Is China picking back up the open source AI baton?
Z.ai, also known as Zhupai AI, a Chinese AI startup best known for its powerful, open source GLM family of models, has unveiled GLM-5.1 today under a permissive MIT License, allowing for enterprises to download, customize and use it for commercial purposes. They can do so on Hugging Face.
The new GLM-5.1 is designed to work autonomously for up to eight hours on a single task, marking a definitive shift from vibe coding to agentic engineering.
Advertisement
The release represents a pivotal moment in the evolution of artificial intelligence. While competitors have focused on increasing reasoning tokens for better logic, Z.ai is optimizing for productive horizons.
GLM-5.1 is a 754-billion parameter Mixture-of-Experts model engineered to maintain goal alignment over extended execution traces that span thousands of tool calls.
“agents could do about 20 steps by the end of last year,” wrote z.ai leader Lou on X. “glm-5.1 can do 1,700 rn. autonomous work time may be the most important curve after scaling laws. glm-5.1 will be the first point on that curve that the open-source community can verify with their own hands. hope y’all like it^^”
In a market increasingly crowded with fast models, Z.ai is betting on the marathon runner. The company, which listed on the Hong Kong Stock Exchange in early 2026 with a market capitalization of $52.83 billion, is using this release to cement its position as the leading independent developer of large language models in the region.
Advertisement
Technology: the staircase pattern of optimization
GLM-5.1s core technological breakthrough isn’t just its scale, though its 754 billion parameters and 202,752 token context window are formidable, but its ability to avoid the plateau effect seen in previous models.
In traditional agentic workflows, a model typically applies a few familiar techniques for quick initial gains and then stalls. Giving it more time or more tool calls usually results in diminishing returns or strategy drift.
Z.ai research demonstrates that GLM-5.1 operates via what they call a staircase pattern, characterized by periods of incremental tuning within a fixed strategy punctuated by structural changes that shift the performance frontier.
In Scenario 1 of their technical report, the model was tasked with optimizing a high-performance vector database, a challenge known as VectorDBBench.
Advertisement
VectorDBBench graphic from z.ai for GLM-5.1. Credit: z.ai
The model is provided with a Rust skeleton and empty implementation stubs, then uses tool-call-based agents to edit code, compile, test, and profile. While previous state-of-the-art results from models like Claude Opus 4.6 reached a performance ceiling of 3,547 queries per second, GLM-5.1 ran through 655 iterations and over 6,000 tool calls. The optimization trajectory was not linear but punctuated by structural breakthroughs.
At iteration 90, the model shifted from full-corpus scanning to IVF cluster probing with f16 vector compression, which reduced per-vector bandwidth from 512 bytes to 256 bytes and jumped performance to 6,400 queries per second.
By iteration 240, it autonomously introduced a two-stage pipeline involving u8 prescoring and f16 reranking, reaching 13,400 queries per second. Ultimately, the model identified and cleared six structural bottlenecks, including hierarchical routing via super-clusters and quantized routing using centroid scoring via VNNI. These efforts culminated in a final result of 21,500 queries per second, roughly six times the best result achieved in a single 50-turn session.
Advertisement
This demonstrates a model that functions as its own research and development department, breaking complex problems down and running experiments with real precision.
The model also managed complex execution tightening, lowering scheduling overhead and improving cache locality. During the optimization of the Approximate Nearest Neighbor search, the model proactively removed nested parallelism in favor of a redesign using per-query single-threading and outer concurrency.
When the model encountered iterations where recall fell below the 95 percent threshold, it diagnosed the failure, adjusted its parameters, and implemented parameter compensation to recover the necessary accuracy. This level of autonomous correction is what separates GLM-5.1 from models that simply generate code without testing it in a live environment.
Kernelbench: pushing the machine learning frontier
The model’s endurance was further tested in KernelBench Level 3, which requires end-to-end optimization of complete machine learning architectures like MobileNet, VGG, MiniGPT, and Mamba.
Advertisement
In this setting, the goal is to produce a faster GPU kernel than the reference PyTorch implementation while maintaining identical outputs. Each of the 50 problems runs in an isolated Docker container with one H100 GPU and is limited to 1,200 tool-use turns. Correctness and performance are evaluated against a PyTorch eager baseline in separate CUDA contexts.
The results highlight a significant performance gap between GLM-5.1 and its predecessors. While the original GLM-5 improved quickly but leveled off early at a 2.6x speedup, GLM-5.1 sustained its optimization efforts far longer. It eventually delivered a 3.6x geometric mean speedup across 50 problems, continuing to make useful progress well past 1,000 tool-use turns.
Although Claude Opus 4.6 remains the leader in this specific benchmark at 4.2x, GLM-5.1 has meaningfully extended the productive horizon for open-source models.
This capability is not simply about having a longer context window; it requires the model to maintain goal alignment over extended execution, reducing strategy drift, error accumulation, and ineffective trial and error. One of the key breakthroughs is the ability to form an autonomous experiment, analyze, and optimize loop, where the model can proactively run benchmarks, identify bottlenecks, adjust strategies, and continuously improve results through iterative refinement.
Advertisement
All solutions generated during this process were independently audited for benchmark exploitation, ensuring the optimizations did not rely on specific benchmark behaviors but worked with arbitrary new inputs while keeping computation on the default CUDA stream.
Product strategy: subscription and subsidies
GLM-5.1 is positioned as an engineering-grade tool rather than a consumer chatbot. To support this, Z.ai has integrated it into a comprehensive Coding Plan ecosystem designed to compete directly with high-end developer tools.
