A security researcher has released exploit code for a Visual Studio Code (VS Code) zero-day vulnerability that allows attackers to steal GitHub authentication tokens by tricking users into clicking a link.
As researcher Ammar Askar explained in a blog post on Tuesday, this VS Code vulnerability allows attackers to install malicious extensions that steal GitHub OAuth tokens when they are passed to github.dev (a browser-based version of Visual Studio Code used to work on GitHub repositories) by exploiting VS Code’s sandboxed webview message-passing system.
The proof-of-concept exploit he also released on Tuesday abuses this system by running malicious JavaScript inside a webview to simulate keypresses in the main editor and install an extension that extracts the GitHub OAuth token sent to github.dev and queries the GitHub API to enumerate all private repositories the victim can access.
“This functionality is achieved by github.com POSTing over an OAuth token to github.dev that allows it to interact with GitHub on your behalf,” Askar said. “The token is not scoped to the particular repo you interacted with, meaning it has full access to every other repo that you have access to.”
Advertisement
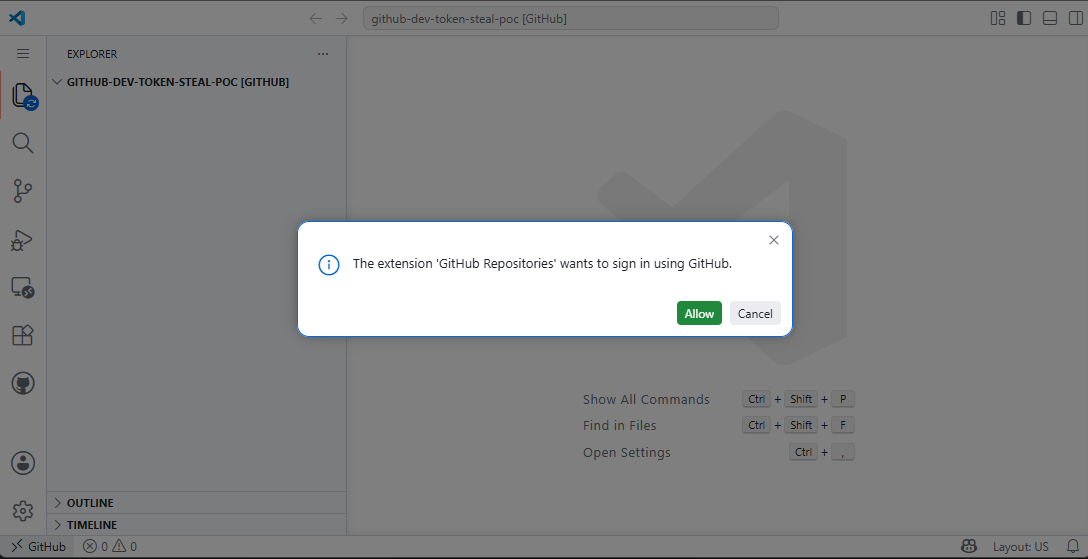
While the vulnerability is not yet patched and has not yet been assigned a CVE ID, VS Code users can protect themselves by clearing cookies and local site data for github.dev in their browser by clicking the Settings icon in the URL bar, and then going into Cookies and site data > Manage on-device site data.
This will ensure that they will get a “The extension ‘GitHub Repositories’ wants to sign in using GitHub.” warning when clicking on links attempting to exploit this flaw.
github.dev initial sign-in dialog (Ammar Askar)
Askar said they notified GitHub one hour before disclosing the bug and noted that they chose immediate public disclosure due to a prior negative experience with Microsoft’s security response process, in which a previously reported VS Code bug was silently fixed without credit or acknowledgment of the security impact.
“That was mostly a courtesy to GitHub, the intent here was full public disclosure. In my past experience reporting github.dev bugs to them, they tell you that it’s out of scope and go report it to MSRC. And as I outlined in the article, I really don’t want to deal with MSRC on VSCode bugs,” he added.
“To summarize the last time I interacted with MSRC regarding reporting a VSCode bug, it was a horrible experience where they silently fixed ‘the bug I pointed out without any credit. They also marked it as not having any security impact.
Advertisement
“As I mentioned in that post, going forward I would be doing full public disclosure for any security bugs I found in VSCode.”
This follows another stream of zero-days in various Microsoft products disclosed by an anonymous security researcher using the ‘Nightmare Eclipse’ online handle who also expressed his discontent with how the Microsoft Security Response Center (MSRC) handles the disclosure process.
