Until the fall of the Soviet Union around 1990 you’d be forgiven as a proud Soviet citizen for thinking that the USSR’s technology was on par with the decadent West. After the Iron Curtain lifted it became however quite clear how outdated especially consumer electronics were in the USSR, with technologies like digital audio CDs and their players being one good point of comparison. In a recent video by a railways/retro tech YouTube channel we get a look at one of the earliest Soviet CD players.
A good overall summary of how CD technology slowly developed in the Soviet Union despite limitations can be found in this 2025 article by [Artur Netsvetaev]. Soviet technology was characterized mostly by glossy announcements and promises of ‘imminent’ serial production prior to a slow fading into obscurity. Soviet engineers had come up with the Luch-001 digital audio player in 1979, using glass discs. More prototypes followed, but with no means for mass-production and Soviet bureaucracy getting in the way, these efforts died during the 1980s.
During the 1980s CD players were produced in Soviet Estonia in small batches, using Philips internals to create the Estonia LP-010. Eventually sanctions on the USSR would strangle these efforts, however. Thus it wouldn’t be until 1991 that the Vega PKD-122 would become the first mass-produced CD player, with one example featured in this video.
The video helpfully includes a teardown of the player after a rundown of its controls and playback demonstration, so that we can ogle its internals. This system uses mostly localized components, with imported components like the VF display and processors gradually getting replaced over time. The DAC and optical-mechanical assembly would still be imported from Japan until 1995 when the factory went bankrupt.
Advertisement
Insides of the Vega 122S CD player. (Credit: Railways | Retro Tech | DIY, YouTube)
This difference between the imported and localized part is captured succinctly in the video with the comparison to Berlin in 1999, in that you can clearly see the difference between East and West. The CD mechanism is produced by Sanyo, with a Sanyo DAC IC on the mainboard. The power supply, display and logic board (using Soviet TTL ICs) are all Soviet-produced. A sticker inside the case identifies this unit as having been produced in 1994.
Amusingly, the front buttons are directly coupled into the mainboard without ESD protection, which means that in a Siberian winter with practically zero relative humidity inside you’d often fry the mainboard by merely using these buttons.
After this exploration the video goes on to explain how Soviet CD production began in the 1989, using imported technology and know-how. This factory was set up in Moscow, using outdated West-German CD pressing equipment and makes for a whole fascinating topic by itself.
Finally, the video explores the CD player’s manual and how to program the player, as well as how to obtain your own Soviet CD player. Interestingly, a former employee of the old factory has taken over the warehouse and set up a web shop selling new old stock as well as repaired units and replacement parts.
Apple’s macOS has its fair share of quirks and a subtle design philosophy that distinguishes it from its biggest rival, Windows. Despite those differences, macOS has a surprising amount of overlap with Windows in both form and function. The Dock in macOS is akin to the Windows Taskbar; they effectively serve the same purpose, just going about it in slightly different ways. The Dock in macOS has heritage going all the way back to Mac OS X, and still serves as the primary way users launch applications in macOS Tahoe 26.
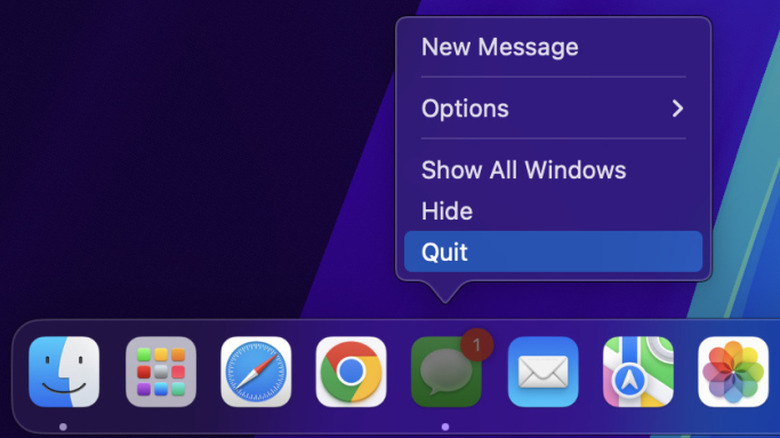
A feature distinct to the macOS Dock is how it handles applications that are currently running. Even if an app doesn’t have a visible window or you’ve closed the window, the app remains open. Those dots underneath the icons on the Dock indicate that those apps are running in the background. This isn’t a feature everyone loves, but fortunately, it can be changed, as there’s a surprising number of macOS settings you may not know you can change, including changes to the Dock itself.
Advertisement
How to really quit apps in macOS
Eric Hamilton/SlashGear
As Apple notes in its support documentation on quitting apps, clicking the red “x” in the upper left-hand of the window doesn’t close the app, but instead moves it to the background. There are a number of reasons why Apple does this, but macOS has a unique way it manages background processes and app termination in an effort to preserve system resources and focus on user experience. Whether you’ve jumped ship from Windows with a new MacBook Neo or you’re a macOS veteran, in order to remove the dots beneath app icons, you’ll need to take a different approach.
