Indeed, the idea of data centers in orbit has gone from science fiction to a serious spending category. Elon Musk’s SpaceX has acquiredxAI (also Musk’s) and is planning a constellation of space-based data centers. Google, not to be outdone, announced Project Suncatcher in partnership with Planet, planning to launch two satellites equipped with GoogleTensor Processing Unit (TPU) AI chips by early 2027. Startup Starcloud has already filed a proposal with the Federal Communications Commission for an 88,000-satellite constellation for orbital data centers. As Starcloud’s filing suggests, these companies are all proposing fleets of satellites numbering in the thousands, each housing a rack or multiple racks of AI-grade GPUs, interconnected with each other through free-space optical links and communicating back to Earth via microwave links, either directly or through other satellites.
Proponents tout the many wonders of computing in space: abundant solar energy, free cooling, and freedom from Earth-based disturbances like earthquakes, floods, and protesters. But a sober look at the physics of space-based computing paints a much more nuanced picture.
Free cooling is perhaps the biggest misconception. Space is cold, but it also has no atmosphere. That means the best heat-removal mechanisms, conduction and convection, are off the table. The only option is radiation. To prevent a chip from overheating in space, a large, costly surface area is required to dissipate the energy and then radiate it.
Advertisement
Solar energy is abundant, but collecting it with functional solar panels that maintain perfect alignment toward the sun is a complex task requiring extensive attitude control systems. On top of that, ionizing radiation in space from cosmic rays and other sources poses a unique challenge, degrading the solar panels, the radiative coolers, and the chips themselves. Because regular maintenance in space is difficult, redundancy has to be built in at launch, and cost estimates have to account for efficiency degradation over time.
At ABI Research, where I work as an aerospace analyst, we did a rough total-cost-of-ownership comparison between a data center on Earth and one in space. It showed that the cost to launch and run a GPU in space for a year is at least an order of magnitude higher than the same feat in a terrestrial data center. Our model was simple, assuming an Nvidia H100 server rack launched with the requisite-size solar panel and radiator on a spacecraft akin to Starcloud’s pilot launch. We assumed SpaceX’s Starship was used at a highly optimistic launch cost per kilogram of US $44, and a terrestrial energy cost of $0.20 per kilowatt hour. This is a simple back-of-the-envelope calculation, but it does signal something real.
From our perspective, the cost of delivery and space hardening of the payload makes general-purpose space-based data centers difficult to justify economically today, despite the fact that data-center builders in many regions are scrambling for electric power. However, there are niche applications where the much higher costs of computing in space could be justified. Examples include preprocessing data from Earth-observation satellites, real-time detection and tracking of hypersonic missiles, and active collision avoidance in the increasingly crowded low Earth orbit. Even for these, though, contending with fundamental physics will still be a demanding challenge. And a technologically compelling one, too.
The Cooling Challenge in Space
Cooling is where physics separates the science from the fiction. The governing equation for radiative cooling, the only type of cooling available in space, is known as the Stefan-Boltzmann Law. It states that the amount of power you can radiate is proportional to the area of the radiator times its temperature to the fourth power. For a space systems architect, the implications of this law are brutal. In orbit, the only variable we can control is area. This restriction creates a geometric penalty, or a “physics tax,” for cooling in space: The more power you need to reject, the bigger the area of the radiator you need to bring along from Earth.
Advertisement
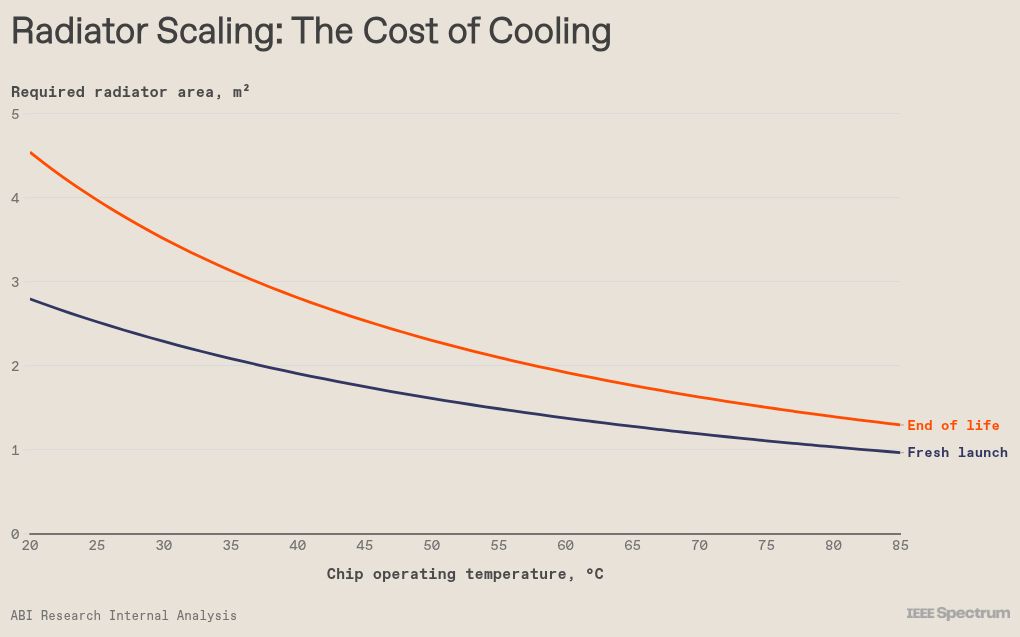
The only cooling method available in space is radiation, and the radiator area required is derived using the Stephan-Boltzmann law. For a single chip drawing 700 watts, like Nvidia’s popular H100 GPU, the area required to keep it at 20 °C is just under 3 square meters, and it goes down to 1 square meter for an operating temperature of 85 °C. However, as the radiator surface is exposed to ionizing radiation, its emissivity decreases, and after 5 years in space the required area increases by about 40 percent.
To understand how big this baseline area is in practice, I used the Stefan-Boltzmann law to model the heat-rejection area needed to keep a single chip that draws 700 watts of power—such as the H100 GPU chip, an AI stalwart—at a constant 60 °C, usually considered the sweet spot for GPU longevity and stability. I further assumed that the radiator is perfectly facing deep space, at a chilly background temperature of 3 kelvins. By this calculation, a single chip would require 1.4 square meters of radiator surface.
