While each file system is sandboxed, meaning it’s isolated from other websites and from the device system itself, the JavaScript can measure the I/O interactions. Then, by running those interactions through a pretrained convolutional neural network—a system that uses deep learning to analyze text, audio, and images—the attacker can deduce various apps and websites open on the device.
“The attacker continuously measures SSD contention by performing random reads from a large OPFS file,” the researchers explained. “SSD contention caused by user activity causes measurable latency differences for these read operations. By training a convolutional neural network (CNN) on these traces, the attacker can fingerprint user activity on the host system by classifying new traces using the trained model.”
The technique has its limitations. First, the OPFS file must be extremely large—likely a gigabyte or more. That requirement means that attacks at scale would inevitably be detected by many users. Additionally, the OPFS file must be stored on the same SSD the visitor is using. This isn’t usually a problem for tracking open websites, since the OPFS file is stored in the browser’s default location. In the event apps are using a separate SSD drive for apps, those apps couldn’t be detected by FROST.
One of the best ways to prevent FROST attacks is to close tabs as soon as they’re no longer needed. More savvy users can monitor the creation and size of OPFS files allocated by unknown websites. The researchers proposed ways for browser makers to shut down the side channel. One such method is to limit the maximum size such files that are allowed. There are no indications FROST attacks have been performed in the wild.
Advertisement
The researchers performed the full Frost attack on an M2 Mac. On Linux, they showed that the underlying primitive (measuring SSD access latency traces from JavaScript) works, but didn’t run the full attack.
“However, since the performance of the primitive is similar between macOS and Linux, we expect similar performance for the full classification,” Hannes Weissteiner, one of the co-authors, wrote in an email. “In principle, it would be possible to train a model on any system activity that reliably generates SSD accesses.”
The researchers did not test Windows.
The paper linked above provides many more technical details. The research is scheduled to be presented at the DIMVA conference in July.
Among the many Chinese AI companies and laboratories vying for market share and attention (no pun intended) on the global marketplace, MiniMax stands out for its commitment to providing frontier-level intelligence across a range of modalities, including text, coding, and video (through its Hailuo model series) — often under permissive, enterprise-friendly, standard open source licenses.
Now, MiniMax is again raising the eyebrows of AI power users and developers around the world by releasing a new, in-depth technical report on the making of its popular M2 series of language models (M2, M2.5, and M2.7) shedding light on its numerous engineering innovations and clever approaches — while the company and its leaders also teased a whole new sparse attention approach for its upcoming MiniMax M3 series of models, which it says yields up to 15.6 times faster decoding (or LLM response) speed at long contexts (a million tokens) by adopting a custom sub-quadratic framework. In so doing, MiniMax has designed M3 to make ultra-long-context AI agent deployment economically viable.
The M2 report is noteworthy for any enterprise working with AI models, and especially those looking to fine-tune and train their own in-house. After all, MiniMax’s M2 series models often achieved top benchmarks in the world for open source AI performance when they were released.
While the title has since been eclipsed by several other Chinese labs including DeepSeek and Xiaomi, MiniMax’s new report offers a blueprint that can be used to improve AI model and agent performance by enterprises around the world.
Advertisement
As Adina Yakup of Hugging Face observed on X, “Beyond the benchmarks, they’ve done some really solid work on MoE efficiency and agent oriented design. Excited to see where M3 goes next!”
The attention dilemma
The core technical architecture of the M2 series relies on a sparse Mixture-of-Experts (MoE) decoder-only Transformer layout used by numerous other state-of-the-art LLMs.
The foundational backbone houses 229.9 billion total parameters, yet maintains a remarkably lean operational footprint by activating just 9.8 billion parameters per token across 256 fine-grained experts.
To optimize routing and avoid standard load-balancing issues, however, MiniMax implemented sigmoid gating paired with learnable, expert-specific bias terms, heavily reducing reliance on restrictive auxiliary losses.
Advertisement
The most definitive engineering decision documented in the M2 paper was the strict adherence to full multi-head attention with Grouped Query Attention (GQA) across all 62 layers.
In large language models, “quadratic scaling” refers to the computationally expensive reality of standard full attention mechanisms, where every token in a sequence must mathematically connect to every other token. To use a real-world analogy, it is akin to attending a networking event and being forced to have a deep conversation with every single person in the room while simultaneously monitoring all other ongoing conversations.
While this approach yields incredibly thorough context, the processing power and memory required explode at the square of the input length, creating a severe hardware bottleneck as models attempt to ingest hundreds of thousands of words.
The problem with sub-quadratic scaling
“Sub-quadratic” scaling introduces architectural shortcuts designed to bypass this exponential computational load. Instead of mapping every possible connection, sub-quadratic methods—such as Sliding Window Attention or compressed linear attention—might only analyze a localized window of nearby words or generate a compressed summary of the broader text.
Advertisement
These efficient methods drastically reduce hardware costs and allow models to process massive documents at high speeds, but they historically introduce severe trade-offs in accuracy, often causing the AI to miss the “big picture” or lose track of distant context.
This mathematical dilemma defines the architectural evolution from MiniMax’s M2 to its upcoming M3 series. During M2’s development, researchers rigorously tested sub-quadratic shortcuts but found they crippled the model’s “multi-hop reasoning”—its ability to connect disparate clues across a long document—forcing the team to absorb the massive computational cost of full quadratic attention to maintain frontier-level intelligence.
Indeed, they aggressively benchmarked efficient attention alternatives during pre-training but intentionally threw them out. They experimented extensively with hybrid setups, interleaving full attention with sub-quadratic architectures like Lightning Attention or hybrid Sliding Window Attention (SWA) configurations.
The empirical results were definitive: at a larger scale, linear and windowed attention variants exhibited severe reasoning deficits.
