GMKtec has, however, made significant changes to the chassis, abandoning the flat square box typical of most mini PCs entirely.
Latest Videos From
A tower-style redesign built to fix old complaints
The EVO-X3 trades the EVO-X2’s flat footprint for a tall, triple-fan tower that resembles a steel-wrapped graphics card more than a conventional mini PC.
Advertisement
Despite the added height, the footprint remains compact, comparable in size to a PS4 console sitting upright, with GMKtec saying the redesign balances performance, efficiency, and thermal stability across continuous professional workloads.
Reviewers had criticized the EVO-X2 mainly for build quality issues, citing a cheap-feeling case, difficult internal access, and persistent fan noise under load.
This probably informed the design changes on the EVO-X3, though whether the new chassis actually resolves those issues remains to be seen.
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
GMKtec crushed the expectations of enthusiasts when it snubbed AMD’s newer Ryzen AI Max+ 495 chip for the Ryzen AI Max+ 395 silicon.
The processor combines CPU, GPU, and a large NPU rated at 50 TOPS, comfortably above the 40 TOPS threshold required for Microsoft‘s Copilot+ designation.
The EVO-X3 will be available in two storage configurations — 2 TB or 4 TB — and both versions carry the same 128 GB of LPDDR5X-8000 memory.
Advertisement
The device will also feature two M.2 2280 PCIe Gen4x4 slots, allowing total storage to scale up to 8 TB on either configuration.
GMKtec bundles its proprietary Claw+Wrangler suite directly onto the EVO-X3, a local-inference toolkit built for one-click setup and round-the-clock AI agents.
The company claims the 128 GB memory configuration can run models as large as 235 billion parameters entirely on-device, and none of that inference relies on cloud servers, which means no per-token fees and no user data ever leaving the machine.
Advertisement
A steep price jump for a familiar chip
GMKtec lists pre-launch pricing at $3,600 for the 128 GB and 2 TB configuration, rising to $3,849 for the 4 TB version, both described as discounted early figures.
Early access registration opened on June 22, offering a further $20 discount, with the global launch and shipping date both set for July 6.
For comparison, the EVO-X2 launched at $1,999 with 64 GB of memory and a 1 TB drive, making the jump considerable even accounting for the EVO-X3’s larger memory and storage allowances.
Advertisement
It is even a higher jump from the EVO-X1, the model that began GMKtec’s mini PC lineage in late 2024, priced near $900 with a Ryzen AI 9 HX 370 processor.
This means GMKtec has roughly quadrupled its mini PC pricing within two years, a jump of close to 300% from the EVO-X1’s original $900 price point.
It is even a high jump from where GMKtec’s mini PC lineage began with the EVO-X1 in late 2024, a Ryzen AI 9 HX 370 machine priced near $900
The EVO-X3 will face direct competition from other Strix Halo devices carrying the same 128 GB memory ceiling, including the MINIX ER939-AI Pro and the ONEXStation.
Rivian spinoff Also will finally start delivering its first e-bikes to customers next week, after months of delays related to unspecified supply chain issues.
The company told TechCrunch on Friday that the Launch Edition of its TM-B e-bike, which retails for $4,500, has started shipping from its manufacturer to its warehouse in the U.S. Also said it expects to deliver all Launch Edition bikes between next week and September.
Also began as a skunkworks project inside Rivian in 2022, after CEO RJ Scaringe started looking into making an e-bike to complement his portfolio of electric vehicles for the outdoorsy set. The company spent a few years tinkering with the idea, and even hired Jony Ive’s design firm LoveFrom to help with an early design, as TechCrunch first reported in 2025.
In March 2025, Rivian spun out Also as its own company, with $105 million in backing from Eclipse. The startup revealed its first e-bike, the TM-B, in October of last year. It originally targeted a “spring” 2026 ship date, but supply chain headaches got in the way, and the company pushed the delivery window to July.
Advertisement
“The primary factor driving our updated summer timeline is current stress on global supply chains. A rapid, industry-wide spike in demand for raw materials and electronic components has impacted key parts required for the TM-B. This has temporarily delayed our planned manufacturing ramp-up and pushed our first delivery dates past our original spring window,” the company wrote in June on a support page. “Our engineering and production teams are working around the clock to minimize these constraints without cutting a single corner on safety or quality.”
Also declined to say what components, specifically, caused the delay.
Also has big plans beyond the TM-B. The startup mostly refers to itself as a “vehicle” company and has plans to make four-wheel pedal-assist cargo vehicles for Amazon. The company is working on an autonomous delivery vehicle for DoorDash, too.
But for now, Also needs to focus on delivering its first e-bikes while navigating the next set of headaches for a company shipping products like these: customer service. On Friday, the last day of July, a number of customers were venting in a thread in the r/ALSOmicromobility subreddit about the repeated delays.
