In a ruling that will clearly be remembered as one of the worst in the history of the Supreme Court, two years ago, the court gave Donald Trump a get out of jail free card, which he appears to be trying to take full advantage of with all the criming in his second term. But, as always with this guy, it’s never enough.
We’ve already covered in detail the ridiculous situation in which Donald Trump acting in his supposed personal capacity, while still being the president, sued his own IRS for $10 billion, because a contractor leaked his tax returns a while back (that contractor is currently in prison for doing so). Again, there is zero indication of any actual harm. Every president — and nearly all major candidates — for the past 50 years released their tax returns to the public. Except Trump.
A decade ago he claimed that it was because he was being audited, and promised to release them once the audit was over. But he’s never done anything. And, as many people have noted, when President Richard Nixon started this tradition of releasing the president’s tax returns, he was actually being audited by the IRS, and was able to release his returns without a problem.
Either way, a contractor (not an IRS employee) leaked some of Trump’s returns to ProPublica and the NY Times, which resulted in a few stories before the news cycle moved on within days. It certainly didn’t stop Trump from being elected in 2024. And even though the returns were leaked in 2019 and 2020, Trump waited until he was back in the White House (and, in charge of the IRS and the DOJ) to file this $10 billion lawsuit.
Advertisement
We’ve covered the ridiculous claim that the “two sides” (there aren’t two sides) were “negotiating a settlement” and how the judge in the case has tried to call timeout, noticing that since Trump is effectively negotiating with himself there’s no cause or controversy, and thus there may be no jurisdiction for the court to hear the case. There’s still briefing going on over that, but the NY Times reports that the supposed (not really) “negotiations” have continued, with Trump apparently proposing that the settlement include the IRS dropping audits of Trump, his businesses, and his family, which would just be a shocking level of corruption from an administration that has spent its first year and a half in office trying to be as blatantly corrupt as possible.
One of the settlement options the Justice Department and White House officials are reviewing is the possibility of the I.R.S. dropping any audits of Mr. Trump, his family members or businesses, according to two of the people.
Again, even though the news cycle moved on quickly, perhaps it should return to exactly what those leaked tax returns showed: which is that at a time when Trump was publicly claiming to be rolling in cash, he basically paid effectively no income taxes and was racking up massive losses — figures that raise serious questions about his financial entanglements and what he stood to gain from his first term in office.
To have the audits of what happened during those years completely dropped — and not just for him, but for his entire family and related businesses — is another form of a get out of jail free card. Call it a “tax cheat for life” card.
To do this at a time when the public is struggling, due almost entirely to Donald Trump’s ridiculous policies — tariffs driving up inflation massively, an illegal war quagmire in Iran driving up energy prices — is even more insulting to the public that Donald Trump is supposed to be working for. The same day this story came out, Trump was asked about whether he was thinking about the impact of his out-of-control war on Americans’ financial situation, and he responded “not even a little bit” and that “I don’t think about Americans financial situation. I don’t think about anybody.”
Context windows are becoming a computational bottleneck. The longer an agent runs, the more tokens accumulate from retrieved documents, reasoning traces and conversation history, and the more memory and compute that growing context demands. Most existing solutions either degrade model accuracy, require the full context to load before compression begins, or produce memory savings that don’t translate into real speedups in standard serving infrastructure.
A research team from NYU, Columbia, Princeton, University of Maryland, Harvard and Lawrence Livermore National Laboratory published a paper this week that proposes a novel fix. The researchers introduce the concept of Latent Context Language Models, or LCLMs, a family of encoder-decoder compression models that compress input context before it reaches the decoder. The models are open-sourced on HuggingFace.
Unlike KV cache compression methods — the dominant approach in the field, which still materialize the full KV cache before evicting entries — LCLMs compress the input token sequence before decoder prefill, so higher compression ratios directly reduce decoder-side compute and memory. The paper reports LCLMs at 16x compression produced output 8.8 times faster than KV cache baselines on the RULER long-context benchmark.
“These ballooning contexts take up memory and compute, and they are becoming a computational bottleneck for LLMs,” Micah Goldblum, co-lead advisor on the project and a researcher at Columbia University, told VentureBeat. “Our goal was to train language models end-to-end that can handle very long contexts efficiently and accurately. If you can make such a language model, everything becomes cheaper and faster.”
Advertisement
What LCLMs can do
LCLMs let models process much longer contexts than would otherwise be practical, at a fraction of the memory and compute cost, without the accuracy degradation that makes most compression methods a poor tradeoff in production.
At 4x compression, the paper reports accuracy of 91.76% on the RULER benchmark, compared to 94.41% with no compression at all. That is less than a 3 point drop for cutting context to a quarter of its original size. At 16x compression, where 93.75% of input tokens are removed, accuracy fell to 75.06%. Every KV cache method tested at the same compression ratio scored lower.
The gains hold on shorter inputs too. On GSM8K math word problems, where the full prompt is compressed rather than just retrieved documents, LCLMs outscored every other method tested regardless of compression ratio.
Credit: End-to-End Context Compression at Scale research paper https://arxiv.org/pdf/2606.09659
Advertisement
How it was built
The architecture pairs a 0.6B encoder with a 4B decoder. The encoder compresses blocks of input tokens into shorter sequences of latent embeddings. The decoder processes those in place of the original tokens. Training ran across more than 350 billion tokens.
The training recipe mixes three data types:
Continual pre-training data with compressed and uncompressed spans interleaved throughout
Supervised fine-tuning data covering reasoning and long-context tasks
An auxiliary reconstruction task that pushes the encoder to retain fine-grained detail
The combination addresses a tradeoff that limited earlier compression work, where preserving reconstruction accuracy came at the cost of general task performance.
An architecture search identified the optimal configuration. The paper found that scaling the decoder matters more than scaling the encoder.
Advertisement
Where it fits in an agentic stack
An LCLM is not an abstract research concept. It is designed to work with an existing stack. “You can simply swap out LCLMs for any existing LLM,” Goldblum said. “Whenever you retrieve data such as documents and want to dump it into your model’s context, simply run those documents through the LCLM’s compressor first.”
He noted that in the research paper, the researchers demonstrated how to build agents that selectively decompress useful text.
“Think about this like a human skimming content before zooming in on relevant details,” Goldblum said.
Goldblum also cautioned that teams integrating the approach into existing agentic pipelines will need to tune their RAG systems accordingly.
