
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.




Resolve AI, the production-operations startup backed by Greylock and Lightspeed Venture Partners, today announced a sweeping expansion of its platform that introduces always-on background agents, a redesigned investigation architecture, and a shared workspace where engineers and AI agents collaborate in real time on live incidents.
The centerpiece of the release is a new multi-agent investigation system developed by Resolve AI’s in-house research lab. Instead of deploying a single AI agent to diagnose a production failure — analogous to a lone engineer pulling an on-call shift — the platform now dispatches a coordinated team of specialized agents that pursue multiple hypotheses in parallel, independently verify each other’s conclusions, and construct complete causal chains from root cause to symptom. The company says the architecture delivers more than a twofold improvement in root cause accuracy on its internal evaluation benchmarks compared to earlier versions of its platform.
“Think of a single agent being on call, the way a human would be,” Resolve AI CEO and co-founder Spiros Xanthos told VentureBeat in an exclusive interview ahead of the announcement. “We now have a team of agents that all work together, almost like a team of humans debugging an issue, and that has improved quality by 2x.”
The announcement arrives at a moment of acute tension in the software industry. AI-powered code generation has exploded in adoption, enabling engineering teams to ship dramatically more software than they could two years ago. But keeping that software running in production — debugging it when it breaks, monitoring it after deployment, auditing its health — remains overwhelmingly manual. For a company that raised a $125 million Series A at a $1 billion valuation earlier this year, Resolve AI is making a direct bet that the operational side of the software lifecycle is the next major frontier for AI investment.
Any accuracy claim from a startup warrants scrutiny, and Xanthos was candid about both the scale and limitations of the evaluation. The 2x figure comes from internal benchmarks, not a third-party audit, though the evaluation set was built to mirror the complexity that Resolve AI’s enterprise customers encounter daily.
“These are very hard, complex evals that we built over time to represent real-world examples,” Xanthos explained. “This is not customer data, but these evals represent difficult cases similar to what we’ve seen at some of the largest tech companies we work with.” He described the set as comprising hundreds of cases that reflect the kinds of production failures encountered at companies like Coinbase, Salesforce, DoorDash, and Zscaler — all named Resolve AI customers.
The practical impact of that accuracy gain is significant. Resolve AI’s agents now act as first responders for every on-call alert, typically triaging within five minutes before a human engineer even becomes involved. In previous public disclosures, the company has cited DoorDash reducing time to root cause by up to 87 percent. When asked to contextualize that figure, Xanthos described the typical baseline.
“When something goes wrong, it might take five to 10 minutes for a human to even get their laptop and connect,” he said. “The typical MTTR is in the tens of minutes, sometimes hours, depending on severity. So an improvement of 80-plus percent — four to five times faster — is actually huge. It’s something we’ve never achieved before with AI, tools, data, or observability.”
One of the core challenges in applying large language models to high-stakes production environments is their tendency to generate plausible-sounding but incorrect answers — a failure mode that, in the context of a live outage, could send an engineering team chasing the wrong fix while a service stays down.
Xanthos acknowledged this directly. “This is a very common issue with models out of the box,” he said. “They always try to give you an answer, and if they don’t have enough evidence, they’ll give you the best possible answer — which is likely to be wrong.”
Resolve AI’s countermeasure is a system of layered verification among its agents. Each agent investigating a hypothesis must cite every piece of evidence it relies on and present that evidence to another agent for independent review. The investigating agent must construct the full causal chain — from root cause to symptom — and peer agents actively attempt to disprove the theory by identifying gaps in the logic.
“Often, agents actually disprove those theories because they find gaps,” Xanthos said. “There are many layers of defense and agentic checks that allow Resolve to be very accurate and not mislead.”
Equally important, he said, is the system’s willingness to say it does not know. “The bar to actually saying ‘I have the answer’ is very high. In those cases, it will say, ‘This is the evidence I found. Here are three or four paths you can take from here, but I wasn’t able to fully prove that this is the problem.’ A system like this that operates in production cannot be a black box.” In domains where wrong answers carry operational consequences, calibrated uncertainty can be more valuable than confident outputs. For an AI system integrated into an incident-response workflow, confidently pointing engineers in the wrong direction during a customer-facing outage could compound the very harm it was designed to prevent.
Beyond incident response, Resolve AI is introducing a new class of background agents designed to handle the continuous, often invisible operational work that engineering teams are expected to perform but struggle to sustain at scale.
These agents run on schedules or wake automatically in response to events — a new deployment, a fired alert, a merged pull request — and accumulate institutional knowledge from every investigation and human interaction over time. When an engineer opens the Resolve AI interface, agents have already been working: pre-investigating priority issues, monitoring deployments, auditing alert hygiene, flagging configuration drift, and surfacing cost anomalies.
Xanthos drew a distinction between background agents and the incident-response agents that have been Resolve AI’s primary offering. “You can now have these agents run in the background at all times — not only when a human asks an agent to debug a problem or when an alert fires,” he said. “A lot of our customers are now monitoring changes that land in production before they cause an issue. There’s an agent that monitors those all the time.”
He described these background agents as “general-purpose SRE agents that are available to every developer,” capable of handling tasks that range from monitoring infrastructure changes that might increase cloud costs to performing post-incident follow-up work like generating code fixes based on incident learnings. The concept addresses a structural problem in software operations: the daily tasks required to keep production systems healthy — monitoring deployments, investigating alerts, tracking changes across complex environments — are critical but reactive and manual. Engineering organizations know this work needs to happen, but it competes for attention with feature development. Automated agents that perform this work continuously could shift teams from reactive firefighting to proactive operational management.
The third major component of the release is what the company calls a shared investigation surface — a workspace where engineers and AI agents work from the same live evidence during an active incident. Reports update dynamically as investigations evolve. Every finding is inspectable. Engineers can explore side investigations without interrupting the primary workflow. Source queries are pullable and modifiable in place, evidence is embedded directly into the workspace, and remediation actions can be triggered from the same interface without switching tools.
“Think of it as an interface to all the production tools, but also an interface where humans and agents can collaborate with each other — or agents with agents,” Xanthos said. “That’s what gradually leads to more trust and more automation, because you work with the agent, you teach it, you see the results.”
The company is also making its platform available as a REST API and an MCP (Model Context Protocol) server, enabling engineering teams to integrate Resolve AI into broader agentic workflows and infrastructure. According to Xanthos, this is already happening in practice. “A general-purpose agent that a company has built — when it comes to debugging, that agent could invoke Resolve,” he said. “Or somebody works on their coding agent on the laptop, and Resolve shows up there as an MCP. If there is some production-related activity, the coding agent can invoke it.” The interoperability play signals that Resolve AI sees itself not as a closed system but as a specialized node in a broader ecosystem of AI agents that will increasingly hand off tasks to one another — a pattern Xanthos compared to the open architecture of the web rather than the walled-garden model of an app store.
