TL;DR
Avataar AI launched Varya, an open-weight video model at $0.005/second, 27x cheaper than rivals. Built under India’s AI Mission, it renders Indian culture accurately.




Avataar AI launched Varya, an open-weight video model at $0.005/second, 27x cheaper than rivals. Built under India’s AI Mission, it renders Indian culture accurately.
Bangalore-based Avataar AI has launched Varya, one of India’s first homegrown video AI models. It generates video at roughly $0.005 per second, or 0.48 rupees. Founder Sravanth Aluru, a former Deutsche Bank investment banker and Microsoft and IIT Mumbai alum, says that is 27 times cheaper than comparable open-source video models.
The cost advantage comes from distillation. Avataar started with Alibaba’s Wan 2.2, a publicly available video generation model, and compressed its capabilities into a leaner version that runs in four steps instead of 50. The result is ten times faster generation at a fraction of the cost. Models like Veo, Kling, Luma, and Runway typically charge $0.10 or more per second.
Varya is not trying to compete with US and Chinese frontier models on quality. ByteDance’s Seedance, Kuaishou’s Kling, and Alibaba’s Wan are pushing motion realism and audio generation far beyond what Varya offers. The pitch is scale and accessibility in a market of 1.4 billion people where cost competitiveness matters more than peak performance.
What makes Varya distinct is cultural specificity. Rather than retrofitting a Western-trained model, Avataar used curated data to train Varya to render Indian clothing, food, architecture, festivals, and everyday settings accurately. Global models trained primarily on Western datasets consistently fail at this, producing culturally wrong outputs that limit their usefulness for Indian businesses, education, and public services.
The model is open-weight and will be released on India’s AIKosh portal, the government’s centralised repository for AI models and datasets. Avataar is one of 12 startups selected for the IndiaAI Mission, a roughly $1.2 billion initiative that gives selected companies access to subsidised GPU compute in exchange for releasing their models publicly.
Avataar has raised $55 million from Peak XV Partners and Tiger Global. The company originally focused on creating video tools for e-commerce. Varya is its first foundation model, reflecting a broader trend of Indian startups building sovereign AI rather than renting Western infrastructure. Sarvam and BharatGen launched their own foundational models earlier this year under the same programme.
India’s AI strategy is different from Europe’s or China’s. It is not trying to build the biggest model. It is trying to build models that work for its population at a price its market can absorb. At $0.005 per second, Varya is testing whether a video model optimised for affordability and cultural relevance can gain adoption faster than a technically superior but expensive Western alternative. In a country where AI startups are already building for local needs at scale, the answer may well be yes.
The last few years have seen AI chip demand skyrocket, with every major player in the industry investing in infrastructure, training, and inference hardware to build out their own data centers and clouds for compute.
The assumption was that better, faster chips were the key to unlocking both Artificial General Intelligence (AGI) and AI-infused efficiency gains as the world shifts its focus from AI agents to AI operators.
The bottleneck that many saw coming but was arguably downplayed is now back in focus: Power limitations may cap future data center growth globally.
A recent report by Gartner indicates that AI servers might not have a chip supply problem, but power limitations that could decisively shape future data center expansion, bringing it to a grinding halt by 2030 if not addressed.
Gartner estimates while current datacenter power needs are capped at 132 GW, they could reach 290 GW by 2030, indicating that energy constraints will undoubtedly rule the roost in future AI data center planning.
“Surging demand for compute-intensive AI workloads is driving unprecedented data center power growth, while AI capacity is now constrained by power availability, making data center power security the new battleground for scaling and protecting margins in the global AI race,” said Linglan Wang, Director Analyst at Gartner.
The current estimate makes even the most extreme case painted by the electric infrastructure provider, Schneider Electric, look tame.
This is why Nvidia CEO Jensen Huang has already begun to single out power efficiency as the reason its chips are superior to the competition.
In a recent interview with Bloomberg, Huang said that data centers and enterprise consumers alike would want the highest number of “tokens per watt” to eke out maximum value in a power-constrained future.
Scaling power generation or upgrading grids may arguably be a more complex or time-consuming endeavor than just the AI data center buildout, with Goldman Sachs estimating that as much as $720 billion in grid spending might be needed by the end of the decade to account for the added load that AI data centers will bring to the table.
Whether this plays out exactly as projected by Gartner remains to be seen; however, with every industry player indicating that they intend to increase spending on AI infrastructure, the projection that sees current power needs (565TWh) more than double (1200TWh) by 2030 is a very possible scenario, and the industry’s focus might shift to delivering both power and efficiency versus raw compute over time to account for the change.

Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds.


