Two former OpenAI employees and a group of AI safety nonprofits are warning that Elon Musk’s AI lab, xAI, could become a liability for prospective investors in SpaceX, which is preparing to file what’s expected to be the largest initial public offering in Wall Street History.
In a letter directed to investors published on Tuesday, the ex-staffers highlighted what they describe as “unpriced risks” related to xAI that could complicate SpaceX’s reported plans to raise up to $75 billion as part of its IPO. The rocket company’s private valuation shot up to over $1 trillion after it acquired xAI last year. Musk claimed his rocket company could launch data centers into space for his AI lab, but the letter’s authors argue that xAI’s poor record on safety issues could complicate how investors view the combined company as it gets ready to submit its IPO prospectus filing.
One of the letter’s signatories and coauthors is a new nonprofit called Guidelight AI Standards, which was cofounded by former OpenAI safety researcher Steven Adler and former OpenAI policy advisor Page Hedley. The group, which is backed by private donors, aims to improve the safety practices of frontier AI companies. Other AI safety nonprofits also signed on, including Legal Advocates for Safe Science and Technology, Encode AI, and The Midas Project.
Hedley tells WIRED in an interview that he believes xAI has the worst safety practices “nearly across the board” compared to other frontier AI developers, including OpenAI, Google DeepMind, and Anthropic. As a result, he argues, SpaceX may face a greater risk of regulation and litigation than other AI labs.
Advertisement
The letter’s authors argue that SpaceX should make several disclosures to investors, including whether xAI intends to continue developing frontier AI models. SpaceX recently struck a deal to sell a significant portion of its GPU capacity to Anthropic, and the letter claims the agreement “leaves it unclear whether xAI is still a frontier-AI competitor inside a larger holding company.” If xAI continues to develop frontier AI models, the authors say that it should be required to publish a public safety and governance plan.
SpaceX and xAI did not immediately respond to WIRED’s request for comment.
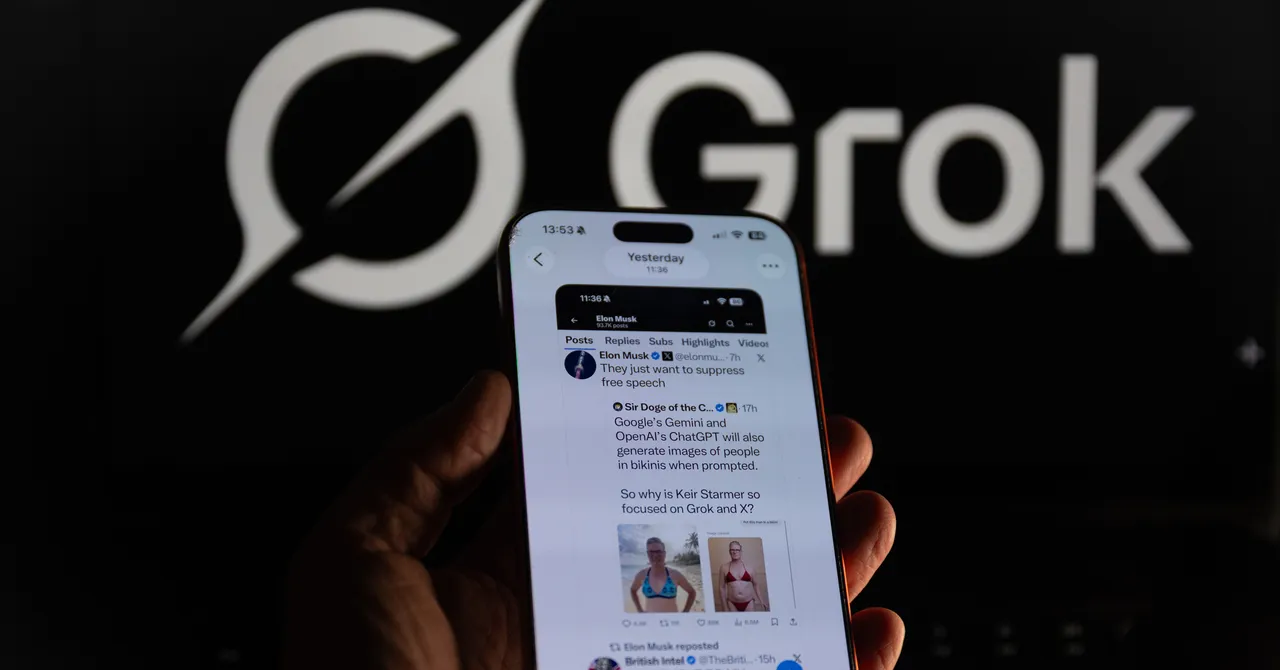
The letter also outlines examples of how xAI has not kept up with industry standard safety practices, such as publishing detailed frameworks for mitigating risks around its AI models being used in cyber attacks. The authors also outline specific safety incidents at xAI that they say warrant additional scrutiny. Among the most notable include when xAI’s flagship AI chatbot, Grok, spontaneously brought up white genocide in its responses. In another case, xAI allowed Grok to generate thousands of sexualized images of women and children, which spread widely across Musk’s social media platform X. The latter case prompted at least 37 US attorneys general to send a letter demanding that Musk’s AI lab take steps to protect women and children on its platform.
Hedley says the number of safety incidents xAI has experienced and the regulatory attention they received is “far out of proportion to its market share.” As lawmakers grow increasingly alarmed by the cyber capabilities of advanced AI models like Anthropic’s Claude Mythos, new security regulations may be on the horizon. The Trump administration is reportedly already weighing an executive order that would give US intelligence agencies more oversight over AI models.