The product offering is divided into three subscription tiers, all of which include free Model Context Protocol tools for vision analysis, web search, web reader, and document reading.
The Lite tier at $27 USD per quarter is positioned for lightweight workloads and offers three times the usage of a comparable Claude Pro plan. The Pro tier at $81 per quarter is designed for complex workloads, offering five times the Lite plan usage and 40 to 60 percent faster execution.
Advertisement
The Max tier at $216 per quarter is aimed at advanced developers with high-volume needs, ensuring guaranteed performance during peak hours.
For those using the API directly or through platforms like OpenRouter or Requesty, Z.ai has priced GLM-5.1 at $1.40 per one million input tokens and $4.40 per million output tokens. There’s also a cache discount available for $0.26 per million input tokens.
Notably, the model consumes quota at three times the standard rate during peak hours, which are defined as 14:00 to 18:00 Beijing Time daily, though a limited-time promotion through April 2026 allows off-peak usage to be billed at a standard 1x rate. Complementing the flagship is the recently debuted GLM-5 Turbo.
Advertisement
While 5.1 is the marathon runner, Turbo is the sprinter, proprietary and optimized for fast inference and tasks like tool use and persistent automation.
At a cost of $1.20 per million input / $4 per million output, it is more expensive than the base GLM-5 but comes in at more affordable than the new GLM-5.1, positioning it as a commercially attractive option for high-speed, supervised agent runs.
The model is also packaged for local deployment, supporting inference frameworks including vLLM, SGLang, and xLLM. Comprehensive deployment instructions are available at the official GitHub repository, allowing developers to run the 754 billion parameter MoE model on their own infrastructure.
For enterprise teams, the model includes advanced reasoning capabilities that can be accessed via a thinking parameter in API requests, allowing the model to show its step-by-step internal reasoning process before providing a final answer.
Advertisement
Benchmarks: a new global standard
The performance data for GLM-5.1 suggests it has leapfrogged several established Western models in coding and engineering tasks.
SWE-Bench Pro benchmark comparison chart showing GLM-5.1 leading other major models. Credit: z.ai
On SWE-Bench Pro, which evaluates a model’s ability to resolve real-world GitHub issues using an instruction prompt and a 200,000 token context window, GLM-5.1 achieved a score of 58.4. For context, this outperforms GPT-5.4 at 57.7, Claude Opus 4.6 at 57.3, and Gemini 3.1 Pro at 54.2.
Beyond standardized coding tests, the model showed significant gains in reasoning and agentic benchmarks. It scored 63.5 on Terminal-Bench 2.0 when evaluated with the Terminus-2 framework and reached 66.5 when paired with the Claude Code harness.
Advertisement
On CyberGym, it achieved a 68.7 score based on a single-run pass over 1,507 tasks, demonstrating a nearly 20-point lead over the previous GLM-5 model. The model also performed strongly on the MCP-Atlas public set with a score of 71.8 and achieved a 70.6 on the T3-Bench.
In the reasoning domain, it scored 31.0 on Humanitys Last Exam, which jumped to 52.3 when the model was allowed to use external tools. On the AIME 2026 math competition benchmark, it reached 95.3, while scoring 86.2 on GPQA-Diamond for expert-level science reasoning.
The most impressive anecdotal benchmark was the Scenario 3 test: building a Linux-style desktop environment from scratch in eight hours.
Unlike previous models that might produce a basic taskbar and a placeholder window before declaring the task complete, GLM-5.1 autonomously filled out a file browser, terminal, text editor, system monitor, and even functional games.
Advertisement
It iteratively polished the styling and interaction logic until it had delivered a visually consistent, functional web application. This serves as a concrete example of what becomes possible when a model is given the time and the capability to keep refining its own work.
Licensing and the open segue
The licensing of these two models tells a larger story about the current state of the global AI market. GLM-5.1 has been released under the MIT License, with its model weights made publicly available on Hugging Face and ModelScope.
This follows the Z.ai historical strategy of using open-source releases to build developer goodwill and ecosystem reach. However, GLM-5 Turbo remains proprietary and closed-source. This reflects a growing trend among leading AI labs toward a hybrid model: using open-source models for broad distribution while keeping execution-optimized variants behind a paywall.
Industry analysts note that this shift arrives amidst a rebalancing in the Chinese market, where heavyweights like Alibaba are also beginning to segment their proprietary work from their open releases.
Advertisement
Z.ai CEO Zhang Peng appears to be navigating this by ensuring that while the flagship’s core intelligence is open to the community, the high-speed execution infrastructure remains a revenue-driving asset.
The company is not explicitly promising to open-source GLM-5 Turbo itself, but says the findings will be folded into future open releases. This segmented strategy helps drive adoption while allowing the company to build a sustainable business model around its most commercially relevant work.
Community and user reactions: crushing a week’s work
The developer community response to the GLM-5.1 release has been overwhelmingly focused on the model’s reliability in production-grade environments.
User reviews suggest a high degree of trust in the model’s autonomy.
Advertisement
One developer noted that GLM-5.1 shocked them with how good it is, stating it seems to do what they want more reliably than other models with less reworking of prompts needed. Another developer mentioned that the model’s overall workflow from planning to project execution performs excellently, allowing them to confidently entrust it with complex tasks.
Specific case studies from users highlight significant efficiency gains.
