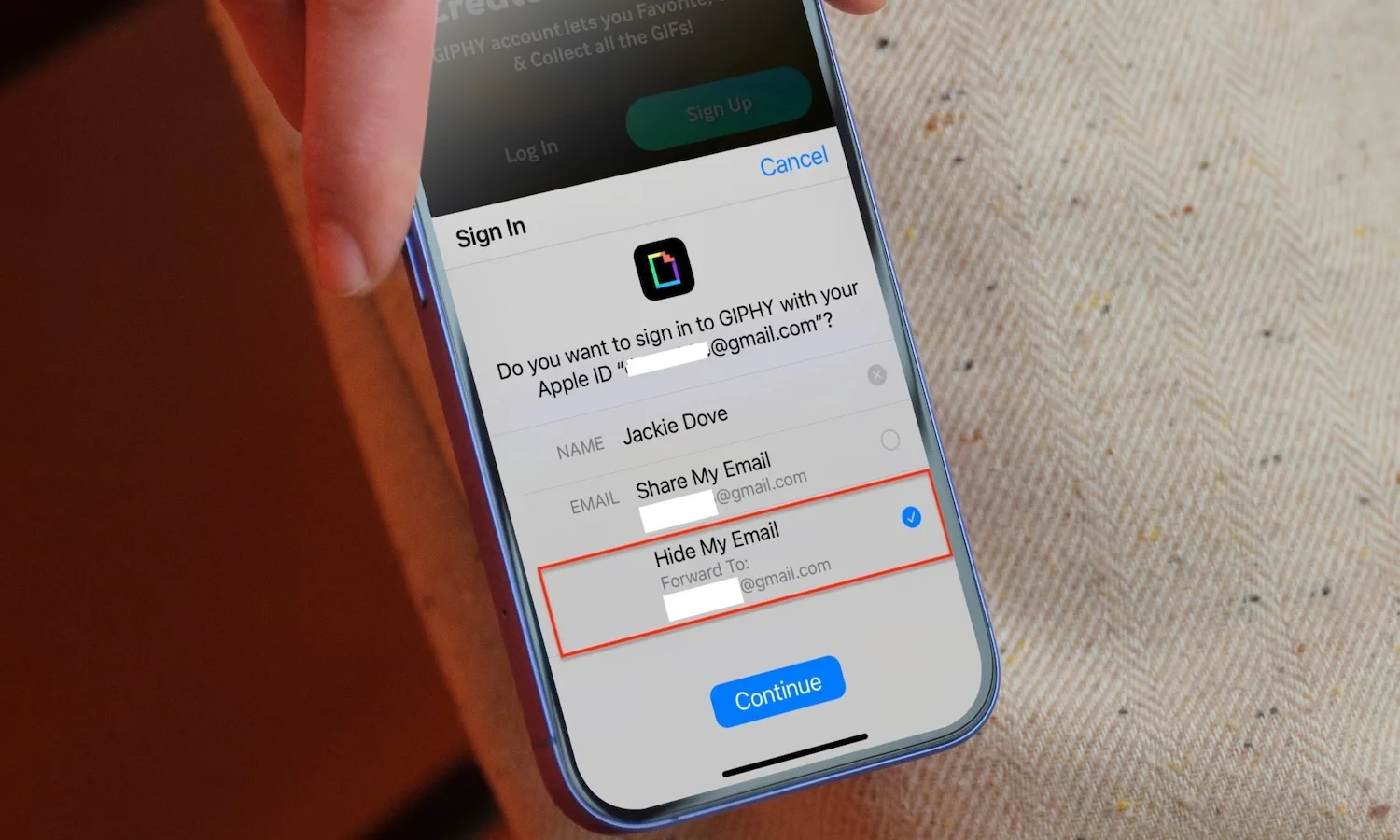
The world’s largest sovereign wealth fund lost NOK636 billion ($68 billion) in investment returns in the first quarter, driven by the equity slide among large US technology companies. The S&P 500 posted its deepest quarterly decline since 2022. The fund marginally outperformed its benchmark.
Norges Bank Investment Management (NBIM), which manages Norway’s Government Pension Fund Global, the world’s largest sovereign wealth fund at approximately $2.2 trillion, reported a negative return of 1.9% for the first quarter of 2026 on Thursday, its first quarterly loss in four quarters.
The fund lost NOK636 billion (approximately $68 billion) in investment returns during the January–March period. It beat its benchmark index by 0.01 percentage point.
The total reported decline in fund value was NOK1.27 trillion ($137 billion), a larger figure that includes the effect of currency movements: as the Norwegian krone strengthened against major currencies during the quarter, the value of the fund’s predominantly foreign-currency holdings declined further in krone terms when translated back.
Advertisement
“The result reflects a quarter with challenging market conditions,” deputy CEO Trond Grande said in a statement. “We saw limited impact on fixed income and real estate, but it was the decline in equities, especially among large US technology companies, that determined the outcome.”
