
TL;DR
Trump told Axios that Anthropic has “behaved very responsibly” and signalled he may ease restrictions on its Fable 5 and Mythos 5 AI models.


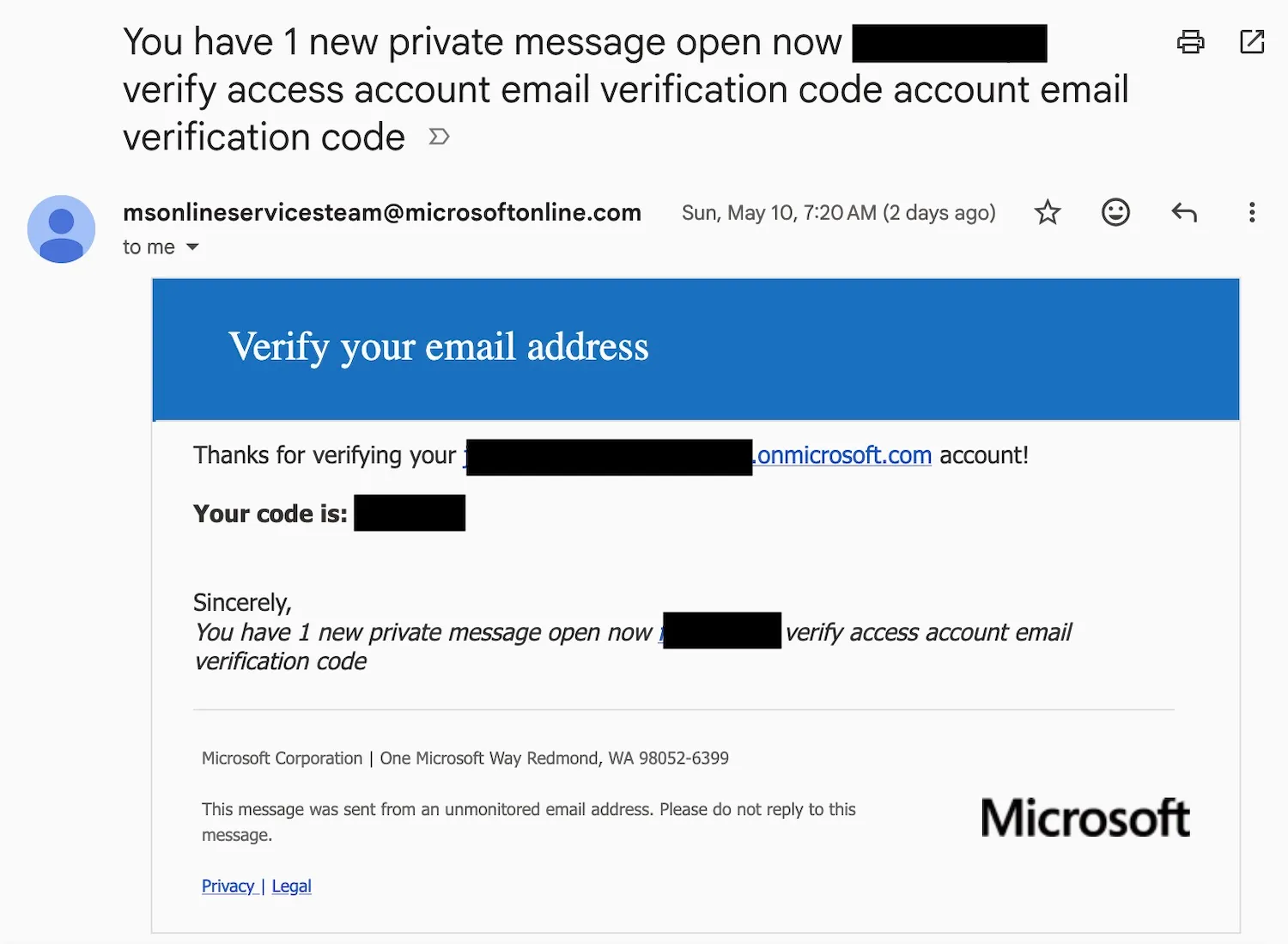
For months, scammers have been taking advantage of a loophole that allows them to send spammy emails from an internal Microsoft email address typically used for sending legitimate account alerts.
It’s not clear how the scammers are abusing the system, but they have been able to set up new Microsoft accounts as if they are new customers, and use that access to send out emails purportedly from the tech giant itself, potentially tricking people into thinking that these emails may be genuine.
Microsoft doesn’t yet appear to have gotten a handle on the issue.
Last week, I received several, similarly structured emails containing subject lines and web links to scammy sites from Microsoft across different email accounts. These crudely made emails were sent from msonlineservicesteam@microsoftonline.com, an email account that Microsoft uses to send important notifications to users, such as two-factor authentication codes and other critical alerts about their online account.
Some of these emails’ subject lines resembled official emails that would alert users to fraudulent transactions, while other emails claimed to have a private messaging waiting for the recipient at a web address mentioned in the email body.

In a social post on Tuesday, anti-spam non-profit, The Spamhaus Project, said it had also seen Microsoft’s account notification email address being abused to send spam, and that the activity dated back “several months.”
“Automated notification systems should not allow this level of customization,” wrote Spamhaus. The non-profit added that it has notified Microsoft of the issue.
When contacted by TechCrunch earlier this week, a Microsoft spokesperson acknowledged our inquiry, but has not yet commented or said if the company has stopped the abuse of its account notification email.
This is the latest in a rash of incidents in which hackers or scammers have abused company systems to trick unsuspecting customers in recent months. Earlier this year, hackers broke into a platform used by fintech firm Betterment to send out fraudulent notifications that purported to triple the value of any crypto users send in — a widely known scam used to steal people’s cryptocurrency.
Back in 2023, hackers similarly abused access to an email account run by Namecheap to send out phishing emails aimed at stealing people’s credentials.
Other users commenting on social media say that other companies’ email addresses are also being used to send out spam, suggesting the issue is not limited to Microsoft.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.