Over the past several months, Nightmare Eclipse disclosed the BlueHammer, RedSun, GreenPlasma, and MiniPlasma privilege escalation zero-day flaws (the first two now being exploited in attacks), YellowKey (a Windows BitLocker zero-day that grants access to protected drives), and UnDefend (another zero-day that can be exploited to block Microsoft Defender definition updates).
Initially, Microsoft reacted to Nightmare Eclipse’s zero-day leaks with threats of legal action, followed by a tweet stating it would work “with law enforcement as appropriate” when “an individual breaks the law and engages in malicious activity causing real harm to our customers.”
Advertisement
BleepingComputer reached out to Microsoft for a comment on the VS Code zero-day flaw disclosed by Askar, but a response was not immediately available.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
Control Resonant launches globally on PS5 on September 24, and Remedy is making a cleaner break from the first game than a new city alone would suggest. Dylan Faden, not Jesse, is the playable character this time.
That choice gives the sequel a sharper charge. Dylan was once treated as a threat, but Control Resonant puts him at the center of a story about power, damage, and the bond that still ties him to Jesse.
Why put Dylan in control now
Dylan gives Control Resonant a way back into the Faden story without replaying Jesse’s rise through the Federal Bureau of Control. He carries a different kind of history, one shaped less by discovery than by fallout.
Sony
The change also reaches into combat. Dylan uses the Aberrant, a shapeshifting weapon built around aggressive close-range action, which gives him a different rhythm from Jesse and her Service Weapon.
That helps the handoff feel more intentional. Remedy isn’t simply changing the face on screen. It’s giving players a new body language for the same haunted universe.
Advertisement
What changes when Jesse steps aside
Jesse’s arc was about forcing answers out of a hostile institution. Dylan begins from a more damaged place, with the consequences of that world already written into him.
That puts Jesse and Dylan’s unresolved history under real pressure. Jesse is still part of the frame, but Dylan carrying the playable perspective forces the sequel to face the damage between them instead of leaving it on the edge of the lore.
Sony
The warped Manhattan setting gives that conflict more room to breathe. Moving beyond the Oldest House lets Remedy expand the threat while keeping the Faden family wound close to the action.
What should players watch next
Pre-orders are open now, but the bigger question is how Remedy handles the handoff from Jesse to Dylan. The risk isn’t that Dylan lacks story potential. It’s whether Control Resonant can make his central role feel earned without flattening Jesse’s importance.
The PS5 Digital Deluxe Edition includes 48-hour advance access, so some players can start on September 22 instead of September 24. Everyone else should watch the same thing when launch arrives, whether Dylan Faden can carry the emotional weight the first game left unresolved.
The UK’s Competition and Markets Authority has imposed binding rules on Google’s search services in a move it calls a world first.
The UK’s competition regulator has formally required Google to let publishers opt out of having their content used to power AI features in search, including its AI Overviews product.
The Competition and Markets Authority (CMA) imposed the conduct requirement today (3 June) under the UK’s digital markets competition regime, making it the first binding ruling of its kind to be issued against a major tech platform in the UK.
Following consultation feedback, publishers will also be able to opt out of their content being used for the fine-tuning of Google’s AI models, giving them control over the full range of AI use cases of their content. Google will also be required to attribute publisher content clearly, using links, in AI-generated search results.
Advertisement
The CMA said the requirement would put publishers, including news organisations, in a stronger position to negotiate content deals with Google.
The ruling follows Google’s designation in October 2025 as having strategic market status in UK search, a formal finding of substantial and entrenched market power that gave the CMA the power to impose targeted rules on the company.
The CMA said it was also responding to Google’s announcement in May that it planned significant changes to its search platform to further embed AI technologies, which the regulator said could fundamentally change how search results are presented to UK users. Today’s requirement will apply to those changes.
“Today, we have introduced a world-first requirement on Google’s search services in the UK, enabling fair treatment, greater transparency and meaningful choice for businesses and consumers,” said Sarah Cardell, CEO of the CMA.
Advertisement
“With features like AI Overviews rapidly reshaping online search, it is crucial that content publishers, including news organisations, have appropriate bargaining power over how their content is used.”