To put this into perspective, consider that a common AI rack can hold approximately 32 GPUs (four H100 server boards). With CPUs, memory, and networking equipment, this rack would draw around 40 kilowatts of power. This single rack includes 2.5 terabytes of memory—enough capacity to serve over 20,000 concurrent users or run 16 simultaneous instances of Llama 3, an open-source AI model. But to cool this thermal load in a vacuum, that single rack would require an 80-square-meter radiator, roughly the size of a pickleball court. For an aggregate 100-megawatt data center, you’d need at least 2,500 of those radiators.
And that’s the best-case scenario. Additional problems are hidden in the low Earth orbit environment itself. Space exposes radiators and their coatings to a chemically hostile brew of ultraviolet light and atomic oxygen, quite the opposite of a clean-room environment. Over a LEO satellite’s typical 5-year lifespan, these elements degrade the radiator’s surface properties and lower its ability to shed heat.
Including this degradation in the model reveals that as the radiator degrades from a “fresh” state to an “end-of-life” state, the physics demands a further penalty. To maintain that same 60 °C operating temperature for the GPU chips, the required surface area jumps from about 1.4 square meters per chip to nearly 2.0 square meters. In other words, the physics tax rises by 40 percent. Therefore, you must launch at least 40 percent more radiator mass, endure higher atmospheric drag, and sacrifice valuable launch volume just to survive the degradation of the thermal coating. This increase adds significantly to the launch cost and further erodes the economics of a space-based data center.
Advertisement
The Silicon Challenge in Space
Solving the heat problem is only part of the battle. The other significant challenge in low Earth orbit is ionizing radiation, which affects the computing hardware itself. Today’s satellites typically use radiation-hardenedprocessors, which are very reliable but also much more expensive, and they perform poorly compared to commercial off-the-shelf processors.
A standard rad-hard chip doesn’t have the processing power to run a modern large language model (LLM). As a result, satellite operators aspiring to launch a data center have no choice but to make a risky compromise: to use hardware meant for terrestrial use. In order to achieve the necessary compute density, orbital data centers must use the same Nvidia H100s or Google TPUs found in terrestrial server farms. The problem is that these chips are “soft” targets in space. High-energy particles can flip bits in memory or cause “latch-ups” in logic that fry the circuit.
One possible option is to shield the computers from radiation with thick, absorbent panels. However, the shielding would add significantly to the already heavy satellites. The other option is to compensate for the radiation damage with redundancy. Indeed, edge computing architects are moving toward software-defined resilience, where instead of one perfectly hardened computer, operators fly a cluster of imperfect, commercial ones whose total cost could be as low as one-tenth to one-hundredth that of the rad-hard model.
This redundant approach is used in many spacecraft, including Artemis II, which recently carried astronauts around the moon, as well as SpaceX’s flight computers and the Hewlett Packard Enterprise edge servers for the International Space Station. By running three (or more) instances of the same calculation on three different nodes and comparing the answers, the system can detect a corrupted processor. If a node fails, the “orchestrator” reboots it while the others continue the mission. While this ensures resiliency, it also means that some fraction of the compute capacity is dedicated to redundancy, further increasing the costs.
Advertisement
The Energy Challenge in Space
An often-touted advantage of space-based data centers is the seemingly unlimited supply of free, clean energy from the sun. Solar energy in orbit is indeed abundant, at 1,361 watts per square meter. Of course, capturing that free energy is made possible only by the very costly launching of large solar panels into orbit. And those solar panels also degrade over time due to radiation exposure, typically losing 1 to 3 percent efficiency per year.
Let’s say a solar array collects 1 MW of power to run an AI cluster. The laws of physics demand that the satellite must eventually radiate 1 MW of waste heat. Because the square area needed to generate the solar power—around 400 W/m2—and to reject the heat—around 450 W/m2—are nearly equivalent, every square meter of power generation now demands approximately another square meter of cooling. The radiator needs to be a structural equal, not merely a passive coating on a surface used for something else.
As Elon Musk recently noted in Davos, the most efficient radiator is one that never sees the sun. By orienting the spacecraft so the solar panels face the sun and the radiators face the deep vacuum of space, efficiency skyrockets for both. But there’s a catch: Maintaining this perfect three-way alignment—panels to sun, radiator to the void, antennas to Earth—requires complex, high-torque attitude control systems. So this configuration means more payload and more computing power. Plus, these control systems are complex components with many failure modes, which is not optimal in a situation where maintenance is difficult.
The Killer Apps for Computing in Space
Given all these challenges of deploying massive radiators for satellites in the hostile environment of space, why build data centers in space at all?
Advertisement
While training or inference on LLMs in space doesn’t seem economical today, there are other, very compelling applications for computing in space. Here are two: solving the downlink bottleneck from Earth-observation satellites and enabling collision-preventing maneuvers in the increasingly crowded low Earth orbit.
The latest Earth-observation satellites, equipped with hyperspectral and synthetic aperture radar sensors, are used for a range of important reconnaissance missions, such as battlefield intelligence, tracking the global shadow fleet of ships carrying contraband, and assessing earthquakes or infrastructure failures down to the millimeter. These systems can generate hundreds of terabytes of raw data per day that must be transmitted to Earth. However, the radio-frequency “pipes” used to downlink the data are congested, and the ground infrastructure cannot absorb the sheer volume of raw data.
Another immediate, mission-critical application for in-space computation is protecting the orbital environment. With over 17,000 satellites in orbit, the overwhelming majority of which are in low Earth orbit, avoiding collisions between these satellites is crucial. As NASA astrophysicist Donald Kessler pointed out back in 1978, a single space collision could cause a cascading effect that renders the entirety of LEO unusable.
According to SpaceX’s recent annual report, the Starlink constellation executes a collision avoidance maneuver every 2 minutes on average. Each maneuver already relies on onboard AI systems but still requires most of the processing to happen on the ground.
SpaceX’s Starlink system currently has over 10,000 satellites in low Earth orbit, each depicted here as a colored dot.
Satellitemap.space
Advertisement
As low Earth orbit gets increasingly populated, collision avoidance will have to break the traditional ground-loop model. In the megaconstellation era of space, the OODA (observe, orient, decide, act) loop must happen onboard, thereby reducing the analysis turnaround from minutes to milliseconds.
The problem is that the flight computers standard on satellites are not built for this level of processing. The complex probability models required for maneuvering cannot currently be implemented by onboard computers in conjunction with their navigation systems. Clearly, more powerful computers are needed.
This is the true economic justification for moving compute to space: to move insight generation there. By placing high-performance computing adjacent to the sensors, we can process terabytes of data in orbit and downlink only the relevant data in real time, and we can do the computations necessary to avoid satellite collisions in real time.
