When enterprises fine-tune LLMs for new tasks, they risk breaking everything the models already know. This forces companies to maintain separate models for every skill.
Researchers at MIT, the Improbable AI Lab and ETH Zurich have developed a new technique that enables large language models to learn new skills and knowledge without forgetting their past capabilities.
Their technique, called self-distillation fine-tuning (SDFT), allows models to learn directly from demonstrations and their own experiments by leveraging the inherent in-context learning abilities of modern LLMs. Experiments show that SDFT consistently outperforms traditional supervised fine-tuning (SFT) while addressing the limitations of reinforcement learning algorithms.
For enterprise applications, the method enables a single model to accumulate multiple skills over time without suffering from performance regression on earlier tasks. This offers a potential pathway for building AI agents that can adapt to dynamic business environments, gathering new proprietary knowledge and skills as needed without requiring expensive retraining cycles or losing their general reasoning abilities.
Advertisement
The challenge of continual learning
Once an LLM is trained and deployed, it remains static. It does not update its parameters to acquire new skills, internalize new knowledge, or improve from experience. To build truly adaptive AI, the industry needs to solve “continual learning,” allowing systems to accumulate knowledge much like humans do throughout their careers.
The most effective way for models to learn is through “on-policy learning.” In this approach, the model learns from data it generates itself allowing it to correct its own errors and reasoning processes. This stands in contrast to learning by simply mimicking static datasets. Without on-policy learning, models are prone to “catastrophic forgetting,” a phenomenon where learning a new task causes the model to lose its past knowledge and ability to perform previous tasks.
However, on-policy learning typically requires reinforcement learning (RL), which depends on an explicit reward function to score the model’s outputs. This works well for problems with clear outcomes, such as math and coding. But in many real-world enterprise scenarios (e.g., writing a legal brief or summarizing a meeting), defining a mathematical reward function is difficult or impossible.
RL methods also often fail when trying to teach a model entirely new information, such as a specific company protocol or a new product line. As Idan Shenfeld, a doctorate student at MIT and co-author of the paper, told VentureBeat, “No matter how many times the base model tries, it cannot generate correct answers for a topic it has zero knowledge about,” meaning it never gets a positive signal to learn from.
Advertisement
The standard alternative is supervised fine-tuning (SFT), where the model is trained on a fixed dataset of expert demonstrations. While SFT provides clear ground truth, it is inherently “off-policy.” Because the model is just mimicking data rather than learning from its own attempts, it often fails to generalize to out-of-distribution examples and suffers heavily from catastrophic forgetting.
SDFT seeks to bridge this gap: enabling the benefits of on-policy learning using only prerecorded demonstrations, without needing a reward function.
How SDFT works
SDFT solves this problem by using “distillation,” a process where a student model learns to mimic a teacher. The researchers’ insight was to use the model’s own “in-context learning” (ICL) capabilities to create a feedback loop within a single model.
In-context learning is the phenomenon where you provide the LLM with a difficult task and one or more demonstrations of how similar problems are solved. Most advanced LLMs are designed to solve new problems with ICL examples, without any parameter updates.
Advertisement
During the training cycle, SDFT employs the model in two roles.
The teacher: A frozen version of the model is fed the query along with expert demonstrations. Using ICL, the teacher deduces the correct answer and the reasoning logic required to reach it.
The student: This version sees only the query, simulating a real-world deployment scenario where no answer key is available.
When the student generates an answer, the teacher, which has access to the expert demonstrations, provides feedback. The student then updates its parameters to align closer to the teacher’s distribution.
This process effectively creates an on-policy learning loop by combining elements of SFT and RL. The supervision comes not from a static dataset, but from the model’s own interaction and outputs. It allows the model to correct its own reasoning trajectories without requiring an external reward signal. This process works even for new knowledge that RL would miss.
Advertisement
SDFT in action
To validate the approach, the researchers tested SDFT using the open-weight Qwen 2.5 model on three complex enterprise-grade skills: science Q&A, software tool use, and medical reasoning.
The results showed that SDFT learned new tasks more effectively than standard methods. On the Science Q&A benchmark, the SDFT model achieved 70.2% accuracy, compared to 66.2% for the standard SFT approach.
Contrary to SFT, SDFT preserves the model’s original knowledge while learning new tasks and knowledge (source: arXiv)
More important for enterprise adoption is the impact on catastrophic forgetting. When the standard SFT model learned the science task, its ability to answer general questions (such as logic or humanities) collapsed. In contrast, the SDFT model improved on the science task while holding its “Previous Tasks” score steady at 64.5%. This stability suggests companies could specialize models for specific departments (e.g., HR or Legal) without degrading the model’s basic common sense or reasoning capabilities.
Advertisement
The team also simulated a knowledge injection scenario, creating a dataset of fictional “2025 Natural Disasters” to teach the model new facts. They tested the model on indirect reasoning questions, such as “Given the floods in 2025, which countries likely needed humanitarian aid?”
Standard SFT resulted in a model that memorized facts but struggled to use them in reasoning scenarios. The SDFT model, having internalized the logic during training, scored 98% on the same questions.
Finally, the researchers conducted a sequential learning experiment, training the model on science, tool use, and medical tasks one after another. While the standard model’s performance oscillated, losing previous skills as it learned new ones, the SDFT model successfully accumulated all three skills without regression.
SDFT can learn different skills sequentially while preserving its previous knowledge (source: arXiv)
Advertisement
This capability addresses a major pain point for enterprises currently managing “model zoos” of separate adapters for different tasks.
“We offer the ability to maintain only a single model for all the company’s needs,” Shenfeld said. This consolidation “can lead to a substantial reduction in inference costs” because organizations don’t need to host multiple models simultaneously.
SDFT limitations and availability
The code for SDFT is available on GitHub and ready to be integrated into existing model training workflows.
“The SDFT pipeline is more similar to the RL pipeline in that it requires online response generation during training,” Shenfeld said. They are working with Hugging Face to integrate SDFT into the latter’s Transformer Reinforcement Learning (TRL) library, he added, noting that a pull request is already open for developers who want to test the integration.
Advertisement
For teams considering SDFT, the practical tradeoffs come down to model size and compute. The technique requires models with strong enough in-context learning to act as their own teachers — currently around 4 billion parameters with newer architectures like Qwen 3, though Shenfeld expects 1 billion-parameter models to work soon. It demands roughly 2.5 times the compute of standard fine-tuning, but is best suited for organizations that need a single model to accumulate multiple skills over time, particularly in domains where defining a reward function for reinforcement learning is difficult or impossible.