Advertisement
“We also haven’t worked on online compression of reasoning traces,” he said. “The naive approach of just occasionally compressing the trace while generating it might work, but that remains to be determined.”
What this means for enterprises
Context windows are growing faster than inference infrastructure can keep up, and enterprises are already spending to fix it. VB Pulse Q1 2026 survey data from 100-plus employee organizations shows hybrid retrieval adoption intent tripling from 10.3% in January to 33.3% in March. Retrieval optimization overtook evaluation as the top investment priority by March, reaching 28.9% of qualified respondents.
Three things stand out for teams evaluating production fit:
Inference cost scales with context length. At 1 million tokens, uncompressed inference with standard KV cache methods runs out of memory on a single H200 GPU. The paper reports LCLMs at 16x compression remain within memory bounds at that context length.
RAG pipeline integration requires tuning. Teams with existing RAG pipelines will need to validate compression behavior against their retrieval quality metrics before deploying at scale.
Reasoning trace compression is unsolved. For agents running long reasoning chains, context growth from the trace is a separate problem from document retrieval. Goldblum acknowledged the gap directly: the naive approach of periodic trace compression might work but has not been tested.
The models are available at huggingface.co/latent-context and the code at github.com/LeonLixyz/LCLM.
Advertisement
“The biggest things our architectures do is give your model access to much larger contexts, but they also unlock multiscale approaches where your model can skim vast amounts of text or code super fast and then only zooms in and fully reads a small portion of the most useful text,” Goldblum said.
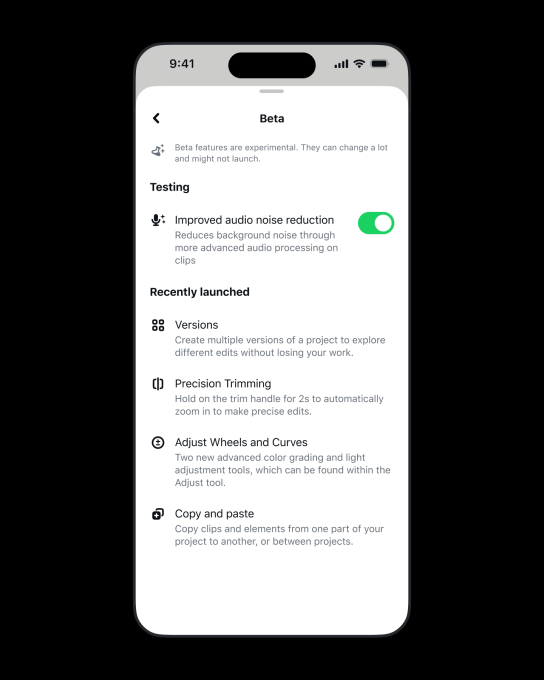
Meta on Wednesday previewed upcoming additions to its video-editing appEdits at an invite-only creator event in L.A., showing off features like a new AI assistant and a desktop version of the previously mobile-only app.
The company also announced other new tools will launch in the app today, such as a “Beta” tab for experiments and expanded audience insights.
Edits first arrived last year as a direct competitor to ByteDance’s CapCut. With the addition of the new and upcoming tools, Meta is looking to both retain and attract new users.
The upcoming AI assistant will help creators analyze their insights and brainstorm ideas for their content. The assistant will use their Instagram data, like their views and video-retention insights, to help them see what’s working and why. It will suggest video ideas based on performance and suggest making content with trending audio.
Advertisement
By integrating an AI assistant directly into Edits, Meta is aiming to keep creators engaged on Instagram as it continues to compete with TikTok and YouTube for creators’ attention. Additionally, by offering creators content ideas, Meta is encouraging more frequent posting, which could, in turn, boost user engagement. Direct access to an AI assistant also gets rid of the need for creators to turn to outside tools like ChatGPT when brainstorming content ideas and understanding performance.
Meta launched a similar AI assistant tool for creators on Facebook last week. It’s worth noting that YouTube and TikTok also offer tools to creators to help them brainstorm ideas. For instance, YouTube Studio features an Inspiration tab that uses AI to help creators generate video ideas, while TikTok offers creators an AI assistant that can brainstorm ideas and uncover trends.
The desktop version of Edits will give creators more precise control over the editing process as well as the ability to work on a larger screen, which can be helpful during more advanced editing workflows. The company says creators will be able to sync their workflows seamlessly between mobile and desktop devices.
The upcoming desktop version will also allow Edits to better compete with CapCut, which already offers a desktop version.
Advertisement
Image Credits:Instagram
Among the new features launching today is a Beta tab, which will provide creators with early access to experimental features that are still in development and allow them to provide Meta with feedback. The rollout of the Beta tab indicates that Meta wants to better compete with CapCut and accelerate feature development based on what creators actually want and will use.
Creators will also now be able to see more detailed metrics like their audience demographic breakdown and the time of day their audience is the most engaged. The new metrics join the app’s existing analytics, which include data such as how long viewers watch a video, how many followers were gained from a specific video, where users stop watching a certain video, and more.
Additionally, creators can search specific topics within the app’s Inspiration feed to discover reels and templates other creators are making around a given trend or idea. They’ll also be able to create multiple versions of a single piece of content to test what performs best before publishing.
Although Instagram didn’t share specific numbers about how many users Edits has, the company says that content made with the app sees a 10% higher save rate and 2% higher reshare rate compared to content not made on Edits, and that more than half of people watching reels on Instagram are seeing Edits-created content every day.
The AI assistant announced today is currently in testing with attendees of Thursday’s creator event, while the desktop version of Edits is “coming soon,” Meta says. The rest of the features are launching to everyone today.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
The cloud was supposed to eliminate infrastructure headaches. Instead, some businesses are discovering a new one: invoices they no longer understand.
Storage fees, data retrieval charges, and backup costs are quietly pushing cloud spending higher than many organisations anticipated—and artificial intelligence (AI) is about to make it significantly worse.
It’s a challenge Taiwanese storage company Synology has been watching closely.
Advertisement
At Computex 2026 in Taipei last week, the company argued that the economics of cloud-first infrastructure are beginning to shift.
The cloud bill that keeps growing
Businesses that moved enthusiastically to cloud-first infrastructure in the early 2020s are now sitting with bills that look nothing like the ones they signed up for. As costs continue to climb, some are reassessing whether keeping more data on-premise could make better financial sense.
