
Tech
Living Heart Project Builds Virtual Twins for Medicine

One morning in May 2019, a cardiac surgeon stepped into the operating room at Boston Children’s Hospital more prepared than ever before to perform a high-risk procedure to rebuild a child’s heart. The surgeon was experienced, but he had an additional advantage: He had already performed the procedure on this child dozens of times—virtually. He knew exactly what to do before the first cut was made. Even more important, he knew which strategies would provide the best possible outcome for the child whose life was in his hands.
How was this possible? Over the prior weeks, the hospital’s surgical and cardio-engineering teams had come together to build a fully functioning model of the child’s heart and surrounding vascular system from MRI and CT scans. They began by carefully converting the medical imaging into a 3D model, then used physics to bring the 3D heart to life, creating a dynamic digital replica of the patient’s physiology. The mock-up reproduced this particular heart’s unique behavior, including details of blood flow, pressure differentials, and muscle-tissue stresses.
This type of model, known as a virtual twin, can do more than identify medical problems—it can provide detailed diagnostic insights. In Boston, the team used the model to predict how the child’s heart would respond to any cut or stitch, allowing the surgeon to test many strategies to find the best one for this patient’s exact anatomy.
That day, the stakes were high. With the patient’s unique condition—a heart defect in which large holes between the atria and ventricles were causing blood to flow between all four chambers—there was no manual or textbook to fully guide the doctors. The condition strains the lungs, so the doctors planned an open-heart surgery to reroute deoxygenated blood from the lower body directly to the lungs, bypassing the heart. Typically with this kind of surgery, decisions would be made on the fly, under demanding conditions, and with high uncertainty. But in this case, the plan had been tested in advance, and the entire team had rehearsed it before the first incision. The surgery was a complete success.
Such procedures have become routine at the Boston hospital. Since that first patient, nearly 2,000 procedures have been guided by virtual-twin modeling. This is the power of the technology behind the Living Heart Project, which I launched in 2014, five years before that first procedure. The project started as an exploratory initiative to see if modeling the human heart was possible. Now with more than 150 member organizations across 28 countries, the project includes dozens of multidisciplinary teams that regularly use multiscale virtual twins of the heart and other vital organs.
This technology is reshaping how we understand and treat the human body. To reach this transformative moment, we had to solve a fundamental challenge: building a digital heart accurate enough—and trustworthy enough—to guide real clinical decisions.
A father’s concern
Now entering its second decade, the Living Heart Project was born in part from a personal conviction. For many years, I had watched helplessly as my daughter Jesse faced endless diagnostic uncertainty due to a rare congenital heart condition in which the position of the ventricles is reversed, threatening her life as she grew. As an engineer, I understood that the heart was an array of pumping chambers, controlled by an electrical signal and its blood flow carefully regulated by valves. Yet I struggled to grasp the unique structure and behavior of my daughter’s heart well enough to contribute meaningfully to her care. Her specialists knew the bleak forecast children like her faced if left untreated, but because every heart with her condition is anatomically unique, they had little more than their best guesses to guide their decisions about what to do and when to do it. With each specialist, a new guess.
Then my engineering curiosity sparked a question that has guided my career ever since: Why can’t we simulate the human body the way we simulate a car or a plane?
 At a visualization center in Boston, VR imagery helps the mother of a young girl with a complex heart defect understand the inner workings of her child’s heart. Dassault Systèmes
At a visualization center in Boston, VR imagery helps the mother of a young girl with a complex heart defect understand the inner workings of her child’s heart. Dassault Systèmes
I had spent my career developing powerful computational tools to help engineers build digital models of complex mechanical systems, using models that ranged from the interactions of individual atoms to the components of entire vehicles. What most of these models had in common was the use of physics to predict behavior and optimize performance. But in medicine today, those same physics-based approaches rarely inform decision-making. In most clinical settings, treatment decisions still hinge on judgments drawn from static 2D images, statistical guidelines, and retrospective studies.
This was not always the case. Historically, physics was central to medicine. The word “physician” itself traces back to the Latin physica, which translates to “natural science.” Early doctors were, in a sense, applied physicists. They understood the heart as a pump, the lungs as bellows, and the body as a dynamic system. To be a physician meant you were a master of physics as it applied to the human body.
As medicine matured, biology and chemistry grew to dominate the field, and the knowledge of physics got left behind. But for patients like my daughter, that child in Boston, and millions like them, outcomes are governed by mechanics. No pill or ointment—no chemistry-based solution—would help, only physics. While I did not realize it at the time, virtual twins can reunite modern physicians with their roots, using engineering principles, simulation science, and artificial intelligence.
A decade of progress
The LHP concept was simple: Could we combine what hundreds of experts across many specialties knew about the human heart to build a digital twin accurate enough to be trusted, flexible enough to personalize, and predictive enough to guide clinical care?
We invited researchers, clinicians, device and drug companies, and government regulators to share their data, tools, and knowledge toward a common goal that would lift the entire field of medicine. The Living Heart Project launched with a dozen or so institutions on board. Within a year, we had created the first fully functional virtual twin of the human heart.
The Living Heart was not an anatomical rendering, tuned to simply replicate what we observed. It was a first-principles model, coupling the network of fibers in the heart’s electrical system, the biological battery that keeps us alive, with the heart’s mechanical response, the muscle contractions that we know as the heartbeat.
The Living Heart virtual twin simulates how the heart beats, offering different views to help scientists and doctors better predict how it will respond to disease or treatment. The center view shows the fine engineering mesh, the detailed framework that allows computers to model the heart’s motion. The image on the right uses colors to show the electrical wave that drives the heartbeat as it conducts through the muscle, and the image on the left shows how much strain is on the tissue as it stretches and squeezes. Dassault Systèmes
Academic researchers had long explored computational models of the heart, but those projects were typically limited by the technology they had access to. Our version was built on industrial-grade simulation software from Dassault Systèmes, a company best known for modeling tools used in aerospace and automotive engineering, where I was working to develop the engineering simulation division. This platform gave teams the tools to personalize an individual heart model using the patient’s MRI and CT data, blood-pressure readings, and echocardiogram measurements, directly linking scans to simulations.
Surgeons then began using the Living Heart to model procedures. Device makers used it to design and test implants. Pharmaceutical companies used it to evaluate drug effects such as toxicity. Hundreds of publications have emerged from the project, and because they all share the same foundation, the findings can be reproduced, reused, and built upon. With each application, the research community’s understanding of the heart snowballed.
Early on, we also addressed an essential requirement for these innovations to make it to patients: regulatory acceptance. Within the project’s first year, the U.S Food and Drug Administration agreed to join the project as an observer. Over the next several years, methods for using virtual-heart models as scientific evidence began to take shape within regulatory research programs. In 2019, we formalized a second five-year collaboration with the FDA’s Center for Devices and Radiological Health with a specific goal.
That goal was to use the heart model to create a virtual patient population and re-create a pivotal trial of a previously approved device for repairing the heart’s mitral valve. This helped our team learn how to create such a population, and let the FDA experiment with evaluating virtual evidence as a replacement for evidence from flesh-and-blood patients. In August 2024, we published the results, creating the first FDA-led guidelines for in silico clinical trials and establishing a new paradigm for streamlining and reducing risk in the entire clinical-trial process.
In 10 years, we went from a concept that many people doubted could be achieved to regulatory reality. But building the heart was only the beginning. Following the template set by the heart team, we’ve expanded the project to develop virtual twins of other organs, including the lungs, liver, brain, eyes, and gut. Each corresponds to a different medical domain, which has its own community, data types, and clinical use cases. Working independently, these teams are progressing toward a breakthrough in our understanding of the human body: a multiscale, modular twin platform where each organ twin could plug into a unified virtual human.
