
TL;DR
Rivian CEO RJ Scaringe says supervised point-to-point self-driving arrives this year on Gen 2 and R2 vehicles, with eyes-off driving in 2027.


Our first look at the entire luxury EV designed by LoveFrom.
If the wild, Jony Ive- and Marc Newson-designed interior for the Ferrari Luce had you intrigued and wanting more, here’s the payoff. After committing to build an EV last year, ignoring those earlier statements that it would never happen, Ferrari has finally given me a look at the entire finished product. As big a departure as that interior is from Ferrari’s current suite of sports cars, the exterior is an even bigger step, one that not everyone is going to love.
Whether you love it or hate it, you can likewise attribute Luce’s exterior styling to LoveFrom, the design house founded by Jony Ive in 2019. Though this is LoveFrom’s first full car design, it’s actually Newson’s second, following on the Ford 021C concept from 1999. That vehicle has a very different shape from the Luce, but it does feature doors that open the same way, and I’m picking up similar vibes from both.
The Luce is definitely not a traditional sports car, more like an SUV in its size and shape, featuring four doors and five seats. It isn’t Ferrari’s first four-door; the Purosangue SUV bears that honor, but it is the first time a car with a prancing horse on the hood has seated more than four people.
And it does so reasonably comfortably. The back seat is quite roomy, accessed via a pair of so-called suicide doors that hinge at the rear, making for a slightly more glamorous, less awkward entry to the back. For extra style on the red carpet, there’s a button that swings them shut for you.
I found headroom in the second row to be just a bit limited, but otherwise, I was quite content. There’s even a little control pad back there to fiddle with that has the same funky knobs and dials as found in the interior up front.
I spent more time fiddling with those controls from the driver’s seat, and I’m sorry to report the software is still largely non-functional at that point. The cheeky little stopwatch in the upper-right of the touchscreen did nothing, nor did the drive modes or seat ventilation. Still, everything looked good and felt great, something that can’t be said for most pre-production models like this.
Seeing the interior inside of an actual car, rather than standing free on pedestals as I experienced it before, gave me a very different impression. Where previously I thought it was far too cold and clinical for a Ferrari, surrounded by the scent and presence of warm leather, it actually seemed to fit.
I still don’t think the typical Ferrari owner is going to immediately fall in love with that interior, but then I don’t think the typical Ferrari owner is going to fall in love with the exterior, either. This is a model to not only extend Ferrari’s portfolio but also to diversify its clientele, too. Or, as Ferrari CMO Enrico Galliera said: “The possibility to enlarge our Ferrari community.”
It may not look or feel like a Ferrari, but it should offer the kind of outrageous performance typical of the brand. It has 1,035 horsepower, which is certainly a lot, but more importantly, it comes from a set of four motors. That means one per wheel, a setup that should deliver some impressive dynamics.
By adding more power to the outside wheels, the Luce can be made to turn into corners more aggressively. And, by modulating power individually, the EV can more precisely handle low-grip situations, or even wheelspin on high-grip surfaces, which will surely be an issue since 1,035 horsepower is plenty enough to liquify even the best of tires.
The car also has four-wheel steering, so it can turn the back wheels with or against the fronts to either add more stability or agility. The Luce features a version of Ferrari’s active suspension, which relies on an electrically actuated damper system to not only provide varying degrees of stiffness or softness, but to dynamically adjust ride height, too. Get up to speed on the highway (maximum 193 mph), and it’ll lower itself by 10mm.
All that comes together with a new, more advanced traction and stability control systems, all managed by what Ferrari calls the Vehicle Control Unit, or VCU. The system is designed to sample the road surface and motor output on all four corners every 5 milliseconds, adjusting power output and suspension behavior to best suit conditions.
Power comes from a 122-kWh gross battery pack situated down low in the car, skateboard-style. That charges at a maximum speed of 350 kW, and Ferrari says it’ll deliver 329 miles on the European WLTP cycle. If that holds, it’ll likely be somewhere south of 300 miles on the harsher EPA cycle.
That’s all fair enough, and I look forward to experiencing how well it comes together in due time, but there’s one other system onboard that might prove equally vital in forming the complete driving experience.
EVs, of course, make very little noise. Their silence is one of their strongest attributes when you’re just cruising to work. But with Ferrari, the sound has always been a crucial part of the experience. Thankfully, that continues with the Luce.
Rather than creating a wholly synthesized sound, like Hyundai’s Ioniq 5 N, for example, the Luce actually has a sort of acoustic pickup mounted on the rear axle. There, it can sample the vibrations of the rear motors. That signal is then pumped through a sort of amplifier to create a distinctive note that is suitably evocative but still wholly distinctive. It has a familiar sound that isn’t far off from some of the company’s high-strung V8s in the past, but yet clearly isn’t trying to pretend to be something else. It is its own thing.
Ferrari likens the process to an amp for an electric guitar, pointing to this being the next evolution beyond analog motoring. Ferrari has already evolved through numerous powertrains in the past, both large and small, and with engines mounted ahead of or behind the driver.
This, though, feels rather more significant, a complete reboot to both the brand’s look and feel as well as its means of propulsion. Will it be successful? Before anyone can draw a conclusion there we’ll have to see how it drives. Hopefully that’s an answer we can provide soon.
Hopefully we’ll know how much it costs soon, too. Ferrari has not yet set U.S. pricing, but in its home market of Italy it will carry a starting price of €550,000. That will make it the company’s most expensive model, pricing it well above the roughly $430,000 Purosangue. That’s quite an ask, but then most of LoveFrom’s prior designs have carried quite a premium, so why shouldn’t this?


