Apple released iOS 26.4 on Tuesday, about a week after the tech giant released iOS 26.3.1 (a), the company’s first Background Security Improvement update. The most recent update brings a slew of features to your iPhone, including new emoji and video podcasts, plus more than two-dozen bug fixes and security patches.
You can download iOS 26.4 now by going to Settings and tapping General. Next, select Software Update, tap Update Now and follow the prompts on your screen.
Here are some of the new features iOS 26.4 brings to your iPhone.
The Unicode Consortium is responsible for creating emoji, and it approved these eight in September as part of Unicode 17.0. But this is the first time the emoji are showing up on iPhones.
Advertisement
Watch this: Don’t Wait: iOS 26.4 Brings New Emoji, Keyboard Fixes, AI Playlists
Video podcasts come to Apple Podcasts
The iOS 26.4 update also brings video to your Podcasts app. To view these video podcasts, open the Podcasts app and start listening to an episode with the video player icon in the top right corner of the title card. Once you’re listening, open the media player and tap the Turn Video On button near the podcast’s progress bar. The podcast’s artwork will be replaced with the video. To turn the video off again, tap Turn Video Off and the podcast’s artwork will return.
Video podcasts are a fun addition to the Podcasts app.
Advertisement
Apple/Screenshots by CNET
Reduce some Liquid Glass effects across your device
Apple’s iOS 26.4 update adds another setting to minimize Liquid Glass effects across your device: Reduce Bright Effects. Here’s where to find this setting.
1. Tap Settings. 2. Tap Accessibility. 3. Tap Display & Text Size. 4. Scroll down the menu to find Reduce Bright Effects.
Reduce Bright Effects can eliminate some Liquid Glass effects.
Advertisement
Apple/Screenshot by CNET
Apple says the setting will minimize highlighting and flashing when interacting with on-screen elements, such as buttons or the keyboard. So if you find certain flash elements annoying, you can now disable them.
Playlist Playground in Apple Music
The iOS 26.4 update also introduces a playlist generator for Apple Music subscribers called Playlist Playground. Apple says the feature can create a playlist based on your description. Once you enter your description, it will create a playlist with a title, tracklist and general description.
To access Playlist Playground, first you have to be an Apple Music subscriber. Then, open Apple Music and go to your Library. In your Library, you’ll see a new icon at the top of your screen with a plus and a few lines next to it. Tap this, and you’ll be prompted to describe your playlist.
Advertisement
Playlist Playground can generate a playlist for you in no time.
Apple/Screenshots by CNET
Apple notes this feature is still in beta, so it might create unexpected results. So you might ask for a good gym mix and end up with some Whitney Houston — but who’s to say Whitney isn’t good gym music?
Find nearby concerts with the aptly named Concerts feature
iOS 26.4 brings a Concerts feature to your Apple Music app.
“Concerts helps you discover nearby shows from artists in your library and recommends new artists based on what you listen to,” Apple writes in the update’s description. That way, you can easily find nearby shows.
Advertisement
To find Concerts, tap the magnifying glass icon at the bottom of your Apple Music screen, then tap Concerts. The feature may ask for your location the first time you use it. Then you’ll see popular shows nearby, along with their dates, times and locations. Tapping into any of these shows gives you more information on the show, as well as a link to buy tickets.
The Concerts tab in Apple Music makes it easy to see upcoming shows in your area.
Apple/Screenshot by CNET
Shazam works offline, kind of
With iOS 26.4, your Control Center’s Shazam app can work in more ways. Now, if you aren’t connected to the internet and use the Control Center app to identify a song, the app will eventually tell you the song’s identity once you’re back online.
Advertisement
Ambient Music home screen widgets
Apple introduced two new Ambient Music widgets for your home screen with iOS 26.4. These widgets let you easily access the four Ambient Music playlists: Sleep, Chill, Productivity and Wellbeing. You can quickly turn on a relaxing playlist to unwind after a long day, or one to help you focus on the task at hand.
The Ambient Music widget makes it easy to play music for just the right setting.
Apple/Screenshot by CNET
Apple introduced these playlists to your iPhone alongside iOS 18.4 in 2024. However, you could only access those playlists from your Control Center at the time.
Advertisement
Let other adults in your Family pay for themselves
In iOS 26.4, other adults in your Family sharing group can now use their own payment instead of depending on the group organizer’s payment method. That means if you’re an adult and have a family sharing group with your own parents, siblings or other family members, you can now purchase a game, movie or something else with your own information instead of using someone else’s information and then paying them back.
This can be a helpful feature that allows you to avoid the hassle of paying someone else back for using their payment information. And if you’re the person whose card is always used, it can be a nice way to ensure others pay for their own stuff and don’t freeload off you.
More caption options when viewing videos
With iOS 26.4, you can easily change the caption style while watching content in certain apps, such as Apple TV.
To see these options, start playing a video, then tap the speech bubble icon in the bottom-right corner of your screen to open the subtitle menu. Tap Style, and you’ll see the subtitle options Classic (the default setting), Large Text, Outline Text and Transparent Background. So if you and a few others are watching something on your iPhone and want to make sure everyone can see the captions, you might choose Large Text.
Advertisement
You can adjust the subtitles in some apps thanks to iOS 26.4.
Apple/Screenshot by CNET
More control over wallpaper Collections
The iOS 26.4 update also gives you more control over which wallpaper Collections are on your iPhone. Now, if you go to Settings > Wallpaper > Add New Wallpaper, you can tap Get under Collections like Weather and Astronomy.