How a digital twin of the heart is constructed
A cardiac digital twin starts with medical imaging, typically MRI, CT, or both. The slices are reconstructed into the 3D geometry of the heart and connected vessels. The geometry of the whole organ must then be segmented into its constituent parts, so each substructure—atria, ventricles, valves, and so on—can be assigned their unique properties.
At this point, the object is converted to a functional, computational model that can represent how the various cardiac tissues deform under load—the mechanics. The complete digital twin model becomes “living” when we integrate the electrical fiber network that drives mechanical contractions in the muscle tissue.
 Each part of the heart, such as the left ventricle [left], is superimposed with a detailed digital mesh to re-create its physiology. These pieces come together to form an anatomically accurate rendering of the whole organ [right].Dassault Systèmes
Each part of the heart, such as the left ventricle [left], is superimposed with a detailed digital mesh to re-create its physiology. These pieces come together to form an anatomically accurate rendering of the whole organ [right].Dassault Systèmes
To simulate circulation, the twin adds computational models of hemodynamics, the physics of blood flow and pressure. The model is constrained by boundary conditions of blood flow, valve behavior, and vascular resistance set to closely match human physiology. This lets the model predict blood flow patterns, pressure differentials, and tissue stresses.
Finally, the model is personalized and calibrated using available patient data, such as how much the volume of the heart chambers changes during the cardiac cycle, pressure measurements, and the timing of electrical pulses. This means the twin reflects not only the patient’s anatomy but how their specific heart functions.
Building bigger cohorts with generative AI
When the FDA in silico clinical trial initiative launched in 2019, the project’s focus shifted from these handcrafted virtual twins of specific patients to cohorts large enough to stand in for entire trial populations. That scale is feasible today only because virtual twins have converged with generative AI. Modeling thousands of patients’ responses to a treatment or projecting years of disease progression is prohibitively slow with conventional digital-twin simulations. Generative AI removes that bottleneck.
AI boosts the capability of virtual twins in two complementary ways. First, machine learning algorithms are unrivaled at integrating the patchwork of imaging, sensor, and clinical records needed to build a high-fidelity twin. The algorithms rapidly search thousands of model permutations, benchmark each against patient data, and converge on the most accurate representation. Workflows that once required months of manual tuning can now be completed in days, making it realistic to spin up population-scale cohorts or to personalize a single twin on the fly in the clinic.
Second, enriching AI models’ training sets with data from validated virtual patients grounds the AI simulations in physics. By contrast, many conventional AI predictions for patient trajectories rely on statistical modeling trained on retrospective datasets. Such models can drift beyond physiological reality, but virtual twins anchor predictions in the laws of hemodynamics, electrophysiology, and tissue mechanics. This added rigor is indispensable for both research and clinical care—especially in areas where real-world data are scarce, whether because a disease is rare or because certain patient populations, such as children, are underrepresented in existing datasets.
Enabling in silico clinical trials
On the research side, the FDA-sponsored In Silico Clinical Trial Project that we completed in 2024 opened a new world for medical innovations. A conventional clinical trial may take a decade, and 90 percent of new drug treatments fail in the process. Virtual twins, combined with AI methods, allow researchers to design and test treatments quickly in a simulated human environment. With a small library of virtual twins, AI models can rapidly create expansive virtual patient cohorts to cover any subset of the general population. As clinical data becomes available, it can be added into the training set to increase reliability and enable better predictions.
 The Living Heart Project has expanded beyond the heart, modeling organs throughout the body. The 3D brain reconstruction [top] shows major pathways in the brain’s white matter connecting color-coded regions of the brain. The lung virtual twin [middle] combines the organ’s geometry with a physics-based simulation of air flowing down the trachea and into the bronchi. And the cross section of a patient’s foot [bottom] shows points of strain in the soft tissue when bearing weight. Dassault Systèmes
The Living Heart Project has expanded beyond the heart, modeling organs throughout the body. The 3D brain reconstruction [top] shows major pathways in the brain’s white matter connecting color-coded regions of the brain. The lung virtual twin [middle] combines the organ’s geometry with a physics-based simulation of air flowing down the trachea and into the bronchi. And the cross section of a patient’s foot [bottom] shows points of strain in the soft tissue when bearing weight. Dassault Systèmes
Virtual twin cohorts can represent a realistic population by building individual “virtual patients” that vary by age, gender, race, weight, disease state, comorbidities, and lifestyle factors. These twins can be used as a rich training set for the AI model, which can expand the cohort from dozens to hundreds of thousands. Next the virtual cohort can be filtered to identify patients likely to respond to a treatment, increasing the chances of a successful trial for the target population.
The trial design can also include a sampling of patient types less likely to respond or with elevated risk factors, thus allowing regulators and clinicians to understand the risks to the broader population without jeopardizing overall trial success. This methodology enhances precision and efficiency in clinical research, providing population-level insights previously available only after many years of real-world evidence.
Of course, though today’s heart digital twins are powerful, they’re not perfect replicas. Their accuracy is bounded by three main factors: what we can measure (for example, image resolution or the uncertainty of how tissue behaves in real life), what we must assume about the physiology, and what we can validate against real outcomes. Many inputs, like scarring, microvascular function, or drug effects are difficult to capture clinically, so models often rely on population data or indirect estimation. That means predictions can be highly reliable for certain questions but remain less certain for others. Additionally, today’s digital twins lack validation for predicting long-term outcomes years in the future, because the technology has been in use for only a few years.
Over time, each of these limitations will steadily shrink. Richer, more standardized data will tighten personalization of the models. AI tools will help automate labor-intensive steps. And the collection of longitudinal data will improve the model’s ability to reliably predict how the body will evolve over time.
How virtual twins will change health care
Throughout modern medicine, new technologies have sharpened our ability to diagnose, providing ever-clearer images, lab data, and analytics that tell physicians what is presently happening inside a patient’s body. Virtual twins shift that paradigm, giving clinicians a predictive tool.
 This “Living Lung” virtual-twin simulation shows strain patterns during breathing. Mona Eskandari/UC Riverside
This “Living Lung” virtual-twin simulation shows strain patterns during breathing. Mona Eskandari/UC Riverside
Early demonstrations are already appearing in many areas of medicine, including cardiology, orthopedics, and oncology. Soon, doctors will also be able to collaborate across specialties, using a patient-specific virtual twin as the common ground for discussing potential interactions or side effects they couldn’t predict independently.
Although these applications will take some time to become the standard in clinical care, more changes are on the horizon. Real-time data from wearables, for example, could continuously update a patient’s personalized virtual twin. This approach could empower patients to understand and engage more deeply in their care, as they could see the direct effects of medical and lifestyle changes. In parallel, their doctors could get comprehensive data feeds, using virtual twins to monitor progress.
Imagine a digital companion that shows how your particular heart will react to different amounts of salt intake, stress, or sleep deprivation. Or a visual explanation of how your upcoming surgery will affect your circulation or breathing. Virtual twins could demystify the body for patients, fostering trust and encouraging proactive health decisions.
A new era of healing
With the Living Heart Project, we’re bringing physics back to physicians. Modern physicians won’t need to be physicists, any more than they need to be chemists to use pharmacology. However, to benefit from the new technology, they will need to adapt their approach to care.
This means no longer seeing the body as a collection of discrete organs and considering only symptoms, but instead viewing it as a dynamic system that can be understood, and in most cases, guided toward health. It means no longer guessing what might work but knowing—because the simulation has already shown the result. By better integrating engineering principles into medicine, we can redefine it as a field of precision, rooted in the unchanging laws of nature. The modern physician will be a true physicist of the body and an engineer of health.
From Your Site Articles
Related Articles Around the Web



