Two former OpenAI employees and a group of AI safety nonprofits are warning that Elon Musk’s AI lab, xAI, could become a liability for prospective investors in SpaceX, which is preparing to file what’s expected to be the largest initial public offering in Wall Street History.
In a letter directed to investors published on Tuesday, the ex-staffers highlighted what they describe as “unpriced risks” related to xAI that could complicate SpaceX’s reported plans to raise up to $75 billion as part of its IPO. The rocket company’s private valuation shot up to over $1 trillion after it acquired xAI last year. Musk claimed his rocket company could launch data centers into space for his AI lab, but the letter’s authors argue that xAI’s poor record on safety issues could complicate how investors view the combined company as it gets ready to submit its IPO prospectus filing.
One of the letter’s signatories and coauthors is a new nonprofit called Guidelight AI Standards, which was cofounded by former OpenAI safety researcher Steven Adler and former OpenAI policy advisor Page Hedley. The group, which is backed by private donors, aims to improve the safety practices of frontier AI companies. Other AI safety nonprofits also signed on, including Legal Advocates for Safe Science and Technology, Encode AI, and The Midas Project.
Hedley tells WIRED in an interview that he believes xAI has the worst safety practices “nearly across the board” compared to other frontier AI developers, including OpenAI, Google DeepMind, and Anthropic. As a result, he argues, SpaceX may face a greater risk of regulation and litigation than other AI labs.
Advertisement
The letter’s authors argue that SpaceX should make several disclosures to investors, including whether xAI intends to continue developing frontier AI models. SpaceX recently struck a deal to sell a significant portion of its GPU capacity to Anthropic, and the letter claims the agreement “leaves it unclear whether xAI is still a frontier-AI competitor inside a larger holding company.” If xAI continues to develop frontier AI models, the authors say that it should be required to publish a public safety and governance plan.
SpaceX and xAI did not immediately respond to WIRED’s request for comment.
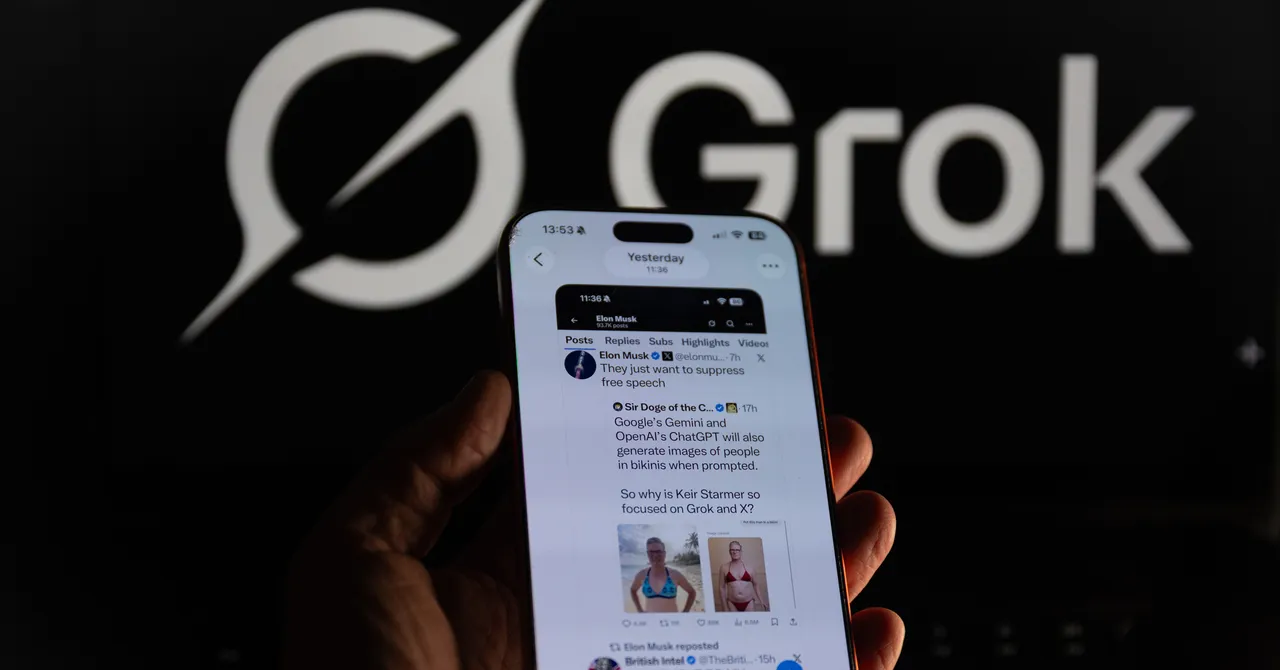
The letter also outlines examples of how xAI has not kept up with industry standard safety practices, such as publishing detailed frameworks for mitigating risks around its AI models being used in cyber attacks. The authors also outline specific safety incidents at xAI that they say warrant additional scrutiny. Among the most notable include when xAI’s flagship AI chatbot, Grok, spontaneously brought up white genocide in its responses. In another case, xAI allowed Grok to generate thousands of sexualized images of women and children, which spread widely across Musk’s social media platform X. The latter case prompted at least 37 US attorneys general to send a letter demanding that Musk’s AI lab take steps to protect women and children on its platform.
