Artificial intelligence promises to change not just how Americans work, but how societies decide which kinds of work are worthwhile in the first place. When technological change outpaces social judgment, a major capacity of a sophisticated society comes under pressure: the ability to sustain forms of work whose value is not obvious in advance and cannot be justified by necessity alone.
As AI systems diffuse rapidly across the economy, questions about how societies legitimate such work, and how these activities can serve as a supplement to market-based job creation, have taken on a policy relevance that deserves serious attention.
From Prayer to Platforms
That capacity for legitimating work has historically depended in part on how societies deploy economic surplus: the share of resources that can be devoted to activities not strictly required for material survival. In late medieval England, for example, many in the orbit of the church made at least part of their living performing spiritual labor such as saying prayers for the dead and requesting intercessions for patrons. In a society where salvation was a widely shared concern, such activities were broadly accepted as legitimate ways to make a living.
Advertisement
William Langland was one such prayer-sayer. He is known to history only because, unlike nearly all others who did similar work, he left behind a long allegorical religious poem, Piers Plowman, which he composed and repeatedly revised alongside the devotional labor that sustained him. It emerged from the same moral and institutional world in which paid prayer could legitimately absorb time, effort, and resources.
In 21st-century America, Jenny Nicholson earns a sizeable income sitting alone in front of a camera, producing long-form video essays on theme parks, films, and internet subcultures. Yet her audience supports it willingly and few doubt that it creates value of a kind. Where Langland’s livelihood depended on shared theological and moral authority emanating from a Church that was the dominant institution of its day, Nicholson’s depends on a different but equally real form of judgment expressed by individual market participants. And she is just one example of a broader class of creators—streamers, influencers, and professional gamers—whose work would have been unintelligible as a profession until recently.
What links Langland and Nicholson is not the substance of their work or any claim of moral equivalence, but the shared social judgment that certain activities are legitimate uses of economic surplus. Such judgments do more than reflect cultural taste. Historically, they have also shaped how societies adjust to technological change, by determining which forms of work can plausibly claim support when productivity rises faster than what is considered a “necessity” by society.
How Change Gets Absorbed
Advertisement
Technological change has long been understood to generate economic adjustment through familiar mechanisms: by creating new tasks within firms, expanding demand for improved goods and services, and recombining labor in complementary ways. Often, these mechanisms alone can explain how economies create new jobs when technology renders others obsolete. Their operation is well documented, and policies that reduce frictions in these processes—encouraging retraining or easing the entry of innovative firms—remain important in any period of change.
That said, there is no general law guaranteeing that new technologies will create more jobs than they destroy through these mechanisms alone. Alongside labor-market adjustment, societies have also adapted by legitimating new forms of value—activities like those undertaken by Langland and Nicholson—that came to be supported as worthwhile uses of the surplus generated by rising productivity.
This process has typically been examined not as a mechanism of economic adjustment, but through a critical or moralizing lens. From Thorstein Veblen’s account of conspicuous consumption, which treats surplus-supported activity primarily as a vehicle for status competition, to Max Weber’s analysis of how moral and religious worldviews legitimate economic behavior, scholars have often emphasized the symbolic and ideological dimensions of non-essential work. Herbert Marcuse pushed this line of thinking further, arguing that capitalist societies manufacture “false needs” to absorb surplus and assure the continuation of power imbalances. These perspectives offer real insight: uses of surplus are not morally neutral, and new forms of value can be entangled with power, hierarchy, and exclusion.
What they often exclude, however, is the way legitimation of new forms of value can also function to allow societies to absorb technological change without requiring increases in productivity to be translated immediately into conventional employment or consumption. New and expanded ways of using surplus are, in this sense, a critical economic safety valve during periods of rapid change.
Advertisement
Skilled Labor Has Been Here Before
Fears that artificial intelligence is uniquely threatening simply because it reaches into professional or cognitive domains rest on a mistaken historical premise. Episodes of large-scale technological displacement have rarely spared skilled or high-paid forms of labor; often, such work has been among the first affected. The mechanization of craft production in the nineteenth century displaced skilled cobblers, coopers, and blacksmiths, replacing independent artisans with factory systems that required fewer skills, paid lower wages, and offered less autonomy even as new skilled jobs arose elsewhere. These changes were disruptive but they were absorbed largely through falling prices, rising consumption, and new patterns of employment. They did not require societies to reconsider what kinds of activity were worthy uses of surplus: the same things were still produced, just at scale.
Other episodes are more revealing for present purposes. Sometimes, social change has unsettled not just particular occupations but entire regimes through which uses of surplus become legitimate. In medieval Europe, the Church was the one of the largest economic institutions just about everywhere, clerical and quasi-clerical roles like Langland’s offered recognized paths to education, security, status, and even wealth. When those shared beliefs fractured, the Church’s economic role contracted sharply—not because productivity gains ceased but because its claim on so large a share of surplus lost legitimacy.
To date, artificial intelligence has not produced large-scale job displacement, and the limited disruptions that have occurred have largely been absorbed through familiar adjustment mechanisms. But if AI systems begin to substitute for work whose value is justified less by necessity than by judgment or cultural recognition, the more relevant historical analogue may be less the mechanization of craft than the narrowing or collapse of earlier surplus regimes. The central question such technologies raise is not whether skilled labor can be displaced or whether large-scale displacement is possible—both have occurred repeatedly in the historical record—but how quickly societies can renegotiate which activities they are prepared to treat as legitimate uses of surplus when change arrives at unusual speed.
Advertisement
Time Compression and its Stakes
In this respect, artificial intelligence does appear unusual. Generative AI tools such as ChatGPT have diffused through society at a pace far faster than most earlier general-purpose technologies. ChatGPT was widely reported to have reached roughly 100 million users within two months of its public release and similar tools have shown comparably rapid uptake.
That compression matters. Much surplus has historically flowed through familiar institutions—universities, churches, museums, and other cultural bodies—that legitimate activities whose value lies in learning, spiritual rewards or meaning rather than immediate output. Yet such institutions are not fixed. Periods of rapid technological change often place them under strain–something evident today for many–exposing disagreements about purpose and authority. Under these conditions, experimentation with new forms of surplus becomes more important, not less. Most proposed new forms of value fail, and attempts to predict which will succeed have a poor historical record—from the South Sea Bubble to more recent efforts to anoint digital assets like NFTs as durable sources of wealth. Experimentation is not a guarantee of success; it is a hedge. Not all claims on surplus are benign, and waste is not harmless. But when technological change moves faster than institutional consensus, the greater danger often lies not in tolerating too many experiments, but in foreclosing them too quickly.