Advertisement
“It takes serious investment to reign in [AI safety] risks, and it seems that xAI has historically under invested here,” says Adler. The letter cites reporting from the Washington Post that said xAI had just “two or three” people working on safety as of January. “A question investors should be wondering is if xAI stays at the frontier, how costly might it be to, in fact, manage these [risks] responsibly? If they don’t, what might be the consequences?”
Tribunal rejects bid to strike blacklisting claims, with proceedings due to conclude shortly before GTA VI launches
Rockstar Games has suffered a legal setback in a dispute over alleged union busting, clearing the way for a final employment tribunal hearing shortly before Grand Theft Auto VI is due to launch.
The developer had sought to have “blacklisting” allegations struck from the case. The employment tribunal rejected the request, and the final hearing is scheduled to run from September 10 to October 15.
Advertisement
According to the Independent Workers’ Union of Great Britain (IWGB), which brought the case, blacklisting is a practice in which information about workers engaged in union activity is compiled to facilitate discrimination.
The Register asked the IWGB for more information, but the union did not respond. Rockstar declined to comment on ongoing legal matters.
The legal dispute stems from the sudden dismissal of 31 IWGB members in October 2025. According to the IWGB, the dismissed workers were part of a private trade union Discord channel where they discussed ways to improve the workplace.
An anonymous source told The Register that when management became aware of the channel, the staff were summarily fired.
Advertisement
At the time, a spokesperson for Rockstar’s holding company, Take-Two Interactive, said: “We strive to make the world’s best entertainment properties by giving our best-in-class creative teams positive work environments and ongoing career opportunities. Our culture is focused on teamwork, excellence, and kindness.
“Rockstar Games terminated a small number of individuals for gross misconduct, and for no other reason. As always, we fully support Rockstar’s ambitions and approach.”
This week, Ellie Dunstan, one of the workers fired last year, described the employment tribunal ruling as a “huge moment for us.”
“Rockstar thought they could control the narrative. They’re wrong, and we look forward to proving it. Our case will now be heard in full and put to the test as it should be. The world will get to see for itself the evidence as to what happened last October.
Advertisement
“We loved our work at Rockstar. Losing our passion, our colleagues, and our incomes in the blink of an eye was devastating, and the company management has treated us with disdain ever since.”
Tech companies are often quick to derail unionization where possible, while working conditions in game development have faced particular scrutiny over “crunch,” the practice of employees working extended hours in the run-up to a release. ®
According to Bloomberg, U.S. Commerce Secretary Howard Lutnick has, in a series of recent meetings, told senior ASML executives he’s concerned that one of the Dutch chipmaker’s extreme ultraviolet lithography machines — the EUV systems that are the only tools on Earth capable of printing the most advanced semiconductor patterns — may have ended up in China. That would be a major breach of export controls that have barred ASML from selling EUV to China since the first Trump administration.
It’s a serious claim. Senior administration officials told Bloomberg they have evidence that ASML shipped EUV-related components and transport equipment to China, though they’ve declined, repeatedly, to show it — to Bloomberg or, apparently, to ASML itself. The company says no such machine exists in China and has never existed there. The Commerce Department didn’t respond to Bloomberg’s questions about whether it has evidence of an actual EUV system on Chinese soil.
You might think this isn’t worth paying attention to if you’re outside the chip industry, but it is. ASML is a Dutch company most people have never heard of, but it is, by a wide margin, the most important company in the global AI buildout that isn’t named Nvidia or one of the hyperscalers. It makes the only machines on the planet capable of EUV lithography — the process of printing the microscopic circuit patterns that define the most advanced chips.
Every cutting-edge processor made by TSMC, the foundry behind Nvidia’s and Apple’s chips, depends on ASML tools that took the company roughly two decades and untold billions to develop. There is, at present, no second supplier. That monopoly has made ASML Europe’s most valuable public company, with a market capitalization that has been trading in the neighborhood of $700 billion as of this week, up sharply over the past year on the back of insatiable AI-driven chip demand.
Advertisement
That scale is exactly why the China question matters so much. If even one EUV machine made it into Chinese hands, it would represent one of the most consequential breaches of the export-control regime the U.S. has built over the past several years to keep advanced AI capability out of Beijing’s military and industrial base.
I sat down with ASML CEO Christophe Fouquet six weeks ago, well before this story broke, and asked him directly about the China question.
Fouquet told me ASML tracks every machine it has ever shipped — they’re either in active use with monitored customers or have been dismantled and returned to the company. He said the firm built an internal firewall years ago: employees who can access EUV technology, documentation, and training are walled off from those who can’t, and ASML’s China-based staff sit on the wrong side of that wall by design. He argued the only reason ASML could build an EUV machine at all was that 80% of it already existed from decades of prior knowledge, and that solving the one genuinely new problem — generating EUV light itself — took 20 years on its own. His broader point seemed to be that you can’t reverse-engineer a machine you’ve never had, and nobody in China has had one.
There’s also a simpler commercial logic that cuts against the idea that ASML would risk its export license to quietly arm a Chinese customer. ASML does sell older-generation deep ultraviolet tools to China — gear it first shipped a decade ago — but Fouquet framed that explicitly as a protective calculation, not a loophole. The idea, he suggested, is that it keeps enough of a generational gap that customers can still do business — but without manufacturing its own future competitor. ASML expects roughly 20% of its 2026 revenue to come from already-permitted sales to China. Risking the EUV ban entirely would put that revenue, and the company’s standing as the most valuable monopoly in European industry, on the line over a single illegal sale.
Advertisement
None of this proves the allegations are false. The government hasn’t yet made its evidence public, and it’s worth withholding judgment until it does.
