Google’s Pixel phones have a handy scam call detection feature that works in the background during calls, alerting users in real time if a conversation shows signs of a potential scam. When triggered, it warns users with a notification, sound, and vibration, offering a timely nudge to hang up before any damage is done. So far, this feature has been exclusive to Pixel devices, but it could soon make its way to phones from other brands, starting with Samsung’s upcoming Galaxy S26 series.
Google debuted Scam Detection on the Pixel 9 series, and the feature is currently available on Pixel 6 and newer models. However, Android Authority has spotted evidence suggesting it could also be coming to the Galaxy S26 lineup. While digging through Google’s Phone app, the publication spotted model numbers for Samsung’s upcoming devices listed alongside a code snippet referencing “Sharpie,” the internal codename for Google’s Scam Detection feature.
In a separate report, the publication claims that Google may bring Scam Detection to non-Pixel devices through a new app called Android Callcore. According to its Play Store listing, the app provides an “infrastructure to support phone-calling based features,” and its latest update includes the ability to detect scam calls.
Pixel’s Scam Detection may expand to devices from more manufacturers
The report adds that the Android Callcore app can only be installed on devices with a specific feature flag, and Samsung’s top-end Galaxy S26 Ultra appears to include this flag. If accurate, this suggests Samsung’s upcoming flagships may not rely on Google’s Phone app to enable Scam Detection.
Advertisement
The app may also allow Google to extend support to more Android devices in the future, but it’s not immediately clear when Scam Detection will roll out more broadly or which manufacturers will be included. More information should emerge when Samsung lifts the covers off the Galaxy S26 series late next month.
Fauna has built Sprout, a humanoid robot designed as a testing platform for robotics researchers and developers.
Tech giant Amazon has acquired Fauna Robotics, a New York-based humanoid robotics developer, for an undisclosed amount.
Fauna Robotics has developed a 42-inch tall humanoid robot called Sprout that can interact with people, walk, grip items and dance. The company has also included a developer platform with the robot, which allows researchers and scientists to build applications for the device.
The acquisition was first reported by Bloomberg, which verified the deal through an Amazon spokesperson. While the acquisition was first revealed yesterday (24 March), sources told Bloomberg that the deal was completed last week.
Advertisement
As part of the acquisition, Fauna – and its team of roughly 50 employees – will join Amazon’s Personal Robotics Group and the company will continue to deploy Sprout to outside researchers. While the start-up will keep its name, it will now be referred to as ‘Fauna, an Amazon company’, according to Bloomberg.
“Together with Amazon’s robotics expertise and decades of experience earning customer trust in the home through our retail and devices businesses, we’re looking forward to inventing new ways to make our customers’ lives better and easier,” an Amazon spokesperson told Bloomberg.
Fauna was established in 2024 by Josh Merel, a former Meta and Google DeepMind researcher, and Rob Cochran, former head of product at CTRL-Labs, a neural interface tech company that was acquired by Meta in 2019 and integrated into Facebook Reality Labs.
Fauna first launched the $50,000 robot out of stealth in January, available to researchers, educators and commercial developers. The robot has been designed to operate in “shared human spaces”, according to Fauna.
Advertisement
A major component of the machine is its application as a testing platform for robotics researchers and developers.
Fauna stated that Sprout is equipped with a number of developer functions such as modular AI architecture that allows robotics teams to use their own AI models anywhere in the system, trained motor control policies, and built-in mapping and localisation capabilities.
The robot has been built with the 64GB Nvidia Jetson AGX Orin, a small AI supercomputer designed for robotics, autonomous machines, medical devices and other forms of embedded computing at the edge.
Amazon’s purchase of Fauna hasn’t been the tech giant’s only robotics news this month.
Advertisement
Last week, the e-commerce company acquired Rivr, a Zurich-based autonomous robotics start-up known for its stair-climbing delivery robot.
These acquisitions come after Amazon announced layoffs in its own robotics division at the start of March. Cuts in the division came after Amazon halted its ‘Blue Jay’ warehouse robotics projects less than six months after launching – Blue Jay was a multi-armed robot designed to sort and move packages.
However, despite the hurdles, Amazon’s robotics division has been considerably successful, having deployed Amazon’s one millionth robot in operations last June. At the same time, the company also launched a new generative AI foundation model designed to make its robot fleet 10pc more efficient.