Artificial intelligence does not require discarding all existing theories of change. What sets modern times apart is the speed with which new capabilities become widespread, shortening the interval in which those judgments are formed. In this context, surplus that once supported meaningful, if unconventional, work may instead be captured by grifters, legally barred from legitimacy (by say, outlawing a new art form) or funneled into bubbles. The risk is not waste alone, but the erosion of the cultural and institutional buffers that make adaptation possible.
Advertisement
The challenge for policymakers is not to pre-ordain which new forms of value deserve support but to protect the space in which judgment can evolve. They need to realize that they simply cannot make the world entirely safe, legible and predictable: whether they fear technology overall or simply seek to shape it in the “right” way, they will not be able to predict the future. That means tolerating ambiguity and accepting that many experiments will fail with negative consequences. In this context, broader social barriers that prevent innovation in any field–professional licensing, limits on free expression, overly zealous IP laws, regulatory bars on the entry to small firms–deserve a great deal of scrutiny. Even if the particular barriers in question have nothing to do with AI itself, they may retard the development of surplus sinks necessary to economic adjustment. In a period of compressed adjustment, the capacity to let surplus breathe and value be contested may well determine whether economies bend or break.
Eli Lehrer is the President of the R Street Institute.
State-backed hackers are using Google’s Gemini AI model to support all stages of an attack, from reconnaissance to post-compromise actions.
Bad actors from China (APT31, Temp.HEX), Iran (APT42), North Korea (UNC2970), and Russia used Gemini for target profiling and open-source intelligence, generating phishing lures, translating text, coding, vulnerability testing, and troubleshooting.
Cybercriminals are also showing increased interest in AI tools and services that could help in illegal activities, such as social engineering ClickFix campaigns.
AI-enhanced malicious activity
The Google Threat Intelligence Group (GTIG) notes in a report today that APT adversaries use Gemini to support their campaigns “from reconnaissance and phishing lure creation to command and control (C2) development and data exfiltration.”
Chinese threat actors employed an expert cybersecurity persona to request that Gemini automate vulnerability analysis and provide targeted testing plans in the context of a fabricated scenario.
Advertisement
“The PRC-based threat actor fabricated a scenario, in one case trialing Hexstrike MCP tooling, and directing the model to analyze Remote Code Execution (RCE), WAF bypass techniques, and SQL injection test results against specific US-based targets,” Google says.
Another China-based actor frequently employed Gemini to fix their code, carry out research, and provide advice on technical capabilities for intrusions.
The Iranian adversary APT42 leveraged Google’s LLM for social engineering campaigns, as a development platform to speed up the creation of tailored malicious tools (debugging, code generation, and researching exploitation techniques).
Additional threat actor abuse was observed for implementing new capabilities into existing malware families, including the CoinBait phishing kit and the HonestCue malware downloader and launcher.
Advertisement
GTIG notes that no major breakthroughs have occurred in that respect, though the tech giant expects malware operators to continue to integrate AI capabilities into their toolsets.
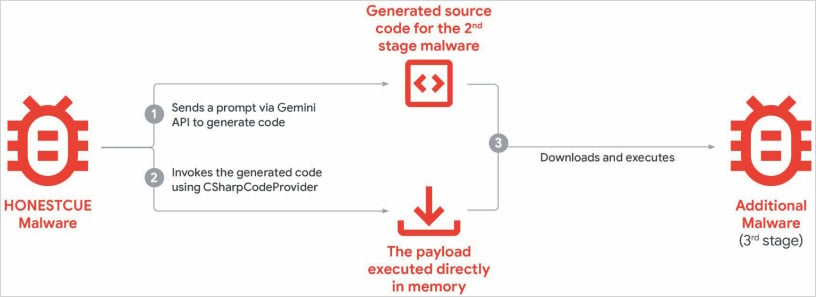
HonestCue is a proof-of-concept malware framework observed in late 2025 that uses the Gemini API to generate C# code for second-stage malware, then compiles and executes the payloads in memory.
HonestCue operational overview Source: Google
CoinBait is a React SPA-wrapped phishing kit masquerading as a cryptocurrency exchange for credential harvesting. It contains artifacts indicating that its development was advanced using AI code generation tools.
One indicator of LLM use is logging messages in the malware source code that were prefixed with “Analytics:,” which could help defenders track data exfiltration processes.
Based on the malware samples, GTIG researchers believe that the malware was created using the Lovable AI platform, as the developer used the Lovable Supabase client and lovable.app.
Advertisement
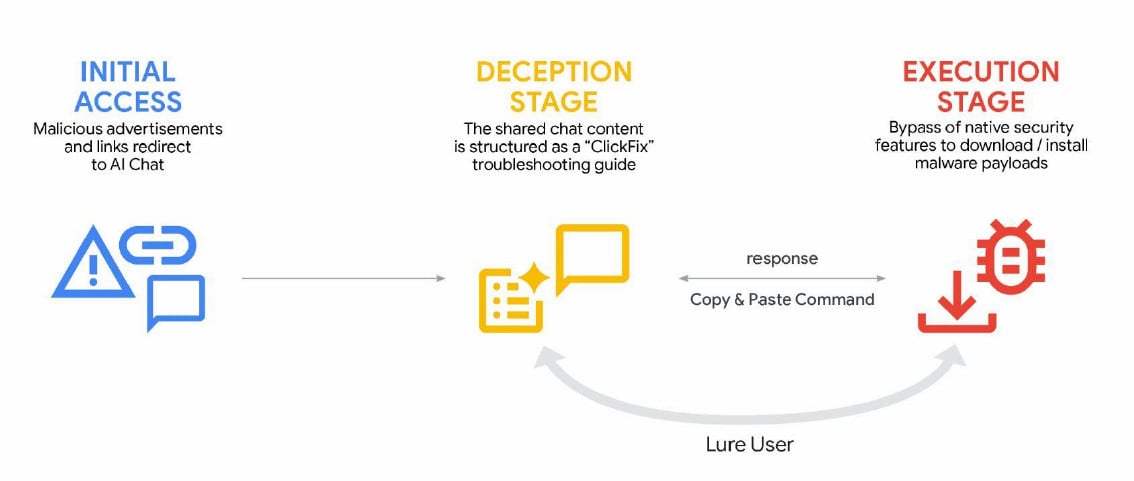
Cybercriminals also used generative AI services in ClickFix campaigns, delivering the AMOS info-stealing malware for macOS. Users were lured to execute malicious commands through malicious ads listed in search results for queries on troubleshooting specific issues.