Advertisement
On evaluations exceeding 32K context windows, SWA variants performed significantly worse than full attention, dropping from a baseline score of 90.0 to 72.0 on the RULER 128K complex word extraction task.
Sub-quadratic configurations proved prone to memory-bound constraints during training, lacked native prefix caching support, and failed to smoothly align with Multi-Token Prediction (MTP) modules used for speculative decoding. Full attention was deemed necessary to preserve multi-hop reasoning capability.
However, recognizing that physical hardware limits cannot sustain quadratic scaling indefinitely, MiniMax is designing the M3 series around a novel sub-quadratic framework to finally deliver both high-speed processing and uncompromised reasoning.
MiniMax Sparse Attention (MSA) and sub-quadratic scaling incoming
The upcoming MiniMax-M3 breaks away from the compute-heavy constraints of its predecessor. As disclosed by MiniMax’s engineering team under the banner “Something BIG is coming,” M3 introduces “MiniMax Sparse Attention” (MSA).
Advertisement
Unlike DeepSeek’s Multi-head Latent Attention (MLA), which compresses keys and values into a low-dimensional latent space, MSA operates on a standard GQA backbone but utilizes block-level selection on real, uncompressed Key-Values.
Elie Bakouch at AI training infrastructure and platform lab Prime Intellect posted on X noting that the main changes feature “block level selection like in CSA but attention is done on the real KV, not in [compressed space].”
This solves the precision loss and prefix-caching obstacles noted in the M2 paper. By filtering and selecting block-level sequences dynamically, MSA delivers an architectural leap: early hardware profiling indicates a 9.7x speedup in prefilling latency and a massive 15.6x speedup during decoding phases at a 1-million token sequence length compared to the full-attention M2 architecture.
To understand why a speedup in the “decoding phase” is so significant, it helps to break down how an AI actually reads and writes information. When you interact with an AI, the processing happens in two distinct steps: prefilling and decoding.
Advertisement
When you hand an AI a prompt—whether it’s a short sentence or a massive 1,000-page document—it processes that entire chunk of text all at once in parallel, known as “prefilling.” It essentially “reads” the input in one big gulp to build its initial understanding and establish context.
In order to generate a response, the AI must enter a “decoding phase.” To predict the first word of its response, it looks at the prompt. To predict the second word, it has to look at the prompt plus the first word. To predict the hundredth word, it must recalculate the context of the prompt and the previous 99 words it just wrote. So the response actually becomes harder to generate as it goes on, with the end requiring a full review of all prior parts.
For a layperson, imagine reading a dense legal brief (prefilling) and then being forced to write a summary report where, before writing every single new word, you must rapidly reread the entire brief plus everything you’ve written so far to ensure your next word makes sense (decoding).
Because the AI must constantly and repetitively look backward to generate each new step forward, the decoding phase is the most severe computational bottleneck in generating text. It is why AI models often type out their answers word-by-word, and why they slow down significantly as conversations get longer.
Advertisement
Therefore, when the passage states the new architecture achieves a massive 15.6x speedup during the decoding phase at a 1-million token sequence length, it means the model has found a structural shortcut to generate its answer—token by token—nearly 16 times faster. It directly solves the exact bottleneck that normally makes AI chatbots freeze or stutter when handling massive amounts of information.
The evolution of the MiniMax M series and the creation of ‘Forge’
On a product level, MiniMax has consistently evolved its models from simple text generation interfaces into autonomous workers.
The M2 series pioneered an “interleaved thinking” protocol where the model alternates between natural-language planning traces and explicit tool invocations inside a single trajectory. Rather than dropping the intermediate chain-of-thought blocks between execution turns, M2 appends the full thinking history directly into the conversation context. This planning persistence prevents state drift, allowing the model to recover gracefully from runtime errors and revise its strategies based on environment feedback.
To train these long-horizon workflows, MiniMax built “Forge,” a scalable agent-native reinforcement learning system. Forge decouples execution into three independent modules—the Agent Side, the middleware abstraction layer (Gateway Server and Data Pool), and the Training/Inference engines.
Advertisement
As MiniMax engineer Olive Song explained on the ThursdAI podcast, “What we realized is that there’s a lot of potential with a small model like this if we train reinforcement learning on it with a large amount of environments and agents… But it’s not a very easy thing to do,” adding that this environmental training was where the team spent a significant portion of their development timeline. To absorb the extreme trajectory-length variance common in multi-step agent environments, Forge implements two vital engineering solutions:
Windowed FIFO Scheduling: A training scheduler that maps a sliding window over the generation queue. It permits greedy, high-throughput fetching of completed tasks within the window to prevent cluster idle time, while strictly enforcing FIFO boundaries to maintain distributional stability and avoid gradient oscillation.
Prefix Tree Merging: An optimization that restructures batch training into tree computation. Completions sharing identical conversation prefixes are calculated exactly once in the forward pass before branching. This eliminates redundant calculations, generating up to a 40x training speedup with zero approximation error.
This reinforcement infrastructure directly spawned the M2.7 checkpoint, moving the series toward “self-evolution”. Operating inside an automated agent harness, M2.7 functions as an independent machine learning engineer. The model profiles its own active training runs, diagnoses anomalies, reads logs, and automatically modifies its own codebase and configurations.
According to MiniMax, M2.7 successfully handled between 30% and 50% of its own development workflow.
On OpenAI’s rigorous MLE Bench Lite suite, which tests autonomous ML research capability, M2.7 achieved a 66.6% medal rate across independent 24-hour trials, effectively tying Google’s closed-weight Gemini 3.1 Pro.
Advertisement
The continuous cadence from M2 to M2.5, which famously completed 30% of internal tasks and 80% of newly committed code at MiniMax HQ, underlines a broader vision.
As the MiniMax team noted during that phase of deployment, “we believe that M2.5 provides virtually limitless possibilities for the development and operation of agents in the economy.”