The Commerce Department, under Lutnick’s leadership, agreed late last year to put up to $150 million of taxpayer money into xLight, a startup developing a next-generation light-source technology that’s been written about as a long-term challenge to the core of ASML’s EUV monopoly. xLight’s own CEO told me last year that the company sees itself as a future partner to ASML, not a rival, building hardware meant to plug into ASML’s machines rather than replace them. When I put that framing to Fouquet in May, he was polite about it but unconvinced; ASML, he made clear, doesn’t see itself as needing xLight’s technology to keep its lead.
Does that have anything to do with why Lutnick is suddenly pressing ASML on EUV? Nothing public connects the two. It could be entirely unrelated. But a federal official scrutinizing a monopoly while his own agency has money riding on a startup angling to improve that monopoly’s core technology is worth examining.
xLight isn’t the only outside bet on the future of lithography. Peter Thiel — who has his own long-running ties to Trump’s political orbit — has backed Substrate, a separate startup explicitly pursuing its own EUV-rival technology, with ambitions to compete with ASML more directly than xLight says it intends to.
Advertisement
As Bloomberg notes, a bipartisan bill moving through Congress would go much further than EUV — it calls for an effective ban on all of ASML’s deep ultraviolet (DUV) shipments to China, the less advanced lithography tools that account for roughly a fifth of the company’s expected 2026 revenue. The bill cleared a key committee in April, and the Trump administration hasn’t taken a formal position on it.
Pictured above: ASML CEO Christophe Fouquet
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
The 3,300 buyers who managed to snag themselves a Dodge SRT Demon 170 got an awful lot for their money. Despite the car’s sub-$100,000 price tag, the Demon produces the kind of power that’s been reserved for ultra-exclusive hypercars until relatively recently. With the right fuel in the tank, it churns out 1,025 horsepower; even on regular pump gas, it’s good for 900 horsepower. At its launch in 2023, Dodge called it the most powerful muscle car in the world, and in the years since then, nothing else has come along to take its crown.
As impressive as it may be, it’s far from the first production car to boast a horsepower output in four-figure territory. For starters, by the time the Demon 170 was announced, Tesla’s Model X Plaid and Model S Plaid had already been on sale for 2 years, with both cars making 1,020 horsepower. To return to the time when the 1,000 horsepower barrier was first crossed in a production car, you’ll have to go back a decade and a half further.
Advertisement
However, the answer to which production car was indeed the first to feature over 1,000 horsepower isn’t as straightforward to answer as you might think. The initial candidate is the Bugatti Veyron, which launched in 2005 after years of anticipation and quickly established itself as a new benchmark in the hypercar world. Originally, it produced 1,001 PS (metric horsepower), which is roughly 987 hp (mechanical horsepower). The second candidate is a much less well-remembered car, the SSC Ultimate Aero TT.
Advertisement
The SSC Ultimate Aero TT is America’s forgotten hypercar
If you’re measuring by mechanical horsepower rather than metric horsepower, the Bugatti Veyron officially falls slightly short of the 1,000 hp mark. However, there are no such caveats with its rival, the SSC Ultimate Aero TT.
SSC is a small American manufacturer founded by Jerod Shelby, who, despite their shared surname and interest in extremely fast cars, is not a relative of the legendary Carroll Shelby. The Ultimate Aero TT entered production in late 2006 and initially made 1,180 horsepower, according to the brand’s archived website. By the time SSC set a world speed record with the car in September 2007, that figure had been tweaked slightly to 1,183 horsepower.
The Veyron might have been designed and developed with the backing of VW Group, but its record as world’s fastest production car was nonetheless eclipsed by the upstart Ultimate Aero TT. During a two-way run, the SSC managed an average speed of 256 mph, just ahead of the Bugatti’s 253 mph average.
Both cars were designed to be the fastest in the world, but they were very different in most other aspects. The Bugatti had a W16 engine with four turbochargers, while the SSC was powered by a twin-turbo V8. The interiors of both cars were also worlds apart, with the Bugatti being luxurious and the SSC being bare-bones at best. In a 2007 feature for Classic Driver, one reviewer claimed that the SSC’s interior “falls way short, not just of other hypercars, but of almost all other cars currently on sale.”
Advertisement
Collectors don’t value the SSC like the Bugatti
As well as their engines and cabins, pricing was also a key differentiator between the two cars. The Bugatti retailed for around $1.2 million at the time of its launch, while SSC charged $550,000 for the Ultimate Aero TT. Today, the difference in value between the two is even more extreme. While the average Veyron sells for around $2 million, interested buyers can pick up an Ultimate Aero TT for under $500,000.
Advertisement
Unfortunately, anyone who’s interested in buying the example that actually beat the Bugatti’s speed record is out of luck. According to The Drive, the record-setting Ultimate Aero TT was crushed at a monster truck event in Washington in 2025, allegedly as a result of its owner being angry with SSC. Speaking to the outlet, Jerod Shelby said that the car had been non-functional for years and was previously in a museum, and added “I can’t imagine why anyone would want to destroy a vehicle of that stature.”
The consultancy giant will take a majority stake in Dragos, and full ownership of RunZero and NetRise.
Accenture is to partially or fully acquire three companies in the area of operational technology (OT) security for critical infrastructure and industrial operations for what it called a “combined enterprise value” of approximately $4.17bn.
The consultancy giant will take a majority stake in Dragos – which Accenture said offers “industry-leading OT threat detection” alongside a “trusted vendor-neutral platform and proprietary dataset” – and full ownership of RunZero and NetRise.
