

Tech
MiniMax-M3 debuts, eclipsing GPT-5.5 and Gemini 3.1 Pro on key benchmark performance for just 5-10% of the cost
Big news in enterprise AI broke over the weekend as Chinese AI startup MiniMax released its highly anticipated M3 large language model on Sunday evening Eastern time, pairing frontier-tier coding and agentic performance with a 1-million-token context window and native multimodality for a fraction of the cost of leading proprietary models, with pricing starting at just $20 per month under its new subscription token plans.
The company’s leadership also announced plans to deliver the model under an open source license including “open weights,” allowing for full enterprise downloading and customizability free-of-charge, coming sometime in the next 10 days. For now, it is available via the MiniMax API at a special discounted price of $0.3 per 1 million input tokens and $1.20 per million output tokens (on fresh cache) for the next week — beating proprietary U.S. giants like Google, OpenAI and Anthropic handily on cost, while also eclipsing the performance of the latest models from the former two on selected benchmarks.
Even at its full price of $0.6/$2.40 per million input/output tokens, MiniMax-M3 remains at just 8-20% the cost of the leading, proprietary U.S. models.
The traditional matrix governing large language model development has long dictated a rigid choice: software developers can either access top-tier closed-source intelligence behind restrictive APIs, or deploy nimble, cost-effective open models that falter on multi-step reasoning, dense coding tasks, and massive data sequences. MiniMax-M3 fundamentally upends this paradigm.
By unifying these two historically separated frontier capabilities, M3 introduces a level of comprehensive utility previously restricted to expensive, closed-source ecosystems, effectively shifting the baseline of open-weights systems while drastically minimizing the operational compute footprint required to execute complex development loops.
VentureBeat Frontier AI Model API Pricing Snapshot
|
Model |
Input |
Output |
Total Cost |
Source |
|
MiMo-V2.5 Flash |
$0.10 |
$0.30 |
$0.40 |
|
|
deepseek-v4-flash |
$0.14 |
$0.28 |
$0.42 |
|
|
deepseek-v4-pro |
$0.435 |
$0.87 |
$1.305 |
|
|
MiniMax-M3 |
$0.30 |
$1.20 |
$1.50 (limited time only) |
|
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
$1.75 |
|
|
MiMo-V2.5 |
$0.40 |
$2.00 |
$2.40 |
|
|
Grok 4.3 low context |
$1.25 |
$2.50 |
$3.75 |
|
|
GLM-5 |
$1.00 |
$3.20 |
$4.20 |
|
|
Kimi-K2.6 |
$0.95 |
$4.00 |
$4.95 |
|
|
GLM-5.1 |
$1.40 |
$4.40 |
$5.80 |
|
|
Grok 4.3 high context |
$2.50 |
$5.00 |
$7.50 |
|
|
Qwen3.7-Max |
$2.50 |
$7.50 |
$10.00 |
|
|
Gemini 3.5 Flash |
$1.50 |
$9.00 |
$10.50 |
|
|
Gemini 3.1 Pro Preview ≤200K |
$2.00 |
$12.00 |
$14.00 |
|
|
GPT-5.4 |
$2.50 |
$15.00 |
$17.50 |
|
|
Gemini 3.1 Pro Preview >200K |
$4.00 |
$18.00 |
$22.00 |
|
|
Claude Opus 4.8 |
$5.00 |
$25.00 |
$30.00 |
|
|
GPT-5.5 |
$5.00 |
$30.00 |
$35.00 |
New MiniMax Sparse Attention (MSA) technique helps keep the model’s cost low
At the core of the model’s efficiency lies an architectural departure from classic Transformer networks. Standard attention mechanisms scale quadratically ($O(N^2)$), meaning computational and financial costs explode as text inputs lengthen.
To combat this “inherent flaw,” the engineering team implements MiniMax Sparse Attention (MSA), a clean, extensible sparse attention blueprint.
To visualize this innovation, think of traditional full attention as an editor reading an entire library from scratch every time they need to verify a single sentence. MSA acts as an intelligent indexing clerk, using a pre-filtering phase to partition Key-Value (KV) matrices into highly precise blocks.
At the operator level, MSA uses a “KV outer gather Q” approach. The system treats KV blocks as an outer loop, dynamically aggregating only the specific queries that hit them. Because each data block is read exactly once and memory access remains strictly contiguous, hardware utilization skyrockets.
In internal trials, MSA runs more than 4x faster than alternative open-source solutions like Flash-Sparse-Attention or flash-moba.
When managing a maxed-out context length of 1 million tokens, M3’s per-token compute demand drops to just 1/20th of the previous generation model, translating into a 9x acceleration in the prefilling stage and a 15x boost during decoding.
Rather than taking a pretrained text network and fusing it with a separate vision model, MiniMax engineered M3 as a natively multimodal system from “Step Zero”.
The company overhauled its data ingest machinery to blend naturally interleaved sequences of text, images, and visual components, scaling the total pretraining corpus beyond 100 trillion tokens.
This deep data alignment enables the model to translate complex visual geometries, such as programming charts or coordinate maps, into structural code without losing contextual fidelity. On standardized assessments, M3 validates this engineering path.
The model records a 59.0% on SWE-Bench Pro, an autonomous agent metric, positioning it ahead of closed models like GPT-5.5 and Gemini 3.1 Pro. It achieves a 66.0% on Terminal Bench 2.1, a 74.2% on MCP Atlas, and an 83.5 on BrowseComp—outstripping Claude Opus 4.7’s benchmark score of 79.3 in autonomous browsing and information retrieval.

