If you’re looking to explore your creativity, there are a number of iPad apps that can help you get started. Although the iPad started off as a simple device that could be used to stream content or browse the web on the go, Apple has essentially turned its iPads into powerful machines that can be used to do things like create digital art and edit videos.
We’ve compiled a list of some of the best iPad apps for creativity that are available on the App Store.
Before we delve in, it’s worth noting that although Adobe’s creative apps are often top choices for creativity on the iPad, this list won’t include them because they are already well-known. We’re focusing instead on somewhat lesser-known apps that you’ll want to know about and try.
Lake
Image Credits:Lake
Not every creative app has to involve a blank page staring back at you. Lake takes a more relaxed approach, letting you digitally color hand-drawn illustrations by independent artists using more than 700 colors and a selection of brushes.
If you want to let your imagination run wild, you can also color and draw on a blank canvas. You can also jot down your thoughts in a coloring journal.
Advertisement
The app is great for people who are just getting started with exploring their creativity or for those who just want a moment to de-stress. You don’t have to be artistic to use it, either; there’s no penalty here for drawing outside the lines.
Lake offers free access to a limited number of illustrations. To unlock the full catalogue of illustrations and features, you’ll need to pay a $9.99 monthly subscription fee.
Techcrunch event
San Francisco, CA | October 13-15, 2026
Advertisement
Procreate
Image Credits:Procreate
Procreate is one of the most popular drawing apps for the iPad, and for good reason. The app lets you create digital paintings, sketches, and illustrations using dozens of different types of brushes. Procreate is easy to use and features built-in gesture controls, along with a simple interface.
The app allows for high-resolution canvases up to 16K by 8K on compatible iPad Pros. It also lets you create storyboards, GIFs, animatics, and simple animations. Plus, you can import image files such as JPG, PNG, and TIFF. Procreate includes several features that are designed to help you during the creative process on your iPad, such as QuickShape, StreamLine, Drawing Assist, and ColorDrop — tools that handle the technical heavy lifting so you can focus on the fun part.
Once you’re finished creating your piece, you can relive your creative journey with the app’s time-lapse “Replay” feature — a surprisingly satisfying way to watch your work come together — and share a 30-second clip on social media.
Advertisement
You can access Procreate with a one-time payment of $12.99.
LumaFusion
Image Credits:LumaFusion
LumaFusion is a great app for editing videos if you’re ready to graduate from iMovie. The app features numerous user-friendly features that make it perfect for aspiring videographers or indie filmmakers on a budget.
With LumaFusion, you can create multiple layer edits with 4K ProRes and HDR media. You can add different effects, choose from dozens of transitions, and record voice-overs. The app lets you create multilayer titles and import fonts and graphics. Plus, you can fine-tune audio with Graphic EQ, Parametric EQ, Voice isolation, and more.
The app lets you create projects with a variety of aspect ratios, including 16:9 landscape, 9:16 portrait, square, widescreen film, anamorphic, and more.
LumaFusion is available for a one-time payment of $29.99. You can also purchase additional features, such as multicam editing and the ability to send your project to Final Cut Pro for Mac.
Advertisement
Canva
Image Credits:Canva
Canva offers a user-friendly platform that allows anyone to create visual content, even without graphic design experience. You can use it to create presentations, infographics, videos, websites, social media posts, and more with over 250,000 templates.
Canva features tools for editing photos, personalizing content with logos and images, adding audio, and cropping and speeding up video.
The platform also has a series of AI features that are designed to make the creation process easier. For instance, you can extend an image using “Magic Switch” or turn ideas into images with “Magic Media.”
Canva is free but offers a $12.99 monthly subscription if you want unlimited access to its AI features, premium templates, and more.
Affinity Designer 2
Image Credits:Affinity
Affinity Designer 2 is a graphic design app that combines vector design, pixel-based textures, and retouching into a single platform. It’s great for professional illustrators, web designers, game developers, and other creatives.
The app lets you create illustrations, branding, logos, icons, UI/UX designs, typography, posters, labels, fliers, stickers, concept art, digital art, and more. It supports Apple Pencil’s precision, pressure sensitivity, and tilt functionality.
Advertisement
Affinity Designer 2 features gesture controls to speed up your workflow, and it lets you customize keyboard shortcuts. You can also do things like create your own custom font and zoom to over 1,000,000% for absolute precision.
You can access the app through a one-time payment of $18.49.
Concepts
Image Credits:Concepts
Concepts is a great app for exploring your ideas and experimenting with designs. You can use the app to sketch plans, make notes and mindmaps, and draw storyboards and designs.
The app features Nudge, Slice, and Select tools that allow you to easily change any element of your sketch without redrawing it. The app features realistic pens, pencils, and brushes that flow with pressure and tilt.
Concepts gives you access to scale and measurement tools that calculate real-world dimensions, and also features a tool wheel or bar that you can personalize to your liking.
Advertisement
The app’s basic features are free. Concepts offers a $4.99 monthly subscription if you want access to additional features, such as the ability to create your own brushes and premium editing tools.
Tayasui Sketches
Image Credits:Tayasui Sketches
Tayasui Sketches is a good, user-friendly sketching and drawing app. It has several different features such as a realistic watercolor brush, digital acrylic brushes, the ability to blend two colors to get the perfect shade, gradient and depth tools, and more.
The app lets you multitask by opening up another app and dragging lawyers and documents between the two. There’s also a “Zen Mode” that lets you create without distractions.
You can also upload your images to incorporate them into your creations. Tayasui Sketches lets you store your creations into personalized folders.
Tayasui Sketches’s basic features are free. The app offers a $2.99 monthly subscription that unlocks unlimited layers, new brushes and markers, an extended brush editor, the ability to backup your drawings, and more.
Advertisement
Dudel Draw
Image Credits:Dudel Draw
Dudel Draw is a bit different from the other apps on this list: It’s designed to unleash your creativity by giving you a new shape every day that serves as a starting point to sketch on top of.