Under the deal, Dragos will continue to function as an independent business while overseeing RunZero, a cybersecurity platform that offers “comprehensive exposure assessment and attack-surface intelligence”, and NetRise, which analyses software supply chains for vulnerabilities.
Advertisement
According to Accenture, combining the three companies, which are based in two different US states, will allow it to advance a platform “to cover the extended environment that controls physical processes” – or ‘xOT’ – at greater scale for the protection of power grids, pipelines, manufacturing operations, distribution facilities and data centres.
“Combining Dragos with RunZero and NetRise will deliver a unified solution that enhances visibility, accelerates threat detection and response, and strengthens Dragos’s ability to scale adoption of its broadened platform,” Accenture said.
Accenture said it expects the three companies to generate, in total, approximately $208m in annual recurring revenue as of June 2026, and noted that its overall cybersecurity business has current revenues of around $10bn, having made a number of OT-focused acquisitions over the past decade.
“Our clients across industries and regions are asking us how to be more proactive and integrated in their approach to cybersecurity,” said Accenture’s CEO and chair Julie Sweet.
Advertisement
Taking on the three companies at a time when “AI-driven cyber threats and geopolitical risk are evolving at a rapid pace … fills this important need”, she added.
Under the deal, which is expected to close in August or September, three executives from the two fully acquired companies will become executives for Dragos, which will continue to be led by its co-founder and CEO Robert M Lee.
“Our energy and water systems, manufacturing plants, data centres and other operational environments need cybersecurity built from the ground up for xOT and designed to keep pace as threats evolve. The consequences of getting it wrong become societal threats,” said Lee.
“Organisations need solutions, not a patchwork of software and services. The addition of RunZero and NetRise will allow the Dragos platform to be a unique, end-to-end platform for global defence, and Accenture will bring its decades of trusted relationships and deep expertise to help us scale and secure more critical infrastructure and physical operations globally.”
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Most people have sat in a go-kart at some point. The seat sits low, the steering feels direct, and the whole thing skitters around with a kind of playful urgency. Very few have ever climbed into one that still carries the shape and branding of a soda machine. A maker known as Mixed Bag set out to close that gap. He bought a used Pepsi vending machine for a hundred dollars on Facebook Marketplace, then spent four months turning it into something that could actually drive.
Initially, the goal was rather straightforward. He saw an advertisement for a local car show in the Dallas area and decided he’d want to enter something, even though a typical project was far out of his price range. The vending machine stood out as a potential contender, and it eventually became his project of choice. Removing all the extra weight the previous machine was lugging around was the first step, as it had a reinforced cabinet and all sorts of internal components that made it way too heavy for battery power and basic mobility. So he removed as much of that as he could, making the endeavor more attainable.
Then came the question of transforming the machine into something that could move. He created a go-kart-style frame that fit inside the cabinet and served as the structural backbone of the item. Battery-powered motors handled propulsion, with two of them driving the rear wheels and providing differential steering, allowing the machine to turn by adjusting speed or direction on either side. Some reused elements from a pair of Razor scooters were utilized for front steering; with the handlebars removed, the steering was joined together for good synchronized movement. Brakes were a must-have, so he installed them. It actually rolled on its own power, though its greatest speed was just about 5 mph. That suited us perfectly, considering the weight and our need to keep it under control during testing and public appearances.
Inside the machine, he installed a real seat, a small AC unit to keep things cool during long runs, and a full set of live cameras on either side. A computer was responsible for monitoring the feeds. He also installed a PA system with an external speaker on the roof, allowing the driver to communicate with anyone close. All of the power came from a set of batteries, one large pack under the item and a few others elsewhere. Fresh Pepsi decals restored its luster, a “mystery flavor” slot at the bottom looked terrific, a rear access hole was cleaned up, and a fresh paint job completed the look.
Testing took place in stages, beginning with night trips and casual cruises about the neighborhood to ensure reliability. It completed a couple of laps on a half-mile track with four bars remaining on the battery, which is equivalent to at least a mile of range on a single charge. Neighbors were more astonished and amused by the gadget than anything else, which was a positive thing because it meant the design seemed friendly rather than frightening. Of course, steering was more difficult on the sidewalk than on the roadway, but it held together relatively well with only a few small failures.
So the real test came at the Rowlett car show, when the organizers allowed it into the custom-built category (with the caveat that it was not street legal, of course). It was parked amid the historic vehicles, lifted trucks, supercars, and insane custom machines, in the ideal location. No trophy was brought home, since Best of Show went to a 1961 Porsche. Mixed Bag stated that the original trophy goal changed once the machine began making strangers laugh, making that outcome more fulfilling than hardware on a shelf.
The big picture: Apple is working on a new version of the iPhone Air due out early next year. Sources familiar with the matter say the new phone will address two complaints that consumers had with the first model: a single rear-facing camera and lackluster battery life.
The next Air will reportedly ship with an ultrawide rear camera alongside the primary unit, boosting its appeal to photo bugs that may have skipped the first-gen device due to its single-camera configuration. In an era where multiple cameras are the norm on most mainstream and premium models, the single-camera Air no doubt felt like a major compromise to some.
Sources tell Bloomberg that Apple is also going to improve the Air’s battery life, although it’s unclear exactly how that will be achieved. The obvious answer would be to simply stuff a higher-capacity pack into the phone but doing so would be counterintuitive to the Air’s thin nature.
Gains could also be made through software tweaks and the use of more efficient hardware like the processor. Speaking of, the second-gen Air will be powered by a version of Apple’s A20 Pro SoC, which will debut in new iPhones due out this fall.