The ruling keeps Anthropic locked out of DoD contracts for now, even though a separate federal court in California recently barred the Trump administration from enforcing a broader ban on the use of Claude.
Read Entire Article
Source link


Microsoft veteran Raymond Chen is once again spilling the beans on how Windows 95 became one of the most influential operating systems ever. Back in the Nineties, Microsoft developers were busy working on many custom solutions to make the new OS compatible with previous software products. However, a few programs…
Read Entire Article
Source link
Tech
Kia cuts EV target, confirms electric pickup, and plans to put Atlas robots in its Georgia factories
In short: On the day that 25% US tariffs on South Korean imports took effect, Kia held its 2026 CEO Investor Day in Seoul and presented a plan built for a changed world: a quietly reduced EV sales target for 2030, a major expansion of its hybrid range, the first confirmation of a North American electric pickup truck, and a commitment to deploy Boston Dynamics’ Atlas humanoid robots in its Georgian factories from 2028. The five-year investment plan reaches KRW 49 trillion, and the company is targeting KRW 170 trillion in revenue by 2030.
Kia President and CEO Ho-sung Song opened the event with a statement of direction: “EVs, HEVs, autonomous driving, and robotics will serve as key drivers for Kia’s fastest growth to date.” The framing is deliberately broad, a recognition that the path to Kia’s 2030 ambitions no longer runs through battery-electric vehicles alone, and that the company must build revenue across multiple technology bets simultaneously.
A lower EV target, a bigger hybrid push
The most numerically significant announcement at this year’s event is one Kia did not frame as a retreat. The company’s 2030 EV sales target now stands at 1 million units annually, across a lineup that will expand to 14 models. That figure represents a reduction of roughly 20% from the approximately 1.26 million target set at last year’s investor day, and a sharper fall from the 1.6 million target Kia set at its 2023 event. The causes are well understood: the elimination of US EV subsidies, the slowdown in US battery-electric sales, and the weight of import tariffs that cost the group KRW 3.3 trillion (approximately $2.3 billion) in 2025 alone.
In place of the lost EV volume, Kia is expanding its hybrid offer substantially. Annual HEV sales are now targeted at 1.1 million units by 2030, supported by a lineup growing to 13 models. Combined with the EV target, Kia plans to sell 2.1 million electrified passenger vehicles per year by the end of the decade, out of a total of 4.13 million units and a targeted global market share of 4.5%. Its purpose-built vehicle (PBV) range, comprising the PV5, PV7, and PV9 commercial models, adds a further 232,000 unit target by 2030. Regionally, Kia is targeting 1.02 million units in the US, 746,000 in Europe, and 1.48 million in emerging markets.
The immediate financial picture is more pressing than the 2030 targets. For 2026, Kia is projecting KRW 122.3 trillion in sales and KRW 10.2 trillion in operating profit — a recovery from the tariff-hit prior year, premised on the 15% tariff rate established under the Korea-US agreement in late 2025, which replaced the previous 25% rate. Whether that rate holds under continued trade policy pressure remains an open question.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
A pickup truck for America, and for the tariff era
The announcement that received the most immediate attention is Kia’s confirmation that it will build a mid-size electric pickup truck aimed specifically at North America. The model will be built on a next-generation EV platform, and the company is targeting a 7% share of the North American pickup truck market, implying annual sales of approximately 90,000 units in the medium to long term.
Kia did not confirm where the vehicle will be manufactured, but the strategic logic is clear. Both of the group’s US facilities — Hyundai Motor Group Metaplant America in Georgia and Kia’s own manufacturing plant in West Point, Georgia — are positioned to produce vehicles that avoid import tariffs, including both the longstanding “Chicken Tax” applied to light trucks and the newer EV import levies. The timing of the announcement, made on the same day that 25% reciprocal tariffs on South Korean imports came into force, underlines the degree to which Kia is reconfiguring its product strategy around US production.
Atlas on the factory floor
Kia also used the investor day to advance its timeline for deploying Boston Dynamics’ Atlas humanoid robots in its manufacturing operations. Atlas robots — trained at Hyundai Motor Group’s Robotics Metaplant Application Centre — are scheduled to begin sequencing tasks at HMGMA in 2028, with more complex assembly operations beginning by 2030. The programme will then expand to Kia AutoLand Georgia in the second half of 2029.
The contest to deploy humanoid robots in production environments at scale has been building for several years, with automakers positioned as early adopters given the structured and predictable nature of assembly line work. Boston Dynamics unveiled a production-ready version of Atlas at CES 2026 and said all 2026 deployments were already committed. As humanoid robots move from demonstration to production-line deployment, manufacturers are working out what tasks the technology can handle reliably and which require further development before genuine integration into complex assembly. Kia’s roadmap, sequencing tasks first, assembly later — reflects that staged approach.
Boston Dynamics is a subsidiary of Hyundai Motor Group, which gives Kia preferential access to Atlas deployments. Alongside the factory programme, Kia is exploring last-mile logistics applications that combine its PBV range with Boston Dynamics’ Stretch logistics robot for warehouse operations and its Spot quadruped for on-site delivery.
Software-defined vehicles, autonomy, and the financial plan
Kia’s technology roadmap beyond hardware commits the company to completing its first software-defined vehicle model, equipped with highway-level 2+ autonomous driving capability, by the end of 2027. Urban autonomous driving at Level 2++ is targeted for rollout from early 2029. The competitive context for higher-level autonomy is shifting quickly, with robotaxi operators expanding their geographic footprints and the gap between technology leaders and production vehicle manufacturers becoming harder to ignore. Kia’s AV programme, while more conservative than pure-play autonomous operators, is designed to bring meaningful driver assistance into high-volume production vehicles rather than limited commercial fleets.
The financial scaffolding for all of this is KRW 49 trillion in investment over the five-year period from 2026 to 2030, of which KRW 21 trillion is earmarked for future business areas including robotics, SDVs, and autonomous driving. The year 2025 crystallised how unevenly the AI and technology dividend was being distributed across industries, and Kia’s investment plan reflects an explicit attempt to ensure that the automotive business captures value from the automation and software transitions rather than ceding it to technology companies entering the mobility space. By 2030, Kia is targeting KRW 170 trillion in annual revenue and a 10% operating profit margin, implying KRW 17 trillion in operating profit. Whether that margin is achievable depends heavily on how trade policy, EV demand, and the pace of hybrid uptake develop over the next four years. The convergence of automotive hardware and AI-driven mobility software is accelerating, and Kia’s investor day is, in aggregate, a bet that traditional automakers can compete in both domains if they act now.