The Future of Computing in Space
So, assuming that some form of computing is inevitable in low Earth orbit in the foreseeable future, how will the heat be handled? The industry is currently experimenting with two main classes of solutions to cope with the Stefan-Boltzmann law.
Advertisement
One creative option is to use origami-inspired radiators, the kind used for the James Webb telescope. Companies are developing flexible, high-conductivity composite radiators that fold into a tight cube for launch and unfurl into enormous yet lightweight thermal wings in orbit.
Another possibility is to use liquid-droplet radiators. This concept proposes removing the rigid radiator structure completely and instead spraying a stream of coolant oil directly into the vacuum of space. The fluid travels through an open loop, exposed to the near-absolute zero of the void, maximizing radiative surface area before being caught by a collector and pumped back into the ship. It sounds like science fiction, but as the heat loads climb into the megawatts, liquid-droplet cooling may be the only way to cheat the mass limits of this exponential reality.
Our rough total-cost-of-ownership model uses optimistic versions of current numbers, such as launch cost, chip cost, and power use. A critic might point out that future technology will improve, both in efficiency, purpose-built designs, and costs.
Sure, the technology is bound to improve. But the critical factor isn’t just launch cost; it’s the computing power per unit mass and electric-power economics. Radiators and solar arrays can consume 65 to 70 percent of total satellite mass, and space-grade photovoltaics run orders of magnitude more expensive than terrestrial equivalents.
Current space-grade solar panels rely on germanium substrates, whose supply is concentrated in China. It will be extremely difficult to scale up availability of these substrates. A transition to radiation-tolerant perovskite solar panels or a similar alternative could change the economics significantly, but that possibility is five years away or more. The technology will get cheaper, but the bottlenecks of power and thermal architecture will remain.
Recognizing the thermal reality of cooling in space forces us to shift how we view satellite operations. We are moving away from the “launch and forget” era toward an era of “autonomous logistics.” As our thermal model demonstrated, the harsh environment of space steadily attacks the hardware. UV radiation degrades thermal coatings; cosmic rays degrade silicon. In a traditional satellite model, when the radiator degrades or the memory fails, the satellite becomes space junk. For a multimillion-dollar data center, that disposal model is potentially ruinous.
To make the economics of orbital computation work, the infrastructure must be serviceable and the rockets to launch them reusable. The orbital domain will require automated servicing vehicles capable of swapping out degraded radiator panels and upgrading fried servers. In these ways, the future of the orbital data centers is dependent on the innovations of an emergent in-space economy.
Advertisement
There’s a good argument to be made that the need for space-based computation is less of a hype cycle and more of an enabler for the new space economy. Look no further than SpaceX’s recent regulatory filings proposing a constellation of up to a million satellites in low Earth orbit. At such a scale, routing all raw data back to Earth is physically impossible; the network itself must become the data center.
However, the winners in this sector will be determined by the systems architects who most cleverly accommodate the thermodynamics and the companies with sufficient vertical integration to take on the massive costs of operating data centers in orbit. Ultimately, the physics tax is universal. Whether managing heat rejection in the vacuum of low Earth orbit or managing power density in a hyperscale facility in Northern Virginia, the constraint is never the silicon. It’s the thermodynamics.
Q&M Dental Group is eyeing 300 clinics with a S$146M expansion plan
If you’ve walked around Singapore long enough, you’ve probably seen one: a neighbourhood dental clinic with bright green lettering and a giant tooth logo.
Chances are, you never thought much about it. But behind those familiar storefronts sits a SGX-listed company worth over S$500 million, operating 110 clinics across Singapore and now pursuing acquisitions in Australia, Thailand, China, and even of another local rival.
That company is Q&M Dental Group—and after nearly three decades of quietly dominating Singapore’s heartlands, it’s now betting big on becoming a regional dental giant.
From the outset, Dr Ng had little interest in building a premium dental brand. Instead, he focused on something far more scalable: providing affordable dental care to everyday Singaporeans.
Advertisement
That philosophy was even reflected in the company’s original Chinese name, “全民” (Quan Min), meaning “for all the people.”
Demand grew quickly and outpaced what one dentist could handle.
By 1998, fellow dentist Dr Ng Jet Wei had joined the practice. A year later, together with Dr Chong Kai Guan, the trio had opened another four clinics. By 2000, Q&M was already operating 10 clinics with 20 dentists.
Rather than chasing prime shopping malls or affluent districts, Q&M planted its clinics where Singaporeans actually lived—in HDB estates, neighbourhood centres, and suburban malls.
Advertisement
The strategy was simple: keep prices accessible, expand steadily, and acquire smaller dental practices whose dentists and patient bases came as part of the deal.
Along the way, Q&M also built supporting businesses, including its own dental laboratory to produce crowns, bridges, and dentures in-house, giving it greater control over costs and operations.
By the time the company listed on the SGX Mainboard in 2009, it already had a proven expansion playbook. The IPO simply gave it the capital to execute it at a much larger scale.
Building the Q&M empire
Image Credit: Q&M College of Dentistry
In the years that followed the IPO, Q&M expanded aggressively through acquisitions, and revenue climbed from roughly S$60 million to S$155 million by 2016.
This brought Q&M Dental Group’s market capitalisation to S$557.6 million that year.
Q&M’s growth has not been limited to opening more outlets. Alongside the clinic network, the group has built a set of adjacent capabilities that reinforce the core business.
Q&M’s training college gives it a head start in sourcing and retaining the practitioners it needs to keep opening clinics, a structural advantage that competitors cannot easily replicate.
Image Credit: Business Times
When COVID-19 hit, Q&M pivoted part of its operations, acquiring Acumen Diagnostics to distribute test kits and run laboratory PCR testing in 2021—a business that briefly became a significant revenue contributor before demand evaporated as the pandemic receded.
In 2023, it opened a Free Dental Clinic at Chai Chee Road, offering essential dental treatment at no cost to underprivileged patients. While charitable in nature, the initiative also reinforces Q&M’s standing in the communities where its business is most deeply rooted.
More recently, Q&M has turned its attention to technology.
Advertisement
In 2024, the group invested in EM2AI, a dental technology firm developing AI-powered diagnostic and treatment-planning tools, including a cloud-based practice management system called EM2Clinic.
The tools are designed to reduce the administrative burden on dentists and standardise clinical workflows, which is useful as Q&M grows toward a network where consistency across hundreds of clinics matters more than before.
That scale creates advantages that go beyond simply having more outlets.