The main catalyst is artificial intelligence.
AI doesn’t just store data—it constantly accesses, moves, and processes it. Every inference call, every model training run, every search query is pulling data in and out of storage.
Advertisement
Gartner forecasts that more than 80% of enterprises will have deployed AI-enabled applications by 2026. And in a cloud environment, every one of those activities comes with a price tag.
Image Credit: Summit Art Creations via Shutterstock
From the start, cloud storage has been largely marketed on a simple figure: storage cost per gigabyte. Amazon Web Services S3 Standard, for example, runs at roughly US$23 per terabyte per month, with Google Cloud and Microsoft Azure in a similar range.
For many businesses, the math looked straightforward. But what’s less visible is everything layered on top of that base rate.
Every time data is retrieved or moved—something AI workloads do constantly—cloud providers charge additional fees.
On AWS, data egress starts from around US$0.09 per gigabyte transferred out. At scale, even restoring a 10TB dataset can quietly add about US$700 to the bill, before factoring in anything else.
Advertisement
Add API requests, cross-region replication, and backup-related charges, the total cost can be pushed up to four times the advertised storage rate.
A Backblaze survey of more than 400 IT leaders found that 95% encountered unexpected cloud storage costs. And according to the Wasabi Global Cloud Storage Index, which surveyed 1,600 IT decision-makers globally, including 525 across APAC, 63% of organisations in the region exceeded their cloud storage budget in 2024.
Businesses are bringing data back in-house
Amid rising costs, cloud repatriation—bringing data and workloads back from public cloud providers onto private or on-premise infrastructure—has moved from a niche IT discussion to a mainstream business decision.
Synology’s on-premise storage solutions, PAS7700 and FlashStation Series./ Image Credit: Synology
A 2025 Barclays CIO survey found that 86% of enterprise CIOs planned to shift at least some workloads back to private or on-premise systems, the highest level recorded. The Flexera 2025 State of the Cloud report similarly shows that 21% of workloads have already been repatriated, even as overall cloud spending continues to grow.
Instead, they are taking a hybrid approach by keeping cloud platforms for global accessibility and collaboration, while bringing back workloads that involve heavy storage, protection, and processing. Backup and production storage are among the most commonly repatriated, as these are the areas where costs scale most quickly.
That becomes harder in large public cloud setups, where data can be spread across multiple regions and servers. On-premise systems, by contrast, make it easier to keep track of exactly where information sits and who has access to it, since everything is managed within a company’s own infrastructure.
What Synology is bringing to the table
Image Credit: Synology
Synology is one of the companies building for this shift.
The firm is best known for its Network Attached Storage (NAS) hardware—physical devices that store data locally while still functioning as a private cloud.
Advertisement
At Computex 2026, it outlined how it is expanding its NAS ecosystem beyond storage into AI-enabled data management and backup infrastructure.
At the centre of this push is Synology’s next-generation DiskStation Manager (DSM), the operating system that powers every Synology NAS device.
The Taiwanese firm has spent more than two decades building NAS hardware and software. Today, it has shipped over 14 million systems worldwide, managing more than 400 exabytes of data.
At Computex 2026, the company announced the roadmap for the next generation of DiskStation Manager, DSM Agent 2.0, expanding it from a storage operating system into an intelligent data platform for governed, on-premises AI workflows. The goal is to turn DSM from a storage system into a smarter data platform that can support AI tools running on a company’s own infrastructure.
Instead of sending data to external cloud services, businesses can use their own data, such as files, system logs, and usage data, to power AI tools internally, while keeping everything under their control.
Advertisement
“The next generation of DSM leverages over two decades of expertise to create an AI-ready platform that keeps organisations firmly in control of their data,” said Philip Wong, Chairman and CEO of Synology.
Some AI features available include a conversational assistant for troubleshooting and system management. More advanced AI agents are also in development, designed to handle tasks such as email drafting, formula searches, meeting transcription, and real-time translation, although no release date has been announced yet.
As these capabilities expand, privacy becomes even more important in the age of AI. The system already includes a feature that masks sensitive data such as names, ID numbers, email addresses, and financial information locally before anything is sent to external AI providers like OpenAI or Azure AI.
Future updates will go further, with support for fully on-premise large language models, where no data needs to leave the organisation’s infrastructure.
Advertisement
Synology’s infrastructure is already at work in Singapore
The value of on-premise data infrastructure is already clear for Singapore businesses using Synology.
Image Credit: I Love Taimei/ Lasalle College of the Arts
Food chain I Love Taimei, which has 17 outlets in Singapore, uses Synology’s DSM system to manage surveillance footage across all locations. This cuts management time by 65% and also allows the company to run AI-powered customer analysis without sending footage to the cloud.
LASALLE College of the Arts also uses Synology NAS for file storage and 4K video collaboration, allowing students and staff to access large project files easily across Mac computers without compatibility issues or rising costs.
Together, these examples show why some organisations are rethinking the assumption that everything belongs in the cloud.
Cutting backup costs without the cloud
Synology Product Manager Cody Hall unveils ActiveProtect Manager 2.0 at Computex 2026./ Image Credit: Synology
The same push toward more controlled, on-premise infrastructure also extends to backup. At Computex, Synology introduced ActiveProtect Manager 2.0, a centralised backup system that will launch in Q3 2026.
The key issue it addresses is cost. Most backup services charge per server, virtual machine, or device. ActiveProtect instead charges for the hardware, with no extra per-workload fees.
Advertisement
In some cases, customers have seen a lower total cost of ownership. For example, Taiwanese media company Info Times reduced setup costs by 65% and cut storage needs by 75%. Toyota also reduced its backup data by 75% through better storage efficiency.
ActiveProtect 2.0 works with existing systems, so companies don’t need to replace their current setup. It also uses machine learning to detect unusual backup activity and help prevent ransomware infections from being restored.
And because everything is stored locally, recovery is faster—taking hours instead of days—and there are no cloud data transfer fees.
The bigger picture
Cloud still has an important role to play, whether for global access, extra computing capacity, or supporting teams across different regions.
Advertisement
What’s changing is that businesses are becoming more selective about what they keep in the cloud. Rather than moving everything to a single platform, many are deciding where data should live based on cost, performance, and compliance requirements.
