





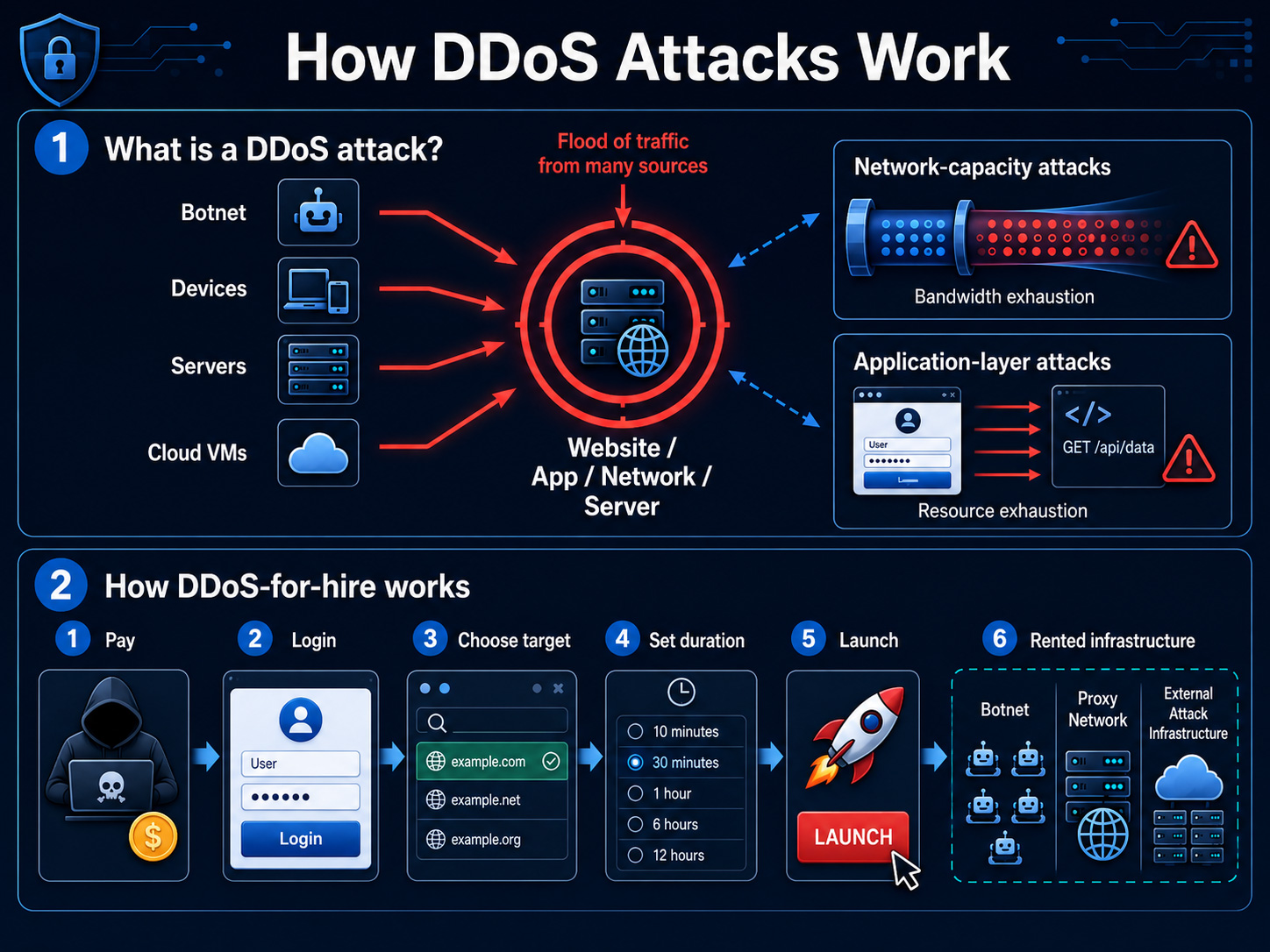









The web browser has been the default interface for accessing online information for decades, but AI search is starting to change that assumption. Tools like Microsoft Copilot already let users ask plain-language questions and receive direct answers, bypassing the traditional results page entirely.