These daily shapes vary from basic geometrical forms to more complex and abstract designs. Plus, you can explore your creativity further by choosing to view the shape from all angles with the app’s “flip” and “rotate” features.
You can also get your friends in on the creativity with some fun competition by comparing your different creations each day. Dudel Draw offers a great way to sharpen your artistic skills, challenge yourself to create something new every day, and just simply express yourself.
Dudel Draw is available for free.
Sketchbook
Image Credits:Sketchbook
Sketchbook is an easy-to-use app for sketching, painting, and drawing. The idea behind the app is to make it feel like you’re drawing on paper, as the digital brushes and pens behave like the real thing.
The app’s interface is simple and lets you tuck away palettes and tools to make it easier to focus on drawing.
Advertisement
You can customize brushes by tweaking the size, opacity, flow, and more to align them with your personal style. There’s also a “predictive stroke” feature that helps smooth out the lines of your drawing.
Sketchbook is available for free, but you can unlock premium features for a one-time payment of $2.99. Premium features include the ability to import additional brushes and color palettes, adjust the size of your canvas after you’ve started working, export multiple canvases or an entire album as a PDF, and more.
This story was originally published in December 2024 and is updated regularly with new information.
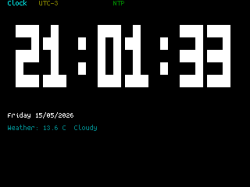
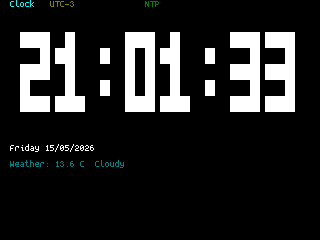
If you’re of a certain vintage, you have probably looked at some of the microcomputers on the market these days and thought “that would have been a decent workstation back in the day!”. We certianly have, and so did [Roberto Alsina]. Rather than allow himself to contemplate his age and threfore rapidly approaching mortailty, [Roberto] wrote a useful operating system called ESP-Osito for the Cheap Yellow Display, which he refers to as “the cheapest computer”. He’s not wrong, and it’s certainly a better use of time than an existential crisis.
He explains some of his reasoning behind the project in an accompanying blog post, but on the project page he compares it to a Palm Pilot– it’s on quick, apps load quick, and the API is simple enough for easy app creation in a few hundred lines of C, unlike certain pocket computers we won’t name. Sure, there’s no multitasking, but when apps jump from SD card to run in memory in microseconds, who cares? Saving the current state of the app back to SD means the experience is virtually identical from a user perspective anyway.
DOS knew what time it was, but how many of us wasted phone time for weather reports?
As this is a one-man show for now, the app store won’t quite rival your smart phone– but there’s everything you’d expect on the 90s-era computer this has the horsepower of: a serial terminal, a text editor, a file explorer, a calculator, a clock, but also some things that aren’t so retro. The clock app gives weather info via futuristic wireless networking, the reader app takes Markdown text, and the chat app connects to an LLM somewhere instead of your friends on IRC. The blackberry keyboard option gives it a feel of a slightly different vintage. You can also play snake, because no computer is complete without games. The OS and all its applications are released under the MIT license on GitHub, and [Roberto] is actively looking for collaborators.
If you doubt the workstation comparison at the start of this article, this CYD runs Macintosh System 3 via a 68k emulator. That’s got old-school cred, but there’s something great about having retro constraints with modern code on modern hardware. In that way, ESP-Osito is similar to the 3D graphics engine behind this Wipeout clone.
Toyota’s lineup has a handful of four-wheel drive vehicles ready for off-roading adventures. Having full control of the drivetrain makes 4WD vehicles perfect for serious challenges. However, you probably don’t go off-roading all the time, even if you want to. But between commuting to work, dropping kids off at school, and running errands, Toyota doesn’t want you to forget about your vehicle’s four-wheel drive.
In your owner’s manual, you’ll see Toyota’s advice to drive your vehicle in four-wheel drive at least ten miles every month. This will keep the front-drive components lubricated. But four-wheel drive is intended for use on rainy, snowy, muddy, or sandy roads, as well as on rugged terrain, allowing slower, more controlled driving. When you’re on a flat, smooth road, using 4WD will use up a lot of gas and cause additional vehicle wear due to extra gears and driveshafts being engaged. You may also have a tougher time braking and turning. If the weather outside is nice, you can still use 4WD by finding a straight, flat road with no turns.
Advertisement
Which Toyota vehicles have 4WD?
Harazaki Ananta Hondro/Shutterstock
Toyota’s lineup includes a wide range of vehicles, from commuters to off roaders. There are currently five models with four-wheel drive. The Toyota Tacoma, 4Runner, and Tundra have 4WD available, the Sequoia has standard 4WD, and the Land Cruiser has full-time 4WD.
Most of Toyota’s vehicles have all-wheel drive instead, from the hybrid Prius to the sporty GR Corolla to the reliable Highlander. That’s because AWD is best used on-road, sending power to all four tires simultaneously. This keeps the vehicle moving forward on slippery surfaces or while cornering at high speeds. Since AWD allows each tire to rotate at its own individual speed, it’s better than 4WD for snow, rain, and other bad weather while you’re commuting, although the increasing price for AWD is getting harder to ignore.
Four-wheel drive offers more control since the front and rear axles turn at the same time, making it ideal for extreme off-roading — but it uses more power, which is why you don’t use 4WD on paved roads — except for those 10 miles a month, of course.
A recent Indian court ruling against Google’s keyword advertising practices has gained fresh attention after founders said competitors have long used the system to siphon off customers and force companies to pay to protect their own brands.
The ruling, delivered by the Delhi High Court on May 22 in a trademark dispute involving bathroom fittings maker Hindware, found Google liable for trademark infringement over its keyword advertising practices and awarded the company ₹3 million (around $31,600) in nominal damages.