AI-powered ClickFix attack source: Google
The report further notes that Gemini has faced AI model extraction and distillation attempts, with organizations leveraging authorized API access to methodically query the system and reproduce its decision-making processes to replicate its functionality.
Although the problem is not a direct threat to users of these models or their data, it constitutes a significant commercial, competitive, and intellectual property problem for the creators of these models.
Essentially, actors take information obtained from one model and transfer the information to another using a machine learning technique called “knowledge distillation,” which is used to train fresh models from more advanced ones.
“Model extraction and subsequent knowledge distillation enable an attacker to accelerate AI model development quickly and at a significantly lower cost,” GTIG researchers say.
Advertisement
Google flags these attacks as a threat because they constitute intellectual theft, they are scalable, and severely undermine the business model of AI-as-a-service, which has the potential to impact end users soon.
In a large-scale attack of this kind, Gemini AI was targeted by 100,000 prompts that posed a series of questions aimed at replicating the model’s reasoning across a range of tasks in non-English languages.
Google has disabled accounts and infrastructure tied to documented abuse, and has implemented targeted defenses in Gemini’s classifiers to make abuse harder.
The company assures that it “designs AI systems with robust security measures and strong safety guardrails” and regularly tests the models to improve their security and safety.
Advertisement
Modern IT infrastructure moves faster than manual workflows can handle.
In this new Tines guide, learn how your team can reduce hidden manual delays, improve reliability through automated response, and build and scale intelligent workflows on top of tools you already use.
When enterprises fine-tune LLMs for new tasks, they risk breaking everything the models already know. This forces companies to maintain separate models for every skill.
Researchers at MIT, the Improbable AI Lab and ETH Zurich have developed a new technique that enables large language models to learn new skills and knowledge without forgetting their past capabilities.
Their technique, called self-distillation fine-tuning (SDFT), allows models to learn directly from demonstrations and their own experiments by leveraging the inherent in-context learning abilities of modern LLMs. Experiments show that SDFT consistently outperforms traditional supervised fine-tuning (SFT) while addressing the limitations of reinforcement learning algorithms.
For enterprise applications, the method enables a single model to accumulate multiple skills over time without suffering from performance regression on earlier tasks. This offers a potential pathway for building AI agents that can adapt to dynamic business environments, gathering new proprietary knowledge and skills as needed without requiring expensive retraining cycles or losing their general reasoning abilities.
Advertisement
The challenge of continual learning
Once an LLM is trained and deployed, it remains static. It does not update its parameters to acquire new skills, internalize new knowledge, or improve from experience. To build truly adaptive AI, the industry needs to solve “continual learning,” allowing systems to accumulate knowledge much like humans do throughout their careers.
The most effective way for models to learn is through “on-policy learning.” In this approach, the model learns from data it generates itself allowing it to correct its own errors and reasoning processes. This stands in contrast to learning by simply mimicking static datasets. Without on-policy learning, models are prone to “catastrophic forgetting,” a phenomenon where learning a new task causes the model to lose its past knowledge and ability to perform previous tasks.
However, on-policy learning typically requires reinforcement learning (RL), which depends on an explicit reward function to score the model’s outputs. This works well for problems with clear outcomes, such as math and coding. But in many real-world enterprise scenarios (e.g., writing a legal brief or summarizing a meeting), defining a mathematical reward function is difficult or impossible.
RL methods also often fail when trying to teach a model entirely new information, such as a specific company protocol or a new product line. As Idan Shenfeld, a doctorate student at MIT and co-author of the paper, told VentureBeat, “No matter how many times the base model tries, it cannot generate correct answers for a topic it has zero knowledge about,” meaning it never gets a positive signal to learn from.
Advertisement
The standard alternative is supervised fine-tuning (SFT), where the model is trained on a fixed dataset of expert demonstrations. While SFT provides clear ground truth, it is inherently “off-policy.” Because the model is just mimicking data rather than learning from its own attempts, it often fails to generalize to out-of-distribution examples and suffers heavily from catastrophic forgetting.
SDFT seeks to bridge this gap: enabling the benefits of on-policy learning using only prerecorded demonstrations, without needing a reward function.
How SDFT works
SDFT solves this problem by using “distillation,” a process where a student model learns to mimic a teacher. The researchers’ insight was to use the model’s own “in-context learning” (ICL) capabilities to create a feedback loop within a single model.
In-context learning is the phenomenon where you provide the LLM with a difficult task and one or more demonstrations of how similar problems are solved. Most advanced LLMs are designed to solve new problems with ICL examples, without any parameter updates.
Advertisement
During the training cycle, SDFT employs the model in two roles.
The teacher: A frozen version of the model is fed the query along with expert demonstrations. Using ICL, the teacher deduces the correct answer and the reasoning logic required to reach it.
The student: This version sees only the query, simulating a real-world deployment scenario where no answer key is available.
When the student generates an answer, the teacher, which has access to the expert demonstrations, provides feedback. The student then updates its parameters to align closer to the teacher’s distribution.
This process effectively creates an on-policy learning loop by combining elements of SFT and RL. The supervision comes not from a static dataset, but from the model’s own interaction and outputs. It allows the model to correct its own reasoning trajectories without requiring an external reward signal. This process works even for new knowledge that RL would miss.
Advertisement
SDFT in action
To validate the approach, the researchers tested SDFT using the open-weight Qwen 2.5 model on three complex enterprise-grade skills: science Q&A, software tool use, and medical reasoning.
The results showed that SDFT learned new tasks more effectively than standard methods. On the Science Q&A benchmark, the SDFT model achieved 70.2% accuracy, compared to 66.2% for the standard SFT approach.
Contrary to SFT, SDFT preserves the model’s original knowledge while learning new tasks and knowledge (source: arXiv)
More important for enterprise adoption is the impact on catastrophic forgetting. When the standard SFT model learned the science task, its ability to answer general questions (such as logic or humanities) collapsed. In contrast, the SDFT model improved on the science task while holding its “Previous Tasks” score steady at 64.5%. This stability suggests companies could specialize models for specific departments (e.g., HR or Legal) without degrading the model’s basic common sense or reasoning capabilities.
Advertisement
The team also simulated a knowledge injection scenario, creating a dataset of fictional “2025 Natural Disasters” to teach the model new facts. They tested the model on indirect reasoning questions, such as “Given the floods in 2025, which countries likely needed humanitarian aid?”
Standard SFT resulted in a model that memorized facts but struggled to use them in reasoning scenarios. The SDFT model, having internalized the logic during training, scored 98% on the same questions.