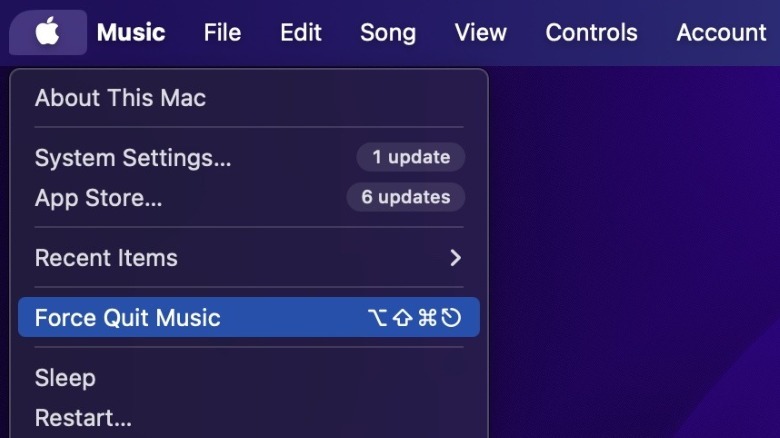
There are three ways to achieve this. First, you can control + click on the app’s icon in the Dock, then select “quit” in the corresponding window. Second, you can use the keyboard shortcut command + Q to quit an app with an open window. Lastly, you can navigate to the Apple menu in the top left-hand corner of the desktop, and select “Force Quit.” This will open a window with all currently running apps, which can then be quit.
Advertisement
Eric Hamilton/SlashGear
If you would rather disable this feature entirely, click the Apple menu and navigate to “System Settings.” Once the System Settings window opens, select “Desktop & Doc” from the left-hand side panel. Inside the Dock & Desktop option, scroll down to the “Show indicators for open applications” and toggle it off. This should prevent any dots from appearing under app icons, with the exception of Finder – this is permanent, and there is currently no way to change it. As a bonus tip, you can also manage all of your open apps and your desktop with Mission Control. On newer Macs, you can launch Mission Control with the F3 key.
It was just a week or so ago that we were talking about the absurd situation in Knox County, Tennessee, where local government used Tennessee’s book-banning laws to remove the book Roots from school libraries. Yes, this is the book by Alex Haley that spawned the 1970s miniseries of the same name and served as a cultural touchpoint for the understanding of American history and race relations across the country. Haley lived in Knox County himself. He even has a bronze statue placed in his honor in Morningside Park in Knoxville. Yet the book that earned him that statue was being banned in public schools.
The backlash to this occurring was swift and severe. It came from both local politicians and from the public around the country. The purity of just how bad and wrong this was hit a nerve. And, now, the county has caved to that pressure and have immediately reinstated Roots back onto public school bookshelves.
Knox County Schools Superintendent Jon Rysewyk said the district will return the 1976 novel to school library shelves, walking back a decision that had added Roots to a growing list of banned books and ignited debate about race, history and the reach of state law into public school libraries.
In a memo to the Knox County Board of Education dated May 26, 2026, Rysewyk said the decision to return Roots to shelves was effective immediately and that the initial removal “was in no way a commentary on the historical, cultural, or literary value of the novel.
And that’s bullshit, of course. Many of the other quotes from Rysewyk are very carefully lawyered, but this one stands out as obvious nonsense. Removing a book, any book, from school shelves is absolutely a commentary on the historical, cultural, and literary value of that book. You’re making a decision to hide away a literary work from children. If the work had value to those children, you wouldn’t be banning it.
Advertisement
Rysewyk goes on to note that he consulted with many lawyers on the passage that led to the book being banned and that there was no consensus whether that passage actually violated Tennessee’s law or not and that that’s why he reinstated it. Then he dropped this gem.
“Removing any book from circulation is, and should be, an immense decision. Our intent will always be to err on the side of access, which is the decision I have made with regard to “Roots,”” Rysewyk said.
No. No it won’t. Because last week was part of “always” and the initial decision was to err on the side of not pissing off racist goobers and removing access. Nice try, though. It was only when the revolt started coming from within the school board itself that Rysewyk was forced to walk this all back.
Knox County School board member Katherine Bike sent a memo to her colleagues demanding the book’s return.
“Removing Roots is not a neutral act,” Bike wrote. “It sends a message to our students, particularly our Black students, about whose history is worth protecting. I don’t believe that is the message any of us intends to send. Intent and impact are two different things.”
On Tuesday after the reversal was announced, State Rep. Sam McKenzie, whose district includes the Haley statue, called the ban a grave injustice and said he was disappointed but not surprised.
Advertisement
“’Roots’ won a Pulitzer Prize and became a cultural touchstone that inspired and united millions of Americans,” McKenzie said. “I knew that taking it out of the hands of thousands of schoolchildren in Knox County would be a grave injustice.”
Now, what this should immediately result in is a recognition that public backlash can reverse bad policy. There are over 120 other books that are currently on the Knox County banned book list, not to mention similar anti-literature lists from the state’s other counties. Every one of them should get similar backlash. Banning Roots failed to work because of the name recognition of the book, the local interest in its author, and its obvious value to children. I have no reason to believe that there aren’t plenty of other works of literature in the other 120-plus books on the list worthy of defending.
That’s where the work actually needs to be done, now. Because the only thing we should be banning is the banning of books.
A security lead at a large enterprise* told me last week, when I asked whether they had any interest in Grok: “The revenge porn edgelord LLM? Yeah, imagine that; our bank wants nothing to do with it.”
A couple of other people I put the question to seemed genuinely surprised I’d brought it up at all, the way you’d react if someone wandered into a board meeting and asked whether anyone wanted to expense a timeshare.
So that’s the current state of enterprise demand for Grok, as measured by the unscientific but reliable method of asking the people who actually sign the cloud contracts. It lands somewhere between “no” and “why would you ask me that?”
Which is awkward, because Business Insider reported this week that AWS is “in talks” to add SpaceX’s Grok models to Bedrock, joining Anthropic, Meta, Cohere, and the OpenAI models AWS is in the process of bolting on. SpaceX has reportedly already shipped the models to AWS. There’s no launch date, which in AWS announcement terms puts us squarely at the “intention to perhaps one day announce an announcement” stage.