The agentic operations space has become crowded in the past year. Datadog, PagerDuty, and major cloud providers have all announced AI-augmented operations capabilities. When asked what separates Resolve AI from these incumbents, Xanthos pointed to the depth of the company’s technical foundation.
“We’re operating at the frontier here. There’s no blueprint for how you build a system like Resolve,” he said. He noted that he and co-founder Mayank Agarwal co-created OpenTelemetry, the most widely adopted open-source project in observability, which now serves as the de facto standard for collecting metrics, logs, and traces from modern software systems.
Xanthos also highlighted the company’s recent AI Lab, led by a researcher he described as the former post-training lead for Meta’s Llama models. “He managed to combine deep expertise of production observability with AI and models, and I think that’s very unique,” Xanthos said. “I don’t believe any other company, whether it comes from an observability background or it’s a startup, has all of that together.”
The company’s structural defenses, according to Xanthos, include a full environment model that Resolve builds for each customer, a memory system that learns within the customer’s specific production environment, and its multi-agent architecture. The lab is now post-training frontier models on production-specific data — the kind of procedural knowledge that experienced engineers use to debug production issues but that does not appear in standard model training sets. This approach reflects an increasingly common pattern among AI application companies: using frontier foundation models as a base layer but investing heavily in domain-specific fine-tuning, retrieval, and agent architectures to achieve accuracy levels that general-purpose models cannot reach alone.
Resolve AI’s pricing model departs from traditional enterprise software licensing. The company sells credits that are consumed when agents perform work — an outcome-based approach that ties cost directly to value delivered.
“We’re not selling software,” Xanthos said. “The way you buy and use Resolve is by buying credits that are consumed when Resolve performs an action. It’s outcome-based. Only when Resolve troubleshoots an alert — that’s the only time that it consumes credits.”
He addressed the cost question head-on, arguing that Resolve AI is actually cheaper than the alternative of building a similar system from scratch using frontier models and MCP integrations. “If you were to take Opus or GPT-5.4 and try to build a solution like Resolve with MCPs, we measured — you actually end up consuming a lot more in tokens than what you have to pay Resolve, because our system is very optimized in terms of context, in terms of how it reads time-series data.”
As for the always-on background agents, Xanthos said their continuous nature does not inherently add to cost. “The background agent doesn’t mean it does intensive work all the time. It means that it can be there; you can give it any task you want. A lot of these tasks are triggered based on some action — an alert happens, somebody merges a PR, and you want to see if it has an impact on production.” For enterprise customers in regulated industries — the Coinbases and Zscalers of the world — data residency and security are non-negotiable. Resolve AI accommodates this with a flexible deployment model: the data plane sits wherever the customer’s existing tools already live, while the inference layer can run as a standard SaaS deployment or inside a customer-specific VPC. “We designed Resolve to work with the large enterprises where security standards are the highest,” Xanthos said. “There are many measures we take to ensure Resolve is secure, including not retaining data.”
The question of whether engineering teams will trust AI agents to take autonomous action in production — rolling back a deployment, adding capacity, generating a pull request — is one of the defining cultural challenges of this technology wave. Xanthos drew an analogy to autonomous vehicles.
“For us to allow a car to drive on its own on the street, we have to prove that it’s safer than a human. Agents in production is a very similar concept,” he said. He acknowledged that not every customer is comfortable with agents taking automated action, but described a gradient of trust that he expects to evolve rapidly.
“There is a set of actions that are relatively risk-free that most tech companies probably are comfortable having an agent take, and probably there is another set of actions for which the human has to approve,” he said. “But as quality keeps climbing the way we see at Resolve, I would say we’re going to cross the threshold this year where most of the actions will be taken by an agent automatically.”
He described the typical adoption arc: companies begin with agents providing recommendations, then a human decides whether to press the button. Over weeks or months, trust builds incrementally. “I don’t think this is a problem where we just let the agents run wild from the beginning,” Xanthos said. The incremental approach mirrors how enterprise technology adoption has always worked — from cloud migration to container orchestration, organizations move at the speed of trust, not the speed of capability.
Perhaps the most provocative argument in Resolve AI’s thesis is that the explosion of AI-generated code is actually intensifying the production-operations problem. In a recent LinkedIn post, Xanthos framed the dynamic in stark terms, arguing that engineering leaders who celebrate faster code shipping without investing in production operations are effectively having their senior engineers “subsidize velocity” through increased incident-response burden.
In his interview with VentureBeat, he returned to this theme. “Now that coding agents are producing code, we produce a lot more code that we’re less familiar with — humans are less familiar with — so you need the AI to be the defense,” he said.
This framing positions Resolve AI not merely as a productivity tool but as a necessary counterweight to the AI coding revolution. As organizations deploy more code, written by tools that their engineers may not fully understand, running against production systems those engineers did not build, the argument is that the operational complexity — and the consequences of failure — will grow proportionally. On the Stack Overflow Podcast last October, Xanthos put numbers to this claim, estimating that engineers spend upwards of 70 percent of their time maintaining and troubleshooting production systems rather than building new features. “We’re facing a new crisis where we’re building faster than we can operate,” he said in that conversation.
Resolve AI was founded in early 2024 by Xanthos and Agarwal, who first met during their PhD programs at the University of Illinois and have worked together for more than a decade. Xanthos previously co-founded Pattern Insight (acquired by VMware) and Omnition (acquired by Splunk), where the pair helped create OpenTelemetry. The company raised a $35 million seed round from Greylock in 2024, followed by the $125 million Series A led by Lightspeed at a $1 billion valuation earlier this year. Named customers include Coinbase, DoorDash, MSCI, Salesforce, MongoDB, and Zscaler.
Xanthos’s long-term vision is expansive. “Over the long run, once agent ability surpasses that of a human software engineer, the end result is a lot more technology and a lot more software,” he said. “It’s not actually fewer people working on it. It’s technology becoming cheaper, becoming more accessible, producing a lot more technology for the benefit of the world.”
That vision will take years to realize. But the more immediate promise of today’s announcement comes down to something every on-call engineer understands viscerally: the 2 a.m. page, the scramble for a laptop, the frantic search through dashboards and logs for an answer that might take minutes or might take hours. Resolve AI is betting that the next time that alert fires, a team of agents will have already investigated, verified, and documented the root cause before the engineer’s phone even lights up. For a profession that has long measured its nights by mean time to resolution, the question is no longer whether AI can help — it is whether engineers will let it.