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The fund holds approximately half its assets in US markets and has major positions in technology companies including Apple, Microsoft, Alphabet, Amazon, Nvidia, Meta, and Tesla.
Advertisement
US tech megacaps sold off sharply during Q1 2026, leaving the S&P 500 with its deepest quarterly decline since 2022, a move driven primarily by the geopolitical shock of the Iran war.
The US and Israel launched coordinated strikes against Iran in late February 2026, triggering a sustained market selloff that hit high-multiple growth stocks hardest.
Technology companies, which trade at elevated price-to-earnings multiples and are sensitive to risk-off sentiment, rising rates, and uncertainty about the economic outlook — bore the brunt.
Although markets have since partially recovered, the Q1 close locked in losses for the period. The Norwegian Ministry of Finance, in its 2026 white paper to the Storting, noted that the Iran war had pushed oil prices up while simultaneously pushing the value of the fund down, an unusual combination for Norway, which is both a major oil producer and a major equity investor.
Advertisement
Norway’s oil revenues have historically supported the fund’s growth, but the fund is now so large that its performance is more sensitive to global equity markets than to the oil price.
The quarter marks the second time in consecutive years that large US technology companies have been the primary driver of a quarterly loss for the fund. In Q1 2025, the fund also posted a loss driven by the tech sector, that time triggered by the emergence of DeepSeek, which wiped $2.7 trillion from US tech megacaps in a matter of weeks.
The pattern underscores the structural concentration risk inherent in the fund’s equity portfolio: as the largest single shareholder in many of the world’s most valuable technology companies, NBIM’s quarterly performance is increasingly correlated with the performance of a small number of US tech stocks.
The fund itself holds approximately 1.5% of all listed equities globally, making diversification within equity markets a genuine constraint rather than a simple choice.
Advertisement
Fixed income and real estate provided some buffer. NBIM’s fixed income portfolio and unlisted real estate holdings saw limited negative impact, consistent with the Q1 pattern in which the selloff was equity-specific and did not trigger a broader risk-off across credit markets.
The fund ended Q1 with a value of approximately $2.1–2.2 trillion depending on the dollar/krone exchange rate applied; the dollar-denominated headline of “$2.2 trillion” reflects the fund’s size at some recent prior date rather than its Q1 closing value after the loss.
The base of the lamp has two slider buttons. One toggle adjusts the warmth, from cold white light all the way to red. One adjusts the intensity, from ultra-bright down to a glareless glow. Hard taps on each button skip ahead, while holding the toggle down on one side or another adjusts the light settings quite slowly—slowly enough I at first sometimes question whether it’s happening.
The maximum brightness is 1,000 lumens—the approximate intensity of a 75-watt incandescent bulb. At this brightness, the battery lasts about five hours. At a lower intensity, this can extend to as long as a dozen hours.
Red light therapy is, of course, the province of TikTok as much as science—a field where wild exaggerations live alongside legitimate uses and benefits. For every sleep study showing that red light is superior to blue light when it comes to melatonin levels, there’s another showing that red light is associated with “negative emotions” before bed.
Advertisement
So I can only offer my own experience, which is that Edge Light Go’s red reading light offers me a pleasant liminal space between awake time and sleepy time, one not offered by a basic nightstand lamp. It allows me to sort of bask in a darkroom space that still lets me see and read, and drift off a little easier.
If I fall asleep, the light has an automatic 25-minute shut-off, which means I won’t do what I far too often do, which is drift off while reading and then wake up, alarmed, to a room filled with bright light in the middle of the night.
Caveats and Quirks
Photograph: Matthew Korfhage
This said, for all the virtues of portability, the Edge Light Go does not boast a base that’s heavy enough to stop the lamp from tipping over if I bend it forward from its lowest hinge. This can be an annoyance when trying to use the lamp as a reading light from a bedside table or the arm of a couch.
Volvo’s parent company has launched a new electric sedan in China that hits a familiar sore spot for US car shoppers.
The Geely Galaxy A7 EV pairs a clean, mainstream shape with a claimed 550km of CLTC range, and it enters the market at a price that still looks strikingly low by Western EV standards. It also appears set to stay far away from US dealerships.
That low headline number needs some caution though. Car News China reports a cheaper entry point, but the launched EV trims are higher, starting at 112,800 yuan, or about $16,530, and rising to 119,800 yuan. That is still aggressive pricing for a sedan of this size, just not quite the jaw-dropping bargain the earliest figure implied.
Geely
Cheap price, messy rollout
Once you get past the pricing confusion, the core package looks solid. The A7 EV uses a 58.05 kWh LFP battery and a front-mounted 160 kW motor, with Geely claiming 550km on the CLTC cycle. Reports say there’s a smaller-battery version, so there’s still some room for Geely to clear up how broad the lineup may become.