Advertisement
But is it any good? (No)
Let me dispatch the obvious objection: maybe nobody wants Grok because they haven’t tried it, and it’s secretly excellent. I’ve run blind tests of the frontier models on some of my own deeply stupid side projects—the shitposting.ai family, where the entire design goal is to be edgier and weirder than the current discourse will tolerate. If there’s a use case purpose-built to let Grok flex its whole “we say the things others won’t” positioning, it’s mine.
Grok loses. It’s fast — legitimately, impressively fast — but it’s just not as good. It’s the energy drink of frontier models: it’ll keep you up, but you won’t enjoy the experience and you’ll regret it in the morning.
So we’ve got a model that enterprise buyers actively don’t want, that underperforms even on the single axis it’s purportedly optimized for, attached to a company whose image generator reportedly was used to produce roughly three million sexualized images of real people over an eleven-day stretch, including an estimated 23,000 depicting apparent minors, according to the Center for Countering Digital Hate, triggering regulatory action in more than a dozen jurisdictions and a Dutch court injunction carrying a €100,000-per-day penalty. That part isn’t a joke, and I’m not going to make one.
Then layer on the fact that nobody sensible wants to take a hard dependency on Elon Musk’s org chart. In roughly a year, the thing has been reorganized into oblivion — X (the rebranded Twitter) sold to Grok-producing xAI, xAI swallowed by SpaceX, with the whole AI unit then being dissolved into a division called SpaceXAI. All eleven original cofounders have left. More than fifty researchers walked after the SpaceX absorption. The API endpoint you’d integrate against, api.x.ai, is migrating to a SpaceX-branded URL on a timeline nobody’s published. Building production infrastructure on top of that is like renting an apartment in a building that keeps changing its name, its address, its compliance with the fire code, and its landlord while you’re still unpacking.
Advertisement
And here’s the part that should bother whoever greenlit this. Bedrock’s entire pitch— the reason anyone pays the wrapper tax instead of hitting a model’s API directly— is governance: IAM, PrivateLink, CloudTrail, encryption, guardrails, and an audit trail you can wave at a regulator. The model is almost secondary to those things for those customers. And the enterprises that actively value that stack are precisely the ones telling me they wouldn’t touch Grok with a borrowed keyboard.
The startups that hypothetically *do* want Grok — for the edge, for the speed, for whatever a founder talks themselves into at 2 a.m. — could not care less about CloudTrail. They want it cheap, fast, and now, and they can already have it: Grok is one curl to a public endpoint away, same as every other model on the shelf. Bedrock has no monopoly on third-party models; it never did. So sketch the Venn diagram. One circle is “wants Grok,” the other is “wants Bedrock’s governance.” Grok-on-Bedrock is built to serve only the gap where they don’t overlap.
So who asked for this?
Nobody. Which is the interesting part.
When customer demand can’t explain a decision, follow the corpdev. And AWS has run this exact play twice already this year, in public, with the numbers attached.
Advertisement
With Anthropic: a commitment to spend more than $100 billion on AWS over ten years and secure up to five gigawatts of Trainium capacity, with Amazon putting in another $5 billion immediately and up to $20 billion more on milestones — on top of the $8 billion it had already sunk in, for a cumulative stake somewhere around $33 billion.
With OpenAI: an existing $38 billion agreement expanded by another $100 billion, OpenAI committing to roughly two gigawatts of Trainium, and Amazon writing a $50 billion check on top.
The pattern is identical both times. Amazon invests, the lab commits to gigawatts of Trainium, and the model shows up on Bedrock as the consumer-facing bow on top. The Bedrock listing is the gift wrap. The Trainium commitment is the gift.
So here’s the way I’m thinking about it: AWS isn’t trying to sell Grok to your bank, but rather trying to sell Trainium to SpaceXAI — a company currently training Grok on something like 550,000 Nvidia GPUs in a Memphis facility the size of the chip on my shoulder. Peel even a fraction of that onto Amazon silicon ahead of the SpaceX IPO and the deal pencils out, regardless of whether a single human ever calls the Grok endpoint in anger. Bedrock becomes little more than a sales funnel with infuriatingly bad documentation.
Advertisement
The part where I say something nice
Because the strategy is clever, and I try to say so when it’s earned. Amazon is now bankrolling both leading independent AI labs at once, on its own chips, through its own model marketplace, while positioning itself as neutral infrastructure for whoever ends up winning. Against the roughly $200 billion in capex Amazon is torching in 2026, getting frontier labs to pre-commit to the silicon is about the only thing that makes that spreadsheet survivable. It worked twice. Why not go for three?
The third just happens to be a satellite-internet competitor. Amazon Leo – Amazon’s own years-later answer to Starlink – is out there signing Delta, JetBlue, AT&T, Vodafone, and NASA. So AWS would be cutting a relationship check to the one company it’s simultaneously trying to chase out of low Earth orbit. This seems fine. This is normal! Everybody in this industry is everybody else’s landlord, tenant, competitor, and shelf-mate, frequently within the same quarter and occasionally within the same press release. There will never be a problem that this arrangement causes.
The caveat that keeps me honest
I have no inside information here past “casual conversations with enterprise execs.” I haven’t seen a term sheet. There’s no public Trainium commitment from SpaceXAI, and Colossus runs on Nvidia today. So I can’t prove this is silicon corpdev rather than, say, AWS executives wanting a seat at the IPO table, or a marketing org that needs to put “every frontier model” on a slide. What I can tell you is that customer demand doesn’t explain it, because there isn’t any – and AWS has shown you, twice and with receipts, what its other explanation tends to look like.