offbeat
Worried that an unexpected strike could take out critical orbital systems, Pentagon researchers want to know how fast the industry thinks it could launch replacements
War may never change, but its domains evolve, and DARPA is looking for ideas to ensure space infrastructure destroyed in future orbital skirmishes can be rapidly replaced.
DARPA, on Friday, put out a request for information for an initiative to develop what it’s calling Rapid Reconstitution of Space Capabilities.
“Other nations seek to position themselves as leading space powers while undermining the stability and tranquility that allows space to benefit all nations,” DARPA said, suggesting that the US would never dare deploy space weapons that could destabilize the tranquility of Earth orbit.
“Space is an increasingly contested environment, presenting a multitude of threats to U.S. space assets,” DARPA added. “Therefore, there is a strategic need to be able to quickly respond to disrupted assets and reconstitute degraded space capabilities.”
While we don’t know if the US has any weapons in space – we asked but didn’t get a response – other countries certainly are striking an aggressive posture.
Both Russia and China have reportedly blown up their own defunct satellites in recent years to demonstrate their space warfare capability, and the US Space Force has noticed what appears to be China experimenting with orbital satellite dogfighting maneuvers. The US has also accused Russia of developing anti-satellite weaponry that may or may not involve orbital nukes, leading the US to update its fleet of satellites designed to keep an eye out for potential nuclear launches.
“U.S. competitors are implementing a sustained effort to develop a broad range of offensive counterspace capabilities through a variety of anti-satellite (ASAT) weapons, including direct attacks on satellites, jamming and spoofing of signals, and continued cyberattacks on satellite and ground infrastructure,” DARPA noted in Friday’s announcement.
Pointing to the 2023 Space Force tactically responsive space exercise Victus Nox, which saw the USSF launch a space vehicle into orbit just 27 hours after getting the word, DARPA said it wants more of the same, but hopefully faster.
“DARPA Strategic Technology Office seeks information supporting technical solutions and operational concepts and strategies to enable rapid, responsive, cost-effective reconstitution of any lost or degraded space capabilities resulting from attacks,” DARPA explained, adding that it’s not looking for anything more than ideas at this point, but is willing to entertain anyone in the US with a good idea, be they laboratory or private outfit.
According to the announcement, DARPA wants ideas that would get degraded operations restored in “hours to weeks,” and offer the same turnaround time for cases of surging demand as well as asset loss.
“Possible solutions could be realized with reconfigurable, software-defined, multifunctional, and multi-mission payloads, as well as proliferated/mesh architectures and rapid on-orbit deployment concepts,” the Pentagon research arm said.
“Rapid space capability reconstitution is a complex task,” DARPA added, so don’t expect this research to move anywhere near the speed of DARPA’s eventual rapid reconstitution rockets.
Then again, America just minted the world’s first trillionaire, and he’s a space guy – maybe ask him how to launch rockets quickly? Surely his ideas would be grounded in good sense, right?

alternative_right shares a report from The Hill: The FBI released an urgent security warning to the public about a fast-acting scam targeting Microsoft 365 users on Teams, Outlook and OneDrive. The agency warned that the hacking platform Kali365 seeks out OAuth device codes, allowing scammers to sneak past multi-factor authentication codes, and without the need for a password, to access Microsoft accounts. Scammers will send a phishing email impersonating a trusted document-sharing service with a device code and instructions on how to verify, according to the FBI.
“Kali365 lowers the barrier of entry, providing less-technical attackers access to AI-generated phishing lures, automated campaign templates, real-time targeted individual/entity tracking dashboards, and OAuth token capture capabilities,” the FBI stated. The platform is sold to scammers with a $250 per month subscription. The FBI, which first detected Kali365 in April, described the hacking platform as an “emerging Phishing-as-a-Service platform.” Hackers with limited skills can access advanced phishing tools through the platform, according to NordPass.