Cisco has released security updates to address a vulnerability in the Catalyst SD-WAN Manager, tracked as CVE-2026-20262, that was exploited in attacks to escalate to root privileges.
Formerly known as SD-WAN vManage, this network management software allows admins to manage up to 6,000 SD-WAN devices from a single dashboard.
The now-patched zero-day security flaw affects all deployment types, regardless of device configuration, including on-prem deployments, Cisco SD-WAN Cloud-Pro, Cisco SD-WAN Cloud (Cisco Managed), and Cisco SD-WAN for Government (FedRAMP).

Cisco said the issue stems from insufficient validation of user-supplied input during file uploads, which can allow low-privilege remote attackers to execute arbitrary commands as root by sending crafted HTTP requests to an affected API endpoint.
“A vulnerability in the web UI of Cisco Catalyst SD-WAN Manager, formerly SD-WAN vManage, could allow an authenticated, remote attacker to create a file or overwrite any file on the filesystem of an affected system,” Cisco said in a Monday advisory.
“An attacker could exploit this vulnerability by sending a crafted HTTP request to an affected API endpoint of the affected system. A successful exploit could allow the attacker to create or overwrite any file on the underlying operating system. This file could later be used to elevate to root.”
Cisco said its Product Security Incident Response Team (PSIRT) became aware of the exploitation of CVE-2026-20262 earlier this month and “strongly” advised customers to patch their systems.
| Cisco Catalyst SD-WAN Release | First Fixed Release |
|---|---|
| 20.9.9.1 and earlier | 20.9.9.2 |
| 20.12.7.1 and earlier | 20.12.7.2 |
| 20.15.4.4 and earlier | 20.15.4.5 |
| 20.15.5.2 and earlier | 20.15.5.3 |
| 20.18.3 | 20.18.3.1 |
| 26.1.1.1 and earlier | 26.1.1.2 |
While the company did not share any details on these attacks, it shared indicators of compromise (IOCs) warning admins to check their SD-WAN vmanage-server, vmanage-appserver, and serviceproxy-access logs for attempts to upload index.jsp and .war files.
In February, Cisco patched another Catalyst SD-WAN Manager information disclosure security flaw (CVE-2026-20133), flagged as actively exploited in late April, and, two weeks later, warned of two more flaws (CVE-2026-20128 and CVE-2026-20122)that were abused in the wild.
Last month, it also tagged a maximum-severity Catalyst SD-WAN Controller authentication-bypass flaw (CVE-2026-20182) as actively exploited as a zero-day to gain admin privileges on unpatched devices.
More recently, in early June, Cisco warned of one more unpatched Catalyst SD-WAN Manager zero-day (CVE-2026-20245) that was exploited in attacks, allowing attackers to gain root privileges.
Over the last several years, the Cybersecurity and Infrastructure Security Agency (CISA) tagged 91 Cisco vulnerabilities as abused in the wild, five of them in Cisco Catalyst SD-WAN Manager and six others exploited in ransomware attacks.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


With gasoline prices hitting four-year highs and continued uncertainty about when they might come back down, many American motorists have changed up their driving habits to save money. Some drivers have simply decided to drive less, while others have tried to adjust their driving style to use less fuel. In some cases, the high cost of gas may even have encouraged some drivers to switch to more efficient vehicles.
This rise in fuel prices has, of course, an even larger impact on those who drive for a living and the transportation industry as a whole. The American trucking industry has been especially hard hit by skyrocketing diesel prices, which have caused many freight carriers to raise their rates to compensate.
Like drivers of passenger cars, truck drivers can save fuel by changing how they drive, and data shows that American truckers have indeed dropped their overall speeds in response to elevated diesel prices. Trucking, however, is a complex industry, and while driving slower could help save on fuel costs, there’s more to consider than fuel consumption. Slower trucks can cause other issues for freight providers, chief among them drivers spending more hours on the road, which, in some cases, could end up costing more than they save.

Even though diesel fuel is typically cheaper in the United States than in Europe, its prices are still much more volatile than gas and rise faster during turbulent geopolitical situations. Naturally, this has a cascading effect on the transportation industry, which relies on diesel-powered trucks carrying loads over vast distances. Eventually, the added cost of transport is likely to be felt in the prices of goods themselves.
Whether it’s an instinctive response from drivers or a dedicated strategy, during the spring of 2026, trucks slowed their speed on American highways by about 4%. For semi trucks, a slightly slower highway speed between 55 and 60 mph is said to be the sweet spot for fuel savings. As you’d expect, owner-operators who fuel their own trucks are more likely to slow their speeds compared to drivers who work for large retailers, which cover the cost of fuel.
Some highway freight providers have decided that the fuel savings from reduced speeds are worth the slightly longer delivery times, which they feel won’t substantially impact their business. However, some experts have warned that slower travel speeds could come with significant trade-offs and hidden costs.