However, when contrasted with Anthropic’s newly released, premium frontier model, Claude Opus 4.8, from last week, the competitive ceiling of M3’s efficient sparse-attention footprint becomes evident across directly comparable, tool-intensive agent benchmarks.
In the domain of pure code modification on SWE-Bench Pro, M3’s 59.0% score drops behind Opus 4.8’s leading 69.2% threshold.
A similar performance delta manifests in automated system environments via Terminal-Bench 2.1; while M3’s 66.0% terminal execution score effectively runs neck-and-neck with the previous-generation Opus 4.7 baseline of 66.1%, it trails the upgraded Opus 4.8 architecture, which achieves 74.6%.
Furthermore, evaluations tracking continuous GUI interaction on the OSWorld-Verified sandbox place M3’s automated computer use at 70.0%, compared to a higher 83.4% validation rate secured by Opus 4.8.
These standardized evaluations illustrate the structural trade-offs currently defining the ecosystem: closed-source systems like Opus 4.8 maintain absolute margin leads on hyper-complex reasoning vectors, yet M3 delivers a highly capable baseline of local, tier-one automated operation without the compounding premium of closed-door API subscription fees.
When positioned alongside the heavy-duty inference metrics of the newly minted, fellow open weights model DeepSeek-V4 Pro Max, M3 holds its ground across core agentic categories while asserting narrow advantages in specialized code synthesis.
On the software engineering matrix of SWE-Bench Pro, M3’s 59.0% resolution efficiency edges past DeepSeek-V4 Pro Max’s score of 55.4%.
However, the competitive friction tightens in command-line environments; under Terminal Bench evaluations, DeepSeek-V4 Pro Max pulls slightly ahead with a 67.9% execution accuracy over M3’s 66.0% mark.
In web orchestration and open-world browsing simulations, the two architectures reach a virtual statistical parity, with M3 registering an 83.5% on BrowseComp compared to DeepSeek’s 83.4%.
Similarly, on the MCP Atlas tool-use framework, M3 secures a narrow lead at 74.2% against DeepSeek’s 73.6%.
This close alignment demonstrates that while DeepSeek handles a massive 1.6-trillion total parameter footprint with specialized high-effort reasoning modes, MiniMax’s block-filtered sparse attention mechanism yields directly competitive execution efficiencies without requiring extensive parameter activation scaling.
MiniMax Code AI agent offers Agentic Team capabilities
MiniMax translates these architectural gains into immediate utility through an updated product suite divided between standalone applications, customizable subscription tiers, and raw developer infrastructure. For end-user orchestration, the flagship implementation is MiniMax Code, an AI agent product designed to maximize M3’s multi-step capabilities.
Operating via web or native desktop apps, MiniMax Code runs an “Agent Team” capable of breaking massive engineering tasks into multi-stage, concurrent workflows.
The system relies on a “Producer + Verifier” adversarial harness loop. As one agent instance generates code, a secondary verifier instance aggressively tests and reflects upon execution outputs, allowing the network to self-correct and operate autonomously for days without human oversight. Because of its native visual grounding, MiniMax Code supports direct computer use.
A developer can issue a cross-application voice prompt via their phone to have the model open a localized enterprise ERP client and batch-populate data tables directly from an open Excel spreadsheet.
For custom setups, developers can pipeline M3 directly into existing workflows using an API key (sk-cp) compatible with common alternative IDE environments like Claude Code, Cursor, Roo Code, and Cline. The API introduces a toggleable “thinking mode”.
When enabled, M3 routes processing power into deep reasoning and long-horizon planning; when disabled, the model runs at minimal latency for quick text completion. The companion Token Plan models an aggressive pricing strategy structured around shared multimodal quotas. Billed annually, three options are available:
-
Plus ($20/month): Supplies ~1.7B tokens per month and handles 3–4 concurrent agents.
-
Max ($50/month): Supplies ~5.1B tokens per month, manages 4–5 concurrent agents, and adds 3 automated video clips per day via Hailuo 2.3.
-
Ultra ($120/month): Supplies ~9.8B tokens per month, facilitates 6–7 concurrent agents, and extends video capacity to 5 daily clips.
Open weights makes M3 much more attractive for enterprise use
MinMax’s pledge to release M3 under an open-weights license model—with weights and technical documentation launching on HuggingFace and GitHub within 10 days—carries significant strategic weight for enterprise infrastructure managers.
However, it is still to be determined precisely which license the weights will be available under, and whether or not it will be permissible for consumer usage, e.g. MIT, Apache 2.0 or the new OpenMDW license. If so, the calculus looks like this:
|
Feature / Model Attribute |
Closed API Providers (e.g., GPT-5.5, Opus 4.7) |
Open-Weights Frontier (MiniMax M3) |
|
Data Privacy & Boundaries |
Requires external API requests; potential data ingestion vectors. |
Total local isolation; runs entirely inside private user clusters. |
|
Custom Optimization |
Limited to basic fine-tuning wrappers or prompt engineering. |
Full pipeline control; architecture allows deep adapter/weights customization. |
|
Cost Vector Consistency |
Bound to perpetual per-token API pricing models. |
Computational demands cut to 1/20th; mitigates hardware ceiling. |
By shipping the underlying model weights directly to the community, MiniMax departs from the closed-door approach favored by major American AI labs.
For enterprise users bound by strict compliance and privacy rules, open weights mean they can run M3 locally on internal hardware.
This setup completely removes the risk of data leakage associated with public APIs. Furthermore, it permits engineering teams to run bespoke fine-tuning passes, modify internal architectures, or embed specialized system prompts deep within the model layers—transforming an off-the-shelf system into a highly targeted proprietary asset.
Initial community reactions are resoundingly positive
The developer ecosystem reacted immediately to M3’s operational benchmarks, singling out its long-horizon autonomous behavior and cost-to-performance profile.
A major focal point of discussion is a 12-hour automated verification test where M3 was tasked with reproducing an ICLR 2025 Outstanding Paper Award winner, titled “Learning Dynamics of LLM Finetuning”.
As MiniMax’s own researcher @MikaStars39 highlighted on X:
“M3 ran autonomously for nearly 12 hours, producing 18 commits and 23 experimental figures on its own, and got the core experiments working:
-
it matched the predicted probability trends in the SFT stage
-
clearly observed the squeezing effect central to the DPO experiments
-
validated the Extend mitigation method proposed in the original paper.”
Simultaneously, creators of developer tools highlighted the practical economic advantages of the model’s new attention mechanism. The official team behind the agentic AI coding harness Cline posted an alert confirming day-one compatibility, stating:
“The new MiniMax-M3 is their first model to have 1m context, multimodal, and agentic coding capability. Congratulations to @MiniMax_AI for the breakthrough in sparse-attention architecture cutting compute & cost to 1/20th their previous generation.”
This sharp drop in execution costs shifts how developers view the relationship between financial investment and capability. Tech commentator @jumperz mapped out this disruption, noting how M3 breaks a historical pattern in machine learning pricing:
By addressing context scaling limitations through fundamental attention-level optimizations rather than brute-force hardware scaling, MiniMax has established a highly efficient open-source baseline. M3 demonstrates that the next phase of agent development will not just be driven by larger datasets, but by efficient architectural choices that make frontier-level performance accessible to the broader open-source community.
For enterprises building autonomous software development or agent infrastructure, MiniMax M3 provides the ultimate “bang for the buck.”
While DeepSeek-V4 Pro holds a microscopic price advantage of $0.195 per million tokens, MiniMax M3 justifies its marginal premium by delivering superior autonomous software engineering resolution rates (59.0% SWE-Bench Pro).
More importantly, because M3 is an open-weights model, the calculation extends far beyond the API chart. By deploying M3’s weights locally inside private enterprise clouds, organizations completely bypass cloud data egress tracking, eliminate structural vendor lock-in, and can implement custom prefix-caching models on internal hardware. This technical approach transforms a highly efficient runtime budget into a permanent, privately owned corporate asset.