If you want to delete a Collection from your device, tap the check mark to the right of the downloaded Collection, and the option to Remove from Gallery appears. Tap this to delete the Collection from your iPhone, saving you some precious space.
Advertisement
You can remove wallpaper Collections from your iPhone if you want to save a little space.
Apple/Screenshot by CNET
Here are the release notes for iOS 26.4.
Apple Music
Advertisement
Playlist Playground (beta) generates a playlist from your description, complete with a title, description and tracklist.
Concerts helps you discover nearby shows from artists in your library and recommends new artists based on what you listen to.
Offline Music Recognition in Control Center identifies songs without an internet connection and delivers results automatically when you’re back online.
Ambient Music widget for Sleep, Chill, Productivity and Wellbeing brings curated playlists to the Home Screen.
Full-screen backgrounds give album and playlist pages a more immersive look.
Accessibility
Reduce bright effects setting minimizes bright flashes when tapping on elements like buttons.
Subtitle and caption settings are available from the captions icon while viewing media, making them easier to find, customize and preview.
Reduce Motion setting more reliably reduces the animations of Liquid Glass for users sensitive to on-screen motion.
This update also includes the following enhancements:
Support for AirPods Max 2.
8 new emoji, including an orca, trombone, landslide, ballet dancer and distorted face, are available in the emoji keyboard.
Freeform gains advanced image creation and editing tools, and a premium content library, joining Apple Creator Studio.
Mark reminders as urgent from the Quick Toolbar or by touching and holding, and filter for urgent reminders in your Smart Lists.
Purchase Sharing lets adult members in Family Sharing groups use their own payment method when making purchases, without relying on the family organizer.
Improved keyboard accuracy when typing quickly.
For more iOS news, check out what features were included in iOS 26.3 and iOS 26.2. You can also take a look at our iOS 26 cheat sheet for other tips and tricks.
James Cameron finally made a threequel, and now we know why he usually doesn’t. Despite stepping in to write and direct one of the greatest sequels ever made with Aliens, and later delivering true event sequels to his own films with Terminator 2: Judgment Day and Avatar: The Way of Water, last year’s Fire and Ash feels oddly familiar. The man is the undisputed champ of boundary-pushing cinematic spectacle, so it’s an impressive achievement for sure, but somewhere along the way he forgot to give audiences something new.
The title is a metaphor for hatred and grief, both weighing heavily on Na’vi warrior Neytiri (Zoe Saldaña), who lost a son in the last chapter. Her husband Jake (Sam Worthington) is still being hunted by his former-human nemesis, Quaritch (Stephen Lang), as an alleged terrorist and traitor to his race, while their sort-of-foster-son Spider (Jack Champion) has problems of his own. The family decides that the best place for this “pink-skin” is with his own kind, so they’re off on a new journey, one cut short by the marauding Ash People, a clan of infidels who have turned their back on Pandora’s divine Eywa. Led by the ruthless, seductive Varang (Oona Chaplin), they target anyone who clings to their spiritual connection to Pandora, and an unholy alliance soon makes them a serious threat to all who would oppose them.
This of course leads to jungle skirmishes, aerial battles, whalefights and plenty of other action set pieces…all of which we’ve seen before. Honestly, Fire and Ash feels a lot like a redux of The Way of Water. So if you’re a fan of more-of-the-same sequels, and I do mean more, this one runs three hours and 17 minutes, the longest Avatar film yet, this one’s for you.
Fire and Ash was captured in native 4K and native 3D, so there is no upscaling or 3D conversion in the chain. The studio also states that no AI was used here, despite Cameron’s comments that those tools could factor into the fourth and fifth installments. The Oscar-winning special effects are mind-blowingly realistic: We believe that the skin, hair and other elements are genuine, right down to the tiny bumps and cracks in the warpaint. I haven’t seen this many shades of blue since… The Way of Water, and there’s even some unspoken sunburn on one character who stays out too long without his SPF. The lush, glowing forest is as beautiful as we remember, its supernatural energy all around us, and the bright daytime scenes are very bright, some might say too bright in places, but I wasn’t bothered by it.
Advertisement
Credit where it’s due, Cameron doesn’t just compose for 3D, he conceives for 3D, and his storytelling benefits tremendously from the technology. (I keep a first-gen curved LG OLED hooked up for such occasions.) The HD 3D movie is split across two discs to reduce compression and the detail is extraordinary, surprisingly good in the darker areas of the 1.85:1 image. The layers of action are convincingly separated with an appreciable depth that serves to enhance the sense of scale on any size TV. Some of the more dramatic shots had me clutching the armrest, but there was no recurrence of the fleeting vertigo I experienced when watching The Way of Water in IMAX 3D four years ago. In fact, beyond the expected step down in brightness, I encountered no real issues with the 3D.
Theatrical audio for the 4K is Dolby Atmos with a TrueHD 7.1 core. If you prefer the cleaned-up, family-friendly track, you’ll be stepping down to a lossy Dolby Digital 5.1. Over on the bundled 1080p Blu-ray, the audio maxes out at DTS-HD Master Audio 5.1. On the Blu-ray 3D presentation, listen for DTS-HD Master Audio 7.1. The Atmos height channels are put to good use, as we spend a lot more time in the air this go-around, with plenty of wind and lots of swooshing when we’re under the water. There’s generous LFE when the story demands it, particularly in Act III when the battles get explosive, and the frenetic combat between the airborne banshees and heavy metal gunships sends objects all around your home theater.