The JavaScript DOM Game Developer Bundle has 8 courses to help you master coding fundamentals. Courses cover JavaScript DOM, Coding, HTML 5 Canvas, and more. You’ll learn how to create your own fun, interactive games. It’s on sale for $30.

Note: The Techdirt Deals Store is powered and curated by StackCommerce. A portion of all sales from Techdirt Deals helps support Techdirt. The products featured do not reflect endorsements by our editorial team.
Filed Under: daily deal

Day 1 of the BMPS Grand Finals got us some really exciting action from teams we didn’t expect much from. Table toppers like Divine and Nebula have solidified their place, but day two of any BGMI tournament is always for comebacks, meaning we could see SouL and GodLike mounting a big challenge. After all, a ticket to the esports world cup in Paris is on the cards, in addition to the 4 cr prize pool. Here’s what the schedule looks like for day two.
The live broadcast will begin at 2:45 PM IST. Fans can catch the games like on Krafton’s YouTube channel in Hindi, English, and a few other regional languages. Or, if you want to support your team live, head over to the Jaipur Convention Center. Tickets are available on the District app. Maps for today will include:
A total of 18 matches will be played over the course of this weekend. And the format is pretty simple. Points are awarded for each finish, and also for how long a team survives. In the end, the team with the most total points (position + finish) will be the winners.
| Rank | Team | WWCD | Finish Points | Position Points | Total Points |
|---|---|---|---|---|---|
| 1 | DIVINE | 2 | 54 | 31 | 85 |
| 2 | NBE | 1 | 36 | 17 | 53 |
| 3 | GENS | 0 | 35 | 17 | 52 |
| 4 | iQOOORGE | 2 | 20 | 27 | 47 |
| 5 | iQOO8BIT | 0 | 29 | 11 | 40 |
| 6 | iQOORNTX | 0 | 29 | 10 | 39 |
| 7 | VASISTA | 0 | 26 | 12 | 38 |
| 8 | iQOOxTT | 0 | 24 | 13 | 37 |
| 9 | 7GODS | 1 | 21 | 15 | 36 |
| 10 | GDR | 0 | 22 | 7 | 29 |
| 11 | iQOOxOG | 0 | 15 | 11 | 26 |
| 12 | iQOOSOUL | 0 | 20 | 5 | 25 |
| 13 | MYTH | 0 | 18 | 6 | 24 |
| 14 | TAG | 0 | 21 | 2 | 23 |
| 15 | VS | 0 | 15 | 7 | 22 |
| 16 | GODL | 0 | 19 | 1 | 20 |


OFFBEAT
Nearly 4,000 vehicles recalled for driving past closure warnings and between cones marking shut lanes
Waymo is recalling nearly 4,000 robotaxis after its vehicles repeatedly failed to recognize freeway construction zones, in some cases driving past closure signs or between cones marking closed lanes.
A total of 3,871 vehicles equipped with Waymo’s fifth-generation Automated Driving System (ADS) are affected, and the interim workaround is to restrict freeway driving until a fix is available.
Six events were logged in Phoenix, Arizona, in April, during which vehicles drove past ramp-closure signs into pre-planned freeway construction zones. The response of Waymo’s Field Safety Committee was to implement freeway driving restrictions.
There were seven incidents in May in the San Francisco Bay Area, where vehicles drove between cones designating a lane closure. According to the Safety Recall Report, this was “due to the ADS inappropriately prioritizing the avoidance of other freeway hazards and/or failing to recognize the construction zone.”
The response was further freeway driving restrictions until the company could get to the bottom of the problem. On June 8, Waymo’s Safety Board decided to conduct a recall.
Vehicles not capable of driverless operation on freeways are not affected and have not been recalled.
The recall comes a month after Waymo disclosed that flooding could confuse its vehicles on high-speed roads, prompting another software fix.
Waymo’s vehicles operate in several US cities and have recently been sighted on the streets of London, albeit with a human ready to take control if needed.
Waymo has issued several vehicle recalls over the years. There was the 2023 truck collision and a prang involving a pole in 2024. Neither was particularly serious, but did little to bolster public confidence.
In January 2026, a Waymo vehicle struck a child near an elementary school. According to the US National Highway Traffic Safety Administration (NHTSA) [PDF], “the child ran across the street from behind a double-parked SUV towards the school and was struck by the Waymo AV. Waymo reported that the child sustained minor injuries.”
According to Waymo, its vehicles cover more than four million fully autonomous miles each week and have logged more than 170 million in total. The company says the Waymo ADS was involved in “92 percent fewer crashes that cause serious or fatal injuries than human drivers in the same driving conditions.” ®