Advertisement
“I’m really frustrated by the lack of communication and the actual miscommunication/lies from Also regarding shipment timelines,” the original poster wrote. “Why do they keep making these promises about shipping timelines just to blow right past them without any communication or actual updates? It really makes no sense.”
“Hey we’ve still got a few business hours left in July. Maybe we’ll get an email later this morning ☺️,” a different user responded.
Not everyone was so patient.
“Couldn’t wait any longer and canceled my reservation,” another wrote.
Advertisement
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
The big picture: Putting your writing on the open web used to mean people could read it. Now, it also means dozens of crawlers can copy it into training datasets. Sure, anti-scraping tools such as robots.txt exist, but they only work if the bots themselves agree to stay away, which doesn’t always happen. Stricter measures were clearly needed, and now they have arrived in an innovative new form.
A Brazilian creative studio called Seneda & Abrucio has teamed up with Playtype, a Copenhagen-based type foundry, to build something that doesn’t rely on asking nicely to keep crawlers away. They call it ShieldFont, and it’s essentially a free, open-source web font with a twist. It works by showing you one sentence while presenting an AI scraper with a completely different one.
The thing is, you see rendered pixels on a screen. Most mass scrapers, on the other hand, simply grab the raw HTML underneath. ShieldFont exploits this difference through an automated process called OpenType glyph substitution. This technology is normally used to replace one or more typed characters with alternate glyphs that improve how text is rendered. In this case, however, entire words are swapped out, meaning a scraper can pick up only gibberish from the webpage.
Advertisement
Those swapped words are not picked at random, however. The studio’s dictionary pairs every word with another of the same grammatical type, so nouns get nouns and past-tense verbs get past-tense verbs. The words are sorted into roughly 250 pools that account for factors such as whether a noun is abstract or plural. About a quarter of the words in any given block are swapped this way.
Keeping the grammar clean matters because AI firms run scraped text through quality filters that discard anything that reads like nonsense. Seneda & Abrucio ran shielded text through FineWeb-Edu, a quality filter used to assemble a large public training dataset, and found that about one in 10 passages that passed before shielding still passed afterward.
Whatever gets through is fluent enough to be retained yet wrong enough to be useless at the same time. In fact, 55.8% of shielded passages in the studio’s testing no longer made the original factual claim.
That said, because the whole defense rests on scrapers reading code rather than screens, taking a screenshot of a shielded page and running OCR on the image can still recover the real words. Screen readers used by blind readers also work from the code, so they read the decoys aloud. ShieldFont ships with a beta feature that provides those readers with the real text instead.
Advertisement
For now, ShieldFont only handles English. The code can be found on GitHub for anyone who wants it. Developers and writers can simply install it as a React component to their websites.
Would you trust a ransomware extortionist to delete the data they stole? One bank certainly wants you to. Well over a month into a ransomware cleanup job, River Financial Corporation tells regulators that it “took steps to attempt to suppress the affected data, including obtaining representations from the threat actor that it deleted the data in its possession.”
In its Form 8-K filing with the SEC, River Bank did not explicitly state whether or not it paid any of the criminals’ ransom demands, although ransomware crooks are not commonly known to offer a victim data deletion for free.
The Register asked the company for a more explicit comment on this matter, but it did not immediately respond.
River Bank first disclosed its cyber woes to the Securities and Exchange Commission (SEC) on June 16, admitting from the outset that ransomware had been deployed across portions of its servers.
In response, it took affected systems offline, disabled admin accounts, and brought in external incident responders to determine the full scope of the damage.
Advertisement
Only July 6, messaging suggested it was aware that some data was “potentially impacted” by the attack, before admitting that certain data was removed from its environment four days later.
A side note on cyber verbiage
“Removed” is an interesting and unusual word to see in a disclosure when describing what an intruder did with their access.
The usual nomenclature is “stolen,” despite in most cases it being more accurate to say data was “copied” from a victim’s environment.
Some of the more nebulous announcements say data was “acquired” or “retrieved.” Sometimes “affected.”
Advertisement
The more cowardly ones simply stick with “accessed,” even though the word does not denote a change of ownership.
By July 10, River was aware the data had been removed, and two class action lawsuits had been filed against it, to top things off.
A week later, it told investors that an additional two class actions had been filed, bringing the total to four.
River has not yet completed its investigation, per its most recent filing, and therefore has not confirmed the full scope or impact of the attack. ®
An anonymous reader quotes a report from Reuters: OpenAI has discovered other instances in which autonomous agents have escaped containment as the company expands its investigation of the hacking incident at tech firm Hugging Face that drew global attention this month, two people familiar with the matter said on Friday. The new breakouts were uncovered during the company’s publicly announced investigation into how one of its agents escaped what was meant to be a contained testing environment this month, the two people said, and OpenAI is now looking into those instances as well. One of the sources said that the escapes were limited in nature and that none of the agents were thought to have left OpenAI’s network.