NASA has named Randy Bresnik, Luca Parmitano, Frank Rubio, and Andre Douglas as the crew for Artemis III, which has been reworked from a moon-landing mission into a roughly two-week Earth-orbit test of lunar landers being built by SpaceX and Blue Origin. NBC News reports: Randy Bresnik, Luca Parmitano, Frank Rubio and Andre Douglas are expected to launch into Earth orbit next year, with the goal of testing two commercially developed lunar landers that are slated to carry astronauts to the surface of the moon during the Artemis IV mission in 2028. Bresnik will be the mission’s commander, with Parmitano, an Italian astronaut with the European Space Agency, serving as the pilot. Douglas and Rubio will be mission specialists, and Bob Hines will train with the crew as a backup member. “This test flight will enable us to prove we can carry out highly choreographed operations with our partners across hardware interfaces, software propulsion systems and life support elements with crew in the high-stakes space environment,” Jeremy Parsons, NASA’s Artemis program manager, said during NASA’s announcement on Tuesday.
Bresnik has been to the International Space Station twice, most recently as commander of an expedition in 2017. A retired U.S. Marine colonel, he was selected as a NASA astronaut in 2004. Bresnik has helped oversee development and testing of spacecraft for the Artemis program as an assistant to the chief of the Astronaut Office, which manages astronaut training and operations. Parmitano has also done two stints on the ISS and served as commander of an expedition in 2019. He has completed a total of six spacewalks and also performed the first live DJ set in orbit. Before becoming an astronaut, Parmitano was a test pilot for the Italian air force.
For Rubio, a physician with 28 years of service in the Army, Artemis III will be his second trip to space. From 2022 to 2023, he spent 371 days on the space station, breaking the record for longest-duration spaceflight by an American, according to NASA. Douglas is the only crew member making his spaceflight debut. An engineer who previously worked on space exploration and robotics at Johns Hopkins University Applied Physics Lab, he became a NASA astronaut in 2022. Douglas was the backup crew member for the Artemis II mission around the moon earlier this year. He told NBC News in an interview after Tuesday’s announcement that the role had at times been a challenge. “It was hard to figure out how do you balance getting ready to go, not go, all that stuff,” he said. “But to go now is just fantastic.”
Back in January of this year, RFK Jr. clearly strong armed the CDC into changing the childhood vaccination schedules in America to mimic those of Denmark. The public messaging was crafted to sound as reasonable as possible and amounted to a claim that America was going to revise vaccination schedules to match those of another successful, industrialized, peer country. There were a couple of problems with the move.
For starters, Kennedy did his usual move of trying to make this change completely outside of the normal process for such things. There was no indication that any of this was done at the behest of his reformed ACIP panel. It didn’t go through the normal scientific checks and balances. And even if it had, the courts later put a stay on all such changes, because Kennedy didn’t follow the American Procedure Act in either those revised schedules or even the formation of ACIP itself. The Trump administration has appealed that decision.
The other main issue with the change was the obvious one: America is not Denmark. Calling Denmark a peer nation to America is laughable for many reasons. As one Danish official pointed out at the time: Denmark has a homogeneous population, universal free healthcare, lower serious outcomes from infectious diseases that they don’t vaccinate for, and a population that actually largely trusts government institutions. America doesn’t have any of that, in large part because the party of Trump doesn’t want us to have it.
Donald Trump doesn’t know how to take an “L”, though, so of course he simply picked up a pen recently and is attempting to executive order his way to trying to change those same vaccination schedules.
While the federal government is appealing that injunction, the new executive order on Friday reaffirms Kennedy’s plans to adopt Denmark’s strategy, calling for “realigning” US vaccine policy with “best practices from peer, developed countries.”It states that the scientific assessment written by Høeg and Kulldorff is a “guiding resource for the Federal Government” and that the CDC shall ” take any appropriate steps to update the United States childhood and adolescent vaccine schedule.”
As before, the AMA is strongly against the unilateral change made without backing from scientific evidence.
“Altering [the vaccine schedule] without clear, evidence-based justification risks continued confusion for parents and patients, undermining trust in vaccines, and ultimately lowering vaccination rates,” Mukkamala said. “That would put more children and communities at risk of preventable illness.”
The American Medical Association (AMA) wasn’t the only one to come out against this top-down edict. The American College of Physicians (ACP) likewise pushed back on the EO publicly, stating unequivocally that it must not be implemented or there would be severe negative health outcomes for American children.
As did, hilariously, scientists in Denmark itself.
Anders Hviid, who leads research on vaccine safety and effectiveness at the Statens Serum Institut, Denmark’s equivalent of the CDC, told The New York Times in December that it did not make sense to compare the US to Denmark. “It’s not at all fair to say look at Denmark unless you can match the other characteristics of Denmark,” he said.
Hviid also told the Times that the US public health policies under Kennedy “get crazier and crazier” by the month. “It is surreal, and it is difficult, from a Danish perspective, to understand what’s going on.”
Trust me, dear Anders, it’s difficult to understand from within the American borders, too.
Now, neither Trump nor Kennedy give a flying damn about Denmark, of course. That much is obvious to anyone with a working frontal cortex. The country’s vaccination schedules are merely being used as a prop to reduce the vaccination schedules for American children because that’s all Kennedy really wants. Over the objections, it turns out, of Danish scientists themselves.
I’m sure the AMA, ACP, or the American Academy of Pediatricians (AAP) will be filing lawsuits over this Executive Order. And I see no reason why the courts shouldn’t put a hold on its implementation, as it did to Kennedy.
But the real mystery is why the do-nothings in Congress just can’t be bothered to push back directly on all of this.
Filed Under: acip, cdc, denmark, donald trump, health & human services, rfk jr., vaccine schedules, vaccines