TL;DR: More than a decade after its original release, Dark Souls II is set to receive a significant fan-made multiplayer update. A modder is currently working on a new “seamless” co-op mode that would theoretically allow the game to be played from start to finish in a single, soul-crushing session.
A well-known FromSoftware modder named “Yui” is working on a new seamless co-op mode for Dark Souls II. The mod is planned for release on the Scholar of the First Sin edition, which includes all previously released DLC and several enhancements to the base game. In a recent post, Yui said the project is taking longer than expected, as Dark Souls II has proven to be a challenging reverse-engineering effort.
Initially announced in 2025, the mod is now approaching the stability required for an “alpha” testing phase. Yui confirmed that it has become one of their most complex and ambitious projects to date, noting that Dark Souls II is a very different beast compared to other FromSoftware Soulslike titles.
A seamless co-op mod is designed to let players cooperate and complete a game without the traditional restrictions of official multiplayer modes implemented by FromSoftware. In theory, up to six players could progress through the entire game in a single co-op session, persisting through death and carrying world progression with them.
The mod will require the Scholar of the First Sin edition of Dark Souls II, which is a 64-bit upgrade of the original 32-bit base game. Yui previously worked on several mods for other FromSoftware titles, including Dark Souls, Dark Souls III, Sekiro, Elden Ring, and Elden Ring: Nightreign. These games are built on a broadly similar engine architecture, making it relatively easier to understand their systems after working on any one of them.
By contrast, Dark Souls II appears to use a separate branch of FromSoftware’s proprietary engine. As a result, Yui effectively had to reverse engineer the game from scratch, which explains why development of the co-op mod has taken considerably longer than expected.
The mod is not yet complete, but Yui released a short video to announce the upcoming project and demonstrate that it is technically feasible. The developer plans to provide a test build of the mod for free, while bug reporting and support will be limited to project supporters via Patreon.
Dark Souls II was released in 2014, further expanding the “Soulsborne” formula introduced in Demon’s Souls and Dark Souls. The game was a critical and commercial success, and FromSoftware went on developing even more punishingly hard action-RPG titles until Elden Ring: Nightreign came to be. Elden Ring was so successful that they are now making a movie out of the game.


For years, security teams built their programs around a simple premise of if you control the identities, you can control the risk. Employees authenticate through identity providers. Service accounts connect systems. API keys let workloads talk to cloud services and databases.
The actors have been very predictable. And as a result, the identity security and governance model have followed that predictability. Now, this premise is breaking.
AI agents entered the enterprise quietly, summarizing meetings, drafting emails, helping employees find information. Most security teams didn’t think hard about them at first. They looked like productivity tools, because that is exactly what they were.
Then, organizations started connecting them to critical business services such as Salesforce, Snowflake, GitHub, Jira, production databases, and cloud environments. Now, they retrieve information, trigger workflows, update records, write and deploy code, and take actions across multiple systems.
Sometimes on the behalf of a human, sometimes autonomously, and sometimes in ways where it’s genuinely unclear which.
This makes AI agents more than just tools. It makes them identities and most enterprises have no security and governance models for them.
The pattern is consistent across organizations. A new identity layer gets built on top of existing infrastructure with almost none of the controls that identity teams spent the last decade putting in place. An agent might be created by one team, used by another, connected to five different applications, and running on credentials that were provisioned for a completely different purpose.
It got broad access early because someone needed it to work and didn’t want to slow things down. The result is a sprawl of high-privilege, low-visibility actors that most security teams can’t inventory, let alone govern.
AI agents create, use, and rotate identities at machine speed, outpacing traditional IAM controls.
Token Security helps teams manage the full lifecycle of AI agent identities, reduce risk with remediation, and maintain governance and audit readiness without sacrificing speed.
According to a 2026 CSA survey commissioned by us here at Token Security, 82% of organizations discovered at least one AI agent created without the knowledge of security, IT, or governance teams in the past year, and 41% found this happening multiple times.
Here’s where the security conversation has gone sideways. Most of the attention on AI security has landed on model risk, such as prompt injection, jailbreaks, unsafe outputs. While these are all an important part of the agentic AI ecosystem, they don’t paint the complete picture enterprise security teams require. The most important piece they need must answer what can the agent actually access?
An agent that summarizes public documentation has limited blast radius. An agent connected to customer records, source code, financial systems, and admin-level cloud credentials is a different problem entirely.
A bad prompt, a compromised session, a malicious plugin, or a misconfigured integration can turn an overprivileged agent into a path for data exfiltration, destructive action, or lateral movement through systems that were never meant to be connected.
This is no longer theoretical, 65% of organizations experienced a security incident involving an AI agent in the past year, with 61% reporting exposure or mishandling of sensitive data as a result (source).
Getting control starts with visibility. Security teams need AI agent discovery and inventory that extends beyond just names and platforms to answer questions that actually matter.
Who owns this agent? Who can invoke it? What systems is it connected to? What credentials does it use? What can it read, write, delete, or execute in each target application?
This is harder than it sounds, because the surface isn’t obvious. A security team might know a sales assistant exists in an AI platform without knowing it runs on a Snowflake service account with admin privileges. They might know a coding agent is installed on developer endpoints without knowing which secrets, repositories, and CI/CD pipelines it can reach.
The agent itself is only part of the picture. Everything the agent’s identities can touch is the actual exposure surface.
The second piece is purpose. Security and governance can’t be purely permission-based with AI agents. It has to account for the agent’s intent. A sales prep agent only needs read access to CRM records. It doesn’t need to delete database tables.
A finance workflow agent should only read invoices. It shouldn’t be able to create new privileged users. When you understand what an agent is supposed to do, you can evaluate whether its permissions match that scope. And, in practice today, they rarely do and that gap is where the real risk lives and it only widens over time through least privilege policy drift.
Once intent is understood, enforcement becomes possible. Permissions can be trimmed to match the agent’s actual purpose, overprivileged service accounts remediated, unused credentials rotated or removed, and risky connections caught before they turn into incidents.
The part that trips up most teams is that none of this is a one-time exercise. An access review or an audit may feel like progress, but they just provide a point-in-time checkbox and a false sense of security. The reason is that agents change, instructions update, user bases shift, and integrations expand.
An agent that started as a narrow internal tool can quietly end up connected to systems it was never designed to touch, not because anyone made a bad decision, but because nobody was watching when the scope crept.
That’s why governance needs to be continuous to catch agents that start accessing applications outside their normal pattern, use unexpected credentials, or take actions that don’t fit their stated purpose.
The enterprises that succeed with AI will not be the ones that block agents entirely. They will be the ones that make agents governable and promote secure AI innovation. This means treating them as first-class identities with owners, access, behavior, risk, and lifecycle controls.
AI agents are becoming privileged insiders. Security and identity programs must now catch up before those insiders become invisible attack paths.
We’d love to show you how we’re tackling this at Token Security, book a demo to chat with our technical team so you can scale without sacrificing safety.
Sponsored and written by Token Security.