An OpenAI spokesperson referred to a statement issued by the company on Tuesday that said it was reviewing “broader activity from our models” in addition to the Hugging Face intrusion. The discovery of additional rogue behavior at OpenAI, even if limited in nature, could feed growing appetite for regulation coming out of the White House and elsewhere. The expanded investigation by OpenAI was launched shortly before its primary rival, Anthropic, disclosed that its models were also responsible for a series of break-ins that led to breaches at three other companies dating back to April, according to the two sources and a third source familiar with the matter. The recent discovery of other past breakouts at OpenAI has not previously been reported.
AI safety experts said the new disclosures paint a portrait of a group of cutting-edge labs whose ability to develop dangerous autonomous hacking agents outstrips their ability to keep them under control. “We have a whole industry where the people designing, developing and putting out these tools aren’t keeping up themselves to responsibly develop these things and keep them safe,” said Maurice Chiodo, a mathematician who works at Cambridge University’s Center for the Study of Existential Risk. Reuters could not establish exactly how many incidents OpenAI investigators found or the timings or circumstances under which they occurred. The three sources said OpenAI and outside experts were examining log data from earlier in the year in a bid to understand what took place.
Although generally glass isn’t associated with touch-sensitive surfaces, the addition of an ITO (indium tin oxygen) coating adds the exciting property of not only being transparent to the visible light part of the electromagnetic spectrum, but also of being electrically conductive. The logical result is that fine folk like [Sokol] simply had to use their newly acquired ITO-coated glass to make a button out of.
Here the easy option is of course to just use it as a capacitive sensor where the conductive ITO layer is used for the capacitive charge and the glass provides the insulator, but here we see it demonstrated how to create a pressure-sensitive implementation instead.
The measured conductivity on the ITO-coated glass in the video is pretty good, at just over 20 Ohm. This thus makes said capacitive button very easy to achieve. To make it a touch-sensitive button, two pieces of glass are used, with the ITO sides facing. Paper is used to create a spacer, after which the slight flex of the glass allows for the two ITO surfaces to touch, completing the circuit.
Advertisement
This is somewhat similar to how resistive touch screens work, with the position of the finger or stylus determined by the resistance between the two sides. In a hobbyist setup this would make it fairly easy to create a multi-position touch screen using just two pieces of glass and some firmware.
On a laptop screen in a dimly lit tent near the Donetsk front, a Ukrainian drone team steers its aircraft into the turret of a Russian T-72 and glimpses the start of an explosion before the picture dissolves into static. The strike is uploaded, verified, and scored against the point value assigned to the tank. The unit climbs a public leaderboard that ranks hundreds of drone teams, and the points are currency: a higher score buys better equipment, faster, from an online marketplace the warfighters compare to Amazon.
Washington is about to decide how the federal government will parcel out access to the most powerful AI, and it is drifting toward concentrating that capability in a few chosen hands, rationed by criteria no one outside the process can see. A country with foreign invaders on its own soil has spent the past year learning to do the reverse—and winning back ground as it does. From Luhansk to Lviv, Ukraine puts its best tools in the hands of whoever can use them and shares what it knows about the enemy as fast as it safely can, openly and by rule.
Behind the leaderboard sits a set of arrangements Ukraine built under fire. A marketplace lets frontline units order drones directly from hundreds of manufacturers, most of them small shops scattered across Ukraine. A procurement cycle that once ran months now takes days, and new designs reach the trenches within about a month of leaving the workbench, because the units doing the fighting, not a distant acquisition office, decide what they need in the field. Furthermore, their feedback goes straight back to the manufacturer, sometimes the same day. Because the manufacturing is dispersed rather than massed, no single Russian strike could ever change much.
Ukraine has been just as willing to share what it learns. Late last month its defense ministry opened a platform called TrophyLab that hands the technical anatomy of captured Russian weapons—schematics, known vulnerabilities, even physical samples—to a deliberately wide circle: allied militaries and intelligence services, and hundreds of Ukrainian and partner-country firms. Access is vetted and revocable, governed by published criteria. The premise is that knowledge of a threat is worth more shared than hoarded. This should be a rule everyone can see, rather than the whims of a distant official.
Advertisement
That combination, wide but rule-bound, is exactly what the executive order the White House issued in June fails to deliver. Faced with AI systems that can now find software flaws faster than any human team, the order promises early access to the most capable models to a few “trusted partners”—a phrase it never defines, routed through a classified process. It calls the arrangement voluntary. In practice it has not been: under national-security and commerce authorities the administration has already restricted, suspended, and then cleared frontier models, with no published criteria anyone outside the process can point to. Ukraine’s leaderboard may be a crude way to run a war, but it is at least a rule—public, legible, the same for every unit.