Grado has been on a quiet tear over the past year. The Grado Signature Series signaled a more ambitious direction for the Brooklyn brand; new materials, updated ergonomics, and a clear effort to modernize without losing its identity. The obvious question was when that thinking would make its way down to the models most people actually buy. The answer arrives now with the new Grado Classic Series; seven revamped headphones starting at $125 that pull select ideas from the top of the range and apply them where they matter most.
This isn’t a wholesale reinvention. Not all of the Signature Series tech has trickled down, and that’s probably the point. What Grado has done instead is tighten the screws where it counts, refining its X2 driver platform, improving cables and headbands, and addressing long-standing comfort and durability quirks without messing with the core formula that made these headphones staples in the first place.The result is a lineup that feels more considered than flashy, with meaningful updates instead of unnecessary bling or design detours that would feel out of place for a brand with such a traditional outlook and long history.
And if you’ve been around Grado long enough, this lands differently. These are the headphones that built the brand’s reputation with people who didn’t have four-figure budgets or the patience for audiophile theater. People like me, who once dragged a pair of SR80s halfway across the Middle East during the Intifada, only to lose them in a chaotic sprint away from a bus bombing in the Negev. I was furious. Not because they were expensive—but because they were mine. I replaced them years later with the SR80x after reviewing them, and the appeal hadn’t changed.
That’s the through-line here. The Grado Classic Series doesn’t try to be something it’s not. It’s Grado remembering exactly who its audience has always been and giving them a better version of what they already loved.
Advertisement
What’s New in the Grado Classic Series?
Grado GS3000
At the center of the Classic Series is Grado’s updated X2 driver platform. This isn’t a ground-up redesign, but a refinement of the company’s long-running approach which is focused on better consistency, improved control, and a bit more balance across the frequency range. There’s more clarity and extension here, but the core traits haven’t been scrubbed out. It still sounds like Grado: fast, open, and direct, with that forward sense of immediacy intact. Each model is tuned to its specific housing, which continues to play a major role in how these headphones present space and dynamics.
Beyond the driver, the changes are more practical than dramatic. The Grado Classic Series picks up revised cable designs derived from the Signature Line that are lighter, more flexible, and easier to live with over long sessions. Durability and handling should be better, but Grado is sticking to its guns with a fixed cable across the lineup. If you were hoping detachable cables would trickle down, they didn’t. That line is still clearly drawn.
Before you get twisted up over that, remember who Grado is building these for. These seven models aren’t aimed at the Head-Fi purist crowd ready to argue over pad materials or single ended versus balanced termination.
Headbands and hardware get some overdue attention as well. Updated assemblies improve adjustment, comfort, and long-term reliability without altering the look that’s been part of the brand for decades. It’s evolution, not reinvention. And like always, everything is still assembled in Brooklyn, which matters to Grado and to a lot of its customers.
The Classic Series Lineup
The new lineup brings together seven of Grado’s most recognizable models: GS3000, GS1000, RS1, SR325, Hemp, SR80, and SR60.
Advertisement
There’s no attempt here to reinvent the hierarchy. This is a range that spans from true entry-level to long-standing reference designs, covering the same ground it always has. For a lot of listeners, these were the gateway into better audio—and in many cases, the pair they stuck with. The update doesn’t change that.
GS3000
Price: $1,995 Driver: 52mm X2 dynamic Design: Open-back Frequency response: 4Hz to 51kHz Sensitivity: 99.8 dB Impedance: 38 ohms Driver matching: 0.05 dB Cushions: G cushions Key build notes: Signature Gold headband assembly, larger diaphragm, optional XLR termination.
Advertisement. Scroll to continue reading.
This is the top Classic Series model and the one aimed at listeners who want the biggest enclosure, the largest driver in the lineup, and the most expansive presentation. Grado says the 52mm X2 driver is meant to improve bass extension, dynamic headroom, and scale, and that tracks with where this model sits in the hierarchy. It also gets the most advanced mechanical package in the Classic range with the Signature Gold headband system.
GS1000
Price: $1,195 Driver: 50mm X2 dynamic Design: Open-back Frequency response: 8Hz to 35kHz Sensitivity: 99.8 dB Impedance: 38 ohms Driver matching: 0.05 dB Cushions: G cushions Key build notes: Signature Gold headband assembly, optional XLR termination.