While effective, the method does come with computational tradeoffs. SDFT is approximately four times slower and requires 2.5 times more computational power (FLOPs) than standard fine-tuning because the model must actively generate its own answers (“rollouts”) during training to compare against the teacher. However, the researchers note that because the model retains knowledge better, organizations may avoid the costly multi-stage retraining processes often required to repair models that suffer from catastrophic forgetting.
The technique also relies on the underlying model being large enough to benefit from in-context learning. The paper notes that smaller models (e.g., 3 billion parameters) initially struggled because they lacked the “intelligence” to act as their own teachers.
However, Shenfeld said that the rapid improvement of small models is changing this dynamic. “The Qwen 2.5 3B models were too weak, but in some experiments we currently do, we found that the Qwen 3 4B model is strong enough,” he said. “I see a future where even 1B models have good enough ICL capabilities to support SDFT.”
Advertisement
Ultimately, the goal is to move beyond static snapshots toward systems that improve through use.
“Lifelong learning, together with the ability to extract learning signal from unstructured user interactions… will bring models that just keep and keep improving with time,” Shenfeld said.
“Think about the fact that already the majority of compute around the world goes into inference instead of training. We have to find ways to harness this compute to improve our models.”
Photo credit: Wall Street Journal The Wall Street Journal recently got a rare look inside Apple Park as part of the company’s 50th anniversary celebrations, with reporters joining Tim Cook for a walk through an archive that Cook himself admitted he had barely visited until preparations for the milestone began pulling decades of stored material back into the light.
The first thing that caught his eye was Apple’s original patent filing for the Apple II, a single document that Cook said effectively opened the floodgates for what eventually became more than 140,000 patent applications. A small drawing on a piece of paper that quietly set the direction for everything that followed.
MIGHT TAKES FLIGHT — MacBook Air with the M5 chip packs blazing speed and powerful AI capabilities into an incredibly portable design. With Apple…
SUPERCHARGED BY M5 — With its faster CPU and unified memory, the M5 chip delivers even more performance and fluidity across apps, making…
APPLE INTELLIGENCE — Apple Intelligence is the personal intelligence system that helps you write, express yourself, and get things done…
An early 2001 iPod prototype came next, and Cook recalled the feeling of holding it for the first time a few years after joining the company. The idea of carrying a thousand songs in your pocket felt genuinely unbelievable at a moment when most people were still rotating five CD changers on road trips. He remembered loading a Beatles song the moment he got his hands on one and how that little white device changed his daily commute.
The 2007 iPhone launch remains Cook’s favorite moment in the company’s history, and a circuit board from one of the first working prototypes sitting on the table illustrated just how far the engineering team had to travel to get there. It looked more like a cutting board than something destined for a pocket, an early proof of concept that needed everything working together before the whole thing could be miniaturized. Cook noted that even inside Apple, employees were walking around with early models watching keys and coins scratch the plastic casing. Steve Jobs made the call to switch to glass within a matter of months, a timeline Cook described as close to impossible, comparing it to trying to land on the moon between January and June.
Cook touched on projects that never made it, framing each one as something the team learned from before showing up the next morning and getting back to work. That steadiness, he suggested, is what carried the company through five decades of setbacks and breakthroughs alike. An early Apple Watch prototype rounded out the tour, and Cook’s attention shifted forward, pointing to the combination of hardware, software, and services as the space where the next significant leap is most likely to come from.
NASA is going back to the Moon! We’ll follow the crew of Artemis II every step of the way.
Day 1 – Liftoff!
After resolving a last-minute communications issue with the Flight Termination System (FTS), the Artemis II Space Launch System (SLS) rocket lifted off from Launch Complex 39B at NASA’s Kennedy Space Center in Florida at 6:35 PM EDT.
Main engine cutoff (MECO) for the SLS rocket occurred at 6:43 PM, placing the Orion spacecraft and crew members Reid Wiseman, Victor Glover, Christina Koch, and Jeremy Hansen safely into orbit around the Earth. Just before 7:00 PM, all four solar array “wings” were successfully deployed from the European Service Module.
Advertisement
The next major milestones are the perigee and apogee raise maneuvers — two engine burns which will put the Orion spacecraft into a higher orbit, necessary for the eventual trans-lunar injection (TLI) burn which will put the vehicle on course for the Moon.
April is a strong month for horror with some of the biggest franchises and originals available to watch from the comfort of your living room. The month is typically associated with pranks and comedies, but if you want something more macabre, I’ve got you covered.
Here are my 7 top horror picks arriving across streaming services this April.
Advertisement
Article continues below
Alien
Alien Trailer HD (Original 1979 Ridley Scott Film) Sigourney Weaver – YouTube
When: April 1 Where: HBO Max (US); Disney+ (UK, AU)
Ridley Scott’s iconic sci-fi horror Alien is streaming throughout April, if you want to revisit one of the greats. And if you haven’t seen this masterpiece of a movie, now is the perfect time.
Advertisement
Alien is well-loved for its groundbreaking effects in the 70s, its iconic Xenomorph creature design, and the atmospheric tension that builds throughout. Other Alien movies can also be found on HBO Max and Disney+, but you really can’t beat the first one, even if some people do think Aliens was better!
Sign up for breaking news, reviews, opinion, top tech deals, and more.
2025’s Deathstalker is a remake of the 1983 movie of the same name. Those looking for dark fantasy won’t want to miss this addition to Shudder’s library, as an alternative to some of the more modern horror movies it offers.
Advertisement
Daniel Bernhardt and Patton Oswalt lead the cast of the remake, which follows a powerful swordsman known as Deathstalker after he recovers a cursed amulet from a corpse-strewn battlefield. When he’s marked by dark magic and hunted by monstrous assassins, he must face the rising evil and break the curse before it’s too late.
Five Nights at Freddy’s 2
Five Nights at Freddy’s 2 | Official Trailer – YouTube
When: April 3 Where: Peacock (US); rent or buy (AU)
Are you ready for Freddy? The sequel arrives on Peacock in April, following a successful box office run. Despite being panned critically, Freddy Fazbear and friends continue to have a dedicated fanbase, so if you’re part of that, you’ll be happy to know it’s coming to streaming.
Advertisement
The adaptation of the successful horror game is set a year and a half after the previous movie, where we follow young Abby Schmidt as she gets manipulated by the Marionette, an animatronic from the original Freddy Fazbear’s Pizza restaurant, who wants revenge against her parents. The Marionette is one of the creepiest figures in the games, and now you get to see it come to life on film.
Earwig
EARWIG | Official Trailer | Now showing on MUBI – YouTube
Earwig is a strange movie, but when you’re a horror fan, that’s often a compliment. Set in a bleak post-war Europe, we follow a middle-aged man, Albert, as he cares for a young girl named Mia, who has no teeth.