Advertisement
The first-gen iPhone Air launched in the latter half of 2025 with a 6.5-inch display and a slim 5.6mm profile. Initial reports suggested a lackluster response from consumers although later analysis refuted those claims. Moving forward with a new model indicates, at the very least, that Apple isn’t ready to give up on the idea just yet.
Apple is expected to launch the second-gen Air in the spring of 2027 alongside the standard iPhone 18. The latter would normally arrive with Pro-grade handsets in the fall but Apple is expected to shake things up this year with the arrival of its first foldable iPhone in addition to the iPhone 18 Pro and Pro Max. A special edition iPhone is being planned for the fall of 2027 to celebrate the iPhone’s 20th anniversary, we’re told.
Facepalm: Sandisk has unveiled a new line of SSDs designed to expand the PlayStation 5’s storage capacity. To no one’s surprise, the new drives are priced more like luxury hardware than an affordable storage upgrade for a mass-market home console.
The US memory manufacturer has launched the Optimus GX PRO 850P SSD lineup, which includes storage drives specifically designed for the PlayStation 5 and PlayStation 5 Pro. While high-capacity SSDs are already expensive, Sandisk’s PS5-branded drives push pricing to an entirely different level.
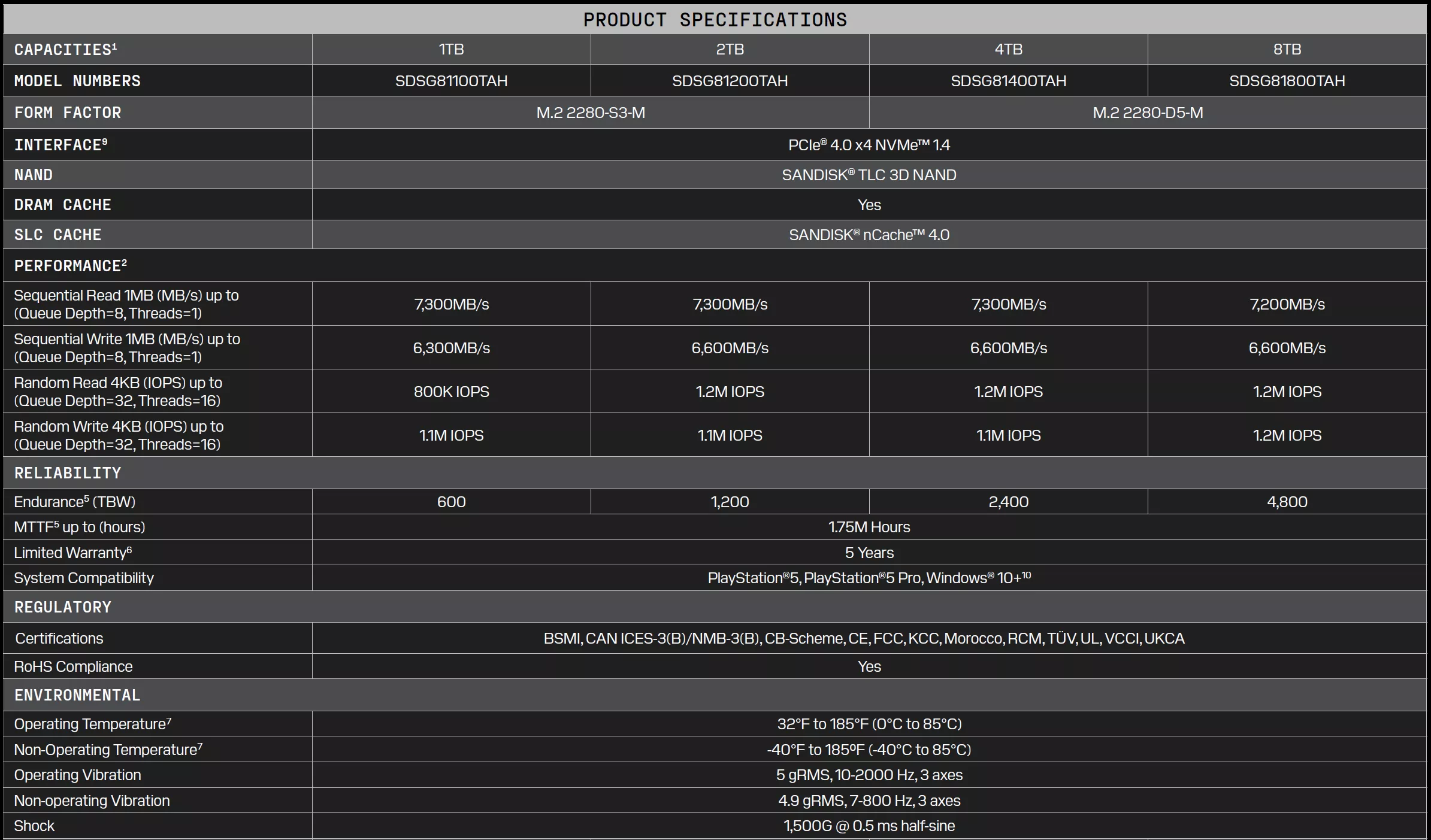
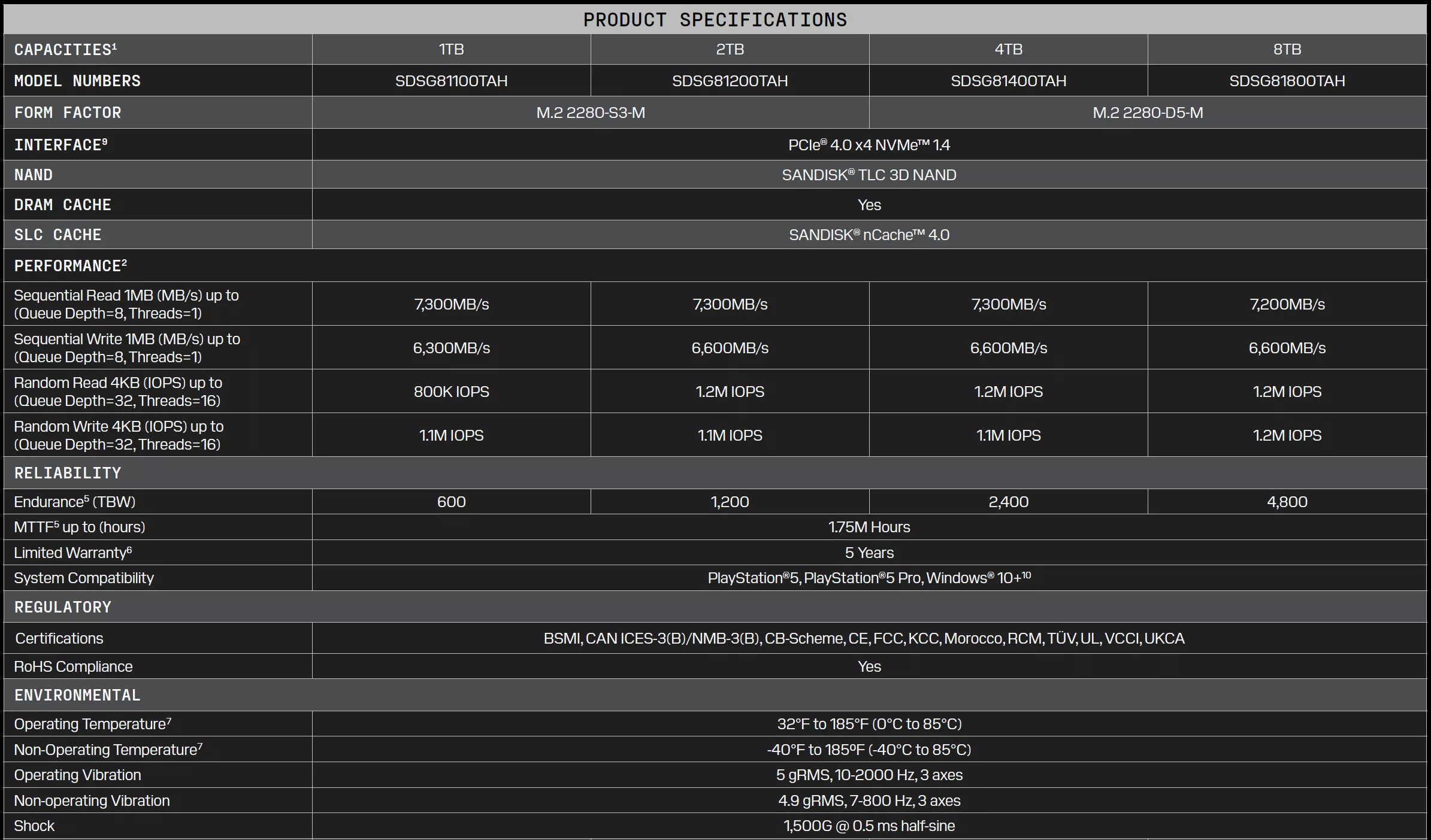
The Optimus GX PRO 850P lineup includes four NVMe SSDs with capacities ranging from 1TB to 8TB. The 1TB, 2TB, 4TB, and 8TB models are priced at $380, $760, $1,500, and $2,960, respectively. Sandisk is also offering introductory discounts on the drives, suggesting their regular retail prices will be even higher once the promotion ends.
Sandisk said the Optimus GX PRO 850P SSDs are officially licensed by Sony and feature an exclusive heatsink design with a PS5 logo on top. The PCIe 4.0 drives have reportedly been optimized for the console’s internal M.2 expansion slot, although they are also compatible with any PC motherboard that supports the M.2 2280 form factor.