A user from Crypto Economy News reported that a task involving preprocessing code, feature selection logic, and hyperparameter tuning solutions, which originally would have taken a week, was completed in just two days. Since getting the GLM Coding plan, other developers have noted being able to operate more freely and focus on core development without worrying about resource shortages hindering progress.
On social media, the launch announcement generated over 46,000 views in its first hour, with users captivated by the eight-hour autonomous claim. The sentiment among early adopters is that Z.ai has successfully moved past the hallucination-heavy era of AI into a period where models can be trusted to optimize themselves through repeated iteration.
Advertisement
The ability to build four applications rapidly through correct prompting and structured planning has been cited by multiple users as a game-changing development for individual developers.
The implications of long-horizon work
The release of GLM-5.1 suggests that the next frontier of AI competition will not be measured in tokens per second, but in autonomous duration.
If a model can work for eight hours without human intervention, it fundamentally changes the software development lifecycle.
However, Z.ai acknowledges that this is only the beginning. Significant challenges remain, such as developing reliable self-evaluation for tasks where no numeric metric exists to optimize against.
Advertisement
Escaping local optima earlier when incremental tuning stops paying off is another major hurdle, as is maintaining coherence over execution traces that span thousands of tool calls.
For now, Z.ai has placed a marker in the sand. With GLM-5.1, they have delivered a model that doesn’t just answer questions, but finishes projects. The model is already compatible with a wide range of developer tools including Claude Code, OpenCode, Kilo Code, Roo Code, Cline, and Droid.
For developers and enterprises, the question is no longer, “what can I ask this AI?” but “what can I assign to it for the next eight hours?”
The focus of the industry is clearly shifting toward systems that can reliably execute multi-step work with less supervision. This transition to agentic engineering marks a new phase in the deployment of artificial intelligence within the global economy.
Amazon has today announced a software update for both the Kindle Colorsoft and Kindle Scribe Colorsoft which will bring dark mode to both e-readers. Even better, users will be able to toggle the settings for specific menus on both devices, so if they want their library dark and their notebook light, they can. Given the option is available on plenty of other Kindle devices, its omission here always felt like something Amazon was just getting around to addressing.
In addition, the update brings Smart Shapes to notebooks, enabling users to add pre-drawn lines, arrows, circles, triangles and rectangles from the toolbar. In addition, a hold-to-snap tool lets you draw a shape freehand, after which point it’ll pull itself into a nice tidy design. Both should help folks who want to add some graphical zing to their note taking who can’t do all those fancy journal designs on their own.
The update is rolling out across the ecosystem across the next few days, further empowering would-be journal scribes using these tablets. For tablets like the Kindle Scribe Colorsoft, it’s clear Amazon needs to build out the Scribe half of the equation, which looks like a poor relative compared to its competition. As Cherlynn Low wrote in her review, it’s a fine e-reader, but one that’s sorely lacking in many areas.
Considering how integral it is to our modern way of life, you could be excused for thinking that the Global Positioning System (GPS) is a product of the smartphone era. But the first satellites actually came online back in 1978, although the system didn’t reach full operational status until April of 1995. While none of the active GPS satellites currently in orbit are quite that old, several of them were launched in the early 2000s — and despite a few tweaks and upgrades, their core technology isn’t far removed from their 1990s era predecessors.
But in the coming years, that’s finally going to change. Just last week, the tenth GPS III satellite was placed in orbit by a SpaceX Falcon 9 rocket. Once it’s properly configured and operational, it will join its peers to form the first complete “block” of third-generation GPS satellites. Over the next decade, as many as 22 revised GPS III satellites are slated to take their position over the Earth, eventually replacing all of the aging satellites that billions of people currently rely on.
To understand the future of GPS, it’s helpful to look at its past. Developed by the United States military during the Cold War, what we now call GPS was originally known as Navigation System with Timing and Ranging (NAVSTAR). While the intent was always to allow civilian use of NAVSTAR, the equipment necessary to receive the signal and get a position was cumbersome and expensive.
There was little public interest in the system until Korean Air Lines Flight 007 was shot down in 1983 after mistakenly entering the Soviet Union’s airspace. With the lifesaving potential of NAVSTAR clearly evident, pressure started building on the industry to develop smaller and more affordable receivers — GPS as we know it was born.
Advertisement
NAVSTAR Satellite
That the development of such devices was possible in the first place was thanks to the design of NAVSTAR. Each satellite in the constellation broadcasts a timed radio signal which receivers on the ground use to compute their distance from the source. By comparing the signals from multiple satellites, a receiver can plot its position without the need for any local infrastructure. Since the process is entirely one-way, the can could be freely used by any device can can receive and decode the signal.
But while this operational simplicity was key to the proliferation of cheap ubiquitous GPS receivers, there’s certainly room for improvement given more modern technology. When NAVSTAR was designed knowing where a receiver was located within a radius of a few meters was more than sufficient, but today there’s a demand for greater accuracy by both civilian and military users. Given the essentially incalculable value of GPS to the global economy, improving reliability is also paramount. Not only has GPS jamming and spoofing become trivial, but even without the involvement of bad actors, legacy GPS struggles in urban environments.
Plans to deliver improved performance in these areas have been in the works for decades, with the United States Congress first authorizing the work on what would become GPS III all the way back in 2000. But when working on a system so critical that even a few minutes of downtime could put the entire planet into turmoil, such changes don’t come easy.
Can You Hear Me Now?