Driving slower will reduce fuel consumption, sure, but time spent on the road is also a crucial aspect of the trucking industry. For a truck driver who is paid per mile traveled, slower speeds mean they’ll end up working more hours to cover the same distance — which isn’t particularly desirable.
Beyond that, there are strict rules that dictate the amount of time truckers can spend on the job — and those working hours often include other things beyond just logging miles on the open highway. For example, if there’s a delay in picking up a load or other issues at distribution centers or freight yards along the route, slower speeds could further compound that time crunch, ultimately costing providers more in man-hours and delays than they save.
Whether truckers decide to drive more slowly on the highway — potentially resulting in longer deliveries and more hours on the road — or pass increased fuel costs on to clients and eventually consumers, it’s safe to say that they all hope that high diesel prices are temporary. For the trucking industry as a whole, the sooner that fuel prices go down, the sooner things can get back up to speed, both literally and figuratively.


WordPress plugins OptinMonster, TrustPulse, and PushEngage have been compromised in a supply-chain attack impacting Awesome Motive’s content distribution network (CDN).
Of the three products, the OptinMonster lead-generation and conversion optimization platform is the most popular, with at least 1.2 million websites using it.
E-commerce security firm Sansec discovered the attack over the weekend and found that malicious scripts were served to unsuspecting OptinMonster and TrustPulse users on Friday between 22:17 UTC and 22:42 UTC.

PushEngage continued to serve malicious JavaScript code until 19:02 UTC on Saturday.
The malware triggered only when a WordPress administrator visited a page on an infected website, collecting authentication tokens and nonces, and using them to create a rogue administrator account.
The intruders then installed a self-hiding backdoor plugin and established a communication channel with a domain impersonating Tidio to send any newly captured data.
The plugin also provided full remote access capabilities, including a web shell (“WPM File Manager & Shell”) and arbitrary PHP code execution, granting attackers full control of compromised websites.
“The operator rotates the plugin’s disguise while keeping the logic byte-identical across renames,” Sansec says.
“We have observed it shipping as “Content Delivery Helper” (content-delivery-helper, v2.7.1) and, currently, as “Database Optimizer” (database-optimizer, v2.9.4).”
Awesome Motive published a security advisory earlier today about the incident, explaining that hackers gained access to a server in its environment after exploiting a known flaw in the UpdraftPlus WordPress plugin.
This server hosted a marketing website and was not connected to the company’s production infrastructure or data systems; however, it hosted credentials for the company’s CDN account, which the hackers stole.
Using the stolen CDN API key, the attackers modified JavaScript files distributed via Awesome Motive’s CDN, causing websites to silently load malicious code directly from the CDN.
The affected files are:
Awesome Motive reports that the malicious scripts were served for a short period on June 12 for OptinMonster and Trust Pulse, albeit not confirming the impact on PushEngage.
“We have since remediated the marketing site, migrated it to a new server, and rotated all credentials, including the CDN API key,”Awesome Motive stated.
The company also assured that its application servers, source code, and plugin hosting servers were not compromised.
“Our application servers, our source code, and the systems that store your OptinMonster and TrustPulse account information are hosted separately and were not breached,” stated the publisher.
“We have no evidence that account data or personal details held by us were accessed.”
Site owners who might have been affected are recommended to:
While the malicious content has been removed, the attacker continues to have access to compromised websites as long as the rogue administrator accounts and hidden backdoor plugins are still present.
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.