Rivian CEO RJ Scaringe says supervised point-to-point self-driving arrives this year on Gen 2 and R2 vehicles, with eyes-off driving in 2027.
Rivian CEO RJ Scaringe said the company will ship supervised point-to-point self-driving on all of its second-generation vehicles and the R2 later this year, describing the capability as “very similar to Tesla’s FSD.” Speaking at the Masters of Scale event in Anaheim on Thursday, Scaringe laid out a three-stage autonomy roadmap: supervised point-to-point driving in 2026, eyes-off unsupervised driving in 2027, and a commercial robotaxi service with Uber beginning in 2028.
The announcement represents a significant jump from Rivian’s current driver-assistance system. Universal Hands-Free, which rolled out in late 2025, handles steering and speed on roughly 3.5 million miles of marked roads in the US and Canada. It does not navigate turns, traffic lights, roundabouts, or parking lots.
Point-to-point driving would extend the system’s capabilities to handle complete journeys from origin to destination, similar to what Tesla’s Full Self-Driving Supervised already attempts. The leap from highway lane-keeping to full urban navigation is the hardest problem in autonomous driving, and no company has solved it without significant constraints.
“Later this year, we’ll have full supervised point-to-point, which will be very similar to Tesla’s FSD,” Scaringe said. “And that’ll roll out to all of our Gen 2 vehicles and, of course, R2.” He did not specify a month or quarter for the rollout, and Rivian has not publicly demonstrated the point-to-point system in an uncontrolled environment.
The comparison to Tesla is deliberate but architecturally inexact. Tesla’s FSD relies exclusively on cameras, while Rivian’s platform integrates 10 external cameras, five radar units, 12 ultrasonic sensors, and a high-precision GPS receiver. Rivian began delivering R2 SUVs earlier this month, and future R2 models will add a roof-mounted LiDAR sensor and the company’s custom RAP1 processor, a 5nm chip delivering up to 1,600 trillion operations per second.
The pricing undercut is sharper than the technology comparison. Rivian’s Autonomy+ package costs $2,500 as a one-time purchase or $49.99 per month, compared with Tesla’s FSD at $8,000 or $99 per month. Whether the lower price reflects a competitive strategy or a difference in capability remains to be seen, given that Rivian’s point-to-point system does not yet exist as a shipping product.
Rivian’s autonomy software is built around what the company calls a Large Driving Model, a foundational AI system trained end-to-end through reinforcement learning. The LDM maps raw sensor input directly to vehicle trajectory, analysing multiple driving paths and selecting the optimal one using a technique called Group-Relative Policy Optimization. The approach mirrors the end-to-end neural network philosophy Tesla adopted with FSD v12, though Rivian’s multi-sensor hardware gives the model a wider range of input data to work with.
The 2027 eyes-off milestone is where the roadmap becomes commercially consequential. Supervised driving, regardless of how capable, still requires a human to watch the road. Tesla has been promising unsupervised FSD for years and has pushed the timeline repeatedly, most recently to Q4 2026 at the earliest. Scaringe has said Rivian targets Level 3 autonomy by 2028 and Level 4 by 2030, timelines that no autonomous driving company has consistently met.
The commercial centrepiece of the roadmap is the $1.25 billion deal with Uber announced in March. Uber committed an initial $300 million investment, with the remainder contingent on Rivian hitting autonomous performance milestones through 2031. The deal calls for Uber or its fleet partners to purchase 10,000 fully autonomous R2 robotaxis, with an option for up to 40,000 more beginning in 2030. Commercial deployment is planned for San Francisco and Miami in 2028, expanding to 25 cities by 2031.
Those targets depend on Rivian achieving something it has not yet demonstrated: a vehicle that can drive itself without human supervision. The company’s Gen 3 autonomy platform, which will power the robotaxi programme, is still undergoing validation. The initial R2 production run launched without the Gen 3 hardware, meaning the robotaxi-grade vehicles are at least one hardware generation away from production.
Scaringe framed the self-driving push as essential to Rivian’s long-term economics. The company posted a net loss of $3.63 billion in 2025 despite achieving its first full-year positive gross profit at $144 million. Autonomy, if it works, transforms the revenue model from selling cars to operating a transportation platform. But the gap between announcing a roadmap at a conference and shipping a reliable autonomous system is where most self-driving timelines have historically broken down.
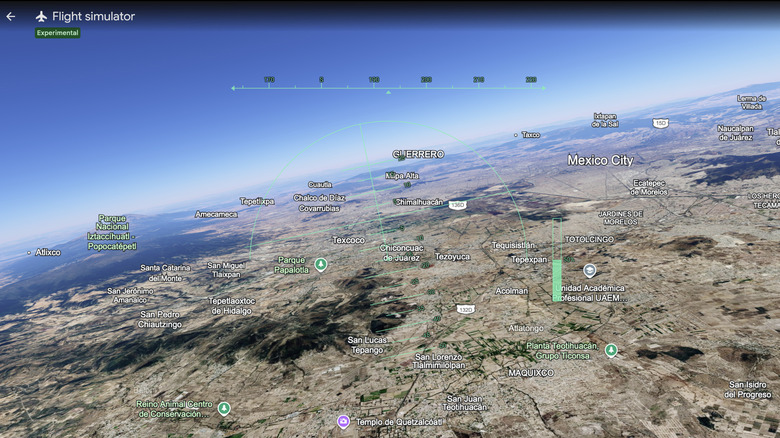
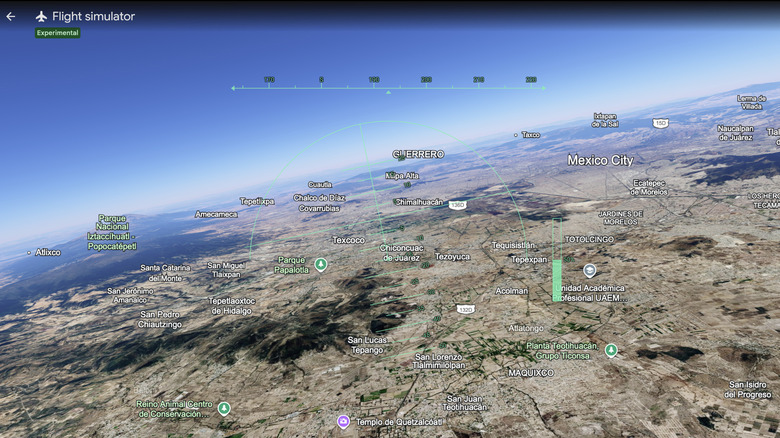
In case Microsoft Flight Simulator is a little too realistic for your tastes, there’s a new way you can take to the virtual skies. Google Earth has a flight sim mode of its own, and it can now be accessed by anyone globally via their browser. Android Police spotted a social media post from the Google property announcing this update.
Prepare for takeoff. ✈️ Flight simulator is now available globally on web to all users. https://t.co/jV5ZW7BZeW
We’ve recently added many our most powerful professional desktop features to web. Elevation profiles, new import types, but there’s always been one other feature… pic.twitter.com/s11NDaCx60
— Google Earth (@googleearth) June 12, 2026
Google Earth seems to be the area where the massive company remembers that tech can be cool and downright fun. In 2024, it added an option for seeing historical recreations of select times and places. This is the sort of clever curio we love, and Google delivered even more the following year.
Once you have Google Earth open, go to Explore Earth, then the Tools menu to find the Flight Simulator mode. There’s an FAQ for you newbie virtual pilots to help you get acclimated to the Google Earth simulation. Just bear in mind two caveats. For one, this is an experimental feature, so you might have some wonky moments with the flight simulator. And second, Google wants to be very clear that this isn’t enough to put you in the cockpit of an actual 747: “The flight simulator is designed for casual exploration rather than high-fidelity aerodynamic training,” it notes. Happy travels!