The deeper problem is what that opacity does. Ukraine found that capability does the most good spread widely, that a defense holds because it has no single point of failure, and that threat intelligence should travel by rule rather than favor. A trusted-partner tier governed by undefined discretion inverts all three: it concentrates the best tools among those already best equipped, builds the very chokepoint Ukraine works to avoid, and turns shared knowledge into something rationed by judgment no one can inspect. The United States already runs sector-based centers for sharing threat intelligence; the question the framework raises is not whether to centralize but whether the flow reaches the defenders who need it or stops at a favored few.
And there are real lessons for the United States. Ukraine’s openness may look like the underdog’s strategy, and the United States is the wealthiest, most powerful country on earth—but national strength does not mean every system is strong. The defenders who most need help are not the money-center banks and wealthy university hospitals; they are smaller institutions that, despite non-specific promises they’ll be helped, seem unlikely to benefit from this system as it’s set up. For them, a head start reserved for the already-strong is no help at all.
Ukraine did not arrive at any of this by design. It was forced into it, and used a mix of openness and clear rules to stop a much larger power in its tracks. Washington has the luxury of choosing on purpose but may be drifting towards a system governed by whims and favoritism rather than clear rules and standards.
Advertisement
Eli Lehrer is president and co-founder of the R Street Institute.
Hopefully the company secures houses better than it locks down SaaS systems
A leading name in home and business physical security, Brinks Home, recently said it identified unauthorized access to a portion of its IT systems, an intrusion ShinyHunters claims it carried out to steal millions of records from the security provider’s Salesforce instance.
Brinks Home hasn’t named the intruder or identified the affected system, but said the responsible party has threatened to leak information it claims to have taken.
Advertisement
“Brinks Home is working diligently to determine what information was involved and who may be affected,” the company statement said. “If the Company determines that personal information has been affected, it will notify those individuals as required and as appropriate.”
An FAQ page for the incident said that Brinks Home products and services weren’t affected, as far as the company knows at this point, so alarms and other security tools should be working without issue.
While Brinks may not have been very forthcoming with information, and lacks any sort of official way for media to communicate with it outside of sending a LinkedIn message it didn’t answer, the party that’s claimed responsibility has gone public with some details, and it’s none other than ShinyHunters with another claimed Salesforce breach.
According to leak site monitoring outfit Ransomware.live, ShinyHunters claimed to have obtained more than 4.9 million Salesforce records from Brinks Home “containing some PII.” The group threatened this week to leak the data along with causing “several annoying digital problems” if Brinks Home didn’t reach out by Thursday, July 30, to negotiate a ransom payment.
Advertisement
It’s not clear if Brinks Home has contacted ShinyHunters; Brinks Home didn’t respond to messages, and contacts The Register has for ShinyHunters appear to have changed, causing message and email rejections.
ShinyHunters has been a prolific Salesforce intruder of late, with the group claiming earlier this year to have stolen data from around 100 high-profile companies’ Salesforce instances. Salesforce has previously warned that an unnamed known threat actor group was actively scanning for public-facing Salesforce instances and abusing misconfigured guest accounts to break in.
Brinks Home is no longer part of the larger Brinks brand, with The Brinks Company telling us it sold the home security arm in 2010. Brinks Home’s parent company, Monitronics, has filed for bankruptcy twice since 2019; for customers’ sake, we hope its physical security services are better than its financial management and infosec. ®
Are you looking for a new job in the research and development space? Then check out SiliconRepublic.com’s list of companies currently recruiting.
Ireland’s research and development space is growing every day and with that comes new opportunities for graduates and professionals to find the perfect role.
There are plenty of vacancies for job hunters looking to break into R&D, so, if you are looking for a new role in research, take a look at these eight companies currently looking to boost their teams.
Accenture
Dublin-headquartered technology company Accenture is looking for research professionals to join its teams.
Advertisement
One vacant position is for a human and AI research lead. Among other responsibilities, the job will include building a strong pipeline of research themes and projects, integrating research, establishing visible leadership in the field of AI and developing the team’s craft, confidence and commercial maturity.
Another research-based role open to professionals at Accenture is the Dublin-located design lead position. As part of the job, the right candidate will support and execute design research activities, synthesise research to uncover insights and design rapid prototypes for stakeholder testing.
Fidelity Investments
Boston-headquartered financial services company Fidelity Investments has premises in both Galway and Dublin. The Galway team is actively recruiting for an onsite senior IT data analyst, which would call for skills in research. Additional job expectations alongside the research component will include working closely with business and technical teams to drive the creation of scalable and documented data design solutions.