You send a file, but how do you know it arrived intact? In other words, how do you know that it didn’t get cut off, garbled, or changed somehow? Simplistically, you could just add up all the bytes in the file — a checksum — and send that along with the file. You compute the checksum when you know the file is good, and the receiver can compare the checksum to see if they match.
However, a simple addition doesn’t catch certain classes of errors, which is why there are better checksum algorithms that, for example, wrap the carry bit around or otherwise modify files with common errors so they produce different checksums. There are two problems with checksums. First, no matter how much you modify the algorithm, the chances that two files produce the same checksum are pretty high. Especially with common error patterns.
For example, assume a very simple algorithm that simply adds the bytes and discards any carry. If a file contains 0x80, 0x80, those numbers essentially cancel each other out. If you replace them with 0, 0, you’ll get the same checksum. To some degree, using anything other than a second copy of the entire file will have this problem — some corruption goes undetected — but you want to minimize the number of times that happens.
The other problem is that a checksum by itself doesn’t let you correct anything. You know the data is bad, but you don’t know why. If you think about it, the simplest checksum is a parity bit on a byte: odd parity is simply summing all the bits together. If the parity bit doesn’t match, you know the byte is bad, but you don’t know why. Any even number of errors goes undetected, but I am sure one-, three-, five-, or seven-bit errors will get caught.
People invent better error-checking codes by devising schemes that can promise they can detect a certain number of bit flips and, at least in some cases, correct them. One of these is the cyclic redundancy check (CRC). It is easy to think of the CRC as a “strong checksum,” but it actually works differently. What’s more, there isn’t just a single CRC algorithm. You have to select or design a particular algorithm based on your needs. Most people pick a “named” implementation like CCITT or Ethernet and assume it must be the best. It probably isn’t.
A CRC is a checksum in the broad sense: you feed it a message, and it gives you a small value that you append, store, or compare later. But unlike a simple additive checksum, a CRC is based on polynomial division over GF(2), which is a fancy way of saying “divide using XOR instead of carries.” That detail matters. It gives CRCs very strong guarantees against common classes of errors, provided you choose the right polynomial for the job. That’s the key. You must choose the right polynomial.
A CRC treats your message as a long binary polynomial. For example, the byte stream is interpreted as a sequence of coefficients: each bit is either present or absent. The CRC algorithm divides the message polynomial, after shifting it by the CRC width, by a generator polynomial. The remainder is the CRC.
In normal arithmetic, division involves subtraction and carries. In CRC arithmetic, subtraction is XOR. That is why CRC code often looks like this:
if (crc & topbit) crc = (crc << 1) ^ poly; else crc <<= 1;
That loop is implementing polynomial long division, one bit at a time. The generator polynomial is the magic number. For a 16-bit CRC, the polynomial has degree 16. For a 32-bit CRC, degree 32. You will usually see it written as a hex constant, such as 0x1021 for CRC-16/CCITT or 0x04C11DB7 for the classic Ethernet/ZIP/PNG CRC-32. But the polynomial is not just an arbitrary constant. It determines what error patterns the CRC is guaranteed to detect.
A well-chosen CRC can guarantee detection of all single-bit errors, many multi-bit errors, all burst errors up to a certain length, and a very high percentage of longer random errors. The key metric is Hamming distance, often abbreviated HD. If a CRC has HD=4 for messages up to a certain length, it detects all 1-, 2-, and 3-bit errors in messages of that length.
That last qualifier is important. CRC strength is not just “16-bit CRC good, 32-bit CRC better.” It depends on the maximum message length. A polynomial that is excellent for 32-byte embedded packets may be mediocre for kilobyte-size messages. A polynomial standardized decades ago may be familiar but not optimal.
[Philip Koopman’s] work at Carnegie Mellon is the go-to reference here. [Koopman] and [Chakravarty’s] paper on CRC polynomial selection for embedded networks specifically looked for good CRC polynomials for short embedded messages, and [Koopman’s] “Best CRC Polynomials” tables list polynomials by width and Hamming-distance performance. The important takeaway is that many standard polynomials were chosen for historical reasons, not because they are mathematically best for your packet size.
There are plenty of videos that explain CRC, but if you are going to watch a video, you might as well pick one of the many from [Phil Koopman] himself, like the one below.
Take CRC-16/CCITT, polynomial 0x1021. It is found everywhere: telecom, embedded examples, and bootloaders. It is not a terrible polynomial, but it is not automatically the best 16-bit choice. [Koopman’s] tables include other 16-bit polynomials with better Hamming-distance behavior over useful embedded-message lengths.
Likewise, classic CRC-32 using polynomial 0x04C11DB7 is deeply entrenched because of Ethernet, ZIP, gzip, and PNG. But CRC-32C, the Castagnoli polynomial, is often a better general-purpose choice. It has excellent error detection properties over common message lengths and is also supported by hardware instructions on many CPUs. Intel added CRC32 instructions with SSE4.2, and ARM AArch64 also includes CRC acceleration for CRC-32 and CRC-32C.
Of course, standards matter if you have to meet the standard. But if you are designing a new private protocol between your sensor board and your controller, blindly copying the first CRC-16 example from the Internet is not engineering. Pick a polynomial based on your packet length and your risk model.
For very small messages, even an 8-bit CRC may be adequate. For moderate packets, a good 16-bit CRC is often enough. For firmware images or large records, 32 bits is more reasonable. The point is not to use the biggest CRC you can tolerate. The point is to choose a CRC width and polynomial that give the desired detection strength for your longest protected message.
Also, remember what a CRC does not do. It is not cryptographic. It does not stop malicious tampering. The point of a CRC is to detect accidental corruption, not protect against sophisticated hacking attempts.
Real-world CRC definitions also include bit reflection, initial value, final XOR value, and sometimes byte order conventions. Two CRCs can use the same polynomial and still produce different answers because those parameters differ. That is a common embedded debugging trap. Someone says “CRC-16,” and both sides implement different CRC-16s. CRC-16/IBM, CRC-16/CCITT-FALSE, CRC-16/XMODEM, CRC-16/KERMIT, and CRC-16/MODBUS are not interchangeable.
If you specify a CRC in a protocol document, include at least the width, the polynomial (which can be represented in different formats, by the way), the initial value, if you use reflection on the input or output, and any value to XOR the output with. It is also a great idea to include the computed checksum for ASCII “123456789” so anyone can compare their algorithm to yours.
If you are working with Linux systems, be sure to look at the cksum program which can use several CRC algorithms or other methods like sha1 and other digest-style methods.
Computing CRCs a bit at a time is compact, but it costs eight loop iterations per byte. In some cases, that’s ok, but for performance, you want a table if you can afford the memory. For a 16-bit CRC, the table is only 512 bytes and can be generated at compile time, if desired.
Many CPUs have CRC peripherals. Use them, but read the fine print to make sure they can handle your desired CRC. It is often a good idea to check a hardware implementation against a known-good software implementation before you send it out into the wild. You can do many CRC tests using an online tool. Of course, there are several out there.
For a new embedded protocol, define the maximum length of data you need to check. Then decide how many bits of overhead you can afford. Then head to Koopman’s tables to pick a polynomial with good Hamming-distance performance for that length.
The CRC has been around for a long time. But it isn’t just something you grab off the shelf. You need to plan and understand the ramifications of picking different polynomials.
CRCs aren’t the only game in town. Credit card numbers, for example, use check digits. There are other ways you can identify and, in some cases, zap bit errors, too.