Looking ahead: Capcom has updated the product page for Onimusha: Way of the Sword with a full breakdown of graphics modes, output resolutions, and target frame rates across PS5, Xbox Series, and PC – along with detailed system requirements covering 1080p, 1440p, and 4K at Low through Ultra settings.
Way of the Sword is the first new mainline entry in the series since Onimusha: Dawn of Dreams in 2006 – a gap of nearly two decades. That said, the series hasn’t been entirely dormant: it produced several spin-offs and side projects, including remasters, the VR title Onimusha VR: Shadow Team, and the browser-based multiplayer game Onimusha Soul.

Casual PC players running older mid-range hardware will be able to get the game running at 1080p/30fps, though the minimum CPU (Intel Core i5-8400) is now eight years old. Those targeting 4K/60fps on Ultra with upscaling will need something more modern on both the CPU and GPU front.
Minimum requirements (for 1080p / 30fps, Low settings)
- Intel Core i5-8400 or AMD Ryzen 3 3100
- Memory: 16GB
- Graphics: GeForce GTX 1660 Super (6GB) or Radeon RX 5500 XT (8GB)
Recommended requirements (for 1080p / 60fps, Medium settings)
- Intel Core i5-10400 or AMD Ryzen 5 3600
- Memory: 16GB
- Graphics: GeForce RTX 2060 Super (8GB) or Radeon RX 6600 (8GB)
Recommended requirements (for 1440p / 60fps, High settings)
- Intel Core i5-10400 or AMD Ryzen 5 3600
- Memory: 16GB
- Graphics Card: GeForce RTX 4060 Ti (16GB) or Radeon RX 6750 XT (12GB)
Recommended requirements (for 4K / 60fps, Ultra settings)
- Intel Core i5-12400 or AMD Ryzen 7 5700
- Memory: 16GB
- Graphics Card: GeForce RTX 4070 Ti (12GB) or Radeon RX 7900 XT (20GB)
All configurations require Windows 11 and at least 50GB of SSD storage.
Capcom confirmed the September 25 launch date during Sony’s State of Play, covering PS5 and Xbox Series, while the Nintendo Switch 2 version was announced separately during a Nintendo Direct. All versions including PC will ship simultaneously.
If you’re curious about this upcoming title, you don’t have to wait for months to experience the gameplay for yourself, a playable demo is currently live on PS5, Xbox, and Steam.
Way of the Sword is a dark fantasy action-adventure that follows the exploits of samurai warrior Miyamoto Musashi as he embarks on a mission to save Kyoto, threatened by supernatural beings during the Edo period. While the sword is Musashi’s primary weapon, he also carries the Oni Gauntlet, a sentient artifact that absorbs the souls of defeated enemies and unleashes superhuman abilities in combat.

Is it time to double down on red?

Subscriptions are everywhere these days, and it feels like only a matter of time before someone figures out a way to paywall the air we breathe. On top of that, the prices just keep going up, with companies ratcheting monthly costs up as much as they can without causing mass attrition. Over time, it adds up, and subscription juggling is a fact of life for many consumers. You might pay for a month of Netflix to catch the last season of Stranger Things while putting your Disney+ on pause until The Mandalorian and Grogu hits the latter service.
But there’s one subscription some people might be able to cut, at least those who spend a good amount of free time watching YouTube. Google’s ubiquitous video platform was once free, but charges a subscription these days in the form of YouTube Premium for users who want to avoid ads and gain access to a slew of user experience improvements.
What you might not have realized is that a full-fat YouTube Premium subscription, which costs $16 at the time of this writing due to a recent price hike, also includes unlimited access to the platform’s music streaming solution, YouTube Music. What that means for at least some heavy YouTube users is the ability to ditch a separate subscription to Spotify, Apple Music or another music streamer.
The trade-off isn’t right for everyone, though. Whether YouTube Music is fit for your needs depends largely on how much you value the features it lacks compared to the competition, as well as how willing you might be to let the platform logic of YouTube dictate the music you listen to. Here’s how YouTube Premium with YouTube Music compares to your existing music service, and how to figure out whether that single subscription is a better deal for you.
YouTube Music is great for avid watchers

The first thing you should know about YouTube Music is that it does not have a high-resolution library, even though that feature has become basic table stakes for the competition. Spotify, which dragged its feet on high-res for years, finally added its own lossless capabilities last year (it’s not bit-perfect lossless, but if you’re splitting that particular hair, YouTube Music isn’t for you and you can safely stop reading this article). However, lossless audio is a relatively niche feature that you can’t truly take advantage of without audiophile-grade playback equipment. If you listen to music on your AirPods via an iPhone, you’re not getting lossless playback in the first place.
YouTube Music tops out at 256kbps in resolution, which absolutely will be noticeable to some ears compared to the 320kbps other services offer before tipping into lossless quality. The bottom line is that, if you already listen to music on YouTube and haven’t had an issue with the sound quality, YouTube Music will suit you just fine in that regard.
Other differences between YouTube Music and Spotify or Apple Music become more subjective. Whereas those services allow you to build a more traditional music library, YouTube Music organizes things much in the same way as the video streaming side of the platform. You subscribe to artists rather than following them, and subscribing to an artist on YouTube also subscribes to them on YouTube Music. Playlists also carry over between both sides of the house. For those who want their taste in video content to affect their music recommendations, and vice versa, this can be a boon. But if you prefer some separation between church and state in that regard, it’s a massive headache. Just because you watched a video about the Drake and Kendrick beef doesn’t necessarily mean you want songs from all three of Drake’s unlistenable new albums piped into your ears during a jog.
YouTube Music has niche features you can’t get elsewhere