In her 163-page judgment (PDF), Justice Mini Pushkarna rejected Google’s argument that it was merely a passive intermediary in serving ads on its search platform. The judge said Google, through its AdWords platform, allowed Hindware’s rivals to use “Hindware” as a keyword to target users searching for the brand.
“Google by selling the trademark of the plaintiff [Hindware] as a keyword without any authorization for commercial gains is infringing the plaintiff’s right to exclusive use of its trademark under Section 28 of the Trade Marks Act,” the judge said.
Advertisement
The judgment drew attention on Friday after Indian entrepreneurs, including Zerodha founder Nithin Kamath and Zoho founder Sridhar Vembu, publicly backed the ruling, arguing that competitors have long used Google’s advertising tools to divert traffic from established brands and force companies to spend money protecting their own names.
Kamath, who said Zerodha had faced the issue for more than a decade, wrote on X: “Whenever someone searches for ‘Zerodha,’ the traffic should rightfully come to Zerodha. But what often happens is that the first couple of results on Google Search are ads, leading the customer to a competitor’s website.”
Google, for its part, said its Ads policy on trademark keywords “does not allow competitor advertisers to use trademarked terms in the ad-text of an ad” and that the policy is applied globally.
“We look forward to continuing to align our operations with local legal frameworks while maintaining strict standards to protect our users’ long-term interests,” a Google spokesperson said in a statement to TechCrunch.
Advertisement
India is a key market for Google, with more internet users than any country other than China, making court decisions affecting its search and advertising businesses particularly significant.
Legal experts, however, said the implications of the ruling may be narrower than some of the public reaction suggests.
“The judgment per se will require platforms to relook at their processes to see if their automated tools encourage or offer trademarked terms to advertisers at large,” said Aprajita Rana, a partner at AZB & Partners.
Nonetheless, Rana told TechCrunch that the decision does not have a “far-reaching impact” on online platforms’ liability in India, as courts have already established that internet companies can lose legal protections when they play an active role in unlawful activity.
Advertisement
“What’s important in this case is how providing access to trademarked terms, even in ad curation that’s between online platforms and advertisers and not known to customers, can amount to a participative activity for platforms,” Rana said.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
The Karcher K5 Comfort Premium makes tough cleaning jobs feel refreshingly easy, with a compact design, four-in-one lance, integrated detergent system and comfortable trigger that help it breeze through patios, driveways and cars. It’s not perfect, lacking finer pressure adjustment and bundled specialist accessories, but it’s still an easy recommendation..
Compact, easy-to-store design
Versatile four-in-one lance
Excellent cleaning performance
No pressure adjustment
Accessories cost extra
Universal detergent lacks foam
Key Features
Advertisement
Review Price:
£400
Compact, storage-friendly design
Advertisement
Smaller and easier to store than older pressure washers.
Four-in-one cleaning power
Advertisement
Switch between four spray modes with a twist.
Built-in detergent convenience
Advertisement
Lets you swap between water and detergent in seconds.
Introduction
Pressure washers aren’t exactly known for being elegant. They’re usually bulky, awkward to store and just a little bit annoying to drag out when it’s time to tackle the driveway, patio or car.
That’s what makes the Karcher K5 Comfort Premium so appealing: it takes the heavy-duty cleaning power you’d expect from a mid-range pressure washer and wraps it in a design that’s noticeably easier to handle day to day.
Advertisement
Part of Karcher’s new Comfort range, the K5 Comfort Premium promises a more user-friendly experience from top to bottom, with a lighter trigger setup, an integrated hose reel, a built-in detergent system, and a four-in-one lance designed to cut down on faff.
Advertisement
After using it to clean everything from a grimy driveway to a dirty car, it’s clear this is a pressure washer built with convenience in mind – even if a couple of omissions stop it short of perfection.
Design and features
Compact design
Four-in-one lance
Integrated detergent system simplifies cleaning
Coming from my years-old, bulky, heavy pressure washer, the K5 Comfort Premium is something of a dream – and that’s kind of the point of the new ‘Comfort’ collection.
Image Credit (Trusted Reviews)
It’s absolutely dinky compared to my old unit, standing at just over 66cm tall and 34cm wide, with a retractable handle that not only makes lugging it around much easier but also means an even more compact footprint for storage – ideal for me and my limited shed space. It’s still a little on the heavier side at 13.8kg, but the large wheels make transporting it from one area to another easy enough.
Advertisement
Advertisement
But I’m getting ahead of myself somewhat here; let’s start with the unboxing experience. As with most pressure washers, the K5 Comfort Premium comes in several pieces, which might look daunting to the untrained eye, but it’s really simple to snap together without any tools. It took me around five minutes to follow the Ikea-style instructions, with no strops or breaks in sight.
The Comfort redesign extends to the gun, which is surprisingly lightweight, easy to manoeuvre, and much more comfortable to use over long periods, with less pressure required to depress the trigger. I spent three hours pressure washing my driveway, and my hands still weren’t aching by the end.
Image Credit (Trusted Reviews)
The gun attaches to the body of the pressure washer via a 10-meter-long high-pressure hose, which is stored in an integrated hose reel that’s surprisingly smooth to extend and retract. Karcher takes additional points here too, with the pressure hose coming out of the opposite side to the power cable and hose input to stop everything from getting tangled. A nice touch indeed.
Image Credit (Trusted Reviews)
The highlight of the experience is the new four-in-one multijet lance, which twists into the gun with surprising ease. It’s a really handy bit of kit too, offering four distinct modes that you can switch between simply by rotating.
Advertisement
The dirt blaster is my favourite for cleaning patios and other brickwork, essentially rotating the tiny jet at a rapid pace to shift even the most stubborn stains and grit, but there’s also the more traditional high-pressure flat jet and reduced-pressure flat jet for jobs like cleaning cars.