Bubbling Costs: Carl Pei is adding his voice to a growing list of industry insiders pointing to the rapid changes driven by the AI investment boom. RAM is now more expensive than ever, and consumer devices will likely have to adapt to these higher component costs.
Nothing co-founder and CEO Carl Pei has said that AI is making components significantly more expensive, warning that a reckoning is coming for consumers buying new devices. In a recent post shared on his X account, Pei said memory chips now account for more than 50% of the total hardware bill of materials in a smartphone.
DRAM – and, likely, solid-state storage as well – has become the most expensive element in a phone’s bill of materials. Pei illustrated how rising costs are affecting his company’s business: for Nothing’s Phone (4a), the cost of memory chips has more than doubled between the design phase and launch, and then doubled again.
– Carl Pei (@getpeid) June 12, 2026
Pei previously highlighted the impact of rising memory prices earlier this year, saying 2026 would be a “truly unprecedented” year for the consumer electronics industry. Smartphone makers have traditionally relied on a simple assumption: that hardware components would gradually get cheaper over time. Demand for chips from AI data center buildouts has disrupted that pattern, reshaping supply chains and driving memory prices sharply higher.
Pei said this shift is now fully underway and accelerating faster than expected. The result, he argued, is that smartphone prices are rising and are likely to continue doing so into next year. New phone models released since February 2026 have launched at prices about $100 higher than previous generations. In India, one of Nothing’s key markets, phones previously priced above ₹30,000 now carry price tags roughly ₹7,000 higher.

The idea that device makers can solve the issue simply by stocking up on chips ahead of the manufacturing phase no longer holds. Memory products are now allocated by chip manufacturers, leaving device companies such as Nothing to take what they are given – regardless of cost.
Pei offered a final piece of advice for users looking to buy a new smartphone or other consumer electronics device: “If you’ve been waiting to upgrade a device, the best time was yesterday. The next best time is now. This year’s sales season won’t have the discounts people are used to.”
Rising memory prices and ongoing shortages are expected to ripple across the industry, with smartphones and PCs among the sectors most affected. Earlier this year, HP CFO Karen Parkhill said that memory’s share of a PC’s bill of materials has risen to more than 30%.