While modern GPS receivers are more sensitive than those in the past, there’s simply no getting over the fact that signals coming from a satellite more than 20,000 kilometers away will be by their very nature weak. So not only is it relatively easy for adverse environmental conditions to block or hinder the signal, but it doesn’t take much to override the signal with a local transmitter if somebody is looking to cause trouble.
As such, one of the key goals of the GPS III program was to deliver higher transmission power. This will lead to better reception for all GPS users across the board, but the new satellites also offer some special modes that offer even greater performance.
Advertisement
In addition to the backwards compatible signals transmitted by GPS III satellites, there’s also a new “Safety of Life” signal. This signal is transmitted at a different frequency, 1176 MHz, and at a higher power, so compatible receivers should hear it come in at approximately 3 dB above the “classic” signal. It’s intended primarily for high-performance applications such as aviation, but as compatible receivers get cheaper, it will start to show up in more devices.
These improvements should be enough for civilian use, but the military has higher expectations and operates under more challenging conditions. In such cases, future GPS III satellites will come equipped with a high-gain directional antenna that can project a “spot beam” signal anywhere on Earth. For receivers located within the beam, which is estimated to be a few hundred kilometers in diameter, the received signal from the satellite will be boosted by up to 20 dB. In contested environments, this should make it far more resistant to jamming and spoofing.
Speaking New Languages
The new signals being transmitted by GPS III satellites won’t just be louder than their predecessors, they’ll gain some new features as well.
For one thing, GPS III satellites will transmit a standardized signal known as L1C which offers interoperability with other global navigation systems such as Europe’s Galileo, China’s BeiDou, the Indian Regional Navigation Satellite System (IRNSS), and Japan’s Quasi-Zenith Satellite System. In theory a compatible receiver will be able to process signals from any combination of these systems simultaneously, improving overall performance.
Advertisement
The new satellites will also support the L2C signal. While this signal was technically available on earlier generation satellites, it’s still not considered fully operational and its adoption is expected to accelerate as more GPS III satellites come online. Compared with the legacy GPS protocol, L2C offers improved faster acquisition of signal, better error correction, and a more capable packet format.
To make GPS III transmissions even more secure, the military is also getting their own signal known as M-code. As you might expect, little is publicly known about M-code currently, but it’s a safe bet that it utilizes encryption and other features to make it more difficult for adversaries to create spoofed transmissions. For what it’s worth, a recent press release from the US Space Force claims that the use of M-code makes the next-generation GPS satellites “three-times more accurate and eight times more resistant to jamming than the previous constellation.”
Testing Out New Toys
Although all ten GPS III satellites are now in orbit, that doesn’t mean the constellation is complete. Starting in 2027, a new fleet of revised satellites known as GPS IIIF will start launching. They will take the lessons learned from the initial GPS III deployment to create a smaller, lighter, and more efficient platform that should have a service life of at least 15 years.
Artist impression of a future GPS IIIF satellite.
They’ll also include new in-development equipment that wasn’t quite ready for deployment when the current GPS III satellites were being assembled. This includes optical reflectors that will allow ground stations to more accurately track the position of each satellite, laser data links that will allow high-speed communication between satellites, and an improved atomic clock known as the Digital Rubidium Atomic Frequency Standard (DRAFS).
Of course, the vast majority of the people who use GPS every day will never be aware of all the changes and improvements happening behind the scenes. When they get a new phone with a GPS III-compatible receiver, they may notice that their navigation app locks on a bit faster or that the position shown on the screen is a little closer to where they are actually standing, but only if they are particularly attentive. But that’s entirely by design — the most important aspect of implementing GPS III is making the whole process as invisible as possible.
Late last month we noted how the Trump FCC under Brendan Carr announced a new “ban” on all routers made overseas (which means pretty much all of them). At the time, we also noted how this was less of a ban and more of a shakedown, with router manufacturers required to beg the Trump FCC for conditional waivers (fees, favors, whatever) to continue doing business in the States.
Not long after, Netgear, which does a lot of work with the U.S. government, announced it had received an exemption from the Trump FCC, though neither Netgear or the government transparently indicated what Netgear had to do to get the exemption. Pay a bribe? Host Brendan Carr for a game of golf? Install a surreptitious backdoor for CIA and ICE access? Nobody knows.
Now Amazon is the latest to get an exemption for both its Eero consumer routers and its Leo low Earth orbit (LEO) routers. Amazon showed up on the exemption list, but again there’s absolutely no indication of what the company had to actually do to get it, or the standards the Trump FCC is using to determine what hardware can be trusted. An Amazon announcement is painfully vague:
“We’re pleased to share that the U.S. government has recognized eero as a trusted and secure provider of routers.”
How did this happen? Does anybody trust the Trump administration to make this determination? Are there concerns about backdoors in exchange for being allowed to continue to do business? Nobody knows, though the FCC has indicated the ban has been expanded to include personal hotspots.
Advertisement
This would all likely be less alarming if the Trump administration wasn’t aggressively transactional, unethical, and authoritarian. Little to nothing Brendan Carr and Donald Trump do is genuinely for the public interest; and while this ban is being proposed as an act to protect national security, with their other hand they’ve taken countless steps to ensure consumers are less secure than ever.
That’s ranged from firing of officials responsible for online election security and investigating hacks, or to the relentless “deregulation” (real, the elimination of corporate oversight) of a U.S. telecom sector that was just the target of one of the worst cybersecurity incidents in U.S. history (in large part because telecom executives failed to change default router admin passwords).