Every day, he makes her new dentures out of ice, and one day, he’s told by a mysterious voice to prepare Mia for the outside world, where she has never been. Described as both a melodrama and a body horror, it’s a disturbing movie that may divide fans, but I can certainly say it’s stuck with me for a while.
When: April 10 Where: Netflix (US); Paramount+ (UK); rent or buy (AU)
2022’s Scream is the fifth entry into the slasher franchise, and why it wasn’t just called Scream 5 continues to baffle me. Anyway, don’t let that deter you; it is a very strong movie and one of my favorites in the series.
Despite the name, it’s not a remake; instead, it focuses on a new core cast of characters, though original stars like Courteney Cox, David Arquette, and Neve Campbell reprise their roles.
Advertisement
A Quiet Place Part II
A Quiet Place Part II (2021) – Final Trailer – Paramount Pictures – YouTube
When: April 11 Where: Netflix (US); Paramount+ (UK); rent or buy (AU)
Ahead of A Quiet Place Part III, which is due next year, why not catch up with the second in the successful horror series? It’s arriving on Netflix for US audiences, while UK audiences can watch on Paramount+.
A Quiet Place Part II continues to focus on the Abbott family (except for John Kransinski’s Lee) as they try to survive in a post-apocalyptic world inhabited by blind aliens with an acute sense of hearing, so it’s critical that they monitor how much noise they make. Horror doesn’t get much more tense than this.
Dolly
Dolly – Official Trailer (2026) Fabianne Therese, Seann William Scott, and Max the Impaler. – YouTube
Finally, at the end of April, we have Dolly. Creepy dolls are a staple in the horror genre, just look at Annabelle and Chucky, but this movie has got me creeped out by the synopsis alone.
Advertisement
Terror strikes when Macy and her boyfriend Chase are attacked while camping, and Macy is abducted by a tall, menacing figure who treats her as if she were a living doll. NWA wrestler Max the Impaler plays said figure, making it their movie debut.
You know what they say — you can’t keep a good website down. OldVersion.com, the repository of outdated software that has been serving up old versions of tools you need for the last twenty-five years, is not going away as we reported last year. Not only is it sticking around, it’s gotten a retro facelift inspired by Windows 3.1 or OS/2. Mostly Windows, given the screensaver, but we’ll let you find that for yourself.
We’re thrilled to see that OldVersion has gotten the support they need to keep going after running into financial troubles. According to founder Alex Levine, some of that support came as a result of the Hackaday article reporting on the then-upcoming closure, so kudos to you guys for stepping up.
While we absolutely love the retro redesign of the new website, that’s one thing notably lacking — an obvious donation button. Well, that and old-school HTTP support so you can get on with your retromachines, but that, at least, is in the works according to the site roadmap. It’s a little weird that in this year of the common era 2026 you have to do extra work to give up on HTTPS functionality, but it is the way it is.
In the meantime, the site is fully usable as long as you have HTTPS capability, or go through a proxy. Perhaps you could use this ESP8266 code to get started making one, if you don’t want to embarrass your old computer by using something more powerful than it as a pass-through.
Advertisement
Speaking of proxies, if old versions of software aren’t enough for you, how about an old version of the internet? We heard you like old versions, so you can visit an old version of OldVersion!
Note that if you’re reading this after 01/04/2026, the look-and-feel of OldVersion.com may not match what’s depicted here.
SpaceX is looking to the heavens for its upcoming initial public offering based on a $1.75 trillion valuation, according to confidential paperwork filed with the US Securities and Exchange Commission.
As reported by Bloomberg, the draft IPO registration is the first step toward a possible June offering that could raise approximately $75 billion. The filing allows the company to get feedback from the SEC before the information is released publicly.
The IPO may be open to more people than just the wealthiest investors. According to a report by The Motley Fool, SpaceX plans to allocate around 30% of the initial shares to “retail investors,” meaning individual investors. Normal retail allocation tends to be around 10% of shares.
Advertisement
A SpaceX representative didn’t immediately respond to a request for comment.
Why a SpaceX IPO is a big deal
Spaceflight is an incredibly expensive endeavor; SpaceX gets billions of dollars from the US government to launch satellites and help keep NASA’s programs running. Almost a year ago, the company set a target of launching every other day through the end of 2025 and ended up launching a record 165 orbital flights.
But SpaceX is no longer just a high-flying rocket company. Its Starlink division provides data access to homes, remote locations, airlines and direct to many mobile phones in areas where there’s no cellular coverage. It also recently acquired xAI, another of Elon Musk’s companies, and owns the social media site X (formerly Twitter).
It’s the AI angle that seems to be driving up the company’s valuation ahead of the IPO. The xAI all-stock acquisition valued the company and SpaceX at $1.25 trillion. This year, OpenAI and Anthropic PBC are also expected to go public.
Advertisement
Although those numbers are eye-popping, the company has plenty of challenges before it can get off the launchpad.
Starlink has announced a plan to send up new V3 third-generation satellites that should bring gigabit internet speeds to its network, but those won’t be ready until 2027. Getting them up requires SpaceX’s heavy-duty Spacecraft vehicle, which has had limited success in testing so far. In the meantime, its current Starlink satellites have been exploding in orbit as recently as this week.
And for xAI, the skies aren’t exactly clear despite the current fervor for all things AI. Musk announced in mid-March that “xAI was not built right first time around, so is being rebuilt from the foundations up.” And the company is being sued by three teen girls and their guardians for “devastating” harm caused by its Grok AI generating child sexual abuse images.
WhatsApp has notified approximately 200 users, primarily in Italy, that they were tricked into installing a counterfeit version of the messaging app that was actually government spyware. The fake application was built by SIO, an Italian surveillance technology company that develops spyware for law enforcement and intelligence agencies through its subsidiary ASIGINT. WhatsApp said it had proactively identified the affected users, logged them out of their accounts, warned them about the privacy risks, and urged them to delete the fake client and install the official app from a trusted source. The company told TechCrunch it also plans to send a formal legal demand to SIO to halt any malicious activity linked to the campaign.
The disclosure, first reported by Italian newspaper La Repubblica and news agency ANSA, marks the second time in little more than a year that WhatsApp has publicly named a spyware vendor operating against its users in Italy. In early 2025, WhatsApp alerted around 90 users, including journalists and pro-immigration activists, that they had been targeted by Paragon Solutions, a U.S.-Israeli surveillance firm whose flagship product, Graphite, was deployed by Italy’s domestic and foreign intelligence services. That revelation triggered a political crisis in Rome. Italy’s parliamentary intelligence oversight committee, COPASIR, confirmed the use of Graphite and found that seven Italians had been targeted. Paragon subsequently cut ties with Italy’s spy agencies after the government declined to verify whether the spyware had been used against a specific journalist, Francesco Cancellato of the news site Fanpage.