.png)
Passwords have been the standard of online security. Next was the two-factor authentication. Then security questions, CAPTCHA, and fingerprinting of devices. Every layer introduced with a new threat. Both were ultimately defeated by more advanced scams.
The trend is obvious: any security system relying on what one knows or possesses will be susceptible to theft, copying, or social engineering. The one verification level that is truly hard to counterfeit is who someone is – and that is exactly where artificial intelligence has transformed all that.
Identity verification using AI is no longer a niche technology that is implemented only by banks and governmental agencies. It is also going to be the minimum security requirement of any business onboarding clients digitally, transacting high-value deals, or working within a regulated sector in 2026. The knowledge of how it works, why it is important, and how to apply it is now a business competency rather than an IT issue.
The Issue Classic Security Cannot Address
It is only prudent to know what AI-driven identity verification is meant to address before delving into how it works, since the threat landscape has changed drastically.
Credential breach has rendered credentials a worthless security signal. The Cost of a Data Breach Report by IBM indicated that in 2024, the mean data breach involved more than 25,000 records. Out of the thousands of breaches that have taken place worldwide in the last ten years, billions of usernames and passwords, social security numbers, dates of birth, and answers to security questions are now being sold on the dark web. With access to such databases, a fraudster can easily pass through traditional credential checks since the credentials are authentic, only that they are owned by a different person.
The synthetic identity fraud has generated a new breed of criminal. More than stealing an existing identity, advanced fraudsters are building identities, assembling a real Social Security number (usually that of a child or an aged individual with no credit history) with invented names, addresses, and biographical information. These artificial identities can withstand a simple verification check since some of the information is authentic. They are mostly unnoticed by traditional rules-based fraud detection systems.
Deepfakes created by AI have defeated selfie-based authentication. The fast development of generative AI has brought about tools that are capable of generating photorealistic fake images, videos, and even real-time video feeds of non-existent individuals within minutes. The days of systems utilizing a mere selfie photo to verify identity are long gone, with fraudsters capable of uploading a deepfake image that, visually, resembles a real photo.
Credential theft, synthetic identity fraud, and AI-generated deepfakes are the three converging threats that next-generation AI-powered identity verification is designed to deal with.
The reality of what AI-Powered Identity Verification does
Identity verification is not just an AI-based technology. It is a multi-tiered system of a series of AI models operating together to determine with high probability that an individual is who they claim they are.
Document Authentication
The initial layer is document checking. A user enters a government-issued identity document, passport, driver’s license, national ID card, and an AI model compares it with thousands of known document templates that exist in the world.
The level of the analysis is much higher than determining whether the document is real. Machine learning algorithms trained on millions of real and fake documents analyze the quality of microprints, the presence of UV patterns, holographic elements, font authenticity, MRZ (Machine Readable Zone) information integrity, and pixel-level anomalies (which signify editing and manipulation). Digitally manipulated documents (even in subtle ways) are detected within seconds.
The system of document verification is available in modern document verification systems that can verify more than 14,000 types of documents representing more than 190 countries, which would not otherwise be feasible to verify manually.
Biometric Face Matching
When the document has been verified, the system will compare the face on the document to a live selfie or a video submission by the individual purporting to be the document holder. In AI facial recognition models, the geometric distance between facial features, such as the distance between eyes, nose shape, jaw angle, and a confidence score of the match, is calculated.
It is a quick, precise, and much more dependable method than a visual inspection by people. Research by the National Institute of Standards and Technology (NIST) consistently reported that the best facial recognition algorithms perform better than human examiners in face matching tasks, especially when there are changes in lighting, angle, and age.
Liveness Detection
It is the layer that deals with deepfake fraud in particular, and it is in this area that AI has achieved the most critical progress.
Liveness detection identifies when the face presented is that of a real, physically present human being, or whether it is a photograph, printed mask, video recording, or deepfake generated by a computer AI. Passive liveness detection examines a single image of slight signs of non-liveness: texture anomalies, unnatural light reflection, absence of micro-movements, or compression artifacts suggesting a screen capture. Active liveness detection requires the user to do randomized behaviors: blink, move their head, smile, which are virtually impossible to impersonate by a still image and computationally infeasible to spoof by a live deepfake.
Passive and active liveness detection combined has increased the threshold to deepfake fraud attacks to the extent that the cost of a successful attack is usually more economical than the fraudulent value, and AI-generated identity fraud attacks are thus not economical in most criminal activities.
Cross-Referencing of Data and AML Screening
Outside the biometric layer, identity verification systems built with AI will cross-verify the verified identity data against external databases in real-time. This encompasses global sanctions lists, Politically Exposed Persons (PEP) databases, adverse media sources, and watchlists that are managed by regulatory agencies such as the OFAC, the UN, and the EU.
It is this AML screening layer that makes identity verification a compliance tool, as well as a security tool, such that businesses can fulfill their Know Your Customer (KYC) and Anti-Money Laundering (AML) requirements alongside the verification check, instead of as a downstream operation.
The Importance of Thematically Integrated Security to Business Security – Not Just Compliance
The argument of AI-based identity verification as compliance is well-established. In practically every jurisdiction, financial services companies, fintech, and other regulated businesses are required to perform KYC and AML processes on a compulsory basis. Failing to meet them carries substantial financial penalties and reputational risk.
However, the business security case is far bigger than regulatory compliance – and to most businesses, the non-compliance risks pale in comparison with the direct losses of fraud that can be easily facilitated by poor identity verification.
Businesses are directly affected by account takeover fraud. Once a fraudster manages to create a successful impersonation of an authentic customer in the process of onboarding or recovering an account, they access the available accounts, payment methods, and stored credit. The ensuing chargebacks, frauds, and dispute settlements are more on the business side than the card network. Account takeover fraud is a major and increasing direct operating expense to e-commerce companies and financial technology applications.
New account fraud generates unpayable debts. Synthetic identity fraud generally leads to the so-called bust-out schemes in which a fraudster accumulates credit exposure on a variety of products, and then defaults on all of them at once. To lenders, credit providers, and buy-now-pay-later sites, the damages of a single synthetic identity that has been nurtured over months can go into tens of thousands of dollars.
Financial loss is compounded by reputational loss because of instances of fraud. In cases where clients of a business fall victim to fraud by a security breach on a platform, the reputational loss is more than just the direct financial loss. The loss of customers, media attention, and regulatory investigations after a fraud incident can be even more expensive than the actual losses incurred in the fraud itself – especially to a business in which trust is the product.
At the onboarding stage, AI-based identity checks prevent the vast majority of such attack vectors, prior to the creation of a fraudulent account. Compliance cost avoidance is only part of the payback; it is the avoidance of downstream fraud losses that grow with business expansion.
Real-life Application: What Companies Should know
The practical considerations of AI-powered identity verification extend beyond the technology when business leaders consider this technology.
Should Be API-First Deployment
Contemporary identity verification systems are implemented through API integration – linking your onboarding process with the verification service without having the customer leave your site. This retains the customer experience and facilitates instant verification decisions. Find options that enable integration of SDKs in mobile applications and provide a webhook-based delivery of decisions to reduce the onboarding latency.
Risk Level should be configurable to determine Verification Decisions
Customers do not pose the same fraud risk, and not all transactions need the same level of verification. An effective AI-based solution enables companies to set up verification processes according to risk indicators – introduce lightweight document verification to transactions with low risks and complete biometric verification with liveness detection to high-value or high-risk onboarding situations. This risk-based model maintains conversion rates among legitimate customers and focuses verification resources where the fraud risk is the greatest.
Audit Trails are Not Negotiable
Each verification decision, be it approval, rejection, or flagged to undergo manual review, should be recorded with a time stamp, the particular methods used to verify, the confidence levels delivered by the methods, and the documentation. Such an audit trail is necessary in regulatory audits, chargeback audits, and internal fraud audits. Firms that are subject to FINTRAC, GDPR, or other regulations must generate such records when they are requested, usually in 30 days or fewer.
Should Be Constructed Human Review Escalation
AI verification systems are extremely precise, yet no computerized system can be 100 percent confident in all cases. Good implementations involve a queue of cases with AI confidence less than a set-point – often around 5-10% of all verifications. The edge cases that are not detected by the automated systems are picked by human reviewers looking at the flagged cases, and their verdicts are used to inform further improvement of the model.
Select a Partner that has Worldwide Document Covers
When you have customers in a variety of countries, your identity verification provider should accept document types in those countries. An optimized system for North American documents will result in an unacceptable high rate of false rejection of customers with a Southeast Asian, Middle Eastern, or African identity document. Such solutions as the document verification offered by Shufti Pro can work with documents issued in 190+ countries – an essential feature that businesses with international clientele can use.
The Competitive Advantage of this Right
The divide between companies that have invested in solid identity verification infrastructure and those that have not is widening, and the difference has repercussions beyond losses in fraud.
The relations between payment processors are based on fraud indicators. The card networks and payment processors keep a close eye on the chargeback rates and the fraud rates. Companies with low fraud traces due to proper identity checking receive superior processing rates, increased transaction limits, and preference of merchants. Companies that have higher fraud rates will be charged higher fees, delays in processing, and, in the worst case, the merchant account will be shut down.
Security posture is also necessary to acquire enterprise clients. Enterprise customers: Large enterprises (especially in the financial services, medical, and government contracting) perform vendor security testing before contracting. Documented, auditable identity verification and fraud prevention program is becoming a condition to winning enterprise business, and not a differentiator.
Fraud infrastructure is studied in investor due diligence. In the case of growth-stage businesses that are in need of investment, fraud prevention infrastructure is part of due diligence. Fintech, e-commerce, and SaaS investors prefer to observe that the business has developed security basics that can scale up since fraud losses that can be controlled at the early stage become existential at the growth stage when the infrastructure is lacking.
The Future: The Future of AI Identity Verification
The technology does not stand still. Several trends are underway transforming AI-driven identity verification in 2026 and beyond.
Continuous authentication has passed onboarding. Instead of authenticating identity when creating an account, AI systems are starting to track behavioral indicators, such as typing patterns, mouse motions, transaction activities, etc., in real time, and used in the course of a user session, which indicates anomalies that may indicate account takeover.
There is an increasing regulatory trend toward decentralized identity frameworks, in which verified credentials are stored by the user, but not by individual businesses, both in the EU and Canada. These frameworks minimise the data liability that businesses already bear when it comes to storing identity documents and biometric data.
There are ever-growing regulatory requirements across the world. Fintrac of Canada, the AML package of the EU, and other systems in Asia-Pacific are increasing standards of identity verification – that is, what is best practice now will become legal minimum tomorrow.
Concluision
The paradigm change that AI-enabled identity verification will be a transition to proactive security, rather than reactive security. Conventional methods identified fraud only once it occurred, by way of chargeback, account audits, and forensic audits. Verification, which is AI-based, detects fraud when it is attempted – before creation of a fraudulent account, before a stolen identity being impersonated, before a deep fake passing through an onboarding test.
In the case of businesses that are scaling, that change does not qualify as a security upgrade. It is a foundation. Survivable losses of fraud at a small scale are devastating at the growth stage. It is the businesses that develop strong identity verification infrastructure early that develop without the compounding drag of costs associated with fraud, compliance failures, and reputational incidents slowing them down.
With the cost of impersonation in a digital economy falling to almost zero, the cost of not authenticating identity is increasing year after year.
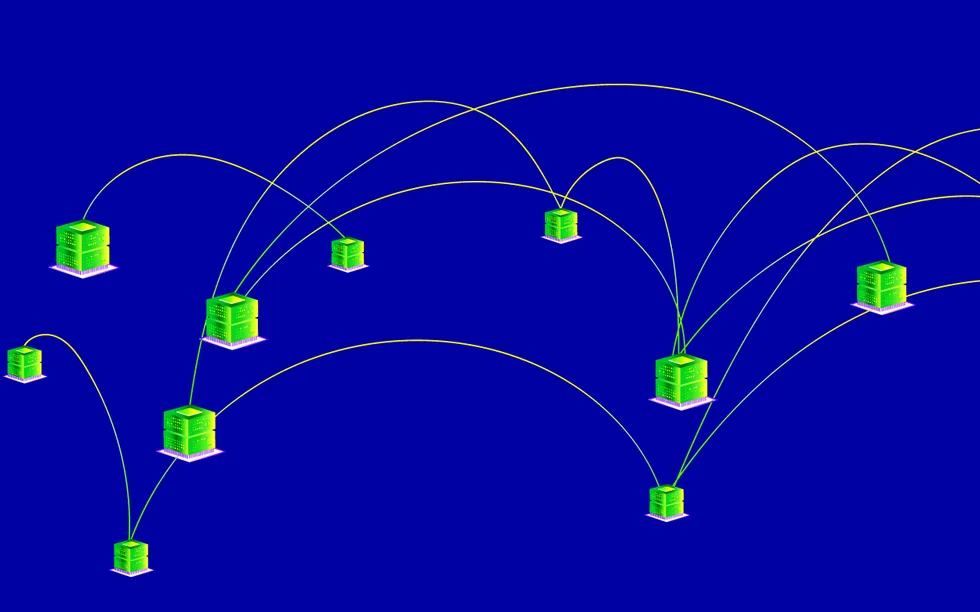