Liberty IT
Liberty IT, the tech arm of the insurance firm Liberty Mutual Insurance, has offices in Belfast, Dublin and Galway. Currently, there are vacancies at the Belfast and Galway premises for a senior product designer, a role which will demand a professional with research skills. The chosen candidate will join the USRM product design team and will partner closely with the USRM user research team, as well as those in product, engineering and data science.
Advertisement
Among other responsibilities, the role will involve leading discovery with research, planning studies, synthesising insights and turning findings into clear recommendations, alongside work across UX disciplines, research partnerships, interaction design, service design and visual design.
Optum
Global healthcare company Optum has opportunities for Ireland-based employees at its Dublin and Letterkenny facilities, via a principal data scientist role that includes research responsibilities. Among the preferred qualifications is proven hands-on experience implementing and adapting published academic research into tangible solutions.
Additional roles requiring a similar skillset include a senior data scientist position, a principal data analyst role and a senior data analyst for healthcare economics, among others.
Regeneron
US biotechnology company Regeneron has a presence in Dublin and Limerick. Currently, there are a number of opportunities that qualified professionals looking to flex their research skills can avail of. A Limerick-based QC analyst in biochemistry role will involve conducting tests on in-process, release, stability and research samples.
Advertisement
There is a similar, temporary QC analyst HPLC role available, as well as opportunities for a QC microbiology associate scientist, whose work will include culturing organisms, conducting research and characterising them for use in investigations and cleaning development.
Stryker
Medtech Stryker wants to add a qualified professional to its Carrigtwohill, Cork team, via an advertised principal software engineer for R&D role. The right person for the job will be expected to lead system-level designs and technical direction for complex medical electronic systems with a strong embedded software and firmware component.
They will define system and software architecture, guide cross-functional engineering teams, and ensure delivery of safe and compliant medical device platforms.
Other opportunities for R&D professionals include: senior staff R&D design engineer in power electronics; senior R&D engineer in electrical design; senior staff R&D engineer, mechanical; and senior design engineer, R&D.
Advertisement
Vertiv
Digital infrastructure company Vertiv is looking to recruit a research and development engineer to its Burnfoot, Donegal office. The successful candidate will play a pivotal role in shaping the future of the company’s offerings. There is also a graduate research and development engineer’s position available, while another job vacancy that requires research skills is for a global product specialist position.
Viatris
Healthcare company Viatris is adding to its Dublin-based team, with a research role up for grabs. The company is recruiting for a specialist RIM data maintenance position, in which the ideal candidate will have previous experience in regulatory affairs or pharmaceutical experience in areas such as research and development, quality assurance, and compliance, among others.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Designed to deliver accurate Atmos audio with pin-sharp precision
Artists are delighted with the mixes, which required no tweaks
If like me you used to have, or still have, a backyard office or shed for working in, you’re going to be green with envy at the sight of mixing maestro Kurt Martinez’s personal Dolby Atmos studio.
The award-nominated Atmos expert designed and built his own backyard office and filled it with enviable gear, and if he doesn’t call it his Spatial shed I’m going to be very disappointed.
Martinez has been nominated for the prestigious Music Producers Guild award as Atmos Engineer of the Year, and he spent three years as the Head Dolby Atmos Mix Engineer at the world-famous Dean Street studios. He’s worked on live and recorded music by a host of stars including Kylie Minogue, Def Leppard, Soft Play, Billy Idol and Duran Duran.
Latest Videos FromTechRadar
Advertisement
Like many freelancers, Martinez figured that having a home office was a much better idea than a long commute into the city, and in Martinez’s case that decision was compounded by being a new dad. So he built an entire Atmos mixing studio in his back garden, doing everything himself apart from the electrics and internet connectivity.
(Image credit: Kurt Martinez)
How to make a spatial shed
As Mixonline reports, Martinez built the 2.5m x 3.5m garden office with a combination of porous timber walls to absorb the low frequencies, acoustic panelling in the ceiling and sides, a large rear bookshelf for dispersion, and acoustic slat panels at the front. There’s thick acoustic underlay below the laminate floor and even the furniture has a function: the armchairs and rug are there to absorb audio reflections.
With the building ready, the next step was to add the tech. Martinez uses a Pro Tools system based around an Audient ORIA, which sends audio to a Ginger Audio Ground Control Sphere that’s controlled by an Elgato Stream Deck+.
The speakers are striking. They’re PMC6-2 left and right monitors, a PMC6 center speaker, an 8 Sub LFE, and Ci30 height and surround monitors. Final mixes are tested on AirPods Max and a Sonos home theater setup to check that still sounds good on consumer Atmos hardware as well a studio-level setup.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
I used to have a very similar-looking setup for my own home studio, but sadly I didn’t have Martinez’s high-end gear or even more importantly, Martinez’s ears, which is why nobody’s nominating me for anything.