Most press coverage of this new router ban acts as if the Trump FCC is still a trusted actor when it comes to the public interest, but that’s a pretty broad assumption given all the dodgy, unethical, and illegal behavior we’ve seen from the agency and administration more generally.
I don’t think most U.S. journalism is journalism. It’s some weird simulacrum designed to not offend. Why would you not at least include one sentence or paragraph on how nothing about this is transparent? Or that the administration has a bad track record on ethics and transparency?
Advertisement
Similarly, no outlets have been inclined to mention that the Trump administration’s open corruption and mindless dismantling of corporate oversight and consumer protection have most certainly endangered national security and consumer cybersecurity and privacy in ways we’ve not yet begun to calculate. “You can trust us on this,” isn’t something anybody, especially media outlets, should be accepting as an answer.
The next gadget you put on your head could scan your brain. Neurable, a Boston-based company that embeds its noninvasive brain-scanning technology into hardware to monitor a person’s focus levels, announced on Tuesday that it is transitioning to a licensing platform model. By certifying third parties, Neurable expects its tech to be in a “flood” of consumer gadgets this year and next.
Neurable has until now focused its efforts on a pair of consumer-grade headphones—made in partnership with audio brand Master & Dynamic. It also has a contract with the US Department of Defense to see how its technology can monitor blast overpressure and potentially help diagnose mild traumatic brain injuries in soldiers. With the licensing model, we could see more of Neurable’s tech in everyday head-based wearables.
The headphones use built-in electroencephalography (EEG) sensors to monitor brain waves. That information is sent to a companion app and lets wearers know when they need a “brain break,” nudging them to take a breather before they feel burnt out to maximize productivity. The app also lets users discover their cognitive readiness for the day, their brain age, and other metrics, such as mental recovery, cognitive strain, and anxiety resilience. WIRED staff writer Emily Mullin tested the original headphones in 2024, though she found it difficult to verify the accuracy of Neurable’s algorithms.
Now, HP-owned gaming brand HyperX is releasing a gaming headset with Neurable’s technology, and it’s all about improving human performance while esports gaming. The headphones are purported to help wearers ease into the right state of mind for the best performance. Ramses Alcaide, Neurable cofounder and CEO, tells WIRED that the company has published a white paper showing improved performance among gamers using Neurable’s tech, with reduced response times in first-person shooter games and a small increase in accuracy.
Advertisement
The improvements may sound minor, but milliseconds are precious in the fast-paced world of esports gaming. And Alcaide says it could translate similarly to other fields: It could help a student reduce anxiety before an exam, while athletes could condition their nerves ahead of a race or game. Neurable is hardware-agnostic; Alcaide says it can be embedded in headphones, smart glasses, hats, or helmets. “There’s a whole landscape of technology that touches your head that’s yet to be embedded with our platform,” he says.
He likens it to when Fitbit made the idea of a wrist-worn heart-rate tracker popular. In the beginning, no one knew how fitness wearables would be received, but now no one blinks an eye at one on a wrist. Soon, no one will think twice about brain-scanning tech in headphones—or, at least, that’s the idea. Neurable’s tech is “invisible” in these types of gadgets.
Companies licensing Neurable’s tech can integrate it into existing hardware, Alcaide says, and will control the entire experience from product design to the software experience; these products will be advertised as “Powered by Neurable AI.” The user data still flows to Neurable’s servers for processing, but Neurable sets the data privacy protections. User identifiers are separated from the data, and while partner companies host the user-facing layer, Neurable says it keeps control of the underlying system and data handling. Neurable has previously said its business model is not to sell user data.
“Any time there’s a new transition to technology, there’s always going to be some anxiety,” Alcaide says. “We’ve been very careful when it comes to that transition. We’re protecting the data, being as ethical as possible.”
At Nvidia, that shift is already visible. “For my team, the cost of compute is far beyond the costs of the employees,” Bryan Catanzaro, vice president of applied deep learning at Nvidia, told Axios. Read Entire Article Source link
Apple is claiming that the Towson Apple Store employee contract prevents guaranteed employment at other locations, and the union has filed an unlawful discrimination suit about the matter.
IAM Union lobs Unfair Labor Practice charge at Apple after alleged discrimination against unionized Towson workers | Image Credit: IAM
On Monday, the International Association of Machinists and Aerospace Workers (IAM) Union officially filed an Unfair Labor Practice (ULP) charge against Apple. The charge, which has been submitted to the National Labor Relations Board (NLRB), alleges that the company unlawfully discriminated against unionized workers at its Towson, Maryland retail location. Towson, Maryland was the first unionized Apple retail location in the United States. It was also one of three locations Apple would be closing permanently in June. Continue Reading on AppleInsider | Discuss on our Forums
We rated the DJI Mic Mini as the best small wireless mic when it was launched in 2024, and it now has a successor in the shape of the Mic Mini 2. Both are 5-star products for content creators wanting an affordable, lightweight, and simple mic for better audio on the go.
Advertisement
If you already own a Mic Mini, there’s very little reason to upgrade to the Mic Mini 2 because performance is practically the same; both mics feature clear 24-bit audio, two-level noise reduction, a transmission range up to 400m, healthy battery life, and a lightweight 11g build.
So what exactly is new? I’ve pinpointed the key differences below, chief among them being much better pricing this time around, plus a new bundle for mobile creators.
Article continues below
Advertisement
Surprisingly, however, DJI also revealed in its Mic Mini 2 press release that a Mic Mini 2S is in the pipeline for later this year. The ‘S’ version will add welcome upgrades missing in current models: internal recording, plus the capacity to sync up to four mics with one receiver. That’s all we know about the Mic Mini 2S for now, but it sounds like it’ll be worth the wait for Mic Mini upgraders.