Advertisement
Image Credit (Trusted Reviews)
What’s most impressive is the integrated detergent jet; with a quick twist of the nozzle, you can spray detergent mixed with water without needing to attach a front-heavy foaming attachment. That’s because the K5 Comfort Premium comes with a new detergent system that integrates the bottle directly into the pressure washer’s body, negating the need for a tank, and includes a bottle of eco-friendly detergent in the box.
You can remove the detergent adaptor from the body and use it on the end of the gun if you prefer, complete with dosing settings, but I really like the integrated approach. It makes tasks like cleaning cars much easier, as I can simply switch between water and detergent without faffing around switching lance attachments.
Image Credit (Trusted Reviews)
As compact as the K5 Comfort Premium is, it still has plenty of space to store the lance and gun, along with any other optional accessories compatible with the K5. And optional accessories there are aplenty, including heads specialised in cleaning patios and cars. It’s just a shame none of these actually come in the box.
Advertisement
Performance
Powerful cleaning with fast results
Lightweight gun improves long-session comfort
No pressure adjustment
As you might expect, the Karcher K5 Comfort Premium is an absolute joy to use. Simply attach the lance to the gun with a push-twist, attach the garden hose to the body, plug it in and power it on.
One note though; release the built-up pressure in the system by pressing the gun’s trigger before starting, or the unit won’t power on. I thought mine was broken after changing power source multiple times before I realised that was the (refreshingly simple) fix.
Image Credit (Trusted Reviews)
That aside, all you need to do is select the type of jet you want to use and press the trigger to get going. The only real decision is which of the modes you want to use. I found that the dirt blaster mode was the most effective for cleaning patios and driveways, though I certainly wouldn’t recommend it for cars, bins or anything like that. I tried it on an old bin and it literally stripped a layer of plastic off – if anything, that’s testament to the level of power here.
That said, cleaning my driveway was an absolute doddle. The dirt blaster mode made incredibly quick work of my (embarrassingly dirty) driveway, bringing it back to its original vibrant colours with only a single pass in most places. I needed to hone in to make sure I got every bit of dirt, as moving it too quickly results in a circular outline, but I’d be lying if it wasn’t satisfying as heck. As noted earlier, it took three hours to do fully, but it felt like half an hour.
Advertisement
Advertisement
Much of the ease of use comes from just how lightweight and comfortable the gun is to use; as noted, it’s lightweight and, with very little pressure needed to depress the trigger, it’s something I could use one-handed much of the time.
Image Credit (Trusted Reviews)
Cleaning the car was equally as successful, with the long 10-meter hose allowing me to fully circle my car (and then some) without accidentally pulling the pressure unit over. Starting with the (less aggressive) reduced-pressure flat jet, I rinsed off the car before switching to the detergent jet – again, something that required no more than a twist of the nozzle – to lift some of the more stubborn stains from the car.
The eco-detergent supplied in the box isn’t designed specifically for cars – it’s a universal cleaner – so there wasn’t much foaming, but it was still easy to apply. I think I’ll keep the Karcher bottle and refill it with a proper foaming detergent for future car cleans.
Advertisement
Advertisement
Still, once done with foaming, switching back to a regular jet to rinse was easy, and the whole process took no longer than 10 minutes – much faster than doing it by hand, with pretty similar results. It didn’t quite get some of the most stubborn stains (those damn birds!), but it was a damn sight cleaner than it was before.
Even if it takes longer, Karcher claims that the K5 Comfort Premium’s water flow rate is only 40% of a garden hose’s, making it a fairly efficient way to clean medium-sized spaces if you’ve got a water meter.
Image Credit (Trusted Reviews)
After using the Karcher to clean my driveway, garden patio and path, and my car, my only complaint is that there’s no way to adjust the pressure level, either on the gun or on the pressure washer’s body; it’s simply on or off.
Yes, I can switch between the three spray modes if I need to wash something a little more fragile, but what if I want to, say, keep the rotation of the high-pressure dirt-blasting mode while toning it down a bit? There are plenty of pressure washers that offer this, so I’m a little surprised it’s not on offer here.
Advertisement
Advertisement
Should you buy it?
You want compact, fuss-free cleaning
The K5 Comfort Premium is easy to store, easy to handle and powerful enough to make light work of patios, driveways and cars, with smart extras like its four-in-one lance and integrated detergent system.
Advertisement
You want finer control or more in the box
For all its polish and power, the K5 Comfort Premium offers no real pressure adjustment beyond its spray modes, and it’s a shame the more specialised accessories cost extra.
Advertisement
Final Thoughts
A great pressure washer should make tough jobs feel less like hard work, and that’s exactly what the Karcher K5 Comfort Premium does.
It’s compact, thoughtfully designed and genuinely enjoyable to use, with standout touches like the four-in-one lance, integrated detergent system and a much more comfortable trigger setup than I’m used to. More importantly, it delivers where it counts, making quick work of patios, driveways and cars alike.
Advertisement
It’s not perfect – I’d have liked some form of pressure adjustment beyond the preset spray modes, and it’s a little disappointing that none of the more specialised accessories are bundled in the box – but even so, those feel like relatively minor gripes when the overall experience is this polished.
If you want a powerful pressure washer that’s easier to store, easier to manoeuvre and far less faff to use than older, bulkier alternatives, the K5 Comfort Premium is easy to recommend. It’s expensive, sure, but it feels like money well spent.
How We Test
We test every pressure washer we review thoroughly over an extended period of time. We use standard tests to compare features properly. We’ll always tell you what we find. We never, ever, accept money to review a product.
Used as our main pressure washer for the review period
Tested on a variety of surfaces for cleaning power
FAQs
Is the Karcher K5 Comfort Premium good for car cleaning?
Yes. It works well for washing cars thanks to its reduced-pressure flat jet and built-in detergent system. You can rinse, apply detergent and switch back to a regular spray with a simple twist of the nozzle, making it much quicker and less fiddly than using separate attachments.
Advertisement
Does the Karcher K5 Comfort Premium have adjustable pressure?
Not in the traditional sense. You can change between different spray modes on the lance, but there’s no dedicated pressure control on the gun or main unit if you want finer adjustment.