Apple’s latest developer betas for iOS 27 and macOS 27 are quietly adding fuel to long-running rumours about two of its most anticipated future devices.
Nothing is officially confirmed, but the code and system changes in the first betas are starting to look less like general platform tweaks. Instead, they look more like support work for new hardware form factors.
Starting with the iPhone Fold, references spotted in iOS 27 include terms like “foldState”, “angleDegrees” and multiple display identifiers.
These strongly suggest the system is being prepared to handle a device that changes shape depending on how it’s opened. These kinds of parameters would make sense for a folding device. In particular, one that needs to dynamically adjust its interface between folded and unfolded states.
On the macOS side, Apple has updated the iPhone Mirroring app to support wider, more flexible layouts that resemble an expanded iPad-style interface. While that could simply improve compatibility with larger screens, it also lines up neatly with expectations for a foldable iPhone display.
There are also broader design signals in iOS 27. Apple has pushed developers toward “app adaptability”, encouraging apps to scale more fluidly across different screen sizes and aspect ratios. Again, that’s not new in itself. However, it becomes more notable when paired with references to a squarer, more variable display shape.
For the touchscreen MacBook, the clues are more indirect but still interesting. macOS 27 introduces refinements like improved Sidecar touch input behaviour, allowing more direct interaction between devices. Additionally, there are UI changes such as pull-to-refresh gestures. These are familiar touch-first design patterns, even if they’re currently still compatible with trackpad and mouse input.
There’s also a new Siri Search and Ask interface with a more compact, pill-shaped design. Some have noted this could eventually translate into a more touch-friendly system UI, if Apple goes in that direction.
Taken individually, none of these changes are proof of new hardware. Apple frequently updates its operating systems to prepare for multiple generations of devices. Many of these adjustments could simply improve flexibility across existing iPhones, iPads and Macs.