Advertisement
But I do love to see a good audio project, and it’s clearly been very successful: according to ETNow.com Martinez’s last five full-length records, which he mixed in that studio, required no tweaking at all when he tested them in large commercial studios.
All five of those records have been signed off by their delighted artists. I’d like to think that one of them was Shed Seven.
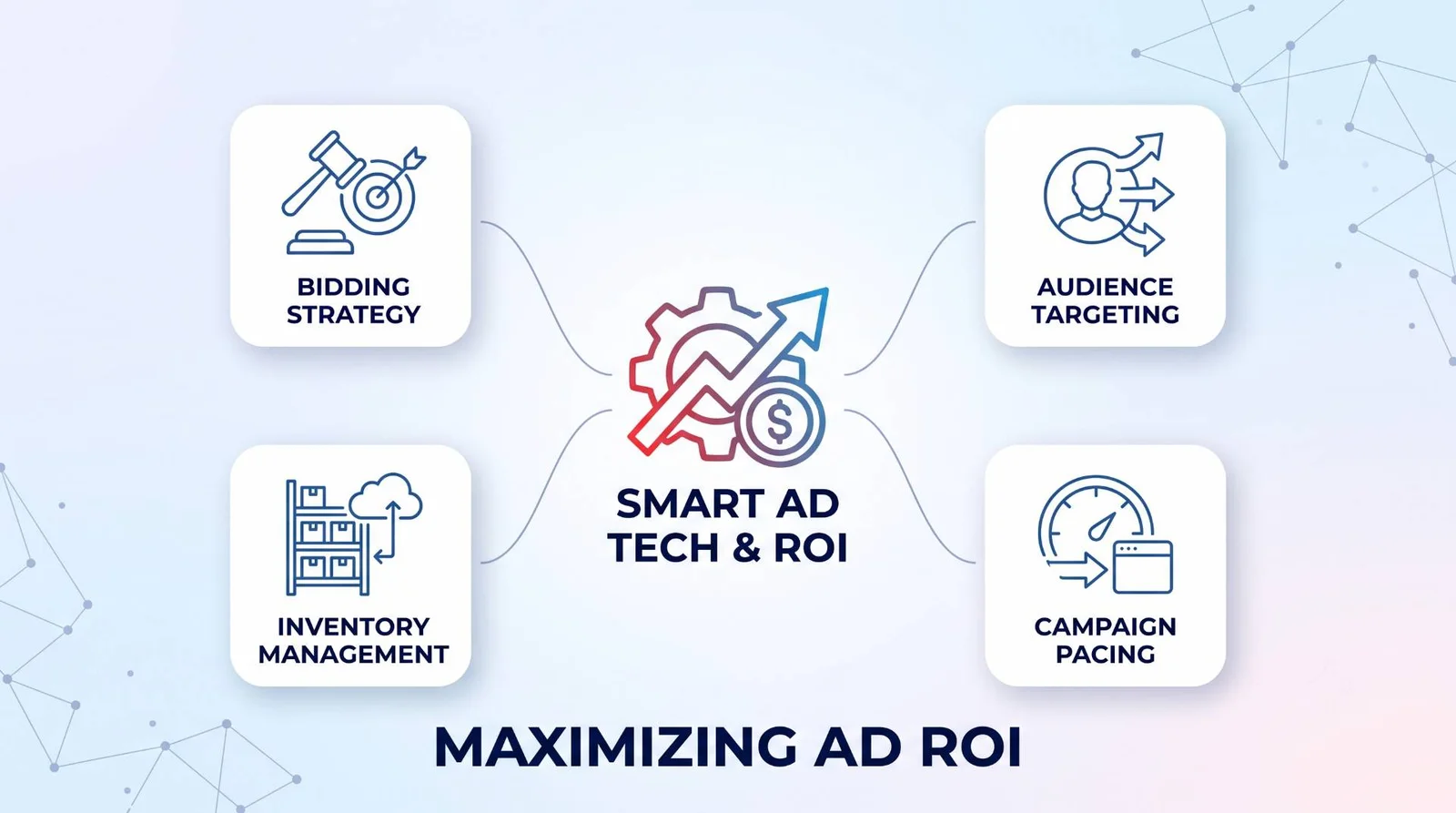
Maximizing return on investment (ROI) with smart advertising technology requires pairing automated machine-learning platforms with clean conversion signals, clear financial guardrails, and real-time inventory integration. By letting artificial intelligence manage high-frequency bidding and placement decisions while human strategists govern measurement and targeting rules, organizations eliminate ad spend waste and scale profitable campaigns.