Finally, the researchers conducted a sequential learning experiment, training the model on science, tool use, and medical tasks one after another. While the standard model’s performance oscillated, losing previous skills as it learned new ones, the SDFT model successfully accumulated all three skills without regression.
SDFT can learn different skills sequentially while preserving its previous knowledge (source: arXiv)
Advertisement
This capability addresses a major pain point for enterprises currently managing “model zoos” of separate adapters for different tasks.
“We offer the ability to maintain only a single model for all the company’s needs,” Shenfeld said. This consolidation “can lead to a substantial reduction in inference costs” because organizations don’t need to host multiple models simultaneously.
SDFT limitations and availability
The code for SDFT is available on GitHub and ready to be integrated into existing model training workflows.
“The SDFT pipeline is more similar to the RL pipeline in that it requires online response generation during training,” Shenfeld said. They are working with Hugging Face to integrate SDFT into the latter’s Transformer Reinforcement Learning (TRL) library, he added, noting that a pull request is already open for developers who want to test the integration.
Advertisement
For teams considering SDFT, the practical tradeoffs come down to model size and compute. The technique requires models with strong enough in-context learning to act as their own teachers — currently around 4 billion parameters with newer architectures like Qwen 3, though Shenfeld expects 1 billion-parameter models to work soon. It demands roughly 2.5 times the compute of standard fine-tuning, but is best suited for organizations that need a single model to accumulate multiple skills over time, particularly in domains where defining a reward function for reinforcement learning is difficult or impossible.
While effective, the method does come with computational tradeoffs. SDFT is approximately four times slower and requires 2.5 times more computational power (FLOPs) than standard fine-tuning because the model must actively generate its own answers (“rollouts”) during training to compare against the teacher. However, the researchers note that because the model retains knowledge better, organizations may avoid the costly multi-stage retraining processes often required to repair models that suffer from catastrophic forgetting.
The technique also relies on the underlying model being large enough to benefit from in-context learning. The paper notes that smaller models (e.g., 3 billion parameters) initially struggled because they lacked the “intelligence” to act as their own teachers.
However, Shenfeld said that the rapid improvement of small models is changing this dynamic. “The Qwen 2.5 3B models were too weak, but in some experiments we currently do, we found that the Qwen 3 4B model is strong enough,” he said. “I see a future where even 1B models have good enough ICL capabilities to support SDFT.”
Advertisement
Ultimately, the goal is to move beyond static snapshots toward systems that improve through use.
“Lifelong learning, together with the ability to extract learning signal from unstructured user interactions… will bring models that just keep and keep improving with time,” Shenfeld said.
“Think about the fact that already the majority of compute around the world goes into inference instead of training. We have to find ways to harness this compute to improve our models.”
Last May, law enforcement authorities around the world scored a key win when they hobbled the infrastructure of Lumma, an infostealer that infected nearly 395,000 Windows computers over just a two-month span leading up to the international operation. Researchers said Wednesday that Lumma is once again “back at scale” in hard-to-detect attacks that pilfer credentials and sensitive files.
Lumma, also known as Lumma Stealer, first appeared in Russian-speaking cybercrime forums in 2022. Its cloud-based malware-as-a-service model provided a sprawling infrastructure of domains for hosting lure sites offering free cracked software, games, and pirated movies, as well as command-and-control channels and everything else a threat actor needed to run their infostealing enterprise. Within a year, Lumma was selling for as much as $2,500 for premium versions. By the spring of 2024, the FBI counted more than 21,000 listings on crime forums. Last year, Microsoft said Lumma had become the “go-to tool” for multiple crime groups, including Scattered Spider, one of the most prolific groups.
Takedowns are hard
The FBI and an international coalition of its counterparts took action early last year. In May, they said they seized 2,300 domains, command-and-control infrastructure, and crime marketplaces that had enabled the infostealer to thrive. Recently, however, the malware has made a comeback, allowing it to infect a significant number of machines again.
“LummaStealer is back at scale, despite a major 2025 law-enforcement takedown that disrupted thousands of its command-and-control domains,” researchers from security firm Bitdefender wrote. “The operation has rapidly rebuilt its infrastructure and continues to spread worldwide.”
Advertisement
As with Lumma before, the recent surge leans heavily on “ClickFix,” a form of social engineering lure that’s proving to be vexingly effective in causing end users to infect their own machines. Typically, these types of bait come in the form of fake CAPTCHAs that—rather requiring users to click a box or identify objects or letters in a jumbled image—instruct them to copy text and paste it into an interface, a process that takes just seconds. The text comes in the form of malicious commands provided by the fake CAPTCHA. The interface is the Windows terminal. Targets who comply then install loader malware, which in turn installs Lumma.
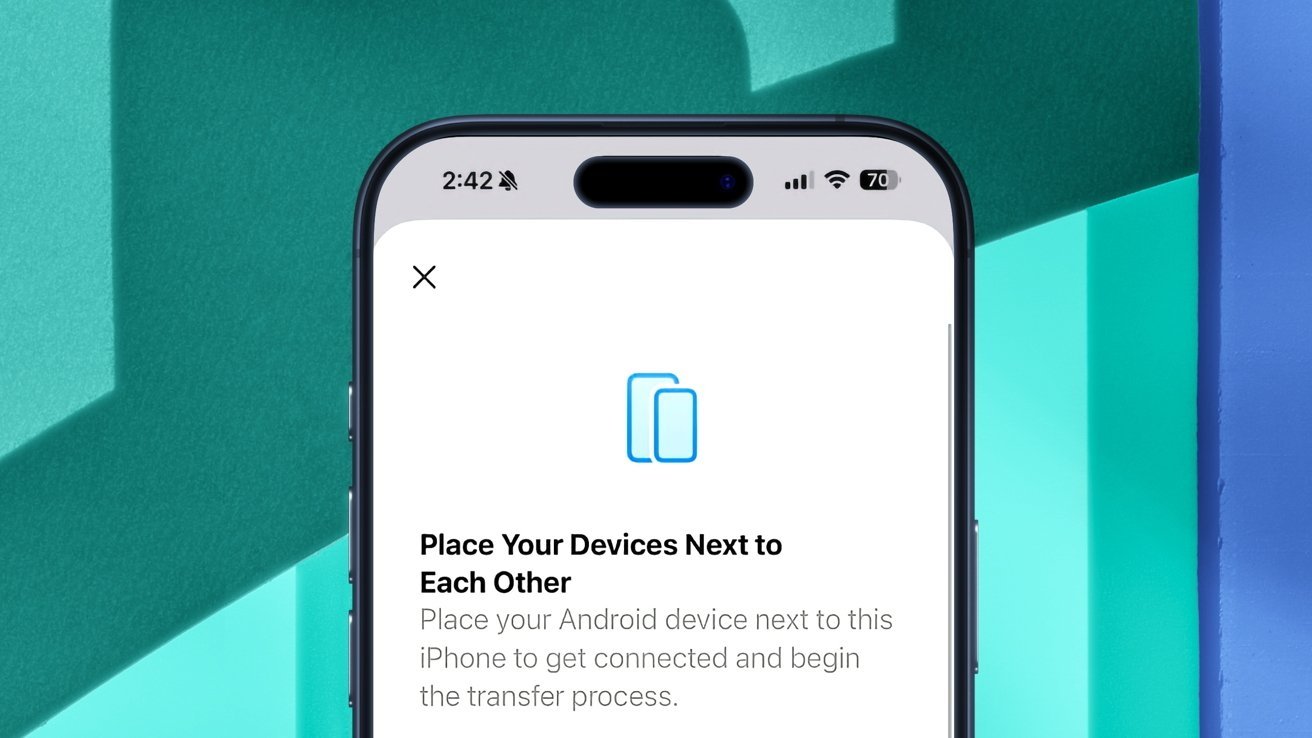
Apple has released iOS 26.3 to the public, with the changes including a simplified way to transfer to an Android device.