The GS1000 sits below the GS3000 but follows the same basic idea: larger driver, larger cushions, and a more spacious presentation than the smaller-bodied models. Grado positions it as open and effortless rather than aggressive, which makes sense given the G-cushions and the 50mm driver platform. It keeps the premium headband hardware, so it is not being treated like a cut-rate version of the flagship.
Advertisement
RS1
Price: $750 Driver: 50mm X2 dynamic Design: Open-back Frequency response: 12Hz to 30kHz Sensitivity: 99.8 dB Impedance: 38 ohms Driver matching: 0.05 dB Cushions: L cushions Key build notes: Signature Gold headband assembly, Signature Silver cable, optional XLR termination.
The RS1 remains the more compact wooden step-up model in the lineup and looks like the point where Grado wants tradition and refinement to meet without going full GS. Grado’s own language here focuses on midrange expression and immediacy, and the L-cushions suggest a more focused presentation than the GS models. It also gets better hardware than the entry models, but still stops short of detachable-cable modernity. Brooklyn giveth, Brooklyn withholdeth.
Hemp
Price: $495 Driver: 44mm X2 dynamic Design: Open-back Frequency response: 13Hz to 28kHz Impedance: 38 ohms Driver matching: 0.05 dB Termination: 3.5mm plug with 1/4-inch adapter Cushions: F cushions Key build notes: Hemp and maple housing, padded leather headband with white stitching, 8-conductor cable, Signature Silver headband assembly, optional XLR termination.
The Hemp remains the material outlier in the lineup, using a hemp and maple housing rather than the more conventional wood, metal, or polymer approach. Grado says the tuning is fuller and more grounded, which separates it a bit from the leaner, faster reputation some buyers associate with the brand. It also gets nicer trim than the SR60 and SR80, which keeps it from feeling like a novelty side quest.
SR325
Price: $350 Driver: 44mm X2 dynamic Design: Open-back Frequency response: 18Hz to 24kHz Sensitivity: 98 dB Impedance: 38 ohms Driver matching: 0.05 dB Cushions: F cushions Key build notes: Aluminum housing, Signature Silver headband assembly, Signature Silver cable.
The SR325 is still the metal-bodied model in the lower half of the lineup and the one that looks most likely to appeal to listeners who want a more controlled and articulate take on the Grado formula. Grado specifically points to tighter bass, forward mids, and crisp top-end extension, and the machined aluminum housing is there to reduce resonance and keep things fast. This is where the Classic Series starts to feel a little more dressed up without losing the family resemblance.
SR80
Price: $175 Driver: 44mm X2 dynamic Design: Open-back Frequency response: 20Hz to 20kHz Sensitivity: 98 dB Impedance: 38 ohms Driver matching: 0.1 dB Cushions: S cushions Key build notes: Standard headband assembly with padded synthetic strap, Bronze cable.
The SR80 is still the heart-of-the-line Grado for a lot of people. Compared with the SR60, Grado says it brings tighter bass, more midrange presence, and more top-end detail, which is basically the company telling you this is the livelier, more direct option without making you take out a second mortgage. It keeps the simpler headband and fixed Bronze cable, so the upgrades are real but still clearly budget-conscious.
Advertisement
SR60
Price: $125 Driver: 44mm X2 dynamic Design: Open-back Frequency response: 20Hz to 20kHz Sensitivity: 98 dB Impedance: 38 ohms Driver matching: 0.1 dB Cushions: S cushions Key build notes: Standard headband assembly with padded synthetic strap, Bronze cable.
Advertisement. Scroll to continue reading.
The SR60 remains the entry point and, honestly, that matters more than any spec-sheet chest beating. Grado describes it as balanced and musical, aimed at long listening sessions rather than maximum bite. It shares the same 44mm X2 architecture as the SR80, but the SR80 is positioned as the more immediate and more energetic step up. For $125, this is Grado keeping one foot planted where the brand actually built its audience in the first place.
The Bottom Line
The Classic Series which includes the GS3000 ($1,995), GS1000 ($1,195), RS1 ($750), Hemp ($495), SR325 ($350), SR80 ($175), and SR60 ($125) is a focused update built around the X2 driver platform, improved cables, and better headband design. Same lineup, just refined where it needed it.