Hedley says the number of safety incidents xAI has experienced and the regulatory attention they received is “far out of proportion to its market share.” As lawmakers grow increasingly alarmed by the cyber capabilities of advanced AI models like Anthropic’s Claude Mythos, new security regulations may be on the horizon. The Trump administration is reportedly already weighing an executive order that would give US intelligence agencies more oversight over AI models.
Advertisement
“It takes serious investment to reign in [AI safety] risks, and it seems that xAI has historically under invested here,” says Adler. The letter cites reporting from the Washington Post that said xAI had just “two or three” people working on safety as of January. “A question investors should be wondering is if xAI stays at the frontier, how costly might it be to, in fact, manage these [risks] responsibly? If they don’t, what might be the consequences?”
from the get-some-actual-probable-cause,-you-mooks dept
Judge Beryl Howell has now told ICE at least twice: it’s not allowed to grade its own papers.
Since Trump’s return to office, the federal government has been engaged in a months-long purge of anyone who looks a bit foreign. ICE has increasingly relied on administrative warrants to do everything including enter homes to effect arrests of people who’ve only allegedly engaged in civil violations.
Don’t let the word “warrant” fool you. No judge has signed off on these so-called warrants, and they’re certainly not capable — constitutionally-speaking — of granting ICE officers the legal authority to effect arrests of people who would normally just be given a summons, much less allow them to enter people’s homes.
But that was the way things went for several months before dozens of courts and hundreds of decisions told ICE otherwise. With courts ordering ICE to stop arresting people without judicial warrants, ICE had to walk back its aggression a bit. But only a bit. What’s being addressed by a second order by this same DC federal court is representative of ICE’s day-to-day activities around the nation.
Advertisement
This court had already ordered ICE to cease its warrantless arrests of immigrants it couldn’t actually show might pose a flight risk if not locked up. Even policy clarification issued by acting ICE head Todd Lyons in the wake of dozens of courtroom losses failed to change anything in DC. The most reasonable explanation for this apparently deliberate “failure” to comply with court orders and the Constitution is that no one in ICE actually believes Todd Lyons will ever hold any ICE officer accountable.
Judge Howell’s order [PDF] says ICE and its current director are playing word games in hopes of keeping the arrest rate up, defining “escape risk” so loosely it would be almost impossible for any migrant accosted by federal officers to be considered anything else than immediately arrestable.
Plaintiffs raise no issue with the Lyons Memo’s initial definition of “escape risk” to mean whether “an immigration officer determines [an individual] is unlikely to be located at the scene of the encounter or another clearly identifiable location once an administrative warrant is obtained,” Lyons Memo at 4 (emphasis added)—and therefore the sufficiency of this definition to reflect the meaning in the statutory text of “likely to escape” is assumed for purposes of resolving this motion.
Subsequent descriptions in the Memo, however, drop the italicized phrase thereby effectively limiting the immigration officer’s analysis to whether an individual “is likely to remain at the scene of the encounter.”
This is a deliberate move by ICE and its leadership, dropping a phrase that would strongly suggest migrants who are attending court-ordered check-ins or otherwise working their way towards naturalization/asylum aren’t “escape risks” because they clearly desire to remain involved in the naturalization process. But ICE has racked up a whole lot of arrests at immigration courts because that’s a place lazy, opportunistic officers are guaranteed to come across undocumented migrants.
Advertisement
The end result of this one-two punch is exactly what one would expect it to be. And it definitely doesn’t look constitutional. It looks like a purge enabled by the administration’s constant refusal to play by the rules. (All emphasis mine.)
Indeed, historically, federal civil immigration enforcement did not rely on costly mass arrests and detention centers to address the issue of law-abiding noncitizens without legal status in this country, but rather issued summonses to bring them before immigration authorities. As the Supreme Court has made clear, “it is not a crime for a removable alien to remain present in the United States,” and “[i]f the police stop someone based on nothing more than possible removability, the usual predicate for an arrest is absent.” Arizona v. United States, 567 U.S. 387, 407 (2012).
[…]
The current administration’s apparent reliance on arrests as a routine method of immigration enforcement is a departure from statutory text and historical understanding…
And while a lot of the reasoning sides with the government (due mostly to the court deciding to grant it an assumption of good faith that this administration definitely doesn’t deserve), Judge Howell still says there’s a lot going on here that could — and should — result in a permanent injunction forbidding this flagrant disregard for civil rights.
Advertisement
To be clear, this memorandum opinion does not render any final conclusions about the legality of the challenged policy and practice, which is left for future proceedings after discovery and briefing on dispositive motions. The determination, at this juncture, that certain factors outlined in the Lyons Memo are compliant with the preliminary injunction order is not to say that those factors would survive APA review at final judgment with the benefit of a full record. Nor does this determination suggest that every warrantless civil arrest predicated on consideration of those factors would satisfy the probable cause requirement under 8 U.S.C. § 1357(a)(2). Indeed some of the Form I-213s and the accompanying declarations in the record contain, simultaneously, dubious reasons for finding escape risk and highly concerning facts about the arrest[s].
And there will be more on the record. The judge grants the plaintiffs’ expanded discovery request while simultaneously reiterating that the court’s previous order needs to actually be followed by ICE, rather than just alluded to in policy memos that appear intended to give the agency and its officers as much plausible deniability as possible.
Microsoft has confirmed user reports that the Teams team collaboration app is displaying non-dismissible location prompts on some macOS systems.
According to affected Teams users, these non-dismissible prompts have been appearing on macOS devices over the past week, asking for permission to use their location “for things like GPS and Wi-Fi.”