As Singapore’s largest private dental chain, Q&M has greater bargaining power with landlords and suppliers, while its size also allows it to spread fixed costs across a much larger network.
Advertisement
Government healthcare policies could further strengthen that position.
The enhanced Community Health Assist Scheme (CHAS) subsidies introduced in Oct 2025 expanded coverage for restorative dental procedures and extended eligibility to 1.7 million cardholders. As the country’s largest CHAS-accredited private dental chain, Q&M stands to benefit more than smaller competitors. Analysts estimated the changes lifted the group’s revenue by around 3% in the second half of FY2025.
More support is also on the way. From mid-2026, seniors will be able to use up to S$400 a year from Flexi-MediSave for dental treatment at CHAS clinics. The policy aligns neatly with Singapore’s ageing population, with one in four residents expected to be aged 65 or older by 2030. As dental needs typically increase with age—and many seniors live in the heartland estates where Q&M has built its network—the demographic trend could provide another long-term tailwind for the group.
Meanwhile, Q&M continues to consolidate its position. In Mar, the group announced plans to fully acquire an unnamed Singapore dental chain, backed by a profit guarantee of up to S$34 million over five years. The deal would further strengthen its presence in its home market even as it looks overseas for growth.
Advertisement
Now betting big on the region
Aoxin Quanmin Stomatology Hospital in Dalian, China./ Image Credit: Aoxin Q & M Dental Group Limited
For most of its history, Q&M’s overseas ambitions effectively stopped at the Causeway.
Over the years, the group steadily expanded its presence in Malaysia, where it now operates 38 dental clinics alongside a dental supplies and equipment distribution business. Beyond that, however, its growth remained largely concentrated in Singapore.
That is now changing.
In recent months, Q&M has unveiled plans to enter three markets almost simultaneously, marking the group’s most ambitious expansion programme to date
The biggest move is Australia. In Jul 2026, Q&M signed binding agreements to acquire Experteeth Group for A$119.64 million (S$107.83 million). The deal would add 40 clinics and around 120 dentists across New South Wales, Victoria, Queensland, Tasmania, and the Australian Capital Territory, making it Q&M’s largest acquisition ever and its first entry into a market outside Asia.
In total, the acquisitions in both countries will amount to a combined US$113.2 million (S$146.26 million) investment to build a pan-Asian dental company.
China forms the third pillar of Q&M’s expansion strategy. The group also owns Chinese dental operator Aoxin Q&M, which it has now fully consolidated as a subsidiary. It plans to use the business as a platform to acquire dental chains in southern China, expanding beyond Aoxin’s traditional base in the country’s northeast.
Not every growth initiative, however, has gone according to plan.
In Apr 2025, the group also proposed a secondary listing on Bursa Malaysia, which would have given Malaysian investors direct access to the stock and strengthened Q&M’s capital markets presence in its second-largest operating market. The plan was later shelved, with the company citing prevailing market conditions.
What could go wrong?
Aoxin Quanmin Stomatology Hospital in Panjin./ Image Credit: Aoxin Q & M Dental Group Limited
Three concurrent acquisitions in markets Q&M has limited or no experience operating in are an ambitious programme for a management team whose track record has been built almost entirely in Singapore and Malaysia.
It only turned a profit again in 2025, roughly six years after the losses began.
Advertisement
Now Q&M has folded Aoxin fully into its own accounts, and in doing so has added S$77.0 million of goodwill to its balance sheet—essentially the premium it’s paying on the bet that these businesses will earn enough in future to justify the price.
If they don’t, that goodwill may eventually need to be written down, hitting profits the same way it did for Aoxin’s own past investments. Australia and Thailand are brand-new markets for Q&M with no comparable track record to lean on, so if that expansion underperforms, the money put into it may not pay off.
Image Credit: Q&M Dental Group
Dental practices are also relationship-driven businesses, where patients follow their dentist, not the brand. When a chain acquires a clinic, the real asset is the practitioners inside it.
If key dentists leave post-acquisition and take their patient books with them, the acquired revenue can evaporate quickly.
Then there is the Johor-Singapore dynamic complicating profits further. The Rapid Transit System Link scheduled to open in Dec 2026, will cut the Woodlands North to Bukit Chagar crossing to around five minutes—at a fare of roughly S$5 to S$7.
When the RTS removes the main friction, being the border queue, from that equation, the maths for price-sensitive patients shifts meaningfully.
Q&M’s 38 Malaysian clinics, including in Johor, might mean some of that outflow stays within the group. But how much of Q&M’s dental revenue holds up once the crossing becomes as easy as taking the MRT is a question nobody can fully answer yet.
Advertisement
From a single clinic in Bukit Batok to a listed group eyeing four countries simultaneously, Q&M’s story is, in many ways, a study in patience. Three decades of unglamorous, heartland dentistry have built toward a moment where the company is finally ready to bet big on becoming Singapore’s dominant private dental chain in the region. Whether the bet pays off will be the next chapter.
Chrome‘s Reading Mode just got a new button tucked inside its settings menu. Google is quietly testing a translate option for the feature on Chrome Canary, the browser’s experimental testing channel where new ideas show up long before they’re ready for everyday use.
What does this new translate button actually do?
The option was first spotted by @Leopeva64, who shared a video demo on X highlighting the new button tucked inside Reading Mode’s dropdown menu. It exists alongside the controls for theme, font, images, and links, though it doesn’t actually do anything yet. Once this feature is live, clicking it would translate whatever page or PDF you’re reading into your preferred language, without leaving Reading Mode.
For now, clicking the button does absolutely nothing. Google appears to have added the interface piece first, well before building out the actual translation function behind it. If you need to translate a page today, the existing Google Translate browser extension already covers the same job just fine.
Is it rolling out to everyone on Canary?
Not quite yet, it seems. PiunikaWeb tested this on the latest Chrome Canary build, but the translate button was nowhere to be found. That mismatch suggests Google might be testing this in limited batches rather than pushing it to every Canary user simultaneously, or it could be a platform-specific rollout.
The Bavarian space-tech is reportedly aiming to raise at least $300m.
As Europe ramps up efforts to compete with US heavyweights in the space sector, Germany’s The Exploration Company (TEC) is reportedly eyeing a major raise that could value the start-up at more than $2bn.
Founded in 2021 by Hélène Huby and a team of aerospace veterans, TEC is building a full-stack space transportation system.
Nyx, the company’s reusable space capsule designed to dock with any space station is expected to go on its first flight demonstration in 2028. The company is also developing a high-thrust staged combustion rocket engine called Storm.