Grado updated its core products and made them more comfortable and durable without losing the house sound that made them extremely popular and also somewhat divisive within the Head-Fi community.
Advertisement
Who are they for? The same audience that built the brand. Listeners who want a straightforward, open-back, wired experience without getting pulled into feature wars and don’t care about third-party detachable cables.
Based on our experience with the Signature models over the past year, these should be very competitive.
Meta is looking to leverage AI’s ability to inform and potentially influence shoppers to increase sales on the company’s social media platforms, like Facebook and Instagram.
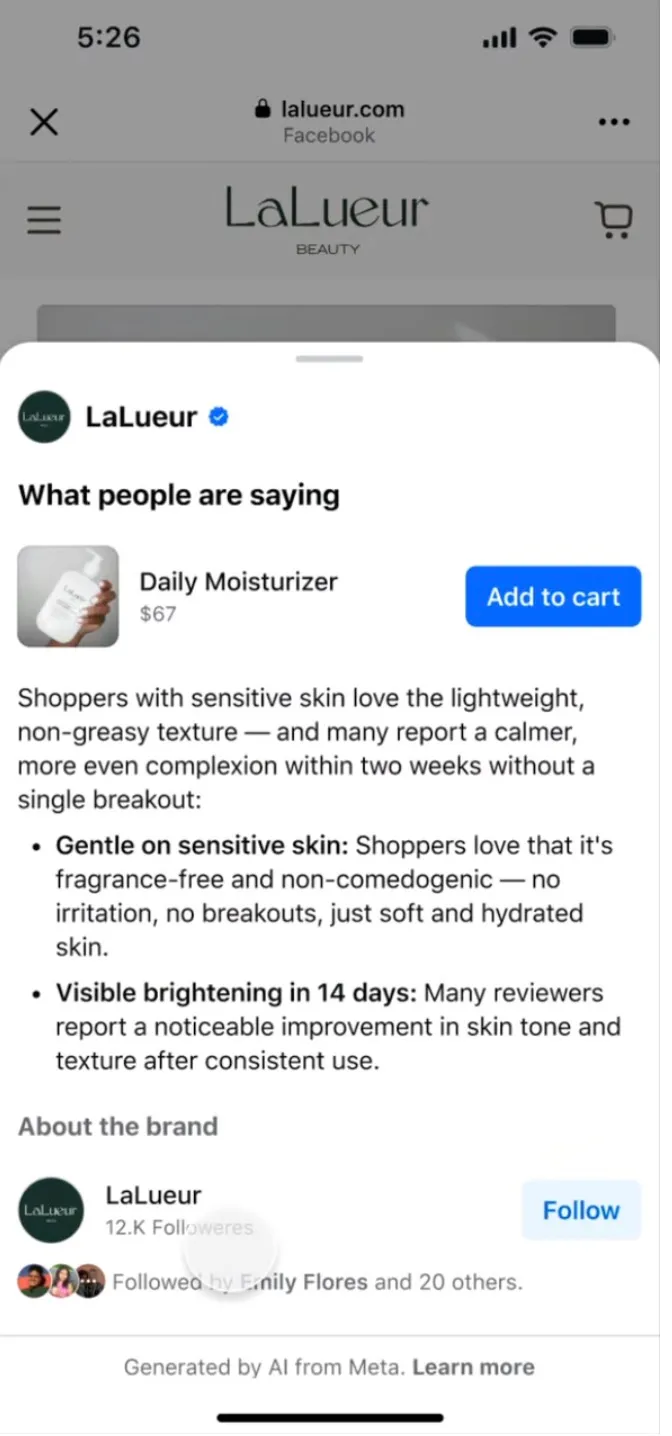
At the Shoptalk 2026 conference this week, the tech giant announced it will begin testing a new experience that allows consumers to see more product information and a summary of user reviews after they click on an ad or visit a website from Facebook or Instagram.
The feature is similar to Amazon’s use of generative AI to enhance its product reviews, introduced in 2023. Instead of requiring users to read through hundreds of reviews to get a sense of what people say about a given product, Amazon uses AI to summarize the reviews into a short paragraph that appears on the product page.
