It’s depressing and entirely predictable that any move to improve efficiency is always hit by a wave of misplaced anger and full-on stupidity. In this case, I’m talking about Ed Miliband’s plan for tumble dryers.
In the recent government document, Raising standards for household tumble dryers, the bit that’s been getting certain people chomping at the bit is the sentence, “To improve the efficiency of household tumble dryers, the final regulations introduce a new minimum performance standard that phases out inefficient gas-fired, air-vented, and condenser models.”
In certain sectors, this move has been likened to the Soviet era, as it removes choice and forces consumers to buy more expensive heat pump appliances. All of which are bizarre hot takes, and completely miss the point. I’d know, as I review tumble dryers and have the cold facts.
This situation reminds me of the time that the EU introduced a new law that reduced the maximum power of vacuum cleaners from 1600W to 900W. The same kinds of people who are moaning about tumble dryers also moaned about this rule change, saying that homes would be dirtier and powerful cleaners would be banned.
Advertisement
Of course, those people were wrong about vacuum cleaners. Cleaning performance isn’t so much about raw suction power as it is overall efficiency: lower power vacuum cleaners can have as much suction power as those that draw more power, and things like motorised brushbars can improve dust collection without using significant amounts of power. In a shocking twist, people moaning about tumble dryers are also wrong.
Advertisement
Heat pump tumble dryers cost a little more but are a lot cheaper to run
It’s true, a heat pump tumble does cost more than a vented and condenser models. Looking at entry-level models, you’ll probably pay around £40 more upfront for a heat pump dryer than for a vented or condenser dryer.
That’s not a huge amount, but the more important bit of information is how much they cost to run. I review a lot of tumble dryers (all of my best buy tumble dryers are heat pump models), and the cold hard truth is that heat pump models are significantly cheaper to run.
Advertisement
In our guide, condenser vs heat pump tumble dryers, we looked at running costs for a washer-dryer (which uses a condenser for drying) and a heat pump model. The washer dryer used 2.387kWh to dry a load of clothes, and the heat pump used 0.813kWh.
At the current price cap of 24.67p per kWh of electricity, that’s a cost of 58.88p for the condenser dryer and 20.05p for the heat pump. That means that the condenser dryer costs 38.83p per cycle more to run.
In 103 cycles, the heat pump tumble dryer has clawed back that extra £40 it cost. That could be under a year (if you run a couple of cycles per week), or within two years. Everything past that is just more saving.
Several people complaining about the tumble dryer plan have said that they’d focus on reducing energy costs instead. So, say we could get electricity prices back down to around 16p per kWh.
Advertisement
Advertisement
In this scenario, our condenser dryer would cost 37.19p per cycle and the heat pump dryer 13p per cycle. The condenser is still 24.19p per cycle more expensive to run. In this scenario, it would take 165 cycles to get your extra £40 outlay back, but that’s still within two or three years for more people. Given that you’re likely to have a dryer for a good eight to 10 years, you’ll still save money in the long run.
Heat pump dryers do take longer, but they’re better for your clothes
Another thing thrown at heap pump tumble dryers is that they take longer to dry your clothes. That’s true, because of the way that they work.
Vented and condenser tumble dryers work via a heating element that’s passed into the drum at around 70°C, heating your clothing and removing moisture. This moisture is then either condensed into a tank (a condenser dryer) or vented out the back (a vented dryer).
Advertisement
Using hotter air speeds up the drying process, but it requires more electricity and the heat you generate is just pumped out.
Heat pump tumble dryers use a closed system, and use a compressor rather than a heating element. These dryers extract heat from the closed system and recycle it continuously (our guide, What is a heat pump tumble dryer?, explains more), running at around 50°C.
Advertisement
That lower temperature means longer drying times, but less energy use overall. And lower temperatures are better for clothes, as they’re kinder to the fabric and less likely to cause issues such as shrinking.
Advertisement
Aside from the money factor, energy is a precious resource, so why not use it as efficiently as possible?
That’s even the case if you have solar and are generating your own power. With a heat pump, less of your solar goes onto drying your clothes, which means, depending on the size of your array, you’re more likely to be able to generate the full power for the cycle, or your spare capacity can be used elsewhere: topping up a battery, running your TV or just for exporting to the grid, where you’ll get paid for it. Doing more with the resource you have is better, no matter how you cut it.
There are alternatives. Hotpoint ColdGuard Heat Pump tumble dryers are built to work in rooms as cold as 0°C.
Advertisement
Heat pump tumble dryers are better than traditional types, and the government taking steps to ensure that efficient models are the only ones you can buy makes sense in the long run. Here, as in any other area, efficiency is better for everyone and a cost saving is a cost saving, regardless of the price of electricity.
Right now, all of us who use AI models regularly for work or in our personal lives know that the basic interaction mode across text, imagery, audio, and video remains the same: the human user provides an input, waits anywhere between milliseconds to minutes (or in some cases, for particularly tough queries, hours and days), and the AI model provides an output.