Advertisement
TEC’s website states that it aims to address the “exclusive[ity]” of space travel by building space vehicles “for humanity”. It is the first European company to have signed a Space Act Agreement with NASA.
The company operates out of Germany, France, Luxembourg, Spain and Italy, with offices in the US and the United Arab Emirates.
According to the Financial Times, the Bavarian space-tech is aiming to pool at least $300m, with the EQT-managed $5bn Scaleup Europe Fund in talks to make one of its first investments in the company.
The fund aims to close the persistent late-stage financing gap that has long pushed European scale-ups to raise capital elsewhere and, in many cases, to relocate abroad altogether. Scaleup Europe Fund is also reportedly expected to back the Paris-based Mistral AI in an upcoming round.
Advertisement
EQT Ventures has backed TEC since 2023. Other investors, including Bayern Kapital, Promus Ventures, Partech, Vsquared Ventures, Cherry and Red River West also back the company.
TEC did not disclose its valuation following a 2024 raise of $160m. Earlier this month, the company opened a new lab near the NASA Johnson Space Center in Houston to conduct further testing on a full-scale mock-up of a Nyx crew capsule.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
A Cincinnati man says that if the fall detection feature of Apple Watch hadn’t called 911, he would have died from undiagnosed blood clotting.
Back in 2023, it was the Apple Watch heart rate monitor that saved a Cincinnati woman’s life by alerting her to a dangerous condition. Now the device’s fall detection has done the same for Mohammad Islam in the city, according to local stationWKRC.
Islam was at home and taking out the trash when he said he turned around and “just collapsed.”
“I don’t know how long I was there,” he continued. “Suddenly my eyes opened up and I was on the ground and sweating like crazy.”
Advertisement
“I tried to get up, but couldn’t. There was a chair so I held it…,” he said. “Then I heard the sirens coming.”
Emergency medics took him to the University of Cincinnati Medical Center where he has been diagnosed with blood clots in his lungs. The cause has not yet been identified, but he has been sent home with medication.
The Apple Watch he wore was given to him by his daughters, and even before the incident, they reportedly pressed him about wearing it. “[Also they] gave a gift to their mother… an Apple Watch,” said Islam, “and every day they call me, they say ‘Are you wearing your Apple Watch?’”
“They’re overjoyed that their gift saved me,” he said.
Advertisement
Islam had not intentionally turned on the fall detection feature, but he is aged over 55, so it was enabled automatically. He says that he was aware of it because of getting occasional false alarms, but he did not know the extent of what the feature can do.
“Because when I work in the yard or something and I bang my hand, it says, ‘Hey, did you fall down? Should we call SOS or something?’” he said. “So, it was in the back of my mind, but I did not know that it was going to call 911.”
Apple Watch keeps saving lives
Apple and just about every smartwatch maker is currently being sued over fall detection and an allegation that it infringes on patents owned by UnaliWear. But in the meantime, it has directly saved countless lives since its introduction with the Apple Watch Series 4 back in 2018.
Fall Detection settings on Apple Watch.
Advertisement
At times, that detection has been when the wearer has been involved in a car crash and the Apple Watch messaged the driver’s family. It’s helped injured mountaineers, too.
Then across its multiple health features, the Apple Watch has also alerted many users to conditions that, if not immediately life-threatening, were extremely series. It was AppleInsider managing editor Mike Wuerthele’s Apple Watch that warned him about a potential atrial fibrillation after his daughter’s passing.
It’s events like these that Tim Cook has said he is most proud of from his time as CEO.
“I remember getting the very first Apple Watch note from a user who told me that the watch saved their life,” he said in April 2026. “Now, of course, I get these on a daily basis, but that first one hit me particularly hard. It caused me to just stop in my steps.
The Clop ransomware gang (also tracked as Cl0p) is targeting Internet-exposed PTC Windchill and FlexPLM instances in a new data theft extortion campaign.
Clop has reportedly been exploiting a critical improper input validation vulnerability tracked as CVE-2026-12569, which allows attackers to execute arbitrary code on vulnerable Windchill and FlexPLM instances.
As cybersecurity company ReliaQuest reported on Thursday, Clop operators have been deploying JSP webshells that allow them to exfiltrate sensitive data from targeted companies’ compromised PLM platforms.
“ReliaQuest has observed threat actors actively exploiting CVE-2026-12569, a critical unsafe deserialization vulnerability (CVSS 9.3) affecting PTC Windchill and FlexPLM. Exploitation enables unauthenticated remote code execution and JSP web shell deployment for remote command execution and sensitive product data exfiltration,” the company said.
“The actor behind these attacks remains unconfirmed. however, the observed tradecraft shares characteristics with previous Cl0p campaigns targeting enterprise applications and high-value data repositories.”
Advertisement
Clop’s Windchill and FlexPLM attacks were also confirmed yesterday by the Ransomware Information Sharing and Analysis Centre (Ransom-ISAC), a non-profit organization dedicated to the tracking and defense against ransomware threats.
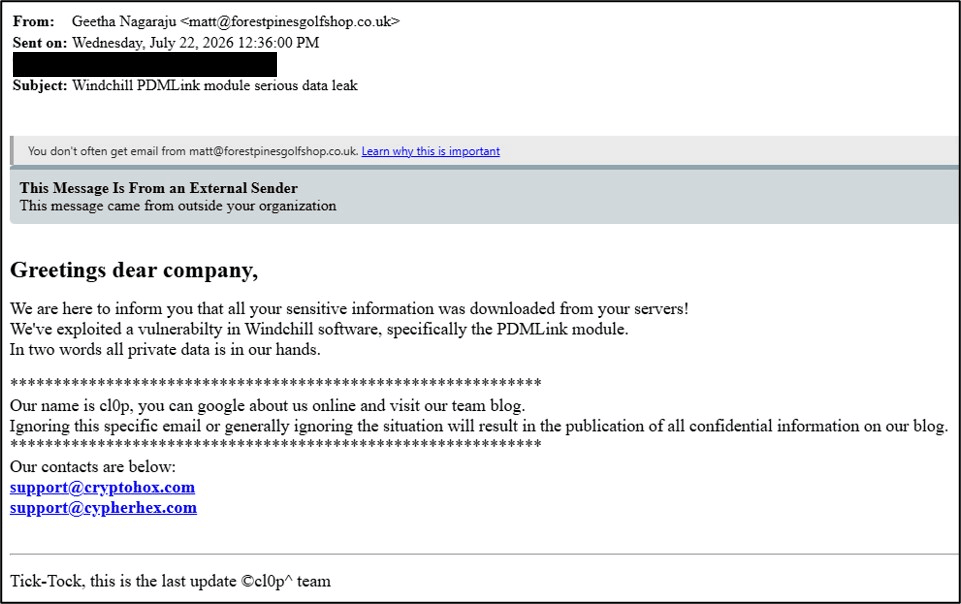
Ransom-ISAC’s Brandon Parsons from Ascent Solutions told BleepingComputer that Clop is using what appear to be previously compromised email accounts to send extortion messages to multiple employees of targeted organizations.