A spokesperson for Google pointed siliconrepublic.com to its official blog post reaction to the announcement, saying it would begin testing a new toggle in Search Console allowing website owners to decide whether their content appears in AI Overviews, AI Mode and related features. Sites that opt out will not receive traffic or impressions from those features, Google said, and the setting will not affect rankings in standard search results.
The company also said it would roll out new performance insights in Search Console showing publishers which of their pages appear in AI responses and in which countries.
Google said it would begin the rollout to a subset of website owners in the UK first, “allowing for thorough testing before rolling them out to website owners globally”.
Advertisement
The blog post, written by Mrinalini Loew, general manager of Google Search Ecosystem, did not directly address the CMA’s ruling but framed the changes as part of Google’s own initiative to give website owners more control as user behaviour shifts toward AI-powered search. Google said AI Overviews now has over 2.5bn monthly active users and AI Mode has surpassed one billion.
Google has nine months to implement all required changes under the CMA’s conduct requirement, though the regulator said it expects the key publisher controls to be available well before that deadline. Google must submit compliance reports every six months in the first year, backed by data and metrics.
Cardell confirmed that further action in relation to Google’s search business would be announced in the coming weeks. The CMA said it has now launched four strategic market status investigations into major tech companies since the digital markets regime came into force last year, covering Google, Apple and Microsoft.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Microsoft announced today at its Build 2026 developer conference the release of Coreutils for Windows, bringing many commonly used Linux command-line utilities to Windows as native applications.
The project is based on the open-source uutils project, a cross-platform rewrite of the GNU coreutils in Rust, and is designed to make it easier for developers to switch between Linux, macOS, Windows, and Windows Subsystem for Linux (WSL) without changing workflows.
“Developers constantly move between platforms, but familiar commands don’t work consistently, forcing workarounds, lost speed and context switching,” announced Microsoft.
“To address this, we’ve built Coreutils for Windows from the uutils open-source project, a cross-platform reimplementation of GNU Coreutils in Rust. These are Linux-like command-line utilities that run natively on Windows.”
According to Microsoft, the goal is to make existing commands and tools work across platforms so that scripts can be used on Windows without modification or other tools.
Advertisement
The Coreutils for Windows project has also been released on GitHub as a Microsoft-maintained package that combines uutils/coreutils, findutils, and a GNU-compatible grep implementation into a single binary.
Linux utilities running natively on Windows