But if AI is to really take on the load of jobs requiring natural interaction, it will need to do more than provide this kind of “turn-based” interactivity — it will ultimately need to respond more fluidly and naturally to human inputs, even responding while also processing the next human input, be it text or another format.
That at least seems to be the contention of Thinking Machines, the well-funded AI startup founded last year by former OpenAI chief technology officer Mira Murati and former OpenAI researcher and co-founder John Schulman, among others.
Advertisement
Today, the firm announced a research preview of what it deems to be “interaction models, a new class of native multimodal systems that treats interactivity as a first-class citizen of model architecture rather than an external software “harness,” scoring some impressive gains on third-party benchmarks and reduced latency as a result.
However, the models are not yet available to the general public or even enterprises — the company says in its announcement blog post: “In the coming months, we will open a limited research preview to collect feedback, with a wider release later this year.”
At the heart of this announcement is a fundamental shift in how AI perceives time and presence. Current frontier models typically experience reality in a single thread; they wait for a user to finish an input before they begin processing, and their perception freezes while they generate a response.
Advertisement
In their blog post, the Thinking Machines researchers described the status quo as a limitation that forces humans to “contort themselves” to AI interfaces, phrasing questions like emails and batching their thoughts.
To solve this “collaboration bottleneck,” Thinking Machines has moved away from the standard alternating token sequence.
Instead, they use a multi-stream, micro-turn design that processes 200ms chunks of input and output simultaneously.
This “full-duplex” architecture allows the model to listen, talk, and see in real time, enabling it to backchannel while a user speaks or interject when it notices a visual cue—such as a user writing a bug in a code snippet or a friend entering a video frame. Technically, the model utilizes encoder-free early fusion.
Advertisement
Rather than relying on massive standalone encoders like Whisper for audio, the system takes in raw audio signals as dMel and image patches (40×40) through a lightweight embedding layer, co-training all components from scratch within the transformer.
Dual model system
The research preview introduces TML-Interaction-Small, a 276-billion parameter Mixture-of-Experts (MoE) model with 12 billion active parameters. Because real-time interaction requires near-instantaneous response times that often conflict with deep reasoning, the company has architected a two-part system:
The Interaction Model: Stays in a constant exchange with the user, handling dialog management, presence, and immediate follow-ups.
The Background Model: An asynchronous agent that handles sustained reasoning, web browsing, or complex tool calls, streaming results back to the interaction model to be woven naturally into the conversation.
This setup allows the AI to perform tasks like live translation or generating a UI chart while continuing to listen to user feedback—a capability demonstrated in the announcement video where the model provided typical human reaction times for various cues while simultaneously generating a bar chart.
Impressive performance on major benchmarks against other leading AI labs’ fast interaction models
To prove the efficacy of this approach, the lab utilized FD-bench, a benchmark specifically designed to measure interaction quality rather than just raw intelligence.The results show that TML-Interaction-Small significantly outperforms existing real-time systems:
Advertisement
Responsiveness: It achieved a turn-taking latency of 0.40 seconds, compared to 0.57s for Gemini-3.1-flash-live and 1.18s for GPT-realtime-2.0 (minimal).
Interaction Quality: On FD-bench V1.5, it scored 77.8, nearly doubling the scores of its primary competitors (GPT-realtime-2.0 minimal scored 46.8).
Visual Proactivity: In specialized tests like RepCount-A (counting physical repetitions in video) and ProactiveVideoQA, Thinking Machines’ model successfully engaged with the visual world while other frontier models remained silent or provided incorrect answers.
Metric
TML-Interaction-Small
GPT-realtime-2.0 (min)
Gemini-3.1-flash-live (min)
Advertisement
Turn-taking latency (s)
0.40
1.18
0.57
Advertisement
Interaction Quality (Avg)
77.8
46.8
54.3
Advertisement
IFEval (VoiceBench)
82.1
81.7
67.6
Advertisement
Harmbench (Refusal %)
99.0
99.5
99.0
Advertisement
A potentially huge boon to enterprises — once the models are made available
If made available to the enterprise sector, Thinking Machines’ interaction models would represent a fundamental shift in how businesses integrate AI into their operational workflows.
A native interaction model like TML-Interaction-Small allows for several enterprise capabilities that are currently impossible or highly brittle with standard multimodal models:
Current enterprise AI requires a “turn” to be completed before it can analyze data. In a manufacturing or lab setting, a native interaction model can monitor a video feed and proactively interject the moment it detects a safety violation or a deviation from a protocol — without waiting for the worker to ask for feedback.
The model’s success in visual benchmarks like RepCount-A (accurate repetition counting) and ProactiveVideoQA (answering questions as visual evidence appears) suggests it could serve as a real-time auditor for high-stakes physical tasks.
Advertisement
The primary friction in voice-based customer service is the 1–2 second “processing” delay common in 2026’s standard APIs. Thinking Machines’ model achieves a turn-taking latency of 0.40 seconds, roughly the speed of a natural human conversation.