Paramount+ looks to have used generative AI to whip up a thumbnail for Star Trek II: The Wrath of Khan, according to a report by Kotaku. The image shows Captain Kirk, as played by William Shatner, dressed in a business suit. Kirk never dons a business suit in Wrath of Khan, or any other time throughout Shatner’s decades of portraying the character. He did rock a flannel shirt and jeans once during a visit to 1930s Earth.
Paramount+ wanted to use the image on the left as a poster for the wrath of Khan, so they used everyone’s least favorite technology to generate the rest of the image.
I’ve watched every episode of Star Trek across a dozen shows and I’m not even sure business suits exist in that far-flung future, aside from an occasional appearance on the Holodeck. There’s no money, so not much need for business.
That leaves us asking why Paramount+ and its little AI buddy decided to plop Starfleet’s most iconic captain in a button-up shirt and tie. We don’t know exactly what happened, but artist Ryan Estrada has an idea. He noted that the actual image of Kirk is from Wrath of Khan, pulled from a scene in which the captain is getting a retinal scan to access a computer file. It’s not a particularly exciting scene, and he’s wearing a Starfleet uniform.
Estrada speculates that Paramount+ got attached to that image of Kirk getting a retinal scan and wanted to highlight it further by making it a thumbnail. However, the image from the film is a close-up of Shatner’s face, so generative AI was used to place Kirk’s head inside of a fake body and put that body in a business suit. His hair also looks very fake and weird as the original frame cuts off at his forehead. Long live AI slop Kirk.
Advertisement
Kotaku has confirmed that the thumbnail is still on the streaming platform, as have folks throughout the internet. Paramount owner David Ellison recently toldCNBC that the company is “using technology to transform every single aspect of this business.” If that thumbnail is a harbinger of things to come, Trek fans should likely start stocking up on Blu-Rays.
Wix is laying off roughly 20% of its workforce, about 1,000 employees, as CEO Avishai Abrahami cites both the rapid evolution of AI and currency pressure from a stronger Israeli shekel against the dollar. The web developer joins a growing list of tech companies making similar cuts, including Amazon, Block, Cisco, Cloudflare, Meta, Microsoft, Oracle and Intuit. Fast Company reports: “We have witnessed the most significant shift in how companies are built since the invention of modern programming languages in the 1970s,” [wrote Abrahami]. “This is not just about adopting new tools — it is about rewiring how companies are built, how they think, how they manage, and how they operate. Companies that embrace this change will not only build faster; they will build things the previous generation literally could not have imagined.”
Abrahami also cited the poor exchange rate between the Israeli shekel and the U.S. dollar. The Israeli currency has significantly strengthened in the past few quarters against a weakening dollar, and the shekel is up nearly 30% against the greenback over the last year.
“As the majority of our teams are Israel-based, a very meaningful portion of our costs are shekel-denominated, while our revenue is largely dollar-denominated,” Abrahami explained on X. “This creates a structural pressure on our ability to operate at our current scale. It is a reality that directly shapes what is sustainable for our company.”
Dell’s stock skyrocketed 32.76% on Friday, “its best day ever,” reports CNBC, after Dell “reported its fastest pace for revenue growth for any period since returning to the public market in 2018…”
“Shares are now up 234% in 2026.”
Dell, which reported first-quarter earnings after the bell on Thursday, saw a flood of artificial intelligence-related demand for its servers, which contain graphics processing units from companies like Nvidia. Quarterly revenue soared nearly 88% year over year, with AI server revenue alone increasing 757% from a year earlier to $16.1 billion…
Ben Reitzes, head of technology research at [research/investment firm] Melius, said he’d “never seen anything like” Dell’s latest quarter. “They beat every line in the model, so this wasn’t just AI, it was great execution,” Reitzes told CNBC’s “Squawk on the Street.” “They beat whatever we would’ve thought….”
Advertisement
Morgan Stanley wrote that while they expected a clean beat and raise this quarter, they’re “eating our humble pie” off the back of Dell’s results. “We got this one wrong, and our model/PT are under review,” the analysts wrote. “This was — across the board — one of the most impressive quarters we’ve seen in our time covering Hardware, especially in the context of what is happening across the component universe.”
We may receive a commission on purchases made from links.
The wearable technology landscape has shifted dramatically over the past few years. They’ve transformed from basic step-counters to advanced health companions. You can now get details about your sleep, your heartbeat rhythm, get a basic ECG done, and even check your blood pressure. Smartwatches are no longer just about logging a morning run and seeing app notifications, but they’re seamlessly integrated into our daily routines. Of course, when shopping for that new smartwatch, there is still a difference between cheap and expensive smartwatches in terms of build quality, sensor accuracy, and long-term support.
This market has matured into something meaningful and interesting. With new releases now featuring better battery life, sharper displays, improved health tracking, and designs that people are actually excited to put on their wrist. We are also seeing the return of tactile buttons with recently released smartwatches, as brands are making efforts to blur the line between traditional timepieces and wrist computers.
Advertisement
Choosing the right smartwatch always comes down to personal priorities. The best choice for you depends on which ecosystem (Android, Apple, etc.) you’re already in and what features are important to you. That’s why we have compiled a list that takes into account customer reviews, personal experience, and long-term data to give you some of the best smartwatches you can buy right now.
Advertisement
Apple Watch Series 11
Ringo Chiu/Shutterstock
If you’re already invested in the Apple ecosystem — meaning you own an iPhone or a bunch of Apple devices — then you’ll know about the Apple Watch Series 11, the latest and greatest smartwatch offering from the company. This model promises one of the most compelling smartwatch experiences in the market. The level of integration with iPhone, the depth and reliability of its heart rate monitor, and the polished software all give you plenty of value for your money. I have previously owned an Apple Watch Series 8, and the only negative aspect of it was the battery. A few generations later, Apple has finally addressed that.