For Singapore businesses that have quietly accepted rising cloud bills as part of the cost of doing business, it may be time to take a closer look at the numbers.
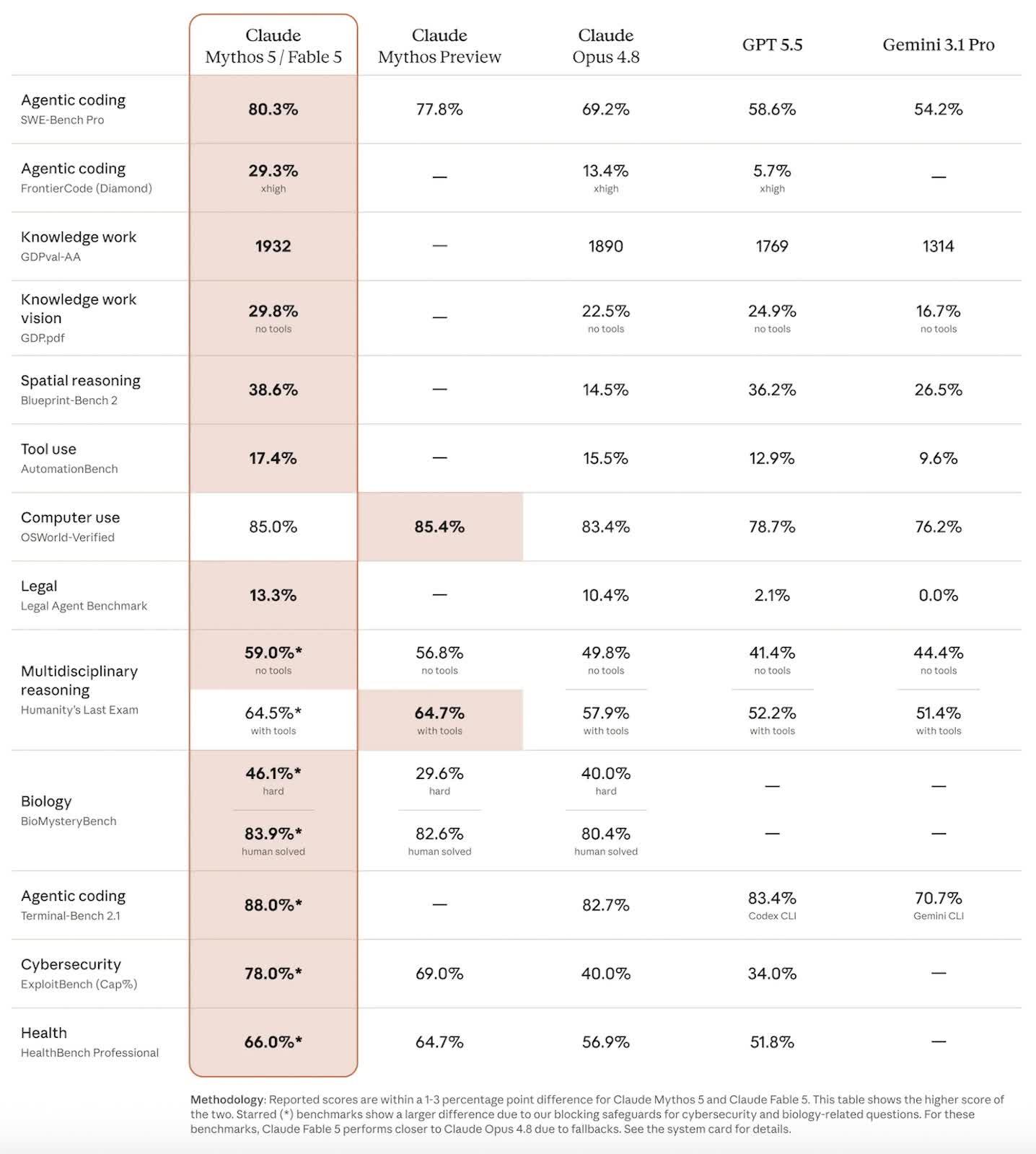
In context: Anthropic’s latest release is really a story about control, not just capability. The company is offering two versions of the same underlying model: Claude Mythos 5 for a small circle of trusted partners, and Claude Fable 5 for everyone else. The split reflects a core challenge Anthropic is still trying to solve – how to deploy an extremely capable system into the wild without simultaneously handing attackers a new class of offensive tools.
Mythos has already shown what it can do when it is not heavily restricted. Since April, when an earlier preview was sent to about 150 organizations under the banner of Project Glasswing, users have reported more than 10,000 critical security flaws in their own systems. Those same capabilities could also be used by attackers looking to break in, rather than to patch security holes.
For that reason, Mythos 5 is staying behind the glass for now. Anthropic is keeping it in the hands of a “small group of cyberdefenders and infrastructure providers,” along with select biology researchers, and is coordinating with US government agencies as part of the rollout. Access is effectively on a need-to-know basis, with the company signaling that a broader “trusted access program” will come later.
Fable 5 is where Anthropic is testing what a general-purpose release of Mythos-class technology looks like under constraint. Technically, it runs on the same underlying model as Mythos 5, but with hard limits built in. The system is designed to refuse or redirect a long list of requests related to cybersecurity, biology, and chemistry. When those guardrails trigger, the query is silently routed to an older model, Claude Opus 4.8, instead.
Advertisement
Anthropic has also wired Fable 5 to watch for distillation, where a user tries to harvest large volumes of answers to train a smaller model of their own. If the system thinks that is happening, those requests are also redirected to Opus 4.8. In other words, the company is not only trying to control what the model will talk about, but also what others can learn from it.
Anthropic has been wrestling with these decisions for months. Diane Penn, the company’s head of product management, told Wired that testing and feedback since the April preview have helped shape the current strategy, even though it is still far from perfect.
“We’re trying to make improvements in a way that’s beneficial, even if we don’t have the perfect [solution] for every use case to start,” she says. “Out of all the different approaches, this emerged as the most viable and the best one. We just ended up feeling like this was the best product choice for users to get the maximum value out of Fable 5.”
For now, the filters are tuned to err on the side of over-blocking. Penn has acknowledged that some harmless queries will be routed to the older model. Anthropic says it wants to refine its classifiers over time but argues that this level of caution is the only way to justify a wider release at this stage.