Clop extortion email (Ransom-ISAC)
“The extortion emails appear to originate from randomly compromised accounts, are sent to hundreds of users within an impacted organization and include Cl0p’s latest contact information,” Parsons said. “This extortion approach is consistent with what we observed with the Oracle EBS campaign last year, except for the use of new email addresses.”
As BleepingComputer has learned, it is a common tactic for this cybercrime group to change email addresses before launching a new extortion campaign.
Flagged as actively exploited in attacks
PTC began releasing security patches for the CVE-2026-12569 flaw on June 17 and, while it didn’t confirm in-the-wild exploitation, it released remediation guidance in a private advisory and urged customers to review their environments for indicators of compromise (IOCs).
Advertisement
After PTC warned customers of “heightened threat activity” on June 26, the Cybersecurity and Infrastructure Security Agency (CISA) added the vulnerability to its Known Exploited Vulnerabilities catalog and ordered U.S. federal agencies to secure their PTC Windchill and FlexPLM instances within three days.
According to German news outlet Heise, CVE-2026-12569 also prompted emergency action from German authorities, with the Federal Office for Information Security (BSI) emailing and calling PTC customers in the middle of the night and warning them to patch their systems as quickly as possible.
German authorities reacted with the same urgency in March after reports that a similar critical Windchill and FlexPLM flaw (CVE-2026-4681) may be exploited or was likely to be exploited soon.
On Thursday, ReliaQuest advised PTC customers to patch Windchill and FlexPLM systems and place them behind VPNs or trusted access gateways if possible. Additionally, if they suspect compromise, they should isolate the affected servers, collect forensic artifacts, and rotate any exposed credentials before restoring service.
Advertisement
A PTC spokesperson was not immediately available for comment when contacted by BleepingComputer earlier this week.
PTC Windchill and PTC FlexPLM are enterprise software platforms in a category known as Product Lifecycle Management (PLM) and used to track, design, and manage products from original idea to final manufacturing.
The two PLM systems are widely popular among engineering, manufacturing, quality, and supply chain teams across high-profile companies in the aerospace, defense, automotive, heavy machinery, retail, and medtech sectors. PTC says that its products are used by more than 30,000 customers globally, including over 1,500 brand and retail customers using FlexPLM.
After breaching their systems and exfiltrating sensitive documents, Clop publishes the stolen data on its dark web leak site, making it available for download via Torrent if victims refuse to pay a ransom.
The U.S. Department of State now offers a $10 million reward for information that could link this cybercrime gang’s attacks to a foreign government.
Update July 24, 07:42 EDT: Added more info on the attacks from Ransom-ISAC.
Advertisement
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.
Long before anyone had heard of ChatGPT, Google CEO Sundar Pichai made clear that AI was a primary driver behind Google’s device push. Now, the company’s journey is about to take a turn with the launch of Googlebooks.
While Googlebooks and Chromebooks will coexist for a number of years, it’s clear that the former will eventually replace the latter. But are Googlebooks actually new “books” or really just new “chapters” that represent an evolution of the Chromebook. That depends on where the comparison lies.
Advertisement
Latest Videos FromTechRadar
Chromebooks have done an excellent job of retaining attributes such as ease of management, security, and affordability. On the other hand, the AI-first mission of the Googlebook represents a dramatic contrast from the cloud-first mission of the Chromebook, and the two platforms carry significant enough differences to justify the new naming.
Foremost, the Googlebooks’ new technical foundation of Android should greatly improve the performance and integration of Android apps versus today’s Chromebooks.
A crash landing from the cloud
Indeed, that serves as a reminder that the original philosophy of the Chromebook as a minimalist web app appliance disappeared a long time ago. And while it is still tough to beat the Chromebook when it comes to computing on a tight budget (Microsoft’s most recent attempt, the education-focused Surface Laptop SE, had the company’s quickest market retreat since Windows RT), Google and its partners have sought to climb the pricing ladder with Chromebook Pluses.
These devices, which have embraced higher quality materials and earlier access to Google’s AI innovations (albeit mostly cloud-based ones), have sold well enough to signal to Google that the market is ready for Windows alternatives that shift away from competing so heavily on price.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Advertisement
While it’s not a perfect parallel for what Apple was able to do in bringing kids who grew up with the Apple II to the Mac, Google has an opportunity to provide a more capable alternative to a generation of kids who grew up with Chromebooks, particularly at a time when AI stands to transform the PC experience from being a tool to being an agent.
(Image credit: Future)
And so the more important question becomes not how Googlebooks will diverge from Chromebooks, but how their new functionality will stack up to Windows, which will also of course continue to evolve.
In this sense, Google’s timing is excellent because it does not need to rely on Android versions of apps catching up to Windows versions; the company has never had much luck getting developers to optimize for Android platforms beyond the phone. Rather, it can compete on a new breed of AI-focused functionality.
But despite Microsoft pulling back from cramming CoPilot into every corner of its desktop operating system, it is still in the early days of integrating AI into that platform as well.
Advertisement
At Build, for example, Microsoft showed not only how it is bringing OpenClaw-pioneered workflows into Windows, but how it is expanding the supporting processor family to include the bold and powerful RTX Spark architecture from MediaTek and Nvidia.
That should put some distance between Windows and Android-based PCs at the top of the market, but the real test will come down to how well Microsoft can scale such AI down versus how well Google scales its desktop AI up.
The Insta360 X6 looks set to arrive sooner as a fresh round of leaks reveals not only its key specs but also an apparent global launch date.
The latest images include what appears to be the camera’s retail packaging. This offers the clearest look yet at what Insta360 has planned for its next flagship 360-degree action camera.
According to the leaks, the Insta360 X6 is expected to launch globally on July 30. It will replace the current Insta360 X5 with a handful of hardware and software upgrades.
The biggest headline appears to be battery life. Packaging images shared online claim the X6 can deliver up to 140 minutes of recording when capturing 8K video at 30fps in 360-degree mode. This represents a notable endurance boost for creators shooting high-resolution footage.