Channel
MSP says it is ‘absolutely devastated’ as woman arrested on suspicion of murder
Neil Muller, newly appointed Group CEO of managed service provider Node4, has died after an alleged stabbing at his home. He was 54.
Muller, a well-respected and long-serving figure in Britain’s tech supply chain, was found with chest wounds at his residence in Claverdon, Warwickshire, in the early hours of June 7.
Warwickshire Police said in a statement: “We received a report from ambulance services at 6.15am about a man in his 50s who required emergency medical care following a stab wound in his chest. Sadly, he was declared deceased at the scene at 6.37am.”
A 55-year-old woman from Birmingham was arrested on suspicion of murder at 7.33am and has since been released on bail. Police confirmed an investigation is underway and said there is “no wider risk to the public.”
Muller had only taken on the Group CEO role at Node4 this month, tasked with refining its strategy and expanding its AI-augmented managed services platform. The MSP said it was “absolutely devastated” by his death, adding: “Although Neil only recently joined Node4, he made a meaningful impact in a short space of time. Our thoughts are with Neil’s family at this very difficult time.”
Before Node4, Muller led Digital Space for seven years, and prior to that he was chief exec at telecoms biz Daisy Group, whose B2B ops merged with Virgin Media O2 last year. Muller started his career at Computacenter – one of Europe’s largest services-based resellers – rising through sales and operations to become UK and Ireland managing director during a 21-year tenure.
Mike Norris, Group CEO at Computacenter and a close friend of Muller, told The Register that he was “deeply saddened from a personal point of view.”
Norris was not alone: many in Britain’s tech business community expressed shock. Charles Bligh, former TalkTalk chief operating officer, wrote on LinkedIn: “Just so shocked to hear this terrible news. Neil was a class act and he filled the room with his energy and leadership. My condolences to his family and his children should know their father was a respected, liked and thought leader in the business community. I know this is cold comfort. Neil you will be missed terribly and RIP.”
Muller is survived by his wife and two children. ®


Even before the recent nationwide rise in gas prices in response to geopolitical circumstances in the Middle East, fuel economy has always been one of the biggest factors that buyers consider when choosing a new vehicle. Whenever gas prices go up, the differences in fuel efficiency ratings between different models matter more to people.
Yet even with elevated fuel prices, the popularity of pickup trucks in America seems unlikely to fade. And while these vehicles may not be as efficient as your average sedan or crossover, recent fuel economy gains have been impressive. So which trucks are the most efficient? If you’re looking for maximum pickup truck efficiency overall, Rivian is the truck brand that gets the win, but its all-electric models are not directly comparable to internal combustion models.
When it comes to traditional pickup trucks with internal combustion engines, a few models come out on top in the fuel economy rankings, though their efficiency is heavily dependent on which engine option you choose. Thanks in particular to the growth of the hybrid truck market, many of these pickups have far better MPG figures than you might assume — we’ve highlighted the standouts below.
Sure, you could put an asterisk next to the Ford Maverick’s inclusion in this list because it’s not a “real” body-on-frame pickup and instead uses a more car-like unibody platform with front-wheel drive being the standard drivetrain layout. Buyers don’t seem to mind, though, and the Maverick has been an absolute hit as far as sales figures go.
When it comes to gasoline use, the Maverick is the most fuel-efficient pickup choice out there, by a significant margin. In its front-wheel-drive hybrid form, the Maverick delivers an incredible 38 MPG combined rating from the EPA, with the all-wheel-drive hybrid version coming in just behind that. Maverick buyers can also opt for non-hybrid models with the more powerful 2.0-liter turbocharged engine, and though the fuel efficiency ratings for the 2.0 Maverick aren’t as high, they are still quite good by pickup truck standards.
As our testing has found, though, there’s more to the Ford Maverick than just great MPG. The truck has also won over buyers who like its compact size, and the Maverick’s affordable price tag is another huge draw at a time when many feel that pickup truck prices are ballooning out of control. When looking for a sensible truck, the potential to save serious money at the gas pump is just one part of the Maverick’s compelling formula.
One might assume that full-size half-ton pickup trucks would be pretty far down a list like this, well behind the smaller mid-size trucks, but that’s not actually the case. Per the EPA’s fuel economy ratings, the truck that comes in second place to the Ford Maverick for fuel efficiency is the Chevrolet Silverado 1500, along with its GMC twin, the Sierra 1500.
More specifically, it’s the Silverado and Sierra powered by the stellar 3.0-liter Duramax inline-six turbodiesel engine. When equipped with this engine, the two-wheel drive Silverado and Sierra 1500 both deliver a combined EPA rating of 25 MPG. The engine’s stout horsepower and torque numbers aside, this is a number that was formerly unheard of when it comes to full-size pickups.
However, when talking about fuel efficiency and saving money on gas, it’s important to note that diesel prices are often higher than gasoline, and even more so under current conditions. You can, of course, get Silverados and Sierras with gasoline engines like the 2.7-liter turbocharged four-cylinder. Despite its lower fuel economy rating, the gas 2.7 could end up being cheaper to fuel than the more efficient turbodiesel models, and even the EPA’s official estimates show the expected annual fuel costs of the two engines are nearly identical.
The Ford F-150 pickup isn’t just a perennial bestseller, depending on powertrain options, it can also be one of the most fuel-efficient trucks on the road. When equipped with its available hybridized 3.5-liter V6 engine, the F-150 PowerBoost is actually the most fuel-efficient non-diesel full-size truck you can buy right now.
The F-150 PowerBoost has an EPA combined rating of 23 MPG, which includes an especially high rating of 22 MPG in city driving — and better yet, that’s the rating for a four-wheel drive model. The Chevy and GMC Duramax diesel half-ton trucks might have the edge in pure fuel efficiency, but per the EPA, the gasoline-powered F-150 Hybrid should be significantly cheaper to fuel up than a comparable Duramax truck.
In our review of the 2025 F-150 Hybrid, we found the added efficiency of the F-150’s hybrid option to be well worth its extra cost, which also buys you a nice bump in horsepower and a fairly substantial boost in torque over the non-hybrid 3.5 EcoBoost F-150. Ford of course, offers other less efficient powertrains in the F-150, including the Raptor R’s gas-guzzling supercharged V8 — but when it comes to balancing performance and fuel economy, the PowerBoost version is hard to beat.
If you are in the market for a mid-sized pickup truck and place a high value on fuel economy, the Toyota Tacoma is going to be difficult to top. Toyota currently offers the Tacoma with two different engines — a standard 2.4-liter turbocharged four-cylinder or a hybrid i-Force Max version of that same engine, which is available on the truck’s upper trim models.
Toyota has been greatly increasing hybrid options across its vehicle lineup in recent years, but the hybrid Tacoma is less about raw fuel efficiency and more about the added horsepower and torque compared to the non-hybrid version. In our review of the 2024 Toyota Tacoma TRD Pro, we found the engine’s impressive 326 hp and 465 lb-ft of torque to be a significant improvement over the base, non-hybrid versions.
However, if you’re simply looking for the most fuel-efficient Tacoma, there actually isn’t a massive difference between the Tacoma Hybrid 4WD’s 23 MPG combined EPA rating, and the non-hybrid 4WD model’s 21 MPG combined rating. If you factor in the added cost of the hybrid powertrain, the money-saving math probably won’t work out in the hybrid’s favor, but that’s not surprising. As mentioned a moment ago, the i-Force Max version of the Tacoma is more about driving performance than saving money at the pump.
Not to be overlooked between the compact Ford Maverick and the larger F-150 is the mid-sized Ford Ranger, which also offers strong fuel-efficiency numbers for its class. Unlike some of the other trucks on this list, the Ranger gets these numbers not from a hybrid or upmarket turbodiesel powertrain, but with its base 2.3-liter turbocharged EcoBoost four-cylinder.
In its two-wheel-drive spec, the 2.3-liter Ranger earns an EPA rating of 23 MPG combined, which, for the money, is about as good as you’ll find in any body-on-frame pickup truck on sale right now. Our review of the current generation Ranger XLT found that the truck’s real-world economy backs those numbers up, which we found very impressive for a non-hybrid, base engine. Those looking for more power from their Ranger can opt for the larger 2.7-liter EcoBoost V6 engine, but as you’d expect, that drops overall fuel economy numbers by a few miles per gallon.
Beyond that, there’s the much more powerful Ford Ranger Raptor, which, not surprisingly, drops that combined EPA rating down even further to 17 MPG. Given recent electrification trends, perhaps at some point Ford will add a hybrid Ranger option similar to the F-150, which would likely take the Ranger’s already-strong fuel economy numbers to a new level.
When putting this list together, we used official EPA fuel ratings as our primary source to pick five of the best-performing, current pickup trucks with internal combustion engines. We also used our first-hand experience on most of these models to back up the selection with real-world fuel economy and performance observations. We all allowed current truck models with either gasoline, hybrid, or turbodiesel engines.