Advertisement
Additional specifications include support for the NVMe 1.4 protocol, sequential read speeds of up to 7,300 MB/s, and sequential write speeds ranging from 6,300 MB/s on the 1TB model to 6,600 MB/s on the 8TB version. Endurance ranges from 600 TBW for the 1TB drive to 4,800 TBW for the 8TB model, while every SSD is backed by a five-year limited warranty.
Sandisk describes the Optimus GX PRO 850P lineup as a “no-compromise” storage solution that can significantly expand the number of games stored on a PS5 at once. However, the company neglected to mention that the 8TB model now costs about as much as five PS5 consoles. Only the 1TB version is currently “cheaper” than the console itself, and even that comparison is based on the higher PS5 prices Sony introduced earlier this year.
Unlike the Xbox Series X and Series S, the PS5 uses a standard M.2 NVMe SSD for expandable storage. If Sandisk’s pricing is too steep, plenty of third-party alternatives can expand the console’s storage at a much lower cost.
Advertisement
The Optimus GX PRO 850P drives are the latest example of hardware affected by ongoing supply chain pressures in the memory industry. The retail SSD market is shrinking, while consumer electronics prices continue to climb because of rising memory costs. AI companies are buying up virtually every memory chip they can secure, even though many planned US data center projects for 2026 have yet to materialize.
After some fierce competition over the past few weeks, 16 teams have qualified for the BMPS Grand Finals happening in Jaipur. And this time, the event is more important than ever. Not only has the prize pool been doubled to ₹4 crore, but the champion of the BMPS Grand Finals gets a direct entry to the esports World Cup happening in Paris later this year. Here’s what the schedule will look like on day one.