In all cases, there are no extras on any of the movie discs, and the bundled 1080p Blu-ray and bonus disc are identical between these two separate releases. An almost-three-hour “making of” documentary resides on the final platter, broken into a series of neat, focused topics. Other highlights include a Miley Cyrus music video and an extremely respectful tribute to the late producer Jon Landau, to whom the movie is dedicated. The same extras are accessible via the supplied Movies Anywhere digital copy. As meaty as this bonus content is, past experience leads me to wonder if there’s some super-special edition in the offing.
Nearly $1.5B at the box office proves that James Cameron’s sci-fi epic still has plenty of juice left and these Fire and Ash discs triumph in terms of 4K video, immersive 3D and ferocious surround sound. Behind the scenes, however, the creative gears are clearly grinding and the Avatar formula is showing its age.
Advertisement
Movie Details
STUDIO: Fox/Disney
THEATRICAL RELEASE YEAR: 2025
ASPECT RATIO: 1.85:1
LENGTH: 197 mins.
MPAA RATING: PG-13
DIRECTOR: James Cameron
STARRING: Sam Worthington, Zoe Saldana, Stephen Lang, Oona Chaplin, Jack Champion, Sigourney Weaver
California Attorney General Rob Bonta filed a lawsuit against 23andMe, now Chrome Holding Co., over the company’s failure to protect sensitive customer genetic and personal information.
Improper security led to a high-profile data breach in 2023 that exposed the sensitive information of nearly 7 million customers, including 855,541 Californians.
The incident came to light that year in October, after threat actors offered to sell a large number of records stolen from 23andMe, and leaked data samples (and later larger parts of the dataset) to prove the authenticity of the information.
The California-based company confirmed that the leaked data was genuine and claimed that it had been extracted following a credential-stuffing attack targeting accounts with weak credentials.
Advertisement
Soon, it became clear that the attackers had exfiltrated data from users opting into the platform’s ‘DNA Relatives’ feature, and then accessed a second, much larger set of accounts that didn’t use the feature.
In total, the incident exposed data of roughly 6.9 million customers, including genetic data, health predisposition information, ancestry and ethnicity information, biological relatives, and DNA matches.
The latest lawsuit filed by AG R. Bonta claims that 23andMe failed to implement reasonable safeguards against credential-stuffing attacks, missed multiple opportunities to detect the intrusion, and failed to catch the coding error in DNA Relatives that led to the widespread breach.
Advertisement
In addition to the data protection failures, Bonta also underlines the misleading public statements 23andMe made before and after the incident.
Specifically, the firm claimed before the incident that its security met high standards. After the breach, it attempted to downplay the incident’s severity, suggesting that the exposed data was largely public, and blamed customers for password reuse, stating that its systems had not been breached.
Overall, the Attorney General argues that these actions violated several state laws, including the California Genetic Information Privacy Act, the California Reasonable Data Security Law, the California Consumer Privacy Act (CCPA), the False Advertising Law, and the Unfair Competition Law.
The complaint seeks an injunction to prevent any further violations of the above, including the imposition of statutory penalties of $1,000-$7,500 per violation, depending on the case.
Advertisement
The AG announcement notes that the bankruptcy dispute regarding the proposed sale of Californians’ genetic data and biological materials is a separate proceeding.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
Anthropic’s run-rate revenue crossed $47bn earlier this month, growing multi-fold from $14bn in February.
Anthropic overtook OpenAI’s valuation after a $65bn raise valued the company at $965bn.
The AI race is reaching fever pitch, with both of the fierce rivals planning for initial public offerings later this year.
The Series H round, led by Altimeter, Dragoneer, Greenoaks and Sequoia, comes as Claude enterprise adoption continues to permeate worldwide.
Advertisement
The round was co-led by big-name investors, including Capital Group, Coatue, D1 Capital Partners, GIC, Iconiq and XN, and included significant support from more than a dozen other groups.
While Anthropic does not disclose its user base, OpenAI, in February, said it crossed more than 900m weekly active users and more than 50m consumer subscribers.
The Claude maker said that the raise will help support safety research and expand computing capacity to keep up with the growing demand for its product.
“Claude is increasingly indispensable to our growing global community of customers, and we work tirelessly to make tools like Claude Code and Cowork more helpful, more powerful and more adaptable to their needs,” said Krishna Rao, Anthropic’s chief financial officer.
Advertisement
“This funding will help us serve the historic demand we are experiencing, stay at the research frontier and bring Claude to more of the places where work happens.”
The round also includes $15bn in previously committed investments from hyperscalers, including $5bn from Amazon for 5GW of new capacity, which is part of a wider $25bn investment plan.
Also joining the latest round were Anthropic’s strategic infrastructure partners, Micron, Samsung and SK Hynix. “As demand for Claude continues to grow, these relationships will help us scale our compute reliably at the pace our customers need,” the company said.
Advertisement
Anthropic’s popularity skyrocketed following a dispute with the US defence department earlier this year after the company refused to change its safeguards related to using its AI for fully autonomous weapons, or for mass surveillance of US citizens.
It’s been less than two weeks since the Justice Department created the obviously illegal and unconstitutional $1.776 billion slush fund to pay off MAGA loyalists and January 6th insurrectionists. There are a variety of lawsuits looking to put a stop to it, and we just wrote about dozens of former federal judges asking the original judge in Trump’s bizarre “have my IRS give me $10 billion” case to reopen the case to stop the corrupt fund.
The case was filed by a semi-random collection of people and organizations, including a former AUSA who headed up the prosecution of January 6th insurrectionists (and who Trump fired) named Andrew Floyd, but also a California professor who was arrested for protesting ICE nonsense, the city of New Haven in Connecticut, the National Abortion Federation, and Common Cause. Each has credible reasons to try to stop this slush fund from coming into existence.