Because it handles simultaneous speech natively, an enterprise support bot could listen to a customer’s frustration, provide “backchannel” cues (like “I see” or “mm-hmm”) without interrupting the user, and offer live translation that feels like a natural conversation rather than a series of disjointed recordings.
Standard LLMs lack an internal clock; they “know” time only if it is provided in a text prompt. Interaction models are natively time-aware, allowing them to manage time-sensitive processes like “Remind me to check the temperature every 4 minutes” or “Alert me if this process takes longer than the last one”. This is critical for industrial maintenance and pharmaceutical research where timing is an essential variable.
Background on Thinking Machines
This release marks the second major milestone for Thinking Machines following the October 2025 launch of Tinker, a managed API for fine-tuning language models that lets researchers and developers control their data and training methods while Thinking Machines handles the infrastructure burden of distributed training.
Advertisement
The company said Tinker supports both small and large open-weight models, including mixture-of-experts models, and early users included groups at Princeton, Stanford, Berkeley and Redwood Research.
At launch in early 2025, Thinking Machines framed itself as an AI research and product company trying to make advanced AI systems “more widely understood, customizable and generally capable.”
In July 2025, Thinking Machines said it had raised about $2 billion at a $12 billion valuation in a round led by Andreessen Horowitz, with participation from Nvidia, Accel, ServiceNow, Cisco, AMD and Jane Street, described by WIRED as the largest seed funding round in history.
The Wall Street Journal reported in August 2025 that rival tech CEO Mark Zuckerberg approached Murati about acquiring Thinking Machines Lab and, after she declined, Meta pursued more than a dozen of the startup’s roughly 50 employees.
By April 2026, Business Insider reported that Meta had hired seven founding members from Thinking Machines, including Mark Jen and Yinghai Lu, while another Thinking Machines researcher, Tianyi Zhang, also moved to Meta. The same reporting said Joshua Gross, who helped build Thinking Machines’ flagship fine-tuning product Tinker, had joined Meta Superintelligence Labs, and that the company had grown to about 130 employees despite the departures.
Thinking Machines was not simply losing people, however: it also hired Meta veteran Soumith Chintala, creator of PyTorch, as CTO, and added other high-profile technical talent such as Neal Wu. TechCrunch separately reported in April 2026 that Weiyao Wang, an eight-year Meta veteran who worked on multimodal perception systems, had joined Thinking Machines, underscoring that the talent flow was not one-way.
Thinking Machines previously stated it was committed to “significant open source components” in its releases to empower the research community. It’s unclear if these new interaction models models will fall under the same ethos and release terms.
Advertisement
But one thing is certain: by making interactivity native to the model, Thinking Machines believes that scaling a model will now make it both smarter and a more effective collaborator.
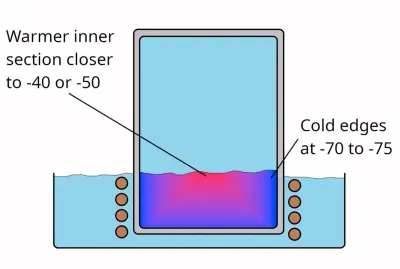
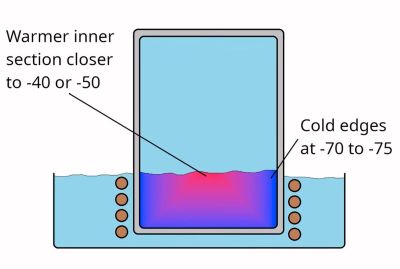
Although the term ‘dry ice’ is generally used for solid CO2, it’s much more accurate to call this ‘dry snow’, as, rather than being actual solid blocks, they are effectively snow that’s been compressed really tightly. While not really necessary for most applications of dry ice, it is possible to make blocks of actual CO2 ice, and thus [Hyperspace Pirate], as someone with a healthy obsession with cold things had to make some of his own.
As a first step, you, of course, have to chill down CO2 in a container, for which Mr. [Pirate] used a Joule-Thomson cryocooler, with a 15% butane, 35% propane, and 50% ethylene gas mixture. Of course, as ethylene is only easy to get if you have a lot of money to spend, you will want to make it yourself from ethanol. This involves boiling and 400°C aluminum oxide to capture the produced ethylene.
With the CO2 pressure chamber cooled in its refrigerated bath, the process didn’t take long. After opening the pressure chamber, the results were interesting to say the least. Although there was definite ice formation along the sides that contacted the metal chamber the closest, the closer to the center, the more the CO2 resembled the usual fluffy, compressed dry ice.
This is encouraging as it shows that it’s definitely possible to make nice ice pucks or cubes, but the method needs further refinement to get more ice and less snow.
BYD has officially unveiled the 2026 Seagull, sold internationally as the Dolphin Mini or Dolphin Surf, and the numbers deserve your attention.
The updated compact EV’s price starts from 69,900 yuan, which is around $10,300, in China, and tops out at 85,900 yuan, which is around $12,600. It debuted at the 2026 Beijing Auto Show before going on sale this week (via CarsNewsChina).