Artificial intelligence harbors an enormous energy appetite. Such constant cravings are evident in the hefty carbon footprint of the data centers behind the AI boom and the steady increase over time of carbon emissions from training frontier AI models.
No wonder big tech companies are warming up to nuclear energy, envisioning a future fueled by reliable, carbon-free sources. But while nuclear-powered data centers might still be years away, some in the research and industry spheres are taking action right now to curb AI’s growing energy demands. They’re tackling training as one of the most energy-intensive phases in a model’s life cycle, focusing their efforts on decentralization.
Decentralization allocates model training across a network of independent nodes rather than relying on one platform or provider. It allows compute to go where the energy is—be it a dormant server sitting in a research lab or a computer in a solar-powered home. Instead of constructing more data centers that require electric grids to scale up their infrastructure and capacity, decentralization harnesses energy from existing sources, avoiding adding more power into the mix.
Hardware in harmony
Training AI models is a huge data center sport, synchronized across clusters of closely connected GPUs. But as hardware improvements struggle to keep up with the swift rise in size of large language models, even massive single data centers are no longer cutting it.
Tech firms are turning to the pooled power of multiple data centers—no matter their location. Nvidia, for instance, launched the Spectrum-XGS Ethernet for scale-across networking, which “can deliver the performance needed for large-scale single job AI training and inference across geographically separated data centers.” Similarly, Cisco introduced its 8223 router designed to “connect geographically dispersed AI clusters.”
Other companies are harvesting idle compute in servers, sparking the emergence of a GPU-as-a-Service business model. Take Akash Network, a peer-to-peer cloud computing marketplace that bills itself as the “Airbnb for data centers.” Those with unused or underused GPUs in offices and smaller data centers register as providers, while those in need of computing power are considered as tenants who can choose among providers and rent their GPUs.
“If you look at [AI] training today, it’s very dependent on the latest and greatest GPUs,” says Akash cofounder and CEO Greg Osuri. “The world is transitioning, fortunately, from only relying on large, high-density GPUs to now considering smaller GPUs.”
Software in sync
In addition to orchestrating the hardware, decentralized AI training also requires algorithmic changes on the software side. This is where federated learning, a form of distributed machine learning, comes in.
It starts with an initial version of a global AI model housed in a trusted entity such as a central server. The server distributes the model to participating organizations, which train it locally on their data and share only the model weights with the trusted entity, explains Lalana Kagal, a principal research scientist at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) who leads the Decentralized Information Group. The trusted entity then aggregates the weights, often by averaging them, integrates them into the global model, and sends the updated model back to the participants. This collaborative training cycle repeats until the model is considered fully trained.
But there are drawbacks to distributing both data and computation. The constant back and forth exchanges of model weights, for instance, result in high communication costs. Fault tolerance is another issue.
“A big thing about AI is that every training step is not fault-tolerant,” Osuri says. “That means if one node goes down, you have to restore the whole batch again.”
To overcome these hurdles, researchers at Google DeepMind developed DiLoCo, a distributed low-communication optimization algorithm. DiLoCo forms what Google DeepMind research scientist Arthur Douillard calls “islands of compute,” where each island consists of a group of chips. Every island holds a different chip type, but chips within an island must be of the same type. Islands are decoupled from each other, and synchronizing knowledge between them happens once in a while. This decoupling means islands can perform training steps independently without communicating as often, and chips can fail without having to interrupt the remaining healthy chips. However, the team’s experiments found diminishing performance after eight islands.
An improved version dubbed Streaming DiLoCo further reduces the bandwidth requirement by synchronizing knowledge “in a streaming fashion across several steps and without stopping for communicating,” says Douillard. The mechanism is akin to watching a video even if it hasn’t been fully downloaded yet. “In Streaming DiLoCo, as you do computational work, the knowledge is being synchronized gradually in the background,” he adds.
AI development platform Prime Intellect implemented a variant of the DiLoCo algorithm as a vital component of its 10-billion-parameter INTELLECT-1 model trained across five countries spanning three continents. Upping the ante, 0G Labs, makers of a decentralized AI operating system, adapted DiLoCo to train a 107-billion-parameter foundation model under a network of segregated clusters with limited bandwidth. Meanwhile, popular open-source deep learning framework PyTorch included DiLoCo in its repository of fault tolerance techniques.
“A lot of engineering has been done by the community to take our DiLoCo paper and integrate it in a system learning over consumer-grade internet,” Douillard says. “I’m very excited to see my research being useful.”
A more energy-efficient way to train AI
With hardware and software enhancements in place, decentralized AI training is primed to help solve AI’s energy problem. This approach offers the option of training models “in a cheaper, more resource-efficient, more energy-efficient way,” says MIT CSAIL’s Kagal.
And while Douillard admits that “training methods like DiLoCo are arguably more complex, they provide an interesting tradeoff of system efficiency.” For instance, you can now use data centers across far apart locations without needing to build ultrafast bandwidth in between. Douillard adds that fault tolerance is baked in because “the blast radius of a chip failing is limited to its island of compute.”
Even better, companies can take advantage of existing underutilized processing capacity rather than continuously building new energy-hungry data centers. Betting big on such an opportunity, Akash created its Starcluster program. One of the program’s aims involves tapping into solar-powered homes and employing the desktops and laptops within them to train AI models. “We want to convert your home into a fully functional data center,” Osuri says.
Osuri acknowledges that participating in Starcluster will not be trivial. Beyond solar panels and devices equipped with consumer-grade GPUs, participants would also need to invest in batteries for backup power and redundant internet to prevent downtime. The Starcluster program is figuring out ways to package all these aspects together and make it easier for homeowners, including collaborating with industry partners to subsidize battery costs.
Backend work is already underway to enable homes to participate as providers in the Akash Network, and the team hopes to reach its target by 2027. The Starcluster program also envisions expanding into other solar-powered locations, such as schools and local community sites.
Decentralized AI training holds much promise to steer AI toward a more environmentally sustainable future. For Osuri, such potential lies in moving AI “to where the energy is instead of moving the energy to where AI is.”
From Your Site Articles
Related Articles Around the Web