SIO’s spyware operates through a different model. The malware, identified in its own code as Spyrtacus, is embedded in fake applications designed to look like legitimate software. Researchers have found 13 different samples of Spyrtacus dating back to 2019, with the most recent from late 2024. Previous versions impersonated Android apps from Italian mobile providers TIM, Vodafone, and WINDTRE, as well as earlier fake versions of WhatsApp itself. TechCrunch first exposed SIO’s Android distribution campaign in February 2025. The latest operation, targeting iPhones, represents an expansion of the tactic to Apple’s ecosystem. Once installed, Spyrtacus can steal text messages, chat histories, and call logs, as well as record audio and video directly from the device’s microphone and camera.
The delivery mechanism is as revealing as the malware itself. In Italy, authorities routinely obtain cooperation from mobile carriers, who send phishing links to their own customers on behalf of law enforcement. The target receives what appears to be a routine update notification from their provider, directing them to install what looks like a standard WhatsApp update. The Italian justice ministry has maintained a price list and catalogue showing how authorities can compel telecom companies to send such messages, a system that effectively turns the mobile network itself into a distribution channel for state surveillance tools. The cost of renting spyware in Italy is remarkably low: as of late 2022, law enforcement could access these tools for as little as €150 per day, without the large upfront acquisition costs that typically limit deployment in other countries.
Italy’s position as a spyware hub is unusual among Western democracies. Companies including Hacking Team, Cy4Gate, RCS Lab, and Raxir have all been based in the country, drawn by a legal framework that provides a formal statutory basis for the “captatore informatico,” or computer interceptor, effectively state-sanctioned trojan software. Fabio Pietrosanti, president of the Hermes Center for Transparency and Digital Human Rights, has said thatspyware is deployed more frequently in Italy than anywhere else in Europebecause the low cost and permissive regulation make it accessible to a far wider range of law enforcement agencies than in neighbouring countries. The result is an ecosystem in which municipal police forces, not just national intelligence agencies, can commission surveillance operations against individuals.
Advertisement
WhatsApp spokesperson Margarita Franklin told TechCrunch the company could not yet confirm whether the 200 affected users included journalists or members of civil society. “Our priority has been protecting the users who may have been tricked into downloading this fake iOS app,” she said. The company did not specify whether it had referred the matter to Italian prosecutors or to any regulatory authority. Apple and SIO did not respond to requests for comment.
The legal landscape around commercial spyware has shifted substantially in the past year. In May 2025, a California jury ordered NSO Group, the Israeli maker of Pegasus, to pay WhatsApp $167 million in punitive damages after finding it had enabled hacks of approximately 1,400 users through zero-click attacks. A federal judge later reduced the award to $4 million but imposed a permanent injunction barring NSO from targeting WhatsApp’s infrastructure. NSO has appealed. WhatsApp’s parent company Meta described the verdict as a landmark, and it has since expanded its legal strategy against the broader surveillance industry. The formal legal demand WhatsApp intends to send SIO follows the same pattern: use litigation and public disclosure as deterrents against companies that profit from compromising encrypted messaging platforms.
The proliferation of spyware vendors presents a challenge that extends well beyond any single platform. Apple has sent mercenary-spyware threat notifications to users in more than 150 countries since 2021, alerting individuals it believes have been individually targeted by state-sponsored attacks. In April 2025, Apple notified the Italian journalist Ciro Pellegrino, one of the Paragon victims, that he had been targeted. The notification systems run by Apple and WhatsApp now represent the primary mechanism by which victims of government surveillance learn they have been compromised, a function that was once the exclusive domain ofthe cybersecurity industry’s specialist researchers.
The global lawful-interception market was valued at $4 billion in 2023 and is projected to reach $15 billion by 2032, growing at roughly 16 per cent annually. That growth is being driven not by the Pegasus-style zero-click exploits that attract headlines, but by the kind of low-cost, phishing-based tools that SIO sells. The barrier to entry for government surveillance has dropped to the point where a local police department in a midsize Italian city can commission the same class of spyware deployment that was once the preserve of national intelligence agencies. Thegap between regulatory ambition and enforcement capacityin Europe means that the legal frameworks governing these tools have not kept pace with the speed at which they are being adopted.
Advertisement
What makes the SIO case distinct from the Paragon scandal is the method. Paragon’s Graphite used zero-click exploits that required no action from the target. SIO’s Spyrtacus requires the target to install a fake application, a social-engineering approach that relies on trust in the carrier and familiarity with routine app updates. The fact that Italian telecoms participate in the delivery chain, sending phishing messages to their own subscribers at the state’s request, turns the mobile infrastructure itself into an instrument of surveillance. It is one thing for a government to hack a phone. It is another for the phone company to help.
WhatsApp’s decision to publicly name SIO and notify the affected users followsthe broader pattern of tech platforms asserting themselves as counterweights to state surveillancein ways that would have been unthinkable a decade ago. The company is not merely patching a vulnerability. It is identifying the vendor, alerting the victims, and threatening legal action, a posture that positions a messaging app owned by Meta as a more effective check on government spyware abuse than any European regulatory body has managed to date. Whether that dynamic is reassuring or alarming depends on your view of where the responsibility for protecting citizens from their own governments should ultimately rest.
For the 200 users in Italy who received WhatsApp’s notification, the immediate question is narrower: who authorised the surveillance, and on what legal basis? The answer may never become public. Italy’s lawful-intercept framework permits the use of these tools under judicial oversight, but the oversight mechanisms haverepeatedly proven inadequate to prevent abuse. The Paragon scandal demonstrated that intelligence agencies could target journalists and activists under the cover of lawful authority. The SIO case suggests the problem runs deeper, extending to less prominent vendors, cheaper tools, and a distribution model that exploits the trust citizens place in their mobile carriers. The spyware industry does not need zero-click exploits to be dangerous. It just needs a convincing notification from your phone company.
Under a new state regulation, venture capital firms operating in California were supposed to submit demographic data about their portfolio companies, including the gender and race of startup founders they backed. But amid public criticism from some tech leaders, the California agency administering the new requirement suspended it just before the Wednesday deadline for firms to make their first disclosures.
“The California Department of Financial Protection and Innovation (DFPI) has announced that it plans to initiate rulemaking in response to comments by various stakeholders relating to the Fair Investment Practices by Venture Capital Companies Law,” the state agency posted on its website in mid-March. “Implementation and enforcement of the [law] will be suspended pending completion of the rulemaking and until final regulations are in place.”