But taken together, they do fit neatly with long-running reports from well-sourced Apple watchers. These reports suggest a folding iPhone could arrive soon. After that, there might be a MacBook Pro with touch support.
(via Bloomberg)
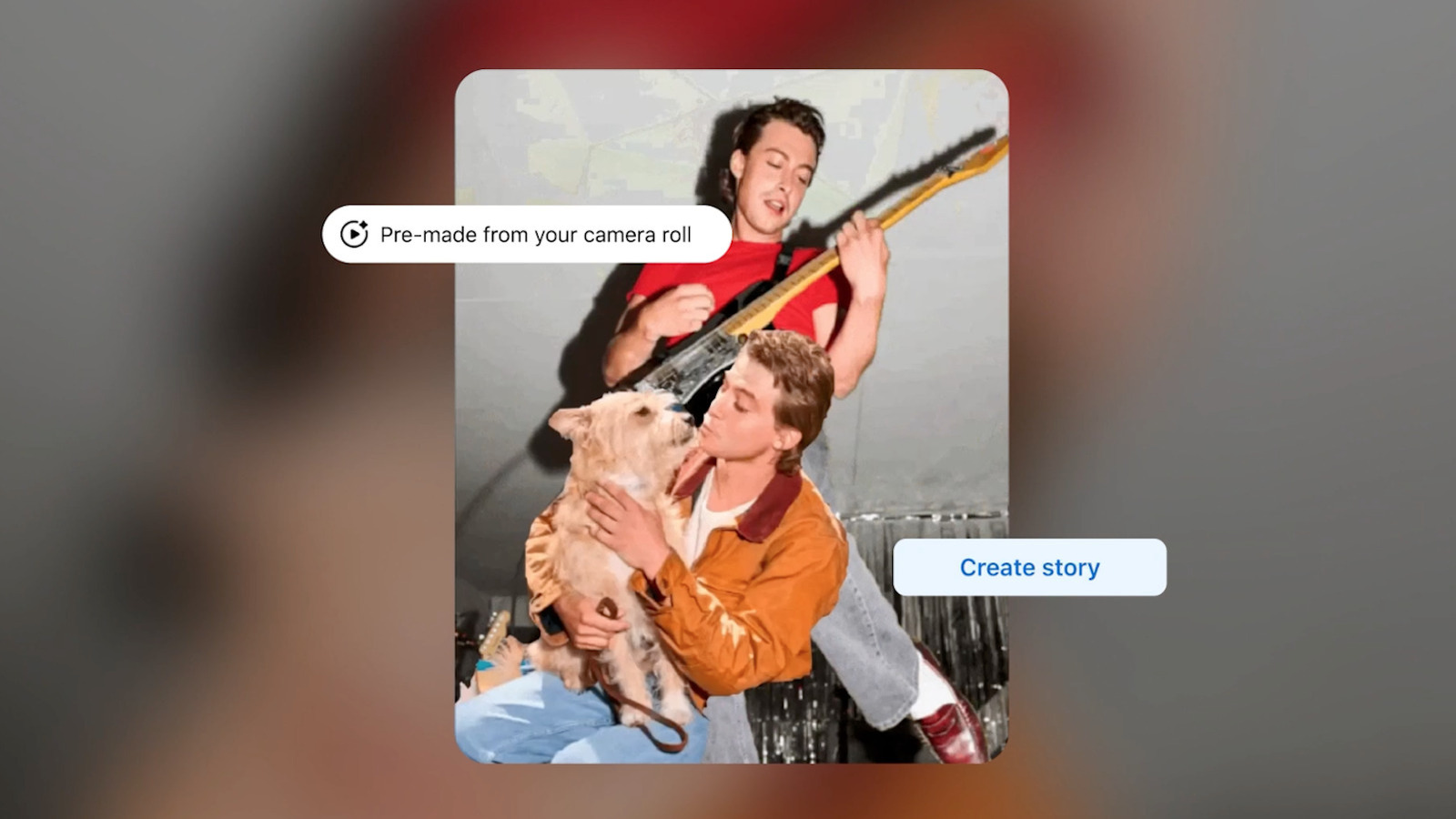
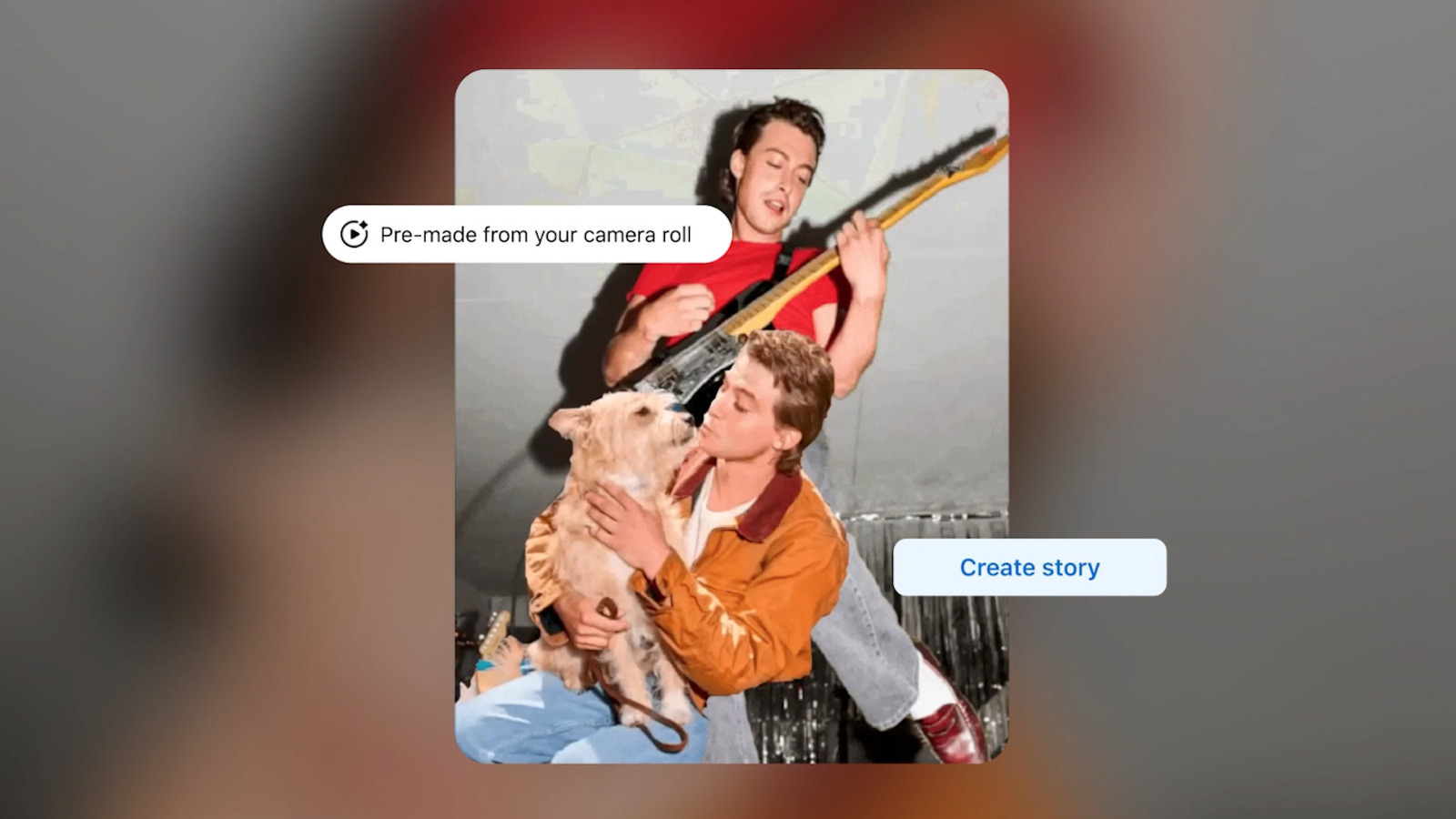
Now you can ask a different chatbot which restaurant to try.
Meta just announced a suite of AI tools for Facebook users. Nothing here looks especially new, but availability on Facebook could be of some use to certain power users.
First up, there’s the simply-named AI Mode. This is a standard chatbot that answers questions, with Meta using the example everyone uses when rolling out one of these tools. The company highlights a person asking the chatbot for nearby summer vacation spots.
Meta does say that AI Mode pulls data from across its apps, like from Groups and Reels, so maybe the information provided will be slightly different than when asking about summer getaways via Gemini, Claude, Grok, ChatGPT and all the rest. The company promises “real perspectives and experience rather than a generic list of search results.” This is all powered by the Meta’s recently-announced Muse Spark technology.
The update also includes photo-editing capabilities, as that tends to be the other big selling point of these tools beyond “find me somewhere to vacation.” There are fresh collage cutout templates for altering photos from the camera roll and new transition effects to create “smooth, stylized video montages that are ready to share.” Meta says it can whip up these videos with “just a tap.”
Finally, there are new photo presets that “make it easy to change your clothing, hair and accessories with AI.” Meta is pitching this for sports fans, so folks “can easily rep your fandom and virtually wear a team jersey to celebrate.” Nothing says true fandom like a fake jersey.
This is launching right now to mobile Facebook users. We don’t know if there’s a version coming to the web, but that would likely be difficult as computers don’t tend to have a camera roll or anything like that.