Marshall’s prolific 2026 continues with the launch of the Stockwell II wireless speaker, which boasts some pretty big specs.
The Stockwell II was one of our favourite Bluetooth speakers when it launched, so we’re looking forward to seeing how Marshall can improve, and on paper, there are some big improvements.
But before that, let’s start with sustainability. The Stockwell III introduces replaceable and modular components, a list which includes the battery, carry strap, silicone sleeve as well as the front and rear grilles to ensure that the Stockwell III can last as long as possible without the need for a full replacement if it gets damaged.
To help its longevity, battery life has been expanded from the Stockwell II’s 20+ to 40+, practically double the battery life than before. The speaker can also act as a powerbank for other devices (such as your mobile device).

Marshall’s True Stereophonic 360 sound has made its way to the Stockwell III, offering consistent audio from whichever angle the speaker is placed to ensure there’s no ‘sweet spots’. Dynamic Loudness also features, taking care of managing bass, mid and treble at any volume and keeping them in balance.
The design remains practically the same, with its vertical silhouette and guitar-inspired PU leather strap and velvet lining. Controls have been updated to make it easier to access presets with the M-button or skip tracks with the media jog. An IP55 rating means that it’s not fully waterproof, but can survive a dip into water for a small amount of time. That’s still a jump up from the Stockwell II’s IPX4 rating.
Pricing is within reach of the older model in some markets, but overall it is more expensive. The Marshall Stockwell III has a price of £199.99 / $249.99 / €229.99 with availability in August (you can register interest in the speaker now). Colours are a choice of Black and Brass, and Cream.