So when Grok eventually lands on Bedrock with no fanfare and no launch date, and then is never mentioned again, don’t read it as AWS believing you want Grok. Read the S-1. If there’s a Trainium number in it, you’ll know what the model was really for.
Advertisement
* Specifics have been fuzzed to protect confidentiality. ®
The only Father’s Day gift I can recall my own dad getting was a plate of fried sardines. It was prepared by my mother, his ex-wife, who knew how gratefully he’d receive a dish he grew up with in the Italian neighborhood of a steel town dying with such theatrical flair that Bruce Springsteen named a song after it. (An acoustic Springsteen song, at that.) We lived in a nearby city that had plenty of red-sauce restaurants, but they weren’t serving tinned fish in those days. As my father had only the most limited of food preparation skills and didn’t date the kind of women who could cook, this was the only way he’d ever taste that flavor again.
As Father’s Day gifts go, being united with a long-lost recipe from childhood is pretty good. If you can pull it off, that’s what you should give your dad this year. Otherwise, I have here a few ideas I’ve spent the last few months gathering for various types of dads and across many different budgets. With the exception of a few things picked by other dads on the team, these are all things I’ve personally tested and approved, and I hope they make your dad as happy as those sardines made mine.
Maybe your dad has fond memories of the Super Soakers of his youth, but the SpyraFour is the new best water gun ever made. WIRED has been covering the German brand’s powerful electric squirt guns since 2023, and they’ve only gotten better over time. Just ask my daughter, who has to use the SpyraThree while I blast away at her with this gun that refills much faster (it sucks up enough water for about 20 shots in a cool 12 seconds) and has a full digital smart display to select between shooting styles and show you how much ammo you’ve got left. This is a very powerful squirt gun that shoots accurately up to 50 feet, and it’s recommended for kids who are at least 14. I can confirm that when I let my 11-year-old and her friends play with it, the battle often ends in tears. This only adds to the appeal as a gift for any dad over 40—when I was her age, we threw rocks at each other, and I had to go to the emergency room to get stitches you can still see. Good times.
Advertisement
Aerobie
Pro Ring
Playing catch is one of those classic activities dads and kids love to do. Over time, I’ve found, it transitions from the kid asking to toss the Frisbee around to the adult asking. Yes, the Aerobie is still the best flying disc you can buy, but the real reason to gift it is as an excuse to toss it around and talk.
St. Pierre
Advertisement
Tournament Bocce Set
Bocce is the best backyard game—it’s great for people of all ages and has no learning curve, though it’s possible to get better with practice. I hoard bocce sets from thrift stores and have owned like four; the best set is one like this from St. Pierre, which is made in America and is the brand they use in tournament play.
For the Grill Dad
Photograph: Martin Cizmar
Mibrasa
Hibachi MH 300 PLUS
Advertisement
Live-fire cooking has been the hottest trend in grilling for half a decade now, possibly as a reaction to the rise of super-automated pellet grills and high-tech smart grilling. The latest up-and-coming device is the charcoal oven, which Spanish brand Mibrasa is best known for (the smallest model, the Nano, runs just under $12,000). That would be an amazing gift for your dad if the budget allows. However, those of more modest means can confidently gift this super-premium hibachi grill from Mibrasa, which is made of heavy-gauge steel.
The MH 300 Plus is roughly one square foot and weighs about 18 pounds empty—you can carry it around, but it’s a little on the hefty side. It gets scorching hot (almost 500 degrees Fahrenheit) and holds the meat very near to the charcoal so that the drippings are vaporized and turned into flavorful smoke. I’ve made steak tacos and chicken skewers, and they’ve turned out perfectly with a kiss of char. When I refresh this guide in a few weeks, I will have used it to test the Snake River Farms Wagyu beef gift box that just arrived, which looks like it will also appear on this list soon.
Jacobsen Salt Co.
Grilling Trio
Advertisement
Jacobsen Sea Salt is hand-harvested on the Oregon coast, where the waters of Netarts Bay impart a lot more character than most of what you buy at the grocery store. The Grilling Trio has three variants blended with herbs to create flavor profiles that complement Dad’s dishes. My favorite is the steak blend, which includes dried garlic, coriander seed, fennel seed, and a half-dozen other classic herbs.
Oyster
Tempo Pro
Oyster has made the prettiest coolers on the market since the Norwegian brand’s debut in 2023. These aluminum ice boxes are double-walled for vacuum insulation, as you find on a travel coffee mug. The new Tempo Pro adds a small digital thermometer that tracks the temp inside without spoiling its clean lines.
Advertisement
For the Beach Dad/Pool Dad
This is one of the few products on this list that I have not personally tested, but for a dad with a pool, it’s such a good gift idea that I had to include it. Our reviewer gave the Sora, which sits in the middle of the Beatbot lineup, a stellar 8/10 review, saying it’ll clean up the debris from pretty much any mess short of a hurricane. This 20-pound robot crawls the walls of your pool, suctioning up grime and saving dad the hassle of skimming for an hour every week.
Vero
Vero X Realtree Tide Tracker
I wear an Apple Watch Ultra most days, but nothing annoys me more than needing to keep it charged during vacations and weekends. That’s where this very cool watch from Vero comes in. It’s a collab with Realtree, the Gucci of camo, and will track the tides for 14 days while being waterproof to almost 400 feet. Even—perhaps especially—if your dad has a smart watch or a luxury watch, this is a great gift that will serve him well in the outdoors and especially near the ocean.