Seattle fusion startup Avalanche Energy was awarded a share of a $5.2 million contract announced Wednesday from the U.S. Department of Defense to develop compact nuclear batteries.
The award comes from the DARPA Rads to Watts program, which is focused on building long-lasting batteries for defense and space applications where chemical batteries, solar power and refueling are not possible.
Avalanche is focused on engineering micro-fabricated energy cells that turn alpha particles emitted by radioactive material into electricity. The process, the team said, is analogous to solar cells converting photons into electricity.
“The goals are to produce a device that has a long lifetime, and that can produce orders of magnitude more power than current technologies,” said Daniel Velázquez, Avalanche’s physicist and materials science lead. The target is a battery that could continuously power a laptop computer, for example, for many months but weighs roughly 10 pounds.
And the timeline is tight. By the end of the 30-month program, the objective is to validate the physics involved and develop a power-producing prototype.
“It’s very ambitious,” Velázquez said.
Avalanche is leading the team tackling DARPA’s nuclear battery challenge, which includes the University of Utah, Caltech, Los Alamos National Laboratory and McQuaide Microsystems.
Others are also working on nuclear batteries, including Seattle’s Zeno Power. The startup plans to demonstrate its first full-scale radioisotope power system this year and commercially produce nuclear batteries by 2027.
While Avalanche is ultimately working to develop a compact device that creates energy from fusion — the reactions that power the sun — the DARPA project feeds directly into that longer-term goal, Velázquez said. There are direct parallels to capturing energy from a nuclear battery and from fusion reactions.
That should help the company compete in the global race to commercialize fusion power, which could provide nearly limitless clean energy. To support domestic enterprises, the Department of Energy is slated to commit a record-setting $135 million over 18 months to accelerate fusion research, Axios reported today.
Demand for new power is spiking with the expansion of data centers and the shift from fossil fuels to electrification.
Since launching in 2018, Avalanche has pursued multiple lines of revenue. Last month, the company announced it’s part of a team receiving $1.25 million from AFWERX, the innovation arm of the Department of the Air Force, to develop advanced materials for extreme environments.
Other efforts include using its fusion machine to produce neutrons for commercial customers; a Pentagon contract to develop technology for space propulsion; and a state grant to launch FusionWERX, a commercial-scale testing facility for fusion technologies in Eastern Washington.
In February, Avalanche announced $29 million in new funding from investors, bringing its total to more than $105 million across venture capital and government grants — a war chest the company is deploying across fusion, propulsion and now compact nuclear batteries.
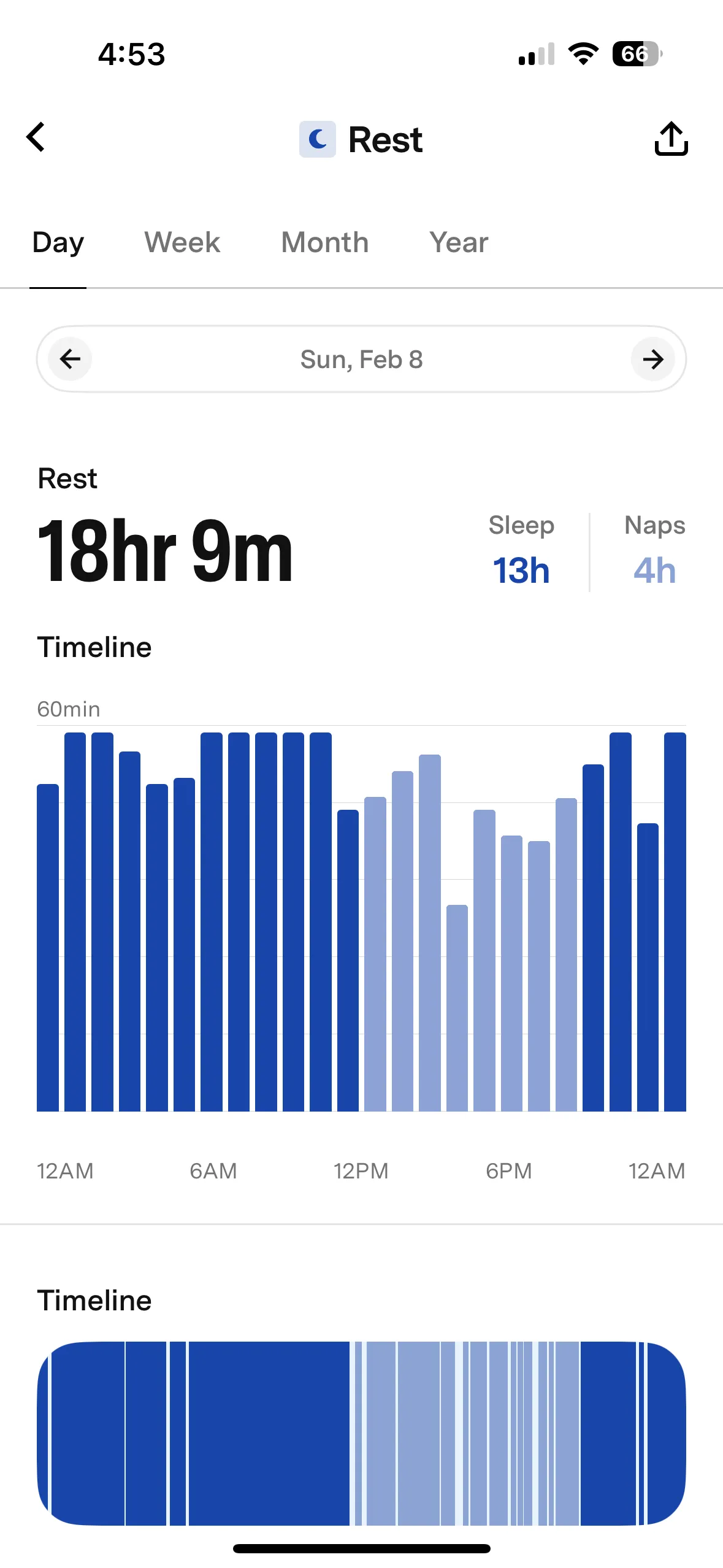
Within the app, you can add safe zones, more pets with Fi trackers, and other users who can also track and monitor the pet. There’s a Health tab where you can add and store things like vet records, receipts, and insurance information, and add vets to easily share your pet’s documents and get appointment reminders. You can also set up the Fi app on your Apple Watch to have even quicker access to monitor your pet’s location, activity, and safety (including Lost Mode) without needing a phone.
When you open the app, you’ll see a map with live tracking showing where your pet is currently, as well as a notification of the last time they were outside and where they were. With the latter, you can pull up stats like location timeline, showing where they were and when. If you dive into any day when the tracker left the home, it will recreate the route, following the path and calculating the distance the pet traveled.
There’s also health-monitoring data from activity and sleep tracking, which is most useful for an indoor-only pet like mine. Like other health-tracking collars, stats for sleep and activity aren’t 100 percent accurate, as the app uses GPS to track movement, categorizing “activity” when the animal is moving and “sleep” when the pet is still for a prolonged period. This means that if Basil was awake but stationary, the app may inaccurately categorize this as sleep.
.png)
Fi Mini App source Molly Higgins
In the Rest tab, you can see sleep metrics, including a daily summary of deep sleep, naps, and interruptions during nightly sleep. You can compare this over time, and the app notes how much more or less Basil slept than the night before. It also compares stats historically, by week, month, and year, so you can track trends and better understand your pet’s normal sleep schedule.
The Activity tab is similar, tracking activity by day, week, and month, noting in the day’s timeline when the pet was most active and for how long. This also compares activity to the day before. I liked looking at the weekly report, comparing days during the week to see which he was most active during and if any patterns in activity popped up.
For example, I noticed that his sleep-versus-activity schedule was similar to mine, except he was active between 4:45 and 6:30 am (while I was still asleep), because that’s when his automatic feeder goes off for breakfast and my roommate is getting ready to leave for work. He was most active in the evenings, when I feed him dinner, have dedicated playtime, and my roommates are home, so there’s more activity to keep him awake. Historical comparison is also a super helpful way to track whether your pet is sleeping more or becoming more lethargic—an early warning sign of a bigger health problem.
Not Without Its Quirks
Since my cat is indoor-only, I ran some experiments to track location, using GPS on both the Fi Mini tracker and my phone. I also had a friend take the tracker out without my phone nearby to see whether I’d get pinged that “Basil” had left the safe zone.
Although it is better than not being alerted at all, the Fi’s GPS has limitations (as did the Tractive tracker I tested). It needs a strong signal to communicate with cell towers for accurate location. If your phone is close to the smart collar (via Bluetooth), it uses that instead of the Fi’s GPS, making it more accurate and alerting quicker. If the pet gets loose and is out of range of your phone, it uses the collar’s cellular antenna (in this case, Verizon cell towers). But because the Fi’s antenna isn’t as strong as a phone’s, location accuracy is lower, and the connection can be very spotty, especially if your pet is in the country or on acreage where cell towers are farther away.