This story is part of a series commemorating the five-year anniversary of the Voices of Change fellowship. Avery Thrush, a former Voice of Change fellow, is currently a LEE Fellow at the Massachusetts Department of Elementary and Secondary Education.
Reading my articles from the fellowship feels like reading diary entries. They’re raw, honest and they reflect how much I was struggling with teaching at the time. Overwhelm is apparent. So is frustration. As a teacher who was impacted by COVID-19 and the year of fully remote learning for students, the Voices of Change fellowship gave me the space to reflect and name the questions that had brought me to teaching in the first place. Since leaving the classroom almost two years ago, I’ve returned to writing frequently to work through the questions teaching left me with.
Having attended Title I public schools myself, I entered the classroom seeking a lens through which to understand my school experiences. As I became more interested in education as an engine of social mobility, I wanted to understand why some kids learned to read and some did not. I wanted to understand why some schools had more resources than others. I wanted to understand why some kids went to college, and some did not. Teaching felt like a way to move closer to those answers.
The process of learning these answers was swift and painful. The stark reality was playing out in front of me every day as I taught at a public charter school during the day and then drove to the suburbs in the evenings to tutor for extra cash. I quickly saw how rarely student success is the product of a single school or teacher, but rather an aligned system of supports that begins at birth.
So here’s what I learned: some kids can read because their schools taught phonics and screened for reading disabilities in kindergarten. Some schools have more resources because housing policy and decades of segregation shaped property values and neighborhood composition. Some kids go to college because they benefited from networks of financial and familial stability, giving them resilience through challenges like the SAT, the Common App and FAFSA. The questions I began with spun out into winding tangles of policy choices, zip codes, race and class.
I’ve come to understand that the grief I felt at leaving the classroom was more than being overwhelmed and overworked — it was the undoing of my belief that education was society’s great equalizer. It was also the realization that I had been lucky; my graduation from high school and matriculation to a four-year college was as much a function of my family’s assumption from birth that I would go to college as it was my academic performance or the opportunities my schools offered.
Achieving academically was easy because I had stable housing, good health care and a network of loving and supportive adults. Had I experienced any learning challenges, they would have been swiftly addressed by my white-collar parents, who are comfortable speaking with educated professionals. Students spend the vast majority of their lives before the age of 18 outside of school. Teaching revealed how profoundly the promise of education depends on systems beyond the classroom.
That isn’t to say that schools and teachers cannot move the needle for students. Teachers grow their students every day in ways that feel nothing short of miraculous. You’d be hard-pressed to find an adult who cannot name a teacher who made a difference in their life. But the biggest gains for students occur when the systems around schools align to support the work teachers are doing — when children arrive at school healthier, safer and more secure in their lives outside the classroom.
On this front, there are two movements I’ve been paying attention to, one that brings me hope and one that makes me nervous. In graduate school, I learned about place-based partnerships, initiatives that bring stakeholders in health care, housing, education, youth services, local government and philanthropy into alignment around shared goals for supporting children and families. The most famous example is the Harlem Children’s Zone, but the model has spread widely. Organizations like StriveTogether now support networks of communities working toward cradle-to-career outcomes. Partners for Rural Impact is helping rural communities coordinate services for children across schools and social supports. Here in Boston, the Boston Children’s Council is bringing together city agencies, nonprofits and schools to think more holistically about the conditions shaping children’s lives.
What gives me hope about these efforts is that they acknowledge something teachers already know: students do not arrive at school as blank slates each morning. They arrive carrying the cumulative effects of housing stability, health-care access, nutrition, family income and community safety. Place-based partnerships represent a policy approach that supports teachers by strengthening the ecosystems around them rather than asking schools to solve poverty alone.
NEWSLETTERS
Sign up for EdSurge newsletters for timely news, insights and analysis.
What makes me more uneasy is the direction some of the frustration with public education has taken. If we spent decades telling ourselves that schools were the great equalizer, then the persistence of large racial and economic achievement gaps, especially in the wake of COVID frustrations, can feel like a failure of the institution itself.
In my home state of West Virginia, that frustration has helped fuel support for the Hope Scholarship, the nation’s only universal education savings account program, which has deleterious impacts on the public education system most students rely on. Policies like this are often framed as empowering families with choice, but I worry they also reflect a disillusionment with the project of public schools as engines of democracy. It is my belief that many of the inequities in public education were never fully within schools’ control to address.
My experience as a teacher, and now as a policy practitioner, has convinced me that the path forward is not to abandon public schools, but to surround them with stronger systems of support for children and families. The question I find myself paying closest attention to now is how policy can help build those systems: partnerships that allow teachers to do what they already do best, while ensuring the conditions outside the classroom make their work possible.
This story is part of an EdSurge series chronicling diverse educator experiences. These stories are made publicly available with support from the Chan Zuckerberg Initiative. EdSurge maintains editorial control over all content. (Read our ethics statement here.) This work is licensed under a CC BY-NC-ND 4.0.
Avery Thrush is a West Virginia native and former educator.

Apple’s iPadOS 27 update is shaping up to be less about one headline feature and more about pulling the whole system closer together with Apple Intelligence is running through the middle of it.
The biggest shift is Siri, which is getting a major upgrade into what Apple is now calling “Siri AI”. Instead of short, scripted requests, Siri AI can now handle natural conversations and follow-up questions.
Additionally, it can tap into personal context on the device. That means it can surface old emails, find specific photos from years ago, or pull up notes without users having to remember exact file names or locations. Apple is also pushing this further with actions inside apps. For example, Siri can do things like edit a recently sent message, add music to a playlist, or help manage reminders based on what you’re currently doing.
There’s also a new dedicated Siri app, which acts as a kind of hub for conversations across Apple devices. You can start a request on iPhone and pick it up on iPad without losing context. This feels like Apple trying to make Siri less of a one-off interaction and more of an ongoing assistant.
Alongside Siri, Apple Intelligence is being woven more deeply into everyday apps. In Photos, that shows up as smarter editing tools, including reframing shots after the fact and expanding images beyond their original borders. Safari gets more practical upgrades too. For example, tabs can automatically group by topic. There is also a new “Notify Me” feature that alerts users when something changes on a page, like a price drop or restock.
The system-wide push continues in Messages and Mail, where Apple Intelligence suggests quick actions based on context. For instance, it can add events to your calendar or pull up relevant photos. There’s also a new Image Playground tool for generating and modifying images from simple prompts. This fits into Apple’s broader move toward description-based input across the system.
Shortcuts is another big beneficiary. Instead of building automations step by step, users can now just describe what they want. Then iPadOS will assemble the shortcut automatically. It’s the same idea Apple is pushing everywhere else: you say what you want, and the system figures out the structure behind it.
Visually, iPadOS 27 also brings refinements to the Liquid Glass design, improving contrast and readability. At the same time, users can adjust how translucent or tinted the interface looks. It’s not a dramatic redesign. Still, it does tighten up the overall feel of the system, especially on larger displays.
There are more practical upgrades too. Passwords can now flag weak or compromised credentials and update them automatically, while Safari and file transfers are noticeably faster. Apple also says performance improvements extend to app launches and AirDrop, making the system feel more responsive in day-to-day use.
On the safety side, Apple is expanding parental controls with more granular setup options, website approval requests through Ask to Browse, and clearer visibility into how children are using their devices. Communication Safety is also being extended to better handle harmful content in shared media.
Expect the software to arrive later this year, and there’s a developer beta available now.