The rest of the car sounds more mature than bargain-bin. The EV gets restrained exterior styling, a 14.6-inch touchscreen, a digital instrument display, and an interior layout that reads like normal family transport instead of a stripped-down cost cutter. That matters because the real appeal here is not novelty. It is normality at a low price.
Advertisement
Why this one won’t reach you
For American readers, the frustrating part is how familiar this story has become.
China keeps producing lower-cost EVs that look usable and complete, while the US market rarely gets anything close to this price in a new electric sedan.
Nothing tied to the A7 EV points to a US launch, so this one looks like another car Americans will only watch from afar.
Geely
What happens before this goes on sale
The next question is whether the EV version can help revive momentum for the wider Galaxy A7 line.
Geely delivered 15,230 A7 units in China in the first quarter of 2026, but that total was down 59.4% from the prior quarter.
Advertisement
If this EV lands with buyers, it will matter as more than a fresh trim. It will show how quickly China’s lower-cost EV market is sharpening up.
If you’ve ever signed up for an app and then spent the next five minutes hunting for a six-digit code buried in your inbox, you know how painful the process is. I especially despise the magic sign-up link that websites send, as they sometimes fail to work if my default browser isn’t Google Chrome.
Thankfully, Google is fixing that with a new verified email credential for Android, and it’s a genuinely smart solution.
So what’s actually broken with OTPs?
The humble OTP has been the backbone of email verification forever, but it comes with real problems. You leave the app, open your inbox, find the email, copy the code, and come back.
It’s a long process that not only hurts consumers but also app developers. The number of steps required may cause a user to leave the app mid-sign-up, meaning the app loses potential users before they even try it.
Advertisement
iOS fixed this issue by directly allowing users to sign in via Apple account. Recently, it also added a feature to autofill OTPs from emails, just as Android supports OTP autofill from messages.
Digital Trends
Now, Google is also creating a seamless signup process that doesn’t require users to jump between apps.
How does the new system work?
Google now issues a cryptographically verified email credential directly to Android devices through the Credential Manager API. When an app needs to confirm your email, it can pull that credential directly using the Credential Manager API.
A small prompt appears on screen showing what information is being requested. You tap to confirm, and the app gets your verified email. No switching apps, no codes, no delay.
Android Developers Blog
Google recommends pairing this with passkey creation, so the first sign-up becomes the last time a user has to do anything manual.
The same can also be used for account recovery and re-authentication of sensitive actions, including setting changes, updating profile details, and more.
Advertisement
Android Developers Blog
The best part is that the new feature supports Android 9 and later devices, so you don’t need the best new Android smartphones to enjoy this quality-of-life improvement.
Are there any restrictions?
There are a few restrictions. The feature currently works only with regular consumer Google Accounts, not Workspace accounts. It also only works with Gmail accounts, and not with third-party email accounts that you might have used to create your Google account.
OpenAI introduced a new paradigm and product today that is likely to have huge implications for enterprises seeking to adopt and control fleets of AI agent workers.
Called “Workspace Agents,” OpenAI’s new offering essentially allows users on its ChatGPT Business ($20 per user per month) and variably priced Enterprise, Edu and Teachers subscription plans to design or select from pre-existing agent templates that can take on work tasks across third-party apps and data sources including Slack, Google Drive, Microsoft apps, Salesforce, Notion, Atlassian Rovo, and other popular enterprise applications.
Put simply: these agents can be created and accessed from ChatGPT, but users can also add them to third-party apps like Slack, communicate with them across disparate channels, ask them to use information from the channel they’re in and other third-party tools and apps, and the agents will go off and do work like drafting emails to the entire team, selected members, or pull data and make presentations.
Advertisement
Human users can trust that the agent will manage all this complexity and complete the task as requested, even if the user who requested it leaves.
It’s the end of “babysitting” agents and the start of letting them go off and get shit done for your business — according to your defined business processes and permissions, of course.
The product experience appears centered on the Agents tab in the ChatGPT sidebar, where teams can discover and manage shared agents.
This functions as a kind of team directory: a place where agents built by coworkers can be reused across a workspace. The broader idea is that AI becomes less of an individual productivity trick and more of a shared organizational resource.
Advertisement
In this sense, OpenAI is targeting one of office work’s oldest pain points: the handoff between people, systems, and steps in a process.
OpenAI says workspace agents will be free for the next two weeks, until May 6, 2026, after which credit-based pricing will begin. The company also says more capabilities are on the way, including new triggers to start work automatically, better dashboards, more ways for agents to take action across business tools, and support for workspace agents in its AI code generation app, Codex.
The most significant shift in this announcement is the move away from purely session-based interaction. Workspace agents are powered by Codex — the cloud-based, partially open-source AI coding harness that OpenAI has been aggressively expanding in 2026 — which gives them access to a workspace for files, code, tools, and memory.
