

Tech
Here’s why Slate changed the battery in its cheap EV truck

Slate, maker of the stripped-down EV pickup truck, found another way to simplify its product: the battery.
When the startup revealed its starting price on Wednesday — $24,950 before destination, taxes, and other fees — it also said it had changed its battery strategy, eliminating the optional 240-mile pack but bumping the standard pack from 150 miles to 205.
How Slate pulled that off illustrates just how significantly the battery market in the U.S. has changed in the past four years.
Initially, the startup planned to use nickel-manganese-cobalt (NMC) cells. The chemistry is widely used in the automotive industry and favored for its energy density, which translates into longer range. But NMC is also expensive, mostly due to high nickel and cobalt prices.
More recently, automakers have begun to use another chemistry, lithium-iron-phosphate (LFP). Battery packs that use LFP are less energy dense but cheaper by about 40%, thanks in part to lower-cost ingredients like iron, one of the main cathode materials, which replaces nickel and cobalt.
There were good reasons why Slate, and other automakers, started with NMC. The LFP supply chain today is today concentrated in China. That wasn’t always the case — early U.S. battery startup A123 Systems was founded to commercialize the technology. But after a few missteps, it fell into bankruptcy and was bought in 2013 by a Chinese auto parts company. Since then, Chinese battery companies have embraced the chemistry and dominated production of LFP cells.
LFP’s foreign origin meant that, before last summer, EVs that used it wouldn’t qualify for a $7,500 tax credit under the Inflation Reduction Act. Only batteries made of materials sourced domestically or from companies with which the U.S. had a free trade agreement would qualify. But when the One Big Beautiful Bill Act axed the tax credits, those concerns evaporated, as well. Chinese manufacturers were back in consideration. Slate said it is working with Hefei-based battery company Gotion to source the cells, which will be built at a factory in Illinois, according to InsideEVs.
The other reason automakers passed over LFP batteries was their limited range. Automakers selling into the U.S. market have prioritized range, though vehicles that can travel more than 300 miles on a charge tend to be pricey — pretty much the opposite of what Slate is going for.
In reality, most people don’t need that much range, and as charging networks have grown in size, reach, and speed, range anxiety is gradually waning. While LFP cells will never match NMC in energy density, modern variations of the chemistry have helped close the gap. Ford, GM, Rivian, and Tesla all offer models that use LFP cells.
The industry’s embrace of LFP cells has also coincided with its transition to cell-to-pack technology, which Slate is using to build its battery packs.
Previously, when automakers assembled a battery pack, they first loaded cells into modules, which were then loaded into the pack. That setup allowed them to use pouch cells, which are cheaper and lighter. But over time, they realized the module approach canceled out the cost and weight savings the pouch cells offered. Though some EVs still use modules, the industry is moving toward cell-to-pack construction, in which rigid batteries, either prismatic or cylindrical, are loaded directly into the pack itself.
Cell-to-pack trims manufacturing steps and boosts volumetric energy density, a helpful trait for a small EV like the Slate truck. Plus, LFP cells can be charged to 100% with fewer concerns about degradation than NMC, meaning drivers can use the full pack on a daily basis.
While there was probably a moment when Slate’s leadership had to green-light the switch from NMC to LFP, the momentum toward that decision had been building for years. LFP won’t take over the entire market — automakers like GM are betting on an entirely different chemistry — but its combination of low cost and decent range make LFP an obvious choice for what will be the cheapest EV in the U.S.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.



Security
CVE-2026-20230 under exploitation, while an earlier SD-WAN 0-day looks even worse than we thought
It’s looking like another tough week (month? year?) for Switchzilla amid reports of new serious vulnerabilities under attack.
First up is a server-side request forgery bug in its Unified Communications Manager tracked as CVE-2026-20230.
Cisco disclosed and patched this flaw in early June. The comms control platform doesn’t properly validate some HTTP requests, and an attacker could exploit this bug to gain root privileges on a compromised device.
At the time, Cisco said that a proof-of-concept exploit was available – and now it seems unknown miscreants are putting that exploit code to use, with threat intel company Defused warning that it observed miscreants exploiting CVE-2026-20230 over the weekend.
“The observed chain abuses the WebDialer SSRF to deploy a rogue Apache Axis service, uses that service to write a first-stage JSP file-writer, then drops a second-stage command-execution shell under /platform-services/axis2-web/,” the firm noted on LinkedIn.
Cisco Catalyst SD-WAN zero day
Then, a Mandiant advisory on Wednesday warned that a Cisco SD-WAN zero-day tracked as CVE-2026-20245 was exploited much earlier than initially disclosed, including at a communications service provider where the attacker elevated a compromised admin account to full root-level access.
While the Google-owned threat hunting biz said it can’t assess the full scope of the intruders’ post-compromise activity, this SD-WAN device compromise could have been dire, potentially giving the attacker total visibility across an entire corporation’s internet traffic. This is what makes SD-WAN zero-days such a hot target for government-sponsored spies looking to set up shop for long-term snooping activities.
It also explains the rash of attackers battering Cisco SD-WAN devices since the start of the year.
Cisco had issued an advisory for CVE-2026-20245 in early June, admitting that attackers had a head start on abusing this security hole. “In June 2026, the Cisco PSIRT became aware of exploitation of this vulnerability,” the vendor said at the time.
In a Wednesday report, however, Google’s Mandiant incident response and consulting biz reported that exploitation of this bug – Cisco’s sixth SD-WAN vulnerability listed as under attack since the start of the year, and the second zero-day in two months – began much earlier.
“In early 2026, Mandiant identified a threat actor targeting SD-WAN infrastructure at a service provider,” Mandiant threat hunters Chester Sng, Pete Boonyakarn, and Logeswaran Nadarajan wrote. “After gaining initial access, the threat actor exploited a zero-day vulnerability (CVE-2026-20245) in Cisco Catalyst SD-WAN to escalate privileges from a compromised administrative account to root-level access.”
The attacker gained initial access via an unauthorized peering connection, abusing the SD-WAN fabric to authenticate between network components and facilitate Secure Shell (SSH) access. In this case, they authenticated to the SD-WAN manager device via SSH using the vmanage-admin account on the same victim devices.
Then, they changed the default password on the admin account, authenticated directly to the SD-WAN Manager web application interface using the admin account, and exfiltrated SD-WAN fabric configurations.
Likely in an effort to cover their tracks and not get caught, the attacker changed the password of the admin account back to its original one before terminating their active session.
Neither the vmanage-admin nor the admin accounts on Cisco Catalyst SD-WAN controllers possess root shell access, however. To gain root access, the attacker exploited CVE-2026-20245, which allows an authenticated, local attacker to execute arbitrary commands as root by supplying a crafted file to the vulnerable system.
The attacker uploaded a file named evil_tenant.csv that contained the exploit payload. Upon execution, the digital intruder created a user account named troot with full root privileges. Mandiant says it later observed the miscreant accessing this new troot account from the admin account using the substitute user command.
The Register reached out to Cisco about the reported exploitation of CVE-2026-20230, and Mandiant’s investigation into CVE-2026-20245. The company pointed us to its June advisory on the latter matter, and is working on response to our first question. ®

