thinking design. Partnering with Devon allows us to honor Klipsch’s 80-year legacy while pushing into new creative territory—delivering a product that is as culturally relevant as it is acoustically exceptional,” said Vinny Bonacorsi, COO of Klipsch.
The Bottom Line
This isn’t a typical brand crossover. Klipsch is working within its core strength—horn-loaded design—while Devon Turnbull brings a different perspective on how these systems look and live in real spaces. The kO-R2 builds on the kO-R1 with a larger, more complex horn and a move to a floorstanding design, which should translate into greater scale and output.
There are still no detailed specifications or pricing, but the context matters. The kO-R1 launched at $8,498 per pair and sold out quickly. For the kO-R2, production is expected to be limited to around 600 pairs, so availability is going to be tight from the start.
It’s aimed at a specific buyer: someone who values both the design and the underlying acoustic approach, and who is comfortable buying into the concept without a full data sheet upfront. Between the prior pricing and limited run, this won’t be a mainstream Klipsch product—and that’s the point.
Advertisement
Klipsch OJAS kO-R2 Loudspeaker in Red Oak veneer.
Price & Availability
Once released (expected to be June 2026), 600 pairs of the kO-R2 will be available worldwide in either Red Oak veneer or Hammertone Silver with a powder-coated, matte-black horn. Price has yet to be announced.
Two entrepreneurs, Benson Phelps and Carroll Faye, teamed up to open a small coal and wood delivery company in Baltimore in 1907. The business saw success in its early years, expanding rapidly over its first couple of decades. Faye decided to move on to other ventures and sold his stake in the business to Phelps, but the company continued to use Faye’s first name as its brand. The Carroll Independent Fuel Company began selling oil in the 1930s under the guidance of Phelps, and it never stopped. Today, drivers can still buy fuel from the same company, although they’ll now recognize it as Carroll Motor Fuels.
The Carroll network of gas stations might have grown significantly over its century-plus of trading, but its ownership structure has remained consistent. It’s still an independent, family-owned business, with various members of the Phelps family at the helm. John Phelps serves as the company’s CEO and President, while Richard B. Phelps III holds the title of Executive Vice President alongside C. Howard Phelps. Several more Phelps family members hold leadership roles.
Carroll isn’t the only gas station chain that has remained family owned since its inception. The Love’s chain of gas stations is also still owned by members of its founding family, and it has risen to become one of America’s largest privately owned companies.
Advertisement
The Carroll network operates under multiple brands
Alongside its own-brand gas stations, Carroll Independent Fuel also operates stations under various other names. The East Coast chain’s network includes stations that use Sunoco branding, which is most famously associated with the NASCAR Cup Series. Other locations are branded as BP gas stations, with Carroll working with the British-owned oil company since 2006.
Advertisement
In 2012, Carroll Independent Fuel also acquired High’s, a Baltimore-based chain of convenience stores. In an interview with the Baltimore Business Journal, Executive Vice President Howard Phelps said that the company realized that “competition on the gasoline retail side was transitioning to convenience,” and that Carroll wanted to “to go toe to toe” with rivals like Sheetz and Wawa.
The Carroll network continues to grow, with the company acquiring seven new sites in 2022. The new locations helped develop its network outside the company’s home state of Maryland, with Delaware, New Jersey, and Pennsylvania all seeing new Carroll-operated locations launched.
We’ve always been interested in fluidic computers, a technique that uses moving fluids to perform logic operations. Now, Spectrum reports that researchers have developed an electronics-free contact lens that monitors glaucoma and can even help treat it.
The lens is made entirely of polymer and features a microfluidic sensor that can monitor eye pressure in real time. It also has pressure-activated drug reservoirs that dispense medicine when pressure exceeds a fixed threshold. You can see Spectrum’s video on the device below.
This isn’t the first attempt to treat glaucoma, which affects more than 80 million people, with a contact lens. In 2016, Triggerfish took a similar approach, but it used electronic components in the lens, which poses problems for manufacturing and for people wearing them.
Naturally, the device depends on 3D printed molds to create channels and reservoirs in the lens. A special silk sponge in the reservoirs can absorb up to 2,700 times its weight. One sponge holds a red fluid that is forced by pressure into a serpentine microchannel. A phone app uses a neural network to convert the image of the red fluid into a pressure reading.
Advertisement
Two more sponges hold drugs that release at a given pressure determined by the width of the associated microchannel. This allows the possibility of increasing the dose at a higher pressure or even delivering two drugs at different pressure levels.


































































You must be logged in to post a comment Login