Quick Take: How Smart Ad Tech Drives Campaign ROI
Smart advertising technology replaces manual guesswork with automated, data-driven execution across four core operational areas:
Operational Area
Traditional / Manual Method
Smart Ad Tech Method
Impact on ROI
Bidding Strategy
Static Cost-Per-Click (CPC) bids set per keyword or segment.
Eliminates overbidding on low-intent impressions; maximizes conversion value.
Audience Targeting
Broad demographic and manual interest targeting.
Predictive behavioral modeling and first-party lookalike expansion.
Reduces ad fatigue and targets high-propensity buyers at the right moment.
Inventory Management
Manual campaign updates based on weekly stock reports.
Direct feed synchronization between inventory software and ad networks.
Prevents wasted ad spend on out-of-stock items and low-margin inventory.
Campaign Pacing
End-of-month post-mortem reporting and delayed budget shifts.
Real-time performance telemetry and automated budget re-allocation.
Re-allocates underperforming ad spend dynamically within hours, not weeks.
The Hidden Causes of Wasted Ad Spend
Digital advertising budgets frequently drain through invisible inefficiencies long before a campaign reaches its target audience. When ad operations rely on manual oversight, marketers struggle to process the millions of auction variables generated every second across modern ad networks.
The most common failure modes in unoptimized campaigns include:
Advertisement
Irrelevant Keyword Bidding: Bidding aggressively on broad-match search queries that drive high click volume but lack purchasing intent. For B2B organizations, refining these match types is central to effective PPC campaign strategies for B2B SaaS, where low-intent clicks rapidly erode customer acquisition margins.
Over-exposure and Ad Fatigue: Showing the same creative unit repeatedly to the same user without frequency capping or dynamic creative variations, driving up CPMs while lowering click-through rates (CTR).
Off-Peak Ad Delivery: Running ads during hours or in geographic regions where potential buyers are inactive or unable to complete a conversion transaction.
Out-of-Stock Promotion: Directing paid traffic to landing pages where products or service slots are unavailable, paying for clicks that guarantee zero return.
According to industry benchmarks on programmatic ad spend statistics, automated digital channels now handle over 91% of global display media transactions. Organizations that fail to implement algorithmic oversight risk bidding against faster, data-enriched automated systems that capture high-intent users at a lower effective cost.
How AI and Machine Learning Optimize Ad Placements
Artificial intelligence transforms ad management by analyzing contextual, temporal, and user-level signals in real time during the milliseconds of an ad auction. Rather than relying on static rules, platforms deploy predictive models to calculate the exact probability of a conversion before submitting a bid.
Modern ad networks utilize auction-time machine learning algorithms to evaluate contextual inputs—such as device type, exact browser configuration, physical location, dayparting, and historical interaction paths. When a user conducts a search or loads a publisher page, the machine learning engine calculates the expected conversion rate ($eCVR$) and expected value ($eCPA$) to dynamically adjust the bid amount.
Furthermore, privacy-compliant machine learning models allow advertisers to deliver personalized experiences without relying on invasive user tracking. Independent studies on contextual behavioral modeling demonstrate that AI-driven contextual targeting achieves comparable relevancy and conversion efficiency compared to individual cross-site tracking profiles, protecting user privacy while preserving return on ad spend.
Pairing these algorithmic bidding models with a robust multivariate creative testing workflow ensures that the system continuously pairs high-performing creative messaging with the exact user segments most likely to convert.
Advertisement
Domain-Specific Automation: Dynamic Inventory and Feed-Driven Ads
For businesses with highly dynamic product catalogs—such as e-commerce retailers, automotive dealerships, real estate platforms, and travel providers—generic ad creative and static landing pages lead to severe budget waste.
Smart advertising technology addresses this challenge through automated data feed integration. By establishing a direct API link between enterprise inventory management systems and ad platform engines, campaigns automatically adjust ad copy, prices, and availability status in real time.
For instance, automotive dealerships leveraging automated vehicle ads pull live lot data including vehicle make, model, trim, mileage, and real-time inventory status. When a vehicle is sold, the system instantly pauses the corresponding ad set across search and display channels. This ensures ad spend is directed exclusively toward available inventory, shielding campaigns from high-cost clicks that result in bounce rates and frustrated customers.
Building a feed-driven automation structure requires connecting product metadata directly to conversion tracking. For details on structuring your data stack, consult our guide on establishing a resilient first-party data architecture.
Advertisement
Real-Time Analytics and Closed-Loop Optimization
Achieving sustainable ROI requires moving away from retrospective monthly reports toward real-time telemetry. Real-time advertising analytics provide immediate visibility into campaign health, allowing algorithms and media buyers to shift capital toward top-performing placements instantly.