Coreutils for Windows includes numerous commands commonly used in Linux, such as cat, cp, find, grep, hostname, ls, mv, pwd, rm, sleep, tee, and uptime.
The utilities can be installed through WinGet using the following command:
winget install Microsoft.Coreutils
Rather than creating separate executables for each program, Microsoft created a single coreutils.exe binary that contains all the functionality of each program.
Advertisement
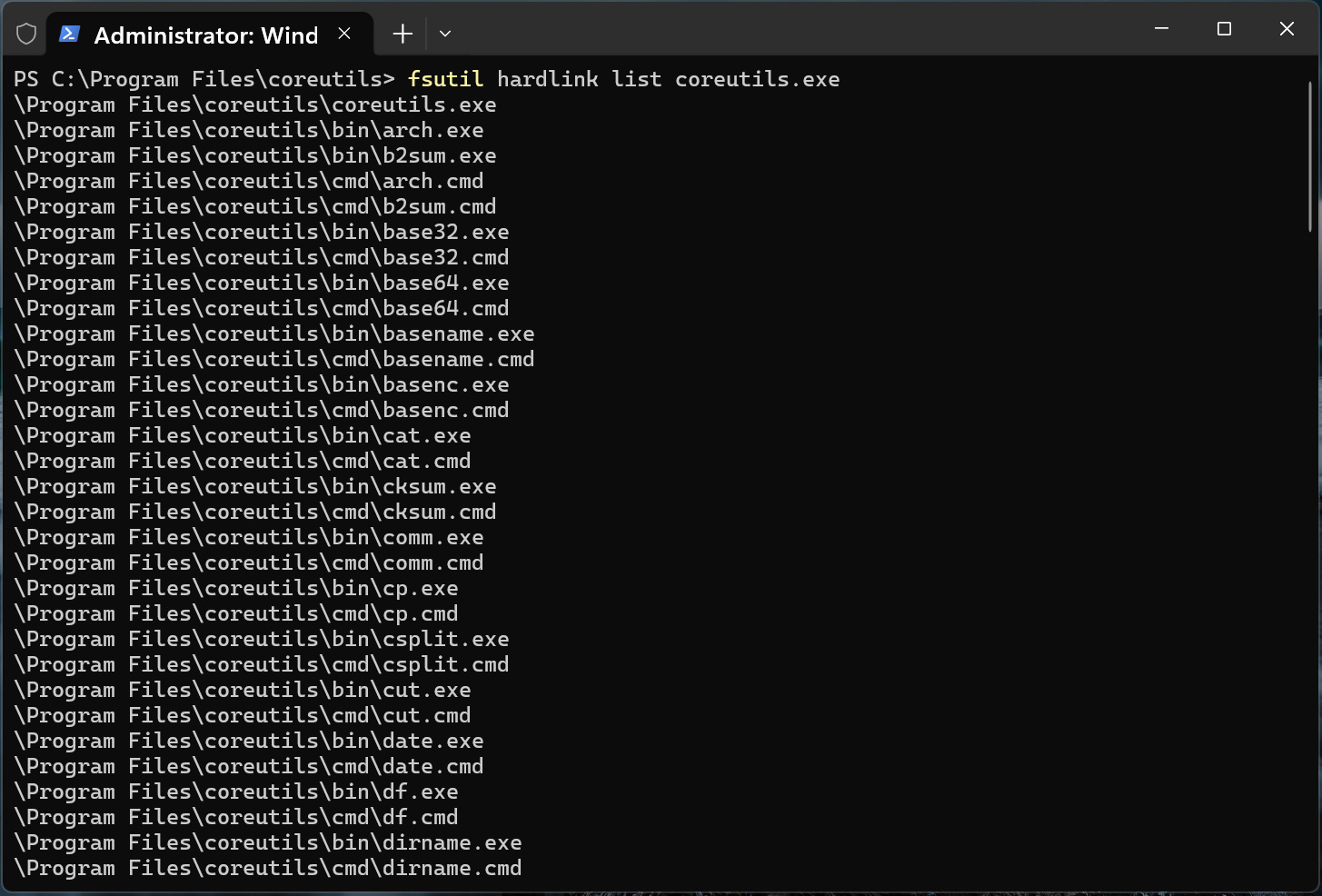
When Coreutils for Windows is installed, the setup creates NTFS hardlinks for each supported command, such as ls.exe, cp.exe, cat.exe, and rm.exe, that all point to the c:\Program Files\coreutils\coreutils.exe executable.
When a user launches one of these commands, Windows loads coreutils.exe, which determines which utility to run based on the name of the command that was executed. This allows Microsoft to maintain a single executable while still providing individual Linux-style commands.
Running fsutil hardlink list coreutils.exe shows dozens of command names, including cat.exe, cp.exe, cut.exe, base64.exe, and others, all referencing the same file on disk.
Coreutils using NTFS hardlinks to map commands to binary
As many Linux command names conflict with existing Command Prompt and PowerShell commands, Microsoft shared a compatibility table showing how each utility behaves in different Windows shells.
For example, commands such as ls, cat, cp, mv, rm, pwd, sleep, and tee are included with the package.
Advertisement
However, whether the Coreutils version is executed depends on the shell being used, the order of directories in the system PATH, and the PowerShell alias table.
Other commands, including dir, more, paste, and whoami, are not shipped because they conflict with existing Windows commands.
Microsoft also did not release several popular Unix utilities that rely on POSIX functionality, which is unavailable on Windows, including chmod, chown, chroot, nohup, tty, and who.
The company says they also did not release the ‘kill’ or ‘timeout’ commands, as Windows does not support POSIX signals, though this may be possible in the future.
Advertisement
Microsoft also warns that there may be differences between Linux functionality and how commands work in Windows due to differences in line feeds, file permissions, and POSIX support.
Coreutils for Windows was announced as part of Microsoft’s strategy to make Windows a developer-friendly platform.
During Build 2026, the company also announced WSL containers, which will provide a built-in way to create, run, and interact with Linux containers on Windows using native CLI and API tools.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
Megaport spent a decade as a company you used to connect to other people’s clouds. On Wednesday it announced a plan to become one. The Australian networking firm secured four new AI infrastructure contracts worth a combined A$458.9M (about $329M) and launched a fully underwritten entitlement offer to raise A$827.3M (about $594M), according to its filing. The money funds a pivot from plumbing to compute.