Advertisement
The retail box also confirms a new PureVideo Mode, which is designed to improve low-light performance, alongside Replaceable Lenses 2.0. Insta360 already offers replaceable lens protection on previous models. However, the updated system appears to refine the design further, potentially making repairs or replacements easier after accidental damage.
Advertisement
Fresh hands-on images also reveal a subtle redesign. Compared with the Insta360 X5, the new camera appears shorter and slightly wider, while still maintaining the familiar dual-lens layout. Side-by-side photos also show it next to GoPro’s older Max 360 camera, highlighting its more compact proportions.
The leaked retail packaging provides a look at what’s included in the box, too. Buyers can apparently expect a 2,600mAh Extra Xtreme battery bundled as standard, alongside the usual accessories.
Advertisement
Pricing, however, appears to vary depending on the package. Previous leaks suggest the standard camera could cost around €589. Meanwhile, a more comprehensive bundle featuring additional accessories may be priced at €789.
While none of the details has been confirmed by Insta360 itself, the consistency across multiple leaks suggests the official announcement may not be far away.
Advertisement
If the leaked specifications prove accurate, the Insta360 X6 looks less like a radical redesign and more like a refinement of the X5 formula. Longer battery life, improved low-light shooting and an updated replaceable lens system would all address practical areas that matter to action camera users. The reported July 30 launch means there’s not long left to wait for the official reveal.
Fareed Zakaria opened with the question everyone is circling. Are we in an AI bubble, and has it begun to deflate? OpenAI has promised to spend hundreds of billions while making a fraction of that, he noted. The maths does not add up.
Nadella did not push back. He reframed the question as a test AI has to pass.
“This is a new general-purpose technology that is going to drive productivity,” he said on CNN’s GPS. “That productivity has to translate into very broad-based economic growth that is economy-wide in terms of GDP growth.”
Then the condition. “If we don’t see that, then we are going to have a problem. So unless we see that broad economic growth, we’re not going to have this movie end well.”
Advertisement
It is a striking thing for the man who spent $190bn this year to say two days before his earnings call.
The other Nadella showed up the same weekend, in his own executives’ account of the company. Microsoft cannot build capacity fast enough. The shortfall has forced it into triage, Business Insider’s Ashley Stewart reported. Its own AI products eat first. Azure customers get the remainder.
Chief financial officer Amy Hood said as much on January’s earnings call. Microsoft solves first for M365 Copilot and GitHub Copilot, then for research and development.
“Then what you end up with is the remainder going towards serving the Azure capacity that continues to grow in terms of demand,” she said. Had those chips gone to Azure instead, she added, growth would have topped 40% rather than 39%.
That admission is not new to readers here. A Michigan pension fund sued Microsoft in June over precisely this. The suit alleges the company hid the diversion before a January drop erased $357bn of market value.
Advertisement
What is new is that insiders say it has got worse. “All of the supply is gone once you solve for frontier labs and our internal businesses like M365 and Microsoft AI,” one executive told Business Insider.
Selling what you cannot deliver
Here is the part that reads oddly. Microsoft is raising quotas for its Azure salespeople despite the crunch. Some quotas rise by 30% this year, according to people familiar with the change.
Meanwhile it is buying capacity from its rivals. Amazon bailed Microsoft out after a run of GitHub outages. It explored leasing Oracle cloud infrastructure and walked away over security and compliance concerns. It is now evaluating Amazon and Google.
“We are shopping for capacity everywhere,” one person familiar with the talks said.
Advertisement
Inside the company, the logic is understood and the messaging is not. One executive framed the trade-off bluntly: why would Nadella prioritise growing Adobe, an Azure customer, over growing M365?
“I have no idea how we’re going to land that message with customers,” the person added.
The trap Microsoft is actually in
The dilemma is real, and Microsoft is not obviously handling it wrongly. Serving Azure customers lifts revenue now. Serving its own products is a bet that they eventually win.
Starve the first and Azure growth disappoints, which hits the share price immediately. Starve the second and Microsoft slips further behind in the race that justified the spending in the first place.
Advertisement
What makes the choice urgent is that customers have somewhere else to go. Google Cloud keeps posting large numbers. Meta and SpaceX are now selling compute too. Microsoft’s customers may not wait to find out what it decides.
The ecosystem argument
Zakaria’s second question was about China. Most firms are not using AI to solve Fermat’s theorem, he pointed out. They are rationalising inventory systems. So will the world simply take the cheaper Chinese open-weight models, like Moonshot’s Kimi?
Nadella’s answer was that provenance matters less than plumbing. “Even take the Chinese models. Guess where these models run? They run on a lot of the hyperscalers that are American, all over the world.”
Because the weights are open, he argued, American firms can monitor, test and post-train them. If a US lab post-trains a Chinese base model and ships it, he asked, whose model is that?
Advertisement
“As long as that remains, we will absolutely be competitive and we will win,” he said. China will have a role, he added, but this is not a zero-sum game.
He has been making a version of this case all week. His pinned post asks how to ensure “frontier benefits are diffused across the entire ecosystem” now that software has real marginal cost for the first time. Diffusion is the theory. Triage is the practice.
Three businesses in the blast radius
The strain is not only physical. Three core businesses now sit in AI’s path at once.
Microsoft 365 is the first. Knowledge workers used to open Word, Excel and PowerPoint to start the day. Increasingly they start inside an AI tool instead. Gartner predicted this year that AI would threaten to dethrone traditional productivity suites in a $58bn shakeup.
Advertisement
GitHub is the second. It had its best month ever, an executive told staff. It has also suffered dozens of major outages this year as AI usage surged. Cursor and Claude Code have taken millions of engineers in the meantime.
Azure is the third, and it is the one being asked to wait its turn.
The churn continues. Rajesh Jha has retired, Yusuf Mehdi is preparing to leave, and Charlie Bell has moved to an individual contributor role. Hayete Gallot, recruited back from Google, is seen internally as Althoff’s long-term successor.
Advertisement
Microsoft also overhauled performance reviews this year, cutting ratings to five categories and sharpening the distinctions between them. Executives say it feels like a return to the stack ranking of the Ballmer era. Managers have been told to thin out the higher-level engineering ranks.
“It’s almost like the old era of Microsoft is back,” one former executive said. “The old Windows era where you lead with a lot of fear and a billy club in your hand.”