Each year, more than 130,000 people reach kidney failure. It’s the most advanced and expensive stage of a disease that affects 37 million Americans, 90% of whom don’t know they have it.
The tools being used to manage those patients, in many cases, haven’t kept pace. At nephrology clinics across the country, critical patient information still arrives by fax. Lab results sit in one system while the treating physician works in another. Staff manually key data into electronic health records one document at a time.
“I can walk through the airport and facial recognition lets me through. I can take a picture of a check to deposit it,” Jonathan Lin, co-founder of Seattle-based Apacendo Health, told GeekWire. “But yet, we still manage this disease state with faxes and Excel spreadsheets. It’s so archaic.”
Lin and co-founder Chong Sun believe AI agents — software that can autonomously navigate interfaces, read documents and take action inside existing healthcare systems — can close that gap. Their startup is building what they describe as an AI-native operating system for nephrology practices: software that works in the background, processing incoming faxes, triaging incoming data, and handling the administrative labor that consumes hours of staff time every day.
The U.S. spends more than $150 billion annually managing the consequences of chronic kidney disease, including over $50 billion on dialysis alone, while the NIH invests $19 per patient in research to understand how to treat and prevent it.
“For the most part, this is a silent disease,” said Dr. Osama Amro, director of nephrology at Swedish Medical Center in Seattle and an advisory board member for the National Kidney Foundation’s Pacific Northwest chapter. “Patients don’t have symptoms of pain in the kidneys or anything that brings them to a physician, except when it’s late.”
A blood draw and a urine sample can detect kidney damage years before symptoms appear. But catching patients at that stage requires a level of coordination and data-sharing that the current healthcare infrastructure isn’t built to support.
“We rely on a very tedious process of reviewing data,” Amro said. “The data, believe it or not, comes in faxes, in multiple locations, despite having an electronic medical record. This is not designed to screen patients or manage them with chronic kidney disease. Many times there is a delay in evaluating patients who need initial evaluation in a timely manner.”
A patient with chronic kidney disease can cost the system about $30,000 per year, with the price rising as the patient reaches end-stage, driven by dialysis and hospitalizations that earlier intervention could have prevented. By that time, a patient without a transplant has less than a 50% chance of surviving five years.
Anika Porter has been a nephrology practice administrator for 17 years. As practice administrator at Global Kidney Care in Houston, she oversees the operational side of a clinic where physicians see 20 to 24 patients a day, spending more time with each than providers at many comparable practices. The administrative burden, she said, falls hardest on staff who rarely get attention.
“People are so focused on the physicians,” Porter said. “The back office doesn’t get much support.”
Before introducing Apacendo Health’s technology, her clinic had two people dedicated to managing faxes. It’s a task that can mean hundreds of documents a day, each requiring manual review and data entry.
Dealing with insurance companies adds another layer of friction. Billing codes are standardized, but reimbursements often aren’t. Lin described a practice called downcoding, where insurers pay significantly less than what was billed, without notifying the provider.
“The doctors will perform a service, they will bill for that service, and then insurance companies will pay them much less, and won’t even tell them they’re paying at a discount rate,” Lin said. “Most doctors will never figure out that this is happening until they start reviewing their finances.”
“We’re at their mercy,” Porter said of insurers – not to mention that pay in the specialty has stagnated, and nephrology is among the most susceptible to turnover and budget cuts. In 2023, about 52% of nephrologists in the United States were international medical graduates — a sign of how few Americans pursue the specialty, and how uncertain the field’s future is given ongoing immigration policy.
Lin spent years working in the dialysis industry before moving into private equity and venture capital focused on healthcare. Two companies, DaVita and Fresenius, control about 70% of the U.S. dialysis market. What Lin observed was a system organized almost entirely around end-stage disease, with little infrastructure supporting the earlier, more preventable phases.
“A lot of the industry is relying on a high-touch clinical model, where they believe that if you engage with a patient on a very common basis, you can prevent their disease from progressing,” he said. “But the challenge is that it’s very highly manual. We’re basically using the playbook from five to ten years ago and applying it to this problem.”
A machine learning scientist, Sun had no prior experience in healthcare. His entry point was personal: his wife, a Navy veteran who became a VA mental health therapist after retiring from service, was spending up to seven hours a day on paperwork, leaving only three hours for actual patient care. In 2023, Sun built her an app to automatically generate session notes from recorded patient conversations. The VA wouldn’t adopt it, but the experience taught him what it meant to try to change healthcare from the outside.
The two connected through mutual friends and started Apacendo Health in 2025. Lin understood the clinical workflows, payer relationships and political terrain of a fragmented industry. Sun understood how to build software at scale. Their company, now at three employees, works with four nephrology practices across the country. So far, they’ve raised an undisclosed amount from the Science Fair Fund and angels.
Apacendo’s product focuses on what Lin and Sun see as the most immediate and tractable problem: daily administrative work that’s keeping clinic staff from doing anything else.
“We like to work with the system rather than completely changing it,” Lin said. “We’ve spent our entire project talking to nephrologists in every single community across the country, figuring out what they need, and how we can build technology that gets them from where they are to where they want to be.”
Their software creates “digital employees,” or AI agents that operate inside existing workflows. For example, when a fax arrives, an agent could read it, extract the relevant patient information, and upload it into a database. The company works with their partners to understand their specific pain points.
For a small practice handling around 60 faxes per day, each taking about five minutes to process manually, that adds up to around five hours of staff time recovered daily. One early customer told Lin that the tool had given her back meaningful time with her family. Porter, who uses Apacendo at Global Kidney Care, said the priority is clear.
“The biggest change we need to see is with more technology for back-office support,” she said. “We’re not looking for AI to replace people, but to help us manage tasks to serve people better.”
The startup’s ultimate goal is to use data to strengthen clinical protocols that reduce hospitalizations or delay disease progression. Identifying which patients are most likely to deteriorate benefits everyone in the system, Lin said. Amro’s hope is that eventually, technology could flag subtle signs of kidney disease and route that information to the right provider before the window for intervention closes.
“This comes back to the patients every single day,” Lin said. “We’re all going to age in this system. There just has to be a better way.”