2026 BYD Seagull got launched w/ px from 69.9 to 97.9k RMB. The top 2 px versions come w/ Lidar + DiPilot-300 & DiLink-150 to have the sensor & compute for latest smart car tech.
This package adds 12k RMB on top of the standard DiPilot-100 config. Still comes in 305/405 km… pic.twitter.com/fEQQ9jOcdU
The standout upgrade this year is the optional “God’s Eye B” intelligence driving package, called the DiPilot 300 system, which adds a LiDAR sensor to the subcompact city car, increasing its price to between $13,400 and $14,400.
The system provides city-level navigation on autopilot, along with traffic light recognition and roundabout handling. That’s semi-autonomous driving capability at a price bracket where most car buyers in the US are still choosing between a used Toyota and a three-year-old Chevy.
The longer range BYD variant packs a 38.88 kWh battery pack that delivers up to 252 miles of CLTC-certified range. Base variants, on the other hand, use a 30.08 kWh battery pack that provides up to 190 miles of claimed range.
CnEVPost / BYD
BYD’s subcompact city car packs in enough punch
Given that it’s designed to be driven around in the city, the new BYD EV features a 55 kW motor that can generate 135 Nm of torque, numbers that might not sound great at first, but complement the car’s purpose.
The cabin offers a 12.8-inch central touchscreen display for handling navigation and 3D vehicle controls. Optional add-ons can get buyers 50W wireless charging, heated front seats, and a six-way power-adjusted driver’s seat.
Advertisement
To me, the Seagull’s 2026 update isn’t just a product refresh. By pushing LiDAR into the sub-$15,000 bracket, BYD is essentially normalizing advanced driver assistance at a price point where it’s hard to even imagine the feature.
When most people think about vacuum tubes, they picture big glass bottles glowing inside antique radios or early computers. History often treats tubes as a dead-end technology that was suddenly swept away by the transistor in the 1950s. But the reality is much more interesting. Vacuum tube technology did not simply stop evolving when the transistor appeared. In fact, some of the most sophisticated and technically impressive tube designs emerged after the transistor had already been invented.
During the final decades of mainstream tube development, manufacturers pushed the technology in remarkable directions. Tubes became smaller, faster, quieter, more rugged, and more specialized. Designers experimented with exotic geometries, ceramic construction, metal envelopes, ultra-high-frequency operation, and even hybrid tube-semiconductor systems. Devices such as acorn tubes, lighthouse tubes, compactrons, and nuvistors represented a last gasp of thermionic electronics.
Ironically, many of these innovations arrived just as solid-state electronics were becoming commercially practical. Vacuum tubes were improving rapidly right up until the market abandoned them.
The Pressure to Improve
By the 1930s and 1940s, vacuum tubes dominated electronics. Radios, radar systems, military communications, industrial controls, and the first digital computers all depended on them. But everyone was painfully aware of their problems.
Advertisement
Traditional tubes were fragile, generated heat, consumed significant power, and suffered from limitations at high frequencies. Internal lead lengths created parasitic inductance and capacitance. At radio frequencies and especially microwave frequencies, those unwanted effects made design difficult.
Military requirements during World War II accelerated development dramatically. Radar systems needed tubes capable of operating at VHF, UHF, and microwave frequencies. Vehicle equipment required devices that could withstand punishment. Computers with tubes suffered from frequent failures, took up entire rooms, and needed special cooling equipment, often bigger than the computer. These pressures drove tube designers into an intense period of innovation.
Acorn Tubes: Tiny Tubes for High Frequencies
One of the earliest major departures from conventional tube geometry was the acorn tube. Developed in the 1930s by RCA, the acorn tube got its name from its distinctive shape, which resembled an acorn with wire leads protruding from the base and sides. Unlike ordinary tubes, where the internal elements had relatively long leads, the acorn design minimized lead length to reduce parasitic capacitance and inductance. At high frequencies, this reduction was crucial.
One famous example was the 955 acorn triode. These tubes found use in experimental television receivers, military radios, and laboratory equipment. Acorn tubes also reflected an important trend in late tube development: engineers were increasingly treating tubes not merely as amplifying devices, but as microwave structures requiring careful electromagnetic design.
Advertisement
The Lighthouse Tube
If acorn tubes were specialized, lighthouse tubes were positively futuristic. Lighthouse tubes abandoned the classic cylindrical glass form almost entirely. Instead, they used stacked disk-like electrodes arranged in a compact coaxial structure. The resulting geometry minimized transit times and parasitic reactances, allowing operation into microwave frequencies.
The tubes vaguely resembled a lighthouse tower. These tubes became essential in radar systems during World War II and the early Cold War period. Some lighthouse designs could operate in the gigahertz range, something impossible for conventional receiving tubes.
Their construction also introduced new manufacturing techniques. Many used ceramic and metal rather than large glass envelopes. This improved heat resistance and mechanical stability while reducing losses at high frequencies. In many ways, lighthouse tubes represented the transition from classic vacuum tubes and true microwave devices like klystrons and traveling-wave tubes.