But the logic of YouTube gives YouTube Music one major edge: its user-uploaded library. In addition to most of the same major label offerings you’ll find on pretty much any modern music streamer, YouTube Music is home to the largest user-uploaded collection of hard-to-find tracks in the world. That leaked single your favorite artist never officially released? YouTube Music has it. That set from Coachella you’d do anything to experience again? Don’t bother looking on Spotify — YouTube Music has you covered and it’s no coincidence YouTube was the official streaming partner for Coachella in 2026. Speaking of the Drake and Kendrick beef, all of the songs from that kerfuffle went up on YouTube far in advance of their arrival on other streaming services as both emcees self-uploaded their disses to one-up each other in real time. The ability to add those kinds of tracks to your existing playlists is a structural advantage no competing service can match. Ditto for music videos because, you know, it’s YouTube.
YouTube Music also includes a robust podcast library, including many audio-forward offerings that only exist on Google’s platform in the form of user-created video essays and documentaries. Even among widely syndicated podcasts, a number of them can only be watched in video form on YouTube. That gives the platform an edge up over Spotify, although big green has put a heavy focus on bolstering its video podcast library in recent years, and an absolute win over Apple Music, as Apple users must get their podcasts from the separate Apple Podcasts app.
Because YouTube Music was born from the ashes of Google Play Music, it carries on its predecessor’s functionality as a cloud player for your own, local files. Its two primary competitors also allow local uploads, but they’ll lump your MP3 files in alongside streaming tracks in your library. YouTube music splits everything out, so you can isolate your uploads and browse just those songs by artist, album, and so on. If you’re still in possession of a digital music library from the iTunes or Napster days (how do you do, fellow kids?), YouTube Music is a great way to continue enjoying them without wasting storage space on your smartphone.
Swapping Spotify for YouTube Premium isn’t right for everyone

If all you got with a YouTube Premium subscription was the platform’s music service, it wouldn’t be worth replacing your Spotify or Apple Music subscription. But you’re also getting a better experience on YouTube itself. Getting your money’s worth from YouTube premium is easy if you’re an avid user already. In addition to never seeing a pre-roll or mid-roll ad ever again, you can skip your favorite creator’s sponsored segments using the Jump Ahead button that intelligently skips you over portions of a video that other users also tended to skip. Then there are perks like background play and offline downloads that let you take more control over where and how you enjoy YouTube videos.
It’s that combined value which makes this comparison worthwhile. YouTube Premium is not cheap at its new price of $16 a month, especially compared to Spotify’s $13 asking price, or Apple Music’s $11 tag. But if you’re already paying for it, and if YouTube Music offers an experience that meets your preferences, you can cut the standalone music subscription from your monthly budget without worry. Others may find it worth cutting the contract with their current music service and signing up for YouTube Premium to take advantage of its unique blend of content and features.


Luke Larson used to get a charge out of working on Tasers and body-worn cameras for law enforcement at Axon. Now he’s buzzing over matcha, the ancient Japanese green tea powder that devotees say delivers calm, focused energy without the jitters of coffee.
Larson’s ambition is noteworthy in its own right as he plans to build Vale into a Seattle-born beverage empire — think Starbucks, but make it matcha — scaling from a handful of local cafes and mobile bars to a nationwide network of thousands of automated machines.
It’s a move he’s pulled off before. As president of Axon, Larson helped grow the company from roughly $100 million to $1 billion in sales before stepping down in 2022.
Larson sees Vale as sitting at the intersection of consumer products, hospitality, technology and automation — and a chance to build something from the ground up.
“While other companies are leaving Seattle, we’re investing in Seattle,” Larson told GeekWire from Vale’s Pioneer Square headquarters, where he’s especially bullish on hiring tech talent from companies including Starbucks, Amazon and Microsoft.
Body cams to matcha bars

Larson, who grew up in Forks, Wash., served two tours in Iraq as a Marine Corps infantry officer and he was awarded the Bronze star with V for valor on his first tour. He joined Axon in 2008 and was product manager for the company’s first cameras.
He rose to president at Axon in 2017 and helped build out the Scottsdale, Ariz.-based company’s significant engineering presence in Seattle. Alongside its mission to build tools and technology to help de-escalate police use of force, Axon attracted attention in Seattle for its geeky spaceship-themed office and its unique recruiting tactics.
In 2022, Larson left Axon following a health scare, taking a six-month medical leave before relocating with his wife and three daughters to Switzerland for a two-year sabbatical — time that gave him space to think about his next chapter.
It was during that period that Larson first tried matcha, at the urging of his wife and sister-in-law. His initial reaction wasn’t promising — he didn’t like it. But an introduction to chef Jeffrey Hayden, a Culinary Institute of America graduate who had worked at Michelin-starred restaurants, convinced him that high-quality, cold-served matcha was a different experience entirely.
Larson returned to Seattle with a new company idea, and last year launched Vale, opening its first cafe in South Lake Union in May 2025.