With the technical report codifying the M2 generation’s successes and the MSA tech blog on the horizon, MiniMax is signaling that the next frontier of AI is explicitly about translating a mini-activation footprint into maximum real-world intelligence.
Sennheiser has taken direct aim at Sony’s WH-1000XM6 with the Momentum 5 Wireless, its refresh of its popular series that adds a user-replaceable battery, doubled microphone arrays, and Dolby Atmos head-tracking.
The hardware builds on the same 42mm transducer from the Momentum 4 Wireless, manufactured at Sennheiser’s facility in Tullamore, Ireland, and tuned to the same signature profile that earned the previous generation strong reviews across the audio press, with Hi-Res Audio certification and aptX Lossless support via Snapdragon Sound now extending that pedigree to lossless wireless playback.
Image Credit (Sennheiser)
The ANC system has been substantially reworked, with the microphone count doubling to four per side, a configuration Sennheiser that credits with delivering up to three times more effective reduction of voice-type ambient noise compared to the previous model, alongside improved transparency mode quality during calls.
Battery life holds at 57 hours with ANC (that’s with AAC streaming), a figure that remains competitive compared to the 30 hours the Sony WH-1000XM6 boasts. The addition of a user-replaceable 700mAh cell means the headphones take a more eco-friendly approach to replacing internal hardware with the EU laws regarding batteries set to come into effect in 2027.
Advertisement
Advertisement
Dolby Atmos with head-tracking arrives via a day-one firmware update rather than out of the box, with Bluetooth 6.0 support to follow down the line through a future firmware release.
Apple takes its sweet time in adopting a new trend or technology, but when it does, it comes up with one of the best implementations ever. That’s exactly what everyone is expecting from the company’s first foldable. Call it the iPhone Fold or the iPhone Ultra, the Cupertino giant has more riding on this launch than perhaps any product launched in the last few years, and it could break cover later this year.
The rumors have been building for months, but at this point, we have a clearer picture than ever, both of the engineering advancements Apple is pushing hard for, and the trade-offs it may have to accept along the way. We’re a couple of months away from the iPhone Fold’s launch, and here’s everything you need to know about it.
iPhone Fold / Ultra: At a glance
Specification
Details
Name
iPhone Fold or iPhone Ultra
Apple yet to confirm the official name
Release date
To be announced in September 2026
Availability possibly October–December 2026
Starting price
$1,999–$2,500
256GB / 512GB / 1TB storage options rumored
Form factor
Book-style fold (horizontal)
Similar to Samsung Galaxy Z Fold but with a wider aspect ratio when unfolded
Inner display
~7.76–7.8 inches, OLED
4:3 aspect ratio; near iPad mini-sized when unfolded
Outer display
~5.3–5.5 inches, OLED
Usable as a standard iPhone when folded
Crease
Near-invisible
Apple reportedly pursued elimination “regardless of cost”
Chip
A20 or A20 Pro
Based on expected September 2026 launch timeline
Biometrics
Side-mounted Touch ID
Face ID likely dropped to save internal space
Cameras
Dual rear (main + ultrawide), no telephoto
One front camera on inner display; one on outer display
Battery
5,000–5,500 mAh
Largest ever on an iPhone, per Weibo leakers
Frame material
Titanium and aluminum
Could use liquid metal hinge
iPhone Fold / Ultra: Latest News
May 26, 2026 A report by Letem světem Applem (via PhoneArena) shows the purported iPhone Ultra inside protective case, revealing almost everything about the phone’s design.
May 26, 2026 A claim from Instant Digital (via Weibo) suggests that Apple is facing problems in improving manufacturing yields during the pre-assembly process. The issue is related to Surface Mount Technology (SMT).
May 19, 2026 Chinese tipster Digital Chat Station (via Weibo) shares that Apple could adopt a similar crease-free solution as Oppo Find N6.
May 16, 2026 Chinese tipster Instant Digital (via Weibo) claims that Apple has achieved a visually crease-free foldable display with “long-term stability.” The core problem, however, is improving the hinge reliability.
May 11, 2026 A report from MacRumors states that the first foldable iPhone could arrive in just two colors at launch.
April 7, 2026 After rumors about Apple hitting a development snag with the foldable, Bloomberg’s Mark Gurman pushed back by reinstating the September launch window.
March 16, 2026 Given that the device will run on iOS, and not iPadOS, it might miss out on some of the most popular apps or the advanced multitasking features built for iPads.
When will Apple release the iPhone Fold?
One of the most credible sources of information for upcoming Apple products, Bloomberg’s Mark Gurman, remains confident that the iPhone Ultra or iPhone Fold is on schedule for a September 2026 launch, at the company’s most important fall hardware event, which has also become one of the most important events in the consumer tech industry.
Apple has spent years watching from the sidelines, as Samsung, Google, and a couple of other Chinese companies reveal their foldables, and it wouldn’t risk revealing its first foldable through a separate event, one that might not have as much awareness or gather as much attention as its iconic fall event.
Front Page Tech
I believe the iPhone Ultra could be the last announcement, after the iPhone 18 Pro and iPhone 18 Pro Max reveal.
On the flip side, analyst Tim Long has flagged the shipments for iPhone Fold might not begin until December 2026, implying that the announcement and arrival could be separated by almost three months, corroborating a report by Nikkei Asia about Apple hitting development snags with the foldable, related to engineering problems.
Advertisement
Date
Rumored milestone
Status
Sep 2026
Announcement alongside iPhone 18 Pro and Pro Max
Most Likely
Oct–Nov 2026
Limited availability after a staggered launch
Possible
Dec 2026
Wider availability as mass production ramps up
Contested
2027
Full launch pushed due to hinge engineering failures
Disputed
I think it makes sense, and for one good reason. Releasing the foldable iPhone about three months after the regular iPhone 18 Pro models ship would give customers and Apple stores a chance to catch their breath, and, at the same time, create more hype for the foldable. It would also allow people to make up their mind about spending a fortune on an iPhone that folds in half or settle for the Pro or Pro Max.