Advertisement
Metal Tubes and Ruggedization
Another path of tube evolution focused on durability and compactness. Early tubes used fragile glass envelopes that were easily broken and susceptible to microphonics and vibration. During the 1930s, manufacturers introduced all-metal tube designs. These tubes replaced the glass envelope with a metal shell, improving shielding and mechanical ruggedness.
Metal tubes were particularly attractive for military and automotive applications. Shielding reduced interference, while the smaller physical size allowed more compact equipment layouts.
Hybrid glass-metal constructions also became common. Engineers experimented constantly with new materials and packaging approaches to reduce noise, improve reliability, and extend tube lifespan.
Advertisement
Subminiature Tubes
One of the most impressive developments was the subminiature tube. These tiny devices often looked more like oversized resistors than conventional tubes. Some were less than an inch long and designed to be soldered directly into circuits rather than plugged into sockets.
Subminiature tubes emerged largely from military demands during and after World War II. Proximity fuzes for artillery shells required electronics small enough to survive being fired from a cannon. Traditional tubes would simply shatter under the acceleration.
The resulting ruggedized miniature tubes were shock-resistant and compact enough for portable military electronics. After the war, subminiature tubes appeared in hearing aids, portable radios, test instruments, and early miniaturized computers.
Advertisement
The Nuvistor: The Ultimate Receiving Tube
One of the most interesting late-stage vacuum tube was the RCA Nuvistor. Introduced by RCA in 1959, the nuvistor represented an attempt to create a truly modern vacuum tube for the transistor age.
Unlike classic glass tubes, nuvistors used a compact metal-and-ceramic construction. They were extremely small, highly reliable, vibration-resistant, and capable of excellent high-frequency performance. They also exhibited very low noise characteristics. At first glance, a nuvistor hardly resembles a traditional tube at all. You could easily mistake these for some other component in a metal can.
Technically, nuvistors were excellent devices. They offered superior performance in many RF applications compared to early transistors, particularly in television tuners, instrumentation, and aerospace electronics.
High-end studio microphones also adopted nuvistors because of their low noise and desirable electrical behavior. Some audiophiles still use nuvistor-based equipment today.
Advertisement
But despite their capabilities, nuvistors arrived too late. Semiconductor technology was improving rapidly. Silicon transistors were becoming cheaper, more reliable, and easier to manufacture in large quantities. Integrated circuits loomed on the horizon. The nuvistor may have been the best small receiving tube ever made, but it was competing against a technology whose economics would soon become overwhelming.
Compactrons
As semiconductor electronics advanced, tube manufacturers attempted another strategy: integration. The Compactron, introduced by General Electric in the early 1960s, combined multiple tube functions into a single envelope. A compactron might contain several triodes, pentodes, or diode sections in one package. This reduced component count, simplified wiring, and lowered manufacturing costs for television sets and other consumer electronics. Of course, tubes with multiple electrodes weren’t new. They dated back to at least 1926. However, GE’s aggressive marketing of the brand was an attempt to prevent designers from defecting to the solid-state camp.
In some sense, compactrons were the vacuum tube answer to integrated circuits. Engineers were trying to achieve greater functional density while keeping tube-based designs economically competitive. GE’s Porta-Color, the first portable color television, used 13 tubes, including 10 Compactrons. They usually have 12-pin bases and an evacuation tip at the bottom of the tube rather than at the top.
Advertisement
Compactrons saw widespread use in televisions, stereos, and industrial electronics during the 1960s and early 1970s. But again, semiconductor integration advanced even faster. The battle was becoming impossible to win.
Specialized Tubes Survived
Even after transistors took over consumer electronics, vacuum tubes remained important in specialized fields. Microwave tubes such as klystrons, magnetrons, and traveling-wave tubes continued to dominate high-power RF applications. Radar systems, satellite communications, particle accelerators, and broadcast transmitters all relied on advanced vacuum devices. In some areas, they still do.
A modern microwave transmitter aboard a communications satellite may still use a traveling-wave tube amplifier because tubes can handle very high frequencies and power levels efficiently.
No Instant Win
One misconception about electronics history is that the transistor immediately rendered tubes obsolete after its invention at Bell Labs in 1947. That is not what happened.
Advertisement
Early transistors had many limitations. They were noisy, temperature-sensitive, low-power, and expensive. Tubes often outperformed them in RF circuits, audio applications, and high-power systems well into the 1960s.
For a significant period, designers genuinely did not know which technology would dominate certain markets. Tube designers were still making substantial advances. Nuvistors and Compactrons were not desperate relics; they were serious engineering efforts intended to compete in a changing world.
Ultimately, however, semiconductors possessed overwhelming long-term advantages. Transistors required less power, generated less heat, occupied less space, and could be manufactured using scalable photolithographic processes. Once integrated circuits became practical, the economics shifted decisively. Vacuum tubes could evolve, but they could not shrink into millions of devices on a silicon chip.