Advertisement
OpenAI says the agents can do far more than answer a prompt. They can write or run code, use connected apps, remember what they have learned, and continue work across multiple steps.
That description lines up closely with the capabilities OpenAI shipped into Codex just six days ago, including background computer use, more than 90 new plugins spanning tools like Atlassian Rovo, CircleCI, GitLab, Microsoft Suite, Neon by Databricks, and Render, plus image generation, persistent memory, and the ability to schedule future work and wake up on its own to continue across days or weeks.
Workspace agents inherit that plumbing. When one pulls a Friday metrics report, it is effectively spinning up a Codex cloud session with the right tools attached, running code to fetch and transform data, rendering charts, writing the narrative, and persisting what it learned for next week.
When that same agent is deployed to a Slack channel, it is a Codex instance listening for mentions and threading its work back in.
Advertisement
This is the technical decision enterprise buyers should focus on. Building an agent on a code-execution substrate rather than a pure LLM-call-and-response loop is what gives workspace agents the ability to do real work — transforming a CSV, reconciling two systems of record, generating a chart that is actually correct — rather than describing what the work would look like.
Persistence and scheduling
In earlier AI assistant models, progress paused when the user stopped interacting. Workspace agents change that by running in the cloud and supporting long-running workflows. Teams can also set them to run on a schedule.
That means a recurring reporting agent can pull data on a set cadence, generate charts and summaries, and share the results with a team without anyone manually kicking off the process.
Here at VentureBeat, we analyze story traffic and user return rate on a weekly basis — exactly the kind of recurring, multi-step, multi-source task that could theoretically be automated with a single workspace agent. Any enterprise with a weekly reporting rhythm pulling from dynamic data sources is likely to find a use for these agents.
Advertisement
Agents also retain memory across runs. OpenAI says they can be guided and corrected in conversation, so they improve the more a team uses them.
Over time they start to reflect how a team actually works — its processes, its standards, its preferred ways of handling recurring jobs — which is a meaningfully different proposition from the static instruction-set GPTs that preceded them.
The integrated ecosystem
OpenAI’s claim is that agents should gather information and take action where work already happens, rather than forcing teams into a separate interface. That point becomes clearest in the Slack examples. OpenAI’s launch materials show a product-feedback agent operating inside a channel named #user-insights, answering a question about recent mobile-app feedback with a themed summary pulled from multiple sources.
The company’s demo lineup walks through a sample team directory of agents: Spark for lead qualification and follow-up, Slate for software-request review, Tally for metrics reporting, Scout for product feedback routing, Trove for third-party vendor risk, and Angle for marketing and web content.
OpenAI also shared more functional examples its own teams use internally — a Software Reviewer that checks employee requests against approved-tools policy and files IT tickets; an accounting agent that prepares parts of month-end close including journal entries, balance-sheet reconciliations, and variance analysis, with workpapers containing underlying inputs and control totals for review; and a Slack agent used by the product team that answers employee questions, links relevant documentation, and files tickets when it surfaces a new issue.
In a sense, it is a continuation of the philosophy OpenAI espoused for individuals with last week’s Codex desktop release: the agent joins the workflow where work is already happening, draws in context from the surrounding apps, takes action where permitted, and keeps moving.
From GPTs to a broader agent push
Workspace agents are not a standalone launch. They sit inside a roughly 12-month arc in which OpenAI has been systematically rebuilding ChatGPT, the API, and the developer platform around agents.
Advertisement
Workspace agents are explicitly positioned by OpenAI as an evolution of its custom GPTs, introduced in late 2023, which gave users a way to create customized versions of ChatGPT for particular roles and use cases.
However, now OpenAI says it is deprecating the custom GPT standard for organizations in a yet-to-be determined future date, and will require Business, Enterprise, Edu and Teachers users to update their GPTs to be new workspace agents.
Individuals who have made custom GPTs can continue using them for the foreseeable future, according to our sources at the company.
In October 2025, OpenAI introduced AgentKit, a developer-focused suite that includes Agent Builder, a Connector Registry, and ChatKit for building, deploying, and optimizing agents.
Advertisement
In February 2026, it introduced Frontier, an enterprise platform focused on helping organizations manage AI coworkers with shared business context, execution environments, evaluation, and permissions.
Workspace agents arrive as the no-code, in-product entry point that sits on top of that stack — even if OpenAI does not explicitly describe the architectural relationship in its materials.
The subtext across all three launches is the same: OpenAI has decided that the future of ChatGPT-for-work is fleets of permissioned agents, not single chat windows — and that GPTs, its first attempt at letting businesses customize ChatGPT, were not enough.
Governance and enterprise safeguards
Because workspace agents can act across business systems, OpenAI puts heavy emphasis on governance. Admins can control who is allowed to build, run, and publish agents, and which tools, apps, and actions those agents can reach.