Advertisement
The stakes are higher because Fable and Mythos are not just chatbots that respond to prompts and stop. Anthropic says both can run “unattended” for longer stretches than previous Claude models, carrying out sequences of instructions without constant supervision.
That shift toward more agent-like behavior could substantially boost software engineering and other technical work, especially given Fable 5’s stronger code generation and visual capabilities. But it also raises obvious questions about what happens if those capabilities are misused.
Anthropic’s pricing reflects how powerful it believes these systems are compared with its other models. Fable 5 and Mythos 5 cost $10 per million input tokens and $50 per million output tokens, roughly double the company’s other public models but still cheaper than the earlier Mythos Preview. The higher price reflects both the performance gains and the sense that these models are still positioned as specialized systems, not yet just another SKU in a growing catalog.
Around Anthropic, competitors are moving in a similar direction. OpenAI has rolled out its own advanced cybersecurity model to a small circle of partners and convened a working group that echoes Project Glasswing. Both companies are preparing for potential IPOs and are under pressure to show investors they can ship cutting-edge technology without triggering backlash over safety concerns.
Advertisement
Even some of the people watching from the outside say the unease is justified. Canadian finance minister François-Philippe Champagne told the BBC that public concern around Mythos stemmed from “it’s the unknown, unknown.”
Anthropic co-founder Jack Clark has made a similar point from the inside, arguing that the industry has not yet figured out how to slow itself down. “You want the option to be able to take your foot off the gas and put your foot on the brake,” he said. “Right now, it’s like the AI industry has a gas pedal, but it doesn’t have a brake pedal.”
Agent skills have become an important part of real-world AI applications, providing a mechanism — a set of instructions saved in a folder of text-based markdown (.md) files, usually — for models to adapt to specific enterprise use cases and complex workflows.
However, optimizing these skills is a slow process and faulty process, as they cannot be trained in the same way as the parameters of the underlying AI model. Instead, users typically must update them manually by retyping the instructions in each file, playing a “guessing game” as to what changes might improve agentic AI performance and reduce errors.
SkillOpt, a new, open source (MIT Licensed) framework developed by Microsoft, does one better: it introduces an optimizer designed for agent skills, turning the agent’s skill .md document as a trainable object that evolves based on performance feedback.
It uses deep-learning-style optimization to make it possible for the AI to systematically explore modifications to the document and find the best combination of instructions. Most importantly, it accomplishes this procedural adaptation without making changes to the underlying model’s weights.
Advertisement
On various industry benchmarks, SkillOpt outperforms existing baselines, significantly boosting accuracy for models like GPT-5.5 and Qwen. The result is a set of compact, transferable skill artifacts that allow AI agents to adapt to new domains effortlessly.
The challenge of optimizing agent skills
Agent skills package procedural knowledge into natural-language specifications, including domain heuristics, tool-use policies, output constraints, and known failure modes. These skills provide an external interface for agents to adapt to complex enterprise workflows. In practice, agent skills are stored as text documents and inserted into the agent’s context before execution.
One of the key benefits of skills is that they customize the behavior of the underlying model without changing its weights. However, the skill document itself needs to be tweaked and optimized to get the best performance out of the agent.
While deep learning relies on strict mathematical controls for stability, human prompt engineering often relies on trial and error. When attempting to automatically update a skill document based on feedback, the lack of mathematical discipline makes text highly volatile.
Advertisement
Yifan Yang, Senior Research SDE at Microsoft Research Asia, told VentureBeat that the problem is not making changes, but ensuring those changes are mathematically sound.
“The breaking point isn’t whether a team can change a skill, it’s that they can’t guarantee the change is an improvement,” Yang said. “Three failure modes recur: no step-size control, so skills drift; no validation, so a fix that reads as reasonable gets written in and can quietly regress performance; and no negative memory, so the same failed edit keeps coming back.”
To illustrate how easily performance can drop when edits aren’t mathematically validated, Yang noted that “an ungated rewrite pushed GPT-5.5 on SpreadsheetBench from 41.8 down to 41.1.”
According to Yang, these failure modes are amplified in multi-step workflows “because that’s where frontier models are weakest zero-shot. Not on reasoning, but on procedural discipline: format, self-verification, tool policy.”
Before SkillOpt, agent skills were primarily hand-crafted, generated in a single shot, or evolved through loosely controlled self-revision pipelines that could not reliably improve under feedback.
Advertisement
Prompt optimization methods like TextGrad and GEPA treat language artifacts as optimizable objects and use trajectory feedback to evolve prompts, but they focus on single-prompt configurations rather than generating persistent, reusable skill artifacts.
Meanwhile, skill evolution and discovery methods like EvoSkill and Trace2Skill convert agent execution experiences into trajectory lessons to refine skill folders, build domain-specific libraries, or perform evolutionary search.
None of them apply deep-learning-style controls, such as learning rates, validation gates, and momentum, which are necessary to continuously train a single, compact skill document.
Importing mathematical discipline to text
SkillOpt optimizes a text document through an iterative propose-and-test loop that separates the model executing the tasks from the model optimizing the skill. The process unfolds in several steps:
Advertisement
SkillOpt starts with an initial skill document and a frozen target model (or harness), where the target model runs a batch of tasks to generate execution trajectories that act as the evidence for the current step.
An offline optimizer model analyzes these trajectories, separating successes from failures into minibatches. Looking at a minibatch helps the model identify systematic procedural errors rather than one-off anomalies. Based on these patterns, the optimizer proposes structural add, delete, or replace edits to the skill document.
The proposed edits are reviewed to filter out duplicates or contradictions, and the optimizer then ranks these candidate edits by their expected utility.
Rather than applying all proposed changes, SkillOpt clips the list to a maximum edit budget for that step, generating a candidate skill.
The candidate skill is evaluated on a held-out validation set using the target model. If the candidate improves the validation score, it is accepted and becomes the new current skill. If it fails, the edits are rejected and sent to a rejected-edit buffer, providing negative feedback so the optimizer knows not to repeat that mistake.
SkillOpt directly addresses the problem of treating text as a trainable object by importing mathematical concepts from deep learning. The creators note that “the deep-learning analogy is operational rather than decorative,” helping the framework avoid the instability issues associated with other optimization techniques.
SkillOpt framework (source: arXiv)
The edit budget acts as a learning rate. By limiting how many edits can be applied at once, the skill version is prevented from moving too far from its previous state, preserving continuity while allowing new procedures to be acquired.