The city that gave the world cloud computing just hit pause on the machines that power it.
The Seattle City Council voted unanimously Tuesday to impose a one-year emergency moratorium on new large data centers inside the city limits, responding to concerns about the implications of AI for the city’s power grid, water supply, utility rates, and economy.
The moratorium would take effect as soon as Mayor Katie Wilson signs it, temporarily halting projects like several large data centers that companies have approached Seattle City Light about building in the city. Those projects reportedly had a combined peak demand equal to about a third of Seattle’s average daily power consumption.
“This is Seattle’s position on AI and data centers,” said Councilmember Debora Juarez, who sponsored the council’s resolution on data center policy. She drew cheers from the audience at the meeting when she said she would halt AI and data center development entirely if she could.
It’s a major statement in a region that’s home to Amazon Web Services and Microsoft Azure, as well as engineering centers for Google, Oracle, Meta and other companies collectively spending hundreds of billions of dollars on data centers globally to meet demand for AI.
The moratorium puts Seattle among the largest U.S. cities to halt the industry’s buildout, joining Minneapolis, Denver, Baltimore, and Indianapolis in a wave of local pushback.
The council approved two measures: an ordinance halting applications for data centers with electrical capacity of more than 20 megavolt-amperes — enough power for thousands of homes — and a resolution committing the city to study their impacts as a precursor to permanent regulations.
The vote followed weeks of escalating public pressure. More than 50 people testified Tuesday, and not one spoke in favor of data centers. Many argued the moratorium doesn’t go far enough, calling for a permanent ban. Councilmembers said they received more than 98,000 emails on the issue.
Some of the most pointed testimony came from inside the industry.
Members of Amazon Employees for Climate Justice, who also testified at two meetings last week, urged the council to add renewable energy requirements and labor protections, and called for an end to what one AECJ member called the industry’s race “to build out as much compute capacity as they can, as fast as they can, before regulations can catch up.”
“It’s great to see this council choose to empower ordinary people and workers over those who see them as expendable,” said Srija Nagireddy, an AECJ member, citing layoffs this year at Amazon and Meta amid record earnings.
Councilmember Bob Kettle offered the closest thing to a defense of the facilities, distinguishing hyperscale projects from what he called “traditional data centers” — including one downtown that he said heats a half-dozen nearby buildings and supports the city’s first responders. His amendment to the resolution, adopted unanimously, specified that AI is driving demand for “hyperscale” facilities, and added the reliance of government, healthcare, and education on existing data centers to the city’s study list.
Notably, neither Amazon nor Microsoft operates data centers in Seattle itself. Kettle pointed out during the meeting that Amazon’s facilities cluster in Oregon, while Microsoft’s data center presence in the state is in Quincy, the central Washington town transformed by cheap Columbia River hydropower. That means the moratorium’s immediate effect falls on data center developers rather than the tech giants.
The ordinance exempts the roughly 30 smaller data centers already operating in Seattle, allowing each to expand by up to another 20 megavolt-amperes, which is the same amount as the threshold of the moratorium on new facilities.
Mayor Wilson, who first floated the idea of a moratorium in April, is expected to sign the legislation. City departments would then develop permanent data center regulations, with zoning legislation expected to reach the council by early 2027.
The fate of one project — Digital Realty’s proposed facility at 301 Virginia St., filed 11 days before the vote — remains unclear. Whether the moratorium can halt an application already in the pipeline is likely a question for permitting officials and possibly the courts.


Samsung refreshed its smartwatch lineup with careful attention to daily comfort and practical health details that many people actually use. The Galaxy Watch 8, priced at $290 (was $350), arrives in two sizes and focuses on longer battery stretches, a brighter screen, and several new measurements that go beyond basic step counts or heart rate. For anyone eyeing an Apple Watch alternative while carrying an Android phone, this model presents a clear case worth examining closely.
The case now has a thinner cushion contour that sits very flat against your wrist. Its 8.6mm thickness makes it feel significantly lighter over long periods of use, and the aluminum body is available in both graphite and silver finishes, which look great and are really versatile. The bands now have an enhanced lug system that keeps the sensors close to your skin without pinching or leaving gaps. This causes many people to forget they are wearing the watch, even overnight, which is a huge step forward in terms of making it usable throughout the day.
Sale

The 40mm model features a 1.34-inch Super AMOLED screen with 438 × 438 resolution. It has a maximum brightness of 3000 nits, allowing you to use it in direct sunlight while the competition fades out. Because to efficiency improvements elsewhere in the hardware, the always-on option now functions without depleting your battery’s life. The battery capacity has been increased to 325 mAh for the 40mm model and 435 mAh for the 44mm. Samsung claims up to 30 hours of use with the always-on display turned on, but real-world tests show ranging from 24-36 hours depending on how frequently you use features like workout tracking, notifications, and the built-in Gemini AI.
People who purchase these watches primarily for health tracking will discover some surprising capabilities built in. The BioActive sensor suite uses bioelectrical impedance to determine your heart rate, blood oxygen, ECG, and body composition, which is a fairly standard set of capabilities at this level. New features include an antioxidant index that shows how your skin is performing in terms of carotenoid levels; simply press your thumb on the sensor to find out where you are. The vascular load feature then analyzes your data overnight to assess how much strain your circulatory system has been under and suggests improvements to your sleep or exercise regimen. They also detect sleep apnea, which checks for dips in oxygen levels, and in countries where it is FDA approved, it works completely. In addition, you will obtain an energy score that offers a snapshot of your daily sleep and movement habits.

Fitness features have also been improved. Following a brief test run, the running coach develops a personalized plan for you and delivers real-time pace recommendations and progress reports as you exercise. The dual frequency GPS (L1 and L5) is very handy because it allows you to correctly locate your location even in challenging conditions, and the heart rate zones adjust to your specific data and track more advanced metrics if you enjoy cycling or swimming. These utilities can be used without a Samsung phone, although a recent Galaxy handset offers some additional features.

Wear OS 6 is the operating system, with Samsung’s One UI Watch 8 built on top; the interface helps to arrange all current information into tiles that may be modified to match your specific needs. Google Gemini sits on your wrist and can remind you of things, answer questions, and execute follow-up tasks all without requiring you to take out your phone.


Anthropic has begun rolling out a new model called “Fable,” which is based on the same underlying model as Mythos, its most powerful AI model class.
Anthropic previously said that it developed a model called “Mythos,” which is a state-of-the-art model that poses security risks to companies around the world.
At that time, Anthropic noted that Mythos was powerful enough to potentially help bad actors attack public and private software.