The Series 11 has a battery life of up to 24 hours, which is amazing, though of course real-life autonomy varies based on your smartwatch usage. Also, the Apple Watch Series 11 holds the title of the highest-rated smartwatch by Consumer Reports. CR praised the watch for its accurate tracking of heart rate, step count, and sleep.
The Series 11 brought a major new addition, the Hypertension notifications. Though not exclusive to Apple Watch Series 11, this feature is available in over 150 countries. It looks for patterns of chronic high blood pressure and alerts users about hypertension. The screen has a peak brightness of 2,000 nits, making the display perfectly visible in harsh outdoor sunlight. If you are sitting on an older device and debating whether you should buy a Series 8 instead, even just the physical upgrades are enough to justify the leap.
Advertisement
Samsung Galaxy Watch8 Classic
VGV MEDIA/Shutterstock
If you are looking for the best smartwatch in the Android world, then the Samsung Galaxy Watch8 Classic is your answer. With this model, Samsung brought back the rotating bezel, which was removed after the Galaxy Watch6 Classic in 2023. Fan demands persuaded Samsung to put the physical rotating bezel back on the watch. In my opinion, this is the best way to navigate a smartwatch without having to touch the screen. This is also the first time a Samsung watch shipped with Google Gemini support built in, which is useful for setting reminders, pulling weather updates, and summarizing tasks without touching the phone.
The device carries a certain weight and presence, that commands attention to the wrist, steering away from its minimalist look. I have used the Galaxy Watch4 (and still have it), but the Galaxy Watch8 Classic was enough to lure me into buying it. It has the perfect combination of software and hardware that I was looking for. However, if you currently own a recent Galaxy Watch, it’s worth investigating whether the upgrade to Galaxy Watch8 is worth it for you.
The AMOLED display peaks out at 3,000 nits. The whole watch can resist water immersion of up to five atmospheres and has an IP68 rating. It also claims to introduce antioxidant level (related to dietary needs) and vascular load (an indicator of cardiovascular need) as two new health metrics. The interface and the battery life have also been improved. Overall, the Samsung Galaxy Watch8 Classic is one of the best Android smartwatches and is an absolute no-brainer for Samsung Galaxy fans.
Advertisement
Google Pixel Watch 4
Erman Gunes/Shutterstock
While iPhone users overwhelmingly default to the Apple Watch for the best ecosystem integration experience, things in the Android world are slightly different. Google, the owner of Android, released its first-ever smartwatch in 2022, and the current generation — the Google Pixel Watch 4 — is a good option in 2026. While the Pixel Watch 4 isn’t much different from its predecessor, the new W5 Gen 2 processor with a Cortex-M55 co-processor and better battery life is something that makes it a better buy.
If you are looking for a smartwatch that lasts a long time on your wrist, the Pixel Watch 4 is a good option. In our review of the Pixel Watch 4, we tested the battery life and came away highly impressed. In an era where most smartwatch batteries would die in about a day, the Watch 4 could last a solid two days or more. The display has also seen an improvement of 10% more screen real estate than the Pixel Watch 3, which isn’t exactly visible to the naked eye, thanks to the smaller bezels. It tops out at 3,000 nits of peak brightness, 1,000 more than the Pixel Watch 3. It is available in two sizes and a bunch of different colors.
Compared to the Pixel Watch 3, the most notable change is that Gemini support is now built-in, meaning you can throw it any question or make it do any task you need right from your wrist. Aside from all the standard health tracking features, the Pixel Watch 4 can be used as a cycling dashboard. Not something new, but nice to have as a built-in feature. While there are cheaper alternatives to the Pixel Watch 4, this smartwatch justifies its $400 price with a premium build, seamless experience, and battery life.
Advertisement
Garmin Venu 4
Battery anxiety is the silent killer of modern smartwatch experience, but it completely vanishes the moment you strap on the Garmin Venu 4. While other smartwatches are good for normal users, a serious runner or cyclist will want something more specialized. When you aim for such heavy tasks, battery life becomes crucial, and Garmin Venu 4 delivers.
Advertisement
The Venu 4 comes with an all-metal casing and an AMOLED display, which is brighter than the Venu 3. However, while the Garmin Venu 4 being able to last up to 12 days on a single charge is impressive, battery life is slightly down from its predecessor because of the brighter display, according to Tom’s Guide. Speaking of features, on top of nap detection, the Garmin Venu 4 also gets two new sleep features — sleep alignment and sleep consistency. Additionally, it gets Garmin’s most advanced training tools, such as Training Readiness and suggested workouts, along with ECG readings, making it a true fitness enthusiast watch.
Our review of the Garmin Venu 3 will give you a good idea of what this brand offers. Sadly, there is still no cellular data option, and its store has limited apps. But the Venu doesn’t try to be the next Google or Samsung watch, and instead focuses on providing accurate fitness readings.
Advertisement
Withings ScanWatch 2
In a market that is filled with smartwatches with glowing OLED screens and watches that are more of a mobile phone on a wrist, the Withings ScanWatch 2 tries to be different. Embracing subtlety is a bold design choice, but that’s what makes it stand out from the crowd. The ScanWatch 2 is available in two sizes and a bunch of colors, and there is also the option to choose band types. It’s a good choice for those looking to track their health metrics without wearing something that looks like a traditional smartwatch.
This hybrid approach is quite impressive. Behind the mechanical hands, the Withings ScanWatch 2 can perform single-lead ECGs (which are useful, if limited) and sleep tracking, packaged with traditional aesthetics that can go with any outfit. In their review, experts at PCMag praised the smartwatch’s design and the staggering 30-day battery life, which completely changes the user experience and frees you from daily charging. While the original ScanWatch barely impressed our reviewer when it came out, the ScanWatch 2 seems to be an upgrade well done. The watch comes with body temperature tracking and menstrual cycle tracking.
So, if you hate the traditional smartwatch look and want something aesthetically pleasing on your wrist, without compromising on all the health-tracking features of regular smartwatches, the $370 Withings ScanWatch 2 is something you should consider.