The final years of vacuum tube development are often overlooked because history tends to focus on winners. Yet this period produced some of the most elegant and specialized electronic devices ever created. By the late tube era, vacuum tube manufacturing had become quite refined. Engineers could produce tubes with tightly controlled characteristics and surprisingly long operating lives.
Advertisement
Some early transistorized devices still retained subminiature tubes in certain high-frequency or low-noise stages because transistors had not yet surpassed tube performance in every application. This overlap period is often forgotten today. Electronics did not instantly switch from tubes to semiconductors. For years, many systems used both. For many years, a typical ham radio transmitter, for example, would be all solid-state except for the power amplifier finals, which were often a pair of 6146 tubes.
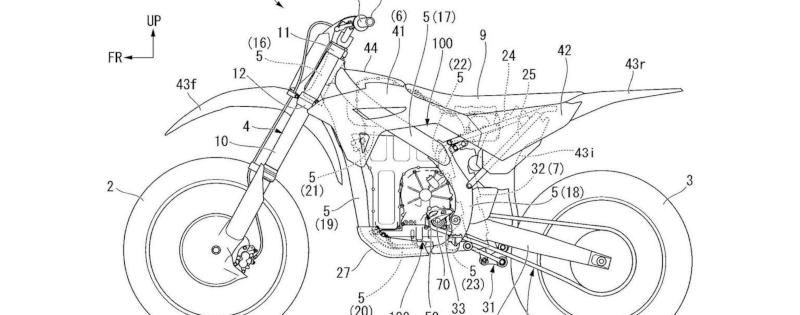
If you ride a motorcycle, you know it is a bit of an art to manage the transmission on a typical bike. Electric motorcycles lose some of that. You usually just have a throttle and a brake. No transmission and, crucially, no clutch. Honda just patented a simulated clutch for those who want the old-school experience, according to [Ben Purvis], writing for Australian Motorcycle News.
This isn’t just a do-nothing lever on the handlebar. There’s haptic feedback to feel when the clutch engages. The motor responds to your actions on the lever. If you pull the clutch in part of the way, the motor loses power up to the point where there is no engine power with the clutch fully in.
Most interestingly, the software understands that when you raise the throttle with the clutch in and then release the clutch, you expect a sudden burst of torque, and it will accommodate the request.
Advertisement
If you are a casual driver, this may seem like a gimmick. However, according to the post, motocross racers rely on precise power control like this.
If you do your own conversion, you could probably do something similar. Or, we suppose, a new build, if you prefer.
California Attorney General Rob Bonta announced a $12.75 million settlement agreement with General Motors (GM) over allegations that the company violated the California Consumer Privacy Act (CCPA).
The violations arise from allegations that the car maker illegally collected and sold Californians’ driving and location data to data brokers Verisk Analytics and LexisNexis Risk Solutions, between 2020 and 2024.
The investigation into this activity began in 2024, following media reports about automakers, including GM, sharing driver behavior with insurers.
The data was allegedly collected through GM’s OnStar subsidiary and its “Smart Driver” system and was reportedly intended for driver-scoring products related to insurance.
Advertisement
The American carmaker, which owns the GMC, Cadillac, Chevrolet, and Buick brands, was previously criticized by the U.S. Federal Trade Commission (FTC) for this unlawful data collection, with the government body banning GM from selling drivers’ data for five years.
The Californian authorities said GM failed to properly notify consumers or obtain their consent for this data collection, and retained the data for longer than necessary, even re-purposing it for sale, and making $20 million nation-wide.
“General Motors sold the data of California drivers without their knowledge or consent and despite numerous statements reassuring drivers that it would not do so,” Attorney General Rob Bonta stated.
“This trove of information included precise and personal location data that could identify the everyday habits and movements of Californians.”
Advertisement
The amount of $12.75 million in civil penalties is a record in the state’s history, and the first case of enforcement action focused on data minimization rules.
In addition to the fine, GM is also required to:
Stop selling driving data to consumer reporting agencies and brokers for five years.
Delete retained driving data within 180 days unless consumers explicitly consent to retention.
Ask LexisNexis and Verisk to delete the data they received previously.
Implement a stronger privacy compliance program and submit regular assessments to regulators.
The officials said California drivers were unlikely to have faced higher insurance premiums as a result of GM’s data sales, thanks to state law prohibiting insurers from using driving data to set rates.
BleepingComputer has contacted GM with a request for a comment on California’s announcement, but we have not received a response by publication time.
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
Microsoft security exec Shawn Bice is returning to Amazon Web Services as VP of AI Services, leading the company’s Automated Reasoning Group as AWS doubles down on making AI agents more reliable.
Bice will report to Swami Sivasubramanian, Amazon’s VP of Agentic AI, according to an internal AWS email Monday afternoon, viewed by GeekWire.
“We are at an inflection point with Agentic AI,” Sivasubramanian wrote in the email, explaining that bringing AI and automated reasoning together is essential to building trustworthy agents.