While a second cafe is in the works on First Hill, Vale’s growth target is more pronounced. The company this summer will operate 23 portable, staffed matcha bars with plans to scale to 100 by year’s end and 1,000 by next year. To support that growth, Vale recently leased 36,000 square feet of production space south of downtown Seattle — a space formerly used by Atomo Coffee as a roastery.
Hayden serves as the startup’s head of craft and Vale has 73 employees, roughly half of them frontline matcha bar workers, with the rest split among software engineers, mechanical engineers and roboticists. Former Axon leaders include CTO Jay Reitz and Sydney Siegmeth, head of people and communications.
Larson, who is the majority investor, plans to keep the company private for another two years before seeking outside capital.
His longer-term play involves robots.
Larson wants to build out a network of automated self-serve matcha machines that he envisions in office towers, apartment buildings and other spaces that wouldn’t support a traditional cafe.
Matcha from a machine

Vale sources ceremonial-grade matcha from Shizuoka, Japan, a region Larson likens to the Pacific Northwest, sitting at the base of Mount Fuji. Hayden leads a team that has developed a specialty drink menu — from classic cold matcha to lattes and seasonal creations like a tiki-themed summer drink — served across the cafe, matcha bars and machines through a single mobile app.
Next to Vale’s HQ in the lobby of an office building at 505 First Ave. S., just a block from Lumen Field, sits a futuristic-looking matcha-dispensing machine. With its smooth finish and rounded edges, it’s about the size of a small car, with a touchscreen centered between two frosted panels that reveal a drink-delivery portal.
A peek inside the back of the machine reveals a robotic arm that moves from end to end. First it applies a personalized label to a plastic vessel to match what the customer typed in. Next it fills the container with the drink of choice from a selection of 10 automated taps. The container is then topped with a soda-can-style aluminum lid before it’s placed in the window for retrieval.

Larson envisions the machine as something like a “Star Trek” replicator, where the technology fades into the background and the focus stays on the customer experience.
“We want to shatter your expectation of what can come out of a machine,” he said.
A $7 strawberry matcha latte tasted by GeekWire came pretty close to doing just that. Flavored with oat milk, the iced, fruity, creamy drink was a nice surprise compared to more traditional hot and bitter matcha I’ve previously sipped from a straw.
Larson hopes the taste lands equally well with a generation of consumers increasingly drawn to matcha as an alternative to coffee — particularly younger drinkers who prefer cold beverages and are wary of the jitters that can come with a caffeine habit.
He’s betting Seattle is the right place to find them, and to build the team to serve them, as Vale plans to hire up to 100 people over the next 12 months.
“I believe that Seattle’s best years are ahead of it,” Larson said. “To build the type of company that I want to build, I don’t think there’s a better city in the world.”


SpaceX’s historic IPO just got super-sized, after the public offering’s underwriters exercised their option to purchase the maximum amount of shares — bringing the total amount raised to $85.7 billion.
Elon Musk’s space-and-AI company had initially raised $75 billion, which was already enough to make it the largest IPO windfall ever.
SpaceX has said it plans to use the proceeds from this IPO in a variety of ways. The company plans to extinguish around $20 billion in debt related to legacy loans tied to X, the social media company formerly known as Twitter, and Musk’s AI company xAI — both of which were combined into SpaceX before the IPO.
Funds will also be used to expand SpaceX’s AI compute infrastructure, enhance its launch infrastructure, and improve Starlink.
SpaceX’s stock started trading on the Nasdaq exchange on Friday. The company finished the day with a valuation of more than $2 trillion, and Musk became the world’s first trillionaire. Shares climbed higher on Monday, helping SpaceX eclipse the valuation of chipmaker TSMC.

Salesforce acquires Fin, the customer-service AI company formerly known as Intercom, in a deal worth about $3.6bn. The CRM giant signed a definitive agreement on Monday, it said, to fold Fin’s “customer agent” technology into Agentforce, its own fast-growing AI-agent platform.
Fin’s pitch is autonomous support.
Its AI Agent handles customer queries end-to-end across live chat, email, WhatsApp, SMS, phone and Slack, and Salesforce says it resolves, on average, 76 per cent of support volume without a human. It runs on Fin’s own model, Apex, which the company says it post-trained specifically for support and which it claims outperforms frontier models from OpenAI and Anthropic on resolution.
Fin brings more than 30,000 business customers with it.
The deal is expected to close in the fourth quarter of Salesforce’s fiscal 2027, subject to regulatory clearance. Salesforce says it will not change its FY2027 guidance or its buyback plans.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
Why Salesforce acquires Fin instead of out-building it
Salesforce is not short of agents. Agentforce, its own platform, hit $1.2bn in annual recurring revenue in the first quarter, up 205 per cent year on year. So this is not a company filling a hole. It is buying speed.
Agentforce is the deeply customisable, enterprise-grade option, powerful but slower to stand up. Fin is the opposite: packaged, pre-trained and live in days, which suits smaller and mid-market firms that want a working support agent now. Buying Fin lets Salesforce sell both, from a drop-in support bot to a bespoke enterprise build, rather than forcing every customer down the heavyweight path.
“We’ll help companies of every size seize this opportunity,” chief executive Marc Benioff said.
A rival, and its own model, absorbed
The target is a pointed one. Fin, under co-founder and chief executive Eoghan McCabe, has spent years positioning itself as the company that defined the customer-agent category, often at the industry’s expense.
Intercom only renamed itself Fin, after its AI agent, in May. Now the agent, the brand and the team are Salesforce’s. “We can deploy it far and wide at a rate far faster than we could have ever achieved on our own,” McCabe said.
There is a quieter prize, too. Fin launched in 2023 on OpenAI’s GPT-4 and later leaned on Anthropic’s Claude, then built Apex, its own post-trained support model, to cut that dependence. Salesforce is buying not just an app but a proprietary model tuned for one job. It slots into a wider land-grab in agentic AI, where the big platforms are racing to own the software that does the work, not just the software people work in.
The test now is integration: whether a packaged agent built outside Salesforce still feels fast once it is wired into Salesforce’s data, security and governance stack.