Advertisement
Apple Watch Ultra 3
i viewfinder/Shutterstock
Don’t be confused by the second Apple Watch gracing this list when we already have the Apple Watch Series 11, which we called one of the best smartwatches you can buy in 2026. The Apple Watch Ultra 3 serves a totally different customer segment — it’s heavily marketed towards deep-sea divers and explorers who are always on the move. To satisfy their needs, Apple went all out with a bulky titanium frame and blindingly bright display. This watch is called “Ultra” because it offers rugged durability and exceptional battery life.
Owning an Apple Watch Ultra over the Watch Series 11 shows the user is more concerned about practicality that extra features. If you spend meaningful time running trails, swimming in open water, or going on multi-day hikes, or often put yourself in a situation where you might need emergency satellite messaging, the Watch Ultra is for you. Ray Maker, aka DC Rainmaker — an influential sports technology reviewer — completed a 70km non-stop hike/trail-run just to see if the Watch Ultra 3’s battery would hold, and it did. Separately, he noted that the two-way satellite communication on the watch is the easiest of any device he’s tested.
Advertisement
Compared to the Series 11, the Apple Watch Ultra 3 has better water resistance, a better build, and longer battery life. But again, it is not for everyone.
Advertisement
Huawei Watch GT 5 Pro
Most of the popular smartwatches in the market are tied to an ecosystem, dominated by Apple and Samsung. But the Huawei Watch GT 5 Pro breaks up this ecosystem, and is ideal for the audience that just wants great hardware and a long battery life. The hardware feels premium — it has a titanium bezel, a sapphire crystal display, and a build quality that gives smartwatches from Samsung and Apple a run for their money.
Experts at GSM Arena tested the Huawei Watch GT 5 Pro under a heavy-use scenario — using GPS tracking, voice calls, and a high brightness watch face during an intense workout — and the GT Pro lasted six days, much more than what the best options from Samsung and Apple offered. On settings approximating a normal day, but with the brightness set very low, the watch lasted 10 days. Since Huawei doesn’t rely on a proprietary ecosystem, the GT 5 Pro works fluidly across both Android and iOS, something that cannot be said about any Apple or Samsung product on this list.
The Huawei Watch GT 5 Pro offers golf, diving, and trail run modes, but the app ecosystem is thin and there is no cellular data option. Those are real trade-offs, but for someone who wants good-looking hardware, reliable health data, and a battery that lasts long, the GT 5 Pro is an excellent choice.
Advertisement
Methodology
Alina Mosinyan/Shutterstock
To pick the best smartwatches, we didn’t just look at spec sheets. We used our personal experience, read through customer feedback, and referenced the work of other trusted reviewers. We focused on the things that actually matter in a smartwatch: accurate health tracking, a battery that keeps it alive for more than half a day, how good it looks on your wrist, and if it’s actually worth your hard-earned cash. Finally, we made sure to include a watch for everyone; Whether you’re Team iPhone, Team Android, or somewhere in between, we made sure to include options that will pair perfectly with your phone.
Plastics, oil, petrol– the modern world is entirely dependent on hydrocarbons. The good sources are slowly running low and supply is increasingly complicated by geopolitical factors we really don’t want to get into, but hey! It’s just hydrogen and carbon, right like it says in the name. How hard could it be to roll your own at home. Well, if you’ve got a lab like [Marb]’s Lab on YouTube, it might just be doable, as he demonstrates in his latest video.
The Fischer-Tropsch reaction was discovered back in 1925 in Germany by a couple of gents named Fischer and Tropsch. In the unpleasantness that followed later, Germany made good use of their process on an industrial scale, since they had ample coal and no oil on hand. Coal-rich South Africa has also made us of it, particularly during the Apartheid-era trade restrictions. Every so often the idea of industrializing the process comes up in the USA, but there’s still enough oil there it doesn’t make sense economically.
Those nations all have something in common: they’re all coal-rich countries, and that makes sense because coal is easily converted to carbon monoxide and hydrogen– a combo known as syngas– and it just so happens that those are the feedstock for this reaction. The actual chemistry going on inside is quite complex, but conceptually it is pretty simple: hydrogen and carbon monoxide mix over a hot metal catalyst, and combine to form various hydrocarbons.
In [Marb]’s glassware-based demonstration, the catalyst is Cobalt (III) Oxide on silica gel– a lovely, cancer-causing substance that must be prepared for each use, as it lasts but 24 hours before further oxidization ruins it. That’s in spite of purging the system with argon– a necessary step if one does not wish to explode. The yield isn’t amazing, and [Marb] isn’t sure exactly what mix of hydrocarbons he has created– although they smell like gasoline and burn like the dickens, so mission accomplished.
Advertisement
This might seem like the furthest thing from green, but if you use solar power to run the process and something like woodgas– which is syngas by any other name– as a feed-stock, then you’ve got a carbon neutral energy storage medium.
In Baltimore County, Maryland on Oct. 20, 2025, a 17-year-old student named Taki Allen was sitting outside his high school after football practice when an artificial intelligence-enhanced surveillance camera falsely identified the Doritos bag in his pocket as a gun. Within moments police cars arrived, officers drew their weapons and Allen was forced to his knees and handcuffed while they searched him. All they found was a crumpled bag of chips. The AI’s misidentification and the human decisions that followed turned a normal evening into a traumatic confrontation.
On Dec. 24, 2025, Angela Lipps, a Tennessee grandmother, was released after spending five months in jail because facial recognition software had incorrectly connected her to fraud crimes in North Dakota, a state she had never visited. Police had arrested her at gunpoint while she was babysitting her four grandchildren.
These are unfortunate examples of how AI can lead to mistreatment of people because of technical flaws as well as misplaced human faith in the technology’s supposed objectivity. These cases involve different tools, but the underlying issue is the same. AI systems produce probabilities, and people treat them as certainties.
