TL;DR
Palantir CEO Alex Karp has assembled a $200M+ real estate portfolio centred on seclusion, from a 3,700-acre Colorado monastery to a Miami compound. The privacy-obsessed lifestyle contrasts sharply with the surveillance software his company sells to governments.
Alex Karp, the co-founder and chief executive of Palantir Technologies, has quietly assembled a real estate portfolio worth more than $200 million across a reported 20 properties worldwide. The common thread is seclusion: a former monastery in the Colorado mountains, a rural compound in New Hampshire, and a pair of mansions on a gated Miami island.
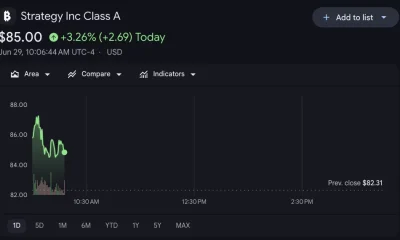
Karp, whose net worth stood at $14.4 billion as of early July according to the Bloomberg Billionaires Index, has said he never learned to drive because he was once “too poor” and is now “too rich.” The fortune that funds his acquisitions comes from Palantir, whose revenue hit $1.63 billion in Q1 2026, up 85% year over year, driven by surging demand for its AI and data analytics platforms from governments and defence agencies.
The monastery
In December 2025, Karp paid $120 million for the Saint Benedict’s Monastery ranch, a 3,700-acre property in the Capitol Creek Valley near Snowmass, Colorado, about 15 miles north of Aspen. The deal, transacted through an entity called Espen LLC, set a record for Pitkin County and was one of the largest residential sales in Colorado history.
Trappist monks of the Cistercian Order of the Strict Observance had stewarded the land since 1956, supporting themselves through farming and candy sales. Their numbers dwindled over the decades until only five remained, and the order’s General Chapter voted to close the monastery in the autumn of 2022.
The property was listed for $150 million in April 2024 before selling for $30 million below asking. The compound includes a chapel, monks’ living quarters, a retreat centre, 1,200 acres of irrigated meadows with senior water rights, and three creek systems stretching more than five miles.
Karp is an avid cross-country skier who reportedly trains 12 to 15 miles daily. A 3,700-acre property in the Elk Mountains is a fitting base for someone whose fitness regime is better described as vocational.
The Miami compound
In June 2025, a Delaware entity called Hibiscus East LLC purchased a nearly 10,000-square-foot waterfront mansion at 55 East San Marino Drive for $46 million. Business Insider reported that the LLC is linked to a New Hampshire attorney and accounting firm that have appeared on documents tied to Karp’s previous transactions.
Karp then bought the house next door at 29 East San Marino Drive for $28.5 million, bringing his total investment on the island to nearly $75 million. The second property was listed at $30 million and went under contract in eight days.
Together, the two lots total more than 0.8 acres with 265 feet of waterfront, and The Real Deal reported that the acquisitions appear to be the start of a compound. San Marino is one of six man-made Venetian Islands in Biscayne Bay, an exclusive enclave whose past and present residents include basketball player Dwyane Wade and singer Gloria Estefan.
The Miami purchases predated Palantir’s decision to relocate its headquarters from Denver to Aventura, a Miami-area suburb, in February 2026. The company is currently operating from a co-working space while searching for permanent offices in areas including Wynwood, Brickell, and Coral Gables.
The New Hampshire compound
Karp’s reported primary residence is a 500-acre estate in Lyman, New Hampshire, part of which he purchased for $825,000 in 2019. He has been known to work from the property’s barn.
Lyman is a rural town in Grafton County with fewer than 600 residents, nearly two hours south of Manchester. Despite running one of the most closely watched companies in the defence technology sector, Karp chose a near-invisible town as home base, a pattern that extends across every significant property in his portfolio.
What Palantir builds
The seclusion of Karp’s lifestyle is striking because of what Palantir does. The company took over Project Maven, the Pentagon’s AI drone analysis programme that Google abandoned after employee protests, and its platforms power surveillance systems used by ICE, the military, and hundreds of local law enforcement agencies across the United States.
Karp has defended this work as essential to national security, arguing that democracies need tools powerful enough to compete with authoritarian adversaries. The company continues to expand its government footprint, competing for contracts including the FAA’s predictive air traffic AI system, and its stock has risen more than 600% since the start of 2024.
The pattern
Karp’s net worth fluctuates with Palantir’s share price, which has traded between $106 and $208 over the past year, meaning the Bloomberg figure is a snapshot rather than a fixed number. The reported 20-property portfolio has not been independently confirmed in its entirety.
What is confirmed is the scale of his recent purchases: $120 million in Colorado, $75 million in Miami, and a 500-acre estate in one of the least populated towns in New Hampshire. Together, they form a portfolio designed around a single principle that Karp’s own company has made a $75 billion business out of undermining: the right to be left alone.










































































You must be logged in to post a comment Login