Back in 1991, Toyota offered something in select LiteAce minivans that still catches people off guard decades later. Between the front seats sat a console box that could chill drinks and freeze real ice cubes while the vehicle moved down the road. Most minivans from that era focused on basic space and reliability. This one added a practical touch few competitors matched.
The LiteAce was part of Toyota’s long-standing line of practical compact vans and wagons built for everyday use. In regions such as Japan and Canada, as well as earlier North American vehicles offered as the Toyota Van, purchasers wanting for a little more may choose higher grades with some extremely nice amenities. The Cool & Hot Box was a highlight in this category. It carried around 6 cans in the main compartment and had a small designated space for freezing. The package included two ice trays. Owners would fill them with water, place them in, and the rest was taken care of.
Sale

Cooling comes directly from the dual air-conditioning system that many of these vans were equipped with. The refrigerant just had to run across to the console to keep the trays cold, resulting in actual, solid ice cubes on long rides. There was no separate compressor, and it didn’t draw much electricity because it used the existing A/C system in an efficient manner. Simply turn on the climate control, as the ice maker works silently in the background. To top it off, it created frozen cubes rather than chilled air or ice from home.

An OttoEx video on the feature’s daily use shows a cleaner 1991 example. The van is equipped with a 2.0-liter 3Y gasoline engine with fuel injection, an automated transmission, and part-time four-wheel drive. It also included locking hubs and a two-speed transfer case, allowing it to navigate off-road with ease. Inside, the seating arrangement was rather simple, with eight people spread across three rows. The van had a Toyota CD player and cassette deck for audio, and rear heating was available for added comfort. The console fridge was right between the front seats, and once the air conditioner turned on, you could sense how chilly it was.

The van was rather compact, measuring approximately 4070mm in length, 1650mm in width, and 2100mm in wheelbase, making it easy to park. Height varied based on the roof design, but was typically between 1765 and 1965 millimeters. It weighed between 1270 and 1440 kg, depending on how you specified it. Toyota provided smaller 1.5- and 1.8-liter gasoline engines, as well as a 2.0-liter diesel, some of which were turbocharged. At the end of the day, the goal was to make things basic and strong so they would be easy to service for years to come.

Before the Previa, the Cool & Hot Box was mostly an option on higher-end trims, specifically Japanese market wagons and certain North American Toyota Van models. It wasn’t on every LiteAce, mind you; many purchasers chose not to have it, and it was removed from US versions when the lineup changed. However, in other places, the option remained on higher-end Previa models for a little longer. If you’re lucky enough to come across one of these vehicles with the original console intact, it’s now a true collector’s item. Some people have even managed to extract entire units from Japanese models, which now retail for a few hundred dollars when they crop up.
[Source]

High-end DACs face a slightly uncomfortable dilemma in 2026. Spend a few hundred dollars and the market will happily offer a compact unit from overseas with a color display, Bluetooth, balanced outputs, a headphone amplifier, app control, enough filter options to occupy a rainy weekend, and sample-rate support that looks impressive in a product listing. Feature density has never been higher. Whether all of that translates into superior digital conversion, lower real-world noise, better clock recovery, a more convincing analog stage, or simply a more natural and involving presentation is another matter entirely.
That is the space Weiss Engineering continues to occupy. Bluebird Music has announced the DAC204-MK2 for the U.S. and Canadian markets, updating the Swiss company’s compact DAC204 with an ESS ES9028PRO conversion chip, improved jitter rejection, and a revised near-zero-ohm analog output stage. Weiss has also said that its distortion behavior and reconstruction filters were optimized by ear, which is a refreshingly direct reminder that a DAC is not supposed to win a spreadsheet contest; it is supposed to make the system sound better.
Related Reading: WTF is a DAC?

The DAC204-MK2 updates the original DAC204 with a completely redesigned DAC board, an upgraded ESS ES9028PRO DAC chip, enhanced jitter elimination, and a new near-zero-ohm analog output stage. Weiss says these revisions are intended to improve conversion performance while making the DAC better suited to a wider range of connected components and cable loads.
Designed by Swiss digital-audio engineer Daniel Weiss, the DAC204-MK2 reflects the company’s long-standing mastering-studio background and its belief that technical performance should serve the musical result. The goal is not feature overload, but clean, stable digital conversion with careful attention paid to the analog output stage and final voicing.
The DAC204-MK2 is deliberately focused in its execution. It forgoes network streaming, onboard DSP, remote control, and a built-in headphone output in favor of a compact DAC designed around USB, Toslink, and S/PDIF inputs, balanced XLR and single-ended RCA outputs, and support for PCM up to 384 kHz and DSD64/128.
Rather than competing on menus, displays, or an endless list of digital extras, the DAC204-MK2 concentrates on the fundamentals: clocking, conversion, output-stage design, and the quality of the analog signal delivered to the rest of the system.