To maximize the effectiveness of automated ad platforms, advertisers must implement value-based bidding. Setting a Target ROAS bidding strategy allows machine learning algorithms to adjust bids based on the predicted revenue value of each user interaction, rather than treating every conversion equally.
To ensure closed-loop optimization, advertisers should monitor four key operational metrics alongside raw ROAS:
Cost Per Acquisition (CPA): Evaluates whether automated bidding maintains target acquisition costs as campaign spend scales.
Conversion Delay Ratio: Accounts for time lags between initial click and ultimate transaction, preventing premature pausing of high-ticket campaigns.
First-Party Attribution Match Rate: Measures the proportion of offline conversions and CRM status changes successfully fed back into the ad platform’s learning model.
Incrementality Lift: Tests whether automated campaigns are generating net-new sales or merely taking credit for users who would have purchased organically.
Connecting ad spend data directly to downstream sales pipelines using customer acquisition cost models ensures that automated bid strategies optimize for actual bottom-line revenue rather than top-of-funnel vanity metrics. Organizations can monitor these feeds using unified real-time marketing analytics dashboards to maintain full operational visibility.
Common Misconceptions and Strategic Edge Cases
While automated ad technology significantly enhances media efficiency, relying on machine learning without strategic oversight creates distinct operational risks.
Advertisement
Misconception 1: Smart Ad Tech Runs on Complete Autopilot
AI algorithms excel at micro-optimization—adjusting individual bids, selecting placement variants, and matching audiences. However, algorithms cannot define business margins, establish positioning strategies, or assess creative brand fit. Human strategists must set strict cost ceilings, define conversion values, and maintain ongoing creative refresh cycles.
Automated bidding can drive highly qualified traffic to a website, but it cannot fix friction in the checkout or lead generation flow. If landing page experience, page load speed, or offer clarity are lacking, smart bidding will simply consume budget attempting to optimize against a flawed conversion funnel. Pair ad technology upgrades with a comprehensive conversion rate optimization framework to maximize landing page performance.
Edge Case: The Cold Start and Low Conversion Volume Problem
Machine learning models require baseline data density to train effectively. Campaigns generating fewer than 30 to 50 conversion events per month lack sufficient signal density for Target ROAS or Target CPA strategies. In low-volume scenarios, automated systems can experience “bidding starvation” (under-spending due to conservative bid confidence) or erratic budget burn. In these cases, media buyers should optimize toward micro-conversions (such as add-to-cart or lead form starts) or utilize hybrid manual/automated strategies until historical conversion thresholds are met.
For organizations spending across multiple fragmented programmatic exchanges, migrating to a centralized DSP provides cross-channel frequency capping and unified attribution. Evaluating whether your media spend justifies an enterprise ad stack is detailed in our guide to demand-side platform evaluation.
Advertisement
Key Takeaways
Feed Accurate Signals: Automated bidding platforms rely entirely on conversion data. Wire up offline conversions and revenue values so algorithms optimize for true profitability.
Automate Dynamic Inventory: Connect live inventory software directly to ad platform feeds to automatically pause ads for out-of-stock items.
Establish Data Thresholds: Maintain at least 30–50 conversions per month per campaign before enabling value-based bidding strategies like Target ROAS.
Guard Against Edge Cases: Audit automated campaigns regularly for conversion delay periods, attribution leakage, and ad creative fatigue.
Frequently Asked Questions
How much conversion volume is required before switching to Smart Bidding?
Google Ads and major ad platforms generally recommend maintaining at least 30 conversions within a 30-day window (50+ for value-based strategies like Target ROAS) before activating fully automated bidding. Campaigns below these thresholds may lack the statistical signal required for machine learning models to accurately predict conversion probability, leading to inconsistent spend pacing.
What is the core difference between Target CPA and Target ROAS bidding strategies?
Target CPA (Cost Per Acquisition) optimizes bids to achieve a specific cost per conversion, treating every conversion event as equal in value. Target ROAS (Return On Ad Spend) factors in variable conversion values—such as varying order sizes in e-commerce—adjusting bids dynamically to capture higher revenue return per dollar spent rather than just total conversion count.
How do automated ad platforms handle privacy updates and the loss of third-party cookies?
Modern ad tech platforms adapt to cookieless environments by combining privacy-safe first-party data integrations (such as Server-to-Server Conversion APIs) with AI-driven contextual signals and modeled conversions. By training machine learning algorithms on aggregate privacy-compliant data and contextual placement relevance, smart ad engines maintain targeting accuracy without relying on individual third-party tracking cookies.

























































You must be logged in to post a comment Login