“I have been getting this message on macOS since May 14, 2026. At first, it would go away after the first click of ‘Don’t Allow,’” one user said. “Today, I have clicked ‘Don’t Allow’ at least twenty times in a row, and the dialog keeps coming right back. I checked for a Microsoft Teams update, but there isn’t one.”
Earlier today, Microsoft acknowledged this known issue in a new incident report (TM1315837) and blamed it on a recent macOS security update that prevents the operating system from retaining users’ location-permission selections.
Advertisement
“We’ve identified that a recent macOS security update doesn’t store users’ location permission selections for Teams as expected, resulting in repeated location prompts,” it said.
“We’re working with Apple to better understand the change and identify a resolution. In parallel, we’re investigating a potential fix within Teams to mitigate the repeated prompts.”
Microsoft added that the issue affects only certain Microsoft Teams users on Mac who have enabled location access in their Teams settings.
Until a fix is available, impacted users are advised to work around the issue by manually enabling location access for Microsoft Teams within macOS settings.
Advertisement
To do that, go to System Settings > Privacy & Security > Location Services, locate “Microsoft Teams” and “Microsoft Teams ModuleHost,” toggle them on and off, then set them back to the desired setting.
While it has yet to share which regions are affected and how many users are impacted by this incident, Microsoft says the first reports surfaced on May 11.
Microsoft has also flagged this incident as an advisory, a label commonly used to describe service issues involving limited scope or impact.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
The most affordable Wildcat Lake notebook currently listed online is the Chuwi UniBook, priced at $449 before tax. It runs Windows 11 and is powered by the Core 3 304 processor, which features five CPU cores clocked at up to 4.3GHz, a single Xe GPU core running at up to… Read Entire Article Source link
It will hold a public farewell campaign ahead of its closure
Snow City, Singapore’s first indoor snow centre, will close on Sept 30 after 26 years, the Science Centre Board (SCB) said in a media release on May 19.
The SCB added that the closure reflects its commitment to “keeping its offerings fresh and relevant amid shifting visitor interests and an evolving attractions landscape,” while aligning with SCB’s science education mission and future plans.
Snow City’s staff will be supported closely during this transition. SCB said the attraction’s eight full-time employees have been offered redeployment opportunities within the organisation.
“For employees who choose to pursue opportunities elsewhere, SCB will provide outplacement assistance and severance support in accordance with applicable employment terms and prevailing Ministry of Manpower guidelines,” it added.
Advertisement
It added that Snow City will honour its contractual obligations to all vendors.
Located in Jurong East, Snow City will hold a public farewell campaign called One Last Snowfall ahead of its closure.
From Jun to Sept, visitors can access limited-time experiences and offers, including a one-hour snow play and bumper car package. During this farewell period, prices drop to S$19 for adults and S$16 for children—down from the usual S$27 and S$23.
More details on the farewell campaign will be shared soon via Snow City’s and Science Centre Singapore’s websites and social media channels.
Advertisement
Read other articles we’ve written on Singaporean businesses here.
When the World Wide Web surged into existence during the 1990s, we were introduced to the problem of how to actually find something in this ever-ballooning construction zone that easily outpaced even the fastest post-WW2 urban sprawl. Although domain names provided a way to find servers using DNS rather than having to mash in IP addresses, you still somehow had to know the relevant URL.
A range of solutions were thought up over time, ranging from printed Yellow Pages type guides, to online curated lists of resources, as well as things like web rings where one website would link to a relevant similar website. This was the time when word-of-mouth was also very relevant, with people proudly announcing their own website on Geocities or other hosting service.
Search engines already existed long before the WWW became the hot new thing during the 1990s, but it was the WWW that would really push them to their limits. As anyone who used search engines for the WWW can attest, they had many issues. Often you’d end up using multiple search engines to find something, and despite fierce competition between web search engines to become the starting page for their browser, actually finding things on the WWW remained a tough problem.
Since a web search engine ‘just’ has to index the WWW and match a search query against the results, why was this such a hard problem that persisted until Google apparently cracked the code?
Advertisement
Unplanned Sprawl
URLs branching off from the main Wikipedia page in 2004. (Credit: Chris 73, Wikimedia)
A nice thing about the WWW is that it was designed to be accessible to all, requiring only an Internet connection and thus opening up the possibility of setting up your own webserver. This unsurprisingly led to a very rapid growth of pages on the WWW, with content appearing, being modified and sometimes vanishing at an ever-increasing pace, making it extremely hard to keep up with.
This is however not how things started when the World Wide Web was created in 1989. Before its opening to the public in 1993 the pace of growth was slow enough that a manually maintained index was maintained. This was kept up until late 1992, with the last version of said index still online on the W3 website.
Over the course of a short few years, the WWW would change the face of the world forever alongside a surge of IBM-compatible PCs, exploding multimedia content, all the dot-com hype and perhaps best of all endless ‘free’ hosting services as long as you didn’t mind an advertising banner plastered above your personal homepage’s content.
Even internet service providers (ISPs) would often offer their own hosting service, along with endless n00b-friendly tools to make something resembling a website for whatever hobby you fancied. In addition to proving that one can absolutely argue about style and the prevalence of colorblindness, this would also serve to balloon the number of websites at an exponential rate.
Whether or not the WWW killing off the Gopher-based internet was a bad thing remains the topic of debate, though it’s beyond question that Gopher integrated search functionality into its protocol, mirroring a file system.