Retroid has brought back the 12GB RAM configuration of the internet-famous Pocket 6, returning it to the lineup at the same $279 price point as the discontinued version.
The original 12GB RAM variant was pulled from sale earlier this year after Retroid cited the rising cost of RAM and storage, leaving the Pocket 6 available only in its 8GB RAM configuration.
However, the updated model comes with the catch of reduced internal storage. That storage reduction is the most consequential change in the new configuration, with the returning 12GB model shipping with 128GB of UFS 3.1 storage rather than the 256GB that the discontinued version carried, effectively halving the built-in capacity at an unchanged retail price.
The new variant also arrives with a more limited set of options than the original, restricted to a single control layout with asymmetrical thumbsticks, meaning buyers who prefer the symmetrical D-pad Top arrangement will need to step down to the 8GB RAM version to get that configuration.
Colour availability has narrowed as well, with the 12GB RAM model offered only in Black, 16Bit, and Silver, dropping the Light Purple and Orange options that were available on earlier Pocket 6 configurations sold through the official Retroid store.
Retroid also announced the returning model through its official Discord channel rather than a formal press release, confirming the device is in stock and available to ship immediately, which places it ahead of competing handhelds such as the AYN Thor and Odin 3 that are currently operating on pre-order timelines.
The new 12GB RAM Pocket 6 is priced at $279 and remains exclusive to the official Retroid website, with the device confirmed in stock and ready to ship immediately.

Fluance has built its reputation by walking the line between affordability and performance, offering a wide range of powered speakers, passive loudspeakers, and turntables aimed at listeners who want better sound without wandering into boutique audio bankruptcy. The new $799.99 Fluance RT87 turntable pushes that formula further, arriving as the company’s most advanced record player to date with a dual plinth construction and a choice of moving magnet cartridges.
That matters because the entry-level turntable category is no longer a sleepy corner of the hi-fi market. Fluance, U-Turn Audio, Pro-Ject, Rega, and Audio-Technica are all fighting for the same growing audience: vinyl buyers who want real performance, clean industrial design, upgrade potential, and pricing that does not require explaining a “lifestyle purchase” to another adult. With the RT87, Fluance is clearly trying to move higher up the food chain without abandoning the value equation that made the brand relevant in the first place.
“With the RT87, we wanted to push every aspect of high-fidelity playback performance further, from vibration isolation to tonearm precision,” said Justin Koetsier, Product Manager at Fluance. “Every decision behind this turntable was made with musical accuracy in mind. As more listeners demand higher-resolution analog systems, the demand is no longer just for a turntable, but for a platform that allows the stylus to retrieve the clearest possible signal from the groove.”

The RT87’s most distinctive physical attribute is its newly developed dual-plinth architecture, designed to isolate key signal-path components from unwanted resonance and environmental vibration. The motor is mounted independently on the lower plinth, while the tonearm and cartridge assembly sit on a decoupled upper plinth, separated by precision conical isolators.
The physical separation created by the RT87’s dual-plinth construction is designed to reduce the transfer of motor-borne resonance and external vibration before it can reach the stylus. The dense wood plinths are also intended to help damp mechanical resonance within the chassis. If properly implemented, this type of isolation can support more stable groove tracking, a lower noise floor, and improved clarity across the soundstage.