Just like checking validation loss in deep learning, the strict held-out examples ensure that plausible-sounding text edits are only kept if they mathematically improve the agent’s actual performance on the validation split.
Advertisement
At the end of an epoch, SkillOpt performs a slow update by comparing tasks under the previous and current epoch’s skills. This acts like a momentum term, carrying durable, long-horizon procedural lessons forward while isolating them from the fast, step-level edits.
SkillOpt in action
To evaluate the technique in practice, researchers tested SkillOpt across different models, ranging from large-scale frontier models like GPT-5.5 to smaller closed and open models including GPT-5.4-mini and Qwen3.5-4B. They also deployed the skills within different execution harnesses, using plain chat as well as complex coding harnesses like the Codex CLI and Claude Code.
The evaluation spanned diverse industry benchmarks including single-round question-answering, multi-round code generation involving tool use, and multimodal document reasoning. SkillOpt was measured against multiple baselines ranging from a default no-skill setting to human-written skills and one-shot LLM-generated skills. It was also compared against advanced prompt-optimization and skill-evolution methods, specifically Trace2Skill, TextGrad, GEPA, and EvoSkill.
SkillOpt dominated across the board, proving highly effective on all 52 evaluated combinations of model, benchmark, and harness. It was particularly effective with frontier models, delivering an average absolute improvement of +23.5 points against the no-skill baseline on GPT-5.5. Furthermore, SkillOpt outperformed a hypothetical oracle baseline that cherry-picks the best competing method for every problem.
Advertisement
Small target models saw immense relative gains, proving that a compact text file can supply procedural knowledge that small models lack in their weights. For example, GPT-5.4-nano nearly doubled its score on multimodal document QA and tripled its score on embodied interaction and sequential decision-making.
These academic benchmarks map to critical enterprise pain points. Zero-shot models often hallucinate formatting or fail to use tools properly in multi-step scenarios. Yang explained that the biggest performance leaps occurred in operations that enterprises historically struggle to automate reliably.
“Document data extraction… exact figures out of contracts, invoices, and forms — AP automation, claims, compliance,” Yang said. “What improves is reliability: precise formatting, self-verification, auditable outputs. And the gains come from learning procedure, not memorizing answers.”
For enterprise practitioners, the true value of SkillOpt lies in its portability, efficiency, and compatibility with existing infrastructure. Experiments confirm that the framework is harness-agnostic. In addition to basic chat, the same optimization loop was successfully integrated into tool-backed execution environments like the Codex CLI and Claude Code with significant gains on industry benchmarks.
Advertisement
Developers can train a skill using one execution loop and deploy it in another. For example, a spreadsheet skill trained entirely inside the Codex loop was moved directly into Claude Code and drove a +59.7 point gain over Claude Code’s native baseline without any further changes.
SkillOpt artifacts also transfer cleanly across model scales. A skill optimized for GPT-5.4 was deployed onto the smaller GPT-5.4-mini and GPT-5.4-nano models with positive gains, proving that the learned procedures encode reusable workflows rather than just exploiting quirks of a specific model’s architecture.
Finally, the framework is highly efficient regarding token usage and context window real estate. Across all benchmarks, the final deployed skills never exceeded 2,000 tokens, with a median length of roughly 920 tokens. This results in highly readable, auditable artifacts that a human practitioner can review and manage in minutes.
Implementation strategies and the enterprise ‘catch’
For enterprise tech leaders, adopting a new framework requires understanding the overhead and limitations. While the research paper notes that training tokens can reach up to 210 million for academic benchmarks, the reality for day-to-day enterprise use cases is much lighter. The high token counts in testing were largely due to re-scoring massive held-out test sets.
Advertisement
“The real upfront work is the verifier and a representative held-out split. The optimizer is light; the evaluation harness is where the engineering goes,” Yang said. He added that for everyday use, “in community frameworks like GBrain, where SkillOpt updates run on Claude Sonnet, training a skill for a single task averages just $1–5.” This optimization cost is a one-time fee that amortizes completely at deployment.
However, the framework requires specific conditions to work effectively, namely a few dozen representative examples and a scorable feedback signal. Teams should avoid applying SkillOpt to open-ended or subjective tasks. “With no clean automatic scorer you have to design a human- or model-based evaluator and watch its stability,” Yang said.
SkillOpt also integrates smoothly with existing orchestration stacks, removing a major adoption hurdle. For instance, developers already using pipeline compilers can run both systems harmoniously. “DSPy is a different, complementary layer,” Yang said. “It compiles declarative LM pipelines and optimizes program structure; SkillOpt optimizes the external skill state a frozen agent loads. You can run them together.”
Looking ahead, open-source developers are already scheduling SkillOpt to run periodically over their agents’ past trajectories, creating a small ecosystem of self-optimizing code-agent plugins. This continuous feedback loop represents a significant shift in how AI systems adapt.
Advertisement
“The valuable version of self-improvement is an agent autonomously discovering knowledge to improve its own behavior and the user experience, under verification and audit,” Yang said. “Skills are the fastest, cheapest, most reversible first step, and the same mindset points toward agents eventually optimizing themselves, all the way down to their own weights.”
Opendoor is shutting down its India operations less than two years after opening offices there. Slashdot reader alternative_right shares a post from Opendoor CEO Kaz Nejatian: “I shared this note earlier today with the entire team at Opendoor. Today we began to say goodbye to our colleagues in India as we wind down our India operations. Our customers are in America, and that’s where our operational work belongs.” TechCrunch reports: In announcing the decision on Wednesday, CEO Kaz Nejatian cited a push to bring operational work back to the U.S., where Opendoor’s customers are, and a shift toward smaller AI-native teams. The company did not respond to requests for comment on how many employees were affected or how much of the decision was driven by AI efficiency. But the announcement quickly gained traction across Silicon Valley, where founders, investors, and outsourcing experts see it as an early example of how AI is reshaping the economics that made India a global hub for back-office operations.
[…] Some investors viewed the decision as a sign of what AI could mean for India’s vast outsourcing workforce. “As manual work gets replaced by AI, a lot of jobs will be lost in India,” wrote Sheel Mohnot, co-founder of Better Tomorrow Ventures. Others viewed Opendoor as evidence of a larger shift in how companies are organized. Keshav Lohia, a venture capitalist at Emergent Ventures, described the decision as a “watershed moment” for AI-driven operations, arguing that advances in AI are beginning to challenge the cost-arbitrage model that made India a popular offshoring destination.