Advertisement
Infinite Library Indexing
Without any provisions in the HTTP protocol of the WWW, the only realistic way for search engines to create an index of the ever-expanding and changing WWW is to perform so-called web crawling. This means going through every known document, following any links found in them, and making sure to revisit any documents in case their contents got changed since the last visit.
The first complication here is that since the search engine’s database is the only real index for the web, initial discovery is purely organic, starting from a certain number of URL seeds in what is called the crawl frontier. This forms an integral part of a web crawler.
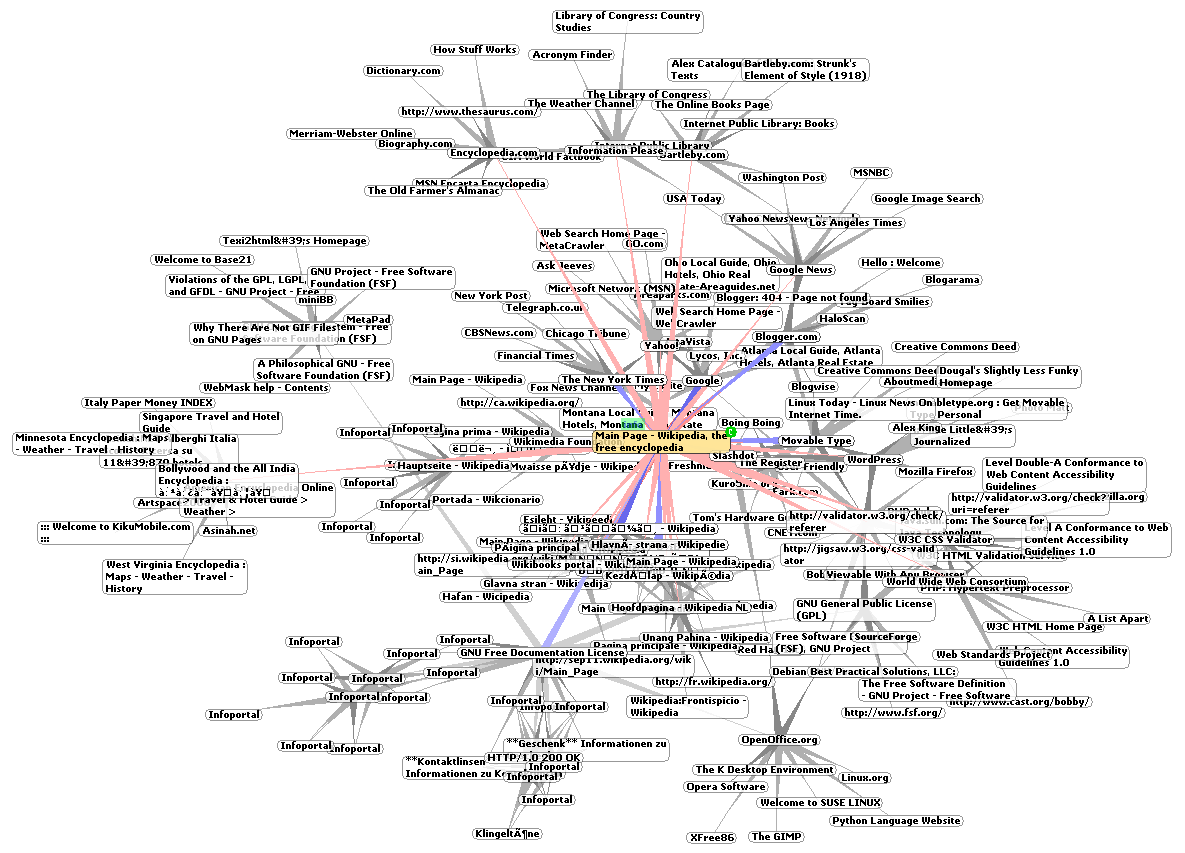
The Structure of Queues that Feed the URL Stream in the WebFountain Crawler (Credit: Edwards et al., 2001)
Development of the algorithms and architecture behind these crawlers formed a major part of the early WWW, with IBM researchers on the WebFountain project in 2001 estimating a grand total of about 500 million pages, with – as they put it – web crawlers caught between the comfortable cushion of Moore’s Law and the hard place of the web’s exponential growth. Today this number is probably closer to forty billion pages.
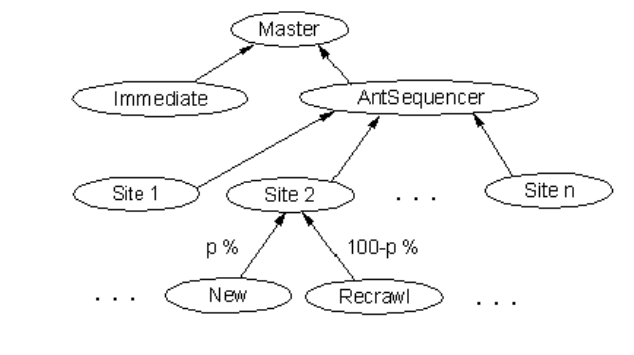
Although the Google Search web crawler was already pretty good back in 2001, WebFountain improved on it by using a distributed system, with ‘ants’ working through their own list of URLs to crawl, as described in the development paper by Jenny Edwards et al.