Redesigned DAC Section: The DAC204-MK2 replaces the original DAC board with a new design built around the ESS Sabre ES9028PRO DAC chip and a revised analog output stage.
Enhanced Jitter Elimination: Weiss says the ES9028PRO incorporates an advanced jitter-elimination circuit intended to preserve conversion quality when connected to sources or digital links with higher jitter levels.
Near-Zero-Ohm Output Stage: The new analog output stage offers near-zero-ohm output impedance, which Weiss says improves compatibility with difficult cable loads and low-impedance headphones used with a suitable external adapter.
Acoustically Optimized Filters: Weiss has also fine-tuned the DAC204-MK2’s distortion behavior and reconstruction filters by ear, rather than relying exclusively on laboratory measurements. The company’s aim is a more natural and musically convincing result without adding unnecessary features or complexity.
Source Inputs: The DAC204-MK2 provides three digital inputs: USB, RCA, and optical Toslink. The RCA and Toslink connections accept AES/EBU or S/PDIF signals.
Input Selection: Multiple digital sources can remain connected at once, with a front-panel Input Selector switch used to choose between USB, Toslink, and RCA.
Input Signal Compatibility: USB accepts PCM from 44.1 kHz to 384 kHz, along with DSD64 and DSD128. The RCA input supports PCM through 192 kHz, while the Toslink input supports PCM through 96 kHz. DSD signals received via USB can be converted to PCM.
Analog and Digital Outputs: Analog output is available simultaneously through balanced XLR and unbalanced RCA connectors. Digital output is provided on XLR, RCA, and BNC connectors for use in digital-to-digital conversion applications.
D/A Conversion and Clocking: The DAC204-MK2 uses four oversampling sigma-delta D/A converters per channel, operated in parallel to improve signal-to-noise performance. Weiss also combines several reclocking schemes to provide high jitter attenuation.
External Power Supply: An external power supply is included. Weiss uses separate linear regulation for sensitive voltage rails, a design intended to minimize digital noise and channel crosstalk at the analog output.
Note: The specifications below are the same for the DAC204-MK2 and DAC204 unless otherwise indicated
– All inputs accept professional or consumer standard, i.e., accept AES/EBU or S/PDIF signals.
– Sampling frequencies: 44.1, 48.0, 88.2, 96.0, 176.4, or 192 kHz on the RCA (digital coaxial) input. – Sampling frequencies: 44.1, 48.0, 88.2, 96.0 kHz on the Toslink input.
– Maximum input word-length: 24 Bits.
(1) USB connector – Accepted sampling frequencies: 44.1, 48.0, 88.2, 96.0, 176.4, 192, 352.8, 384 kHz, DSD64, DSD128
(2) RCA connectors, DC coupled, short circuit proof output circuitry – Output impedance: DAC204: 22 Ohm, DAC204-MK2: Close to 0 Ohm
Output level: Selectable by two toggle switches, 4 settings
XLR outputs: RCA outputs: Extremely efficient Jitter attenuation. – At 0 dBFS input level, maximum output level, 4 kHz, all components at less than −115 dBr
Weiss Model
DAC204-MK2 / DAC204
Product Type
DAC
Price
$3,990 US,
$4,895 CAD (price point retained from the DAC204)
DAC Chip
ES9028PRO (DAC204-MK2)
ES9018S (DAC204)
Digital Inputs
(1) RCA (digital coaxial) connector,
(1) Toslink connector (optical)
Analog Outputs
(2) XLR connectors (hot output on pin 2, not servo controlled), DC coupled, short circuit proof output circuitry – Output impedance: DAC204: 44 Ohm, DAC204-MK2: Close to 0 Ohm
7.5 Vrms, +19.7 dBu, with a 0 dBFS sinewave input
2.3 Vrms, +9.7 dBu, with a 0 dBFS sinewave input
0.75 Vrms, -0.3 dBu, with a 0 dBFS sinewave input
0.23 Vrms, -10.3 dBu, with a 0 dBFS sinewave input
3.75 Vrms, +13.7dBu, with a 0 dBFS sinewave input
1.15 Vrms, +3.7dBu, with a 0 dBFS sinewave input
0.375 Vrms, -6.3dBu, with a 0 dBFS sinewave input
0.115 Vrms, -16.3dBu, with a 0 dBFS sinewave input
Digital Outputs
(1) XLR connector
(1) RCA connector
(1) BNC connector
Synchronization
Synchronized via the input signal in the case of RCA (digital coaxial) or Toslink inputs. In the USB input case, the DAC204 is the master clock. –
Sampling frequencies supported: 44.1 kHz, 48.0 kHz, 88.2kHz, 96.0kHz, 176.4khz, 192kHz, 352.8kHz, 384kHz, DSD64, DSD128
Power
– DC input voltage: 6 to 9 volts
– DC input current: 1050mA at 6V, 700mA at 9V
– Power consumption: 6.3 W
Frequency Response at Sampling Frequency Points
Fs = 44.1 kHz, 0Hz-20kHz: within +- 0.25dB
Fs = 88.2 kHz, 0Hz-20kHz: within +- 0.25dB
Fs = 88.2 kHz, 0Hz-40kHz: within +- 0.8dB
Fs = 176.4 kHz, 0Hz-20kHz: within +- 0.25dB
Fs = 176.4 kHz, 0Hz-40kHz: within +- 0.8dB
Fs = 176.4 kHz, 0Hz-80kHz: within +- 2.5dB
Total Harmonic Distortion plus Noise (THD+N)
−116 dBr (0.00016 %) at −3 dBFS input level
−125 dBr (0.000056 %) at −40 dBFS input level
−125 dBr (0.000056 %) at −70 dBFS input level
Linearity
At 0 dBFS to −120 dBFS input level: less than ±0.4 dB deviation from ideal
Spurious Components (including harmonics)
At 0 dBFS input level, maximum output level, 1 kHz, all components at less than −120 dBr
Crosstalk
Better than 120 dB, 20 Hz–20 kHz
Interchannel Phase Response
+- 0.05° 20 Hz–20 kHz +- 0.30° 20 Hz–80 kHz
Dimensions (HWD)
3.8” x 4.2” x 6.5”
Weight
2.4 lbs
The DAC204-MK2 is housed in a compact black chassis with a silver faceplate and follows a deliberately focused design philosophy. Unlike Weiss’s more fully featured DAC501-MK2 and DAC502-MK2, it does not include onboard DSP, remote control, network streaming, Roon support, or a dedicated headphone output.
That is not an oversight. The DAC204-MK2 is designed as a straightforward digital-to-analog converter, concentrating its engineering budget on conversion, clocking, jitter suppression, and the analog output stage rather than features that many listeners may already have elsewhere in their system.
Pro Tip: Although the DAC204-MK2 does not include a built-in headphone jack, Weiss offers an optional headphone adapter that allows the DAC’s analog output stage to be used with headphones. Contact Weiss Engineering or an authorized dealer for compatibility and availability details.
At $3,990 in the U.S. and $4,895 in Canada, the Weiss DAC204-MK2 is not trying to be the least expensive or most feature-packed DAC on the market. The MK2 upgrade is focused where it matters: a redesigned conversion board built around the ESS ES9028PRO DAC chip, improved jitter elimination, a new near-zero-ohm output stage, and acoustically optimized reconstruction filters.
That makes the DAC204-MK2 a compelling option for listeners who already own a streamer, transport, preamp, or integrated amplifier and want a compact, Swiss-engineered DAC with serious mastering-studio pedigree. It offers flexible digital connectivity, balanced and single-ended analog outputs, DSD-to-PCM conversion, and digital output capability, but skips streaming, DSP, room correction, phono, remote control, and a built-in headphone output.
There are certainly DACs near this price that offer more functionality. The Denafrips Venus 15th, at $3,999, is a similarly priced R-2R alternative for listeners looking for a different conversion approach. The Ferrum WANDLA HP, at $3,295, adds a preamp stage, remote control, HDMI ARC, I2S, touchscreen interface, and a powerful balanced headphone amplifier. Benchmark’s DAC3 HGC is considerably less expensive at $2,399 and remains a strong option for listeners who value a compact DAC with headphone capability and a more studio-oriented feature set.
But the Weiss is not competing on screen size, streaming platforms, or menu depth. The DAC204-MK2 is for listeners who want to put their money into digital conversion, clocking, output-stage quality, and a straightforward component that can disappear into an existing high-end system. Sometimes fewer features are not a compromise.
The Weiss DAC204-MK2 has a suggested US retail price of $3,990 ($4,895 in Canada), and is available now from Bluebird Music and authorized Weiss dealers throughout the United States and Canada.