The RT87 features a 9-inch carbon fiber tonearm designed for low resonance, high rigidity, and precise stylus control. Its straight-arm geometry and 230 mm effective length are intended to trace a controlled arc across the record surface, helping reduce tracking error when properly aligned. The tonearm supports cartridges weighing 5 to 9.5 grams.

This feature enables listeners to fine-tune cartridge alignment for optimal stylus contact and enhanced detail retrieval, while a removable headshell makes cartridge upgrades and adjustments simple, giving listeners the flexibility to evolve their setup over time.

The Fluance RT87 is available in two configurations, each fitted with a premium moving magnet cartridge. The Audio-Technica AT-VM95ML version uses a Microlinear stylus and offers a 3.5 mV output, making it the more detail-focused option, particularly for listeners concerned with groove tracing and inner-groove distortion.
The Ortofon 2M Blue version uses a nude elliptical stylus and delivers a higher 5.5 mV output, giving it a stronger signal into a MM phono stage and a different tonal balance. These are not interchangeable flavors of the same cartridge; the AT-VM95ML and 2M Blue have distinct output levels, stylus profiles, and sonic personalities.
“Each cartridge brings its own character to the RT87,” said Justin Koetsier, Product Manager at Fluance. “Whether listeners prioritize warmth, detail retrieval, or overall musicality, both options were selected to fully showcase the capabilities of the platform.”

For improved playback stability, the RT87 uses a thicker and heavier 22 mm, 4.1-pound anti-static acrylic platter. Compared with the 16 mm, 3-pound acrylic platter used on the RT85 and RT85N, the new platter adds both thickness and mass, which should increase rotational inertia and may help reduce speed instability. Fluance also claims the acrylic construction helps damp unwanted resonance and reduce static. The belt-drive system supports 33⅓, 45, and 78 RPM playback speeds, and the RT87 also includes auto-stop functionality.

Fluance takes a traditional connectivity approach with the RT87. There is no built-in phono preamp, USB output, or Bluetooth connectivity, so the turntable is aimed at listeners who plan to use a conventional analog setup. The RT87 provides a standard phono-level output with a ground connection. To connect it directly to an integrated amplifier or stereo/AV receiver, that component needs a dedicated MM phono input. If it does not, an external MM phono preamp must be connected between the turntable and an available line-level input on the amplifier or receiver.
In the following chart, we have compared the Fluance RT87 with their popular, but lower-priced RT85N and the popular Denon DP-500BT at a similar RT87 price point, which includes built-in Bluetooth.

| Brand/Model | Fluance RT87 (2026) | Fluance RT85N (2021/2022) | Denon DP-500BT (2026) |
| Product Type | Turntable | Turntable | Bluetooth Turntable |
| Price | $799.99 | $549.99 | $899.99 |
| Turntable Type | Belt Drive | Belt Drive | Belt Drive |
| Speed | 33 1/3 RPM 45 RPM 78 RPM |
33 1/3 RPM 45 RPM |
33 1/3 RPM 45 RPM 78 RPM |
| Speed Variation | 33 – 0.08% 45 – 0.06% 78 – 0.01% |
0.10% | Not Indicated |
| Wow and Flutter | 0.06% | 0.07% | 0.1% (WRMS) |
| Signal-to-Noise Ratio (Weighted) | 70 dB | 68 dB | 62 dB |
| Weight of Platter | 4.1 lbs (1.85 kg) | 3 lbs (1.56 kg) | Not Provided |
| Height of Platter | 0.86 inches (22 mm) | 0.62 inches (16 mm) | Not Provided |
| Auto-Stop | Yes | Yes | Yes |
| Tonearm Type | Static Balanced, Straight | Static Balanced, S-Type | Static Balanced, S-Type |
| Supported Cartridge Weight | 5 g – 9.5 g | 5 – 7.5 g | 5 – 13 g |
| Tonearm Material | Carbon Fiber, One-Piece Tube | Aluminum | Aluminum |
| Overhang | 0.73 inches (18.5 mm) | 0.76 inches (19.2 mm) | 0.6 inches (16mm) |
| Effective Tonearm Length | 9.06 inches (230 mm) | 8.82 inches (224 mm) | 8.7 inches (220mm) |
| Pivot to Spindle Distance (NEW SPEC) | 8.33 inches (211.5 mm) | Not Indicated | Not Indicated |
| Headshell Offset Angle (NEW SPEC) | 24° | Not Indicated | Not indicated |
| Connectors | Tiffany Style RCA (24k Gold-plated) | Tiffany Style RCA (24k Gold-plated) | Standard RCA |
| Phono Preamp | – | – | Yes |
| Phono Cartridge | Audio-Technica AT-VM95ML, or Ortofon 2M Blue |
Nagaoka MP-110 | Denon CN-6518 |
| Bluetooth | – | – | Yes |
| Dimensions (HWD) | 6.3 x 16.5 x 14.25 inches
16.0 x 42.0 x 36.2 cm |
6 x 16.5 x 14.25 inches
14.6 x 41.9 x 36.2 cm |
4.65 x 16.8 × 14.1. inches
11.8 x 42.6 × 35.7 cm |
| Weight | 21 lbs (9.5 kg) | 16.76 lbs (7.6 kg) | 13.7 lbs (6.2 kg) |