Dutch Trade Minister Sjoerd Sjoerdsma visited Washington this week to meet with Commerce Secretary Howard Lutnick and members of Congress to oppose the MATCH Act, a bill that would bar Chinese chipmakers from accessing Western semiconductor equipment, and one that would hit ASML especially hard.
ASML, based in the Netherlands, is Europe’s most valuable company and the only maker in the world of the sophisticated lithography machines that are used to make cutting-edge AI chips.
“It’s exceptional that I’m coming here to broadly outline our concerns to Congress,” Sjoerdsma told Bloomberg after the meetings. “The stakes for the Netherlands may be very high.”
China accounts for 19% of ASML’s net system sales. The MATCH Act would go further than existing controls, extending curbs to ASML’s deep ultraviolet immersion machines on top of the long-standing ban on its most advanced extreme ultraviolet, or EUV, tools reaching China.
As ASML CEO Christophe Fouquet told TechCrunch in May, what China can currently buy are older-generation deep ultraviolet tools — gear first shipped about a decade ago — the same machines the MATCH Act would now relegate off limits.
The bill, introduced in April, hasn’t yet faced a full House or Senate vote; Bloomberg notes it would likely need to be folded into a larger package to pass.
I have had big ideas before. Ideas that felt urgent and important at 11 p.m. and somehow evaporated by morning. So, when the idea for creating an AI-powered reading recommendation system to generate student excitement about our school’s library catalog came to me, I asked my partner what she thought about me giving up evenings and weekends for a year or two. “Just go for it,” she said.
That conversation was in May 2025. By November, my vibe-coded app was live in my classroom.
Why I Started Vibe Coding
I’m a U.K.-trained primary school teacher with 11 years of experience in international schools across the Middle East and Southeast Asia. Over the years, I have seen librarians carefully curate books only to have them sit untouched on library shelves. This is because there was no systematic way to connect each child to the book most likely to excite them.
Existing solutions were expensive, rigid, and built around proprietary book lists that didn’t match our collection. The more I looked at what was available, the more I realized the problem wasn’t that the technology didn’t exist — it was that nobody had built it for teachers like me, working in schools like mine.
So, I decided to build one myself, using an AI technique that I had read about with increasing interest: vibe coding.
Learning to Build an App
Vibe coding is a practice where people use AI tools to generate software code by describing what they want in plain language to the tool, with little to no traditional programming knowledge required. So, I started vibe coding and telling a large language model what I was trying to build.
Progress was painfully slow — a day forward, three days back. Over the summer months I nearly quit several times. The early architecture decisions haunted me: I was working on a 12-year-old Mac I hadn’t upgraded, and just getting the right development environment installed felt like a full-time job. The worst moment came when several files of code were deleted with no backup. Hours of work, gone. I sat staring at the screen for a long time.
One of the most painstaking phases involved book cover images — I wanted to display covers for our library’s 10,000 books using freely available API calls, without scraping the information, to stay on the right side of copyright laws. Writing the code for this was exhausting. When it finally worked imperfectly, I built a separate page to manually evaluate every cover — AI searching for the ones that hadn’t loaded correctly. That process took weeks. Then the page itself failed completely, and I had to start from scratch.
Switching from Copilot to Claude made a significant difference. It was still prone to errors and loops that would, as I put it to colleagues, drive me absolutely crazy. But it was more reliable than what I’d had before.
What strikes me now is how much has changed — what took me days and weeks in late 2025, I can now accomplish in hours. The rate of improvement in LLMs is frankly frightening.
How It Works
If you’re interested in building a similar tool, the steps are simple: A teacher uploads their school’s library catalog as a CSV file — no re-cataloging required. The teacher then creates student profiles and runs a short reading assessment to gauge their reading level and interests. The AI analyzes the catalog against each student’s reading level, interests, favorite authors and curriculum topics, and generates a personalized reading list from the books already on the shelves.
Student profiles include name, reading age, reading interests, favorite authors, preferred genres, and current class topic. These profiles power the AI recommendations. Progress data includes books read, reviews written, points earned, and comprehension quiz scores. Student profiles and progress data are only visible to their class teacher and school librarian — not to other students.
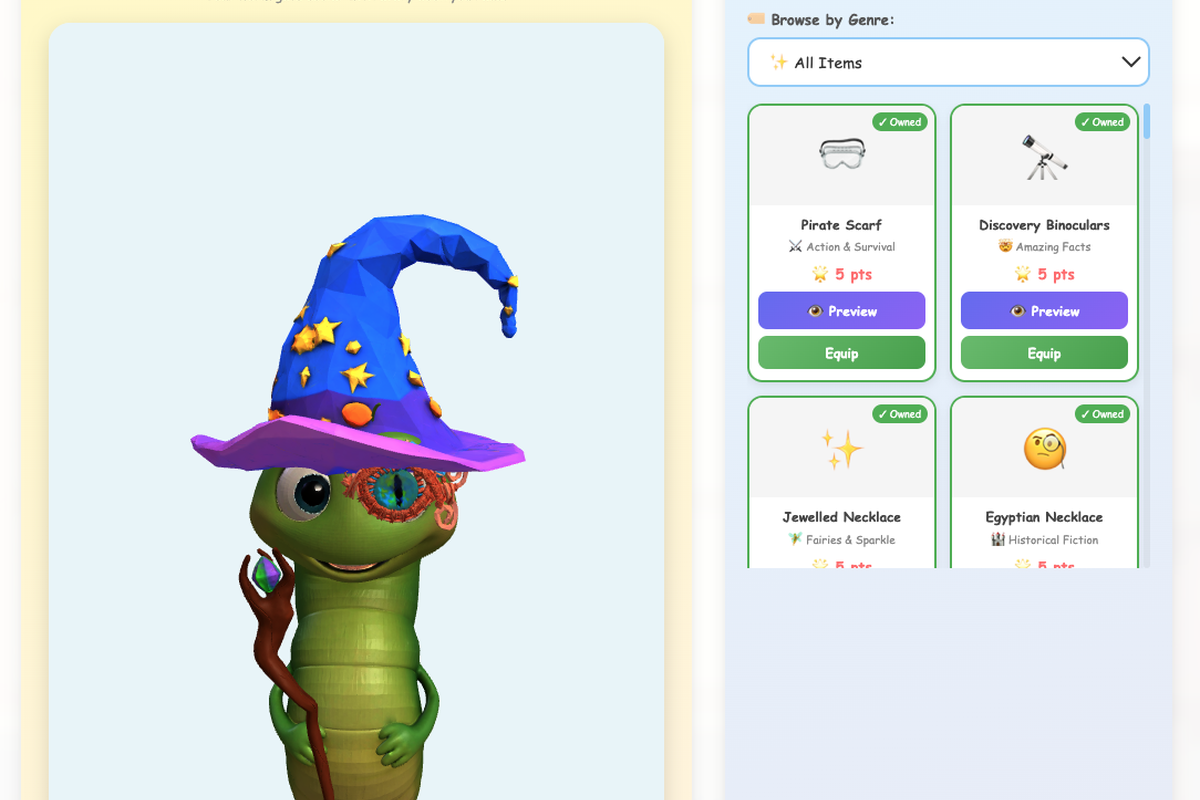
When students log in, they see their recommendations — typically 50 books ranked by how well the books match their profile. Students can mark books as “reading,” “finished,” or “want to read.” When they finish a book, they write a teacher-verified review and answer AI-generated reading comprehension questions. Correct answers earn genre-specific points which unlock accessories for their animated worm companion — one accessory category per genre across 21 genres, so reading widely is rewarded, not just reading a lot. Student reviews are fed back into the recommendation engine — so a hidden gem that one child discovers becomes visible to the whole school community over time.
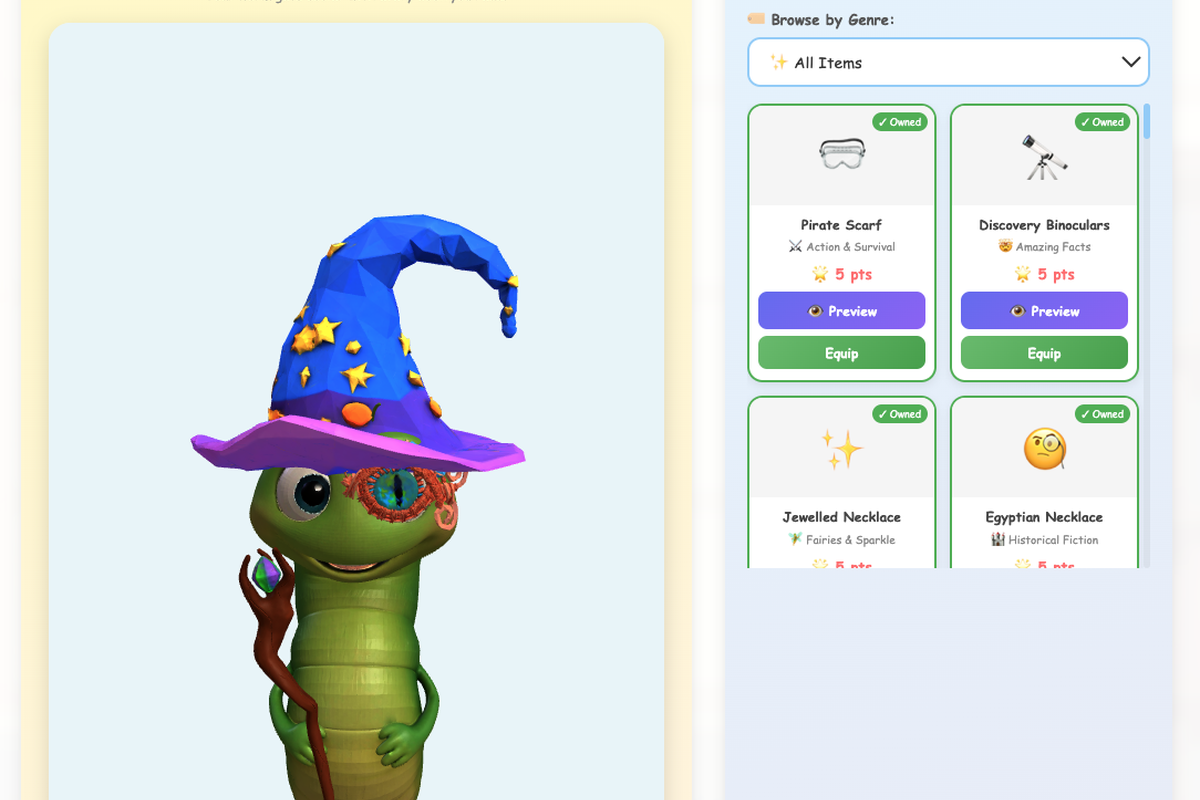
A LibraryAid Recommendation Worm
Credit: David Webb
The recommendation engine in the app draws on a “master books” list I built from more than 1,000 award-winning and highly rated children’s titles across various categories. It’s not just matching reading levels — it’s actively surfacing books that most children would never stumble upon independently.
Student Book Recommendations
Credit: David Webb
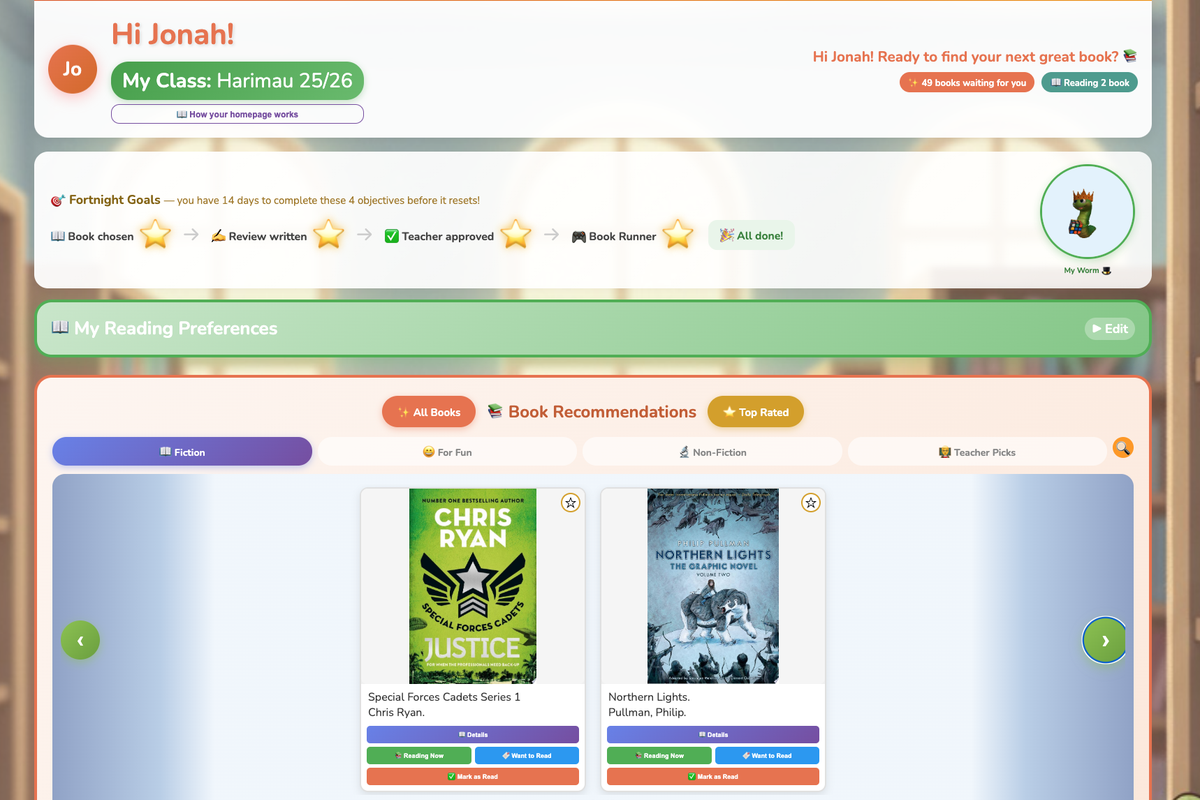
Sometimes a recommendation worked because it was an award-winning book the child had never heard of. Sometimes it was simply a genre they hadn’t tried before but which sat under a topic they’d listed as an interest — opening their eyes to a new corner of the library. Other times it was a natural next step: a similar author, a continuation of a series, a book that built on something they’d already loved and rated.
For data protection, LibraryAid is COPPA and GDPR compliant. Student data is stored securely in Google Firebase. No student email addresses are collected — students log in via a school-issued code and PIN, with no personal email required. Data is never sold or shared with third parties.
Positive Feedback From Colleagues and Family
Early on I told a colleague what I was trying to do. What she said, and the sincerity with which she said it, gave me more confidence than any tutorial or documentation. She said she genuinely believed I could make it work, and that I should not give up. Feedback from other teachers proved equally invaluable. It was frank and occasionally humbling. So far, one colleague has integrated the app into her class and found it very useful.
My 12-year-old son, however, became perhaps my most enthusiastic supporter. He spent considerable time testing the system, told his own school about it and, in what felt like a distinctly contemporary parenting moment, told me he’d asked an LLM whether LibraryAid had a high chance of being successful and it responded with an enthusiastic “yes.”
What My Students Thought
When my tool went live with my students, something shifted in them. Children who had been unenthused about the library before suddenly became excited to explore it. Finding their recommended book became a treasure hunt. Students began venturing into new series and authors they would never have chosen independently.
One student, an English learner reading approximately two grade levels below his current placement, made 3x the average reading progress of his classmates once he was matched to books that genuinely interested him at the right level. The technology didn’t fix his reading struggles, but it connected him to books worth the effort of reading.
I also read aloud to my class, ending the school year with “Swimming Against the Storm” by Jess Butterworth, which has a strong environmental theme. The impact of reading that book last year was striking: suddenly the majority of the class was searching the app for adventure stories with a similar feel. That moment reinforced something I believe deeply about the app — it works best alongside human influence, not instead of it. The app surfaces the right books for students, but the teacher or librarian sparks the interest.
What Vibe Coding Taught Me
Debugging code and diagnosing why a student isn’t understanding a concept require surprisingly similar thinking. For both, you need to be systematic, patient, and hypothesis-driven. Writing algorithms that adapt to different reading patterns made me think more clearly about differentiation. And spending months building something that real children would use every day gave me clarity into why so much edtech misses the mark. At least in my own experience, most education technology is built for administrators, not teachers. It optimizes for reporting and data dashboards rather than the daily reality of 30 children with 30 different relationships with reading. The products that work are the ones built by people who have stood in a classroom and felt the gap between what exists and what’s needed.
Although my tool surfaces an array of enticing books for children, there is no guarantee the recommendations will inspire them to take action. I remember a moment I had with one child this term, who showed me her curated list with a lost expression and eyes that were pleading for guidance. Her list had hidden gems and well-known classics, all with appealing covers — some in her comfort zone and some designed to stretch her thinking. However, the only one that interested her was a familiar series she already knew. The algorithm had done its job. What she needed next was a conversation with a trusted adult.
There isn’t a recommendation engine in the world that can replace the moment a child says, “I’m not sure about any of these,” and looks to their teacher or librarian for a nudge. The trust a child has for the person standing in front of them can’t be coded.
My advice to any educator considering building their own edtech tool: build something that extends what teachers do rather than replaces what they do. The technology should handle the matching but let the children’s learning guides handle the moment.
LibraryAid has turned out to be the most useful thing I have ever built, perhaps even eclipsing some of my lessons.