The contracts come first. All four are with US-based technology providers running AI applications, are expected to start in the first half of 2027, and require nearly A$369.5M in capital expenditure, mostly for high-performance Nvidia GPUs alongside network and storage. That is a meaningful commitment for a company of Megaport’s size, and it explains why the raise is so large relative to the business.
What the capital is really buying is the strategy behind the contracts. Megaport says it will build a globally distributed AI inference cloud, anchored by an on-demand GPU pool backed by about A$350M in investment and offered to enterprise customers on both contracted and consumption-based pricing.
The pool is to be deployed across the company’s existing footprint of more than 1,100 connected data centres in 31 countries, with rollout over the next six to nine months.
Advertisement
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The bet is geographic. Most GPU capacity today sits in a handful of enormous data centres optimised for training the largest models. Megaport is targeting the other half of the AI workload: inference, the act of running a trained model to answer a query, which benefits from being close to the user.
Its pitch is that a distributed network of smaller GPU pools, spread across the data centres it already connects, fits inference better than centralised mega-campuses, and slots into the gap between hyperscaler clouds and single-location GPU specialists.
Advertisement
It is a credible reading of where AI infrastructure is heading. As models move from research demos into products embedded in real applications, the economics shift from training to serving, and serving rewards proximity and distribution.
Megaport already owns the network that links the locations where that compute would live, which is a genuine structural advantage if the thesis holds.
The numbers around the raise were briefly muddled across early coverage, which is worth untangling. The four contracts are worth A$458.9M in total contract value; the capital raise is A$827.3M; the GPU pool commitment is about A$350M.
Several headlines collapsed these into a single figure. They are distinct: contract wins, the money to fund them, and the specific compute investment inside that money.
Advertisement
Megaport also tightened its 2026 revenue guidance to A$307M–A$315M and projected combined group pro forma annual recurring revenue of A$662.9M once the compute division is folded in. The shares were halted while the raise was arranged, a standard mechanism for a deal of this scale on the ASX.
The risk is the obvious one for any company spending heavily on Nvidia GPUs on the strength of contracts that begin in 2027: that AI infrastructure demand, and pricing, may look different by the time the hardware is installed and earning.
Megaport is committing capital now against revenue that lands later, in a market moving fast enough that 18 months is a long time. The contracts give it a floor. The inference-cloud ambition is the part that has to compound, and that is the part the A$827M is really betting on.
We’ve seen just about every possible way to make a clock here at Hackaday over the years. So it’s rare to have a first, but here we are with [Twisted & Tinned], who’s made a novel clock with a diffraction grating.
The display of the clock looks for all the world like a jumble of LEDs, that is, until you place the grating in front of it. Those LEDs are addressable multi-color parts, and each digit is generated at a different color all on top of each other. The grating splits out these colors, resulting in a magical set of floating LED figures.
Behind those LEDs is a Pi Pico, but that’s just one of many microcontrollers that could have powered this project. It’s the use of the diffraction grating in a novel way with those LEDs that makes the difference, and we rather like it. He’s also managed to get the grating pattern in the 3D printed surround for a shimmering look, by printing directly onto a diffraction grating sheet. That in particular is a technique we’ve looked at before in detail.
The Trump administration is moving to dismantle the National Science Foundation’s $368 million Ocean Observatories Initiative, a network of more than 900 deep-sea instruments used to monitor ocean currents, marine ecosystems, carbon absorption, heat waves, fisheries, coastal flooding, and climate change. The NSF said it would send ships in June to begin the removal of the instruments anchored off Oregon, Washington, Alaska, North Carolina, and an area between Greenland and Iceland known as the Irminger Sea. The New York Times reports: The ocean observation system began operating in 2016 and was expected to continue for 25 years. Jim Edson, a marine meteorologist who led the Ocean Observatories Initiative, called it “the world’s most advanced continuously operating ocean observing systems.” When it was first proposed, the science foundation said it was important to have a long-term presence at scientifically important sites in the Atlantic and Pacific oceans. Removing the instruments could take 15 months. Seismic instruments positioned around an active underwater volcano off Oregon will continue operating until 2028.
Each observation station consists of several moorings that secure long arrays of devices connected to wires. The devices measure ocean currents as well as chemical and biological conditions from the water’s surface down thousands of feet. The instruments were hardened to resist the pressure of the deep ocean, corrosive seawater as well as marine plants and animals that can foul electronics. Remotely controlled robotic vehicles and gliders around the moorings collect and transmit data to research laboratories.