The under-$1,000 turntable category has become one of the more competitive corners of hi-fi, and Fluance is clearly trying to move beyond its value-driven comfort zone with the RT87. At $799.99, this is not just another RT85 variant with a different cartridge bolted to the headshell. The RT87 adds a dual-plinth chassis, a thicker 22 mm acrylic platter, a 9-inch carbon fiber tonearm with VTA adjustment, 78 RPM playback, auto-stop, and the choice of either the Audio-Technica AT-VM95ML or Ortofon 2M Blue moving magnet cartridge.
That makes the RT87 more focused than many of the lifestyle-driven turntables now crowding this price range. Fluance is not chasing Bluetooth, USB ripping, app control, or plug-and-play convenience here. There is no built-in phono preamp, no wireless output, and no USB connection, which means buyers will need an amplifier or receiver with a proper MM phono input, or a separate outboard phono stage.
Those omissions will matter to anyone looking for an all-in-one vinyl solution. The Technics SL-40CBT and Denon DP-500BT offer more modern convenience, while Pro-Ject, Rega, and U-Turn continue to fight hard on tonearm design, speed control, build quality, and upgrade paths. But the RT87’s argument is different: spend the money on the mechanical parts that matter most to analog playback and leave the digital extras outside the plinth.
That makes the Fluance RT87 a more serious step up for listeners who already own, or plan to buy, a proper phono stage. It is less convenient than some of its rivals, but also more purpose-built. For the dedicated record listener who wants cartridge flexibility, better isolation, and a more substantial platform without crossing the $1,000 line, the RT87 looks like Fluance’s most credible turntable yet.
The Fluance RT87 is available now in Natural Walnut, Piano White, and Piano Black with a choice of an Audio Technica AT-VM95ML or Ortofon 2M Blue phono cartridge for $799.99 at Amazon or Fluance.

JBL is not done feeding the party speaker machine in 2026. Following the PartyBox On The Go 2 Plus, the company has added two more portable party speakers to the lineup with the new JBL PartyBox 330 and PartyBox 130.
Both models arrive with upgraded woofers, new tweeters, deeper bass extension, and clearer highs, along with JBL’s AI Sound Boost and Smart EQ to help optimize playback across different tracks. That matters in this category, where “loud” is easy and “loud without sounding like a shopping cart full of Bluetooth regrets” is the harder trick.
The design has also been updated, with a new hexangle profile, curved front grille, redesigned lightshow, and a simplified top control panel built around a single dial for volume, sound modes, and lighting effects. Available in Black or White with orange accents, the PartyBox 330 and 130 look like JBL is pushing the line toward a cleaner, more modern identity without forgetting the main job: make the room, backyard, beach, or basement move.

At its core, the JBL PartyBox 330 uses dual 6.5-inch woofers and delivers 280 watts of total output power. Making their PartyBox debut, twin PEN dome tweeters bring technology used in JBL’s professional concert systems, with the goal of producing cleaner, more detailed highs that can cut through the mix when the volume climbs.
JBL also includes AI Sound Boost with Smart EQ Mode, which adjusts playback to help keep the sound balanced across different tracks. The redesigned cabinet adds a new profile, ripple-effect side panels built from miniature JBL horn shapes, and a reinvented beat-synced lightshow because, apparently, standing still in the corner was never part of the brief.
Battery life is rated at up to 18 hours, while a 10-minute Fast Charge can provide up to 2 hours of playback. The battery is also replaceable, so users can charge a spare and swap it in when the party outlasts the first pack.
For easier transport, the PartyBox 330 includes a telescopic locking handle and wide all-terrain wheels. The IPX4 splashproof rating adds protection against splashes, making it suitable for poolside use, patios, and outdoor gatherings.
Dual mic and guitar inputs support karaoke, sing-alongs, and basic live performance use. JBL has also added an optical TV input, USB-C for lossless audio, and Bluetooth for wireless streaming from smartphones and tablets.
Auracast support allows users to pair multiple compatible JBL speakers, making it easier to expand coverage for larger spaces or bigger crowds.

For those looking for a more compact PartyBox model, the JBL PartyBox 130 delivers up to 200 watts of output power. It uses upgraded 5.25-inch woofers and 25mm silk dome tweeters, with JBL promising stronger bass and clearer highs from the smaller cabinet.
The PartyBox 130 also includes a redesigned lightshow with strobe edge lighting and dynamic visual effects. Battery life is rated at up to 15 hours, while a 10-minute Fast Charge provides up to 80 minutes of additional playback.
A redesigned foldable carry handle makes the 130 easier to move, and its IPX4 splashproof rating adds protection against splashes and light spills. Like the PartyBox 330, it includes mic and guitar inputs, Bluetooth streaming, and Auracast support for connecting multiple compatible JBL speakers.