Presented by Splunk
AI has changed the economics of cyber deception.
An attacker can now generate thousands of convincing phishing lures, fake identities, and tailored pretexts before a defender finishes a single change-control cycle. That is the new security challenge: deception got faster and cheaper, while verification did not.
Much of the discussion around AI for defense centers on detection models. Detection matters, but it is not the only bottleneck. The deeper constraint is evidence: where data lives, whether it is available when needed, how quickly it can be correlated, how long it is retained, and whether analysts or agents can trust what they retrieve.
Defense in the AI era is a data problem before it is a detection problem.
The defender’s advantage is truth
Attackers can afford to lie at enterprise scale. They can test endless combinations of messages, identities, domains, and attack paths, and most can fail at almost no cost.
Defenders do not have that luxury. Their advantage is truth: quickly knowing what happened, where, when, which identity was involved, which assets were affected, what changed, and what business process may be at risk.
That truth must be documented, governed, auditable, and defensible. Attackers are using AI to scale deception, impersonation, social engineering, and speed. Defenders need AI to scale verification.
The goal is not just to act faster than the attacker. It is to take action that people and machines can trust.
Fragmented data breaks modern defense
Consider a suspicious login from a contractor account. On its own, it is just another authentication anomaly. To know whether it matters, a security team may need identity history, endpoint activity, cloud access logs, ticketing records, asset ownership, configuration changes, network telemetry, and business context.
If those records sit in different tools, expire at different times, or require multiple teams to retrieve, defenders are not investigating the incident. They are negotiating with their own data estate.
When signals can be reached in place and correlated quickly, the issue is no longer just whether the login looks unusual. It becomes whether the enterprise has enough evidence, in enough context, to take action it can defend.
That challenge grows more urgent with AI assistants and agents. AI can only reason over what it can retrieve in time to matter. If the data is partial, stale, fragmented, unavailable, or stripped of context, AI does not create truth. It accelerates uncertainty.
The system of record must become a defensive control plane
For years, enterprises treated security platforms, SIEMs, and data lakes as passive repositories: places to store data for later search and analysis. That model is no longer enough.
What organizations now need is a defensive control plane: a layer that connects what happened, what it means, and what the enterprise is allowed to do about it. In architectural terms, it ties together raw machine data, business context, and policy. It does not just store evidence. It makes evidence usable for decisions and actions that must be explainable and trusted.
In practice, that means doing four things well: preserving evidence, reaching data wherever it lives, adding business context, and governing action. More on each below.
The old system of record answered one question: What is the official record?
A defensive control plane answers the questions that matter operationally: What happened? What does it mean? What evidence supports that conclusion? And what action can we trust?
AI does not reduce the need for authoritative records. It raises the standard for what those records must do.
A defensive control plane must do four things
-
Preserve evidence. Logs, metrics, traces, events, identity records, configuration changes, tickets, and asset state all help establish what happened. Their value often becomes clear only after an incident begins.
-
Make data accessible wherever it lives. Security-relevant data is already spread across object stores, cloud platforms, operational tools, and business systems. Moving every byte into one place is often too slow, too expensive, and too difficult to govern. The better model is to bring analytics to the data.
-
Add business context. Correlating machine data with business information turns “anomaly on host X” into “the system supporting payment services for top accounts is being probed.” That is what allows organizations to prioritize correctly.
-
Govern action. In the agentic era, systems will do more than summarize incidents. They will enrich alerts, open cases, trigger workflows, isolate assets, update policies, and escalate decisions. Enterprises need to know what evidence an agent used, what policy governed the action, whether it stayed within scope, and how the decision can be reviewed afterward.
The real SOC problem is not too little data
Modern SOCs are not suffering from a lack of data. They are suffering from a lack of usable context.
According to the Splunk State of Security 2025 report, SOC analysts continue to struggle with too many alerts (59%), too many false positives (55%), and alerts that lack context (46%). The issue is not data volume. It is the difficulty of turning fragmented signals into trusted decisions.
Today, analysts are left stitching together context manually, pivoting across disconnected tools, and making high-stakes decisions without the full picture in time. Even as AI improves, outcomes still depend on whether humans are willing to approve changes across fragmented environments.
This creates a daily crisis of context. Teams are forced to make consequential decisions based on data they cannot easily see, correlate, or trust. The result is latency, inconsistency, missed opportunities, and unnecessary risk.
Trusted action is the durable advantage
A data fabric architecture offers a way forward by creating a unified, intelligent layer across data sources spanning SecOps, ITOps, and NetOps. The goal is not centralization for its own sake. It is to break down silos and deliver context-rich insight at the speed AI-driven operations require.
This is an operating model before it is a product. AI-driven defense depends on a foundation that can preserve evidence, reach data where it lives, add context, and maintain a reviewable link between data, decision, and action. That is the architectural shift behind Cisco Data Fabric powered by the Splunk Platform, which brings together machine data, federation, business context, governance, and provenance to help teams move from signal to trusted action.
Attackers will keep making deception cheaper, faster, and more personalized. Defenders do not win that race by generating more noise. They win by making truth faster, and by grounding every action in evidence that people and machines can trust.
Learn more about the Cisco Data Fabric powered by the Splunk Platform.
Seth Brickman is VP, Global Product – Splunk Platform, Cisco.
Sponsored articles are content produced by a company that is either paying for the post or has a business relationship with VentureBeat, and they’re always clearly marked. For more information, contact sales@venturebeat.com.
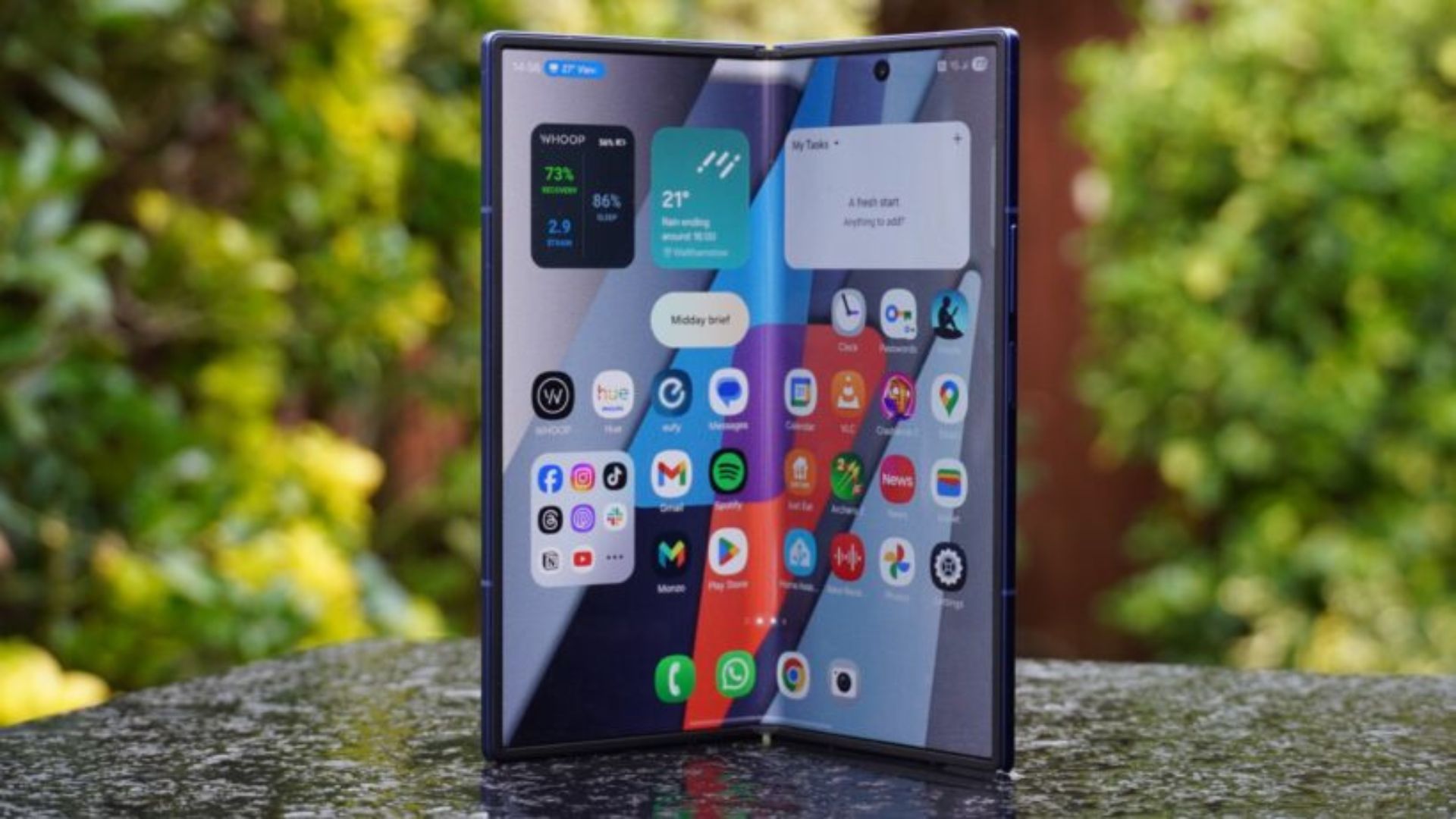
Samsung’s next foldable line-up may have just leaked ahead of schedule. A new image appears to show screen protectors for the upcoming Galaxy Z Flip 8, Galaxy Z Fold 8 and Galaxy Z Fold 8 Ultra side by side.
While leaked screen protectors aren’t usually the most exciting reveal, this one offers an early look at how Samsung could be reshaping its foldable range.
Most notably, the Galaxy Z Fold 8 appears wider and slightly shorter than previous models. Meanwhile, the Fold 8 Ultra looks set to sit in a class of its own.
If the leak is accurate, it suggests Samsung is putting more distance between its standard Fold and Ultra models. The company may no longer treat the Ultra as a simple spec bump. That could help the company better compete. After all, rivals such as Apple, Xiaomi and Vivo continue to push into the foldable market.
The image was shared by well-known tipster Ice Universe and appears to show noticeable differences between the two Fold devices. The standard Fold 8 looks broader than before. This could make the outer display feel more like a traditional smartphone screen. It may also feel less like the narrow panels found on earlier Galaxy Fold devices.
Beyond the redesigned shape, previous leaks have pointed to several upgrades for the Fold 8. These include a less visible display crease, a 4,800mAh battery and a weight of around 201g.
The Galaxy Z Flip 8, meanwhile, is expected to be a more modest update. Rumours suggest Samsung has tweaked the hinge design to make the clamshell foldable slightly thinner when closed. Additionally, the company is also shaving off a little weight. The biggest changes may come under the hood. Reports point to Samsung’s Exynos 2600 chip in Europe and South Korea. In other markets, there may be a Snapdragon 8 Elite Gen 5 for Galaxy processor.
Samsung expects to officially unveil the Galaxy Z Flip 8, Galaxy Z Fold 8 and Galaxy Z Fold 8 Ultra at its next Unpacked event on July 22. The company will reveal these alongside the Galaxy Watch 9 and Galaxy Watch Ultra 2.