The Apple Watch Series 11 [GPS 42mm], priced at $279 for Prime Day (was $399), retains the same slim profile, while the always-on screen is clear even in direct sunlight. The battery now lasts nearly two full days on a single charge, allowing for less time plugged in and more time on the wrist, where it should be. Health tracking runs silently in the background and sends useful signals such as irregular beats or blood pressure changes without requiring any additional steps or complicated configuration. When paired with an iPhone, the watch handles calls, messages, and apps with ease, and the 5G option keeps everything responsive even when the phone is in a bag or another room.
5. Meta Quest 3S 128GB Gorilla Tag Bundle – $349.99 $296.79
Meta’s Quest 3S slips on easily and transports you immediately into virtual worlds without the use of wires or additional gear. The integrated Gorilla Tag experience transforms you into a nimble gorilla swinging from tree to tree and tagging teammates in fast-paced multiplayer battles that get your full body moving in a way that feels more like play than exercise. The full-color passthrough keeps the real room visible, allowing you to keep track of furniture and space while the virtual activity takes place around it. A three-month trial of other games, as well as exclusive in-game items and currency for Gorilla Tag, ensures that there is enough to discover straight away. Product page.
4. Ninja CREAMi 7-in-1 Ice Cream Maker – $219.99 $169.99
Ninja’s CREAMi 7-in-1 converts a simple overnight freeze into fresh homemade ice cream or sorbet in just a few minutes of processing after the base has set. You combine whatever ingredients seem appealing, such as milk and sugar for classic flavors, protein powder for a lighter treat, or fruit for a dairy-free option, pour them into the pint, freeze, and then insert the container into the machine and pick the desired setting. The powerful blades cut through the frozen block, changing it into a smooth, scoopable texture. A separate mix-in cycle allows you to fold in cookies, candy, or nuts at the end, retaining their delightful texture rather than blending into the foundation. Product page.
3. Elgato Stream Deck+ – $179.99 $141.99
Elgato’s Stream Deck+ stands on your desk like a little command center, with eight LED buttons that identify their function and four smooth-turning knobs that allow precise control over whatever you assign them. A single button press can change camera angles during a stream, start or stop a recording, mute the microphone, or launch any software without the need to explore menus or recall complex key combinations. The dials allow you to easily increase or decrease volume, explore a video timeline, and change settings in small increments, while the touch strip above them allows you to swipe through additional menu pages when you need more options. Everything is linked using simple software that allows you to drag and drop operations onto the buttons and knobs, ensuring that the entire layout matches your personal workflow. Product page.
2. Roborock Q10 S5+ Robot Vacuum and Mop – $564.99 $264.99
Roborock’s Q10 S5+ moves across floors according to its own schedule and returns to its port to empty its own dustbin, letting you to go weeks without touching the machine. The powerful suction takes pet hair and ground-in filth from carpets, while the vibrating mop removes ordinary spills and footprints from hard floors, automatically lifting itself when it detects carpet to ensure nothing gets wet where it shouldn’t. Smart mapping allows it to remember your home’s layout after the first run and thereafter clean only the rooms you designate or skip portions you indicate in the app. Dual tangle-resistant brushes keep things moving smoothly even in homes with long hair or shedding dogs, and the entire operation is quiet enough to be used while you are at home. formerly everything is set up the first time, the robot will simply keep the floors clean day after day with very little effort from you, transforming what was formerly a weekly duty into something that happens automatically. Product page.
1. Anker SOLIX S2000 Portable Power Station – $1,199 $599
The Anker SOLIX S2000 rests in a corner or closet and offers consistent power to a fridge, lights, or small appliances when the lights go out, allowing everything to run smoothly for hours or perhaps a complete day, depending on what you plug in. The efficient design consumes relatively little power on its own, so stored energy lasts longer than you may expect, and the long-life LFP battery cells allow for thousands of charges over many years without losing capacity. Five common wall plugs make it simple to connect daily gadgets without the need for adapters, and a quick recharge from a wall socket restores it to full power in less than two hours when needed again. App monitoring allows you to check the remaining runtime from your phone, while the complete unit remains small and portable enough to be transferred as needed. Product page.
Tech
Your enterprise AI agents should automatically remember which model is right for which task. Mindstone built the capability with Rebel