To get more out of the PartyBox 330 and PartyBox 130, JBL also offers EasySing Mics as an optional accessory. They add karaoke-focused features for users who want to use either speaker for sing-alongs, parties, or casual live performance.
Pro Tip: JBL EasySing Mics are not included with the PartyBox 330 or PartyBox 130. They require a separate purchase.
The JBL EasySing Mics provide real-time, AI-powered vocal removal from tracks while maintaining clear, balanced audio. Users can adjust the vocal level to 25%, 50%, or fully removed. The EasySing algorithm enhances live vocals with Voice Boost for improved high-frequency clarity, along with reverb, echo, and noise suppression.
The JBL EasySing Mic Mini is a new compact version that provides a pocket-sized solution for singing and content creation. It includes Voice Boost for high-pitch support and AI-based noise suppression to reduce background interference.
| JBL Model | PartyBox 330 | PartyBox 130 |
| Product Type | Party Speaker | Party Speaker |
| Price | $629.95 | $449.95 |
| Power Output (total) | 280 W | 200 W |
| Speaker Drivers | 2 x dual 6.25″ Woofers 2 x 25mm PEN dome Tweeters |
2 x dual 5.25″ Woofers 2 x 25mm silk dome Tweeters |
| Product Height | 26.1 inches | 22.6 inches |
| Weight | 37.7 lbs | 24.9 lbs |
| AI Sound Boost | Yes | Yes |
| Smart EQ Mode | Yes | Yes |
| Light Show | Yes | Yes |
| Playtime | Up to 18 hours | Up to 15 hours |
| Fast Charge | 10 min = 2 hrs | 10 min = 80 min |
| Handle | Telescopic | Foldable |
| IP Rating | IPX4 splashproof | IPX4 splashproof |
| Inputs (Wired) | Dual mic
Dual guitar inputs USB-C lossless audio Optical input 3.5mm aux |
Dual mic
Dual guitar inputs USB-C lossless audio Optical input 3.5mm aux |
| Inputs (Wireless) | Bluetooth 6.0 | Bluetooth 6.0 |
| Auracast™ | Yes | Yes |
| JBL EasySing Mic Compatibility | Yes | Yes |
| JBL One App | Yes | Yes |

The PartyBox 330 and 130 push JBL deeper into the portable party speaker category with more power, upgraded drivers, Auracast support, mic and guitar inputs, splash resistance, replaceable batteries, and updated lightshows. The 330 adds more output and longer battery life, while the 130 offers a smaller, less expensive option that still keeps the core PartyBox feature set intact.
What’s missing? EasySing microphones are optional, not included, and neither model is pretending to replace a serious PA system. But for parties, outdoor gatherings, karaoke, casual performances, or buskers who need portable amplification without a complicated setup, the PartyBox 330 and 130 make a practical case at $629.95 and $449.95, respectively.
The JBL PartyBox 130 and 330 will be available for presale starting June 7, 2026. Shipping is expected to start on June 28, 2026.

Total Wireless, formerly known as Total by Verizon, is a prepaid, no-contract wireless provider with unlimited data covered by the Verizon 5G network. Total Wireless Total 5G Unlimited plan has unlimited data, talk, and text, along with a five-year price guarantee—meaning it won’t get jacked up after a trial period, guaranteeing you get unlimited data at a low price. Total Wireless has also introduced unlimited data on Verizon’s 5G Ultra Wideband network that promises to be up to 10 times faster than the median download speeds of other providers.
Whether you have to have the newest iPhone 17, or are more of an Android phone person, we wanted to highlight the best Total Wireless promo codes and discounts that will make anyone happy!
My phone bill is always way more expensive than I think it will be, and it doesn’t help that phone contracts can be confusing and difficult. Total Wireless makes it easy, with incentives like free items and price-lock discounts. Right now, you can get 50% off the Total 5G Unlimited plan when you bring your own phone (aka ‘Bring Your Own Device’). These plans start at as low as $20 per month, with taxes and fees included.
To get this Total Wireless promo code for 15% off, all you have to do is sign up for the Total Wireless newsletter and get 15% off on your first phone purchase. Plus, with the newsletter, you’ll get exclusive Total Wireless offers and promotions delivered to your inbox to save even more and get up-to-date on the latest drops.
Total Wireless wants to thank you for switching. Right now, you can get a free Galaxy A36 5G when you switch to a Total 5G or 5G+ unlimited plan. Or, you could choose to get up to 4 free Moto G Stylus 5G phones when you switch to the Total Base 5G Unlimited plan (or higher). They have tons of other promos going on too, so there’s something no matter your taste. Right now, if you switch, you’ll get up to $250 off select devices, including the iPhone 13 for $50 ($249 off), a free Samsung Galaxy, or a free Samsung Galaxy A25 5 (originally $180), and so much more.
Total Wireless also has a loyalty program; when your friend gives you a referral code to join, you’ll get a free month of service upon joining. Once you make the switch to Total Wireless and join Total Rewards, as long as you enter your friend’s code within 14 days of activation, you’ll both receive 5,000 points, which is enough for a $50 service plan.