California lawmakers first passed the measure in 2023, and it was signed into law shortly thereafter by Governor Gavin Newsom. For decades, women and people of color have received only a small share of overall startup funding relative to their representation in the US population. Lawmakers hoped putting more public scrutiny on investment decisions would help foster greater equity in the market, including for people who are disabled, retired military, or LGBTQ+.
The law called for venture capital and some other investment firms to file annual reports starting March 1 of last year about the overall makeup of the founding teams they had invested in and the amount of money they provided to diverse founders. Firms were meant to collect the demographic data through a voluntary survey that was then anonymized. California authorities planned to publish the filings online. Lawmakers amended the law in 2024 to delay reporting until April 1, 2026 and enable the state to levy daily fines for noncompliance.
Advertisement
The California Department of Financial Protection and Innovation did not immediately respond to a request for comment on the authority it used to sidestep the deadline set by lawmakers. Newsom’s office also didn’t immediately respond to a request for comment.
Financiers focused on funding entrepreneurs from underrepresented backgrounds had supported the law. But the National Venture Capital Association, the tech investment industry’s leading trade group, opposed it. The group argued that voluntary data collection would inflate diversity statistics and that publishing inaccurate data could lead to unfair attacks on investors genuinely trying to tackle diversity issues. Over the past year, the Trump administration has defunded and attacked diversity, equity, and inclusion, or DEI, initiatives in both the public and private sectors, leading many businesses and organizations to pull back from them.
In February, the venture capital association wrote to Newsom asking for the reporting deadline to be pushed back again because, in its view, the state had bungled the process. California authorities didn’t publish the standardized survey founders were supposed to fill out until early this year and, at the time, they still hadn’t introduced a way for firms to register with regulators as required by the law, according to the association. “This administrative timeline creates an environment ripe for error and threatens to produce the misleading and counterproductive data we previously warned against,” association president and CEO Bobby Franklin wrote.
Last month, as the deadline for the first reports loomed, some entrepreneurs and investors began complaining on social media about the survey effort. “The latest California malarky is a requirement for venture investors to collect/report racial and gender statistics,” wrote Blake Scholl, the founder and CEO of venture-backed aviation startup Boom Supersonic. “I want to live in a world where merit matters—not skin color or what you have between your legs.”
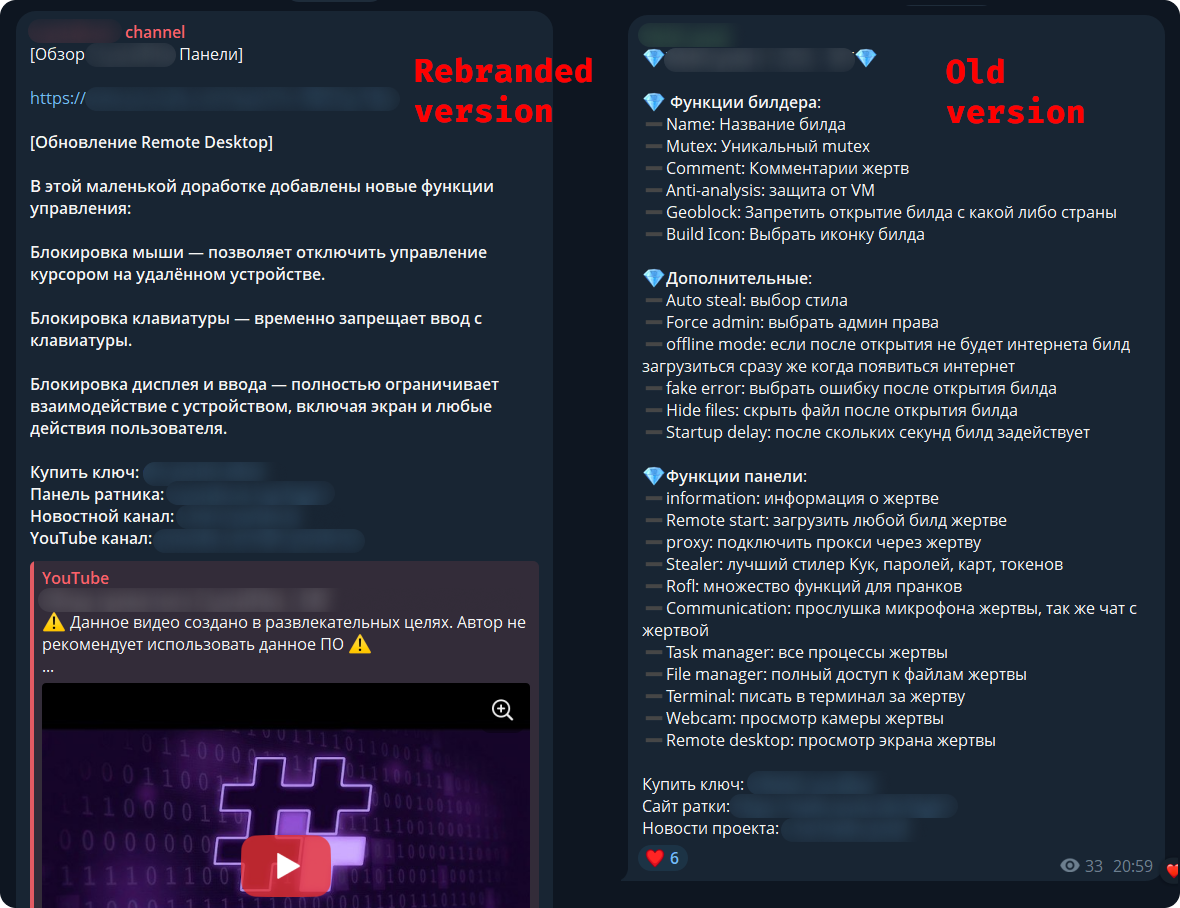
A new malware-as-a-service called CrystalRAT is being promoted on Telegram, offering remote access, data theft, keylogging, and clipboard hijacking capabilities.
The malware emerged in January with a tiered subscription model. Apart from the Telegram channel, the MaaS was also promoted on YouTube, via a dedicated marketing channel that showcased its capabilities.
Kaspersky researchers say in a report today that the malware features strong similarities to WebRAT (Salat Stealer), including the same panel design, Go-based code, and a similar bot-based sales system.
CrystalX also includes an extensive list of prankware features designed to annoy the user or disrupt their work. Despite its “fun” side, CrystalX offers a large set of data theft capabilities.
Advertisement
Telegram channel promoting CrystaX RAT Source: Kaspersky
CrystalX RAT details
Kaspersky says that the malware provides a user-friendly control panel and an automated builder tool that supports customization options, including geoblocking, executable customization, and anti-analysis features (anti-debugging, VM detection, proxy detection, etc.).