“The advantage will belong to the side that can get the most out of these tools,” Anthropic warned in April when it announced the Mythos model.
“In the short term, this could be attackers, if frontier labs aren’t careful about how they release these models. In the long term, we expect it will be defenders who will more efficiently direct resources and use these models to fix bugs before new code ever ships.”
In other words, it could have been abused to find and exploit vulnerabilities in apps like Firefox.
Because of those risks, Anthropic decided to limit access to models like Mythos and offer them only to cybersecurity experts and trusted companies.
Now, Anthropic says it has developed strong guardrails for the same model class, which means these powerful AI models can no longer be easily exploited by bad actors.
As a result, it’s launching a safer version called “Fable 5.”
According to Anthropic, this model has strict safeguards in place that will block or divert sensitive queries, like those involving offensive cybersecurity, biology, or chemistry, to its previous model, Opus 4.8.
Claude Mythos 5 is the unrestricted version of that same model, with those safeguards lifted.
Because of the risks involved, it is only available to a highly vetted group of trusted partners, such as government cyberdefenders and specific life sciences researchers.
Anthropic says Fable 5 is an expensive model because it requires a lot of compute, which means the company cannot afford to make it available as easily as Opus 4.8 or its previous models.
However, until June 22, Anthropic says Fable 5 will be offered to all Pro, Max, and Enterprise customers, but after the window expires, it’ll switch to usage-based pricing.
In our tests, BleepingComputer observed that Fable 5 uses a massive amount of tokens in a span of minutes.
I particularly noticed this behaviour when I used Workflow, a new execution system that allows Claude to break complex prompts into smaller tasks and spin up parallel subagents to implement them.
Claude Fable 5 exhausted my $100 Max subscription’s daily usage, which was at zero when I started using it, in just 9 minutes
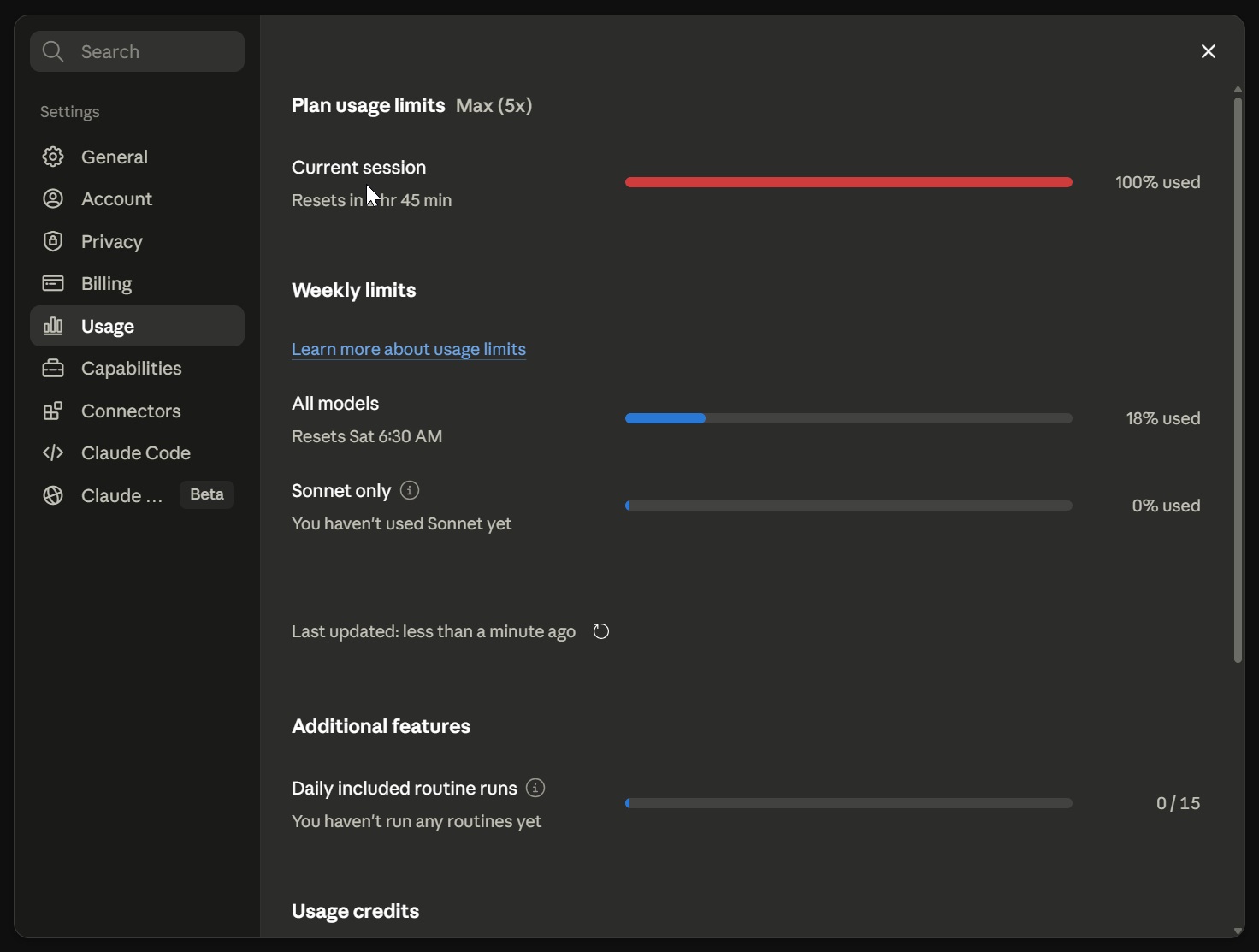
This doesn’t happen when you casually interact with Claude Fable 5, but if you switch to Workflow mode and change model thinking to high, you’re going to consume all your tokens in minutes.
However, even if you don’t use Fable 5 with workflow in xhigh effort, you’re still going to consume it 2 times faster than Opus model.
This explains why Anthropic is hesitating to unlock Fable 5 in the same capacity as Opus and other models, but that could change in the coming weeks, as the company is known for nerfing its models and increasing the capacity later.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.




Weekend Open Thread: Evereve – Corporette.com
Jensen Huang Approves Samsung, SK Hynix, and Micron for NVIDIA (NVDA) HBM4 Memory Supply


Anatomy of the June crypto crash: Fed, Iran, Saylor

The Best Mystery Series of All Time Is Surging on Streaming 30 Years After It Ended


Alexander Zverev wins the French Open to finally earn a 1st Grand Slam title


Suspicious Polyfill login prompts pop up on Toshiba, Muji websites

Senator Cynthia Lummis Calls CLARITY Act the Most Consequential Financial Legislation of This Generation


Microsoft unveils seven homegrown AI models in new bid for ‘long term self-sufficiency’
Microsoft launches MXC, an OS-level sandbox for AI agents, with OpenAI and Nvidia already on board


(VIDEO) Justin Bieber Delivers Surprise Happy Birthday Serenade to Diners at Los Angeles Mexican Restaurant

The Pain Points Taking a Fragile Tech Rally Down a Notch
LBank Surpasses 25 Million Users Worldwide as AFA Partnership Continues to Drive Global Growth


Trump’s AI Ownership Plan Could Benefit Anthropic at OpenAI’s Expense
Meta steals a tactic from Tesla and builds data centers in tents


Von der Leyen’s AI envoy pick draws conflict-of-interest fire

Bangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News


High Stakes for Wembanyama as New York Pushes for 3-0 Lead
Eli Lilly (LLY) Stock Surges 4% Following Breakthrough Sleep Apnea Trial Results


Hackers now exploit SolarWinds Serv-U flaw to crash servers


Notion restores access to Anthropic after service disruption






You must be logged in to post a comment Login