AI agent orchestration platforms are popping up like weeds these days, but London-based AI transformation startup Mindstone’s Rebel might be among the most promising I’ve come across.
That’s because the system, which officially launched this week, is a local-first, agentic AI operating system distributed under a “Fair Source” license, allowing teams of under 100 users to freely adopt and customize it to suit their needs, while those organizations with more users will require paying for an enterprise license.
The marquee features are its simplicity and extensive customizability to fit any given team, no matter how unique or specific the workflows, all based around the common, open source standard file format markdown, and, as a result, an organizational memory layer that ensures agents reliably use the enterprise’s preferred AI models for each given task or even subtasks — dynamically switching between local and cloud ones in a predictable, visible way to save costs and maintain data privacy and security as needed.
“Shared memory is the most empowering thing you could possibly do with a knowledge-worker AI,” said Greg Detre, chief technology officer (CTO) of Mindstone, in a recent video call interview with VentureBeat. “You get this feeling of being a super-organism as a company that just gets smarter and smarter.”
Rebel is available now for macOS on Intel and Apple Silicon machines, as well as Windows, with Linux support in development.
Mindstone has raised $5 million from private investors including Pearson Ventures, Moonfire Ventures and Zanichelli Venture.
A distinctive, local-first architecture based on markdown files
What makes Rebel distinctive is its local-first architecture.
Instead of the approach found in developer-heavy agent frameworks such as as LangGraph, CrewAI and AutoGPT, which require teams to wire together databases, cloud infrastructure and state-management logic, Rebel’s core agent memory and instructions live across local markdown (.md) text files — arguably the simplest, easiest, and most popular way to steer AI agents, one that has been widely adopted by AI developers and power users around the globe.
Mindstone says Rebel stores its state, prompts, task instructions and memory hierarchy in these files, allowing users and companies to easily inspect, move or modify them as needed. A primary configuration file, agents.md, acts as the agent’s core instruction layer and runtime boundary.
That architectural choice is partly about cost. Mindstone argues that common office formats such as Word documents and PDFs often carry formatting and metadata overhead that consumes model token context and raises API costs. Markdown keeps the information closer to raw text, allowing more of the model’s context window to be spent on the actual task rather than document structure.
The company also positions the approach as a hedge against vendor lock-in. If a company’s agent instructions, automations and memory are stored locally as text files, they are not trapped inside one SaaS provider’s interface or database. That matters more as enterprises begin giving AI systems broader access to email, calendars, documents and internal workflows.
Rebel also lets users create repeatable AI workflows. “Skills” are saved multi-step procedures an agent can reuse. “Operators” adjust how the agent behaves for a given task, such as reviewing a pitch deck from an investor’s perspective or evaluating work through a security lens. “Automations” can run scheduled background tasks, such as scanning messages or files, finding relevant updates, drafting responses, or preparing work before an employee opens the app.
Automatically selecting the best, enterprise-preferred AI model for every task (and subtask)
Another important feature is multi-model orchestration. Rebel can break a task into parts and route different steps to different models, including splitting between local and cloud-based ones depending on the sensitivity of the information or as guided by enterprise policies.
A more powerful model can handle planning or complex reasoning; a cheaper model can handle routine work; a local model can handle sensitive steps or approval checks. This matters for enterprises that want flexibility or are seeking cost controls: not every task need be sent to the same expensive cloud model, and some enterprise workflows prohibit sensitive corporate data leaving local infrastructure.
“I want to be able to say, ‘Help me with this,’ and it knows what’s personal, what’s sensitive, and what can be shared with the whole company,” Detre explained.
That model-agnostic setup gives companies more control over cost and security. Data-heavy work can run on lower-cost models such as Llama or DeepSeek. Higher-level reasoning can be reserved for more expensive models. Sensitive work can be routed through a local model running on the user’s machine, keeping that information from leaving the device.
This approach also gives enterprise teams a way to mix cloud and local inference without treating the choice as all-or-nothing.
By shifting away from centralized, monolithic cloud interfaces toward a local file-driven architecture, Mindstone is introducing a model for how enterprise technical decision-makers orchestrate autonomous workflows without forfeiting data sovereignty or predictability
How it works in practice
Mindstone CTO Greg Detre designed Rebel’s memory system to avoid a common problem in enterprise AI: dumping large amounts of company information into a database and hoping search will retrieve the right context later.
Instead, Rebel uses a tiered memory structure. When an interaction happens, the system estimates how likely that information is to be useful again.
Information with a high expected value is written into a local readme.md file tied to a specific project space. Information with a moderate expected value becomes a reference link back to deeper historical records.
Lower-priority material is stored in an indexed memory directory, where it remains available but dormant until a relevant task calls it back.
An ROI dashboard for enterprise buyers
For larger organizations, Mindstone Pro adds an Impact Dashboard designed to show where Rebel is saving time and money across business units.
Mindstone says the dashboard uses a separate, closed LLM to evaluate telemetry and calculate business impact. The company says the system is calibrated conservatively, using the lower end of estimated performance gains to avoid inflated productivity claims.
That feature speaks to a practical problem for enterprise AI buyers: proving value without over-surveilling employees. Mindstone says the dashboard is isolated from individual workspaces, allowing IT and business leaders to evaluate adoption and return on investment without reading employees’ private agent activity.
Fair Source licensing aims to reduce platform risk
Mindstone is releasing Rebel under a Fair Source license, a model meant to sit between fully closed SaaS and permissive open source.
Under the license, Rebel’s code is viewable, auditable, modifiable and deployable. Individuals and organizations with up to 100 concurrent users can run it for free. Once an organization exceeds that threshold, it needs a commercial Mindstone Pro license.
The license also includes a two-year sunset clause. Twenty-four months after a given version is released, that version automatically converts to the MIT open-source license.
For enterprise buyers, the practical pitch is that Rebel reduces the risk of being trapped. If every automation, memory file and agent instruction is stored locally in markdown, a company can move its data and workflows elsewhere if needed. The product may be commercial, but the underlying work is designed to remain inspectable and portable.
Security questions focus on local approvals and shared memory
Rebel’s debut on the open access tech product sharing platform Product Hunt this week prompted technical questions about how a local-first agent should handle permissions, safety checks and shared memory.
One developer, Nikita Pokryschko, asked whether approval checks for sensitive actions could run entirely on a local model, or whether the gating logic still required a cloud call.
Detre responded by explaining Rebel’s separation between planning, execution and background safety logic. Wöhle added that companies can configure Rebel to rely entirely on a local model for gating decisions.
That distinction matters for corporate security teams. Autonomous agents often need broad permissions to read files, draft emails or interact with internal systems. If the final approval layer depends on an external cloud model, some companies may see that as a compliance risk. Mindstone is arguing that Rebel can keep those approval boundaries local.
A second discussion focused on how Rebel decides what memory can be shared. Product developer Clement Morel asked whether shareability is determined by content, user settings or learned behavior, and what happens if the system gets it wrong.
Detre said Rebel uses the user’s local “Chief-of-staff README” and defined spaces to separate private, team and company-wide information. When the agent encounters ambiguous context, the system pauses and asks the user for approval before proceeding.
That emphasis on visibility is part of Mindstone’s broader argument against opaque agent systems. As CEO Joshua Wöhle put it in a post on his LinkedIn account: “If an agent is going to sit inside your workspace, remember your context, and ask permission before changing the world, you should be able to see how it works. Not because everyone will read the code, but because someone can.”
Mindstone points to customer rollout as early proof
Mindstone says Rebel has already been deployed across the 250-person workforce of customer Epignosis, covering sales, engineering, product, finance and customer success teams.
“The entire organization is operating on Rebel today,” Wöhle told VentureBeat.
Over a 12-week deployment, Mindstone says Epignosis recaptured the equivalent capacity of eight full-time roles. The company says adoption spread organically after employees saw colleagues automate time-consuming work, a pattern employees reportedly called the “potatoes effect.”
The Epignosis case is central to Mindstone’s argument that enterprise AI should not be treated as a set of isolated personal tools. Rebel’s shared-memory design is meant to let workflows move across teams and improve as more employees use them.
“The border between learning and doing is fading out – and that changes everything about how you scale,” Epignosis CEO Dimitris Tsingos said in a statement provided to VentureBeat by Mindstone.
Background on Mindstone
Mindstone Learning Limited, headquartered in London, launched in 2020 under the direction of CEO Joshua Wöhle, previously a co-founder of the digital child safety firm SuperAwesome. Originally positioned in the consumer education technology market, the company built a digital curation tool likened to a “Spotify for learning” that utilized compound learning methodologies.
However, following the widespread commercialization of generative artificial intelligence platforms between 2022 and 2024, Mindstone moved into business-to-business enterprise enablement. Leadership identified a critical “last-mile” barrier: while AI tools promised substantial productivity gains, traditional corporate training failed to equip the workforce to practically integrate them into daily operations.
Today, Mindstone functions as a comprehensive enterprise software and training ecosystem designed to maximize corporate return on investment for existing AI licenses. The product architecture systematically addresses different organizational tiers through highly contextualized, “live-fire” software applications rather than abstract slide presentations.
Financially, Mindstone utilizes a hybrid capitalization strategy that interweaves institutional venture capital from entities like Moonfire Ventures and Pearson Ventures with community-based equity crowdfunding on platforms such as Seedrs and Crowdcube.
Mindstone has successfully penetrated the enterprise market, securing commercial contracts with blue-chip corporations including The Home Depot, Hyatt Hotels Corporation, Pearson, and Ernst & Young.
Ultimately, Mindstone positions itself as the crucial antidote to corporate inertia, ensuring organizations establish the internal competency required to execute successful AI transformations.
Mindstone’s bet: enterprise AI needs shared memory, not more seats
Rebel arrives as companies are trying to move from AI experimentation to AI operations. The first wave of enterprise adoption centered on access: giving employees chatbots, copilots and model subscriptions. Mindstone is betting the next wave will center on coordination.
That means shared memory, reusable workflows, local control, flexible model routing and measurable business impact. It also means giving enterprises a way to inspect the systems they are being asked to trust.
The company’s challenge now is execution. Local-first software can be harder to manage than cloud SaaS. Shared memory raises governance questions. Multi-model routing adds complexity. And enterprises will still need proof that agentic workflows can deliver reliable productivity gains without creating security or compliance headaches.
But Mindstone is making a clear argument: buying AI seats is not the same as building AI infrastructure. Rebel is its attempt to turn scattered employee experiments into an operating layer for work.