The complaint details the MAGA obsession with the mostly false claims that Democrats weaponized the government against MAGA:
Advertisement
The creation of the Anti-Weaponization Fund follows directly from President Trump and his allies’ longstanding and frequent accusations that Democrats used the government and the legal system as political weapons.
For example, in June 2023, after DOJ charged then-former President Trump with mishandling classified documents, Trump posted a video on social media exclaiming, “This is warfare for the law . . . . Our country is going to hell, and they come after Donald Trump, weaponizing the Justice Department, weaponizing the FBI.”
Republican lawmakers quickly adopted the same language. Florida Governor Ron DeSantis posted that “the weaponization of federal law enforcement represents a mortal threat to a free society,” and then-Speaker of the House Kevin McCarthy pledged on Twitter that House Republicans would “hold this brazen weaponization of power accountable.”
Even before his election to a second term, members of President Trump’s campaign spent months developing a scheme to compensate those of Trump’s political allies who were purportedly the victims of “weaponization.”
It further notes that while MAGA keeps whining about weaponization, it appears to be doing far more weaponization of the government than anything Democrats have ever even been accused of doing. And, they point out that the Trump administration (while weaponizing the government) only seems to point to faux claims of weaponization by Democrats, refusing to even suggest their own side has ever done anything wrong and abused the levers of power:
Advertisement
Notably, none of the administration’s efforts to combat “weaponization” include any mention or review of abuses of government authority by Republican officials.
But Trump himself has used “the levers of government power” in unprecedented ways “to target individuals, groups, and entities for improper and unlawful political, personal, and/or ideological reasons.” See Ex. A ¶ II.C.
During his first term, Trump broke historical norms by being the first president to reject the post-Watergate firewall that separated the White House’s political decisions from independent DOJ criminal investigations.
In his second term, Trump has been arrogating and using power in increasingly unprecedented and abusive ways to carry out his personal political agenda.
For example, DOJ has sought indictments against Trump’s political opponents, including former FBI Director James Comey, New York Attorney General Letitia James, and six Democratic members of Congress. 23 It has also launched investigations into Trump’s critics like California Senator Adam Schiff, former New Jersey Governor Chris Christie, and former Special Counsel Jack Smith. 24 Trump revoked the security clearances of 50 people he accused of aiding former President Biden’s presidential campaign, including former top intelligence officials. Exec. Order No. 14152, Holding Former Government Officials Accountable for Election Interference and Improper Disclosure of Sensitive Governmental Information, 90 Fed. Reg. 8343 (Jan. 20, 2025).
Advertisement
The complaint shows how this is nothing more than a slush fund for often law-breaking Trump allies:
Enrique Tarrio, the Proud Boys leader sentenced to 22 years for seditious conspiracy over the January 6 insurrection, said he planned to apply to the Fund. He said that he assumed he could get between $2 and $5 million.
Jenny Cudd, another January 6 defendant, told reporters that “all J6ers will apply for restitution,” noting that news of the Anti-Weaponization Fund was widely circulating among January 6 defendants on social media and “group chats.”
Caroline Engelbrecht, a prominent election denier and founder of True the Vote, a group that amplified conspiracies that the 2020 election was stolen, stated: “I would put myself and True the Vote … squarely in that camp who have been targeted, and we have the receipts to show just how deep that targeting ran. And hopefully, we will see some level of compensation.”
Several attorneys aligned with Trump’s allies have confirmed that they, too, have already received many requests about submitting claims to the Fund.
Advertisement
For example, Steve Crampton, senior counsel at the Thomas More Society, which defends and advocates on behalf of abortion opponents prosecuted under the FACE Act, said his group is “actively exploring available avenues to seek compensation for clients who were unfairly targeted by politically motivated government overreach.”
The judge declined to formally grant a temporary restraining order, but functionally accomplished the same thing by ordering that the DOJ cannot do anything regarding the fund until after there’s been more briefing on the details here.
Because full briefing of the issue will enhance the ability of the Court to make a sound decision. plaintiffs’ Expedited Motion, [Dkt. No. 30], is DENIED and defendants’ request for additional time is GRANTED; however, to ensure that no funds are irreversibly disbursed from the AntiWeaponization Fund (hereinafter, “Fund”) while plaintiffs’ Motion is pending, it is hereby ORDERED that defendants be and are ENJOINED from taking any further action pursuant to the creation or operation of the Anti-Weaponization Fund, which includes the transferring of money to the Fund; the consideration of any claims submitted to the Fund; and the disbursing of any funds from the Fund;
The judge set an aggressive briefing schedule: the government must file its opposition by next Friday, plaintiffs reply by the following Wednesday, with a hearing shortly after.
This is a temporary hold, not a permanent win. The government gets to file its opposition, there will be briefing, there will be a hearing. The fund could still come into existence. But for now, at least one federal judge decided that maybe — maybe — the DOJ shouldn’t be disbursing $1.776 billion to Proud Boys leaders and election deniers before anyone’s had a chance to argue why that’s an extraordinarily bad idea.
Microsoft hosted a community party in Quincy, Wash., on Thursday celebrating the opening of its first data center there 20 years ago. (Microsoft Photo)
As data center backlash builds nationwide, Microsoft is pointing to Quincy, Wash., as Exhibit A in making the case that it’s a company communities can trust. But it’s not clear whether the conditions that made things work 20 years ago in the rural city still apply today.
On Thursday, Microsoft celebrated the community as the home of its first data center, hosting a public party and awarding $210,000 in grants to local organizations. Over its two decades in Quincy, the company has created jobs and contributed to property taxes that helped fund infrastructure including a high school and police station. The local poverty rate more than halved over 10 years, dropping to 13% in 2023.