Meta will also use AI in the same way. In the new pop-up experience that appears, the AI feature can offer a round-up of “what people are saying” about the given product. This may include a brief intro followed by key bullet points.
Advertisement
Image Credits:Meta
However, in Meta’s apps, the feature will also provide other general information, including details about the brand itself, recommended products, potential discounts or sales, and, on an individual product’s page, a button to add the item to the user’s cart.
Image Credits:Meta
This is then followed by an updated checkout flow, built in partnership with payment providers Stripe and PayPal, which allows consumers to complete the purchase in just a tap. Meta says it’s already working on other integrations with Ayden and Shopify, which will roll out in the future.
The advertiser is in control of which checkout partner they use, so when a consumer taps the “Buy Now” button, they can complete the purchase and fulfill the order, while the user remains in Meta’s app.
Image Credits:Meta
The changes to checkout come alongside other updates to Meta’s product discovery tools and features.
This includes an update aimed at creators that offers an expanded range of affiliate partners for them to work with on Facebook, as competition with TikTok heats up. The affiliate additions include Amazon, eBay, and Temu in the United States, Mercado Libre in Latin America, and Shopee in Asia.
On Instagram later this year, Meta will also test affiliates like Amazon (U.S.) and Shopee (Asia). The partners will choose which products they want featured and set the commission rates for sales that the creator receives when someone buys through their account.
In addition, Instagram Reels creators will gain access to product catalogs from businesses in 22 countries that will help them find products to feature in their videos.
Energy startup Arbor Energy on Wednesday said it had sold up to 5 gigawatts worth of its modular turbines to GridMarket, a company that helps arrange power projects for data centers and industrial users.
“Everyone wants more power. They wanted it yesterday,” Brad Hartwig, co-founder and CEO of Arbor, told TechCrunch. “The time frames are compressing and the scale is getting larger.”
Arbor’s Halcyon turbines are based on rocket turbomachinery, high-performance engine technology originally developed for spaceflight, and its first commercial turbines will be 3D printed and capable of generating 25 megawatts each. GridMarket’s order, if fully fulfilled, represents 200 units.
Neither company disclosed the exact price of the deal, though Hartwig said that Arbor has seen a “willingness to pay of upwards of $100 per megawatt-hour.” A person familiar with the deal told TechCrunch that the total is in the single-digit billions of dollars.
Advertisement
The startup plans to connect its first turbine to the grid in 2028 and ramp production through 2030, at which point it hopes to deliver more than 100 turbines annually. The goal, Hartwig said, is to eventually produce enough for 10 gigawatts of new capacity every year.
Arbor’s initial designs intended for Halcyon to subsist on a vegetarian diet — the power plant would ingest organic material like crop waste and wood scraps from farms and timber operations, which would be turned into syngas — a combustible gas mixture — and burned in the presence of pure oxygen. The result would be pure CO2, which could be captured and stored underground.
Under that process, each Halcyon turbine would generate carbon negative power. The organic matter it consumes would otherwise have decayed, releasing methane and carbon dioxide into the atmosphere.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
Since then, Arbor has modified Halcyon to accept natural gas in addition to biomass — making it, in effect, more of an omnivore. The process otherwise remains the same, meaning the CO2 that emerges can still be sequestered.
Advertisement
Because it’s using natural gas, it wouldn’t be carbon negative in that configuration. In fact, because methane leaks from pipes and valves throughout the supply chain, Halcyon turbines running on fossil fuel will still produce some greenhouse gas emissions while also fostering continued demand for natural gas. Hartwig said that the company is working with low-leak natural gas suppliers, and that it’s “economically a benefit to sequester that CO2.”
“We see a long-term path to less than 10 grams of CO2 per kilowatt-hour,” Hartwig said. That’s significantly lower than typical natural gas power plants without carbon capture, which release about 400 grams of CO2 per kilowatt hour.
Arbor hasn’t abandoned its biomass-powered projects, and the sale to GridMarket isn’t restricted to one specific fuel. However, other announced deals built around biomass are considerably smaller than the one signed with GridMarket.
Like many energy startups, Arbor has gotten a meaningful boost from the data center boom. Makers of traditional gas turbines were caught flat-footed, and given the volatility of such markets in the past, they’ve been reticent to significantly increase production. Hartwig said that they’d be hard-pressed to quickly ramp production, even if they wanted to.