Devops
93% of organizations report infrastructure incidents attributable to AI
AI vendors have been pushing organizations to board the AI hype train as it races by at full speed. But many of the companies doing so, unable to move quite that fast, have stumbled along the way.
According to a survey of 406 IT decision makers, 93 percent of organizations have experienced AI-caused infrastructure incidents, but a mere 19 percent had the necessary governance to respond.
The survey, conducted in April by Panterra Group at the behest of Spacelift, forms the basis of the orchestration platform’s 2026 State of Infrastructure Automation report [PDF]. It posits an “AI Readiness Gap,” meaning that companies are adopting AI before they’re ready to do so and are paying the price.
“The findings are unambiguous: organizations are using AI to generate infrastructure code at a rate their governance frameworks were never designed to handle,” said Paweł Hytry, co-founder and CEO of Spacelift, in a statement.
The consequences of these incidents, respondents say, consist of reworking AI-generated changes (37 percent), security misconfigurations that reached production (36 percent), compliance violations (36 percent), infrastructure drift attributable to AI changes (35 percent), and incidents caused by agentic systems (33 percent).
The report characterizes 24 percent of organizations as “exposed.”
“Exposed organizations are using AI, but without the governance or frameworks to support it safely,” the report says. “What they are doing diverges significantly from what they have in place to manage it.”
And then there are the “fragmented” entities, 32 percent of respondents, that use AI sometimes, unevenly, and have some governance, but no coherent plan.
The two remaining categories, “outpacing” and “pioneer,” at 25 percent and 19 percent respectively, describe heavy AI adoption that’s ahead of business controls, and AI use in conjunction with structural discipline, respectively.
In terms of AI-caused infrastructure incidents, 97 percent of “exposed” organizations reported at least one such snafu. Meanwhile, among “pioneer” entities, 17 percent said they had no AI-related infrastructure incidents.
Spacelift, an infrastructure-as-code (IaC) platform, contends that automated validation accounts for the difference here because it outperforms manual code review.
Across the board, respondents report greater use of AI for generating code – 82 percent say between 25 percent and 74 percent of their code was created with help from AI.
This has a downstream effect on the infrastructure teams that deploy said code: 40 percent of respondents say security vulnerabilities are showing up more frequently, 40 percent say governance has become more challenging, 37 percent cited higher change volume, 35 percent see strains on the development pipeline, and 35 percent report infrastructure drift.
Spacelift’s report calls out the cognitive dissonance – a blameless formulation of “self-delusion” – among organizations adopting AI: 86 percent say they can govern it, while only 30 percent actually have a formal AI governance policy in place.
The report advises organizations to start paying attention to AI-oriented metrics that few organizations bother to track, specifically the volume of AI-generated IaC in deployment pipelines, error rates due to AI-generated changes, and infrastructure drift attributable to AI changes.
It also stumps for greater automation through IaC, for building governance to cover that automation, getting AI-generated code into governed IaC orchestration workflows, and planning for the governance of AI agents. ®