Sunguard
Advertisement
Men’s Overhead Hoodie
I have been slathering myself in sunscreen—most dads I know do this too—which is why I’ve quickly become addicted to sun hoodies. I’ve amassed a half-dozen of them to wear when taking my daughter to the beach or pool, or when going for a hike. The best I’ve used so far is the Sunguard line from EMS, which offers 50 SPF protection in a polyester-elastane blend that’s thin, soft, and breathable. It dries ultra-fast, and the hood will cover as much of your face as you need to without being cumbersome when not in use.
For the Car Dad
Photograph: Martin Cizmar
Photograph: Martin Cizmar
Portable tire inflators and jump starters are both great things to have, and I have both. The AX65 from Noco is a high-powered combination of the two, and the best version of either I’ve encountered. The tire inflator is extremely quick, as fast as a gas station air compressor in my testing, and advertises it’ll take a tire from flat to 40 psi in two minutes. It holds 2,150 amp hours of power, enough to jump a regular passenger car multiple times. It jumped my Dieselgate-era Jetta with ease (I’ve had the device for a month and already needed to jump my car thanks to its lack of alarm when you leave the lights on). It’ll also recharge a phone or laptop via a 60-watt USB-C port, so it’s not just taking up dead space on road trips until disaster strikes.
BlueDriver
Pro Next Gen OBD2 Scanner
Advertisement
There are dozens of OBD2 scanners out there, and I’ve owned three or four different ones. The BlueDriver stands out for having lots of powerful features without requiring a subscription or credits to unlock its functions. This device connects to your car’s port and pairs to a phone app via Bluetooth so you can read, and in many cases clear, trouble codes. It plays pretty well with my VW, though it’s not a full VCDS system.
Decked
Halfrack 32
Decked makes the sturdiest of the many car storage systems I’ve used over the years, and what the medium-sized Halfrack lacks in size it more than makes up for in sheer toughness. It’s gasketed so it doesn’t leak, and not only can you stand on it, but supposedly drive a truck over it without it cracking (I have not driven my truck over it). It has a locking lid that can be opened with one hand and a convenient carry handle that folds down flush when not in use. This is the gateway to a full system of boxes and drawers, so if your dad likes it, you have gift ideas for years to come.
Advertisement
For the Yard Dad
Photograph: Martin Cizmar
Photograph: Martin Cizmar
My childhood neighbor Don Elmerick had the finest lawn I’ve ever seen. Elmerick, who lived across the street from my mother’s house for nearly 50 years before he passed in 2019, spent every summer meticulously tending to his acre of bright green grass, getting tan while mowing shirtless in jeans. His lawn was so nice that, as legend had it, the groundskeepers from the modest public golf course behind our house would come by to admire it. Every dad I know, including myself, would love to have a lawn like that. Unfortunately, I do not have the spare 10 to 20 hours a week it takes to do the research and labor required.
I won’t say that the Lawnbrite plan has my more modest patch of lawn looking like Firestone Country Club after six months of treatment, but it does look better than any lawn I’ve kept in my adult life. That’s thanks to this service, which uses data from your lawn to create a custom treatment plan and then sends different treatment bottles at strategic times. All you do is open the box, attach the bottle to a hose, and spray. I applied the Green Machine formula in the fall and then Weed Wipeout in the spring. If your dad is always talking about how nice another man’s grass looks, this is the gift for him.
If you’re of a certain vintage, you have probably looked at some of the microcomputers on the market these days and thought “that would have been a decent workstation back in the day!”. We certianly have, and so did [Roberto Alsina]. Rather than allow himself to contemplate his age and threfore rapidly approaching mortailty, [Roberto] wrote a useful operating system called ESP-Osito for the Cheap Yellow Display, which he refers to as “the cheapest computer”. He’s not wrong, and it’s certainly a better use of time than an existential crisis.
He explains some of his reasoning behind the project in an accompanying blog post, but on the project page he compares it to a Palm Pilot– it’s on quick, apps load quick, and the API is simple enough for easy app creation in a few hundred lines of C, unlike certain pocket computers we won’t name. Sure, there’s no multitasking, but when apps jump from SD card to run in memory in microseconds, who cares? Saving the current state of the app back to SD means the experience is virtually identical from a user perspective anyway.
DOS knew what time it was, but how many of us wasted phone time for weather reports?
As this is a one-man show for now, the app store won’t quite rival your smart phone– but there’s everything you’d expect on the 90s-era computer this has the horsepower of: a serial terminal, a text editor, a file explorer, a calculator, a clock, but also some things that aren’t so retro. The clock app gives weather info via futuristic wireless networking, the reader app takes Markdown text, and the chat app connects to an LLM somewhere instead of your friends on IRC. The blackberry keyboard option gives it a feel of a slightly different vintage. You can also play snake, because no computer is complete without games. The OS and all its applications are released under the MIT license on GitHub, and [Roberto] is actively looking for collaborators.
If you doubt the workstation comparison at the start of this article, this CYD runs Macintosh System 3 via a 68k emulator. That’s got old-school cred, but there’s something great about having retro constraints with modern code on modern hardware. In that way, ESP-Osito is similar to the 3D graphics engine behind this Wipeout clone.
Toyota’s lineup has a handful of four-wheel drive vehicles ready for off-roading adventures. Having full control of the drivetrain makes 4WD vehicles perfect for serious challenges. However, you probably don’t go off-roading all the time, even if you want to. But between commuting to work, dropping kids off at school, and running errands, Toyota doesn’t want you to forget about your vehicle’s four-wheel drive.
In your owner’s manual, you’ll see Toyota’s advice to drive your vehicle in four-wheel drive at least ten miles every month. This will keep the front-drive components lubricated. But four-wheel drive is intended for use on rainy, snowy, muddy, or sandy roads, as well as on rugged terrain, allowing slower, more controlled driving. When you’re on a flat, smooth road, using 4WD will use up a lot of gas and cause additional vehicle wear due to extra gears and driveshafts being engaged. You may also have a tougher time braking and turning. If the weather outside is nice, you can still use 4WD by finding a straight, flat road with no turns.