How much will the iPhone Fold cost?
On pricing, there’s a rare agreement among the sources: the iPhone Fold won’t be cheap, not by a long shot. Ming-Chi Kuo places the starting price between $2,000 and $2,500, a range that Gurman seems to agree with. However, we’ve also heard rumors about the starting price being less than $2,000.
I believe that a $1,999 starting price could be the sweet spot that is high enough to reflect the technology but just below the psychologically daunting $2,000 ceiling.
The dummy models shared by Sonny Dickson on X in April 2026 make this immediately apparent. Both the cover screen and inner screen are noticeably broader than existing book-style foldables; Apple is clearly charting its own way.
According to Ming-Chi Kuo, the foldable iPhone could come with a 5.5-inch outer display and a 7.8-inch inner screen, both measured diagonally, both featuring an OLED panel. A MacRumors report goes further, citing specific resolutions: 2,088 x 1,422 on the 5.49-inch cover screen, and 2,713 x 1,920 on the 7.76-inch inner panel.
The inner screen could be closer to a 4:3 aspect ratio, as opposed to Fold 7’s 10:9, to better handle side-by-side app multitasking and video consumption without the black bars on the top and the bottom. While the inner screen could get Apple’s ProMotion display technology (up to 120Hz refresh rate), the cover screen could be limited to 60Hz, though that might not sit well with buyers who’re shelling out $2,000 for the smartphone.
yeux1122 / Naver
There should be a punch-hole cutout on the cover screen. The inner screen will also have a front camera, though whether it will be a punch-hole or under-display remains unconfirmed. On the back, the phone might feature a camera visor, similar to the one we’ve seen on the Pixel phones, with a double-camera array toward the left and LED flash and microphone on the right side.
The frame could use a combination of titanium and aluminum. The most important design challenge, for Apple, is the foldable’s crease. On the crease front, Apple reportedly pursued a dual-layer ultra-thin glass structure and a liquid metal hinge to minimize it.
Prototype testing in May revealed a hinge rattling issue, but a follow-up leak on May 19 from DCS claimed Apple had since locked in both the hinge and panel design (via Notebookcheck), with the solution mirroring the near-crease-free approach used on the Oppo Find N6.
Performance and software
Under the hood, the iPhone Fold or Ultra will most likely run on one of Apple’s A20 chips, built on TSMC’s 2nm fabrication process. With more transistors on the chip, the chips could be up to 15% faster and 30% more efficient than the A19 series (via WCCFTech). Whether the foldable gets the regular A20 or the A20 Pro chip remains a point of contention.
AI Visualization
The result could be faster RAM access, leading to better performance, less heat generation, and improved on-device Apple Intelligence performance. For those wondering, the iPhone Fold could ship with 12GB of LPDDR5X RAM, the same amount as the iPhone 17 Pro and the purported iPhone 18 Pro. Storage could span across three tiers: 256GB, 512GB, and 1TB.
9To5Mac
On the connectivity front, we could get Apple’s second-generation C2 modem (same as the iPhone 18 Pro), the successor to the C1X modem on the iPhone 17e, which would also bring mmWave 5G support to the foldable. The device could also be eSIM-only, given the limited internal space.
As I mentioned earlier, the iPhone Fold or Ultra will most likely feature Touch ID instead of Face ID, a compromise that might sting in the beginning, but given that fingerprint authentication is already present on existing iPads, shouldn’t take long to get the hang of.
Advertisement
Out of the box, the iPhone Fold is expected to run iOS 27, and a special version of the operating system no less, which will be built around utilizing the additional screen real estate on the foldable.
Apple
It might sound like iOS 27 for the foldable iPhone is taking a lot of inspiration from iPadOS, after all it’s designed for a bigger-screen iPhone, but the Fold won’t run iPadOS entirely, nor will it support iPad apps out of the box. Apple might make it easier for developers to transition their apps from an iPad to the iPhone Fold, but that would be the extent of it.
Apple should give us a glimpse of iOS 27 at the WWDC 2026, which is also when the public beta of the next operating system should come out. The stable version should ship after Apple concludes the September 2026 event.
Cameras and battery
On paper, the iPhone Fold or Ultra’s camera systems don’t look as good as the iPhone 18 Pro, or the iPhone 17 Pro for that matter, and for a device that might cost twice as much, that isn’t a trade-off worth ignoring.
The iPhone Fold is expected to come with two 48MP sensors on the back, similar to the baseline iPhone 17, one with a wide lens and another with an ultrawide lens. What’s missing here, you might ask? It’s the telephoto lens found on the Pro models, and I think it’s likely due to space constraints in the foldable’s chassis that Apple might not include a dedicated zoom lens.
A November 2025 JP Morgan forecast (via MacRumors) also claimed that Apple might drop the LiDAR module and optical image stabilization on the foldable. While the first might be okay, the second could be a dealbreaker, especially for a smartphone that costs around or over $2,000. If I were to presume, the company will lean on computational photography and the A20’s NPU to compensate for the lack of hardware.
Talking about the battery, the iPhone Fold is rumored to ship with the largest battery on an iPhone, ever. According to Chinese tipster Fixed Focus Digital (via Weibo), the foldable could sport a 5,000 to 5,500 mAh battery, which, if true, could be bigger than the Fold 7’s 4,400 and the Pixel 10 Pro Fold’s 4,821 mAh battery.
The Razr Fold has a 6,000 mAh battery, but Cupertino’s foldable might beat it in terms of usage time, primarily due to better hardware-software optimization and its chip’s superior efficiency. Initial rumors hinted toward the presence of a silicon-carbon battery on the purported foldable, but none of the most credible sources have supported the notion.