Transfer to Android is now an option in iOS 26.3
Following another beta testing cycle, Apple has released its update for iOS 26.3 to the public. The update follows after just one beta build was tested by Apple, with testers using the first build throughout the end-of-year holiday period. While iOS 26.2 brought many new features to the operating system, iOS 26.3 brings somewhat fewer. This is fairly common for Apple, as the main features are released as part of the initial release in the fall, with fewer features added down the road. Continue Reading on AppleInsider | Discuss on our Forums
Making sure the heatgun is on ‘low’ and gloves are on while pushing on the mold. (Credit: Zion Brock)
Although hobbyists these days most often seem to use thermoplastics as a print-and-done material in FDM printers, there’s absolutely nothing stopping you from taking things further with thermoforming. Much like forming acrylic using a hot wire or hot air, thermoplastics like PLA can be further tweaked with a similar method. This can be much less complex than 3D printing the design with supports, as demonstrated by [Zion Brock].
For this classically styled radio project the front grille was previously 3D printed with the curved shape, but to avoid an ugly edge it had to be printed with most of the grille off the print bed, requiring countless supports and hours of printing time. To get around this, [Zion] opted to print the grille flat and then thermoform its curved shape. Of course, due to the unusual shape of the grille, this required a bit more effort than e.g. a spherical form.
This is similar to what is used with sheet metal to get detailed shaped, also requiring a mold and a way to stretch the flat shape over the mold. With the flat form designed to have all the material in the right places, it was able to be printed in less than an hour in PLA and then formed with a heatgun aimed at the part while the two-section mold is slid together to create the final form.
You can find the design files and full instructions on the website for the radio project.
Cleveland’s Terminal Tower, a landmark of the city’s skyline since 1930. (GeekWire Photo / Kurt Schlosser)
Cleveland Mayor Justin M. Bibb responded Wednesday to a GeekWire guest column in which Seattle tech veteran and angel investor Charles Fitzgerald warned the Pacific Northwest tech hub not to repeat the mistakes that led to the Ohio city’s decades-long decline.
The real lesson, Mayor Bibb asserted, isn’t in the city’s past but in its ongoing comeback.
Cleveland Mayor Justin M. Bibb. (City of Cleveland Photo)
“For decades, national narratives have framed Cleveland as a cautionary tale,” he wrote on LinkedIn. “But that framing misses the bigger story. Cleveland didn’t quit. Cleveland rebuilt.”
In his response, he pointed to Cleveland’s institutional anchors, including the Cleveland Clinic and Case Western Reserve University, as engines of a growing health-tech and research economy. “This is the Cleveland ERA,” he wrote, citing billions in infrastructure and development investments.
Bibb, 38, is a Cleveland native with degrees from American University and Case Western and a background in civic technology and racial equity advocacy. He took office in January 2022 and was reelected last November with nearly 74% of the vote. He recently ended a term as president of the Democratic Mayors Association.
Seattle, he wrote, “should study Cleveland as a case study of what’s possible when you confront age-old problems with bold, urgent leadership.”
Advertisement
In many ways, Fitzgerald and Bibb seem to be on the same page.
Fitzgerald welcomed Bibb’s response and, in a comment on LinkedIn, sought to clarify: “This is not about Cleveland today.”
He explained, “My point is how cities should respond when their world changes. Deindustrialization came for Cleveland 75 years ago. Seattle has punched well above its weight in software, but that era is ending. We must confront that reality plus, like every city, adapt to the broader AI wave.”
Fitzgerald also agreed that Seattle has a lot to learn from Cleveland.
Advertisement
“People in Seattle complain about the problems of being a prosperous city,” he wrote. “They should hear firsthand about what it means to manage a city that was once also very prosperous, but lost that prosperity. You’re playing the game in difficult mode. We can learn from that.”
In his original column, Fitzgerald drew a parallel between Seattle now and Cleveland in the 1950s, when it was the seventh-largest U.S. city, home to industrial giants like Standard Oil and Republic Steel, with median household incomes rivaling New York’s.
Within two decades, the city’s fortunes had reversed dramatically. Cleveland has since dropped to 56th in population, with median incomes less than half the national average.
Fitzgerald’s concern is that Seattle, riding decades of prosperity fueled by Microsoft, Amazon, and the broader software industry, may be approaching a similar inflection point as the AI era reshapes the tech landscape. He worries that local leaders aren’t paying attention.
Advertisement
What’s more, he asserted, legislators in Olympia are treating the tech industry as a bottomless source of revenue rather than working to nurture the region’s economic future — a dynamic he says mirrors Cleveland’s missteps during the Rust Belt era, when a confrontational posture from local government made it easier for companies to leave.
Bibb’s response cited specifics including a $100 million investment to transform 1,000 acres of industrial land, a $1.6 billion airport modernization, and nearly $5 billion reshaping the city’s lakefront and the Cuyahoga River.
The mayor’s post drew a wave of support from Clevelanders, many of whom took issue with Fitzgerald’s framing. “My lord, what a lazy, outdated trope,” wrote one commenter. Others pointed to Cleveland’s strengths in healthcare and the arts, and its cultural diversity.
The original column also generated spirited responses in GeekWire’s inbox, with no shortage of profanity from Cleveland partisans.