Advertisement
Which Toyota vehicles have 4WD?
Harazaki Ananta Hondro/Shutterstock
Toyota’s lineup includes a wide range of vehicles, from commuters to off roaders. There are currently five models with four-wheel drive. The Toyota Tacoma, 4Runner, and Tundra have 4WD available, the Sequoia has standard 4WD, and the Land Cruiser has full-time 4WD.
Most of Toyota’s vehicles have all-wheel drive instead, from the hybrid Prius to the sporty GR Corolla to the reliable Highlander. That’s because AWD is best used on-road, sending power to all four tires simultaneously. This keeps the vehicle moving forward on slippery surfaces or while cornering at high speeds. Since AWD allows each tire to rotate at its own individual speed, it’s better than 4WD for snow, rain, and other bad weather while you’re commuting, although the increasing price for AWD is getting harder to ignore.
Four-wheel drive offers more control since the front and rear axles turn at the same time, making it ideal for extreme off-roading — but it uses more power, which is why you don’t use 4WD on paved roads — except for those 10 miles a month, of course.
A recent Indian court ruling against Google’s keyword advertising practices has gained fresh attention after founders said competitors have long used the system to siphon off customers and force companies to pay to protect their own brands.
The ruling, delivered by the Delhi High Court on May 22 in a trademark dispute involving bathroom fittings maker Hindware, found Google liable for trademark infringement over its keyword advertising practices and awarded the company ₹3 million (around $31,600) in nominal damages.
In her 163-page judgment (PDF), Justice Mini Pushkarna rejected Google’s argument that it was merely a passive intermediary in serving ads on its search platform. The judge said Google, through its AdWords platform, allowed Hindware’s rivals to use “Hindware” as a keyword to target users searching for the brand.
“Google by selling the trademark of the plaintiff [Hindware] as a keyword without any authorization for commercial gains is infringing the plaintiff’s right to exclusive use of its trademark under Section 28 of the Trade Marks Act,” the judge said.
Advertisement
The judgment drew attention on Friday after Indian entrepreneurs, including Zerodha founder Nithin Kamath and Zoho founder Sridhar Vembu, publicly backed the ruling, arguing that competitors have long used Google’s advertising tools to divert traffic from established brands and force companies to spend money protecting their own names.
Kamath, who said Zerodha had faced the issue for more than a decade, wrote on X: “Whenever someone searches for ‘Zerodha,’ the traffic should rightfully come to Zerodha. But what often happens is that the first couple of results on Google Search are ads, leading the customer to a competitor’s website.”
Google, for its part, said its Ads policy on trademark keywords “does not allow competitor advertisers to use trademarked terms in the ad-text of an ad” and that the policy is applied globally.
“We look forward to continuing to align our operations with local legal frameworks while maintaining strict standards to protect our users’ long-term interests,” a Google spokesperson said in a statement to TechCrunch.
Advertisement
India is a key market for Google, with more internet users than any country other than China, making court decisions affecting its search and advertising businesses particularly significant.
Legal experts, however, said the implications of the ruling may be narrower than some of the public reaction suggests.
“The judgment per se will require platforms to relook at their processes to see if their automated tools encourage or offer trademarked terms to advertisers at large,” said Aprajita Rana, a partner at AZB & Partners.
Nonetheless, Rana told TechCrunch that the decision does not have a “far-reaching impact” on online platforms’ liability in India, as courts have already established that internet companies can lose legal protections when they play an active role in unlawful activity.
Advertisement
“What’s important in this case is how providing access to trademarked terms, even in ad curation that’s between online platforms and advertisers and not known to customers, can amount to a participative activity for platforms,” Rana said.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
The Karcher K5 Comfort Premium makes tough cleaning jobs feel refreshingly easy, with a compact design, four-in-one lance, integrated detergent system and comfortable trigger that help it breeze through patios, driveways and cars. It’s not perfect, lacking finer pressure adjustment and bundled specialist accessories, but it’s still an easy recommendation..
Compact, easy-to-store design
Versatile four-in-one lance
Excellent cleaning performance
No pressure adjustment
Accessories cost extra
Universal detergent lacks foam
Key Features
Advertisement
Review Price:
£400
Compact, storage-friendly design
Advertisement
Smaller and easier to store than older pressure washers.
Four-in-one cleaning power
Advertisement
Switch between four spray modes with a twist.
Built-in detergent convenience
Advertisement
Lets you swap between water and detergent in seconds.
Introduction
Pressure washers aren’t exactly known for being elegant. They’re usually bulky, awkward to store and just a little bit annoying to drag out when it’s time to tackle the driveway, patio or car.
That’s what makes the Karcher K5 Comfort Premium so appealing: it takes the heavy-duty cleaning power you’d expect from a mid-range pressure washer and wraps it in a design that’s noticeably easier to handle day to day.
Advertisement
Part of Karcher’s new Comfort range, the K5 Comfort Premium promises a more user-friendly experience from top to bottom, with a lighter trigger setup, an integrated hose reel, a built-in detergent system, and a four-in-one lance designed to cut down on faff.
Advertisement
After using it to clean everything from a grimy driveway to a dirty car, it’s clear this is a pressure washer built with convenience in mind – even if a couple of omissions stop it short of perfection.
Design and features
Compact design
Four-in-one lance
Integrated detergent system simplifies cleaning
Coming from my years-old, bulky, heavy pressure washer, the K5 Comfort Premium is something of a dream – and that’s kind of the point of the new ‘Comfort’ collection.