The generated payloads are zlib-compressed and encrypted with the ChaCha20 symmetric stream cipher for protection.
The malware connects to the command-and-control (C2) via WebSocket and sends info about the host for profiling and infection tracking.
CrystalX’s infostealer component, which Kaspersky found to be temporarily disabled as it is being prepared for an upgrade, targets Chromium-based browsers via the ChromeElevator tool, Yandex, and Opera. Additionally, the tool collects data from desktop apps such as Steam, Discord, and Telegram.
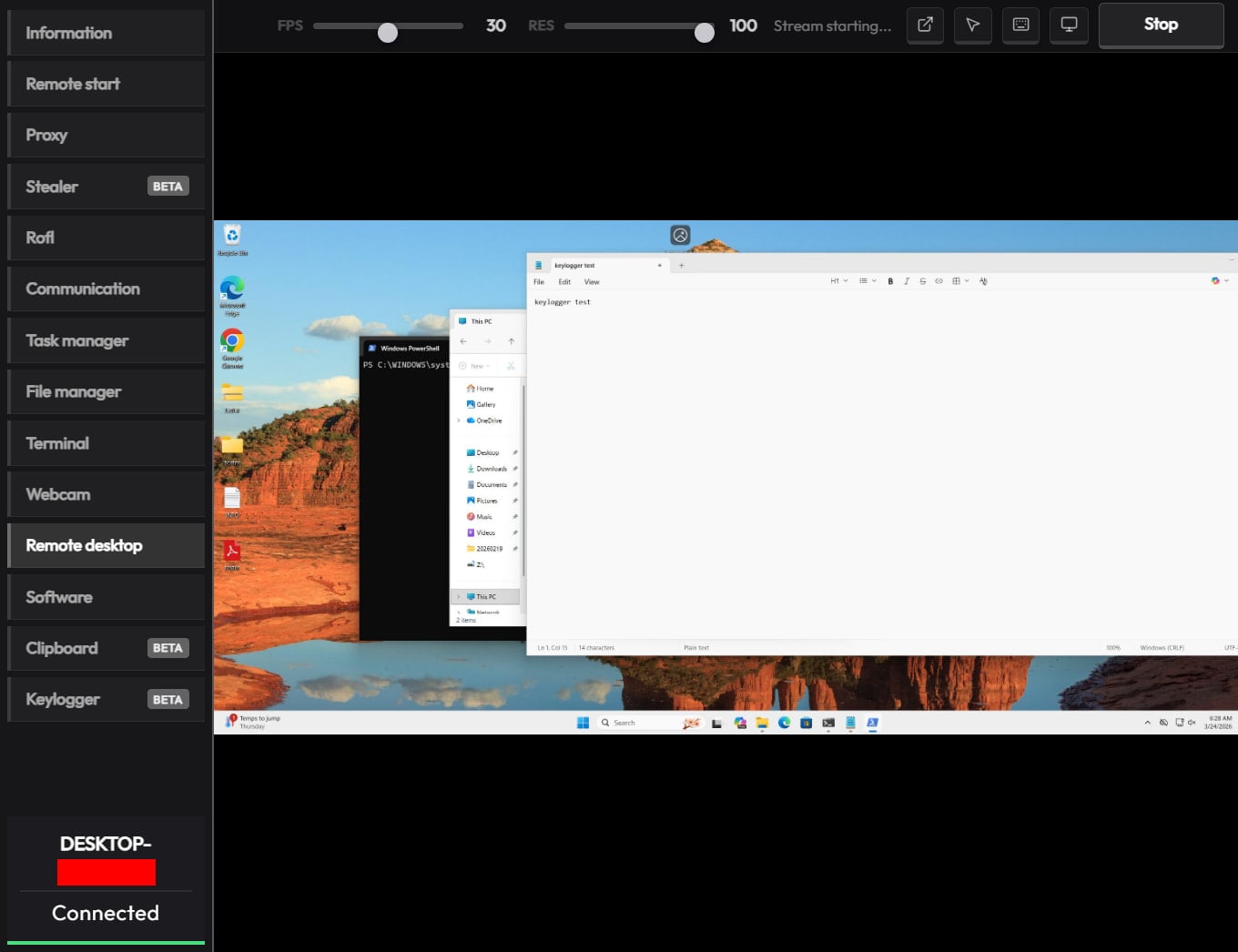
The remote access module can be used to execute commands via CMD, upload/download files, browse the file system, and control the machine in real time via built-in VNC.
Advertisement
The malware also exhibits spyware-like behavior, as it can capture video and audio from the microphone.
Finally, CrystalX features a keylogger that streams keystrokes in real time to the C2, and a clipper tool that uses regular expressions to detect wallet addresses in the clipboard and replace them with ones the attacker provides.
Remote desktop function in CrystalX RAT panel Source: Kaspersky
Putting some “fun” in the package
What sets CrystalX apart in the crowded MaaS space is its rich set of prankware features.
According to Kaspersky, the malware can do the following on infected devices:
change desktop wallpaper
alter display orientation to various angles
force system shutdown
remap mouse buttons
disable input devices (keyboard/mouse/monitor)
show fake notifications
change cursor position on the screen
hide various components (desktop icons, taskbar, the Task Manager, and the Command Prompt executable)
Provide attacker-victim chat window
While the above features do not improve the attack’s monetization potential for cybercriminals, they certainly make the product distinctive, and could bait script kiddies and low-skilled/entry-level threat actors into getting a subscription.
Another reason for the prank features could be potential for victim manipulation, or even distraction, while the data theft modules run in the background.
Advertisement
To reduce the risk of malware infections, users are advised to exercise caution when interacting with online content and avoid downloading software or media from untrusted or unofficial sources.
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.
Because South Dakota governor Larry Rhoden is forever obligated to serve Kristi Noem and Kristi Noem is forever obligated to serve Donald Trump, he and his GOP buddies are making America MAGA again, starting with his home turf.
Non-citizens have never really disrupted voting. But they’re the convenient scapegoat for a party that’s justifiably worried it’s going to lose its majority during the mid-terms. Multiple efforts are being made all over the nation to disenfranchise anyone that’s not part of Trump’s most rabid voting base. Pretending people not allowed to legally vote are somehow flipping elections for the Democratic Party is more than merely obnoxious. It’s actually harming the democratic process.
Here in South Dakota, two laws have been passed in recent weeks with the express purpose of keeping non-white people from showing up to vote. The first, passed at the beginning of this month, allows any rando to claim a person they saw voting shouldn’t be allowed to vote.
Voters in South Dakota will soon be able to challenge other voters’ citizenship.