Advertisement
The role-based controls are more granular than the ones most custom-GPT rollouts ever had: admins can toggle, per role, whether members can browse and run agents, whether they can build them, whether they can publish to the workspace directory, and — separately — whether they can publish agents that authenticate using personal credentials.
That last setting is the risky case, and OpenAI explicitly recommends keeping it narrowly scoped.
Authentication itself comes in two flavors, and the choice has real consequences. In end-user account mode, each person who runs the agent authenticates with their own credentials, so the agent only ever sees what that individual is allowed to see.
In agent-owned account mode, the agent uses a single shared connection so users don’t have to authenticate at run time. OpenAI’s documentation strongly recommends service accounts rather than personal accounts for the shared case, and flags the data-exfiltration risk of publishing an agent that authenticates as its creator.
Advertisement
Write actions — sending email, editing a spreadsheet, posting a message, filing a ticket — default to Always ask, requiring human approval before the agent executes.
Builders can relax specific actions to “Never ask” or configure a custom approval policy, but the default posture is human-in-the-loop.
OpenAI also claims built-in safeguards against prompt-injection attacks, where malicious content in a document or web page tries to hijack an agent. The claim is welcome but not yet proven in the wild.
For organizations that want deeper visibility, OpenAI says its Compliance API surfaces every agent’s configuration, updates, and run history.
Advertisement
Admins can suspend agents on the fly, and OpenAI says an admin-console view of every agent built across the organization, with usage patterns and connected data sources, is coming soon.
Two caveats worth flagging for security-sensitive buyers: workspace agents are off by default at launch for ChatGPT Enterprise workspaces pending admin enablement, and they are not available at all to Enterprise customers using Enterprise Key Management (EKM).
Analytics and early customer signal
OpenAI also ships an analytics dashboard aimed at helping teams understand how their agents are being used. Screenshots in the launch materials show measures like total runs, unique users, and an activity feed of recent runs, including one by a user named Ethan Rowe completing a run in a #b2b-sales channel.
The mockup detail supports OpenAI’s broader point: the company wants organizations to measure not just whether agents exist, but whether they are being used.
Advertisement
The clearest early-adopter signal in the launch itself comes from Rippling. Ankur Bhatt, who leads AI Engineering at the HR platform, says workspace agents shortened the traditional development cycle enough that a sales consultant was able to build a sales agent without an engineering team. “It researches accounts, summarizes Gong calls, and posts deal briefs directly into the team’s Slack room,” Bhatt says. “What used to take reps 5–6 hours a week now runs automatically in the background on every deal.”
OpenAI’s announcement names SoftBank Corp., Better Mortgage, BBVA, and Hibob as additional early testers.
The era of the digital coworker
Workspace agents do not land in a vacuum. They land in the middle of a broader OpenAI push — through AgentKit, through Frontier, through the Codex overhaul — to make agents more persistent, more connected, and more useful inside real organizational workflows.
They also land in a deeply crowded field: Microsoft Copilot Studio is wired into the Microsoft 365 base, Google is pushing Agentspace, Salesforce has rebuilt itself as agent infrastructure with Agentforce, and Anthropic recently introduced Claude Managed Agents, all different flavors of similar ideas — agents that cut across your apps and tools, take actions on schedules repeatedly as desired, and retain some degree of memory, context, and permissions and policies.
Advertisement
But this launch matters because it turns OpenAI’s strategy into something concrete for the teams already paying for ChatGPT, and because it quietly retires the product those teams were most recently told to standardize on.
If workspace agents live up to the pitch — shared, reusable, scheduled, permissioned coworkers that follow approved processes and keep work moving when their human is offline — it would mark a meaningful change in what workplace software does. Less passive software waiting for input, more active systems helping teams coordinate, execute, and move faster together.
The era of the digital coworker has begun. And, on OpenAI’s plans at least, the era of the custom GPT is ending.
‘It ultimately made people realize that music was worth paying for’: Spotify’s Sten Garmark on how the streaming giant created an entirely new business model, and its mission to convince users that ‘there was something better than free’
Over the past couple of decades we’ve witnessed a whirlwind of cultural changes in the music industry, but also major changes in terms of how we find and listen to music. And there’s arguably one entity that has contributed to these shifts more than any other: Spotify — which was founded 20 years ago today (April 23). Feel old yet? I sure do.
For many music lovers out there, myself included, Spotify was their introduction to music streaming, and over the last 20 years it’s climbed to the top of the ladder, amassing over 750 million users and cementing its position as one of the best music streaming services — and in the eyes of many, the daddy of them all.
However, it’s likely that few of today’s users know much about the company’s early days. Someone who knows more than most is Sten Garmark, Spotify’s Global Head of Consumer Experience, who’s been integral to its evolution since 2011.
