






UL’s Prof George Barreto discusses his research and how it could help form new treatments for treating and protecting the brain.
Prof George Barreto is a professor in cell biology/immunology at the University of Limerick (UL), and a neuroscientist.
Outside the lab, Barreto is the assistant dean for equality, diversity and inclusion (EDI) in UL’s Faculty of Science and Engineering.
“And I teach,” he tells SiliconRepublic.com. “I run some courses for our undergraduate and master’s students, mostly on how the body works, how medicines work (pharmacology) and how cells behave (cell biology).
“So my job is really a mix of three things – running my research lab, teaching the next generation of scientists and helping build a better academic culture.”
Here, Barreto tells us more about his work.
Can you tell us about your current research?
My lab studies how the hormones in our bodies, the ones we usually link to being male or female, affect the brain, and how that differs between men and women. We pay special attention to a tiny part of every cell that acts like its battery or power plant. These are called mitochondria, and these little batteries do not just give our cells energy. They also help decide whether our cells stay healthy or die.
Our hormones have a big influence on how well these powerhouses work in the brain. A key point is that those hormone levels naturally drop as we get older. I believe that is possibly one of the main reasons why diseases like Alzheimer’s are more common in women than in men.
So, our lab works on a few connected questions. Why does the ageing brain go from being resilient to being vulnerable? How do hormones keep brain cells healthy, and why does that protection fade with age? How does a head injury throw the body’s hormones out of balance and cause harmful inflammation in the brain?
And finally, I think the part I find most hopeful, can we take drugs that already exist (and are FDA-approved) and use them in a new way to protect the brain?
What drew you to this area/subject?
It came from a question I just could not let go of – why are women hit harder by Alzheimer’s and similar diseases, and why does that risk seem to change around the time of menopause? For a long time, medical research either ignored the differences between men and women or treated them as a minor detail. The more I looked, the more I felt this was not a small detail at all, it was right at the heart of the problem.
And then there are the brain’s support cells, the astrocytes. They have fascinated me since my very first steps in research, back in Brazil and later in Madrid, and now in Ireland, and honestly, they still do.
People used to dismiss them as the glue that just holds the brain together, but I came to see them as real decision-makers. They have a big say in whether the brain heals after damage or not. Once I put that together with hormones, which fade so differently in men and women, and with those tiny batteries that hold the power of life and death over a cell, I finally felt I had a way to actually explain these differences, instead of just pointing at them.
Why is this research important?
I think there are two reasons. The first is very simple – as people live longer, more of us will face diseases like dementia, and women carry more of that burden. If we can really understand why the loss of hormones makes the female brain more vulnerable, we can start to design treatments that fit a person’s biology, rather than treating everyone the same way, which is mostly what we still do today.
The second reason is more about the bigger picture. When those little cell batteries start to fail, it is not a problem unique to one disease. We see it in ageing, in brain injury, in inflammation, in dementia. So, if we can find ways for hormones to keep those batteries running, we have found something that could help in many situations at once.
That is exactly why we focus on drugs that already exist and are already known to be safe. Taking an approved drug and giving it a new purpose is a much faster, cheaper way to reach patients than developing one from scratch. And for people who are suffering now, speed matters.
What has been the most surprising insight/discovery in your research?
The biggest surprise has been just how much sex matters, right down to a single cell.
We tend to assume a drug does roughly the same thing in everyone. But when we studied a hormone-based drug called tibolone, we found it acted differently in cells taken from females than in cells taken from males.
The cells responded in their own distinct ways, and the drug even restored their natural cleaning-up ability differently depending on whether they were male or female. The idea that a cell sitting in a dish still ‘knows’ whether it is male or female and reacts to the very same drug differently because of it is striking, and it is still something a lot of people do not fully understand.
What surprised me even more was that this difference goes right down to those tiny batteries (mitochondria) inside the cell that I mentioned earlier.
We discovered that, in the brain’s support cells (astrocytes), mitochondria from females were tougher and coped far better than the ones from males when we exposed them to high levels of saturated fat, the kind of stress the body goes through in obesity.
In other words, the female brain cells’ energy systems were simply more resilient under that pressure. That was a real eye-opener for me, because it suggests these male/female differences are not just small details, but they are built deep into how a cell powers itself and protects itself. And it reinforces why we cannot keep designing treatments as if one size fits all.
What are your thoughts on Ireland’s research landscape? What improvements would you suggest?
I think Ireland is at a really interesting turning point. In 2024, the Government brought its two main research funding bodies together into one, now called Research Ireland, which now funds work across every subject, from science and engineering to the arts and social sciences. I see that as a good move. Before, some subjects were not properly included in the funding system, which put Ireland a step behind other countries. For me, whose work crosses several fields at once, a system that genuinely supports that kind of crosstalk between different areas is very much welcome!
There is real ambition behind it too. Ireland plans to invest in its universities and wants to support thousands of new PhD students and researchers who are early in their careers. And for such a small country, what strikes me most is the talent and the genuinely close links between academia, industry and pharma. That combination is honestly quite unique in the world, and it is part of what made me want to build my lab here.
That said, there are a few things I would push on. First, I would love to see steadier, more predictable money for fundamental research. Applied work matters enormously, but the truly big breakthroughs so often start as curiosity-driven science with no obvious (and long-term impact) commercial angle. My own tibolone work began exactly like that.
Second, we have to look after our younger researchers, the PhD students, the postdocs, the research assistants and the new group leaders. The ambition to train thousands of them is wonderful, but only if we then value them and build real ways to keep them here, instead of losing them abroad.
Third, our infrastructure. Modern biomedical research needs advanced imaging, computing power, data science and shared facilities, and that needs continued investment.
And fourth, and this one is close to my heart given my EDI role, I would like to see equality, diversity and inclusion treated as part of research excellence, not as a box-ticking exercise on the side. For me, they are the same thing. Broader participation, inclusive teams, and fair structures simply produce better science.
My own field is the proof. Ignoring the differences between men and women held the science back for decades. This is not acceptable.
Finally, I think Ireland is perfectly placed to connect academia, healthcare, industry, policy and communities. For areas like dementia, women’s health and menopause, the real progress will come from people working across those boundaries. Ireland is small enough that you can actually get those people into a room quickly, and ambitious enough to lead the world if we support those connections properly.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.