BMPS 2026 Grand Finals Day 1 Schedule & Timing
The live broadcast will begin at 2:45 PM IST. Fans can catch the games like on Krafton’s YouTube channel in Hindi, English, and a few other regional languages. Or, if you want to support your team live, head over to the Jaipur Convention Center. Tickets are available on the District app. Maps for today will include:
Match 1 — Rondo
Match 2 — Erangel
Match 3 — Erangel
Match 4 — Erangel
Match 5 — Miramar
Match 6 — Miramar
A total of 18 matches will be played over the course of this weekend. And the format is pretty simple. Points are awarded for each finish, and also for how long a team survives. In the end, the team with the most total points (position + finish) will be the winners.
‘We’ve seen an increase in Blu-ray orders of 10,000%’: I spoke to a Blu-ray and vinyl manufacturer about their Blu-ray sales and it’s given me even more hope for physical media’s survival
Physical home media has gone through a turbulent time the last few years. With the rise of streaming services, demand for physical media over the past few years has steadily declined, with people choosing the convenience of streaming over physical discs.
There’s still a dedicated fanbase of physical media collectors, though, and more recently streaming price rises and splintering means people have more interest just owning the stuff they want to watch. I’ve been writing about my hope for the resurgence of 4K Blu-ray, and physical media in general, since 2023. Now in 2026, I’m actually more hopeful than ever. It couldn’t come at a better time either, with the 20th anniversary of Blu-ray’s debut on June 20th, 2026.
I recently spoke to Kath Summersgill, Joint Group Head of Sales at Key Production Group, a manufacturer specializing primarily in music manufacturing with vinyl, cassette and CD. However, the group also works with Blu-ray, both video and audio varieties, and DVD. We discussed the state of Blu-ray production, and physical media in general, and she had some encouraging things to say.
Advertisement
Latest Videos From
Promising numbers
(Image credit: Future)
“We’ve seen an increase in Blu-ray sales of over 10,000%, particularly in Blu-ray Audio” Kath tells me. “That’s over the span of the past eight to 10 years.” For a format that’s been on the decline, that’s an incredibly encouraging number.
Kath then mentions the ERA (Entertainment Retailer’s Association) report from December 2025, which reveals sales revenue for Music, Video and Gaming sales. “Although there was an overall decrease in the physical video format, Blu-ray actually increased by 3%”. While that may not sound like a lot, it’s a positive after some particularly bad numbers.
If you read more into the 2025 ERA report, 4K Blu-ray sales increased 19.5%, which is an extremely encouraging number. The strongest selling disc of the year was Wicked, a disc I regularly use for testing AV equipment and one of the main highlights of our Blu-ray Bounty feature (more on that later).
Advertisement
So, why have 4K Blu-ray sales turned around? For that answer, we’ll have to look to streaming services.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
You can’t rely on streaming
One major issue with streaming is you don’t own the movie (Image credit: Shutterstock)
One of the most frustrating things people have with streaming services is the availability of movies. At one time or another, most people will have experienced a movie leaving a streaming service, only for it to either go to a rival service (that typically you won’t subscribe to) or for it just to disappear.
Advertisement
I’ve even seen horror stories of people buying movies on a streaming service that then also disappear. A Reddit thread in the r/AmazonPrime subreddit is a great example of this, where user u/Electrical_Paper6286 has had it happen “4 times between 2 movies”. Although the movies eventually returned, it’s a sign of how tentative the ‘ownership’ of movies on streaming platforms can be.
It’s one of the key issues affecting people’s trust in streaming services and something that’s driving people to physical media. Kath relates it to vinyl. “We know that vinyl is never ever going to replace streaming, but it exists very happily alongside it. I think that Blu-ray is the same, it offers different things that streaming doesn’t. It’s very much something that you can have and hold and you can keep and you can play over and over again.”
Kath also points out another issue with online-based movie and music streaming. “[With physical] you’re not at the whim of your internet connection speed, or whether or not certain libraries drop certain titles, licence changes”.
Advertisement
This is another frustration. Numerous times I’ve gone to watch a movie on streaming and due to connection issues , it’s either streamed in reduced quality, buffered or just not streamed at all. This isn’t a problem with physical media.
A passionate fanbase
Steelbooks are just one way passionate 4K Blu-ray fans indulge in the hobby (Image credit: Future)
As I mentioned above, I’m a budding collector of 4K Blu-ray. While I don’t have fully stacked shelves (yet), I do have a collector’s edition or two and more than a few steelbooks.
In FilmStories’ article about the ERA 2025 report, they mention that steelbooks and special editions helped the growth in 4K Blu-ray in the UK, with every one in 10 4K Blu-rays released having some sort of steelbook or special edition, and due to their higher prices, they made up £2 of every £10 spent on 4K Blu-ray in 2025.
Advertisement
I tell Kath I’m a sucker for nice packaging and she agrees and she relates it to a recent vinyl release that Key Production Group handled. “We find people are doing this. We did a vinyl release recently with 72 variants and even though the packaging was the same, the color of the vinyl was different.”
(I’m also a sucker for colored vinyl, with a rust-effect Jack White/Dead Weather release from a Third Man Records Vault collection being a particular highlight in my stack.)
While special editions are great, it’s also the work of independent distributors and manufacturers, delivering more excellent 4K restorations than ever, that gets more people to invest in 4K Blu-ray.
The Criterion Collection and Arrow Video are two of the big names, but other organizations such as Kino Lorber, Shout Factory, Boutique Home Video and the BFI are crucial. These companies are producing more sought-after titles and giving them excellent restorations that mean people want to own them in the best possible quality.