Republican Gov. Larry Rhoden signed legislation into law last week that authorizes challenges by individuals and election officials.
Advertisement
[…]
State law already allows challenges to a voter’s registration up to the 90th day before an election, if a person is suspected of lacking South Dakota residency, voting in another state or being registered to vote in another state. The new law adds citizenship as a justification for a challenge.
Challenges may be filed by the South Dakota Secretary of State’s Office, the auditor in the county where the voter is registered, or a voter in the same county. The challenge must be in the form of a signed, sworn statement and must include what the law describes as “documented evidence.”
Now, we can all see what the law is. But we all know how it will be applied. State employees with access to voter rolls will raise challenges against anyone with a foreign-sounding last name. While it’s unlikely few citizens will actually file challenges, they’ll certainly feel comfortable accosting anyone standing in line to vote whose skin is darker than their own. Given the inevitability of these responses, it’s easy to see the law accomplishing exactly what it’s supposed to: limit the number of non-white voters at the polls during the mid-terms and beyond.
Advertisement
But that’s not the only suppression effort signed into law this month. There’s also this one, which raises the bar for participating in the democratic process with the obvious intention of limiting participation to the sort of voters the GOP thinks with vote for it:
New voters in South Dakota will have to prove that they are United States citizens in order to cast a ballot in state and local races under a bill signed on Thursday by Gov. Larry Rhoden.
The new law, which does not apply to South Dakotans already on the voter rolls, comes amid a national push by Republicans to tighten voting rules and root out voting by noncitizens, which is already illegal and believed to be rare.
“This bill ensures only citizens vote in state elections, keeping our elections safe and secure,” said Mr. Rhoden, who is seeking election to a full term this year and is facing a crowded Republican primary field.
It’s already illegal in South Dakota to vote if you’re not a citizen. This bill addresses a completely imaginary “problem.” And it forces voters to provide a passport, birth certificate, and other documents proving citizenship before they’re allowed to vote. While it may be easy for many people to present these documents, the simple fact is that they’ve never been asked to do this before, and anyone who’s not aware this law has been passed will be denied the opportunity to vote because the GOP decided to move the goalposts during an election year.
Advertisement
Non-citizens voting in South Dakota has never been an issue. The fact that 273 non-citizens were recently removed from the state’s voting rolls may seem a bit sketchy but there’s a good reason there might be a few hundred non-citizens with voter registrations:
Noncitizens can obtain a driver’s license or state ID if they are lawful permanent residents or have temporary legal status. There’s a part of the driver’s license form that allows an applicant to register to vote. That part says voters must be citizens.
The problem is that this is all on the same form. The voter registration part of the form has a signature line, which many applicants will fill out and sign even if their intention is only to get a drivers license or ID card, especially since it appears before the final signature block for the entire application.
If applicants are not asked to affirmatively state their intention to register to vote (as the Department of Public Safety employees ask now, along with asking applicants to write “vote” on the form to signal their affirmation), their applications might be processed, along with the voter registration applicants didn’t realize they enabling.
The Secretary of State’s office (the office that’s supposed to be reviewing voter registrations for eligibility) threw the Department of Public Safety under the bus:
Rachel Soulek, director of the Division of Elections in the Secretary of State’s Office, placed blame on the department in her response to South Dakota Searchlight questions about the situation.
“These non U.S. citizens had marked ‘no’ to the citizenship question on their driver’s license application but were incorrectly processed as U.S. citizens due to human error by the Department of Public Safety,” Soulek wrote.
Advertisement
That’s not what happened. Their ID applications were processed and the Soulek’s department failed to catch the inadvertent errors. And it doesn’t really even matter who’s at fault because despite the errors, this is still a non-issue.
Soulek said only one of the 273 noncitizens had ever cast a ballot. That was during the 2016 general election.
A handful of clerical errors that resulted in a single illegal vote in the past decade cannot be a rational basis for a new law. And there’s a good chance the sole vote was made in error, rather than maliciously. After all, if the state told this person they could vote, who were they to question that determination?
This is nothing more than state governments stepping up to do what Trump can’t. His SAVE Act is stalled and lots of last-minute gerrymandering at the behest of the president is tied up in court. His loyalists are doing what they can to make his perverted dreams a reality in states that are most likely to lean Republican in the first place, which makes all of this as pointless as it is stupid. But the underlying threat to democracy remains, ever propelled forward by the people who claim to love America the most.
This week, juries in California and New Mexico dealt a pair of landmark verdicts against America’s social media giants.
In Los Angeles, jurors awarded $6 million to a young woman who alleged that Instagram and YouTube had damaged her mental health. A day earlier, a jury in Santa Fe ruled that Meta had designed its social media platforms in a manner that harmed minors — and ordered the company to pay $375 million in recompense.
These decisions constituted a breakthrough for a legal movement that sees social media companies as the new “Big Tobacco” — an industry that knowingly peddles harmful and addictive products. And it was a triumph for advocates of “child online safety,” who believe that social media is corrosive to minors’ psychological well-being. With thousands of similar lawsuits pending, the California and New Mexico verdicts could prove to be transformative precedents.
Yet the decisions have also raised alarm bells for many free speech advocates. To organizations like FIRE — and civil libertarian writers like Reason’sElizabeth Nolan Brown — these decisions will do more to undermine free expression online than to safeguard young people’s mental well-being.
Advertisement
To better understand — and interrogate — this perspective, I spoke with Nolan Brown. We discussed how the recent verdicts could open the door to broader censorship, the evidence for social media’s psychological harms, and whether parents can sufficiently protect their kids from problematic internet use without the government’s help. Our conversation has been edited for clarity and concision.
You’ve written that these verdicts are “a very bad omen for the open internet and free speech.” How so?
What we’re seeing in these cases is an attempt to get around Section 230 by recharacterizing speech issues as “product liability” issues. Instead of saying, “We’re going after platforms for hosting harmful speech,” the plaintiffs are saying, “We’re going after them for negligent product design.”
Advertisement
In other words, the choices that social media companies make about how to curate their feeds or encourage engagement.
Right. Some of the things they complained about were “endless scroll” (where you keep going down and the feed doesn’t stop at the end of a page), recommendation algorithms that promote content that a user is more likely to engage with, and beauty filters.
But ultimately, if you look at what they’re actually going after, it comes down to speech. When you talk about TikTok or YouTube being so engaging that it’s “addictive,” you’re talking about content: No matter how TikTok’s algorithm is designed, it wouldn’t be compelling to people if the content wasn’t compelling.
Similarly, in the California case, the plaintiff argued that Meta allowing beauty filters on images was a negligent product design, since they promote unrealistic beauty standards, which caused her to develop body image issues.