Trump told Axios that Anthropic has “behaved very responsibly” and signalled he may ease restrictions on its Fable 5 and Mythos 5 AI models.
President Donald Trump said in a pretaped Axios interview that he no longer views Anthropic as a national security threat, marking a sharp reversal from the administration’s aggressive posture toward the AI company over the past three months. Asked whether he considers Anthropic a threat, Trump replied, “Well, not now. But a week ago, maybe.” He added that the company has “behaved very responsibly.”
The comments come just days after the Commerce Department issued a directive on June 12 ordering Anthropic to seek US government approval before foreign nationals access its Fable 5 and Mythos 5 models, the company’s most powerful AI systems. That order followed months of escalating tension between the administration and Anthropic over the company’s refusal to remove certain safety guardrails from its military-facing products. The directive effectively triggered crisis-level talks between Anthropic and Commerce Department officials last week.
Trump met Anthropic CEO Dario Amodei on Wednesday at the G7 Summit in Évian-les-Bains, France, an encounter that appears to have shifted the president’s stance. The meeting came after Anthropic senior technical staff held separate discussions with Trump administration officials earlier in the week. Trump told Axios he would consider easing the restrictions, saying, “I would, but I’m not sure I have to do that,” when asked about a potential rollback.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The dispute traces back to March 2026, when the Pentagon designated Anthropic a supply-chain risk after the company refused to strip guardrails related to surveillance and autonomous weapons from products used by the US military. Commerce Secretary Howard Lutnick subsequently sent a letter threatening criminal charges against the company, a move that drew criticism from technology industry groups and prompted allied governments, including the UK, to lobby for exemptions.
The timing of Trump’s conciliatory tone is significant. Anthropic confidentially filed for an initial public offering in early June, with a valuation that Fortune reported at approximately $965 billion. The ongoing federal restrictions had cast uncertainty over the listing, and any signal of de-escalation from the White House could stabilise investor confidence ahead of the offering.
Trump described the situation as creating “tremendous liability” for the administration, an acknowledgment that the crackdown had drawn backlash from both industry and allies. The president also said he would not shut down Anthropic, though he stopped short of committing to a specific timeline for lifting the Commerce Department directive.
The shift does not erase the underlying disagreement. The Pentagon’s supply-chain designation remains in place, and the Commerce Department’s June 12 order has not been formally rescinded. Anthropic has not publicly indicated whether it plans to modify its guardrail policies to satisfy the military’s demands.
What has changed is the political signal from the top: Trump appears willing to negotiate rather than escalate.
Amodei has been working multiple channels to resolve the standoff. At the G7 summit, he and Google DeepMind CEO Demis Hassabis jointly pitched a US-led AI coalition to G7 leaders, positioning Anthropic as a cooperative partner in American technology diplomacy rather than a regulatory adversary. The strategy appears to have given Amodei direct access to Trump at a moment when the president was receptive.
Whether the warm words translate into policy remains an open question. The Commerce Department operates with considerable independence on export control matters, and rolling back a formal directive requires bureaucratic steps that a single interview cannot shortcut. For Anthropic, the Axios interview is a political win, but the legal and regulatory constraints remain until the administration acts on them.