Advertisement
We are researchers who studythe intersection of technology, law and public administration. In researching how police departments use AI and how digital technologies operate in a democratic society, we have seen how quickly the shift from probabilistic prediction to operational certainty happens in practice.
AI policing tools are used in dozens of U.S. cities, although no public registry tracks the full footprint. The tools ingest historical crime data and score neighborhoods on predicted risk so officers can be routed toward the resulting hot spots. The mechanism is straightforward, but its consequence is not. Once a system signals a possible threat, the question is no longer how certain the prediction is but what to do about it. A statistical output turns into a deployment decision, and the uncertainty that produced it gets lost on the way.
A matter of probabilities
When generative AI models such as ChatGPT or Claude respond to human requests, they are not searching a database and pulling out facts. They are predicting the most likely answer based on patterns in data they have been trained on. When asked, “Who invented the light bulb?” the models do not go to a source or fact-check a finding. They generate a statistically probable answer which is “Thomas Edison.” The reply might be right, but it might not capture the full story – such as Joseph Swan’s parallel invention at the same time as Edison’s. The danger arises when people believe that the model is retrieving truth rather than generating likelihoods.
This distinction matters. The most probable response is not the same as a factually verified answer, complete with context.
Advertisement
Police handcuffed teenager Taki Allen at gunpoint after an AI camera system incorrectly indicated he had a gun.
This reality can be highly problematic for policingand law. For example, when law enforcement agencies use AI systems trained on geographical data to estimate where criminal activity is likely to occur, the algorithms analyze historical crime data and geographic patterns. These systems generate statistical risk scores or heat maps for locations based on prior incidents. But such predictions may have little bearing on who was involved in a new crime in the area, even if an algorithm generates information that sounds authoritative.
Some researchers have argued that predictive policing systems do not increase the likelihood that racial minorities will be arrested more often relative to traditional policing practices. The broader concern, however, is not limited to measurable disparities in arrest outcomes alone. It is about how probabilistic predictions can become standardized operational decisions absent further verification.
Advertisement
Artificial intelligence researchers caution against using these models in isolation for crime and legal proceedings or decision-making. Research at the University of Virginia’s Digital Technology for Democracy Labwith police chiefs shows that some law enforcement groups follow strict policies that dictate when technology is used in tandem with, or in place of, human discretion, while others have no such policy.
What most users do not realize is that AI systems rarely produce binary answers: yes or no, a positive identification or a negative one. They generate probabilities. Some systems assign scores that assess the system’s confidence in a prediction. In those cases, engineers set a confidence threshold, a level of certainty that determines when the system should trigger an alert about a possible threat. You can think of this threshold as settings on a control knob. A 95% confidence level, for example, indicates that the model considers its interpretation to be highly likely.
A low threshold catches more potential threats but increases false alarms. A high threshold reduces mistakes but risks missing real dangers. Either way, these algorithmic thresholds are often invisible to the public and are set quietly by vendors or agencies, even though they shape when police action begins.
Advertisement
Angela Lipps was unjustly jailed for more than five months based on a mistake by a facial recognition system.
Where to draw the line
In medicine, these kinds of trade-offs are explicit. Diagnostic tools are calibrated on the relative harm of different errors. In infectious disease settings, for instance, systems that detect infections are often designed to accept more false positives to avoid missing contagious individuals. Then medical professionals look into the human cases. And the algorithm-based decisions are subject to professional standards, ethics reviews and regulatory oversight.
In policing, an AI system must balance false positives, where the system flags a threat that does not exist, and false negatives, where it fails to detect a real danger. The trade-off carries significant consequences. A lower threshold may generate more alerts and allow officers to intervene earlier, but it also increases the risk of mistaken identifications, which happened to Angela Lipps, or escalated encounters like the one Taki Allen experienced. A higher threshold may reduce wrongful interventions but could allow legitimate threats to go undetected.
Some law enforcement agencies argue that acting on imperfect signals is preferable to missing serious risks. But lowering the bar for algorithmic alerts based on probabilistic estimates effectively expands the number of people subjected to police attention. It is important to realize that these thresholds are not neutral features of the technology; they are choices embedded by the creators in the model’s code. Decisions about where to draw the line determine when an algorithmic suspicion becomes a real-world police action, even though the public rarely sees or debates how those thresholds are set.
Advertisement
Limits of optimization
Developers often use several methods to determine where to set a confidence threshold. Techniques such as “receiver operating characteristic curve analysis” examine how changing the threshold for an alert alters the balance between correctly identifying real events and mistakenly flagging harmless ones. Precision–recall analysis examines a similar trade-off, asking how accurate the system’s alerts are relative to the number of incidents it successfully detects.
These approaches could help calibrate systems more responsibly by testing how often an algorithm wrongly flags people or locations. Fine-tuning can improve system performance. But the techniques cannot resolve the underlying question of how much algorithmic uncertainty society is willing to tolerate.
In law, legal standards of proof determine how convincing evidence must be before a judge or jury can rule in favor of a plaintiff or defendant. Courts use formal standards of proof depending on the stakes, such as probable cause, preponderance of the evidence and beyond a reasonable doubt. These standards reflect a societal judgment about how much uncertainty is acceptable before exercising legal authority. A court does not accept a guess or a prediction; it follows a process to weigh evidence. Unlike humans, an AI model does not usually say, “I’m not sure.” A model typically has confidence in its reply, even when the answer is incorrect.
Stakes are rising as AI enters the courtroom, law enforcement, the classroom, the doctor’s office and the public sector. It is important for people to understand that AI does not know things the way many assume it does. It does not distinguish between “maybe” and “definitely.” That is up to us. We believe that technologists should design systems that admit uncertainty and need to educate users about how to interpret AI outputs responsibly.


































































You must be logged in to post a comment Login