Eurail B.V., a European travel operator that provides digital passes covering 33 national railways, says attackers stole the personal information of over 300,000 individuals in a December 2025 data breach.
Eurail is a Netherlands-based company that sells Interrail and Eurail passes for multi-country train travel across Europe, passes that are also available to young Europeans through the EU’s DiscoverEU program.
When it disclosed the incident in February, the company said the attackers gained access to travelers’ sensitive information, including full names, passport details, ID numbers, bank account IBANs, health information, and contact details (email addresses, phone numbers), after breaching its customer database.

Eurail also warned at the time that the threat actors had published a sample of the stolen data on Telegram and were attempting to sell it on the dark web.
“The evidence showed that an unauthorized actor transferred files from our network on December 26, 2025,” the European train travel company said in breach notification letters sent to affected individuals on March 27.
“We reviewed the files involved and, on February 25, 2026, determined that they contained some of your information. The information included your name and passport number.”
The same day, Eurail revealed in a filing with the Office of Oregon’s Attorney General that the resulting data breach impacted 308,777 individuals.

While Eurail said that it didn’t store financial information or passport photocopies on the compromised systems, the European Commission warned in a separate alert that this type of data (as well as health information) may have been exposed for young travelers who received a Pass through the DiscoverEU program.
Eurail told customers whose information was exposed in the breach to remain vigilant against potential phishing attacks and scams, and advised them to update their Rail Planner app account passwords and reset them on any other platform where they’re also used.
The company added that customers should monitor their bank account activity and report any suspicious transactions to their bank as soon as possible.
Last month, the European Commission also confirmed a data breach after the Europa.eu web platform was hacked in a cyberattack claimed by the ShinyHunters extortion gang.

Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.


Wi-Fi 8 is already taking shape, and while it won’t raise peak speeds beyond Wi-Fi 7, it promises something just as important: more reliable, lower-latency wireless performance where it actually matters.