Advertisement
But that really just comes back to speech: The choice to use a filter is something that individual users do to express themselves. Providing those tools for users is a form of speech.
But aren’t many of these product design choices content-neutral? A defender of these verdicts might argue: Social media companies are manipulating minors into compulsively using their platforms, in a manner that’s bad for their mental health. And they’re doing this, in part, through push notifications, autoplaying videos, and endlessly scrolling feeds. So, why can’t we legally restrict their use of those features — without constraining the kinds of speech they’re allowed to platform?
Some people will say, “Why don’t we limit notifications — or kick people off after an hour — if they’re minors?” But in order to implement any set of rules or product design choices just for young people, these platforms would need to have a foolproof way of knowing who is a minor and who is an adult.
And that means age verification procedures, where they’re either checking everyone’s government-issued ID, or they’re using biometric data — or something else that requires everyone to submit identification before they can speak anywhere on the internet.
Advertisement
And that creates a lot of problems. It makes people’s data more vulnerable to identity theft, hackers, and scammers. It also means that your identity is tied to everything you do online. And that can be dangerous, especially for people who are talking about sensitive issues or protesting the government. The ability to speak and organize online anonymously is very important.
What if the product design restrictions applied to adults and minors alike? If we barred social media companies from issuing push notifications for everyone, that would avoid the age verification issue, right?
Many platforms give people the tools to do these things already. You can turn autoplay off. You can have a chronological feed. You can tailor your settings so that you don’t have these features.
If we’re saying, “Why can’t the government mandate these options?” I think that’s a very slippery slope. You might think, “Okay, who cares about push notifications? Why can’t the government just mandate that they not do push notifications?” But the rationale for that gets us into much broader territory.
Advertisement
It’s effectively saying: Since some people will have a problem with this, the government must micromanage the way that the product is made. Yet people can use all sorts of products in a problematic way: Fitness regimes, streaming services, food. And we’re not saying like, okay, the government gets to step in and tell these companies exactly how to do business in the way that would be least harmful to people. And that attitude is particularly dangerous when we’re talking about products involving speech.
A skeptic might argue that the slope here isn’t actually that slippery. After all, the government has already shown that it can enact targeted, content-neutral restrictions on speech without triggering a cascade of censorship.
For example, since 1990, there have been limits on the amount of advertising that can air during children’s programming in a given hour — and also a requirement that ads and content be clearly separated. Those measures are arguably more intrusive on speech than, say, banning autoplay of videos on a social media platform. And yet, the Children’s Television Act of 1990 didn’t lead to any really sweeping constraints on First Amendment rights.
I just think it makes a big difference if you’re talking about restricting speech for minors and restricting it for adults. And what you were just mentioning were restrictions that would apply to everybody.
Advertisement
Beyond the First Amendment issues, you’ve expressed some skepticism about the specific causal claims made by plaintiffs in these cases: Specifically, that social media caused their mental health difficulties. Yet many social psychologists — most prominently Jonathan Haidt — have argued that these platforms are corrosive to children’s psychological being. So, why do you think the allegations here are overstated?
In the California case specifically, this young woman is alleging that, because she was on social media since she was very young, she developed mental health issues. But there was a lot of testimony showing that there were many other things going wrong in her life. She was exposed to domestic violence. She had troubles with her parents, troubles at school.
So the idea that social media directly caused her difficulties — rather than these life stressors that are well-known to cause harm — I think that’s kind of suspect.
And I think you see this problem in the broader research on social media’s mental health impacts. There’s often a correlation between depressive symptoms and heavy social media use because people who are having a difficult time at home and at school — people who are socially isolated — tend to use social media more than people in better circumstances.
Advertisement
How much do your views on the regulation of social media hinge on skepticism about the actual harms of these platforms? If we acquired evidence that there really were major impacts here — that autoplay and beauty filters were dramatically worsening kids’ mental health — would you support legal restrictions on these features? Or would First Amendment considerations override public health concerns, irrespective of the evidence?
The strength of the evidence is important for guiding the decision-making of individuals, parents, families, communities, and school districts. But even if we knew that beauty filters caused a lot of harm, the government still would not be justified in banning them, since they are avenues for speech. Plenty of people are not harmed by them.
There are so many things that harm some people, but that are useful to others. And I don’t think the existence of problematic use justifies banning those things for everyone.
I think talk of social media “addiction” can be unhelpful on this front. That language suggests that this is something that’s automatically harmful for everyone. And that just isn’t the case. Plenty of people use social media in a healthy way, in the same way that countless people can drink alcohol without it harming them, or eat a bag of chips without bingeing on them.
Advertisement
I think it’s the same way with social media. This is a technology that can harm some people, particularly those who already have psychological issues.
But it isn’t this addictive substance or a poison where you can’t even be exposed to it, or else. I think that view imbues smartphones with an almost mystical quality.
There are many cases, though, where we choose to heavily regulate a substance or practice — not because it harms everyone who engages with it — but rather, because it imposes massive harms on a minority of problem users. Gambling and alcohol are two examples. But even with opioids, many people can pop some pills and never develop a dependency. Yet some end up addicted and dying of overdoses. And for that reason, we heavily restrict access to opioids.
So, I feel like the question here might be less about whether social media is bad for everyone than whether it has truly large harms for problem users.
Advertisement
I think there are people who talk about it the way you do. But others describe social media as if it’s something that people are powerless against. But yes, I don’t think we have strong evidence that this is harmful in the way that addictive substances are. In fact, I think the evidence is really mixed. Some studies suggest that moderate smartphone use is actually correlated with better mental health outcomes.
You argue that, instead of seeking government restrictions on social media, parents should exercise more responsibility over their kids’ use of smartphones and apps.
Many parents argue that their capacity to monitor their children’s social media use is really limited and that they lack the tools to protect their kids from the harmful effects of these platforms. What would you say to them?
I think this is straightforward with very young children. Like, why is a 6-year-old having unfettered alone time on a digital device? In the California case, the plaintiff was using social media as a very young child. And at that age, parents definitely have control over what their kids do and see online; you can control whether your kid has access to a smartphone. With adolescents, there are areas where tech companies are working with parents. We’ve seen more parental controls being introduced in recent years. We’ve seen Meta roll out specific accounts for minors that have some restrictions on them. We’ve seen things like the introduction of phones that allow basic texting but not certain apps. So, I think private solutions are possible here. I think we can address people’s legitimate concerns without having the government infringe on free expression.




































































You must be logged in to post a comment Login