Beyond the basic recursive following of links in a document there are many confounding factors, such as when to recrawl a URL, which very much depends on how often the content on it is expected to be updated. Here one dives into the territory of statistics, as depending on the type of site we can make an educated guess on how often it is expected to be updated. For example, a government’s historical news pages are unlikely to see frequent updates, whereas the front page of a news site can see updates practically every few minutes.
Advertisement
Inverted Indexing
As complex the topic of web crawling is, the fun part begins when you have pruned all duplicate documents and stripped all the irrelevant fluff that’s not text to be indexed. In order to make the resulting search index at all searchable before the heat death of the Universe you cannot simply do a full text search on every single document whenever someone enters a search query.
Instead an index is constructed whereby certain keywords are mapped to documents. This inverted index is generally implemented as a hash table or similar data structure where it provides a quick access into the full text documents, not unlike the keyword index in the back of a book, or the more elaborate concordance of yesteryear. These latter works also provide a keyword index, but add accompanying text to provide immediate context to further save time.
Creating an inverted index is a fairly labor-intensive process, with a new document often used for a forward index that decomposes the text into its keywords prior to updating (or creating) the inverted index. As with all of such text processing related tasks and data structures in general there are many ways to go about it, with some fun curveballs thrown into the mix such as parsing languages that do not separate words with spaces, like Japanese.
All of which is to say that implementing a search engine is easy, but making it performant, accurate and efficient at the same time is a minor nightmare. This is basically why search engines took so long to stop being so terrible, as the engineers behind them were trying to solve many rather complex problems, presumably with the C-suite and investors breathing down their necks during the dot-com days.
Advertisement
Search Battles
Over on the Wikipedia entry for ‘Search engine‘ we find a pretty good timeline of web search engines, along with their current status. Perhaps unsurprisingly none of the 1993-era ones made it, but 1994’s WebCrawler somehow crawled into the modern age, along with Lycos. Much like 1990’s Archie search engine and similar for the Gopher web, many of these early search engines simply couldn’t compete in the rapidly changing years leading up to the new millennium.
This was also the era in which some figured that the WWW simply needed to become more ‘3D’ with virtual environments using VRML, bringing it closer to sci-fi like that portrayed in Snow Crash or Tron. Perhaps unfortunately the WWW remained the domain of mostly text and images, although most recently the flood of JavaScript frameworks appear to want to turn once simple HTML documents into full-blown desktop-like applications, all probably to the delight of web crawler engineers.
Meanwhile some search engines figured that they could lift along on the hard work of others, with so-called meta search engines collating the results from multiple search engines to save people the trouble of querying them individually. Here 1996’s Dogpile is still going strong.
Some search engines are missing from the list, such as Marginalia, which boasts the use of open source software for its indexing and crawling, while focusing on non-commercial content. There is also the ever excellent Frog Find that provides a bridge between modern search engines and systems that really cannot run the latest web browser.
Advertisement
Today’s Survivors
The search engine landscape remains a brutal one today, with us having to recently say farewell to Jeeves, of Ask Jeeves fame, most recently seen carrying the Ask.com name. Personally I didn’t really Ask Jeeves much back in the day, instead mostly using AltaVista (RIP) and probably Lycos and a few others that I do not recall off the top of my head.
Having Google Search burst on the scene by 2000 was definitely quite the event, which was certainly when the web search game improved. Looking back it probably was less that Google Search was simply better, but more that it pushed hard just being a search engine, whereas the others were still very much stuck in that early WWW mindset of being a portal to the web.
To a certain extent this is understandable, as search engines aren’t a charity and running the associated hardware as well as the required bandwidth costs a lot of money. Despite this it would seem that we still have a rather thriving web search engine landscape, even if ChatGPT, Claude and kin are trying to become the very last ‘site’ you will ever need. This even as their little web crawlers are still doing the same crawling as has been done since the birth of the WWW.
Threat actors earlier today published more than 600 malicious packages to the Node Package Manager (npm) index as part of a new Shai-Hulud supply-chain campaign.
Most of the affected packages are in the @antv ecosystem, which include libraries for charting, graph visualization, building flowcharts, and mapping. However, popular packages outside this namespace have also been compromised.
As in the previous Shai-Hulud campaign impacting TanStack and Mistral packages, the payload collects secrets from developer and CI/CD environments and exfiltrates them over the Session P2P network to complicate detection and takedown efforts.
The threat actor also used GitHub as a fallback exfiltration mechanism and published stolen data in repositories under victims’ accounts, when tokens used for publishing were found.
Advertisement
According to application security company Socket, the hackers published 639 malicious versions across 323 unique packages in about one hour. Some of the impacted libraries include:
echarts-for-react
@antv/g2
@antv/g6
@antv/x6
@antv/l7
@antv/g2plot
@antv/graphin
timeago.js
size-sensor
canvas-nest.js
Endor Labs researchers highlight that some of the packages (e.g., timeago.js, size-sensor, and jest-canvas-mock) had not received a legitimate update for a long time and were less likely to have their OIDC trusted publishing security feature configured.
For instance, although the jest-canvas-mock still has10 million monthly downloads, it has been dormant for about 3 years.
Socket researchers maintain a list of package artifacts affected by all Shai-Hulud attack, which has grown to more than 1,000 entries.
The Shai-Hulud campaigns started last September and continue to affect multiple software ecosystems, such as npm, PyPI, and Composer to a lesser degree.
Advertisement
The malware compromises maintainer accounts or publishing tokens to push legitimate packages with malicious code that steals developer and CI/CD secrets, and can spread to other projects using the stolen credentials.