Letem světem Applem
Contrary to earlier rumors, the iPhone Fold’s recent pictures, via a leaked case listing (via PhoneArena), suggest that it might feature MagSafe charging after all. However, if that doesn’t happen, the iPhone Fold will be the first high-end iPhone to move out of the production line without MagSafe, since the iPhone 11 Pro, a genuinely baffling omission at $2,000.
Bottom line
The iPhone Fold is shaping up to be one of the most consequential product launches in Apple’s history, and one of the most expensive. While the company might actually achieve a crease-free display and create an ultra-durable foldable that passes the test of time, the compromises are hard to ignore, especially at an asking price north of $2,000. Apple needs to do what the company does best: stick with its core instincts and make the product work at all costs.
To the surprise of nobody at all, people are continuing to abuse prediction markets to make a quick buck. Or according to accusations recently levied against a Google employee, a million quick bucks. Software engineer Michele Spagnuolo has been accused of using insider information from his employer to place bets on Polymarket about common Google search subjects. A federal criminal complaint has charged Spagnuolo with commodities fraud, wire fraud and money laundering. He allegedly earned $1.2 million after betting that the top-searched person on Google for 2025 would be singer d4vd, then tried to hide the source of his sudden windfall.
A Google spokesperson shared the following statement with ABC News regarding the case: “We’re working with law enforcement on their investigation. The employee accessed our marketing material using a tool available to all employees, but using such confidential information to place bets is a serious breach of our policies. We’ve placed the employee on leave and will take the appropriate action.”
Insider trading has been making headlines with some regularity on prediction markets. Everyone from an employee of YouTuber MrBeast to political candidates to military personnel have tried to turn privileged information into money on these platforms. Some people have allegedly gotten up to even stranger hijinks to try and scam the bets. Polymarket adopted new rules in March specifically to cut down on insider trading, but only time will tell whether the policies are effective.
Workplace AI usage has nearly tripled repeatedly across global office environments since 2023
ChatGPT lost significant market share as competing workplace AI tools expanded rapidly
Google Gemini emerged as ChatGPT’s strongest challenger within professional productivity workflows
Workplace AI adoption has entered a phase of extraordinary acceleration across global office environments, as The total time spent using AI tools nearly tripled between 2023 and 2024, then repeated that explosive growth into 2025.
A new report from DeskTime analyzed anonymized data from more than 50,000 users over three years, revealing increasing competition with ChatGPT within workflows.
ChatGPT, which commanded an astonishing 99.91% of all tracked AI time back in 2023, has seen that monopoly shattered considerably, as according to DeskTime, which tracked power users who log at least 26 hours annually, ChatGPT’s share dropped to 74.71% during the first four months of 2026.
This erosion mirrors what earlier internet users saw as Firefox gradually lost ground to newer alternatives.
“With AI, it’s often difficult to separate hype from reality, so DeskTime decided to look into what’s really going on in today’s workplace,” said Artis Rozentals, the chief executive of DeskTime.
“The figures are compelling…AI is fundamentally redefining work, and the risk of falling behind is growing exponentially.”
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Gemini and Claude remains ChatGPT’s major rivals
Google’s Gemini has surged to become the primary challenger among workplace AI tools by capturing 14.38% of office AI time tracked so far in 2026.
Claude has mounted an even more dramatic ascent, now accounting for 8.56% of usage and showing the steepest upward curve this year.
Advertisement
Both rivals have converted casual experimenters into repeat users at a pace that ChatGPT cannot match.
However, Microsoft’s Copilot presents a puzzling contrast, as its share has stagnated at roughly 1% across multiple years.
Neither growth nor collapse appears to characterise this tool’s trajectory within office settings.
Advertisement
Meanwhile, a category of smaller alternatives, including Perplexity and Mistral, has failed to gain any meaningful foothold.
The market for workplace AI agents increasingly resembles a three-horse race rather than a one-player field, and workplace professionals are actively diversifying their toolkits rather than sticking with a single familiar interface.
These figures come from a single productivity tracking service and may not represent a widespread narrative of AI use.
The definition of “AI time” may vary across different job functions and industries in ways that distort competitive comparisons.
Advertisement
Nevertheless, the current trend appears consistent enough to warrant attention from any dominant software provider.
Whether ChatGPT can reverse this decline or will follow Firefox into niche status remains an open question for the remainder of 2026.
Two people in a dinghy get a c loser look at Launchpad, the superyacht docked in Seattle on Lake Union on Wednesday. (GeekWire Photo / Kurt Schlosser)
People saw it on Facebook. And they saw it on Instagram. But many had to come see it up close and in person.
Social media scrollers turned into real-life gawkers on Wednesday as a steady stream of onlookers paused along the western shore of Seattle’s Lake Union to take in Meta founder and CEO Mark Zuckerberg’s superyacht.
No one knew why the $300 million, 387-foot Launchpad was in Seattle. Some wished it wasn’t. Others were pretty thrilled to get a glimpse of the gleaming blue and white vessel, backed into a giant slip along Westlake Avenue North.
Seattle boat salesman Tony Witek grabs a selfie with Mark Zuckerberg’s superyacht in the background. (GeekWire Photo / Kurt Schlosser)
“I’ve been selling boats here in Seattle on Lake Union for 35 years, and I believe this to be the biggest boat I think I’ve ever seen on the lake,” Tony Witek told GeekWire.
The biggest boat Witek has ever sold was about 90 feet long. He called Zuckerberg’s Dutch-built yacht a “personal cruise ship.” Asked how many boats he’d have to sell to afford one like Zuck’s, Witek laughed.
“I think you’d only have to sell this one, and then you could easily go into retirement,” he said.
Advertisement
On a blue-sky May day at lunchtime, the bike and pedestrian trail along the lake was especially busy, and slowed to a pinch point as people stopped to stare, take selfies, FaceTime friends or just ask, “Whose boat is that?”