Image Credit (Trusted Reviews)
It’s absolutely dinky compared to my old unit, standing at just over 66cm tall and 34cm wide, with a retractable handle that not only makes lugging it around much easier but also means an even more compact footprint for storage – ideal for me and my limited shed space. It’s still a little on the heavier side at 13.8kg, but the large wheels make transporting it from one area to another easy enough.
Advertisement
Advertisement
But I’m getting ahead of myself somewhat here; let’s start with the unboxing experience. As with most pressure washers, the K5 Comfort Premium comes in several pieces, which might look daunting to the untrained eye, but it’s really simple to snap together without any tools. It took me around five minutes to follow the Ikea-style instructions, with no strops or breaks in sight.
The Comfort redesign extends to the gun, which is surprisingly lightweight, easy to manoeuvre, and much more comfortable to use over long periods, with less pressure required to depress the trigger. I spent three hours pressure washing my driveway, and my hands still weren’t aching by the end.
Image Credit (Trusted Reviews)
The gun attaches to the body of the pressure washer via a 10-meter-long high-pressure hose, which is stored in an integrated hose reel that’s surprisingly smooth to extend and retract. Karcher takes additional points here too, with the pressure hose coming out of the opposite side to the power cable and hose input to stop everything from getting tangled. A nice touch indeed.
Image Credit (Trusted Reviews)
The highlight of the experience is the new four-in-one multijet lance, which twists into the gun with surprising ease. It’s a really handy bit of kit too, offering four distinct modes that you can switch between simply by rotating.
Advertisement
The dirt blaster is my favourite for cleaning patios and other brickwork, essentially rotating the tiny jet at a rapid pace to shift even the most stubborn stains and grit, but there’s also the more traditional high-pressure flat jet and reduced-pressure flat jet for jobs like cleaning cars.
Advertisement
Image Credit (Trusted Reviews)
What’s most impressive is the integrated detergent jet; with a quick twist of the nozzle, you can spray detergent mixed with water without needing to attach a front-heavy foaming attachment. That’s because the K5 Comfort Premium comes with a new detergent system that integrates the bottle directly into the pressure washer’s body, negating the need for a tank, and includes a bottle of eco-friendly detergent in the box.
You can remove the detergent adaptor from the body and use it on the end of the gun if you prefer, complete with dosing settings, but I really like the integrated approach. It makes tasks like cleaning cars much easier, as I can simply switch between water and detergent without faffing around switching lance attachments.
Image Credit (Trusted Reviews)
As compact as the K5 Comfort Premium is, it still has plenty of space to store the lance and gun, along with any other optional accessories compatible with the K5. And optional accessories there are aplenty, including heads specialised in cleaning patios and cars. It’s just a shame none of these actually come in the box.
Advertisement
Performance
Powerful cleaning with fast results
Lightweight gun improves long-session comfort
No pressure adjustment
As you might expect, the Karcher K5 Comfort Premium is an absolute joy to use. Simply attach the lance to the gun with a push-twist, attach the garden hose to the body, plug it in and power it on.
One note though; release the built-up pressure in the system by pressing the gun’s trigger before starting, or the unit won’t power on. I thought mine was broken after changing power source multiple times before I realised that was the (refreshingly simple) fix.
Image Credit (Trusted Reviews)
That aside, all you need to do is select the type of jet you want to use and press the trigger to get going. The only real decision is which of the modes you want to use. I found that the dirt blaster mode was the most effective for cleaning patios and driveways, though I certainly wouldn’t recommend it for cars, bins or anything like that. I tried it on an old bin and it literally stripped a layer of plastic off – if anything, that’s testament to the level of power here.
That said, cleaning my driveway was an absolute doddle. The dirt blaster mode made incredibly quick work of my (embarrassingly dirty) driveway, bringing it back to its original vibrant colours with only a single pass in most places. I needed to hone in to make sure I got every bit of dirt, as moving it too quickly results in a circular outline, but I’d be lying if it wasn’t satisfying as heck. As noted earlier, it took three hours to do fully, but it felt like half an hour.
Advertisement
Advertisement
Much of the ease of use comes from just how lightweight and comfortable the gun is to use; as noted, it’s lightweight and, with very little pressure needed to depress the trigger, it’s something I could use one-handed much of the time.
Image Credit (Trusted Reviews)
Cleaning the car was equally as successful, with the long 10-meter hose allowing me to fully circle my car (and then some) without accidentally pulling the pressure unit over. Starting with the (less aggressive) reduced-pressure flat jet, I rinsed off the car before switching to the detergent jet – again, something that required no more than a twist of the nozzle – to lift some of the more stubborn stains from the car.
The eco-detergent supplied in the box isn’t designed specifically for cars – it’s a universal cleaner – so there wasn’t much foaming, but it was still easy to apply. I think I’ll keep the Karcher bottle and refill it with a proper foaming detergent for future car cleans.
Advertisement
Advertisement
Still, once done with foaming, switching back to a regular jet to rinse was easy, and the whole process took no longer than 10 minutes – much faster than doing it by hand, with pretty similar results. It didn’t quite get some of the most stubborn stains (those damn birds!), but it was a damn sight cleaner than it was before.
Even if it takes longer, Karcher claims that the K5 Comfort Premium’s water flow rate is only 40% of a garden hose’s, making it a fairly efficient way to clean medium-sized spaces if you’ve got a water meter.
Image Credit (Trusted Reviews)
After using the Karcher to clean my driveway, garden patio and path, and my car, my only complaint is that there’s no way to adjust the pressure level, either on the gun or on the pressure washer’s body; it’s simply on or off.