Phil Fersht, chief executive of HFS Research, an advisory firm that tracks the global outsourcing and business services industry, told TechCrunch that the development should not be viewed simply as jobs moving from India to the U.S. The more important shift, he said, is that AI is reducing the amount of operational labor companies require in the first place, allowing firms to run leaner organizations regardless of location. “This is not an isolated restructuring,” Fersht said. “It is part of a much broader pattern we are starting to see as companies redesign operations around AI, automation, and much leaner workflows.” Fersht argued that the winners would be companies that combine AI, software and human expertise to deliver outcomes without continually adding headcount, a model he described as “Services-as-Software.” While Opendoor may be one of the first high-profile examples, he said it is unlikely to be the last.
Some investors are already extrapolating beyond individual companies. Varun Rekhi, a venture capitalist at Speedinvest, argued that if AI reduces demand for labor-intensive services, it could eventually pressure one of India’s most important export industries, which is built around supplying talent and expertise to global corporations.
Photo credit: iFixit iFixit engineers tore down the Trump Mobile T1 this week and put every layer to the test. The gold-finished handset drew plenty of early attention for its bold look and branding. What came out during the full examination showed a device that borrows almost everything from an existing model with only light cosmetic updates on top.
Advanced imaging equipment eventually revealed some obvious indicators. Scans of the interior configuration gave us a good idea of what was going on without necessitating disassembly. The inside layout was almost identical to the HTC U24 Pro, including component arrangement and board shape. The camera area received a few small adjustments, but the general design stayed the same. The engineers started by working on the back cover. One of the most significant changes was a larger flex cable for the flash to accommodate the repositioned module, although the rest of the connections, spring contacts, and surrounding hardware remained identical to the original HTC design. The aluminum chassis, on the other hand, had slightly different machined holes for the speaker grill, but the speakers were in the same spot and worked just as well.
TYPE IT IN. TRANSFORM IT FAST: Enhance any shot in seconds on your smartphone by using Photo Assist¹ with Galaxy AI.² Add objects, restore details…
MAKE IT. EDIT IT. SHARE IT: Turn everyday moments into something personal with creative tools built right into your mobile whether it’s a special…
FAST. POWERFUL. AI-READY: Power through your day with AI-accelerated performance from our fastest, smoothest and most powerful Galaxy processor yet…
A deeper inspection of the mainboard revealed the same exact shape, screw positions, and anti-tamper stickers, showing that the entire assembly was identical to the HTC version. Engineers pulled the board from the T1 and installed it in an HTC U24 Pro body, and it simply worked. The opposite was also true: insert an HTC board into the T1 chassis, and everything worked as usual. The only notable difference was in memory, with Micron in one and SK Hynix in the other. Just one of several supply chain alternatives.
Both phones used the same CPU, the Qualcomm Snapdragon 7 Gen 3. On paper, the display sizes differed slightly, but the panels and mounting hardware were fully interchangeable. The wireless charging hardware, ports, and extension features were all carried over intact. However, the battery was a very other story. Capacity had increased to 19.35 watt-hours, but charging speed had decreased to 30 watts. No doubt because the HTC model supports faster 60-watt charging. The new cell features an insignia from the Philippines-based company Newlix Mfg Inc.
The HTC U24 Pro has a repair rating of three out of ten. This was partially due to a lack of official servicing instructions and spare parts. For the time being, the T1 obtained the same rating; however, no service documentation for that model was discovered. However, all of this brought further perspective. The majority of the components were standard off-the-shelf parts obtained from global manufacturers, with a significant amount of Chinese production mixed in. Although some final assembly occurred in Florida, the chassis, display, and the majority of the subassemblies were prefabricated overseas. The T1’s battery was manufactured in the Philippines, which is unsurprising. The device’s labeling indicate that it was manufactured in the United States, but in the end, it appears to be a standard issue device.
Klipsch arrived at High End Vienna 2026 with the kind of product lineup that reminds everyone why the brand still matters after 80 years: big horns, real wood, inspired design, unapologetic efficiency, and enough Heritage DNA to satisfy even a die-hard lover of vintage horn speakers.
On paper, all of these products sit in very different parts of the Klipsch universe. One is a tribute to Paul W. Klipsch’s original corner-horn loudspeaker. One is a design-forward collaboration with Devon Turnbull (a.k.a. OJAS). The third is a smaller-format Heritage model based on the rare 1958 H8 “Model H” design.
Advertisement
Seeing (and hearing) them all at the show, the message was pretty clear: Klipsch is not treating Heritage like a museum wing. These are real products that will find their way into real music lovers’ homes this year. They are inspired by the past, but use modern fabrication techniques and crossover designs to bring the performance beyond what was possible with the legacy products.
The vintage Klipsch Model H (H8) speaker on the left was the inspiration for the company’s new Rebellion bookshelf loudspeaker.
At around $2,700/pair, the Klipsch Rebellion may be the most interesting of the three from a real-world buyer perspective. It is the first compact bookshelf/stand-mount loudspeaker in the Heritage Series, and Klipsch says it traces its roots back to PWK’s rare 1958 Model H “H8” design, of which only 16 were made.
Paul W. Klipsch designed the Model H as a dedicated center channel speaker to fill in the gap between the company’s other speakers when they were spaced far apart from each other, in order to improve the imaging by providing a rock-solid anchor for vocals. That kind of backstory can become marketing fog very quickly, but the Rebellion has a more practical job: give Heritage fans a smaller horn-loaded speaker that does not require a dedicated listening room, reinforced corners, or a long conversation with a structural engineer.
Standard finish options for the Rebellion include American Walnut and Black Ash. To celebrate Klipsch’s 80th anniversary, a limited-edition Tigerwood finish will also be available (I wonder if the golfer gets a discount?).
Advertisement
Marcus Buckler, from Premium Audio Company, shares details on the 80th Anniversary Klipschorn (pictured) and Rebellion speakers at HIGH END 2026.
At the other end of the room, the 80th Anniversary Klipschorn was pure legacy with new control under the hood. Limited to 280 pairs worldwide, the anniversary model updates the Klipschorn concept with an external active DSP crossover while retaining the essential corner-horn architecture that made the original one of the most recognizable loudspeakers in audio history.