It cost $48 million annually to operate the network. The Trump administration repeatedly tried to shutter it, proposing to cut its funding by 80 percent in both 2025 and again in 2026. Congress pushed back, restoring the money. To try to reduce costs, managers turned off some of the instruments and collected less data, according to a December 2025 presentation about the observatories at the annual meeting of the American Geophysical Union, a nonprofit organization of scientists. Still, the science foundation moved ahead to decommission the observatory network.
Healthcare cybersecurity in 2026 is defined less by novel attack techniques than by a widening gap between which controls organizations report having and which controls are reducing loss.
Our portfolio data from 2023 through mid-2025 shows that social engineering, backup gaps, and weak data governance drive the majority of material losses in healthcare claims.
Si West
Director of Customer Engagement at Resilience.
The headline numbers already tell part of the story. U.S. healthcare organizations reported 275 million records breached in 2024, more than double the prior year and the largest single-year exposure in the sector’s history.
Latest Videos From
Ransomware attacks against healthcare climbed 32 percent over the same period, and the Change Healthcare incident alone exposed an estimated 190 million individuals.
Advertisement
The useful question for CISOs, CFOs, and boards is not how big the breaches got. It is what claims data reveals about which threats are driving losses and which investments are measurably reducing them.
What is driving healthcare cyber losses right now
Social engineering drove 88 percent of material losses across our portfolio in the first half of 2025, and healthcare-specific claims followed the same pattern. Phishing, business email compromise, and vendor compromise show up repeatedly in the underlying incident data, alongside backup gaps that leave organizations exposed when ransomware lands and tracking pixel errors that quietly expose patient information.
The threat actor landscape is also more distributed than the most visible groups suggest. While BlackCat and Cl0p appeared most frequently in healthcare-related activity, the actual successful intrusions were spread more evenly across operators like Interlock, Lockbit, and Medusa. That distribution matters for defenders, hardening against the loudest names while remaining exposed to lesser-known operators is a specific failure mode the data keeps surfacing.
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Extortion demands have also climbed. In the first half of 2025, healthcare-related incidents in the portfolio carried extortion demands as high as $4 million. Those costs carry a different weight when patient care is at stake and the alternative to paying is not just operational disruption but clinical risk.
Which cybersecurity controls reduce risk in healthcare
Five controls show the highest measurable risk reduction in healthcare environments in our portfolio: secure email gateways, immutable backups, multi-factor authentication on all remote access, formal data governance, and regular tabletop exercises that include clinical operations. None of these are exotic, and most healthcare organizations can implement them without a transformational budget request.
Advertisement
Two findings in the portfolio data stand out as specific to healthcare. Immutable backups deliver stronger risk reduction in healthcare than in other industries on average, largely because ransomware against clinical systems creates a different recovery calculus than ransomware against, say, a manufacturer’s ERP software. And organizations with a formal data governance committee see more than three times the risk reduction compared to peers in other sectors, a reflection of how much of healthcare’s exposure lives in the data layer itself, not just the endpoint.
The pattern matters more than any single control. Every control on the list operates before or during an incident, not after. That is where the measurable risk reduction lives.
Advertisement
Why the budget conversation keeps breaking down
Healthcare CISOs face a specific version of a universal problem: the controls with the highest modelled risk reduction are often the least visible to executive leadership, and the controls most visible to executive leadership are often the ones with the weakest loss-reduction signal. That asymmetry is what quantifying cyber risk is meant to close.
In practice, the healthcare organizations getting ahead on this are doing three things. They are translating control adoption into dollar terms their CFO can evaluate against other capital decisions. They are prioritizing spend against the specific controls the claims data identifies as high-ROI in their sector, rather than defaulting to a framework checklist. And they are running tabletop exercises that include clinical leadership, not just IT, because the decisions that determine whether a ransomware event becomes a patient-care event are not purely technical.
What this looks like in practice
Two contrasting examples from our portfolio make the point. A mid-sized regional health system believed its security posture was stronger than it turned out to be and discovered the gap the hard way during a major ransomware incident, including the discovery that clinical imaging files had been left out of its backup strategy. Recovery costs, regulatory exposure, and care disruption compounded.
Advertisement
A mid-market biotechnology firm took a different path. It built a quantified, prioritized cyber risk program, mapped its controls against its largest modelled loss scenarios, and was able to redirect security spending toward the controls with the highest return. When an attempted business email compromise hit, the controls worked, and the claim never materialized.