Yes, I can switch between the three spray modes if I need to wash something a little more fragile, but what if I want to, say, keep the rotation of the high-pressure dirt-blasting mode while toning it down a bit? There are plenty of pressure washers that offer this, so I’m a little surprised it’s not on offer here.
Advertisement
Advertisement
Should you buy it?
You want compact, fuss-free cleaning
The K5 Comfort Premium is easy to store, easy to handle and powerful enough to make light work of patios, driveways and cars, with smart extras like its four-in-one lance and integrated detergent system.
Advertisement
You want finer control or more in the box
For all its polish and power, the K5 Comfort Premium offers no real pressure adjustment beyond its spray modes, and it’s a shame the more specialised accessories cost extra.
Advertisement
Final Thoughts
A great pressure washer should make tough jobs feel less like hard work, and that’s exactly what the Karcher K5 Comfort Premium does.
It’s compact, thoughtfully designed and genuinely enjoyable to use, with standout touches like the four-in-one lance, integrated detergent system and a much more comfortable trigger setup than I’m used to. More importantly, it delivers where it counts, making quick work of patios, driveways and cars alike.
Advertisement
It’s not perfect – I’d have liked some form of pressure adjustment beyond the preset spray modes, and it’s a little disappointing that none of the more specialised accessories are bundled in the box – but even so, those feel like relatively minor gripes when the overall experience is this polished.
If you want a powerful pressure washer that’s easier to store, easier to manoeuvre and far less faff to use than older, bulkier alternatives, the K5 Comfort Premium is easy to recommend. It’s expensive, sure, but it feels like money well spent.
How We Test
We test every pressure washer we review thoroughly over an extended period of time. We use standard tests to compare features properly. We’ll always tell you what we find. We never, ever, accept money to review a product.
Used as our main pressure washer for the review period
Tested on a variety of surfaces for cleaning power
FAQs
Is the Karcher K5 Comfort Premium good for car cleaning?
Yes. It works well for washing cars thanks to its reduced-pressure flat jet and built-in detergent system. You can rinse, apply detergent and switch back to a regular spray with a simple twist of the nozzle, making it much quicker and less fiddly than using separate attachments.
Advertisement
Does the Karcher K5 Comfort Premium have adjustable pressure?
Not in the traditional sense. You can change between different spray modes on the lance, but there’s no dedicated pressure control on the gun or main unit if you want finer adjustment.
Paramount+ looks to have used generative AI to whip up a thumbnail for Star Trek II: The Wrath of Khan, according to a report by Kotaku. The image shows Captain Kirk, as played by William Shatner, dressed in a business suit. Kirk never dons a business suit in Wrath of Khan, or any other time throughout Shatner’s decades of portraying the character. He did rock a flannel shirt and jeans once during a visit to 1930s Earth.
Paramount+ wanted to use the image on the left as a poster for the wrath of Khan, so they used everyone’s least favorite technology to generate the rest of the image.
I’ve watched every episode of Star Trek across a dozen shows and I’m not even sure business suits exist in that far-flung future, aside from an occasional appearance on the Holodeck. There’s no money, so not much need for business.
That leaves us asking why Paramount+ and its little AI buddy decided to plop Starfleet’s most iconic captain in a button-up shirt and tie. We don’t know exactly what happened, but artist Ryan Estrada has an idea. He noted that the actual image of Kirk is from Wrath of Khan, pulled from a scene in which the captain is getting a retinal scan to access a computer file. It’s not a particularly exciting scene, and he’s wearing a Starfleet uniform.
Estrada speculates that Paramount+ got attached to that image of Kirk getting a retinal scan and wanted to highlight it further by making it a thumbnail. However, the image from the film is a close-up of Shatner’s face, so generative AI was used to place Kirk’s head inside of a fake body and put that body in a business suit. His hair also looks very fake and weird as the original frame cuts off at his forehead. Long live AI slop Kirk.
Advertisement
Kotaku has confirmed that the thumbnail is still on the streaming platform, as have folks throughout the internet. Paramount owner David Ellison recently toldCNBC that the company is “using technology to transform every single aspect of this business.” If that thumbnail is a harbinger of things to come, Trek fans should likely start stocking up on Blu-Rays.
Wix is laying off roughly 20% of its workforce, about 1,000 employees, as CEO Avishai Abrahami cites both the rapid evolution of AI and currency pressure from a stronger Israeli shekel against the dollar. The web developer joins a growing list of tech companies making similar cuts, including Amazon, Block, Cisco, Cloudflare, Meta, Microsoft, Oracle and Intuit. Fast Company reports: “We have witnessed the most significant shift in how companies are built since the invention of modern programming languages in the 1970s,” [wrote Abrahami]. “This is not just about adopting new tools — it is about rewiring how companies are built, how they think, how they manage, and how they operate. Companies that embrace this change will not only build faster; they will build things the previous generation literally could not have imagined.”
Abrahami also cited the poor exchange rate between the Israeli shekel and the U.S. dollar. The Israeli currency has significantly strengthened in the past few quarters against a weakening dollar, and the shekel is up nearly 30% against the greenback over the last year.
“As the majority of our teams are Israel-based, a very meaningful portion of our costs are shekel-denominated, while our revenue is largely dollar-denominated,” Abrahami explained on X. “This creates a structural pressure on our ability to operate at our current scale. It is a reality that directly shapes what is sustainable for our company.”






































































You must be logged in to post a comment Login