Advertisement
My ‘Blu-ray Bounty’ column has shown me all kinds of films that are are excellent for showing off your home theater, such as the new Lawrence of Arabia restoration (Image credit: Sony Pictures / Future)
In November 2024, I started the Blu-ray Bounty. This is an ongoing monthly column where I test the latest 4K Blu-rays from each month — and since its debut, the column has been growing.
We’re covering more discs than ever, covering a wider range of genres, and I have a feeling it’s only going to get bigger. I’ve produced tons of lists of excellent 4K titles that are perfect for showing off home theater systems, such as this 6 action movies list and 6 classic movies that show what 4K can do. and a good chunk of my reference discs for AV testing came from the Blu-ray Bounty.
I’m also an active user of the r/4kbluray subreddit and this is again one of the most passionate subreddits I’ve come across. Users update each other on releases, give their thoughts and reviews on the latest titles and always showing off their collections in the best possible way.
While it may well have been doom-and-gloom for 4K and Blu-ray in the last couple of years, I for one am hopeful for its future. What better way to celebrate Blu-ray’s 20th anniversary than with some good news.
Advertisement
The best 4K Blu-ray players for all budgets
Thinking of buying a new TV?
Try our TV size and model finder! You tell it how far you sit from your TV, we’ll tell you what size to buy based on viewing angle advice from image quality experts, and we’ll recommend our three top TVs at that size for different prices.
In a voice vote last week, the House of Representatives passed H.R. 6028, the “Legislative Branch Agencies Clarification Act.” The legislation is presented as a technical reorganization of some government agencies, but it’s much more than that.
H.R. 6028 would fundamentally change the U.S. Copyright Office, and not in a good way. The bill removes the Library of Congress’ current supervisory role over the Copyright Office, transfers several powers directly to the Register of Copyrights, and makes the Register a presidential appointee, confirmed by the Senate.
These changes would make an office that’s already hugely influential in copyright and tech policy much more political. EFF first explained why that’s a terrible idea when it came up nearly a decade ago. This bill, like the older one, weakens the few public-interest checks and balances that do exist. We hope the Senate promptly rejects this bill.
The Copyright Office Doesn’t Need More Politics—Or More Power
The Copyright Office’s main responsibilities are administrative and advisory. It registers copyrights, maintains records, grows the Library of Congress’s collections, and provides expertise to Congress on copyright law. But over the past two decades, the Office has also become increasingly influential in copyright policy debates that affect free expression, libraries, educators, competition—and everyday internet users. Unfortunately, it has not been a neutral advocate. The office’s recent report on the role of AI severely bungled the issue of fair use, prioritizing private licensing market “solutions” over user rights.
Advertisement
Going further back, the Copyright Office supported one of the most infamous anti-internet proposals of all time—the Stop Online Piracy Act (SOPA), a disastrous internet censorship proposal that sparked one of the largest online protests in history. The Office has repeatedly advanced positions that favored large entertainment-industry interests over the public interest.
The Office also plays a major role in the Digital Millennium Copyright Act (DMCA) Section 1201 rulemaking process, which determines when the public may lawfully bypass digital locks for activities such as security research, repair, preservation, or accessibility. EFF has used this process repeatedly to mitigate some of the worst harms of the DMCA. H.R. 6028 would move rulemaking authority over 1201 from the Librarian of Congress to the Register of Copyrights, further consolidating power within the Copyright Office itself.
The bill also makes the Register of Copyrights a presidential appointee confirmed by the Senate. Each administration will be pressured to pick nominees aligned with their own policy preferences, and the powerful copyright owning industries will invest even more heavily in lobbying to get their way, and influence the selection. This position should be focused on administrative ability and actual expertise, not lobbying and politics.
The Copyright Office Should Stay Connected To The Library of Congress
H.R. 6028 would do more than change who appoints the Register of Copyrights. It would sever the Copyright Office from Library of Congress supervision and transfer many Librarian powers directly to the Register.
Advertisement
The supervisory relationship exists for good reason, as the nation’s libraries have pointed out for years. The Library, while far from perfect, at least has the mission of preserving and providing access to knowledge. That should be an important public-interest counterweight in copyright debates. Congress has not explained how weakening the ties between the Library and the Copyright Office would serve the public better, or even seriously inquired about it.
This Bill Was Rushed Through
Back in March, EFF joined Public Knowledge, the Center for Democracy and Technology, library organizations and tech groups, urging Congress not to fast-track this legislation. We told them changes to the Copyright Office will have major consequences for the “speech rights, educational opportunities, and creative freedoms of all Americans.”
Yet Congress moved forward without any hearings on the bill, and without meaningful examination. H.R. 6028 creates a years-long separation of the Copyright Office from the Library of Congress, transfers significant legal authority, and restructures the appointment process for the nation’s top copyright official. Changes like that deserve hearings, debate, and public scrutiny. H.R. 6028 got none of that.
The Senate Should Stop This Bill
Copyright law exists to serve the public and “promote the progress” of science and learning. The institutions that administer copyright law should do the same.
Advertisement
H.R. 6028 would move the Copyright Office further away from that goal. Congress should be strengthening public-interest oversight of copyright policymaking, not looking for ways to concentrate more authority in a single presidentially appointed official.
The Senate should reject H.R. 6028. The Copyright Office should serve the public—not presidential administrations, and not industry lobbyists.





























































You must be logged in to post a comment Login