The latest wave involves the injection of a heavily obfuscated ‘index.js’ payload that attempts to steal GitHub, npm, cloud, Kubernetes, Vault, Docker, database, and SSH credentials.
It primarily targets developer workstations and CI/CD environments, including GitHub Actions, GitLab CI, Jenkins, Azure DevOps, CircleCI, Vercel, Netlify, and other build platforms.
The stolen data is serialized, Gzip-compressed, AES-256-GCM-encrypted, and RSA-OAEP-wrapped to make network inspection harder.
Advertisement
When GitHub credentials are available, the malware uses the GitHub API to automatically create new repositories under the victim’s account and upload the stolen data to them.
Socket has found 1,900 publicly visible GitHub repositories matching the campaign’s markers. However, a newer report from software security platform Aikido notes that the attacker has already published more than 2,700 rogue repositories on GitHub using stolen tokens.
One key new addition in this latest Shai Hulud variant, according to Endor Labs, is its ability to generate valid Sigstore provenance attestations by abusing OIDC tokens from compromised CI environments and submitting them to Fulcio and Reko.
As a result, malicious npm packages may appear legitimately signed and pass standard provenance verification checks despite containing credential-stealing malware.
The self-propagation capability is present in this attack too. The malware validates stolen npm tokens, enumerates packages owned by the victim, downloads the tarballs, injects the malicious payload, and republishes infected packages with bumped version numbers.
Advertisement
Given that Shai Hulud’s code was recently leaked on GitHub by the TeamPCP threat group, and has already been used in attacks, attribution of the new Shai-Hulud campaign is more difficult.
Socket says this variant differs technically from earlier Mini Shai-Hulud payloads but shares the same operational characteristics.
“The AntV payloads differ from earlier Mini Shai-Hulud artifacts such as TanStack’s router_init.js and Intercom-related router_runtime.js payloads,” explains Socket.
“The AntV sample uses a root-level index.js, a different primary C2 endpoint, and a smaller payload body. However, the core operational model is consistent.”
Advertisement
Developers who downloaded any of the infected npm packages should uninstall them immediately, and rotate all secrets within reach of the infected systems.
Automated pentesting tools deliver real value, but they were built to answer one question: can an attacker move through the network? They were not built to test whether your controls block threats, your detection rules fire, or your cloud configs hold.
This guide covers the 6 surfaces you actually need to validate.
Meta CEO Mark Zuckerberg and his wife Priscilla Chan are hiring a seasonal, on-call “Beach Water Person” based in Kauai, Hawaii, where the family owns a sprawlingcompound, according to a new job listing on Greenhouse associated with West 10, the Zuckerberg family office.
This is an interesting choice for a job title, because according to the job description, the primary duties of this “Beach Water Person” include serving as a “Beach Lifeguard,” and “Pool Lifeguard.” In other words, being a lifeguard.
The job listing names a few additional duties related to water activities, such as instructing “stand-up paddleboarding (SUP), canoe paddling, snorkeling, and other ocean-based activities.” These, however, come after the water safety duties in the job description.
This position easily could have been called “Pool/Beach Lifeguard,” or simply “Lifeguard.” For the sake of comprehensiveness, “Pool/Beach Lifeguard and Boat Deckhand” would have also worked. Alternatively, the Zuckerbergs could have chosen “Beach/Pool Attendant,” a job title roughly synonymous with lifeguard that could reasonably be interpreted as encompassing extra duties associated with leisure, such as tending to a boat or teaching people how to stand-up paddleboard.
Advertisement
Arguably, any of these options would have provided more clarity than “Beach Water Person,” which does not appear to correspond with a job title anywhere else in the English-speaking world.
WIRED did not immediately hear back from representatives of the Zuckerberg family. Lacking a human to speak with, we decided to ask Meta’s AI chatbot “what is a ‘beach water person’?”
“‘Beach water person’ would just mean someone who loves being in/near the ocean,” the chatbot said. “The word for that is thalassophile—’a person who loves the seas and oceans.’” Ok!
We’ve talked a lot about how Americans have somehow accepted the fact that our voice networks are now saturated with scammers, fraudsters, and robocallers (no, that’s not something that happens in well run, functionally regulated countries).
I’ve also explained for years how the U.S. government solutions to the problems are usually ineffective because they’re endlessly trying to create rules (or undermine existing ones) to carve out exceptions for big “legitimate corporations,” which routinely engage in the same sleazy behavior as scammers.
Regulatory capture and corruption means that you wind up with a lot of performative solutions that sound good, but don’t fix anything. And some of the progress we had made on robocalls is being undermined by the Trump administration’s brutal assault on the federal regulatory state, something that still, somehow, isn’t getting enough public and press attention.
Now the Trump administration is cooking up a new “fix” that once again isn’t likely to fix the robocall problem (because our consumer protection regulators don’t function and the Trump administration doesn’t actually care about the subject anyway), but is likely to introduce all manner of new privacy and surveillance headaches. If it’s even implemented.
Advertisement
In late April, the Trump FCC announced it was considering the development of new “Know Your Customer” rules requiring that the buyer of any new phone present a government ID, a physical address, a full legal name, and an existing phone number at the point of sale. This has raised eyebrows both among activists and telecom industry lawyers, albeit for understandably different reasons.