AI AND ml
PwC says AI hiring jumped 61 percent despite wider slowdown in vacancies, with employers increasingly looking for workers who can use AI rather than build it
Britain’s AI jobs boom is creating a two-track labor market, according to PwC, which just so happens to make a healthy living helping companies navigate AI-driven transformation.
The consulting giant’s latest AI Jobs Barometer found hiring for AI specialists in the UK jumped 61 percent over the past year, rising from 112,000 roles in 2024 to 180,000 in 2025, even as overall job vacancies across the economy fell by 6.6 percent.
That headline figure is the sort of thing consultancies put in press releases, but the more interesting bit comes later.
PwC’s analysis suggests employers aren’t rushing to hire hordes of machine learning engineers and model builders. Instead, they’re increasingly looking for people who can use AI inside existing professions and business functions. The firm found that so-called AI user roles grew by almost 66,000 positions during the year, while AI developer roles increased by just 2,600.
After years of declaring that AI will revolutionize everything from accounting to sandwich-making, companies appear to have reached the awkward stage where somebody actually must make the technology useful.
PwC argues the result is a “two-track” labor market. Jobs where AI helps skilled workers automate repetitive tasks and focus on higher-value work are growing faster than roles where the technology mainly makes tasks easier and lowers barriers to entry.
According to the report, roles most enhanced by AI have grown by 39 percent since 2018, compared with 17 percent growth in jobs where AI is primarily simplifying work.
The firm’s wage data tells a similar story. Jobs requiring AI skills now command an average wage premium of 34.2 percent, up from 11 percent a year ago. Consumer market companies are offering premiums as high as 64 percent, while government and public sector employers top out at 12 percent.
That’s certainly good news for workers with AI skills. It’s also not the sort of conclusion likely to upset a firm that advises clients on AI strategy for a living.
The findings land against a backdrop of growing anxiety about AI’s impact on employment. Recent polling found one in five Britons believes AI-driven layoffs could eventually trigger civil unrest, while another survey found that office workers are already spending nearly six hours every week checking, correcting, or redoing work generated by AI tools.
For all the excitement around AI, the hiring surge appears to be concentrated in a surprisingly old-fashioned category: people who know what they’re doing. ®