Advertisement
Article continues below
To celebrate this milestone, Garmark and I sat down for an in-depth discussion, reflecting on Spotify’s impact on music over the last 20 years, and on what it took to craft a strong global brand, and reminiscing about its most iconic product features.
Advertisement
Let’s go back to the beginning
Daniel Ek (left) founded Spotify with Martin Lorentzon (not pictured) in April 2006 (Image credit: Getty Images / Kevin Mazur)
As with so many of today’s tech behemoths, from Apple to Amazon, Spotify had to start small, and Garmark remembers the unpredictable nature of the industry at the time it was founded. “The music industry was in free-fall, and it was kind of a dire time,” he tells me. “So the challenge in the beginning was to turn this around.”
In an age where piracy was rife, this became the catalyst for founders Daniel Ek and Martin Lorentzon to kick-start what was then a small business. “Daniel and Martin’s wild idea was trying to compete with piracy by forming partnerships with the industry, with labels and publishers, to create an entirely new business model for music to convince users that, actually, there was something better than free,” Garmark continues. “It ultimately also made people realize that music was worth paying for.”
These were the days before the modern smartphones really took off — the first iPhone was launched in January 2007 — which Garmark believes is the key to understanding Spotify’s early struggles in terms of scaling its business.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Advertisement
“This was a world of PCs and the iPod,” he says “The key innovation in the beginning was the ‘freemium’ model, and us believing that music was worth paying for, which most people didn’t at the time. Freemium was the way to get there, to give away a really fantastic free product, and we did that on the PC.” However, when the smartphone revolution kicked off, this opened up a gap in the market, and Spotify immediately aimed for it.
Garmark has played a major role in developing Spotify’s mobile experience, and he says of those early years, before he came on board: “After the iPhone launched, the company said ‘oh, go mobile’, then you pay a subscription. So that was the business model, mobile just took off and PC sales weren’t the thing, so we had to totally reinvent ourselves to really reimagine how the whole business model worked.”
It all started with the playlist
Over the years Spotify has been building on its playlist feature, now offering tools such as Prompted Playlists, Blends, AI Playlists, and more (Image credit: Future)
One area where Spotify continues to have an advantage over its rivals, is its range of addictive product features, which in themselves have contributed to the cultural shifts in music consumption and discovery. Beloved tools like Spotify Wrapped and Discover Weekly have hooked subscribers and reeled them in, but for Garmark, there’s one feature that’s truly iconic; the playlist.
Advertisement
“It’s such a basic feature that it almost feels like you just assume it’s there,” he says. “If you go back to before Spotify, a playlist was something you had on your own MP3, but you couldn’t share it. I think (the playlist) is the core innovation, because we built so much on top of it.”
When you think about it, the basic foundation of the playlist has served as the basis for pretty much all of Spotify’s unique product features over the last 20 years. It paved the way for Collaborative playlists and Prompted playlists, and even for fun tools like Daylist, but Spotify also prides itself on its editorial playlists, curated collections of songs put together by Spotify employees who Garmark refers to as “the taste-makers”. But not all of Spotify’s ideas for new features have seen the light of day.
“There are so many”, says Garmark. “There are two ways to do product development. You look at what other people do and copy that. The other thing is you imagine things that you’d want in the world, but which don’t exist. We are firmly the latter. It’s our job to make bets and come up with ideas and believe that, if we build this thing, people are going to love it. They might not always be asking for it, but once they’ve experienced it, they’re never going to look back.”
Advertisement
Music discovery is forever
(Image credit: Future)
There’s no doubt that the playlist has been a powerful asset to Spotify’s user experience, but I’d argue that the algorithm has been a monumental development, shaping how we find new music, and also how it finds us. The issue of tastes becoming homogenized remains a concern for many and is still a hot topic — but Garmark believes otherwise.
“I think it’s totally the other way around,” he tells me.“You have a new user come in on Spotify, and if they’re a little bit older, they tend to just listen to the music that they fell in love with in their formative years. Then things get frozen in time, and that’s what people tend to listen to for their whole life. But it also means that they fall out of love with music in a way, and discovery is so important to kind of keep falling in love with music over again.
“The algorithms that we have really enable that. What we see with our users coming in as we follow them on their journeys, is that the variation of what they listen to isn’t wrong. When they come in they explore more, and they get to discover more, and it never ends. It’s this wonderful machinery of just discovering more wonderful, talented artists that people just keep falling in love with.”
Advertisement
Despite Spotify’s vast list of achievements over the years, in terms of both innovating and growing its user base, it feels like, for Garmark, this is just the beginning, and my senses tell me that it has a lot more tricks up its sleeve for the next 20 years and beyond. And sure enough, Garmark leaves me with a tease: “At Spotify, we are full of ideas.”
NASA announced that it will launch the Nancy Grace Roman space telescope into orbit in September 2026, eight months ahead of schedule. The new space telescope is expected to deliver 20,000 terabytes of data to astronomers over the course of its life.