Advertisement
One LinkedIn commenter noted the juxtaposition of the “foreboding, black and white skyline photo” combined with the “Don’t become the next Cleveland” headline and the author’s closing disclaimer: “I want to be very clear that I mean no offense to Cleveland.”
(By the way, the photo on the column was chosen by GeekWire’s editors, not by Fitzgerald, so we’ll own that one. Note the blue skies in the lead photo on this follow-up piece!)
Others offered a more nuanced view. One commenter who moved to Cleveland from the Pacific Northwest wrote that the city “should be nervous about repeating mistakes that have failed repeatedly across the nation,” adding that Cleveland’s real opportunity lies in expanding economic prospects for working people rather than the wealthy.
In the end, the mayor invited Fitzgerald to visit and see the progress firsthand.
Advertisement
Fitzgerald seemed to be open to the idea, in his inimitable way. He has already emailed the mayor, and noted in his LinkedIn comment, “I’m waiting for the tickets for my junket to arrive.”
In the meantime, GeekWire has contacted Bibb’s office to see if we can arrange a follow-up interview, and raised the possibility of Fitzgerald joining the call. Stay tuned.
[Teddy Warner]’s GPenT (Generative Pen-trained Transformer) project is a wall-mounted polargraph that makes plotter art, but there’s a whole lot more going on than one might think. This project was partly born from [Teddy]’s ideas about how to use aspects of machine learning in ways that were really never intended. What resulted is a wall-mounted pen plotter that offers a load of different ‘generators’ — ways to create line art — that range from procedural patterns, to image uploads, to the titular machine learning shenanigans.
There are loads of different ways to represent images with lines, and this project helps explore them.
Want to see the capabilities for yourself? There’s a publicly accessible version of the plotter interface that lets one play with the different generators. The public instance is not connected to a physical plotter, but one can still generate and preview plots, and download the resulting SVG file or G-code.
Most of the generators do not involve machine learning, but the unusual generative angle is well-represented by two of them: dcode and GPenT.
dcode is a diffusion model that, instead of converting a text prompt into an image, has been trained to convert text directly into G-code. It’s very much a square peg in a round hole. Visually it’s perhaps not the most exciting, but as a concept it’s fascinating.
The titular GPenT works like this: give it a scrap of text inspiration (a seed, if you will), and that becomes a combination of other generators and parameters, machine-selected and stacked with one another to produce a final composition. The results are unique, to say the least.
Advertisement
Once the generators make something, the framed and wall-mounted plotter turns it into physical lines on paper. Watch the system’s first plot happen in the video, embedded below under the page break.
This is a monster of a project representing a custom CNC pen plotter, a frame to hold it, and the whole software pipeline both for the CNC machine as well as generating what it plots. Of course, the journey involved a few false starts and dead ends, but they’re all pretty interesting. The plotter’s GitHub repository combined with [Teddy]’s write up has all the details one may need.
It’s also one of those years-in-the-making projects that ultimately got finished and, we think, doing so led to a bit of a sigh of relief on [Teddy]’s part. Most of us have unfinished projects, and if you have one that’s being a bit of a drag, we’d like to remind you that you don’t necessarily have to finish-finish a project to get it off your plate. We have some solid advice on how to (productively) let go.
Chinese AI startup Zhupai aka z.ai is back this week with an eye-popping new frontier large language model: GLM-5.
The latest in z.ai’s ongoing and continually impressive GLM series, it retains an open source MIT License — perfect for enterprise deployment – and, in one of several notable achievements, achieves a record-low hallucination rate on the independent Artificial Analysis Intelligence Index v4.0.
With a score of -1 on the AA-Omniscience Index—representing a massive 35-point improvement over its predecessor—GLM-5 now leads the entire AI industry, including U.S. competitors like Google, OpenAI and Anthropic, in knowledge reliability by knowing when to abstain rather than fabricate information.
Beyond its reasoning prowess, GLM-5 is built for high-utility knowledge work. It features native “Agent Mode” capabilities that allow it to turn raw prompts or source materials directly into professional office documents, including ready-to-use .docx, .pdf, and .xlsx files.
Whether generating detailed financial reports, high school sponsorship proposals, or complex spreadsheets, GLM-5 delivers results in real-world formats that integrate directly into enterprise workflows.
Advertisement
It is also disruptively priced at roughly $0.80 per million input tokens and $2.56 per million output tokens, approximately 6x cheaper than proprietary competitors like Claude Opus 4.6, making state-of-the-art agentic engineering more cost-effective than ever before. Here’s what else enterprise decision makers should know about the model and its training.
Technology: scaling for agentic efficiency
At the heart of GLM-5 is a massive leap in raw parameters. The model scales from the 355B parameters of GLM-4.5 to a staggering 744B parameters, with 40B active per token in its Mixture-of-Experts (MoE) architecture. This growth is supported by an increase in pre-training data to 28.5T tokens.
To address training inefficiencies at this magnitude, Zai developed “slime,” a novel asynchronous reinforcement learning (RL) infrastructure.
Traditional RL often suffers from “long-tail” bottlenecks; Slime breaks this lockstep by allowing trajectories to be generated independently, enabling the fine-grained iterations necessary for complex agentic behavior.
Advertisement
By integrating system-level optimizations like Active Partial Rollouts (APRIL), slime addresses the generation bottlenecks that typically consume over 90% of RL training time, significantly accelerating the iteration cycle for complex agentic tasks.
The framework’s design is centered on a tripartite modular system: a high-performance training module powered by Megatron-LM, a rollout module utilizing SGLang and custom routers for high-throughput data generation, and a centralized Data Buffer that manages prompt initialization and rollout storage.
By enabling adaptive verifiable environments and multi-turn compilation feedback loops, slime provides the robust, high-throughput foundation required to transition AI from simple chat interactions toward rigorous, long-horizon systems engineering.
To keep deployment manageable, GLM-5 integrates DeepSeek Sparse Attention (DSA), preserving a 200K context capacity while drastically reducing costs.
Advertisement
End-to-end knowledge work
Zai is framing GLM-5 as an “office” tool for the AGI era. While previous models focused on snippets, GLM-5 is built to deliver ready-to-use documents.
It can autonomously transform prompts into formatted .docx, .pdf, and .xlsx files—ranging from financial reports to sponsorship proposals.
In practice, this means the model can decompose high-level goals into actionable subtasks and perform “Agentic Engineering,” where humans define quality gates while the AI handles execution.
High performance
GLM-5’s benchmarks make it the new most powerful open source model in the world, according to Artificial Analysis, surpassing Chinese rival Moonshot’s new Kimi K2.5 released just two weeks ago, showing that Chinese AI companies are nearly caught up with far better resourced proprietary Western rivals.