Rockstar Games has officially revealed more information about GTA 6, one of the most anticipated games of the decade. With a confirmed release date, new protagonists, and a return to a familiar location, excitement continues to build among fans eager to explore the next Grand Theft Auto adventure. After several delays, GTA 6 now has an official release date. Rockstar plans to launch the game on November 19, 2026. The studio said it needed additional time to refine the game and meet player expectations. Pre-orders will open on June 25.
GTA 6 Story and Price
GTA 6 introduces Lucia, the first playable female protagonist in a 3D Grand Theft Auto game. Players will also take control of Jason, her partner in crime. The story follows the duo as they navigate a dangerous criminal world together. Early trailers suggest a Bonnie-and-Clyde-inspired adventure filled with robberies, chases, and high-stakes situations. The plot kicks off when an easy score fails, pulling the pair into bigger challenges.
Rockstar has not officially announced the price of GTA 6 yet. Fans will likely learn more when pre-orders open on June 25. Some analysts believe GTA 6 could be one of the most expensive major game releases to date. Reports have suggested a price of around $100, but Rockstar has not confirmed those claims.
Exploring Leonida and Vice City

Players will explore Leonida in GTA 6, a new state based on Florida. Apart from this, another iconic location making a comeback in GTA 6 is Vice City. Inspiration for Vice City comes from Miami. Vice City offers players a lively environment thanks to its entertainment and nightlife. The map includes various places, such as beaches and wildlife areas. Rockstar’s artistry captures the environment even better because of features like flamingos and alligators.
Why has it taken so long to develop?
There has been a lot of discussion about why it is taking so long to come out. Rockstar released GTA 5 in 2013 and then spent several years developing Red Dead Redemption 2 afterward. Officially, development of GTA 6 began in 2022, but it must have started earlier. The modern game needs more people, more technology, and more time to be made.
The reasons behind the hype for this game are many. Grand Theft Auto is one of the biggest franchises ever made in the video game industry. Fans are excited about meeting new characters and a different storyline. Rockstar Games is also expected to deliver an improved version, both graphically and in terms of gameplay. The return of Vice City has added even more anticipation among longtime GTA fans.
Platforms Available for GTA 6
Rockstar has revealed that GTA 6 will launch on PlayStation 5 and Xbox Series X and S. These platforms will be the first to experience the next chapter in the Grand Theft Auto series. The developer has not yet discussed a PC version, leaving many players waiting for more information. There is also no official confirmation regarding a Nintendo Switch 2 release. Fans will have to watch for future announcements from Rockstar.
Tech
Stanford researchers will discuss their agentic ‘scientists’ that are on course to reshape drug discovery at VB Transform 2026


Drug discovery is notoriously inefficient. Pharmaceutical projects span years, moving from one specialized human team to the next through disconnected workflows that result in knowledge loss during each handoff.
A shocking 90% to 95% of drug discovery projects reportedly fail — one of the highest failure rates of any industry. A single successful drug can take over a dozen years and up to $1 billion from initial discovery to patient distribution, according to published reports.
Generative AI is being used to solve some of the challenges, but Stanford researchers have moved the ball forward with agentic AI.
A team led by James Zou, associate professor of Biomedical Data Science at Stanford University, has deployed thousands autonomous AI “scientist” agents in a virtual biotech that simulates the full lifecycle of drug development. The agents handle everything from initial discovery through safety testing and clinical trial design, while maintaining the continuity that’s lacking in today’s drug discovery processes, according to Zou.
The project uses a hierarchical orchestration framework. At the top sits a chief scientist officer agent that acts as a planner, delegating tasks to teams of specialized agents, Zou told VentureBeat during a call ahead of his upcoming session at VB Transform 2026.
While one team of agents focuses on discovery, another manages safety, and others handle specialized analytical tasks. Because these agents operate within a unified, hierarchical ecosystem, they retain the full context of a project, maintaining continuity from the first molecule identified to the final clinical outcome.
The “brain” of the system relies on a vast amount of primary data. The agents are granted access to data sources ranging from genomics and FDA chemistry data to clinical trial databases using a model context protocol.
The team has invested heavily in agent-native and agent-friendly data, allowing the AI to synthesize complex information more effectively. The system relies on a combination of models, with Zou noting that while Claude often serves as the backbone for coding and data analysis, the architecture employs a mixture of models, including those fine-tuned specialized use cases.
Zou is raising money at a roughly $1 billion valuation for his startup, Human Intelligence, based on the research.
During Zou’s session at VB Transform on July 15, titled How 10,000 agentic scientists in Stanford’s lab are set to revolutionize medical research and discovery, he will share valuable insights including strategies for managing context and long-running, multi-step workflows in a multi-agent system, the process of transforming and indexing raw enterprise data to make it agent native, and how to use human auditing and experimental reward signals to verify agent actions.
Another session at VB Transform focused on the value of agentic context includes Building a trustworthy agentic AI foundation: How Zillow accelerated engineering by 40%, with Zillow’s SVP of engineering and technology, Toby Roberts and Glean’s CEO Arvind Jain.
Interested in attending VB Transform 2026? Register here. A select number of complimentary passes are also available to senior technology leaders. Contact us to get yours.
Mistral AI on Tuesday released OCR 4, a document intelligence model that moves beyond raw text extraction to return structured representations of entire documents — complete with bounding boxes, block-type classification, and per-word confidence scores. The release marks Mistral’s fourth generation of optical character recognition technology in roughly 15 months and lands at a moment when the company’s pitch for European AI sovereignty has never been more commercially relevant.
The model supports 170 languages across 10 language groups, accepts PDF, DOC, PPT, and OpenDocument formats, and can be deployed as a single container on an organization’s own infrastructure — a capability Mistral is positioning directly at enterprises in regulated industries that cannot route sensitive documents through U.S.-jurisdiction cloud APIs.
“Mistral OCR 4 extracts and structures content from a wide range of documents,” the company said in its announcement. “Where previous generations focused on converting a page into clean text and tables, OCR 4 returns a structured representation of the document.”
The model is available immediately through the Mistral API, Document AI in Mistral Studio, Amazon SageMaker, and Microsoft Foundry, with Snowflake Parse Document support coming soon. Pricing starts at $4 per 1,000 pages, dropping to $2 per 1,000 pages through a batch API discount.
OCR 4 treats every document as a semantic map, not a wall of text
The central engineering shift in OCR 4 is structural. Rather than outputting a flat stream of extracted text — the paradigm that has defined OCR for decades — the model returns a layered representation in which every block is localized with a bounding box, classified by type (title, table, equation, signature, and others), and scored for confidence at both the page and word level.
Mistral says bounding boxes were its most-requested capability. The reason is straightforward: without location data, downstream systems cannot trace an extracted fact back to its source on a specific page. That traceability gap has been a persistent friction point for enterprises building retrieval-augmented generation (RAG) pipelines, compliance workflows, or any application where “where did this number come from?” is a question that needs an auditable answer.
Block classification addresses a related problem. A paragraph tagged as a “title” can segment a document into hierarchical chunks for semantic search. A block tagged as a “table” can be routed to a structured-data pipeline rather than a text summarizer. A block tagged as a “signature” can trigger a redaction workflow in a compliance system.
These are not novel ideas in isolation, but packaging them as first-class outputs of the OCR model itself — rather than requiring a separate layout-analysis stage — removes an integration layer that enterprise teams have historically had to build and maintain themselves.
The confidence scores serve a dual purpose. At scale, they allow organizations to programmatically route low-confidence regions to human reviewers and auto-approve high-confidence extractions, building what the industry calls human-in-the-loop verification without requiring a person to review every page of every document. In production systems, OCR is rarely the end goal — it is the first step in a larger pipeline.
Developers building RAG systems, agent workflows, or document automation often spend more time reconstructing layout and structure than on the downstream AI logic itself. OCR 4 aims to eliminate that reconstruction step, and if it delivers on that promise, the value accrues not just in OCR cost savings but in reduced engineering hours across the entire document pipeline.
Independent reviewers preferred Mistral’s output 72 percent of the time, but benchmarks tell a complicated story
Mistral reports that OCR 4 achieved a 72% average win rate in a head-to-head human evaluation against leading competitors, conducted by independent annotators across more than 600 real-world documents in over 12 languages. The model also achieved the top overall score on OlmOCRBench at 85.20 and scored 93.07 on OmniDocBench.
But the company itself urges caution in interpreting those numbers. In its release, Mistral took the unusual step of auditing and publicly disclosing the specific types of scoring artifacts it encountered, including ground-truth errors in the reference annotations, equivalent LaTeX notation scored as mismatches, column-reading-order assumptions, and header/footer attribution issues. “We therefore treat the aggregate score as directional rather than definitive,” the company said — a notably transparent stance from a vendor announcing a product.
That transparency is well-timed. On the public OlmOCRBench leaderboard, some researchers have noted that OCR 4 currently ranks third, behind open models like Chandra OCR 2. And some open-weight models self-report higher OmniDocBench composite scores — PaddleOCR-VL-1.6 claims 96.33 — though those results have not been independently reproduced on the public leaderboard.
Early enterprise feedback has been favorable nonetheless. Aidan Donohue, an AI engineer at financial AI firm Rogo, said the company benchmarked OCR 4 against leading agentic document parsers on a chart-dense financial QA dataset and “reached equivalent accuracy at roughly 8x lower cost and 17x lower latency.” Ivan Mihailov, an AI engineer at intellectual property management firm Anaqua, said OCR 4 is “roughly 4x faster per page than our incumbent provider.”
Enterprise buyers, however, should run their own evaluations rather than relying on any vendor’s benchmark numbers. The practical question is not which model scores highest on a leaderboard, but which model produces the fewest errors on your specific documents, in your specific languages, at a price and latency that fit your workflow.