Advertisement
“Those supply chains largely all get bottlenecked by blades and vanes for traditional turbines. Those are fairly inelastic supply chains, both in how artisanal the production method is — doing directionally solidified, single-crystal turbine blades — as well as very specialized labor, the workforce behind it,” he said. “If you were to get in line for a turbine today, you’d be waiting until 2032.”
Arbor is betting that its machined and 3D printed parts will help it get to market quicker. “People want power in the next few years and they want a lot of it,” Hartwig said.
Kali Linux 2026.1, the first release of the year, is now available for download, featuring 8 new tools, a theme refresh, and a new BackTrack mode for Kali-Undercover.
Kali is a Linux distribution designed for ethical hackers and cybersecurity professionals, with tools for red teaming, penetration testing, network research, and security assessments.
This distribution is available as a live environment or an installable operating system, and it supports a wide range of hardware, including Raspberry Pi devices and compatible Android phones via Kali NetHunter.
New tools added to Kali Linux 2026.1
In this release, the Kali Team has added 25 new packages, updated 183 others, and upgraded the Kali kernel to 6.18.
Advertisement
It has also added new tools to the network repositories, including:
AdaptixC2 – Extensible post-exploitation and adversarial emulation framework
Atomic-Operator – Execute Atomic Red Team tests across multiple operating system environments
Fluxion – Security auditing and social-engineering research tool
GEF – Modern experience for GDB with advanced debugging capabilities
With this year’s first release, the Kali Team introduced a theme update that adds new wallpapers, tweaks the graphical installer interface, and improves the boot and login experience.
“As with previous 20xx.1 releases, this major update brings our annual theme refresh, a long-standing tradition that keeps the Kali Linux interface as modern and innovative,” the Kali devs said.
“This year’s release unveils a brand-new theme from the moment you boot. Everything from the boot menu, installer to the login display, and a fresh set of desktop wallpapers.”
Kali Purple Desktop (Kali)
BackTrack mode for Kali-Undercover
This version also adds a new “BackTrack mode” to the distro’s Kali Undercover, a feature previously that may also be used to make the Kali desktop look like a default Windows 10 installation.
With the new mode, users can quickly switch to a theme closely resembling Kali’s predecessor, BackTrack Linux.
Advertisement
“This mode transforms the desktop to recreate the look and feel of BackTrack 5, with the same wallpaper, colors, and window themes,” the announcement reads.
“You can run it directly from the menu or by running kali-undercover –backtrack in the terminal. You can switch back to the default Kali desktop (or not) by running it again.”
Kali BackTrack Mode (Kali Linux)
The Kali Team also made improvements to the Kali NetHunter app, including a HID permission check and fixes for the WPS scan bug and the back button issue.
If you’re using Kali on Windows Subsystem for Linux, you should consider upgrading to WSL 2 for better support of graphical applications. To check your WSL version, run wsl -l -v in a Windows command prompt.
After upgrading, you can check whether the process was successful using the following command: grep VERSION /etc/os-release.
You can view the complete changelog for Kali Linux 2026.1 on Kali’s website.
Malware is getting smarter. The Red Report 2026 reveals how new threats use math to detect sandboxes and hide in plain sight.
Download our analysis of 1.1 million malicious samples to uncover the top 10 techniques and see if your security stack is blinded.
Apple’s M4 iPad Air refresh is overkill for nearly every tablet task, and sits in a strange but welcome spot between the iPad and iPad Pro.
M4 iPad Air review: iPad Air is now powered by the M4 chip
Recently, the iPad Air has been simultaneously a compromise and upgrade sitting in the middle of on the iPad roster. It provides users with more performance than they’d get on the base iPad, but without hitting the sometimes-nosebleed pricing of the premium iPad Pro. This is why it’s been our recommended iPad for most users. It’s most of an iPad Pro, more than an entry-level iPad, at a solid price point. Continue Reading on AppleInsider | Discuss on our Forums
The new jobs are part of Newcode’s international expansion, following a seed funding round of more than €5m.
Norwegian software company Newcode is continuing its European expansion with plans to hire 30 employees as it develops a presence in Dublin, Ireland. The move is part of Newcode’s plans for international growth, following a seed-funding round of more than €5.7m, which was backed by Alliance VC, The LegalTech Fund and other major investors.