On the water, people got even closer in dinghies and kayaks — and were warned to stay back by a private security guard from land. A stand-up paddleboarder floated nearby to take pictures. The Argosy Cruises tour boat slowed during a pass by the yacht’s bow. Two electric rental boats did circles as passengers looked up at the towering Launchpad.
Walkers, runners, bikers and others pause and pass by the Launchpad superyacht as seen from the trail along Lake Union. (GeekWire Photo / Kurt Schlosser)
The vessel arrived in Seattle Tuesday night, drawing a similar crowd as it passed through the Ballard Locks. The timing was called less than ideal by some, as Meta cut nearly 1,400 jobs in Washington state earlier in the day.
“The timing of it seems a little distasteful,” said Tim Peterson of Renton. “Probably should have kept it out there in the Sound a little bit longer.”
Peterson said he can’t afford a boat of his own and said he’d be lucky to be able to get a dinghy. He’s not on Facebook, but he is on Meta-owned Instagram.
Advertisement
“I helped pay for it a little bit,” he laughed. “I guess my taxes helped pay for it as well,” he added, lamenting the yacht as a glaring example of excess while many people lack food, housing and healthcare.
“If people have that, then by all means, get you a big old boat,” Peterson said.
A U-Haul box truck is unloaded by workers from the Launchpad superyacht moored on Lake Union on Wednesday. (GeekWire Photo / Kurt Schlosser)
The yacht drew several employees from Meta’s nearby South Lake Union offices. Two engineers said it was interesting to get a sense of the scale of the ship, especially one owned by the head of their company.
“That’s what it’s like to work for a conglomerate,” one of the workers said. The two didn’t want to give their names for fear of being fired.
Steven Redpath, a former Boeing worker, said he used to come to Lake Union to see the aerospace company’s superyacht, Daedalus. The floating corporate entertainment venue was sold for approximately $13 million in 2020.
Advertisement
“Boeing has cleaned up their corporate image and got rid of the yacht,” said Redpath, who took a detour on his bike ride to get a glimpse of Launchpad.
“We bend over backwards for public transportation. We are always looking for solutions to the homeless crisis, and that doesn’t help with either one,” he said, pointing at the yacht. “I think capitalism is letting us down. This is not what our founding fathers were intending to do. This is run amok.”
A float plane takes off from Lake Union above the Launchpad superyacht. (GeekWire Photo / Kurt Schlosser)
Gurneet Takhar, an estate planning attorney in Seattle who spends her time analyzing the money moves of millionaires and billionaires, called the yacht “an interesting asset to own.”
A man piloting a dinghy nearby said he owned a boat on the lake and cruised over to get some size perspective, joking about how many of his boats would fit in the yacht. Another man made a comment about taxes while pointing out the yacht’s Marshall Islands flag, a common registry for large yachts.
And another onlooker, a real estate broker reflecting on the effect of tech layoffs on Seattle and the housing market, called the boat “ugly.”
Advertisement
Deckhands from the yacht could be seen unloading cardboard boxes from a U-Haul box truck parked on the dock. It was tough to tell what was in the boxes — supplies for the stay in Seattle, perhaps. Other workers, including one wiping down parts of the boat, could be seen on decks above.
There was no sign of Zuckerberg.
Ava Pappas shoots a video talking about the big boat behind her on Wednesday in Seattle. (GeekWire Photo / Kurt Schlosser)
Ava Pappas stopped by after seeing a picture of the yacht in her aunt’s Instagram story.
Pappas leads a Seattle run club called Cool Down Running that runs from the Center for Wooden Boats in South Lake Union up to the Fremont Bridge and back on Wednesday nights.
She planned to make a stop with the group mid-run.
Advertisement
“It’s insane. Most people don’t understand the caliber of this megayacht,” Pappas said. “It’s definitely just a treat to be able to see it in person. It’s a beautiful boat, and I love just kind of looking at it in awe.”
Check out more GeekWire images:A kayaker who owns a boat nearby said he cruised over to get a look at the superyacht on lake Union. (GeekWire Photo / Kurt Schlosser)A worker scrubs part of the superyacht while it’s docked on Lake Union on Wednesday. (GeekWire Photo / Kurt Schlosser)A sailboat in a neighboring marina is dwarfed by Launchpad. (GeekWire Photo / Kurt Schlosser)A paddleboarder floats near Launchpad taking close-up photos. (GeekWire Photo / Kurt Schlosser)
The Steam Deck OLED 512GB variant has risen from $549 to $789, while the 1TB model has climbed from $649 to $949. The entry-level LCD Steam Deck, which had anchored the lineup at $399, has been discontinued entirely. Competitive pricing was one of the Steam Deck’s most unexpected strengths when… Read Entire Article Source link
In the months leading up to the implementation of Australia’s social media ban in December 2025, there was much discussion about the possible negative consequences.
Among these were concerns that teenagers would consume less news. As most young adults use social media for news and many rely on it, this was a real risk.
So months on, has this come to pass? In our newly-published research, we found the more young people are impacted by the ban, the more likely they are to report they are getting less news and having less opportunity to discuss news and the issues that matter to them.
Advertisement
Our research
In February we surveyed 1,027 young people aged 10 to 17, just two months after the legislation took effect.
First, we investigated if the ban had affected young people’s social media use by asking them if their engagement with each banned platform had changed at all, and if so, whether the change was a complete stop or if they just used it less.
We found 61% of under-16s who had previously been using banned platforms reported little or no change in their social media use. For the majority of young people surveyed, the ban was ineffectual.
Advertisement
In fact, only one in four (26%) reported their social media use had been affected.
Next, we asked young people if the ban had affected their engagement with news.
For those whose social media use was significantly disrupted, the result was stark: 51% reported getting less news as a direct result of the ban.