Wednesday’s test
Microsoft reports fourth-quarter results on Wednesday. Amazon follows on Thursday. Between them the two will spend roughly $400bn on data centres this year, Fortune reported, with Microsoft near $190bn.
Investors are already twitchy. Alphabet’s stock fell 7% last Thursday after it raised capital-expenditure guidance and posted negative free cash flow. Microsoft shares are down about 19% this year, and roughly 25% over twelve months. That is the worst of the Magnificent 7 by some distance. Meta is next, down almost 17%.
Advertisement
The underlying business is not weak. Microsoft disclosed nearly $627bn of remaining performance obligations, almost double a year earlier. It is funding roughly $35bn of building a quarter from operating cash flow rather than new debt. Azure and other cloud services are forecast to reach $148.9bn in fiscal 2027.
Nadella has heard doubts before. “I remember when I became CEO, everybody said, oh my God, isn’t it too late man?” he recalled at a Morgan Stanley conference in March. Microsoft built anyway, and the public cloud turned out to be multiplayer.
At that same conference he described the plan. “We have OpenAI book, we have Anthropic book, but we want to also have the long tail of enterprise IT,” he said. The long tail is the part now waiting at the back of the queue.
Wake up, sheeple! You can’t trust American tech, and I speak as a US citizen whose ancestors first arrived in the States in the 1770s. Finnish MEP Aura Salla put it well at February’s Open Source Policy Summit: “The EU runs on Microsoft. The US could turn us off inside one hour.”
The same is true for the UK and pretty much every country in the world. If that doesn’t scare you, it should.
Ireland was preparing to pull the trigger on a Microsoft procurement potentially worth €1 billion when the government called a halt. Opposition politicians then asked why open source alternatives had never made it onto the shopping list.
Ireland’s Minister for Public Expenditure, Infrastructure, Public Service Reform and Digitalization, Frankie Feighan, said the agreement for Microsoft software and services had been canceled after “matters of concern were raised by an interested party.”
At the UN Open Source Week, Ireland’s Government CIO, Louise McKeever, said that as far as she was concerned, digital sovereignty is “the ability of a government to maintain control over its digital infrastructure, data, and technologies” in a world of cross‑border data flows, AI, and geopolitical risk – and that makes it “a national security concern” as much as a tech one.
Advertisement
Cian O’Callaghan, deputy leader of Ireland’s opposition Social Democrats, would agree. He said that, for value-for-money reasons and to avoid US technology dependency, Ireland should at least consider alternatives including “LibreOffice, Linux, Thunderbird, and Open-Xchange.”
In the United Kingdom, however, it’s a different story. A House of Commons Library briefing published in March put it plainly: “The UK Government does not have an overarching policy on digital sovereignty. It has set out its approach to building ‘sovereign capability’ in key technologies.”
Advertisement
The closest thing Britain has is the UK Compute Roadmap. It states that the government wants “sovereign, secure, and sustainable capability,” and directs the UK Sovereign AI Unit to treat compute as a priority area. Back in 2025, which is prehistory by AI standards, Labour wanted to pour £2 billion into sovereign AI. Now? Who knows? Stay tuned.
Yes, I agree. Those are insane numbers. Welcome to the wild, wonderful world of AI bubble spending.
Leaving aside the crazy AI numbers, some people in the UK get that digital sovereignty must be a priority. The Open Rights Group has a petition: Demand UK Digital Sovereignty. I suggest you sign.
Advertisement
As Trump has shown time and time again, “his” US has no “special relationship” with anyone. Just ask Israel or Canada. If the new PM, Andy Burnham, so much as sneezes at Trump, the President could take offense and apply pressure for the UK to lose its access to American tech resources.
To me, there’s no longer any question about it. Everyone, including companies and people in the States, must reduce their reliance on American software and services. Linux and open source alternatives that are not beholden to Washington offer the clearest way forward. ®
Apple’s insurance for multiple devices including iPhones, Watches and MacBooks, is finally expanding a year after launching in the US. AppleCare One is now available in four additional countries: the UK, France, Germany and Australia. The service is set to arrive in those regions on August 4th this year.
“With AppleCare One, customers in the UK can now enjoy the trusted protection of AppleCare+ in a way that’s simpler and more flexible than ever before — one plan, one price, and the peace of mind that comes with knowing all their eligible products can be covered,” the company said in an article on its UK newsroom.
In the UK, the service will cost £16.99 per month for three devices, with the ability to add more at any time at £4.99 per month per device. In France, it will cost €20.99 per month and €5.99 per month for the same coverage, respectively, according to 01net.com. That compares to $20 a month for three devices and $6 per month for additional devices in the US.
AppleCare One provides the same coverage as AppleCare+ with theft and loss, “including fast and unlimited repairs for accidental damage, battery replacement service, and 24/7 priority access to Apple experts,” Apple UK wrote. It also includes theft and loss coverage for iPhone, iPad and Apple Watch. You can use AppleCare One to not only insure brand new devices, but also ones you already own — provided they’re no more than four years old and in “good condition.”
Advertisement
Along with AppleCare One, Apple is also bringing theft and loss coverage for iPad and Apple Watch to AppleCare+ in the UK. Those devices join the iPhone, which already has the theft and loss option. The price for that for a base iPad model will start at £4.99 per month in the UK (£49.99 per year), compared to £3.49 for current AppleCare+ coverage without theft and loss. For the base iPhone 17, AppleCare+ with theft and loss is £9.49 per month, compared to £6.49 per month for regular AppleCare+.
Whether or not you’ll save money on AppleCare One compared to AppleCare+ depends on your devices and coverage. Apple notes that “a customer protecting their iPhone, iPad, and Apple Watch together can save up to £11.48 per month compared to maintaining separate AppleCare+ with theft and loss plans for each device.”
However, if you purchased the most basic versions of those devices with AppleCare+ but no theft and loss coverage (£6.49 + £3.49 + £2.49 = £12.47), individual coverage would be cheaper. AppleCare One is therefore best if you have higher-end devices or were planning to ensure them for theft and loss on top of accidental damage repairs. The benefits also accrue if you add a fourth or fifth device, particularly if it’s on the expensive side.
In the US, AppleCare One looks like an even better deal since AppleCare+ prices just went up for Macs and iPads. The increase is due to higher prices for those devices ranging from $100 for a basic iPad to $500 for an M5 Max MacBook Pro.



 Chris Philpot
Chris Philpot































































You must be logged in to post a comment Login