The Anthropic export ban gave Mistral’s sovereignty pitch the proof point it needed
Mistral’s release lands in a geopolitical context that could hardly be more favorable for its strategic positioning.
On June 12, Anthropic was forced to disable all access to its newest AI models, Fable 5 and Mythos 5, after the U.S. Commerce Department used national security export controls to bar the company from distributing the models to any foreign national. Enterprise clients in finance, healthcare, SaaS, and critical infrastructure found their core intelligence services abruptly disabled, without prior warning or effective recourse. As of June 24, both models remain offline, with prediction markets giving only 57% odds of restoration before July 1.
That episode validated a warning Mistral CEO Arthur Mensch has been sounding for over a year. As Business Insider reported, Mensch warned at London Tech Week in June 2025 about American AI companies “having the keys” for their models, calling it a scenario where European companies are “giving leverage to their providers.” He added: “At some point, you need to be able to turn it off or turn it on, and you don’t want to leave it to another country.”
The argument gained further urgency as Mensch’s broader sovereignty pitch escalated in recent months. As reported by CNBC in late May, Mensch told the outlet: “Europe is lagging behind when it comes to [the] buildout of infrastructure, and so we are investing to close that gap.”
At the same time, Mensch pushed back against Pope Leo XIV’s call for AI to be “disarmed,” arguing that Europe cannot afford to fall behind U.S. tech giants. “We’re all for peace, but if you look at our rivals and adversaries in the world, they’re using artificial intelligence … we do need to have our own capabilities,” Mensch told reporters.
OCR 4’s single-container, self-hosted deployment model is the product-level expression of that argument. A U.S.-headquartered provider offering EU data residency means documents are stored in Frankfurt but governed by U.S. law. Mistral, incorporated in France and operating under EU jurisdiction, offering on-premise containerized deployment, means documents never leave the customer’s infrastructure at all. The EU AI Act’s fine enforcement provisions take effect August 2, adding regulatory pressure to the compliance calculus for European enterprises evaluating document AI vendors.

Baidu’s free, open-weight OCR model arrived one day earlier — and the contrast is revealing
Mistral’s release did not arrive in isolation. Just one day before OCR 4 launched, Baidu shipped Unlimited-OCR on June 22 — a 3-billion-parameter MIT-licensed model that tackles one of the most persistent pain points in document AI: parsing entire PDFs and multi-page scans in a single forward pass, without chunking the input or stitching the output back together afterward.
Baidu’s model uses a technique called Reference Sliding Window Attention (R-SWA) that, as a top Hacker News commenter explained, splits the AI’s focus into two paths: maintaining full attention on the original document image while restricting memory of generated text to a tight, moving window. The result is constant KV cache size and the ability to transcribe 40-plus pages in a single forward pass. The model gathered 1,800 GitHub stars in its first 24 hours and racked up more than 479 upvotes on Hacker News, where the discussion thread ran to 109 comments.
The two releases frame what some analysts are calling the June 2026 document-AI split: self-hosted long-horizon parsing with open weights versus structured managed extraction with enterprise features.
Baidu’s model is free under an MIT license, runs on standard GPU hardware, and has no managed API or enterprise SLA. Mistral’s model is a commercial product with per-page pricing, bounding boxes, confidence scores, block classification, multi-platform distribution, and self-hosted deployment options for enterprise customers.
Unlimited-OCR may be the better tool for a research team digitizing scanned dissertations on a single GPU. OCR 4 is built for the IT procurement process — the world of SLAs, data processing agreements, and compliance audits.
Beyond Baidu, the broader OCR competitive field includes Google Document AI, Amazon Textract, Azure Document Intelligence, ABBYY Vantage, and a growing number of open-weight models.
On the Hacker News thread for Unlimited-OCR, practitioners offered a candid assessment of the state of the art. Joss82, who has worked on document parsing for 10 years, wrote bluntly: “OCR still sucks in 2026.” Meanwhile, one user named SyneRyder reported success with Claude for OCR of hundreds of pages of handwritten documents, noting the model delivered results with “no corrections required” and even pointed out a continuity error in the source text. These practitioner reports underscore a key tension in the market: performance varies wildly depending on the specific document type, language, and quality of the source material.
The real play is not OCR — it is an enterprise AI stack with document intelligence as the on-ramp
Step back far enough, and Mistral’s OCR 4 release is not really an OCR story. It is an enterprise go-to-market story built on top of a $4.4 billion global intelligent document processing market that is forecast to grow at a 33.1% compound annual growth rate through 2030, according to Grand View Research.
For Mistral, OCR is a wedge into enterprise AI budgets. The model feeds directly into Mistral’s Search Toolkit, the company’s open-source composable search framework announced at the AI Now Summit. In that architecture, OCR 4 serves as the ingestion layer for retrieval-augmented generation and enterprise search pipelines, converting raw documents into citation-ready, structurally classified input. The logic is clear: once an enterprise adopts OCR 4 for document extraction, Mistral’s broader model suite — including Medium 3.5 for reasoning and the Vibe agentic platform for task execution — becomes the natural next step in the stack.