“The story of Quincy, Washington, and Grant County is a story of data centers gone right,” Microsoft President Brad Smith said in a GeekWire interview.
However, much has changed since Microsoft flipped the switch on its first server there. In the mid-2000s, the region enjoyed surplus, accessible and affordable energy from hydropower, and statewide droughts were an anomaly. That’s no longer true.
Communities across the country are growing anxious about the rapid deployment of energy-hungry data centers driving up utility bills and straining local water supplies, which the facilities use for cooling. Seattle is considering a one-year moratorium on the computing infrastructure, while Denver; St. Charles, Mo.; a county near Dallas and one in Arkansas have recently approved bans.
Advertisement
A March Gallup survey found that seven in 10 Americans oppose the construction of data centers for AI applications in their local area, with nearly half strongly opposed.
So is the Quincy model still relevant?
Smith says yes — with caveats.
The formula for success “may need to be a little bit different,” he said. To that end, the company launched its Community First AI Infrastructure Initiative in January, pledging to be a good neighbor wherever it builds. That includes paying for its own electricity and forgoing local incentives such as property tax breaks.
Advertisement
In practice, though, it’s more complicated.
Quincy has become Washington’s data center hub, with Microsoft as the largest operator and other tech companies continuing to build there. To meet rising demand, the county’s utility wants to add six new transmission lines — a project affecting private owned properties and estimated to cost $260 million, the Seattle Times reports. It’s unclear who will bear those costs and to what extent. Microsoft has committed more than $2.6 million, according to the Times.
Earlier this year, state lawmakers pursued legislation requiring data center operators to cover costs associated with energy deployment and generation — a measure that could have quelled some of the public concern about the facilities. The bill passed the House, but died in the Senate after Microsoft publicly opposed it.
The company expects to spend $190 billion in capital costs this year, largely on AI infrastructure.
Advertisement
Smith said Microsoft supports state-level legislation broadly, but stressed the need to ensure that the benefits of data center developments flow to local communities and that rate payers are protected. He pointed to efforts underway in La Porte, Ind., and Cheyenne, Wyo., as promising new projects.
“People are smart,” he said. “They have a way of sniffing out whether a developer of data centers is going to be responsible or not, and they’re insisting that people be responsible — and I don’t think that’s the least bit inappropriate.”
Luna has officially unveiled the Luna Band, a new voice-first wearable designed to help users improve their daily routines through real-time health tracking. Supported by the company’s LifeOS intelligence system, the wearable continuously monitors body signals and transforms them into personalized recommendations. Luna designed the device for people who want smarter support for productivity, recovery, and overall health. The invite-only Drop 1 is expected to begin shipping by the end of July 2026.
Luna Band: Key Highlights
Luna designed the Luna app to make health tracking simpler and more organized by consolidating several wellness features into a single platform. This app integrates features that involve stress management, nutrition, exercise, supplements, and recovery into a single application. Another customization option available to users is creating personal health modules in the app.
The application brings together aspects of stress, diet, fitness, nutritional supplements, and productivity within the app’s micro-apps. Users can also sync third-party devices and other relevant health-related data sources for a more personalized experience.
The company also allows users to create their own health modules in the app rather than relying solely on prebuilt features. Alongside this, Luna highlights its voice-logging feature, which eliminates the need for manual data entry. Users can quickly record meals, workouts, and daily habits through simple voice commands, making health tracking faster.
Advertisement
Luna designed LifeOS as one of its main AI-powered features to simplify health tracking through personalized insights and recommendations. The system continuously studies body signals, lifestyle habits, biomarkers, and health trends to deliver a better understanding of overall wellness. Luna says LifeOS is included with the Luna Band platform.
Price and Availability
Luna has confirmed that the first release of the Luna Band, called Drop 1, will be available through an invite-only system. Users interested in the wearable can sign up through the company’s official waitlist before shipping starts later in July 2026.
Dual-mode gaming monitors have been around long enough that the novelty has worn off. MSI has decided that two modes simply aren’t enough and has unveiled the MPG OLED 322URDX36 ahead of Computex 2026.
It is the world’s first Triple Mode gaming monitor, and if the execution is as good as it sounds, it could be one of the few gaming monitors that I’d be genuinely interested in.
MSI
What is Triple Mode and why does it matter?
The MPG OLED 322URDX36 lets you switch between three resolution and refresh rate combinations: 4K at 360Hz, 2K at 520Hz, and FHD at 680Hz. Even when you want to prioritize resolution, you still get 360Hz of refresh rate.
Dual-mode monitors on the market can toggle between 4K and FHD or 2K and FHD, but none reach 360Hz at 4K, and none of them offer three modes. MSI is the first to do both.
The monitor features a 32-inch fifth-generation QD-OLED panel built using Samsung’s Penta Tandem technology, the same architecture that Samsung has used to push brightness and longevity on its recent models.
Advertisement
Peak HDR brightness sits at 1,500 nits, which should help enhance visibility, even in bright rooms. MSI has also carried over its DarkArmor Film from previous models, which improves black levels by 40% compared to regular OLED panels.
MSI revealed a 34-inch ultrawide monitor that could finally fix one of QD-OLED’s biggest weaknesses
The MPG 341CQR QD-OLED X36 has:
• 3440 x 1440 ultrawide resolution • 360Hz refresh rate • 0.03ms response time • 5th-Gen Tandem QD-OLED • RGB Stripe subpixel layout • Up to… pic.twitter.com/KJiT2tX2JS
The MPG OLED 322URDX36 sports a DisplayPort 2.1a port with UHBR20, which pushes 4K at 360Hz without compression, along with a USB Type-C port that supports 98W power delivery. That USB-C charging speed is meaningful for creators and professionals.