Advertisement
This finding is a significant concern because it suggests that as the ban becomes more “successful”, with a greater number of young people being removed from platforms, their news engagement will fall in parallel.
The impact on civic involvement
A 2025 report from the Australian Curriculum, Assessment and Reporting Authority, based on testing of year 6 and year 10 students, finds school students’ civics knowledge is the lowest it has been since testing began 20 years ago. This is despite most young people believing it’s important to take action in the community on issues that matter to them.
Our findings show that when young people are impacted by the social media ban they lose access to news about issues they care about. They are also talking less about news and finding fewer opportunities to share their views or take other forms of action.
Advertisement
Our previous research shows news engagement makes young people feel knowledgeable and more capable of responding to issues.
A large body of research also shows news interest and engagement is closely associated with civic engagement. The more engaged people are with news, the more likely they are to become involved in community and social issues.
Social news or no news
It’s unlikely that being cut off from news on social media will lead young people back to traditional news sources.
Advertisement
Most young Australians say they don’t feel represented or heard by traditional news organisations. They also feel the news mainstream outlets create isn’t accessible to young people and doesn’t focus on the issues that matter most to them.
In our survey, 75% said news organisations have no idea what their lives are actually like, and 71% said they find it difficult to find news relevant to people their age.
Our earlier research also shows Australian news organisations rarely include young people in news stories. When they are included, they are seen but not heard.
For instance, young people are shown in news stories in photographs and video footage ten times more than their voices are heard or they are quoted in stories.
Advertisement
In addition, another study of news has shown that when young people are included in breaking news events, they are often stereotyped as being lazy, dangerous and entitled.
These findings demonstrate some of the reasons young people have likely turned to social media for news in recent years.
So what should we do?
It’s likely that over time, more young people will be cut off from social media as loopholes in the ban are ironed out. This emphasises the need to find ways to encourage young people to engage with other news sources in productive and meaningful ways.
A key concern is trust. We need to educate young people about the importance of news to democratic process, providing them with insights into how high quality journalism is produced and supporting them to make informed decisions about who and what to trust online.
Advertisement
This can happen as part of media literacy education but this requires investments in high quality curriculum resources and teacher training.
In Australia, we are in the fortunate position that we already recognise the need for media literacy in the Australian curriculum. High quality news literacy resources are being produced by the ABC through programs such as BTN (Behind The News), and other organisations such as Squiz Kids.
At the same time, to develop trust, mainstream news organisations need to do a much better job of representing young people in fair and inclusive ways so they feel seen and heard.
Finally, it’s important to recognise that amid all of these changes to young people’s technology access, our research shows family is the first and most trusted source of news for young people. We need to help parents understand the important role they play in helping their kids navigate the news.
Dataware house gambles cloud conveniences, AI accelerated insights will justify the cost.
Cloud data warehouse Snowflake plans to spend $6 billion on Amazon’s custom Graviton CPUs and AI accelerators over the next five years.
The collab aims to reduce friction in connecting Snowflake customer data with a growing number of AI services built atop AWS’ cloud infrastructure.
Advertisement
“We are making it easier for enterprises to bring AI directly to governed data, so they can move faster, operate with greater density and create measurable impact at scale,” Snowflake CEO Sridhar Ramaswamy said in a canned statement.
Snowflake is a long-time AWS customer, having built the company atop the cloud titan’s servers going back to 2011. Over the past few years, Snowflake has shifted an increasing amount of compute from Intel and AMD CPUs to Amazon’s own Arm-based Graviton instances.
Now in their fifth generation, Amazon’s latest Graviton processors cram 192 Arm Neoverse V3 cores which are fed by 12 channels of memory up to 8800 MT/s.
As we’ve previously reported, CPUs are back in the spotlight again after years of being overshadowed by GPUs and other AI accelerators.
Advertisement
The models themselves still run on GPUs, but the tools and functions those models call — a SQL query or Python script, for example — do not. Those workloads still rely on CPUs.
This has driven renewed demand for CPU cores as each agent’s performance is inherently limited by how quickly the processor can service the request.
Under the agreement, Snowflake will run and train its GenAI models and services using a combination of GPUs running in AWS and Graviton CPU cores. For example, Snowflake says that its Cortex AI platform can convert natural language to SQL queries, summarize data, and conduct sentiment analysis.
According to Amazon, Snowflake’s lifetime AWS marketplace sales crossed $7 billion and exceeded $2 billion during the 2025 calendar year. Clearly the data warehousing platform is betting these AI tools will continue to drive revenues enough to justify splashing $1.2 billion a year on additional infrastructure.
Advertisement
Gamble or not, Wall Street doesn’t seem to worried, with Snowflake rallying by more than 30 percent in after hours trading Wednesday.
Snowflake isn’t the only company diving deeper into Graviton’s orbit. Back in April, Meta revealed plans to deploy tens of millions of Amazon’s Graviton 5 CPU cores. The multi-year collaboration was expected to make the social network one of the biggest consumers of AWS’ homegrown silicon.
Much like Snowflake’s $6 billion investment in Amazon’s infrastructure, Meta’s cloud spend is largely aimed at securing cores for AI agents.