With high extremely high sensitivity, the Klipschorn can be driven from a single ended triode tube amp, so the 125 Watts/Channel of the 80th Anniversary Onkyo Muse Y-50 integrated amp was more than enough to push these speakers to 110 dB+ reference levels with tight, extended bass and effortless detail. The speaker will be available for $25,000-$27,000/pair depending on finish options.
Everybody puts this baby in a corner. The gold lines on the outside of the cabinet actually match the internal folds inside the cabinet.
The Klipsch/OJAS kO-R2 pushes in a different direction, taking horn-loaded audio into the design and culture space without abandoning the efficiency and immediacy that made Klipsch famous in the first place. Designed in partnership with artist and noted audio DIYer, OJAS (Devon Turnbull), the kO-R2 was set up in Vienna outside the convention center in its own listening room, built into a storage container. Although that sounds spartan, it was actually a nicely air-conditioned storage container, treated quite effectively with comfy seats and sound treatments to keep outside sounds out (and inside sounds in).
The Klipsch/OJAS kO-R2 is a passive 2-way loudspeaker, featuring the OJAS 1506 Multisectoral horn. The speaker is handcrafted in Hope, Arkansas, by Klipsch artisans, and designed in collaboration with OJAS. The cabinet is built from 13-ply Grade A Baltic birch plywood. It houses the company’s K-33-E 15-inch woofer in a vented enclosure, crossed over at 760Hz to the K-706 high frequency compression driver, which is loaded on an exposed sand cast aluminum multi-sectoral horn. Features of the kO-R2 include anodized aluminum binding posts, anti-vibration rubber feet, an elegant engraved metal ID plate with serial number, and a five-step high-frequency high frequency gain attenuator.
Advertisement. Scroll to continue reading.
OJAS (Devon Turnbull) collaborated with Klipsch on the OJAS kO-R2 speaker.
The room had a cool, relaxed vibe as Devon himself spun some of his favorite tunes on vinyl and reel-to-reel tape with mostly home-made amplification gear powering a pair of the kO-R2 speakers. As with any great horn speaker, the kO-R2 produced dynamic, punchy sound that was particularly effective on drums and percussion, but also possessed the finesse to reproduce the delicacy of stringed instruments and human vocals.
The Klipsch/OJAS kO-R2 is available for sale exclusively on ojas.nyc at $11,995.pair. They are taking pre-orders now and expect to beginning shipping the speakers in August or September of this year.
Social engineering is still the top vector, but basic account security measures do a lot of the heavy lifting
A new report from ReversingLabs is warning doomscrollers of videos spreading across short-form platforms like TikTok and Instagram Reels infecting users with password-stealing malware.
The videos typically promise free access to subscriptions like Spotify Premium, Windows, Office and Adobe – an instant, telltale sign that things might not be as they seem.
Instead of receiving phishing emails, victims are instructed to open command-line tools like PowerShell, then paste and run the command shown in the video.
Latest Videos From
Watch out for this info stealing malware
When they run the command, it triggers a piece of malware to be downloaded and installed to a victim’s computer. Vidar, the infostealer, targets usernames, passwords, cookies, session tokens, cryptocurrency wallet data, personal files and documents, and other sensitive information.
Advertisement
But more importantly, it marks a significant change – previously, email phishing campaigns have been extremely popular for gaining access to victims’ credentials, with a simple click of a link leading to potential disaster. This newer method relies on victims physically inputting commands into a tool, which requires more patience.
Ultimately, the attack exploits current economic strains and the fact that consumers are looking out for cheap and free alternatives to popular subscriptions.
“This kind of social engineering is an easy way for threat actors to drive traffic off social media and onto an attacker-controlled malicious website,” the researchers wrote.
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Regardless, the overarching theme is that social engineering remains the clearest path for attackers to reach victims, and that’s good news because there are many basic principles could-be victims can follow, like using multi-factor authentication to secure accounts.
Being wary of suspiciously cheap or free products/services and only downloading software from official vendors would also help in this instance.
The bill comes months after Australia enacted a similar ban designed to make internet usage safer for young people.
Canada’s government has introduced Bill C-34, the Safe Social Media Act, which will prohibit young people under the age of 16 from using social media, with an exception made for platforms that meet specific safety standards. Another goal of the bill is to make AI chatbots safer by setting up a digital regulator to establish safety standards.
Minister of Health Marjorie Michel said: “Social media platforms and AI chatbots are designed to capture attention. They do not support healthy childhood development and have become a source of anxiety, isolation, depression and a range of other mental health challenges for many young Canadians.
“The healthy development of our children begins with their physical and mental wellbeing, which is grounded in strong and healthy social connections. This legislation will provide a safer environment for young Canadians and empower them to connect in-person, build friendships, focus in school, and learn real-world skills so they can thrive.”
Advertisement
It could potentially take up to a year for the bill to pass and an additional six months to establish the digital regulator, additionally, the companies that fail to comply with the rules face penalties of 3pc of global revenue, or up to C$10m.
The proposed legislation will make online services more accountable and transparent by introducing new safety requirements for social media services and AI chatbot services. This will include an age restriction, measures to reduce children’s exposure to certain content and high-risk interactions and regulated services will be required to identify, mitigate and address the risks on their platforms.
Marc Miller, the minister of Canadian Identity and Culture, with responsibility for Official Languages, said, “We have seen the very serious consequences that online harms can have. As technologies evolve, we must ensure our laws keep pace, because parents cannot face these challenges alone.
“The safety of children cannot be an afterthought. This legislation will introduce stronger responsibilities for online platforms to ensure their services are safe by design and include appropriate measures to keep children safe.”
Advertisement
Canada is not the first region to consider limiting young people’s access to social media. In December of last year, Australia enacted the world’s first social media ban for minors under the age of 16, in a bid to bolster child safety. The ban affects Facebook, Instagram, Threads, X, YouTube, Snapchat, Reddit, Kick, Twitch and TikTok.
Other regions that have considered implementing changes include the UK and France and in November of 2025 the European Parliament proposed an EU-wide minimum age to access social media, video-sharing platforms and AI companions.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.


































































You must be logged in to post a comment Login