The gap between those two outcomes was not budget. It was how each organisation decided what to spend the budget on.
What healthcare security leaders should do now
Three moves are defensible, specific, and available without a transformational program. First, audit the organization’s backup posture against a realistic ransomware scenario, including clinical systems and imaging data, not just administrative files. In our portfolio, backup gaps are one of the single largest drivers of healthcare ransomware severity.
Advertisement
Second, measure social engineering resilience directly. Tabletop exercises, phishing simulations, and control reviews of email gateway posture are faster to run than most organizations assume, and social engineering’s share of material loss makes them high-ROI by any reasonable measure.
Third, translate the top three or four risk scenarios into dollar terms and walk them to the board. The CFO conversation goes differently when the ask is framed as loss reduction, not technology spend. Risk quantification is what makes that reframe defensible.
This shows the need for risk quantification on plausible material loss scenarios; without it, budget conversations stay abstract while the exposure stays real. It requires a willingness to let the claims data, rather than the vendor roadmap, set the priority list.
This article was produced as part of TechRadar Pro Perspectives, our channel to feature the best and brightest minds in the technology industry today.
The views expressed here are those of the author and are not necessarily those of TechRadarPro or Future plc. If you are interested in contributing find out more here: https://www.techradar.com/pro/perspectives-how-to-submit
One billion is the number apps spend years chasing and most never reach. ChatGPT got there faster than anything before it. OpenAI’s app crossed 1 billion global monthly active users in May, roughly three years after launch, according to estimates from Sensor Tower, making it the quickest app in history to the milestone.
The pace is the point. ChatGPT reached a billion monthly users faster than Google Maps, TikTok, Instagram and YouTube, products that defined consumer software in their eras. The comparison flatters ChatGPT and also says something about the moment: AI assistants have moved from novelty to default habit in a span that earlier categories measured in many more years.
A caveat belongs up top, because the figure is an estimate. The billion comes from Sensor Tower’s market intelligence, not from OpenAI’s own audited disclosure, and counts monthly active app users rather than total users across web and API.
The order of magnitude is widely corroborated; the precise number carries the usual uncertainty of third-party measurement, and is worth citing as an estimate rather than a reported fact.
The milestone lands in the middle of an intensifying contest with Anthropic. By the same Sensor Tower reckoning, Anthropic’s Claude app had about 56 million global monthly active users, a fraction of ChatGPT’s base, but growing at roughly 640% year on year.
Advertisement
The two numbers tell different stories: ChatGPT owns the consumer mass market, while Claude is growing fast from a smaller base, with particular strength among developers and in coding.
That split runs through the rest of the rivalry. OpenAI has leaned into consumer scale and prosumer subscriptions, recently launching a $100 ChatGPT Pro plan pitched directly at Claude’s power users.
Anthropic has built a formidable enterprise and developer business, crossing $30bn in annualised revenue and attracting investor offers at an $800bn valuation. Raw app users are one scoreboard; revenue and developer loyalty are others, and the two companies lead on different ones.
What a billion users buys OpenAI is distribution, the asset that turned earlier consumer-software winners into durable franchises. Reach at that scale compounds: more usage generates more data, more feedback and more pricing power, and it sets the default that competitors have to dislodge rather than merely match.
Advertisement
For a company spending heavily on compute and racing to convert free users into paying ones, a billion monthly actives is the top of a funnel nobody else has built.
The harder question is what the number is worth. Monthly active users are not paying users, and the economics of AI remain punishing: inference is expensive, free usage is a cost rather than a revenue line, and OpenAI’s challenge is converting a vast audience into a sustainable business before the spending catches up with it.
A billion people trying ChatGPT is a triumph of adoption. A billion people paying for it would be a different milestone, and the one that actually matters.
For now, the record stands on its own terms. No app has reached a billion monthly users this quickly, and the category that produced it barely existed three years ago. Whether ChatGPT’s lead in users translates into a lead in the business is the contest the next year will settle. The audience, at least, is no longer in question.
For the past 10 years, Uber’s annual Lost & Found Index has provided a rather quirky anthropological snapshot of its riders — and even a few insights into society. The annual catalogue of millions of forgotten items ranges from mundane modern-day tools such as smartphones and laptops, to more eyebrow-raising objects like live fish, an ankle monitor, a toboggan, a package of live butterflies, and a single Louboutin shoe.