It’s a full-circle move for Bice. He worked at Microsoft early in his career and spent five years running AWS’s database portfolio before another former AWS leader, Charlie Bell, recruited him back to Microsoft in 2022 to help build the Redmond company’s revamped security organization.
At Microsoft, Bell stepped down from that security leadership role in February to become an individual contributor.
Advertisement
Amazon’s Automated Reasoning Group uses a discipline known as neurosymbolic AI, which combines traditional AI’s pattern-matching abilities with mathematical techniques that can prove whether software is doing what it’s supposed to do.
In the email, Sivasubramanian wrote that bringing automated reasoning and AI together is “the fundamental premise” behind AWS’s investment in the field, calling it critical to building agents that businesses can trust to act on their own.
AWS has been facing questions about the reliability of AI agents in its own operations. In February, Amazon pushed back on a Financial Times report that its Kiro AI coding tool had caused AWS outages, though it acknowledged a limited disruption to a single service after an AI agent was allowed to make changes without human oversight.
At Microsoft, Bice’s role had expanded to Corporate Vice President of Security Platform & AI, overseeing Microsoft Security Copilot, Microsoft Sentinel, and AI security research, according to his LinkedIn profile.
Advertisement
Before that, he spent a year as president of products and technology at Splunk, sandwiched between his two stints at the larger companies.
Bice originally joined Microsoft in 1997 and spent more than 17 years there across two stints, in roles that included managing SQL Server and Azure cloud data services. He left for AWS in 2016, where he ran the database portfolio — including Amazon Aurora, DynamoDB, and RDS — for five years before departing in 2021.
He also serves on the board of WaFd Bank, where he chairs the technology committee.
Digg is relaunching again, this time as an AI-focused news aggregator rather than the Reddit-style community site it recently abandoned. TechCrunch reports: On Friday evening, the founder previewed a link to the newly redesigned Digg, which now looks nothing like a Reddit clone and more like the news aggregator it once was. This time around, the site is focused on ranking news — specifically, AI news to start. In an email to beta testers, the company said the site’s goal is to “track the most influential voices in a space” and to surface the news that’s actually worth “paying attention to.” AI is the area it’s testing this idea with, but if successful, Digg will expand to include other topics. The email warned that the site was still raw and “buggy,” and was designed more to give users a first look than to serve as its public debut.
On the current homepage, Digg showcases four main stories at the top: the most viewed story, a story seeing rising discussion, the fastest-climbing story, and one “In case you missed it” headline. Below that is a ranked list of top stories for the day, complete with engagement metrics like views, comments, likes, and saves. But the twist is that these metrics aren’t the ones generated on Digg itself. Instead, Digg is ingesting content from X in real-time to determine what’s being discussed, while also performing sentiment analysis, clustering, and signal detection to determine what matters most. […] The site also ranks the top 1,000 people involved in AI, as well as the top companies and the top politicians focused on AI issues.
There’s a new book out by author Roland Betancourt, entitled, “Disneyland and the Rise of Automation: How Technology Created the Happiest Place on Earth.” In an extensive article about the book in Smithsonian Magazine, written by the author, Betancourt details the events that led Walt Disney to visit several Detroit-area Ford locations in 1948, following his visit to the Chicago Railroad Fair. Disney and his traveling companion, animator Ward Kimball, saw Ford’s collection of locomotives and antique cars, Ford’s historical Greenfield Village, and finally Ford’s huge, 1200-acre River Rouge assembly plant.
River Rouge was a place where the ore for making steel went in one end and finished automobiles rolled off the assembly line at the other end. The entire process took only 28 hours, from raw materials to completed vehicles.
But there was an additional reality that may not have been lost on Walt Disney and Ward Kimball — the River Rouge plant, built by the man behind America’s first major automotive giant, was also a giant tourist attraction to promote the Ford brand. A full four years before its opening, tours had started going through the plant, moving people from place to place in custom glass-roofed buses. The tour itself started in the Ford Rotunda, a building originally created for an exhibition in Chicago during 1933-34 and moved near River Rouge afterward. The author posits that while Greenfield Village may have inspired Main Street, USA, River Rouge had a direct connection to Disneyland’s Tomorrowland, where future innovations could be showcased.
Advertisement
What else should you know about the Disneyland-Ford connection?
Earl Theisen Collection/Getty Images
Automation was a hot topic in the postwar U.S., from the period of the late 1940s up until the 1960s, stoking fears of widespread job losses. Roland Betancourt makes the case that the technology underpinning the rides at Disneyland was derived from what Walt and Ward saw in action at River Rouge. It was automation that made it possible for Disney’s dream to come true, with repeatable, consistent results and even special effects provided by the machines behind the scenes.
He explains how the Peter Pan ride was based on a commonly used conveyor system that suspended riders from a rail placed above their heads. Programmable logic controllers from the auto industry to control the Matterhorn Bobsleds, as well as the adaptation of magnetic tape drives used in missile testing to animate the Tiki Room’s macaws, were all implementations of automation that seemed friendlier and less threatening.