Advertisement
According to z.ai’s own materials shared today, GLM-5 ranks near state-of-the-art on several key benchmarks:
SWE-bench Verified: GLM-5 achieved a score of 77.8, outperforming Gemini 3 Pro (76.2) and approaching Claude Opus 4.6 (80.9).
Vending Bench 2: In a simulation of running a business, GLM-5 ranked #1 among open-source models with a final balance of $4,432.12.
GLM-5 benchmarks from z.ai
Advertisement
Beyond performance, GLM-5 is aggressively undercutting the market. Live on OpenRouter as of February 11, 2026, it is priced at approximately $0.80–$1.00 per million input tokens and $2.56–$3.20 per million output tokens. It falls in the mid-range compared to other leading LLMs, but based on its top-tier bechmarking performance, it’s what one might call a “steal.”
This is roughly 6x cheaper on input and nearly 10x cheaper on output than Claude Opus 4.6 ($5/$25). This release confirms rumors that Zhipu AI was behind “Pony Alpha,” a stealth model that previously crushed coding benchmarks on OpenRouter.
Advertisement
However, despite the high benchmarks and low cost, not all early users are enthusiastic about the model, noting its high performance doesn’t tell the whole story.
Lukas Petersson, co-founder of the safety-focused autonomous AI protocol startup Andon Labs, remarked on X: “After hours of reading GLM-5 traces: an incredibly effective model, but far less situationally aware. Achieves goals via aggressive tactics but doesn’t reason about its situation or leverage experience. This is scary. This is how you get a paperclip maximizer.”
The “paperclip maximizer” refers to a hypothetical situation described by Oxford philosopher Nick Bostrom back in 2003, in which an AI or other autonomous creation accidentally leads to an apocalyptic scenario or human extinction by following a seemingly benign instruction — like maximizing the number of paperclips produced — to an extreme degree, redirecting all resources necessary for human (or other life) or otherwise making life impossible through its commitment to fulfilling the seemingly benign objective.
Should your enterprise adopt GLM-5?
Enterprises seeking to escape vendor lock-in will find GLM-5’s MIT License and open-weights availability a significant strategic advantage. Unlike closed-source competitors that keep intelligence behind proprietary walls, GLM-5 allows organizations to host their own frontier-level intelligence.
Advertisement
Adoption is not without friction. The sheer scale of GLM-5—744B parameters—requires a massive hardware floor that may be out of reach for smaller firms without significant cloud or on-premise GPU clusters.
Security leaders must weigh the geopolitical implications of a flagship model from a China-based lab, especially in regulated industries where data residency and provenance are strictly audited.
Furthermore, the shift toward more autonomous AI agents introduces new governance risks. As models move from “chat” to “work,” they begin to operate across apps and files autonomously. Without the robust agent-specific permissions and human-in-the-loop quality gates established by enterprise data leaders, the risk of autonomous error increases exponentially.
Ultimately, GLM-5 is a “buy” for organizations that have outgrown simple copilots and are ready to build a truly autonomous office.
Advertisement
It is for engineers who need to refactor a legacy backend or requires a “self-healing” pipeline that doesn’t sleep.
While Western labs continue to optimize for “Thinking” and reasoning depth, Zai is optimizing for execution and scale.
Enterprises that adopt GLM-5 today are not just buying a cheaper model; they are betting on a future where the most valuable AI is the one that can finish the project without being asked twice.
The best place to start is at the beginning, so the video demonstrates a simple cube wireframe drawn by connecting eight points together with lines. This is simple enough, but modern 3D graphics are really triangles stitched together to make essentially every shape we see on the screen. For [NCOT Technology]’s software, he’s using the Utah Teapot, essentially the “hello world” of 3D graphics programming. The first step is drawing all of the triangles to make the teapot wireframe. Then the triangles are made opaque, which is a step in the right direction but isn’t quite complete. The next steps to make it look more like a teapot are to hide the back faces of the triangles, figure out which of them face the viewer at any given moment, and then make sure that all of these triangles are drawn in the correct orientation.
Rendering a teapot is one thing, but to get to something more modern-looking like a first-person shooter, he also demonstrates all the matrix math that allows the player to move around an object. Technically, the object moves around the viewer, but the end effect is one that eventually makes it so we can play our favorite games, from DOOM to DOOM Eternal. He notes that his code isn’t perfect, but he did it from the ground up and didn’t use anything to build it other than his computer and his own brain, and now understands 3D graphics on a much deeper level than simply using an engine or API would generally allow for. The 3D world can also be explored through the magic of Excel.
A member of the Crazy ransomware gang is abusing legitimate employee monitoring software and the SimpleHelp remote support tool to maintain persistence in corporate networks, evade detection, and prepare for ransomware deployment.
The breaches were observed by researchers at Huntress, who investigated multiple incidents where threat actors deployed Net Monitor for Employees Professional alongside SimpleHelp for remote access to a breached network, while blending in with normal administrative activity.
In one intrusion, attackers installed Net Monitor for Employees Professional using the Windows Installer utility, msiexec.exe, allowing them to deploy the monitoring agent on compromised systems directly from the developer’s site.
Once installed, the tool allowed attackers to remotely view the victim’s desktop, transfer files, and execute commands, effectively providing full interactive access to compromised systems.
The attackers also attempted to enable the local administrator account using this command:
Advertisement
net user administrator /active:yes
For redundant persistence, attackers downloaded and installed the SimpleHelp remote access client via PowerShell commands, using file names similar to the legitimate Visual Studio vshost.exe.
The payload was then executed, allowing attackers to maintain remote access even if the employee monitoring tool was removed.
The SimpleHelp binary was sometimes disguised using filenames that pretended to be related to OneDrive:
C:\ProgramData\OneDriveSvc\OneDriveSvc.exe
The attackers used the monitoring software to execute commands remotely, transfer files, and monitor system activity in real time.