Founded in 2021, Newcode is an Oslo-headquartered organisation with an additional presence across Europe and the US. The company enables firms and enterprises to run intelligent, auditable and context-aware workflows across their legal operations. Currently the company is pitching its agentic AI platform as a digital co-worker for legal teams and processes, as an agent that sits between a firm’s systems, data and applications.
Commenting on the jobs announcement, Maged Helmy, Newcode’s co-founder and CEO, said, “As we expand our international footprint, we’re excited to establish our presence in Ireland starting with new 30 hires planned in the first year as we scale and invest in one of Europe’s most dynamic technology and professional services markets.
Advertisement
“With operations already across Denmark, Oslo, Sweden, Finland, Palo Alto, and New York, Dublin is the natural next step in our growth.”
This week, also in Norway, Lace Lithography, a Microsoft-backed chipmaking equipment start-up, announced the raising of $40m to be used in the advancement of its unique semiconductor technologies. Lace’s engineers have developed a novel system that uses a helium atom beam over a light based system, to enable the design of chips that are 10 times as small as what is currently possible.
The organisation’s CEO Bodil Holst explained Lace’s advancements could allow chipmakers to print silicon wafers at what could be considered “ultimately atomic resolution”.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Last month, Iran’s Tehran Times posted what appeared to be damning satellite proof: a before-and-after image of “American radar,” supposedly “completely destroyed.”
It wasn’t. The image was an AI-manipulated version of a year-old Google Earth shot from Bahrain—wrong location, wrong timeline, fabricated damage. Open source intelligence researchers debunked it within hours matching it to older satellite imagery and identifying identical visual artifacts, down to cars frozen in the same positions.
A small act of disinformation, quickly debunked. But it pointed to a challenge that becomes more difficult during active conflict: The satellite infrastructure that journalists, analysts, pilots, and governments rely on to see conflict clearly in the Gulf is itself becoming contested terrain—delayed, spoofed, withheld, or simply controlled by actors whose interests don’t always align with public access.
The escalation follows rising tensions between the US, Israel, and Iran, with missile and drone activity crossing Gulf airspace and regional infrastructure—including satellites and navigation systems—entering into the conflict.
Advertisement
No Longer Neutral Infrastructure
When satellite data becomes unreliable, control over it becomes a central question.
In the Gulf, satellite infrastructure is largely run by state-backed operators. These rely on geostationary satellites—positioned high above the equator—which are used for activities such as broadcasting, communication and weather forecasting.
In the United Arab Emirates, that includes Space42 for secure communications and Earth observation. Saudi-led Arabsat handles broadcasting and broadband, while Qatar’s Es’hailSat supports regional connectivity. All operate under close government oversight.
Iran is building a parallel system. Its satellites, including Paya (also known as Tolou-3), are part of a broader push to expand surveillance capabilities independently of Western infrastructure. The high-resolution Earth observation satellite was launched from Russia’s Vostochny Cosmodrome.
Advertisement
The market around that infrastructure is growing fast. The Middle East satellite communications sector is valued at more than $4 billion and projected to reach $5.64 billion by 2031, according to one estimate, driven largely by airborne connectivity linked to both commercial aviation and defense demand. Maritime platforms already account for nearly a third of regional revenue.
Access Is the New Bottleneck
Commercial low-Earth orbit fleets like Planet Labs and Maxar operate differently from government-owned systems—and access is the main constraint. Governments receive priority tasking, while newsrooms and NGOs rely on paid subscriptions.
On March 11, Planet Labs announced it would extend delays on imagery of the Middle East by two weeks. The company denied the decision came from any government request, stating instead that it was to “ensure our imagery is not tactically leveraged by adversarial actors to target allied and NATO-partner personnel and civilians.”
Maryam Ishani Thompson, an open source intelligence (OSINT) reporter, tells WIRED Middle East that “the loss of Planet Labs is so harsh because we were getting a fast refresh rate. Even if we turn to Chinese satellites, we don’t get that speed.”
Advertisement
Chinese platforms like MizarVision, a Shanghai-based open source geospatial intelligence provider, have seen increased use since the delays—part of a broader shift in who controls the imagery pipeline. Russia and China are also increasingly sharing satellite access with Iran, meaning the companies that once set the terms of what the world could see are no longer the only ones with eyes on the Gulf.