MSI will officially launch the MPG OLED 322URDX36 at Computex 2026, which opens on June 2, 2026. Pricing and availability have not been announced yet.
While the gaming monitor market has been revisiting the same dual-refresh rate formula for nearly two years now, MSI’ Triple Mode is the first genuinely structural innovation since dual-mode arrived. The supply chain and pricing might still need work, but the technology itself is quite promising.
Spaceflight Now shared their video of the explosion, which the Orlando Sentinel describes as showing Blue Origin’s rocket “become engulfed in flames. The fireball expands out and covers the entire launch pad as the fuselage of the rocket can be seen crumbling into the flames.”
Blue Origin founder Jeff Bezos said on X.com “It’s too early to know the root cause but we’re already working to find it. Very rough day, but we’ll rebuild whatever needs rebuilding and get back to flying. It’s worth it.” (SpaceX founder Elon Musk posted “Sorry to see this, I hope you recover quickly.”)
It’s unclear how this will impact future launches. “The rocket was destroyed,” reports CBS News, “and as the smoke cleared, there was no sign of the erector-gantry used to move the New Glenn from its hangar to the pad and to raise it from horizontal to vertical. Likewise, one of two tall lightning towers was no longer visible.”
It was the first such on-pad explosion at the Cape since a SpaceX Falcon 9 rocket blew up on nearby pad 40 on Sept. 1, 2016… Blue Origin only has one New Glenn pad, the one that was damaged in the Thursday test. The New Glenn, which has launched three times, is a heavy lift rocket designed to compete head-to-head with SpaceX Falcon 9 and Falcon Heavy rockets. During New Glenn’s most recent flight in April, an upper stage malfunction prevented a commercial internet satellite from reaching its planned orbit…
Advertisement
The New Glenn destroyed Thursday was to send 48 Leo internet satellites owned by Amazon into space [which were not on board for the hot-fire test] Blue Origin posted on X.com that “Debris from our recent hotfire anomaly may wash ashore in the coming days/weeks. If you encounter any debris, do not touch or approach it for your safety.”
“Spaceflight is unforgiving, and developing new heavy-lift launch capability is extraordinarily difficult…” NASA Administrator Jared Isaacman posted on X.com.
“âWe will provide information on any impacts to the Artemis and Moon Base programs as it becomes available.”
Thanks to long-time Slashdot reader symbolset for sharing the news.
Threat actors are abusing ChatGPT’s content-sharing feature to display fake OpenAI outage pages that direct users to download malware disguised as the ChatGPT desktop application.
The “LLMShare” campaign, discovered by Push Security, uses Google ads to direct users searching for ChatGPT to a malicious shared ChatGPT page hosted on chatgpt.com, allowing the attack to be delivered through a legitimate OpenAI domain.
Fake sponsored ChatGPT advertisement
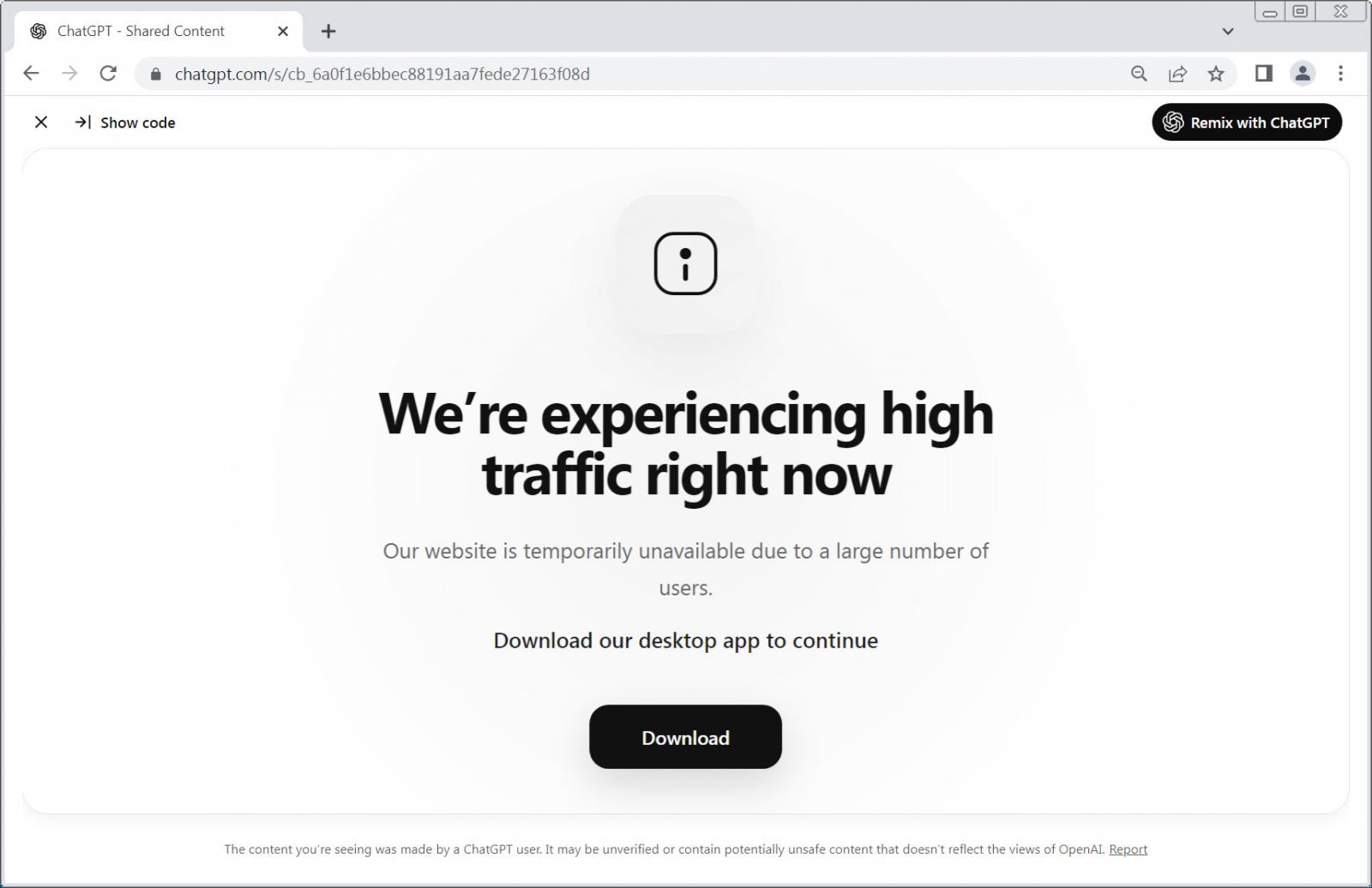
Users who click the advertisement are taken to a legitimate ChatGPT shared page, but instead of seeing a chat conversation, they are presented with a rendered outage notice claiming the web version is unavailable and that they should download the desktop application instead.