“We must bring meaningful robocall relief to consumers. The FCC is attacking the problem of illegal robocalls at every point in the call path in order to help consumers and restore trust in America’s voice networks. These proposals set the stage for significant advancement toward those goals by aiming to get providers to take accountability and step up their game in our shared battle against illegal robocalls.”
Telecom lawyers are nervous because the rules propose a $2,500 penalty, per call, per carrier, in a country that sees around 4.2 billion robocalls per month. So yeah, in a theoretical country where we actually had functioning consumer protections this would be quite a shift.
But accountability requires consumer protection enforcement, and this is Brendan Carr. A guy who generally doesn’t believe in holding major corporations accountable for literally anything. And who believes in defanging the federal regulatory state. It’s once again this interesting intersection between the Trump administration’s claims, and their very unsubtle effort to lobotomize government.
Advertisement
Which is to say I’m not even sure this proposal passes, much less sees any enforcement. And if it does pass, and does get enforced, it likely won’t actually help stop robocalls, because that would require a government willing to be tough on the biggest telecom giants which have historically not done enough to police fraud on their networks (at points because they were profiting from the fraud).
So what is Brendan Carr actually thinking? Like all dutiful autocrats, he’s thinking about his administration’s own power, and he’s thinking about surveillance.
There are, of course, numerous instances where you might want legal but covert ownership of a cell phone (a refugee seeking government punishment, a domestic abuse victim fleeing an abusive relationship, a journalist trying to protect a source identity, an activist planning a demonstration). Reclaim the Net is particularly concerned on the restrictions impacting the prepaid cell phone market:
“The real privacy stakes sit in the proposal’s section on prepaid service. Right now, you can pay cash for a prepaid phone and SIM card without showing identification. Journalists use prepaid phones to protect sources, domestic violence survivors use them to avoid being traced, and whistleblowers, activists, or anyone with a reason to separate phone activity from legal identity relies on this.”
So yeah, if Brendan Carr, a censorial autocratic zealot with a history of disdain for corporate accountability and consumer protection, is suddenly pitching you a quick and easy solution for a complicated consumer-facing issue, you should probably raise a skeptical eyebrow. Especially if you’re a journalist.
‘Beth still wants to protect it’: Dutton Ranch star on why including John Dutton’s Yellowstone legacy in new Taylor Sheridan spinoff was a non-negotiable
Even though Beth (Kelly Reilly) and Rip (Cole Hauser) have had to relocate to Texas after a devasting wildfire, the Yellowstone spirit hasn’t been completely forgotten in new spinoff series,Dutton Ranch.
In a nutshell, Beth and Rip are starting over in the small Texan town of Rio Paloma, even though they bought a brand-new Montana ranch at the end of Yellowstone season 5 part 2.
Unsurprisingly, it doesn’t take too long for Dutton patriarch John (Kevin Costner), who was killed towards the end of the main series, to get a mention. As the Montana fire breaks out, Beth immediately packs a photo of them from their younger years, his hat and his knife.
Advertisement
Latest Videos From
Months later, when she’s settled in Texas, Beth admits to Rip just how much she misses her dad. “We brought the best parts of him with us,” Rip replies.
Even though we’re only two episodes in to Dutton Ranch, I suspect this isn’t going to be the last we hear about the Yellowstone ranch. In fact, the cast is convinced that John Dutton’s legacy remains Beth’s “reason to live.”
‘Beth carries her dad’s legacy with pride and love’
Dutton Ranch | Final Trailer | Paramount+ – YouTube
“I think the legacy has been a lot for Beth, and for all of these years has been her reason to live,” Reilly tells me. “It was how she moved, her only dream and her only reason to exist, protecting the land for her father. She was his strongest soldier.
“I think she carries it in her with pride and love, and I think there is something that she’s wanting to protect around that. She doesn’t want to blow it up to be something that she could use in a gratuitous way, but something in her heart that is hers and her family’s.
Advertisement
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Reilly continues, “But she saw the damage of what preserving a legacy does, the price of it. I don’t think she has much interest in that. I think she’s now moving into a place where people in her life are more important than land.”
IfDutton Ranch episodes 1 and 2 are anything to go by, I’m not completely sure that Reilly’s last sentence is true. But what she says does mean that we can guess how John Dutton and the Yellowstone ranch might be referenced moving forward.
In short, don’t expect the spinoff to suddenly pivot to becoming Yellowstone 2.0. John Dutton will remain background context for Beth and Rip’s new beginnings, and will possibly inform how others, such as ranch rival Beulah (Annette Bening) view them in kind.
Advertisement
As Hauser puts it, “The Dutton ranch obviously harks back to John Dutton, but other than that, the show is about us as a small unit, going to Texas and finding our own way.”
Most email marketers aren’t failing because their product is weak or their copy is bad. They’re failing because they’re sending the same message to everyone and calling it an email marketing campaign. With inboxes receiving an estimated 376 billion emails a day in 2025, generic blasts don’t just underperform; they get ignored.
The good news is that email still delivers a higher return than any other digital marketing channel, averaging $36 to $42 for every dollar spent, according to data from Litmus and HubSpot. The gap between average and high-performing campaigns comes down to a handful of tactical decisions. Here’s what separates them.
1. Segment your list — and keep those segments fresh
Advertisement
Segmented campaigns generate up to 760% more revenue than untargeted ones, according to Campaign Monitor data. That’s not a small edge. It’s the difference between a campaign that pays for itself and one that quietly erodes your sender reputation.