If You Can’t Verify, You Can’t Challenge the Narrative
Operationally, the consequences are immediate.
Ishani’s verification process depends on historical reference points. The static nature of the Tehran Times image—with cars in identical positions across both frames—was detectable precisely because journalists had recent imagery to compare against. Remove that baseline, and the same image becomes harder to debunk.
“In that opaque space,” Ishani says. “Iran is producing its own false narrative. If we can’t document it and fact-check it, they can continue to create a narrative and sell it to their people.”
Advertisement
Victoria Samson, chief director of space security and stability at nonprofit Secure World Foundation, says that, for most commercially and privately owned satellite companies, the US government is one of their largest customer—creating “a reluctance to upset the US government.”
Ring has today announced a spec bump to its battery-powered video doorbells for all those folks who can’t wire their units to power. The flagship Battery Doorbell Pro (2nd gen) gets 4K video, with 10x zoom and the promise of far longer time between recharges than the previous model. At the same time, it’s bringing 2K imaging to its lower-end battery doorbells, the Battery Doorbell Plus and Battery Doorbell (2nd gen). The former, as fitting its higher price, gets a quick-release battery pack, while both models get 2K video and 6x zoom. Naturally, these features are already available on Ring’s wired products, the bulk of which were announced back in September 2025.
The company is also aware that swapping out batteries isn’t ideal if you really need a doorbell to work all of the time. That’s why it’s also launching a new Solar Charger which integrates into the mount, keeping your doorbell running for longer between trips to the wall outlet. There’s also a bigger Solar Panel, which pumps out more juice than its smaller sibling, and can be mounted in a wider variety of places. All of the above are available to pre-order from today, and are priced as follows: Pro ($250), Plus ($180), Battery Doorbell ($100), Solar Charger ($50), Solar Panel ($60).
Production will be shifted to its regional facilities in Malaysia and Vietnam
[Editor’s Note: This article has been updated with the latest developments on APBS’ job cuts and Tuas plant changes.]
Tiger Beer brewer Asia Pacific Breweries Singapore (APBS) is cutting jobs and scaling down its brewing operations in Singapore, according to media reports from The Business Times and Channel NewsAsia today (Mar 24).
The brewer plans to progressively phase down large-scale brewing at its Tuas plant by the end of 2027, with around 130 roles affected as production is shifted to regional facilities in Malaysia and Vietnam. Over time, the Tuas site will be redeveloped to support regional logistics and innovation activities, including a pilot brewery.
The operational changes in Singapore will be implemented “progressively.” APBS said it will work with the Food, Drinks and Allied Workers Union (FDAWU) to support affected employees with severance, reskilling, outplacement services and well-being resources.
Advertisement
The retrenchments aren’t coming out of nowhere. APBS last restructured in late 2023, cutting 33 jobs and giving affected staff severance, bonuses, and annual wage supplements.
Globally, parent company Heineken also flagged more cuts earlier this year, saying 5,000 to 6,000 jobs could go over the next two years as market conditions tighten. Singapore serves as its Asia-Pacific headquarters.
The move follows a 2.8% drop in consolidated beer volumes in 2025, with Europe and the Americas seeing declines of 4% and 3.6%, respectively. The two markets account for 68.2% of total beer volumes.
Industry experts note that declining alcohol consumption among younger consumers is reshaping the market. Many young adults are drinking later, in smaller quantities, or not at all, opting for experiences over intoxication.
Advertisement
That said, Asia-Pacific beer volumes still rose slightly by 0.4% to 4.6 billion litres.
APBS, formerly known as Malayan Breweries, launched Tiger Beer in 1932 through a partnership between Heineken and Fraser and Neave (F&N). The company rebranded as APBS in 1990, and Heineken acquired F&N’s stake for S$5.6 billion in 2012.
Vulcan Post has reached out to APBS for further information.
Read more stories we’ve written on the latest job trends here.
Featured Image Credit: MR. AEKALAK CHIAMCHAROEN via Shutterstock.com/ Asia Pacific Breweries Singapore



































































You must be logged in to post a comment Login