Fin raised $250m in debt in March to help fund its AI agents and make 650 new hires.
Salesforce is purchasing Irish customer agent unicorn Fin for approximately $3.6bn, marking the latest in a series of acquisitions aimed at strengthening its enterprise AI capabilities.
Fin was founded as Intercom in 2011 by CEO Eoghan McCabe, chief strategy officer Des Traynor, chief engineer Ciaran Lee and David Barrett, who worked as a front-end developer at the company before departing in 2018. The company changed its name to Fin – after its AI customer agent platform – last month.
The company’s core offering is Fin, an AI service agent that resolves end-to-end customer queries across channels including live chats, email, WhatsApp, phone and Slack. The AI agent is powered by the company’s proprietary AI model called Apex, purpose-built for customer support.
The company said that it surpassed $400m in annual recurring revenue in March, with Fin alone set to reach the $100m revenue mark.
Fin’s wide-ranging customer base includes companies such as Anthropic, cloud company Snowflake and crypto prediction platform Polymarket. More than 30,000 companies use Fin’s products.
The acquisition comes a few months after Fin raised $250m in debt to help fund its AI agents. The company, at the time, said that it planned to make 650 new hires across offices in Dublin, London, Berlin, Sydney, Chicago and San Francisco this year.
“We’re thrilled to welcome Fin to Salesforce as we enable every company to become an agentic enterprise,” said Marc Benioff, the CEO and chair of Salesforce.
“Fin brings proven agent technology, a deep commitment to customer success, and an incredible AI team that will complement Agentforce with powerful service agent capabilities.”
Salesforce’s AI platform Agentforce grew 205pc, hitting $1.2bn in annual recurring revenue in its fiscal quarter ending in May. Fin’s AI package is expected to help Salesforce provide organisations with improved autonomous resolution and reduced cost-to-serve.
McCabe said that “this is a major win for consumers of the world”.
“Our technology has defined this category and set the new standards for what great customer service looks like today,” he said.
Salesforce announced its intention to acquire Berlin-founded digital experience platform Contentful earlier this month.
Last summer, the company acquired enterprise cloud data management business Informatica in an $8bn deal to integrate the tech into its AI platform Agentforce.
In October, it acquired automation platform Regrello, followed by Qualified, an agentic AI marketing solutions provider, this April.
Salesforce shares are up more than 1.5pc today (15 June), but overall has dropped around 35pc over the past year.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.

Every now and then a project comes into the Hackaday feed that has so many levels of wrong about it that you really shouldn’t do it at home, but is amusing enough to feature anyway with a warning. So it is with [ArcaEge]’s Capacitor Alarm Clock, which wakes up its unfortunate owner by blowing up electrolytic capacitors with reverse voltage. If you survive, you’ll certainly be awake!
It’s inspired unsurprisingly by an [ElectroBoom] video, and the premise is simple enough. An ESP32 serves as the clock, and triggers a relay for the alarm, which in turn overloads a suitably low-voltage electrolytic capacitor in a socket. The resulting explosion which appears in a video we’ve placed below the break, wakes the slumberer.
We don’t have to tell you that this is not the safest of hacks, and is presented here only for your entertainment. But it does provide a few points of interest, for example in identifying the difference between capacitors with a vent, and those without.
This isn’t the first time we’ve seen a project based around exploding capacitors, and that one maybe was a don’t-do-this-at-home too.




No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw


Oppenheimer backs SpaceX as $70 billion retail frenzy builds


Weekend Open Thread: Tuckernuck – Corporette.com

Markets Rally as SpaceX IPO Looms Amid Iran Tensions and Inflation Surge

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


The Ryan Gosling True Crime Thriller On Netflix That Gets Even Stranger, Stream It Now


NanoClaw integrates JFrog registries to secure AI agent downloads

Bangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News


Bitget enters Argentina’s regulated crypto market through PSAV registration


This Week In Security: Microsoft On Microsoft, Register Your Domains, Linux On ARM, And FreeBSD Joins The File Cache Club


El Nino has formed in the Pacific and could set records, forecasters say
Dutton Ranch star claims they ‘didn’t see any disruption’ on set following Chad Feehan’s exit from Yellowstone spinoff fueled by Taylor Sheridan clash rumors


Politics Home | Healey Resignation Is “Colossal Failure Of Government”, Says Former Labour Defence Secretary


Thailand Ranks Second Worldwide for AI Adoption Growth, Microsoft Reports


‘This is Seattle’s position on AI’: City Council votes unanimously to pause big new data centers

Donnie Wahlberg & More Heat Up Las Vegas at Circa’s Barry’s Downtown Prime

Opendoor Ends India Operations, Fueling a Bigger Conversation About AI and Outsourcing


First Time Since 1971: Australia Register Historic Low In ODI Cricket


Belfast burns, while Met chief points finger at Iran and Russia


FBI searches office of Ohio voter registration group





You must be logged in to post a comment Login