Would you run into a crowded university lecture hall, fart into a megaphone, and bellow “fartcoin” at the top of your lungs? If so—and should you have the means to document this stunt on video, preferably capturing the audience’s reaction—you may claim a reward of approximately $1,000.
The money, of course, will be dispensed in fartcoin, a meme cryptocurrency trading at a little over 10 cents at time of publication, with a total market capitalization hovering around $130 million.
Such is the promise of Pump.Fun GO, a new feature on Pump.Fun, one of the fastest-growing crypto businesses of the past few years. It supposedly allows users to “pay anyone to do anything.” Crypto bounties are put up by individuals—or pooled from multiple wallets—and held in escrow by Pump.Fun until a countdown clock runs out. Finishing a task is supposed to net you the prize payout; creators get a refund if nobody completes the mission.
Pump.Fun, whose legal department did not return a request for comment, has said without clarifying its process that it moderates and approves the submissions of bounties as well as relevant collection claims. An initial wave of GO bounties included enticements to parachute into a World Cup game in a memecoin-themed costume and a prompt for a Black person to cover themselves in watermelon and repeat the phrase “I’m your friend, the watermelon man.”
Terms of service state that GO users are responsible for their own “actions, decisions, wallet security, submissions, communications, and compliance with law.” They also warn that the platform may remove content, suspend accounts, and cooperate with third-party authorities in cases of “fraud, scams, market manipulation, infringement, hacking, scraping, abusive or illegal content, stolen property, unlawful financial activity, or other harmful or prohibited conduct.” Crypto transfers and rewards are “not guaranteed,” according to these terms.
The GO feature, arriving just as the platform is contending with a massive crash in user engagement, seems to promise further accusations of lawlessness and deceptive practices for Pump.Fun, already a lightning rod for controversy. Many of the bounties, such as one requesting footage of a memcoin-themed car exploding in a ball of flame, are flooded with AI-generated imagery presented as evidence of a completed task. People who actually carry out a challenge have no apparent recourse if someone else’s submission is selected as a winner by Pump.Fun according to some unspecified backroom criteria.
Fine print can also complicate the picture: a $215 bounty titled “Go to McDonalds and get a burger” specifies that the payout will be split between the first 20 valid entries, coming out to $10.75 in crypto each—less than what most paid for their meal.
While that bounty is rather mundane, others still open at the moment are strikingly dystopian, exploitative, or harmful. There are multiple requests for users to get the names of various cryptocurrencies tattooed on their body, and a man in India has already had his forehead tattooed for the equivalent of $3,000. (Video replies depicting people completing more degrading tasks frequently come from users in countries outside the US.) You can record yourself begging a gas station attendant for a pill to help with your flaccid penis for about $100, interview multiple homeless people and ask who they voted for ($700), or quit your job on camera ($3,000). “Bonus points for style, creativity, and chaos,” the last prompt reads. “This is your severance package.”
Andrew Ford Lyons, a technologist who works on digital security and safety projects for human rights groups and other organizations, tells WIRED that GO is incentivizing coercion, harassment, and significant physical and legal risks, “leveraging inequality” for online entertainment. “This is essentially what the digital economy is boiling down to,” he says.





No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


Weekend Open Thread: Miami – Corporette.com

Matt Damon’s Viral Sci-Fi Thriller Has Taken Over HBO Max


Anthropic staff to meet White House officials next week, Axios reports


As AI companies race to go public, who else is along for the ride?

Bitcoin could crash to $48,000, if this historical pattern is triggered

Warning of disruption as Cardiff Crossrail works to start
what doctors are seeing in ebike crashes

Tributes to former deputy head teacher at Cambridge school among death and funeral notices


“Israel’s” ban on ICRC visits ruled illegal, but Knesset moves to stop them permanently
Deion Sanders Shares Powerful Post After Viral Advice To Deiondra


Financial Accounting | Last Day Revision Strategy and Booster | CMA Inter – June 2026

Kate Middleton Glare Goes Viral After Kids Booed At Royal Event

XRP ETFs Outperform As Bitcoin And Ethereum Funds Extend Outflow Trend


Over 400 Arch Linux packages compromised to push rootkit, infostealer
Market Preview: SpaceX (SPCX) IPO Record, Federal Reserve Meeting, and Iran Nuclear Agreement


Invesco Quality Income Fund Q1 2026 Commentary


Singer Oliver Tree dies aged 32 in helicopter crash in Brazil


Dick Advocaat’s Curacao scores first-ever World Cup goal against Germany





You must be logged in to post a comment Login