That will add to 57 gigabytes of breath-taking imagery downlinked daily from the James Webb Space Telescope, which began its work in 2021, and the start of a survey later this year by the Vera C. Rubin Observatory in the mountains of Chile, which is expected to gather 20 terabytes of data each night.
For comparison, the Hubble Space telescope, once the gold standard, delivers just 1 to 2 gigabytes of sensor readings each day. It’s been a while since all those readings were pored over by hand, but like everyone else with a pile of data, astronomers are now turning to GPUs to solve their problems.
Brant Robertson, a UC Santa Cruz astrophysicist, has had a front-row seat to this step change in science while supporting or using data from these missions. Robertson has spent the past 15 years working with Nvidia to apply GPUs to the problems of understanding space, first through advanced simulations testing theories about supernnova explosions, and now developing the tools to analyze a torrent of data from the newest observatories.
Advertisement
“There’s been this evolution [from] looking at a few objects, to doing CPU-based analyses on large scales of the data set, to then doing GPU-accelerated versions of those same analyses,” he told TechCrunch.
Robertson and then-graduate student Ryan Hausen developed a deep learning model called Morpheus that can pore over large data sets and identify galaxies. Their early AI analysis of Webb data identified a surprising number of a specific type of disc galaxies and added a new wrinkle to theories about the development of our universe.
Now Morpheus is changing with the times: Robertson is switching its architecture from convolutional neural networks to the transformers behind the rise of large language models. That will result in the model being able to analyze several times the area than it can currently, speeding up its work.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
Robertson is also working on generative AI models trained on space telescope data to improve the quality of observations collected by ground telescopes, which are distorted by Earth’s atmosphere. Despite advances in rocketry, it’s still hard to get an 8 meter mirror into orbit, so using software to improve Rubin’s observations is the next best thing.
Advertisement
But he’s still feeling the pressure of global demand for GPU access. Robertson has used the National Science Foundation to build a GPU cluster at UC Santa Cruz, but it is becoming outdated even as more researchers want to apply compute-intensive techniques to their work. The Trump administration proposed cutting the NSF’s budget by 50% in its current budget request.
“People want to do these AI, ML analyses, and GPUs are really the way to do that,” Robertson said. “You have to be entrepreneurial…especially when you’re working kind of at the edge of where the technology is. Universities are very risk averse because they just have constrained resources, so you have to go out and show them that, ‘look, this is where we’re going as a field.’”
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
There’s little point in setting up your own shed-based clean room for semiconductor purposes if you don’t try to do something practical with it. Something like responding to the RAMpocalypse by trying to make your own RAM, for example.
Testing the DRAM cells. (Credit: Dr. Semiconductor, YouTube)
After all, what could be so hard about etching the same repeating structures over and over? In a recent video, [Dr. Semiconductor]’s experience doing exactly this are detailed, with actual DRAM resulting at the end.
We covered the construction of the clean room shed previously, which should provide at least the basic conditions to produce semiconductors without worrying about contaminating dies. From here the process is reminiscent of etching PCBs, with a prepared surface coated with photoresist. Using UV exposure through a mask, the pattern is etched into the photoresist and from there the pattern is subsequently etched into the wafer’s surface.
With the patterns formed, the next step is doping of the silicon in order to create the active structures, i.e. the transistors and capacitors. Doping can be done in a variety of ways, with ion implantation being the industry standard method, but a bit too expensive and bulky for a shed fab. Instead a spin-on-glass method was used. After this the remaining functional structures can be built up.
If anyone was expecting to see a DDR5 DRAM die pop out at the end, they’re bound to be disappointed. The target here was to create a 5×4 array of DRAM cells, for a dizzying 20 bits. Still, the fact that it’s possible to DIY DRAM like this at home is already pretty awesome, with clearly plenty of room to push it towards and past fabrication nodes of the 1990s and beyond.
Advertisement
Although the produced DRAM cells have fairly leaky capacitors, they’re good enough for their purpose, and the plan is to scale up to a large DRAM array from here. Whether the DRAM control logic will also be implemented in hardware like this remains to be seen, but the video’s ending makes it clear that the goal is to attach it to a PC somehow.
CATL unveiled a new wave of EV battery tech, “including a lighter battery pack rated for a 1,000-km (621-mile) driving range and an upgraded fast-charging battery that can go from 10 percent to 98 percent in under seven minutes,” reports Interesting Engineering. From the report: The launches were made during a 90-minute event in Beijing ahead of the Beijing Auto Show, where automakers are expected to showcase next-generation EVs and connected technologies. CATL said its latest Qilin battery — a high-energy-density pack often paired with nickel manganese cobalt (NMC) cells for long range and improved space efficiency — can deliver a 1,000-km (621-mile) driving range. It is designed to deliver long range while reducing battery pack weight.