Latest Videos From
Segmentation doesn’t have to mean dozens of micro-lists. Start by grouping subscribers based on where they are in the customer journey: new sign-ups, active buyers, and lapsed customers. From there, layer in behavioral signals like recent clicks or product category interest. Tools like Campaigner and ActiveCampaign support behavior-based segmentation that updates automatically as subscribers interact with your emails or website.
One thing many marketers miss: segments go stale. A customer who bought from you eight months ago and hasn’t opened an email since needs different messaging than someone who clicked three times last week. Build a re-engagement flow for dormant contacts before they start dragging down your deliverability metrics.
Advertisement
2. Personalize beyond the first name
Dropping a subscriber’s first name into a subject line is a good start, but it’s table stakes. Personalized subject lines lift open rates by around 26%, according to Campaign Monitor, though deeper personalization tied to behavior or purchase history can push those gains much further.
Dynamic content blocks let you show different email content to different segments without building separate campaigns. A retailer, for example, can send a single email that surfaces different products for different buyer segments, with the rest of the copy staying identical. Platforms like Campaigner offer dynamic content features that pull from CRM data or purchase history to tailor individual sections of an email automatically.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
The practical benchmark worth aiming for: more than 80% of marketers report performance improvements when they use subject line personalization, per Omnisend research. Combining that with content-level personalization typically compounds the gains.
Advertisement
3. Build automation workflows around what subscribers actually do
Automated emails make up just 2% of total email volume, yet they drive 37% of all email-generated sales, according to Litmus. The math is hard to argue with.
The highest-performing automations are behavioral, triggered by actions like signing up, viewing a product, or abandoning a cart. Abandoned cart emails alone achieve an average open rate of 50.5% and a conversion rate of over 3%, based on Klaviyo benchmark data. That’s well above what a standard promotional newsletter will deliver. Most mid-range and enterprise email platforms include visual workflow builders that let you map out multi-step journeys with branching logic, including Campaigner and HubSpot.
If you’re starting from scratch, a welcome series and a cart recovery flow will cover the majority of high-value automation use cases for most businesses. Add a re-engagement sequence once those are running.
(Image credit: ActiveCampaign)
4. A/B test with a clear hypothesis, not a gut feeling
A/B testing works best when you treat it as a structured experiment rather than a chance to try things and see what sticks. Pick one variable, state what you expect to happen, and let the test run until you have a statistically meaningful result. Testing subject lines against a large enough segment, typically at least 1,000 contacts per variant, is usually where the biggest gains are found first.
Subject line length and personalization are both worth testing systematically. Research from Snov.io shows that subject lines with six to ten words tend to outperform shorter or longer ones on open rates, though your audience may behave differently. Send time and day of week also affect performance: some analyses identify Tuesday and Thursday as the strongest days for B2B emails, but your own historical data will always give a more accurate picture than industry averages.
Advertisement
Build a testing log so you don’t repeat experiments or lose track of what you’ve already learned. Even small lifts compound meaningfully over a year of consistent testing.
5. Sort out your deliverability foundations first
None of the tactics above matter if your emails are landing in spam. Deliverability is often treated as a technical afterthought, but it’s the precondition for everything else working.
Start with authentication. Setting up SPF, DKIM, and DMARC records for your sending domain tells inbox providers that your emails are legitimate. Only 33.4% of senders had DMARC configured correctly as of 2025, per industry data, meaning most businesses are unnecessarily exposed to inbox placement problems. Google and Yahoo both tightened enforcement standards in 2024, and non-compliant senders face increased filtering as a result.
Advertisement
List hygiene matters just as much. Sending to a large number of invalid addresses or disengaged contacts inflates your bounce rate and signals to inbox providers that your domain is low-quality. Most platforms let you suppress contacts who haven’t engaged in 90 to 180 days, which protects your sender reputation without requiring you to permanently delete those contacts.
6. Design every email as though it will only be read on a phone
More than half of all email opens now happen on mobile devices, with some estimates putting that figure closer to 65%. If your email doesn’t render cleanly on a small screen, a significant share of your audience will delete it before reading a single line.
Single-column layouts work best on mobile. Keep your font size at 14px or above for body text and make sure your call-to-action button is large enough to tap without zooming in. More than 50% of mobile users delete emails that don’t display correctly, according to ZeroBounce data, so a poorly formatted email leaves a negative impression that’s hard to walk back.
Advertisement
Most email platforms include mobile preview tools. Use them on every campaign, not just the ones you consider high-priority.
7. Track metrics that actually reflect engagement
Open rates have become a less reliable indicator of genuine engagement since Apple introduced Mail Privacy Protection in 2021. With around 64% of Apple Mail users on MPP, which pre-loads email images regardless of whether the subscriber actually opened the message, open rate figures are now artificially inflated for many senders.
Click-through rate (CTR) and click-to-open rate (CTOR) are more trustworthy signals. CTR measures how many recipients clicked a link relative to total emails sent; CTOR compares clicks to opens, giving you a clearer read on whether your content resonates with people who did engage. Revenue per email is arguably the most useful metric for ecommerce senders, as it connects campaign performance directly to business outcomes.
Advertisement
We’d also recommend tracking unsubscribe rate by segment and campaign type. A sudden spike often signals a content mismatch or frequency problem that’s worth addressing before it compounds into a deliverability issue.


























































You must be logged in to post a comment Login