Advertisement
Five days after returning to California in 1948, Disney sent a message to a production designer concerning a “Mickey Mouse Park.” It included a railroad, a village with stores, and other features he had seen at Ford’s Greenfield Village. By the time that Disneyland officially opened to the public in Anaheim, California on Monday, July 18, 1955, Disney’s vision had expanded to include attractions like Mr. Toad’s Wild Ride, the Jungle Cruise, Snow White’s Adventures, and Space Station X-1, as well as the Castle and the Stagecoach. More than 70 years later, there are six different Disney-themed parks in the U.S., Europe, and Asia.
For decades, assessingcholesterol risk has been built around a simple idea: Lower “bad” cholesterol, lower your chance of a heart attack. The test at the center of that approach measures how much low-density lipoprotein, or LDL cholesterol, is circulating in part of the blood. It has shaped everything from clinical guidelines to the widespread use of statins, medications that reduce LDL.
It works. Lowering LDL cholesterol reduces heart attacks, strokes, and early death. But it doesn’t tell the whole story.
The LDL cholesterol test measures the amount of cholesterol inside the low-density lipoprotein particles circulating in the bloodstream. Those LDL particles containing the cholesterol can get trapped in artery walls, forming plaques that can eventually block blood flow. As the test measures the amount of cholesterol being carried, not the number of LDL particles themselves, two people can have the same LDL cholesterol level but very different numbers of particles, and therefore different levels of risk.
That gap has pushed researchers toward a different way of measuring risk. Apolipoprotein B, or apoB, reflects the total number of cholesterol-carrying particles in the blood rather than how much cholesterol they contain. A growing body of research suggests it’s a more accurate way of identifying who is at risk and who’s not.
Advertisement
In March 2026, the American Heart Association and American College of Cardiology recognized this. Their updated cholesterol guidelines acknowledged apoB as a potentially more precise marker, in line with earlier European recommendations. But they stopped short of recommending apoB as the primary method for testing.
“They review the evidence and rank apoB as superior, but the actual rules of the road continue to prioritize LDL,” says Allan Sniderman, a cardiologist at McGill University.
Sniderman was an author on a 2026 JAMA modeling study that analyzed lifetime outcomes for around 250,000 US adults eligible for statin treatment. Comparing LDL cholesterol, non-HDL cholesterol, and apoB, the study found that using apoB to guide treatment decisions would prevent more heart attacks and strokes than current approaches, while remaining cost-effective.
ApoB testing can be done through standard blood tests. So why has it not filtered into routine care? Not even in Europe, where the guidelines have reflected its usefulness for years.
Advertisement
Part of the answer is inertia. For decades, LDL cholesterol has been both a scientific breakthrough and a public health success story. It is simple, widely understood, and directly linked to treatments that work.
“For 50 years, LDL cholesterol was an amazing discovery,” Sniderman says. “It’s not that it isn’t a good marker. It is a good marker.”
Børge Nordestgaard, president of the European Atherosclerosis Society, agrees that LDL cholesterol remains central for a reason. “The evidence is immense; it’s beyond discussion,” he says. “Statins reduce heart attacks, strokes, and early death through LDL cholesterol lowering.”
That success helped shape a powerful narrative: LDL is “bad cholesterol,” and lowering it saves lives. But that simplicity has also limited how risk is understood.
Advertisement
“The result is patients and physicians know little or nothing about apoB,” Sniderman says.
More recent research suggests that the cholesterol picture is more complex, especially in people already taking statins. Previous studies led by Nordestgaard have shown that in treated patients, high levels of apolipoprotein B and non-HDL cholesterol remain associated with increased risk of heart attacks and mortality, while LDL cholesterol does not. ApoB, in particular, emerged as the most accurate marker.
For Kausik Ray, a cardiologist at Imperial College London, the challenge is not choosing one marker over another, but understanding what each one captures, and what it misses.
“We’re not interested in cholesterol for its own sake,” Ray says. “We’re trying to prevent heart attacks and strokes.”






 Although the term ‘dry ice’ is generally used for solid CO2, it’s much more accurate to call this ‘dry snow’, as, rather than being actual solid blocks, they are effectively snow that’s been compressed really tightly. While not really necessary for most applications of dry ice, it is possible to make blocks of actual CO2 ice, and thus [Hyperspace Pirate], as someone with a healthy obsession with cold things had to make some of his own.
Although the term ‘dry ice’ is generally used for solid CO2, it’s much more accurate to call this ‘dry snow’, as, rather than being actual solid blocks, they are effectively snow that’s been compressed really tightly. While not really necessary for most applications of dry ice, it is possible to make blocks of actual CO2 ice, and thus [Hyperspace Pirate], as someone with a healthy obsession with cold things had to make some of his own.




















































You must be logged in to post a comment Login