Advertisement
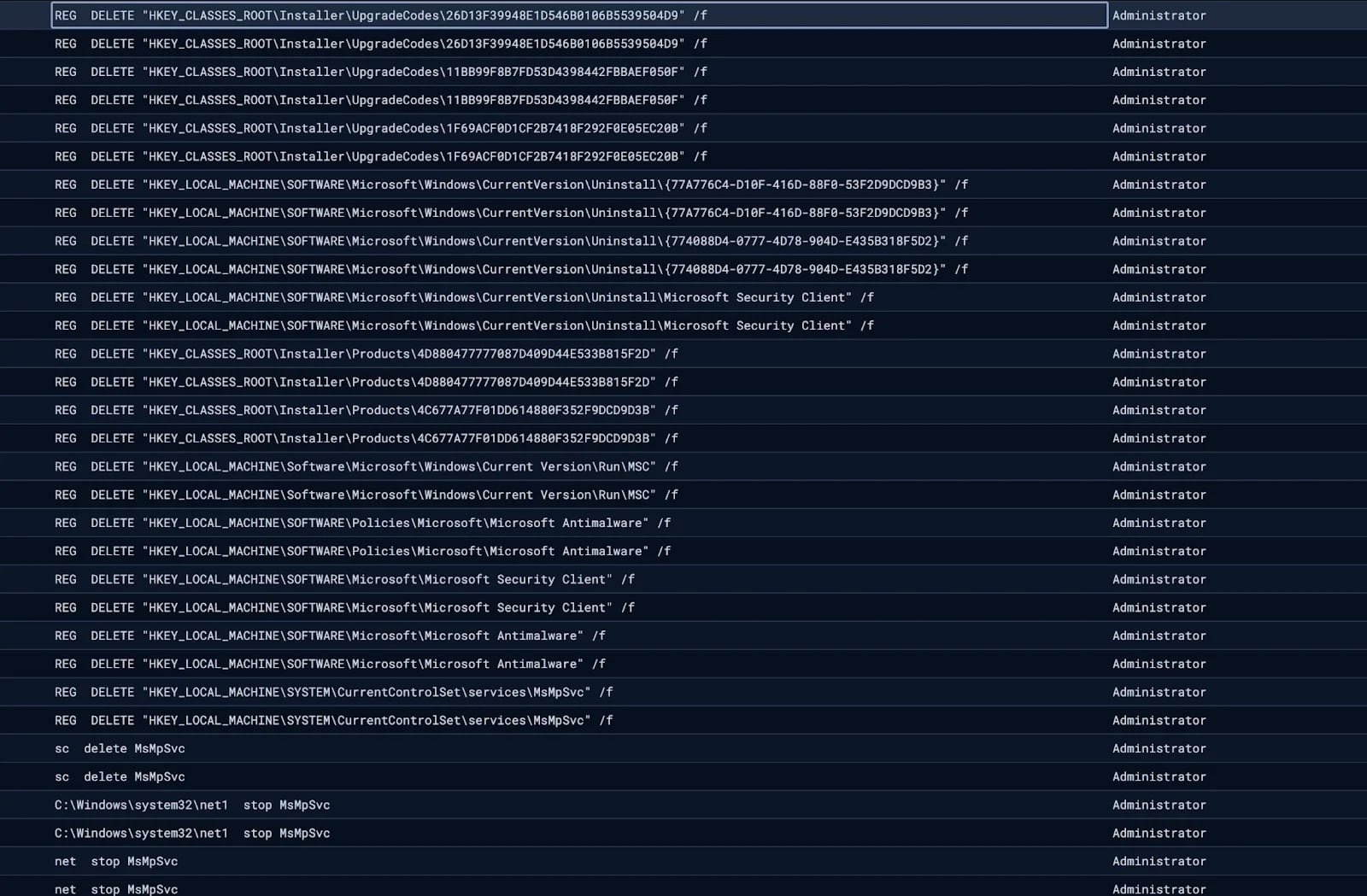
Researchers also observed the attackers disabling Windows Defender by attempting to stop and delete associated services.
Disabling Windows Defender Source: Huntress
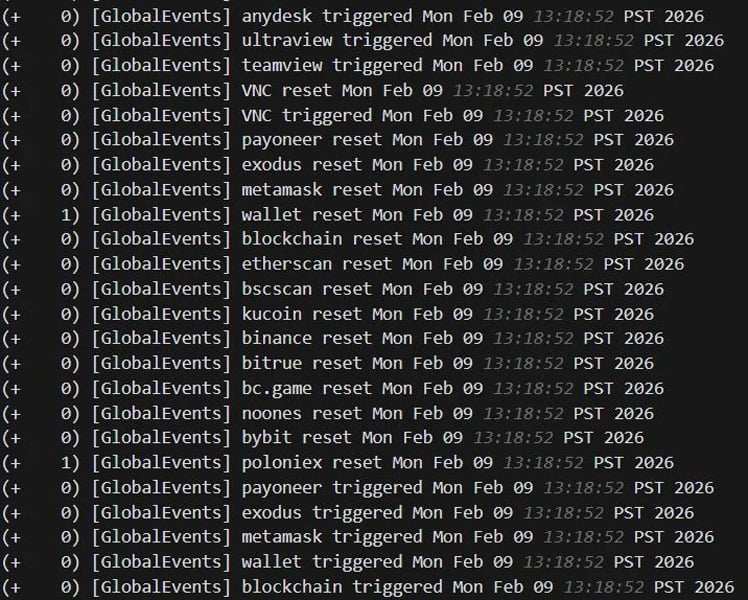
In one incident, the hackers configured monitoring rules in SimpleHelp to alert them when devices accessed cryptocurrency wallets or were using remote management tools as they prepared for ransomware deployment and potential cryptocurrency theft.
“The logs show the agent continuously cycling through trigger and reset events for cryptocurrency-related keywords, including wallet services (metamask, exodus, wallet, blockchain), exchanges (binance, bybit, kucoin, bitrue, poloniex, bc.game, noones), blockchain explorers (etherscan, bscscan), and the payment platform payoneer,” explains Huntress.
“Alongside these, the agent also monitored for remote access tool keywords, including RDP, anydesk, ultraview, teamview, and VNC, likely to detect if anyone was actively connecting to the machine.”
Keywords monitored by SimpleHelp agent Source: Huntress
The use of multiple remote access tools provided redundancy for the attackers, ensuring they retained access even if one tool was discovered or removed.
While only one incident led to the deployment of Crazy ransomware, Huntress believes the same threat actor is behind both incidents.
Advertisement
“The same filename (vhost.exe) and overlapping C2 infrastructure were reused across both cases, strongly suggesting a single operator or group behind both intrusions,” explains Huntress.
The use of legitimate remote management and monitoring tools has become increasingly common in ransomware intrusions, as these tools allow attackers to blend in with legitimate network traffic.
Huntress warns that organizations should closely monitor for unauthorized installations of remote monitoring and support tools.
Furthermore, as both breaches were enabled through compromised SSL VPN credentials, organizations need to enforce MFA on all remote access services used to access the network.
Advertisement
Modern IT infrastructure moves faster than manual workflows can handle.
In this new Tines guide, learn how your team can reduce hidden manual delays, improve reliability through automated response, and build and scale intelligent workflows on top of tools you already use.