Let’s now see how the Mic Mini and Mic Mini 2 compare. You can find out more about each product in our full reviews via the links above.
Advertisement
1. Design
Image 1 of 3
(Image credit: DJI)
(Image credit: DJI)
(Image credit: DJI)
Both products are tiny, discreet, and lightweight — the Mic Mini 2 weighs just 11g by itself (not including the magnetic attachment). However, there’s one new design trick in the Mic Mini 2 that could be worth an upgrade, depending on the user: magnetic covers.
The Mic Mini 2 has a magnetic surface that accepts covers, with a wide range of colors available, as you can see in the lead image of this article. There are further limited edition covers too (see above). There’s a selection of covers included in the 2 TX + 1RX + Charging Case bundle (details below), while additional covers can be purchased separately.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Advertisement
If you’re style-conscious and like the sound of a wireless mic that matches the color of your outfit, then this new feature could be worth the upgrade alone. However, if you don’t mind the standard black or white options, then this upgrade could feel like a bit of a gimmick.
2. Voice tone presets
DJI has added three voice tone presets to the Mic Mini 2: regular, rich, and bright. The idea is that each preset optimizes audio quality based on the recording environment. However, our reviewer found that there was so little difference between the sound in each preset that it’s barely worth the upgrade.
So if customizable colors aren’t your bag, nor do the voice tone presets entice, there’s essentially no reason to upgrade to the Mic Mini 2 from the Mic Mini. However, for those buying new, the biggest reason to be excited is a significant price cut, along with a new bundle designed for mobile creators.
Advertisement
3. Pricing and bundles
Image 1 of 6
The complete kit, housed in a charging case(Image credit: DJI)
The standard receiver in the priciest bundle. Design-wise, it’s a better fit for proper cameras rather than phones(Image credit: DJI)
Here’s the bundle for mobile(Image credit: DJI)
It includes a mobile receiver which is a much better fit for phones(Image credit: DJI)
(Image credit: DJI)
(Image credit: DJI)
When the Mic Mini was unveiled in 2024, the 2 TX + 1RX + Charging Case bundle cost $169 / £145 / AU$245. It seems hard to believe, then, that the equivalent Mic Mini 2 bundle costs just £89 / AU$149 — that’s a huge price cut, likely due to increased competition. As is the way with DJI currently, there’s no US pricing or availability at launch.
There’s also a new bundle designed for solo mobile creators, which comprises one mic, one mobile receiver (see our DJI Mic series mobile receiver hands-on), and a charging case, available for just £49 / AU$89. This kit includes a sleek receiver that slots into your phone’s USB-C, whereas the bundle above includes the standard receiver, which is much clunkier when connected to a phone, and is a better fit for proper cameras.
Advertisement
The price for the mobile bundle is the same price that DJI was asking for a single mic when it launched the original Mic Mini. Sadly, it’s not possible to buy a solo Mic Mini 2 mic just yet.
All that being said, the price of the original Mic Mini complete kit mentioned above has continually dropped during its two-year life, and can now be found for as little as £65 / AU$124 — that’s less than the new version with its additional colored covers.
For me, those Mic Mini 2 prices are super competitive. Yes, the second-gen model is a tiny upgrade (customizable covers aside), but it led the way for value in an increasingly competitive space and is my new favorite small wireless mic. Whether or not the Mic Mini 2S reveal rains on the Mic Mini 2 parade, we’ll have to wait and see.
‘Human lives are already being lost’: Open letter signed by hundreds of Google employees requests CEO reject ‘unethical and dangerous’ US military AI use
Google employees sign open letter to CEO over concerns of military AI use
AI developers do not want their technology used for ‘classified purposes’
Google is currently negotiating a contract with the Pengaton
Over 600 Google employees have signed a letter calling on CEO Sundar Pichai to reject any uses of its AI technology for military purposes.
The open letter highlights the serious ethical concerns the staff have, stating, “Human lives are already being lost and civil liberties put at risk at home and abroad from misuses of the technology we are playing a key role in building.”
“As people working on AI, we know that these systems can centralize power and that they do make mistakes,” the letter said. “We feel that our proximity to this technology creates a responsibility to highlight and prevent its most unethical and dangerous uses.”
The new OpenAI contract with the Pentagon was full of holes that would have allowed the same use of ChatGPT that Anthropic feared for Claude. The contract was amended to state that OpenAI’s models would not be used for “deliberate tracking, surveillance, or monitoring of U.S. persons or nationals, including through the procurement or use of commercially acquired personal or identifiable information.”
Shortly after, Sam Altman told his employees that the Pentagon has said OpenAI does not “get to make operational decisions” on how the military uses AI technologies.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Now, Google employees are joining the growing number of AI company employees and members of the public opposed to the military use of AI tools. “Making the wrong call right now would cause irreparable damage to Google’s reputation, business and role in the world,” the letter states.
Advertisement
Following protests involving Google staff in 2018, the company amended its AI Principles to state that it would not deploy its AI tools where they were “likely to cause harm,” and would not “design or deploy” AI tools for surveillance or weapons. These clauses were quietly removed from its AI Principles on 4 February 2025.
On Apr 28, LinkedIn unveiled its 2026 Top Companies list, naming the 15 best places to work in Singapore.
The rankings are based on LinkedIn’s own data, with companies assessed on various elements of career progression, including factors like how well they help employees progress in their careers and build new skills.