NLWeb is Microsoft’s attempt to extend that shift down to the website level itself. Announced at Build 2025, it’s an open protocol that lets any web property respond to natural language queries without a search engine acting as an intermediary.
Whether Build 2026 marks a meaningful step forward for NLWeb’s adoption, or confirms that it’s still an experiment in search of a standard, is worth paying close attention to. Here’s what we know so far.
What is the NLWeb Protocol?
NLWeb stands for Natural Language Web. It’s an open-source project from Microsoft that allows any website to accept and respond to natural language queries, turning a standard web property into what Microsoft describes as an AI-powered app.
The project was conceived and built by R.V. Guha, who joined Microsoft as CVP and Technical Fellow. Guha’s background in web infrastructure matters here: he created RSS, RDF, and Schema.org, three formats that now underpin how structured content is shared and indexed across much of the web.
Microsoft introduced NLWeb at Build 2025 in May 2025 and drew a direct comparison to HTML’s role in making website creation accessible. That framing is ambitious, and worth holding lightly. HTML solved the problem of publishing content; NLWeb is attempting to solve how both humans and AI agents query that content once it’s published.
What distinguishes NLWeb from a standard chatbot widget is that every NLWeb endpoint also runs as a Model Context Protocol (MCP) server. MCP is an open standard that Anthropic originally developed in November 2024 for connecting AI systems to external data sources, and it has since gained widespread industry adoption. By building NLWeb on top of MCP, Microsoft is wiring website content directly into the broader ecosystem of AI agents.
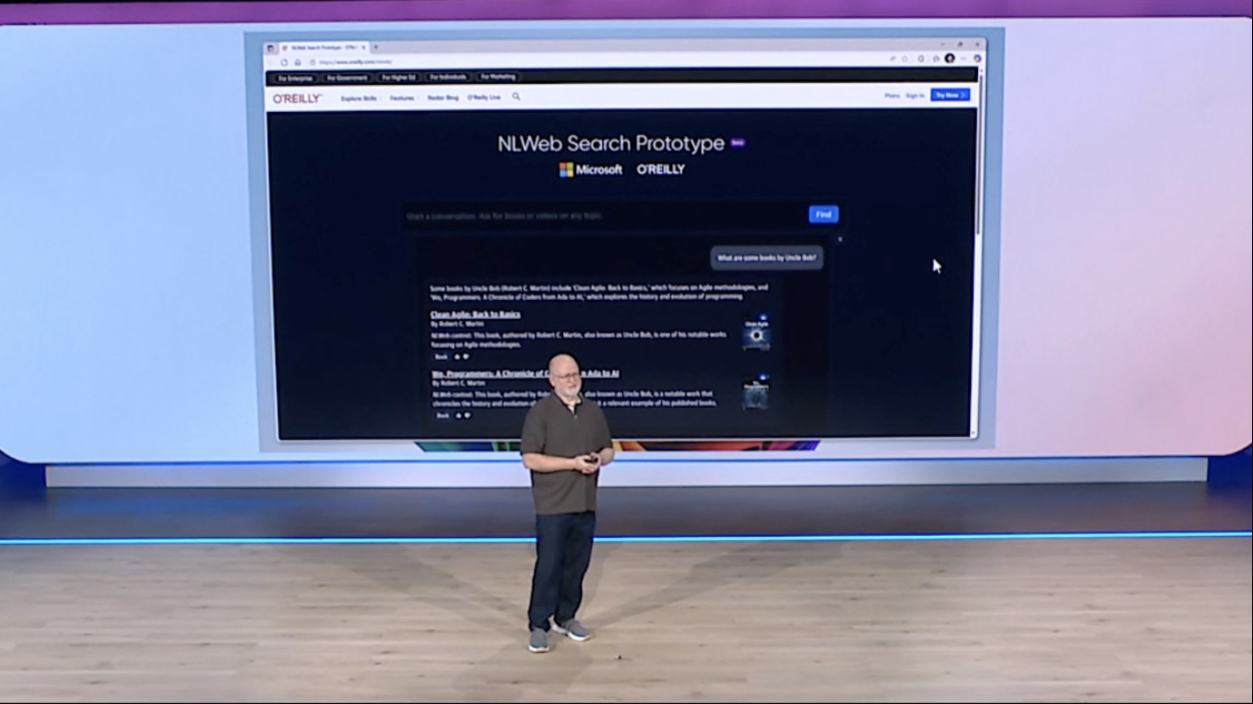
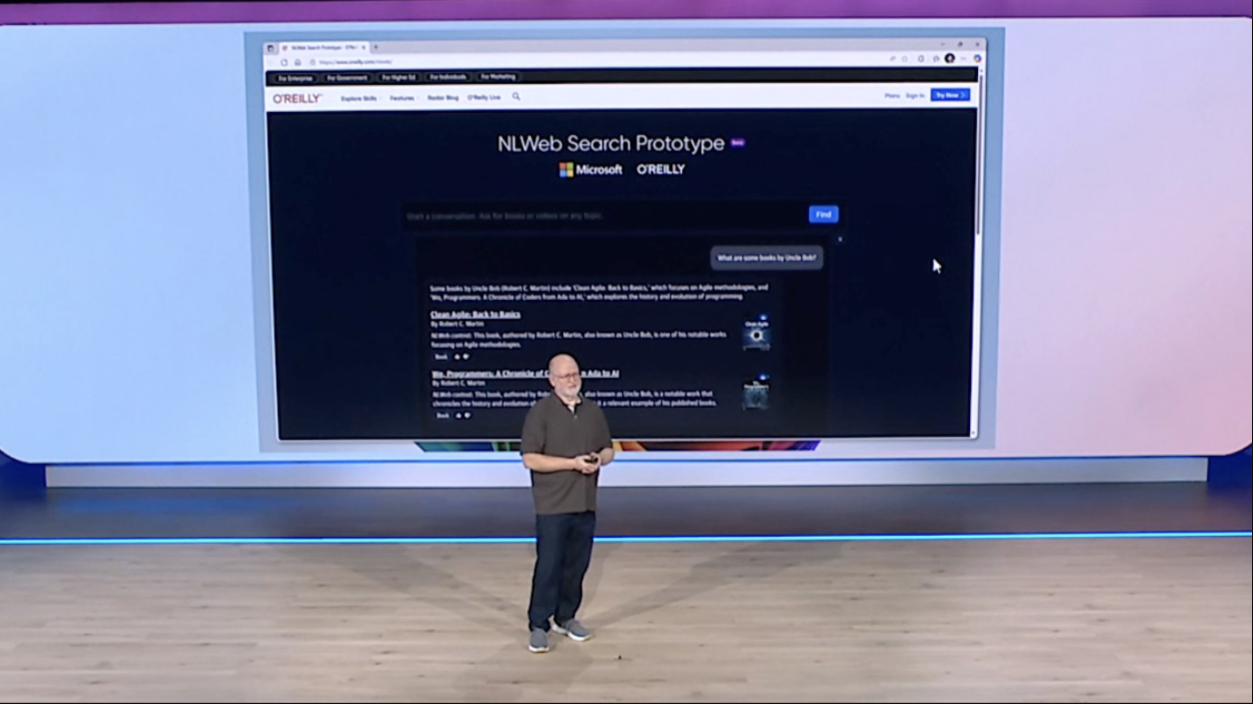
Early adopters include Shopify, TripAdvisor, Eventbrite, O’Reilly Media, Hearst properties like Delish, Chicago Public Media, and Common Sense Media. The pattern across those names is clear: well-organized sites with structured catalogs of content, the kind that maps cleanly onto the web formats NLWeb depends on.
How does the NLWeb Protocol work?