SOFTWARE
Linux app packaging rethink could leave alternative-init distros in the cold
Flatpak development has been very quiet for years. Discussions about a next-generation take are happening – and some of the signs are worrying if, like many FOSS folks, you are systemd-intolerant.
In the course of researching our article on MX Linux 25.2, we came across an interesting Reddit discussion from last month, which in turn led us to a Flatpak development blog post from late last year.
It looks like a team is collecting ideas for what is currently called “Flatpak-NG” – as in next generation. If this solidifies into code, this may form the basis of Flatpak version 2.
The blog post isn’t very informative, but the Reddit thread links to the video of a presentation from last month’s Linux App Summit in Berlin, which spells things out more clearly.
The Flatpak-NG idea involves handing off a lot of the isolation in Flatpak from the current bubblewrap layer to an as-yet-unwritten systemd component that the developers are currently calling systemd-appd. This would considerably simplify Flatpak, and enable it to do more isolation, including virtualizing the network stack – but at the price of making Flatpak 2 depend on systemd. A developer who was at the talk, Jorge Castro, later explained and confirmed this in a Fediverse thread.
The teams behind other init systems could, of course, write their own replacement for the notional systemd-appd, but that would be a substantial amount of work. The tool that provides the new init-switching functionality in MX Linux 25.1 and 25.2, init-diversity, currently supports six other init systems besides systemd, and we’ve seen little sign of them cooperating to create an alternative to systemd that provides even a subset of its wider functionality.
Flatpak is widely used and supported. Not all distros include it by default, but it’s the only widely adopted alternative to Canonical’s Snap packaging system.
Snap is more versatile: it works fine with shell programs, and even the kernel can be packaged as a Snap, which is how Ubuntu Core handles it. Snap’s implementation is much simpler and cleaner than Flatpak’s, as is the distribution model – which, as we’ve reported before, is entirely open source. The only proprietary part is Canonical’s Snap Store website. The trouble is, the louder advocates in the peanut gallery rarely even think about things like implementation details; they just get upset about more visible things that are easier to understand – such as who owns a website.
There are other alternatives out there, such as AppImage, 0install, AppDir, and GNUstep’s implementation of NeXT and Apple’s .app format. We have compared these in detail before.
Only two really have wide adoption, though. There’s Snap, which Canonical claims has more users simply because Ubuntu has more users than all the other desktop distros put together, and there’s Flatpak, which is used by every other distro with any kind of cross-distro package support.
The snag is, if Flatpak 2 does arrive in a year or two, and requires systemd, then that could spell the end of Flatpak support on many systemd-free distros. That includes MX Linux, Alpine Linux, Devuan, Slackware, and many other smaller projects. For many of these, Flatpak is a lifeline: the only way to access much of the wider Linux app market.
It’s not so much that the Flatpak-NG team is the “A-Team,” but the only team. In the original A-Team, Colonel John “Hannibal” Smith was wont to say “I love it when a plan comes together.” We suspect a lot of people will not love it if this plan comes together. ®

Onimusha: Way of the Sword releases September 25 with surprisingly modest system requirements

Neha Nagar On Why Having A Child Needs Financial Planning

Teacher guilty of sexual abuse and murder of baby who was treated as ‘plaything’





-

 Business24 hours ago
Business24 hours agoNo Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw
-

 Crypto World4 days ago
Crypto World4 days agoOppenheimer backs SpaceX as $70 billion retail frenzy builds
-
 Crypto World4 days ago
Crypto World4 days agoMarkets Rally as SpaceX IPO Looms Amid Iran Tensions and Inflation Surge
-

 Fashion3 days ago
Fashion3 days agoWeekend Open Thread: Tuckernuck – Corporette.com
-

 Sports7 days ago
Sports7 days agoFIFA WC 2026 Group C: Morocco, Scotland challenge Brazil’s hunt for glory | FIFA World Cup 2022
-
 Crypto World16 hours ago
Crypto World16 hours agoZimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations
-

 Entertainment6 days ago
Entertainment6 days agoThe Ryan Gosling True Crime Thriller On Netflix That Gets Even Stranger, Stream It Now
-
 Sports6 days ago
Sports6 days agoBangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News
-

 Tech3 days ago
Tech3 days agoNanoClaw integrates JFrog registries to secure AI agent downloads
-

 Tech3 days ago
Tech3 days agoThis Week In Security: Microsoft On Microsoft, Register Your Domains, Linux On ARM, And FreeBSD Joins The File Cache Club
-

 Crypto World2 days ago
Crypto World2 days agoBitget enters Argentina’s regulated crypto market through PSAV registration
-

 Politics4 days ago
Politics4 days agoPolitics Home | Healey Resignation Is “Colossal Failure Of Government”, Says Former Labour Defence Secretary
-
 Tech4 days ago
Tech4 days agoDutton Ranch star claims they ‘didn’t see any disruption’ on set following Chad Feehan’s exit from Yellowstone spinoff fueled by Taylor Sheridan clash rumors
-

 Tech5 days ago
Tech5 days ago‘This is Seattle’s position on AI’: City Council votes unanimously to pause big new data centers
-

 NewsBeat4 days ago
NewsBeat4 days agoEl Nino has formed in the Pacific and could set records, forecasters say
-
 Entertainment4 days ago
Entertainment4 days agoDonnie Wahlberg & More Heat Up Las Vegas at Circa’s Barry’s Downtown Prime
-

 Sports4 days ago
Sports4 days agoFirst Time Since 1971: Australia Register Historic Low In ODI Cricket
-
 Tech4 days ago
Tech4 days agoOpendoor Ends India Operations, Fueling a Bigger Conversation About AI and Outsourcing
-

 Politics4 days ago
Politics4 days agoBelfast burns, while Met chief points finger at Iran and Russia
-

 NewsBeat3 days ago
NewsBeat3 days agoFBI searches office of Ohio voter registration group
You must be logged in to post a comment Login