Here are this year’s top companies to grow your career in Singapore, according to LinkedIn:
1. DBS Bank
Image Credit: DBS Bank
Claiming the top spot once again is DBS Bank, Southeast Asia’s largest bank. The financial giant is currently hiring for over 200 roles here, including:
Microsoft is a technology company that develops software, hardware and cloud‑based services. Singapore serves as a key regional hub for its Asia‑Pacific operations, supporting customers across consumer, enterprise and public sector markets.
It is also the parent company of Activision Blizzard, GitHub, Skype, LinkedIn and others. LinkedIn and its employees are excluded from Microsoft’s score.
The company is looking for new hires for these positions:
Goldman Sachs is a financial services firm that provides investment banking, asset management and financial advisory services. It has offices across Asia, including Singapore, serving corporations, governments and institutional investors in the region.
These are some of the jobs the firm is hiring for:
Originally founded in Switzerland, Roche is a multinational healthcare company that focuses on research and development of medical solutions for major disease areas such as oncology, immunology, and neuroscience.
The fifth largest bank in the world, JPMorgan Chase & Company, first opened in Singapore back in 1964 and has established itself as a global financial services firm across 17 markets in the Asian Pacific region.
The firm is looking for fresh faces for these roles:
A heavyweight in the global IT industry, HP is a technology company that manufactures a range of monitors, laptops and desktops. It also produces and offers services around printers and 3D printers.
The tech company is currently looking to fill these roles:
You can browse through HP’s full job listings here.
7. Standard Chartered
Image Credit: Standard Chartered
Another notable bank on the list, Standard Chartered offers banking services across 52 markets worldwide.
The bank’s on the lookout for people to fill these positions:
Advertisement
You can look at Standard Chartered’s full job list here.
8. MSD
Image Credit: MSD
Known as Mereck in the United States and Canada, MSD is a pharmaceutical company that specialises in producing prescription medicines, vaccines and animal health products.
Genting Berhad is a diversified company with businesses in leisure, hospitality, energy and plantations.
The group’s Singapore subsidiary, Genting Singapore Limited, has a significant presence in the city-state linked to its regional leisure and hospitality activities.
Advertisement
It is currently hiring for these roles in Singapore:
Barclays is a financial services company providing banking, lending, investment and wealth management services. It serves individuals, businesses and institutional clients through retail and corporate banking operations.
These are some of the roles it is hiring for in Singapore:
The company behind the all-familiar iPhone, Apple, first opened its facility in Singapore in 1981 and has since grown its presence in the city-state with three outlets in Orchard, Marina Bay Sands and Jewel Changi.
Apple has close to 100 openings listed on LinkedIn as of writing, including:
Micron Technology is a semiconductor company that designs and manufactures memory and storage products. These components are used in computers, mobile devices, data centres and other electronic systems.
The firm is currently hiring for these positions:
Click here to view Micron Technology’s full job list.
14. Rockwell Automation
Image Credit: Shutterstock.com
Rockwell Automation is an industrial technology company that provides hardware, software and services for manufacturing and production operations. Its products help businesses automate processes and manage industrial systems.
Citi operates as a full-service bank in Singapore. It provides individuals, corporations, governments, investors and institutions with a range of financial products and banking services.
The bank’s on the lookout for people to fill these positions:
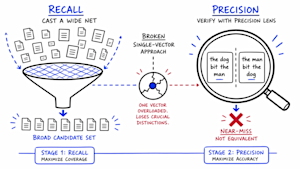
Enterprise teams that fine-tune their RAG embedding models for better precision may be unintentionally degrading the retrieval quality those pipelines depend on, according to new research from Redis.
The paper, “Training for Compositional Sensitivity Reduces Dense Retrieval Generalization,” tested what happens when teams train embedding models for compositional sensitivity. That is the ability to catch sentences that look nearly identical but mean something different — “the dog bit the man” versus “the man bit the dog,” or a negation flip that reverses a statement’s meaning entirely. That training consistently broke dense retrieval generalization, how well a model retrieves correctly across broad topics and domains it wasn’t specifically trained on. Performance dropped by 8 to 9 percent on smaller models and by 40 percent on a current mid-size embedding model teams are actively using in production.
The findings have direct implications for enterprise teams building agentic AI pipelines, where retrieval quality determines what context flows into an agent’s reasoning chain. A retrieval error in a single-stage pipeline returns a wrong answer. The same error in an agentic pipeline can trigger a cascade of wrong actions downstream.
Srijith Rajamohan, AI Research Leader at Redis and one of the paper’s authors, said the finding challenges a widespread assumption about how embedding-based retrieval actually works.
Advertisement
“There’s this general notion that when you use semantic search or similar semantic similarity, we get correct intent. That’s not necessarily true,” Rajamohan told VentureBeat. “A close or high semantic similarity does not actually mean an exact intent.”
The geometry behind the retrieval tradeoff
Embedding models work by compressing an entire sentence into a single point in a high-dimensional space, then finding the closest points to a query at retrieval time. That works well for broad topical matching — documents about similar subjects end up near each other. The problem is that two sentences with nearly identical words but opposite meanings also end up near each other, because the model is working from word content rather than structure.
That is what the research quantified. When teams fine-tune an embedding model to push structurally different sentences apart — teaching it that a negation flip which reverses a statement’s meaning is not the same as the original — the model uses representational space it was previously using for broad topical recall. The two objectives compete for the same vector.