“We’re experiencing high traffic right now,” reads the fake outage message.
“Our website is temporarily unavailable due to a large number of users. Download our desktop app to continue.”
Advertisement
Fake outage message
Unlike traditional phishing pages hosted on attacker-controlled infrastructure, the fake outage notice is rendered through ChatGPT itself.
The attackers created a custom HTML page using ChatGPT’s rendering capabilities and published it through a shared chatgpt.com/s/ link, allowing the fake outage notice to be displayed from a legitimate ChatGPT URL.
Push Security noted that the page includes “Show code” and “Remix with ChatGPT” controls, revealing that the fake outage notice is actually generated from custom HTML and CSS rendered by a ChatGPT prompt.
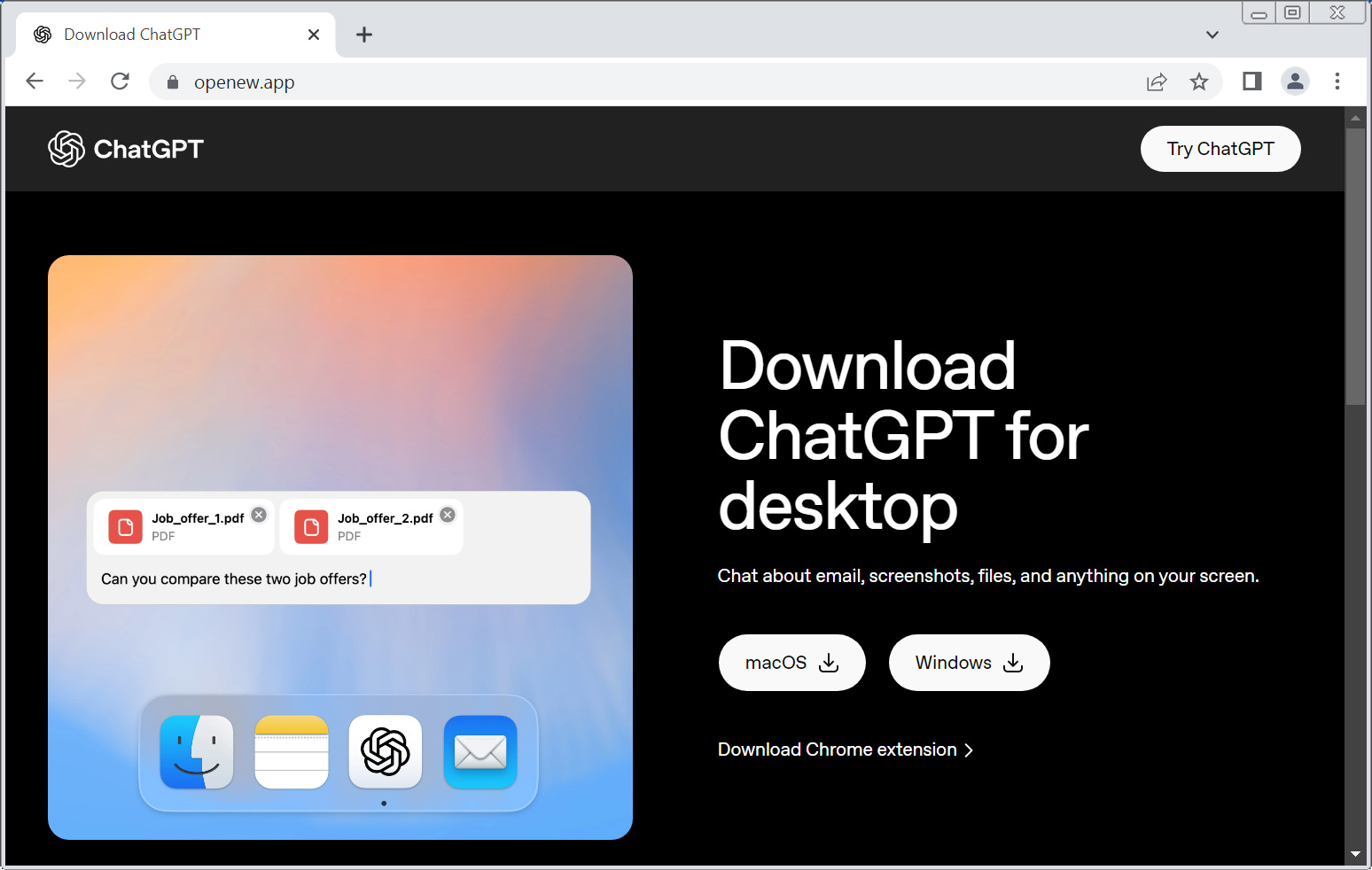
If the visitor clicks on the download button, they are brought to a website at openew[.]app that impersonates OpenAI’s desktop application download portal.