The company said the product is aimed at automakers facing tighter efficiency rules in China and other markets. It also rolled out an upgraded Shenxing battery — CATL’s fast-charging lithium iron phosphate (LFP) pack — that targets one of the biggest barriers to EV adoption: charging time. CATL said the pack can recharge from 10 percent to 98 percent in less than seven minutes.
The new Shenxing battery marks a significant improvement over CATL’s previous version, which charged from 5 percent to 80 percent in 15 minutes, according to Financial Times. […] The company also announced plans to begin mass delivery of sodium-ion batteries in the fourth quarter. Sodium-ion technology is seen as a lower-cost alternative that could reduce dependence on lithium, cobalt, and nickel.
A satirical but working tool called Malus uses AI to create “clean room” clones of open-source software, aiming to reproduce the same functionality while shedding attribution and copyleft obligations. “It works,” Mike Nolan, one of the two people behind Malus, who researches the political economy of open source software and currently works for the United Nations, told 404 Media. “The Stripe charge will provide you the thing, and it was important for us to do that, because we felt that if it was just satire, it would end up like every other piece of research I’ve done on open source, which ends up being largely dismissed by open source tech workers who felt that they were too special and too unique and too intelligent to ever be the ones on the bad side of the layoffs or the economics of the situation.” 404 Media reports: Malus’s legal strategy for bypassing copyright is based on a historically pivotal moment for software and copyright law dating back to 1982. Back then, IBM dominated home computing, and competitors like Columbia Data Products wanted to sell products that were compatible with software that IBM customers were already using. Reverse engineering IBM’s computer would have infringed on the company’s copyright, so Columbia Data Products came up with what we now know as a “clean room” design.
It tasked one team with examining IBM’s BIOS and creating specifications for what a clone of that system would require. A different “clean” team, one that was never exposed to IBM’s code, then created BIOS that met those specifications from scratch. The result was a system that was compatible with IBM’s ecosystem but didn’t violate its copyright because it did not copy IBM’s technical process and counted as original work.
This clean room method, which has been validated by case law and dramatized in the first season of Halt and Catch Fire, made computing more open and competitive than it would have been otherwise. But it has taken on new meaning in the age of generative AI. It is now easier than ever to ask AI tools to produce software that is identical in function to existing open source projects, and that, some would argue, are built from scratch and are therefore original work that can bypass existing copyright licenses. Others would say that software produced by large language models is inherently derivative, because like any LLM output, it is trained on the collective output of humans scraped from the internet, including specific open source projects.
Malus (pronounced malice), uses AI to do the same thing. “Finally, liberation from open source license obligations,” Malus’s site says. “Our proprietary AI robots independently recreate any open source project from scratch. The result? Legally distinct code with corporate-friendly licensing. No attribution. No copyleft. No problems.” Copyleft is a type of copyright license that ensures reproductions or applications of the software keep it free to share and modify.
Ancient Slashdot reader hwstar shares a report from The Conversation: For the first time ever, more than 50 nations will gather next week in Colombia to hash out how to wind down and end their dependence on coal, oil and gas. The history-making conference was planned before the Iran war. But this year’s energy crisis has greatly raised the stakes. […] Around 80% of the trapped oil was destined for the Asia-Pacific. Faced with dwindling supply, the region’s governments are implementing emergency measures such as sending workers home, banning government travel, rationing fuel and cutting school hours. The problem is especially bad in the Pacific. Many island nations use diesel for power generation. In response, leaders declared a regional emergency.
[…] But the real difference from half a century ago is that fossil fuel alternatives are ready for prime time. Since the 1970s, the price of solar panels has fallen 99.9%, while the cost of wind has fallen 91% since 1984. Battery prices have fallen 99% since 1991. […] This year’s oil shock shows signs of creating an unplanned social tipping point — a threshold for self-propelling change beyond which systems shift from one state to another. Climate scientists warn of climate tipping points which amplify feedback and accelerate warming. But social scientists also point to positive tipping points — collective action that rapidly accelerates climate action.
[…] The routine burning of coal, oil and gas is the primary driver of the climate crisis. The world’s highest court last year made clear nations have obligations to stop burning fossil fuels. But fossil fuels have barely been mentioned in 30 years of global climate negotiations, due in part to blocking efforts by big fossil fuel exporters and lobbyists. Frustrated by slow progress, a coalition of nations has bypassed global climate talks to discuss how to actually phase out fossil fuels. The first of these summits will take place next week. More than 50 nations will gather in Santa Marta, Colombia, to discuss a potential standalone treaty to manage fossil-fuel phaseout while protecting workers and financial systems.


































































You must be logged in to post a comment Login