But unlike Snowflake, which for better or worse remains heavily reliant on AWS for compute, Meta’s tie up may only be a stopgap while it awaits Arm’s buzzword-packed AGI CPUs. ®
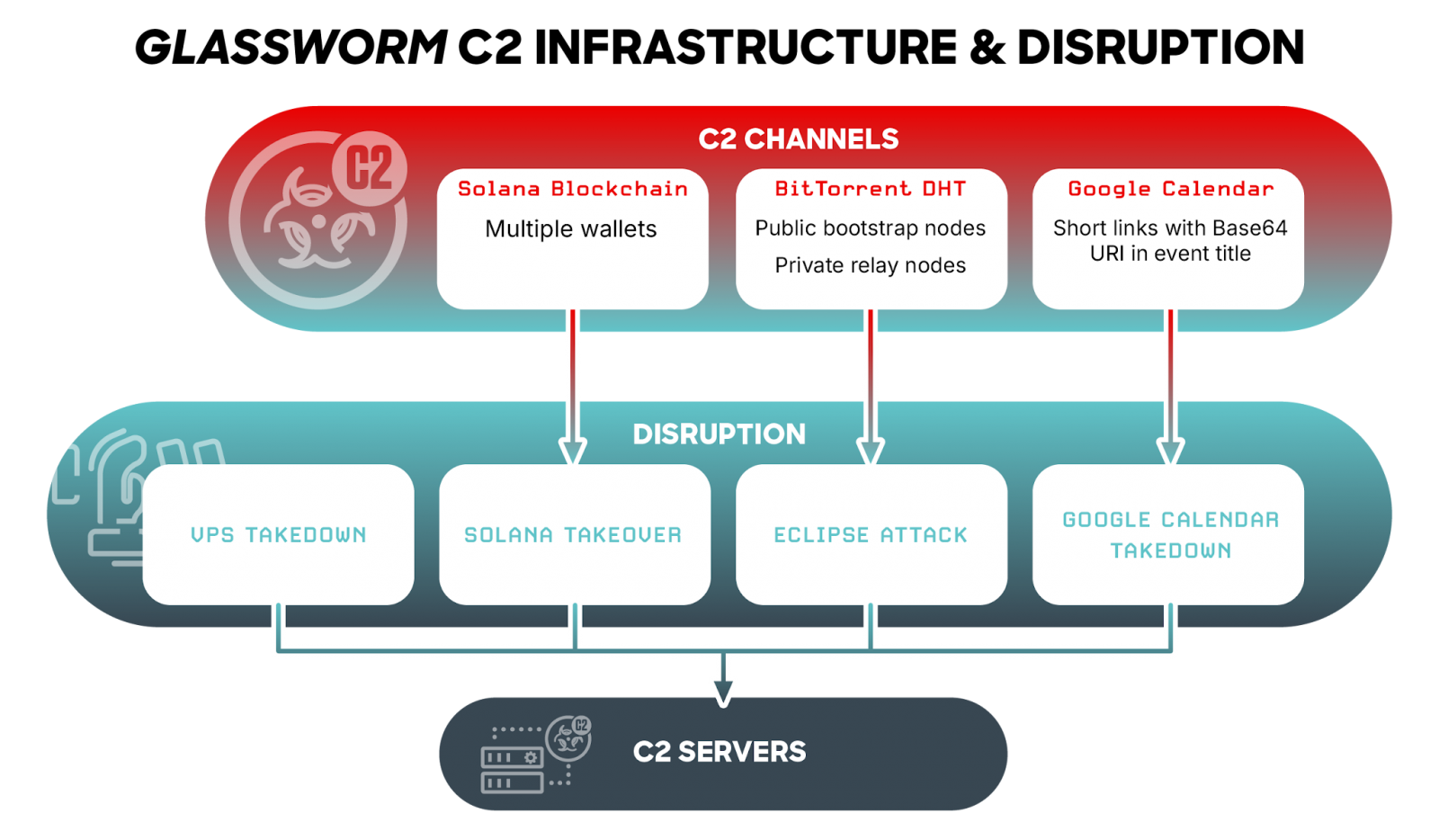
The Glassworm botnet targeting developers in software supply-chain attacks has been disrupted after researchers took down its resilient command-and-control infrastructure relying on Solana blockchain transactions and the BitTorrent DHT network.
In a coordinated operation conducted yesterday, CrowdStrike, Google, and The Shadowserver Foundation cut off the botnet operators’ access to four distinct command-and-control (C2) channels designed to resist conventional disruption efforts.
Glassworm campaigns have been ongoing since October 2025 and initially targeted developers with malicious OpenVSX and Microsoft VS Code extensions that stole cryptocurrency wallets and developer credentials.
One reason the Glassworm threat has survived this long is its C2 infrastructure, which relies on non-traditional communication channels that are difficult to take down.
“The combination of blockchain, peer-to-peer, and legitimate web services as resolution layers was designed to be resilient against takedowns — a dynamic front protecting the actual C2 servers behind multiple layers of indirection,” CrowdStrike notes.
The researchers say that “Glassworm’s operators built their infrastructure for resilience,” and taking down the botnet required hitting the four C2 channels simultaneously:
Advertisement
Solana blockchain: C2 server addresses are encoded in the memo fields of blockchain transactions, creating an immutable, publicly accessible dead drop that cannot be taken offline by conventional means.
BitTorrent Distributed Hash Table (DHT): The GlasswormRAT queries the BitTorrent peer-to-peer network for configuration data stored against hardcoded public keys, leveraging a global decentralized network with no single point of failure.
Public calendar service: Glassworm uses Google Calendar event titles as dead-drop locations for Base64-encoded C2 paths.
Direct server connections: Traditional C2 infrastructure hosted on commercial VPS providers served as the final payload delivery mechanism.
Because of this architecture, disrupting a single channel would have little impact on the Glassworm operation, as communications could shift to another channel, allowing the threat actor to maintain control.
“All four channels had to be disrupted simultaneously in a coordinated effort. As a result, infected machines can no longer receive new instructions or payloads,” CrowdStrike says.
Following the disruption, all machines compromised in a Glassworm attack are beaconing to the IP address 164.92.88[.]210 operated by CrowdStrike.
Organizations are advised to look for this network indicator and take immediate remediation action. Additionally, the researchers have published YARA rules to confirm infections on suspected hosts.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.












































































You must be logged in to post a comment Login