The research also found the regression is not uniform across failure types. Negation and spatial flip errors improved measurably with structured training. Binding errors — where a model confuses which modifier applies to which word, such as which party a contract obligation falls on — barely moved. For enterprise teams, that means the precision problem is harder to fix in exactly the cases where getting it wrong has the most consequences.
Advertisement
The reason most teams don’t catch it is that fine-tuning metrics measure the task being trained for, not what happens to general retrieval across unrelated topics. A model can show strong improvement on near-miss rejection during training while quietly regressing on the broader retrieval job it was hired to do. The regression only surfaces in production.
Rajamohan said the instinct most teams reach for — moving to a larger embedding model — does not address the underlying architecture.
“You can’t scale your way out of this,” he said. “It’s not a problem you can solve with more dimensions and more parameters.”
Why the standard alternatives all fall short
The natural instinct when retrieval precision fails is to layer on additional approaches. The research tested several of them and found each fails in a different way.
Advertisement
Hybrid search. Combining embedding-based retrieval with keyword search is already standard practice for closing precision gaps. But Rajamohan said keyword search cannot catch the failure mode this research identifies, because the problem is not missing words — it is misread structure.
“If you have a sentence like ‘Rome is closer than Paris’ and another that says ‘Paris is closer than Rome,’ and you do an embedding retrieval followed by a text search, you’re not going to be able to tell the difference,” he said. “The same words exist in both sentences.”
MaxSim reranking. Some teams add a second scoring layer that compares individual query words against individual document words rather than relying on the single compressed vector. This approach, known as MaxSim or late interaction and used in systems like ColBERT, did improve relevance benchmark scores in the research. But it completely failed to reject structural near-misses, assigning them near-identity similarity scores.
The problem is that relevance and identity are different objectives. MaxSim is optimized for the former and blind to the latter. A team that adds MaxSim and sees benchmark improvement may be solving a different problem than the one they have.
Advertisement
Cross-encoders. These work by feeding the query and candidate document into the model simultaneously, letting it compare every word against every word before making a decision. That full comparison is what makes them accurate — and what makes them too expensive to run at production scale. Rajamohan said his team investigated them. They work in the lab and break under real query volumes.
Contextual memory. Also sometimes referred to as agentic memory, these systems are increasingly cited as the path beyond RAG, but Rajamohan said moving to that type of architecture does not eliminate the structural retrieval problem. Those systems still depend on retrieval at query time, which means the same failure modes apply. The main difference is looser latency requirements, not a precision fix.
The two-stage fix the research validated
The common thread across every failed approach is the same: a single scoring mechanism trying to handle both recall and precision at once. The research validated a different architecture: stop trying to do both jobs with one vector, and assign each job to a dedicated stage.
Stage one: recall. The first stage works exactly as standard dense retrieval does today — the embedding model compresses documents into vectors and retrieves the closest matches to a query. Nothing changes here. The goal is to cast a wide net and bring back a set of strong candidates quickly. Speed and breadth are what matter at this stage, not perfect precision.
Advertisement
Stage two: precision. The second stage is where the fix lives. Rather than scoring candidates with a single similarity number, a small learned Transformer model examines the query and each candidate at the token level — comparing individual words against individual words to detect structural mismatches like negation flips or role reversals. This is the verification step the single-vector approach cannot perform.
The results. Under end-to-end training, the Transformer verifier outperformed every other approach the research tested on structural near-miss rejection. It was the only approach that reliably caught the failure modes the single-vector system missed.
The tradeoff. Adding a verification stage costs latency. The latency cost depends on how much verification a team runs. For precision-sensitive workloads like legal or accounting applications, full verification at every query is warranted. For general-purpose search, lighter verification may be sufficient.
The research grew out of a real production problem. Enterprise customers running semantic caching systems were getting fast but semantically incorrect responses back — the retrieval system was treating similar-sounding queries as identical even when their meaning differed. The two-stage architecture is Redis’s proposed fix, with incorporation into its LangCache product on the roadmap but not yet available to customers.
Advertisement
What this means for enterprise teams
The research does not require enterprise teams to rebuild their retrieval pipelines from scratch. But it does ask them to pressure-test assumptions most teams have never examined — about what their embedding models are actually doing, which metrics are worth trusting and where the real precision gaps live in production.
Recognize the tradeoff before tuning around it. Rajamohan said the first practical step is understanding the regression exists. He evaluates any LLM-based retrieval system on three criteria: correctness, completeness and usefulness. Correctness failures cascade directly into the other two, which means a retrieval system that scores well on relevance benchmarks but fails on structural near-misses is producing a false sense of production readiness.
RAG is not obsolete — but know what it can’t do. Rajamohan pushed back firmly on claims that RAG has been superseded. “That’s a massive oversimplification,” he said. “RAG is a very simple pipeline that can be productionized by almost anyone with very little lift.” The research does not argue against RAG as an architecture. It argues against assuming a single-stage RAG pipeline with a fine-tuned embedding model is production-ready for precision-sensitive workloads.
The fix is real but not free. For teams that do need higher precision, Rajamohan said the two-stage architecture is not a prohibitive implementation lift, but adding a verification stage costs latency. “It’s a mitigation problem,” he said. “Not something we can actually solve.”

















































































You must be logged in to post a comment Login