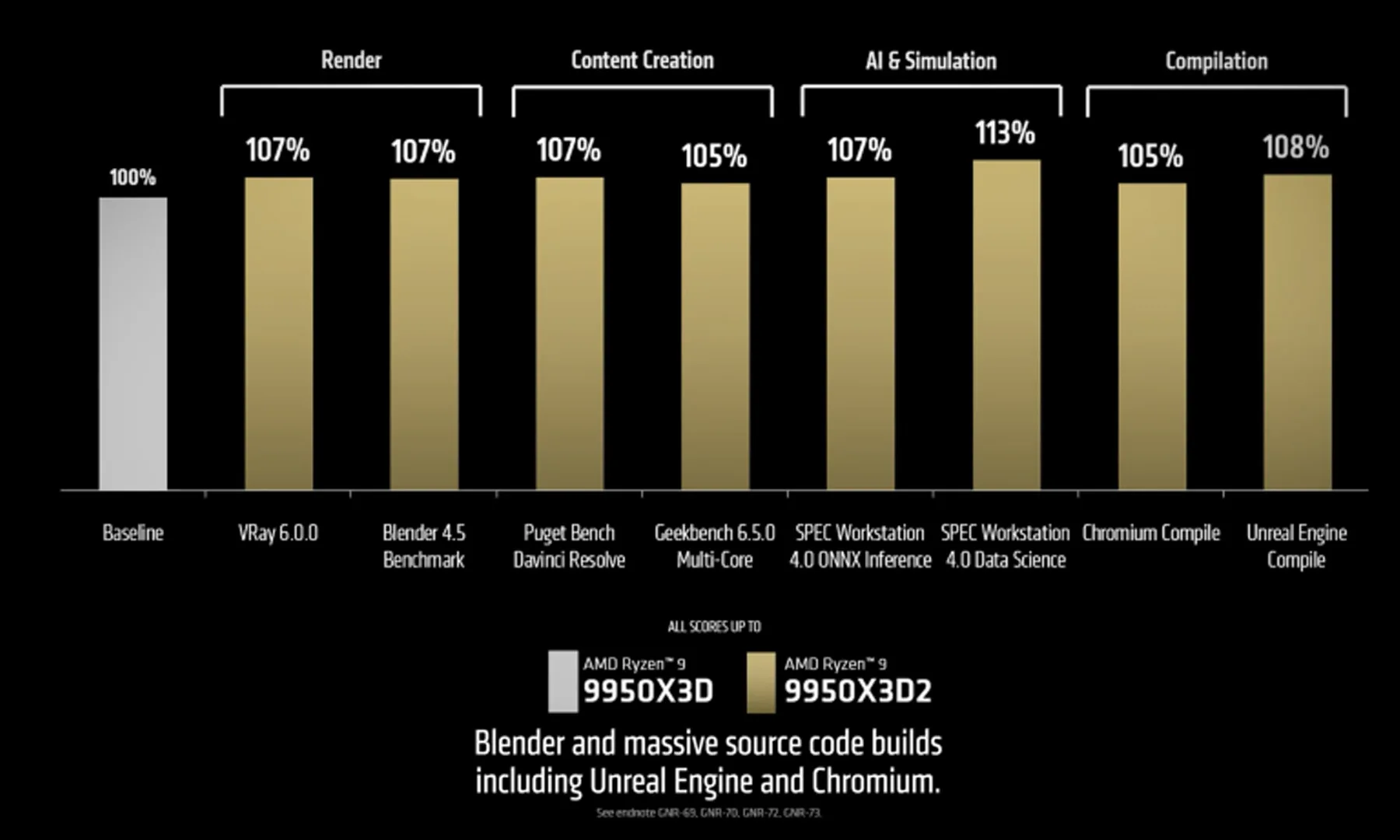
AMD has locked in the price for its Ryzen 9 9950X3D2, and it lands high at $899. This is a flagship desktop chip aimed at people who rely on fast systems every day and don’t want to rebuild everything just to get there.
The processor introduces a dual 3D V-Cache setup, which AMD is using to push both gaming and heavy workloads forward at the same time. It also fits into the current AM5 ecosystem, so users with compatible boards and memory can upgrade without replacing the core of their system.
It goes on sale April 22, though there’s no detail yet on how widely it will be available at launch.
Who this $899 chip is for
At $899, this chip sits well outside the mainstream. AMD is going after creators, developers, and power users who notice slowdowns immediately and are willing to pay to avoid them.
The pricing also signals where this part sits in the stack. It’s a top-tier option in the Ryzen 9000 lineup, built to prioritize sustained performance in demanding scenarios rather than broad affordability.
There’s a clear tradeoff here, where you’re paying more upfront to reduce waiting time during real work.
How dual V-Cache changes things
The dual 3D V-Cache design builds on AMD’s earlier work with stacked cache, but pushes it further. Instead of leaning mostly toward gaming gains, this version is meant to handle a wider mix of tasks without compromise.
That shift is important because earlier X3D chips often felt specialized. This one is positioned as more balanced, giving users who split time between games and production workloads a stronger reason to consider it.

Still, AMD hasn’t shared detailed performance figures in this material, so it’s not yet clear how much improvement shows up across different types of work.
Should you upgrade now
Compatibility is one of the more practical advantages here. The Ryzen 9 9950X3D2 works with existing AM5 motherboards and memory, which makes it a simpler upgrade for current users.
That helps take some pressure off the high asking price, especially if you’re already invested in the platform. Instead of planning a full rebuild, you can focus on swapping the processor and moving on.
With the April 22 release approaching, the decision comes down to whether you need the extra headroom now or can wait for more data.

Bitcoin Depot Reports $3.7M Loss after Breach of Corporate Wallets

Offset Faces Lawsuit Over $100K Casino Debt Drama
Northern Irish passport holder shows reality of new EES system at popular Spanish spot

Why Israel is blocking foreign journalists from entering

Bitcoin: We’re Entering The Most Dangerous Phase

Alan Cumming Brands Baftas Ceremony A ‘Triggering S**tshow’

Which 2 would you pick? #finance #investmenttips #investmentadvice #investmentforbeginners #trader

google pay pocket money kya hai | how to use google pay pocket money | gpay pocket money new update

WARNING: Bitcoin is 11 Days Away from a MASSIVE Move! (ETH, XRP, SOL, AVAX)
-

 NewsBeat7 days ago
NewsBeat7 days agoSteven Gerrard disagrees with Gary Neville over ‘shock’ Chelsea and Arsenal claim | Football
-

 Business7 days ago
Business7 days agoNo Jackpot Winner and $194 Million Prize Rolls Over
-

 Fashion6 days ago
Fashion6 days agoWeekend Open Thread: Spanx – Corporette.com
-

 Business5 days ago
Business5 days agoExpert Picks for Every Need
-

 Business4 days ago
Business4 days agoThree Gulf funds agree to back Paramount’s $81 billion takeover of Warner, WSJ reports
-

 Sports5 days ago
Sports5 days agoIndia men’s 4x400m and mixed 4x100m relay teams register big progress | Other Sports News
-

 Tech2 days ago
Tech2 days agoHow Long Can You Drive With Expired Registration? What Florida Law Says
-
Business4 days ago
No Jackpot Winner, Prize to Climb to $231 Million
-

 Fashion3 days ago
Fashion3 days agoMassimo Dutti Offers Inspiration for Your Summer Mood Board
-

 Fashion2 days ago
Fashion2 days agoLet’s Discuss: DEI in 2026
-

 Tech7 days ago
Tech7 days agoCommonwealth Fusion Systems leans on magnets for near-term revenue
-
Politics6 days ago
Wings Over Scotland | The quality of mercy
-

 Business5 days ago
Business5 days agoAkebia Therapeutics, Inc. (AKBA) Discusses Pipeline Progress and Strategic Focus on Kidney Disease Treatments at R&D Day – Slideshow
-

 Fashion7 days ago
Fashion7 days agoStatement Sunglasses: The Accessory Shaping Modern Fashion
-

 Crypto World23 hours ago
Crypto World23 hours agoBitcoin recovers as US and Iran Agree a Ceasefire Deal
-

 Politics6 days ago
Politics6 days agoEast Jerusalem Palestinian families eviction orders
-

 Sports7 days ago
Sports7 days agoWhich German players will make final cut?
-

 Fashion7 days ago
Fashion7 days agoFor Love & Lemons’ Spring 2026 Line is for the Romantics
-

 Politics6 days ago
Politics6 days agoWhy so many children are now classified as ‘disabled’
-

 Fashion7 days ago
Fashion7 days agoCoffee Break: Santa Croce Tote
You must be logged in to post a comment Login