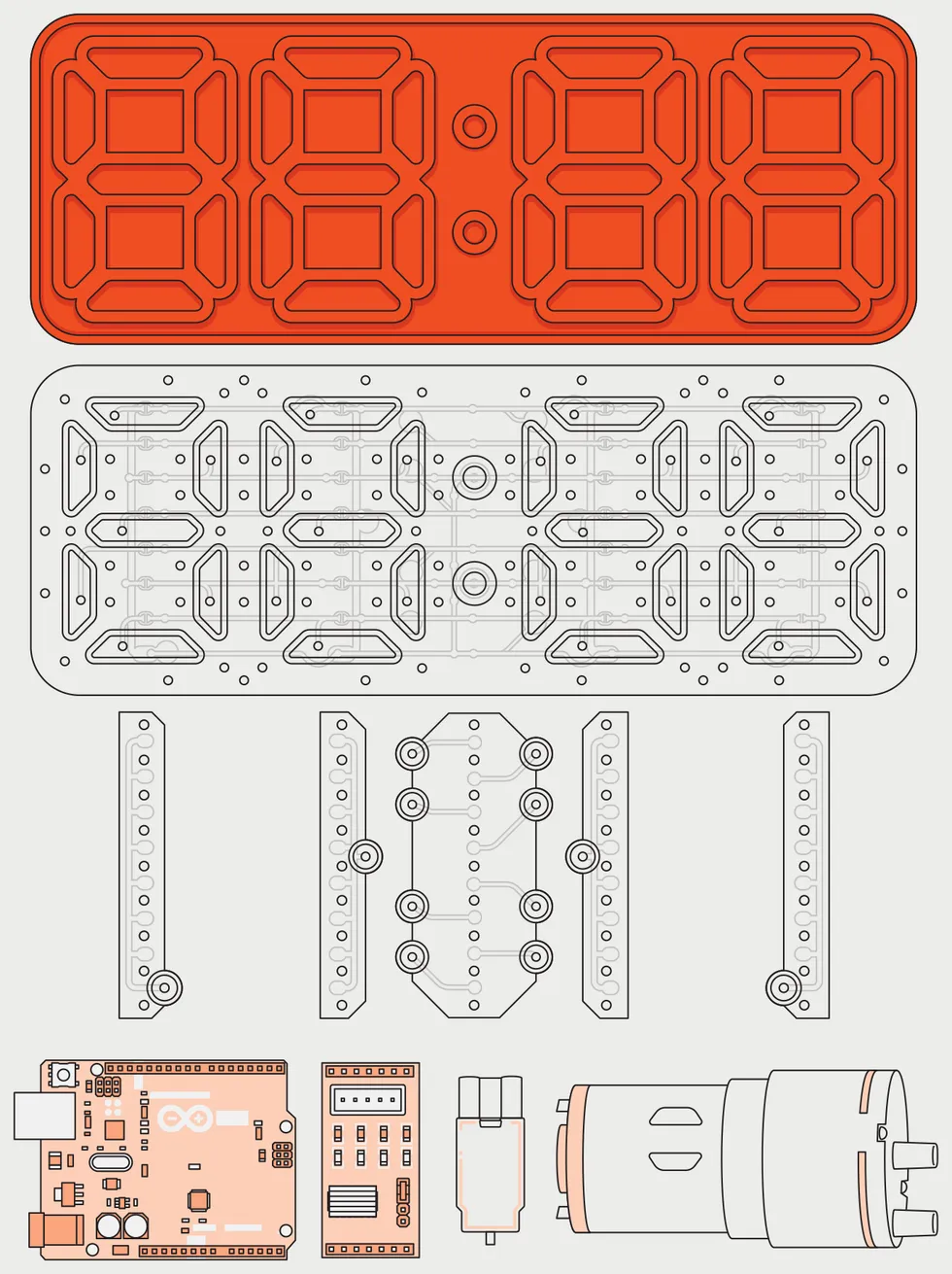
 A cast silicone membrane forms the face of the clock [top], while behind it sits 3D-printed millifluidic blocks [middle rows]. An
A cast silicone membrane forms the face of the clock [top], while behind it sits 3D-printed millifluidic blocks [middle rows]. An  A pneumatic transistor is off when its upper control chamber is at atmospheric pressure [top]. When air is removed from the control chamber, it lifts a membrane, which allows air to flow between lower flow chambers and turns the transistor on [bottom]. James Provost
A pneumatic transistor is off when its upper control chamber is at atmospheric pressure [top]. When air is removed from the control chamber, it lifts a membrane, which allows air to flow between lower flow chambers and turns the transistor on [bottom]. James Provost



































You must be logged in to post a comment Login