That pipeline ambition is critical context for understanding Mistral’s current fundraising trajectory. Bloomberg recently reported that the company is in early discussions to raise about €3 billion ($3.5 billion) at a valuation of roughly €20 billion — nearly double the €11.7 billion valuation from its September Series C round. To date, Mistral has raised only about $4 billion, a fraction of what its largest U.S. rivals have taken in. OCR 4 and its associated enterprise revenue pipeline are part of how the company plans to justify that higher valuation, with Mistral targeting €1 billion in revenue for 2026, up from €200 million in 2025, according to Le Monde.
Mistral is a company with roughly 1,000 employees and ambitions to compete with labs that have raised 40 times as much capital. It cannot win a general-purpose model arms race against OpenAI and Anthropic. What it can do is build a differentiated enterprise stack around sovereignty, structured document intelligence, and agentic workflows — and use that stack to capture European enterprise budgets that are increasingly wary of U.S. provider dependency.
The pricing structure reinforces that strategy: at $2 per 1,000 pages in batch mode, the cost of processing a 100,000-page corporate archive falls to $200, making large-scale digitization projects economically viable in ways they may not have been with token-based vision-language model pricing.
Whether Mistral can execute that vision at scale — against Google, Amazon, Microsoft, and a surging open-source ecosystem — remains an open question. But the Anthropic export control crisis is still unresolved, European data sovereignty regulations are tightening, and a potential €20 billion funding round is on the horizon. The company is holding an OCR 4 production webinar on July 7 at 6:00 PM CET.
Two weeks ago, the argument for building AI infrastructure outside the reach of U.S. export controls was theoretical. Then the U.S. government flipped a switch, and Anthropic’s most advanced models went dark for every non-American on the planet. Mistral did not cause that crisis — but it spent the last year building the product that makes it matter.


If you spend $80 of your hard-earned income on a physical edition of Grand Theft Auto VI, you’ll receive a box with a code inside. The box is your standard rectangular, disc-holding shape, but the game itself doesn’t come on a disc — or two — at all. Perhaps the physical part is the warm feeling you get when you manually type the code into your PS5 or Xbox Series X? It surely can’t just be referencing the box, right?
Anyway, at least the physical edition doesn’t cost any more than the digital version, which is already raising eyebrows at $80. This isn’t an unheard-of price point in today’s market, but it is a shock to players who are still getting used to the $70 standard for AAA games. Nintendo has been at the forefront of the more-than-$70 movement, pricing Mario Kart World at $80 in 2025 and following that up with Elden Ring heading to Switch 2 this August. Xbox also teased an increase to $80 for its first-party games in 2025, but it backtracked just a few months later. (Classic Xbox).
The writing has been on the wall for a while now, but Rockstar pricing the standard edition of GTA VI at $80 feels like a turning point. The doors were cracked, but now they’re wide open, and the wave of $80 AAA games can start flooding in.
This matters because it affects players’ budgets at a time when the cost of living is rising at a torturous rate — but don’t worry, if you look at it from a holistic perspective, it gets worse. On a grand scale, the $80 price point matters because we’re simply spending more to own nothing. The GTA VI physical edition is the clearest, most tangible example of this trend.
I’ve said it before, but about 10 years ago, it feels like we all kind of forgot that DRM sucked. Digital rights management drew heavy consumer ire in the 2000s, as publishers started adding always-on authentication requirements to major new releases like BioShock, Mass Effect and Assassin’s Creed 2 in the name of fighting piracy. Some publishers even developed their own stores to ensure every copy of Half-Life 2 was activated and official. Many titles had to regularly connect with the publisher’s servers while in use, a feature that generated major glitches and sometimes rendered games unplayable. Players felt like they didn’t actually own their purchased games, and there was broad pushback against DRM with awareness campaigns, petitions and lawsuits.
But then broadband and wireless infrastructure expanded, downloads became more common than discs, and the number of games coming out each week skyrocketed, particularly on Steam. Players needed places to purchase and store their growing backlogs, download speeds increased, and the market leaned into convenience. And here we are today: Valve owns your entire Steam library and is simply letting you access it, and the same goes for most game downloads on PlayStation, Xbox and Nintendo platforms. Online games can be shaken up or taken down by their rights holders at any moment, and even AAA single-player narrative experiences come with day-one patches and critical post-launch updates. In a digital-first world, DRM reigns supreme.
So when Rockstar prices GTA VI at $80 and calls a game box with a code inside a “physical edition,” it feels like, yeah, the joke’s on us. Not only does the physical edition not include any discs, but it’s also spiking prices on a whole line of products — AAA games — that players can’t own and don’t control.
The GTA VI physical edition is what it looks like when game ownership disappears. It isn’t a new trend, but combined with the upgraded price point, the code-in-a-box brings this phenomenon into supreme clarity. Purchasing any ultra-hyped AAA game feels like a gamble (or, maybe a loot box).
This hasn’t been happening in a vacuum, of course. Consumer protections are on the rise in the video game space, alongside efforts to preserve the industry’s history. The grassroots Stop Killing Games movement has been loudly advocating against publishers that remove titles from players’ libraries and haphazardly shut down their services. Stop Killing Games recently failed to convince the European Commission to require publishers to maintain support for games that they’ve stopped selling, but the group is generating conversation and change on a large scale.
Meanwhile, the GOG storefront remains completely free of DRM, and in 2024 GOG launched its Preservation Program aimed at adapting historic games for modern hardware. The program has spit-shined and preserved 300 classic games so far, including Metro 2033, The Witcher and its sequel, Devil May Cry: HD Collection, Resident Evil 1–3, six Tomb Raider installments, Diablo and Crysis. All of the preservation work is handled by GOG, with no upkeep required from the original game makers. And of course, itch.io is another storefront that doesn’t have built-in DRM like Steam.
The $80 GTA VI physical edition — without any physical media — is exactly what we should expect from the existing AAA machine. It’s a matter of Rockstar playing its part in the video game ecosystem: perpetuating crunch-layoff cycles, raising the baseline price of all AAA games, and further solidifying strict DRM control structures that benefit publishers over players. Rock on, I guess.

THE BIG SHORT! I’M DONE WITH BITCOIN
Hidden bay provides peaceful escape from overcrowded beaches amid heatwave
Macy’s EVP, COO & CFO Edwards Jr. sells $408,726 in stock





-

 Fashion5 days ago
Fashion5 days agoWeekend Open Thread: Miami – Corporette.com
-

 Entertainment4 days ago
Entertainment4 days agoRenter of Home in Anne Heche Crash Denies Settlement With Son
-

 Tech3 days ago
Tech3 days agoMicrosoft accidentally kills epic Outlook email threads
-
 Sports1 day ago
Sports1 day agoTwo goals and an assist by sheer aura: Cristiano Ronaldo just entered the World Cup chat
-

 Business4 days ago
Business4 days agoSoccer-U.S. defends Iran World Cup travel restrictions, says discussions ongoing
-
Crypto World22 hours ago
Bitcoin (BTC) Dips Below $62K, Ethereum (ETH) Plunges 6% Daily: Market Watch
-

 Politics6 days ago
Politics6 days agoBBC Reporter Discusses Cross Party Criticism Of Trumps Iran Deal
-

 Politics5 days ago
Politics5 days agoAndy Burnham and the meaning of Makerfield
-

 Crypto World19 hours ago
Crypto World19 hours agoSecuritize Wraps Roubini's SEC-Registered ETF as Dubai VARA Digital Security
-
Business1 day ago
Entergy settles forward sale agreements, raises $672 million in cash proceeds
-
 Business5 days ago
Business5 days agoWall Street Week Ahead: Investors see Micron earnings as pulse check of AI rally momentum
-

 NewsBeat5 days ago
NewsBeat5 days agoKeir Starmer Allies Question His Chances For No 10
-

 Tech6 days ago
Tech6 days agoAWS enters the context layer race with a graph that learns from agents, not manual curation
-
 Crypto World5 days ago
Crypto World5 days agoCan Charles Hoskinson Really Rescue Cardano?
-

 Crypto World5 days ago
Crypto World5 days agoHIVE shares jump as $220M AI deal speeds Bitcoin mining pivot
-

 Crypto World5 days ago
Crypto World5 days agoJake Chervinsky accuses CME of protecting derivatives monopoly
-
 Tech4 days ago
Tech4 days agoSignal’s Meredith Whittaker says AI chatbots ‘are not your friends’ and calls Copilot agents a backdoor
-

 Entertainment5 days ago
Entertainment5 days agoJose Alvarado Wants Taylor Swift at More Knicks Games
-

 Tech2 days ago
Tech2 days agoNearly 7,000 fake Amazon domains registered ahead of Prime Day 2026, researchers warn
-

 Business6 days ago
Business6 days agoBrexit cost 6% of UK economy, Bank of England company data suggests
You must be logged in to post a comment Login