This year, Uber is using the report to highlight the same old problem of lost items with a new twist: robotaxis. Thousands of items (it’s a bit too new for millions) were left behind in robotaxis on Uber’s ride-hailing network in the past year, the company said Tuesday. There were the usual suspects of phones, keys, wallets, passports, and headphones, along with a few items that strayed into the who-is-this-rider category: a set of dentures, an “I Heart Hot Dads” bag, and a blue hat that reads “Emotional Support Human.”
Beyond this entertaining list lies a business opportunity, if a minor one. Even in a future of robot taxis, someone still has to return the things passengers leave behind.
Uber has spent the past several years locking up dozens of partnerships with autonomous vehicle (AV) technology companies. But it really wasn’t until March 2025, when the “Waymo on Uber” robotaxi service launched in Austin, that the commercial wheels on its AV business started turning. Since then, Uber and Waymo have also started a robotaxi service in Atlanta. Uber has added other AV companies to its app in the past year, including Motional in Las Vegas and Avride in Dallas, although these still have human safety operators behind the wheel.
Advertisement
That Uber has already logged thousands of lost items in just 12 months gives some sense of just how many robotaxi rides have been completed on its app. The underlying message here is that Uber’s existing network is already set up to reunite riders with their lost items, including a 15-pound yo-yo, one large black marble duck, a Squishmallow, and a Charli XCX poster.
When an Uber rider forgets belongings in a robotaxi, the process for recovering them is similar to any other Uber ride: open the app, click the activity tab, select the trip during which the item was lost, and contact customer support. Riders are then able to message, chat, or call a support agent. If the item is located, they have two options: pay $15 for an Uber Courier driver to provide same-day local delivery, or pick up the belonging in person from an AV depot, where the vehicles are stored and serviced.
Uber Courier is a rebrand of Uber Connect, which launched in 2020 and allowed users to send packages and personal items between local addresses. But Uber says there is more to its robotaxi support network than repurposing existing services.
“With tens of millions of lost items reported on Uber each year, we’ve spent the last decade building systems that help riders quickly and seamlessly reunite with their belongings,” Amy Satrom, global head of autonomous support at Uber, said in a statement. “As autonomous rides continue to scale on Uber, we’re bringing that same expertise to AVs — combining our fleet operations, support teams, and hybrid network to make getting a lost item back simple, even when there’s no driver behind the wheel.”
Advertisement
In February, the company announced Uber Autonomous Solutions, a new business division that conveys its bigger ambitions around driverless tech. The division provides companies with a suite of services that handle all the tasks associated with operating a robotaxi, self-driving truck, or sidewalk delivery robot business, including software and support services.
And Uber clearly means to make AVs a major revenue driver. The company plans to offer robotaxi rides through its app in as many as 15 cities globally by the end of the year and has said it intends to be the largest facilitator of AV trips in the world by 2029.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
Perplexity, an AI-powered search and answer engine, has a new way to turn personal devices into decentralized data centers.
The company said Tuesday that it’s adding a new hybrid local-server system to Personal Computer, its AI agent that can work across files, apps and the web. Starting in July, the system will automatically decide which parts of a task should run directly on a user’s device and which should be sent to more powerful AI models in the cloud.
A smaller model running locally could handle sensitive data and routine work locally, such as financial records, health information and personal files. More complicated work that requires the capabilities of a larger AI model could still be sent to a server.
Advertisement
Today we’re announcing that hybrid agentic inference is coming to Perplexity Computer.
Computer can split tasks between a local model running on your machine and frontier models in the cloud. This keeps private data on your device and maximizes token efficiency.
Perplexity says its system will make that decision automatically, breaking a larger task into smaller parts and routing each one to the appropriate place. Users won’t need to choose between a local model and a cloud-based model before getting started.
Although the current app is available on Mac, Perplexity is pitching the underlying technology as a broader system that can work across different types of hardware. The company said it unveiled the system with Intel and that the same framework runs on other local silicon, including Nvidia’s RTX Spark platform.
Moving more work onto users’ devices could also reduce the amount of expensive cloud computing required to complete AI tasks. Perplexity argues that routine work shouldn’t consume the same data center resources as a request that genuinely needs one of the most capable AI models.























































You must be logged in to post a comment Login