NLWeb sits on top of structured data that most websites already publish. It reads formats like Schema.org and RSS, which are in use across more than 100 million websites according to the project’s documentation, and adds a natural language layer on top of them using a large language model of the developer’s choice.
The protocol exposes two endpoints. The /ask endpoint handles natural language queries from human users via JSON over REST, returning structured Schema.org JSON responses. The /mcp endpoint implements an MCP server, allowing external AI agents to connect to the site and query its content programmatically on terms the publisher controls.
When a query arrives at /ask, NLWeb doesn’t hand it to a single LLM call. It breaks the query into multiple parallel processing steps: decontextualizing the query, retrieving relevant content from a vector database, and using the LLM to rank and generate the final response. This pattern of many focused model calls rather than one large prompt produces more consistent results than a single-pass approach.
The /ask endpoint also maintains chat history within a session, so follow-up questions can build on earlier ones without forcing the user to re-establish context. That’s a practical difference from keyword search, where each query starts from scratch regardless of what came before.
Because NLWeb is technology-agnostic, you’re not locked into any specific model, infrastructure provider, or operating system. The project’s GitHub repository provides a Python reference implementation and quickstart guides, with support for all major vector databases and LLM endpoints.
NLWeb at Microsoft Build 2026: What to expect
Build 2026 takes place June 2-3 at Fort Mason Center in San Francisco, marking a notable venue shift from the Seattle Convention Center that has hosted the conference for most of the past decade. Microsoft has described this year’s event as deliberately “no-fluff,” with a focus on technical depth over broad-audience announcements.
The session catalog spans over 90 entries organized across seven tracks: Agents and Apps, Azure AI Platform / Azure AI Foundry, GitHub and developer productivity, Microsoft Fabric, Responsible AI, Windows, and Working with Models. NLWeb is most directly connected to the Agents and Apps track, which is expected to cover MCP tooling updates given Microsoft’s ongoing investment in that protocol.
NLWeb was announced just over a year ago, which means Build 2026 is the first major conference where the protocol can be evaluated against documented real-world deployment rather than potential. Cloudflare added native NLWeb support via its AutoRAG infrastructure in early 2026, offering a managed deployment path rather than a manual integration, which is a signal that the ecosystem is beginning to solidify.
Microsoft joined the MCP Steering Committee at Build 2025 and contributed an updated authorization specification and the design of an MCP server registry service. Any further updates to MCP governance, agent discovery, or server orchestration at Build 2026 will have direct implications for NLWeb, given how tightly the two protocols are coupled.
The opening keynote from CEO Satya Nadella is where Microsoft typically frames its platform-level priorities. At Build 2025, Nadella characterized the event as marking “the age of AI agents.” Whether NLWeb receives dedicated keynote attention in 2026 or surfaces primarily through breakout sessions, it sits squarely within what the conference catalog describes as its central theme: moving AI agent development from announced to production-ready.
What this means for web developers
For developers building on the web, NLWeb creates practical pressure to audit how structured your site’s data actually is. The protocol performs best with content organized as lists of items: products, events, recipes, reviews. Sites with poor or missing semantic markup will get noticeably weaker results, because NLWeb’s retrieval layer depends on the Schema.org annotations many publishers have underinvested in.
But more importantly, NLWeb blurs the boundary between a website and an API. Running an NLWeb endpoint means your site becomes queryable by external AI agents, not just human visitors with a browser, which raises governance questions about which agents can access your content, at what rate, and on what terms.
On the tooling side, Microsoft has been expanding Azure AI Foundry and its MCP-related developer infrastructure, both of which are expected to feature at Build 2026. For developers who want to add NLWeb to an existing property today, the reference implementation on GitHub is the clearest starting point, with Cloudflare’s AutoRAG integration now offering a more managed path to deployment for teams that don’t want to handle the underlying infrastructure themselves.















































You must be logged in to post a comment Login