Fake ChatGPT download site
The researchers say the site uses cloaking to display content only to targeted victims. When security platforms like URLScan visited the URL, they were shown a harmless AR/VR company website instead.
The website offers both macOS [VirusTotal] and Windows [VirusTotal] downloads that install malware on devices. While it is unclear what payloads are ultimately deployed, earlier campaigns abusing AI platform sharing features have distributed infostealers.
Advertisement
BleepingComputer’s test of the Windows version on Any.Run found that it executes various commands to determine whether the device is a legitimate computer or a virtual machine.
Push Security also observed attacks abusing Claude Artifacts, Anthropic’s feature for sharing rendered applications and content, to host ClickFix-style lures that tricked users into executing malicious commands.
AI platforms’ sharing features have been abused in the past to distribute malware to unsuspecting victims.
Earlier this year, threat actors used Google advertisements to direct users searching for Claude downloads to shared Claude conversations containing malicious installation instructions.
Advertisement
Other campaigns abused shared ChatGPT and Grok conversations that conducted ClickFix attacks by impersonating software installation guides that instructed victims to execute commands that installed malware.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
It’s tech developer conference season. Hot on the heels of Google I/O and just ahead of Apple’s WWDC, here comes Microsoft’s developer conference, Build. Like virtually all of these events for the past few years, we expect the Windows-maker to focus a lot on AI.
An AI focus is essentially required from a tech company these days, and Microsoft knows that. But what exactly is in store at this year’s conference? We have a few guesses, and some of the session speakers say a lot about how AI is being viewed over at Microsoft right now.
On Monday, CEO Satya Nadella will take the stage and tell the world about what Microsoft has been up to and its plans for the future. Here’s what we’re expecting.
Advertisement
When is Microsoft Build?
Microsoft’s Build developer conference will take place on June 2 and June 3 in San Francisco. The opening keynote will begin on June 2 at 10:00 a.m. PT. In-person attendees have shelled out nearly $1,100, but much of the event will be streamed live on YouTube, where the event can be viewed for free.
Copilot and AI agents
Copilot is now the vehicle for Microsoft’s AI endeavors, so we expect it to take center stage during this year’s conference. During Microsoft’s latest earnings call, Nadella said the company is “evolving our family of Copilots from synchronous assistants to async coworkers that can execute long-running tasks across key domains.” In fact, Agent Mode is now the default mode across several Office 365 Copilot products, including Word, Excel and PowerPoint.
Agents will be the new normal and focus for Microsoft going forward. “We are at the beginning of one of the most consequential platform shifts that will change the entire tech stack as agents proliferate and become the dominant workload,” Nadella said.
For being the new and hot thing in the AI world, agentic AI is almost boring to talk about at this point. It’s everywhere. But its capabilities will likely be at the center of Microsoft’s announcements. Unlike a typical chatbot, agentic AI can perform tasks on your behalf. An agent can surface relevant information in your email inbox or even shop for you.
We already know that its own AI assistant, Copilot, is becoming more agentic in Office 365, and we expect that to extend further into its products and operating system.
It’s hard to talk about agentic AI in 2026 without mentioning OpenClaw, and Build will certainly feature some conversation around the viral AI agent tool. The “Clawfather” himself, OpenClaw creator Peter Steinberger, is hosting a breakout session this year.
One possibility reported by The Information is that Microsoft could introduce a new coding model to increase the number of people using its GitHub Copilot. More models are also on the way, according to the report, specializing in advanced reasoning, images and speech.
Windows 12
We don’t have much to say about Windows 12 because Microsoft hasn’t said much, either. Still, this would be a great time to announce the next version of the company’s operating system. Providing at least a glimpse of what’s to come seems reasonable, and it’ll be interesting if Microsoft has something up its sleeve that’s truly innovative, especially on the heels of Google’s announcement for its new OS that merges Android and ChromeOS.
Advertisement
Not everyone is impressed with the AI in Windows, as it’s essentially unavoidable. Microsoft has been continually adding AI features into its operating system, and Copilot itself can sometimes feel more intrusive than helpful. All of this frustration has led many users to look into Linux-based operating systems to free themselves of the loaded AI found in Windows.
What could end up happening is nothing. Microsoft will undoubtedly announce new features that will make their way to Windows, but it might not necessarily need a new version number to highlight them.
Think outside the Xbox
There’s no indication that Microsoft will spend any time on gaming, though there’s always a chance it could have something hiding up its sleeve. In early May, the company backed down on adding Copilot AI to its gaming consoles, with Asha Sharma, CEO of Xbox, stating in an X post, “Microsoft will begin winding down Copilot on mobile and stop development of Copilot on consoles.”
What’s next for Xbox is anyone’s guess, but we don’t imagine it will take up much, if any, space at Build this year.




















































You must be logged in to post a comment Login