Adani and Jabil are teaming up to make AI hardware in India.
The Adani Group, India’s infrastructure-and-energy conglomerate, and Jabil, the US contract manufacturer, said on Monday they intend to form a strategic alliance to build a vertically integrated AI and data-centre hardware platform in the country. They put no number on it, and the agreement is not yet signed.
What they want to make is the physical guts of an AI data centre. The plan is multi-gigawatt capacity for high-density, liquid-cooled AI racks, servers, storage and networking, plus the power and cooling gear that surrounds them: distribution and coolant units, transformers, switchgear and thermal systems.
The pitch is a single, end-to-end source, from design to deployment. Jabil brings 60 years of manufacturing and, after recent acquisitions, power and thermal expertise; Adani brings infrastructure, green energy, logistics and its own fast-growing data-centre operations.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The demand case is a sovereignty case. India’s data-centre capacity is forecast to reach 5 to 8 gigawatts by 2030, hyperscalers have lined up more than $50bn in spending, and the country’s data-protection law and data-localisation push are nudging buyers toward hardware made at home.
A new tax holiday for data centres, running to 2047, sweetens the export maths further.
For Adani, the alliance slots into a vast existing bet: a $100bn commitment to develop 5 gigawatts of green-powered, AI-ready data centres by 2035. Making the racks and power gear domestically, rather than importing them, lets it capture more of that build-out and, in theory, sell the surplus abroad.
Gautam Adani framed it in epochal terms, calling AI an “Intelligence Revolution” and arguing India must be “a creator, builder, and exporter of intelligence,” not just a consumer.
The deal is one piece of a much larger surge. India has now attracted more than $200bn in AI-infrastructure commitments, led by a $110bn pledge from Reliance, with tens of billions more from Google, Microsoft and Amazon; only last week Meta signed its first Indian data-centre deal, with Reliance.
The country is trying to convert its position as a huge AI consumer into a place that builds the kit, too, the same sovereignty instinct now driving its push for homegrown models.
The caution is that this is, so far, a press release. There is no disclosed investment, no binding contract, and the companies say they are still negotiating the “definitive operational frameworks.” Their own filing warns the alliance may never be finalised, and the headline-grabbing “$3 trillion market” is their framing of the opportunity, not a commitment.
The ambition is real and well-timed; whether it becomes gigawatts of Indian-made AI racks, or stays a signing-day vision, depends on what gets funded and signed next.
Apple’s beta testing routine for the current-gen operating systems continues, with the second developer builds of iOS 26.6, iPadOS 26.6, watchOS 26.6, tvOS 26.6, visionOS 26.6, and macOS Tahoe 26.6 out now.
The second developer builds arrive after the first, which landed on May 26.
While usually we deal with only one set of betas, sometimes we have to manage two of them. Following the WWDC keynote, Apple has introduced developer betas of its 27-generation operating systems, including iOS 27 and macOS 27.
Apple will continue to update the 26-generation operating systems as usual, complete with beta rounds running close to the fall release of the 27 generation.
At the same time, Apple has also brought out two more release candidates:
Generally speaking, when there are two developer beta tracks, the next-generation version will include the feature changes, while the current-gen track tends to be more muted.
Apple is keen to keep the features for the new versions. The current-gen beta updates are usually performance and security-focused.
The first iOS 26.6 beta build included a new feature for Contacts that notifies if users reach the maximum of 20,000 blocked listings. There was also a security fix for Apple Maps.
AppleInsider and Apple strongly recommend that users avoid installing beta operating systems or beta software onto “mission-critical” or primary-use hardware, due to the potential for issues and data loss. Instead, they should retain backups of their data and try to use secondary hardware that isn’t as essential to maintain.
For users wanting a less risky experience, Apple usually brings out a public beta version shortly after the developer counterpart. It is a more battle-hardened version of the update, with typically fewer issues than the developer builds.
Find any changes in the new builds? Reach out to us on Twitter at @AppleInsider or @Andrew_OSU, or send Andrew an email at [email protected].




No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw


Oppenheimer backs SpaceX as $70 billion retail frenzy builds

Markets Rally as SpaceX IPO Looms Amid Iran Tensions and Inflation Surge


Weekend Open Thread: Tuckernuck – Corporette.com

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


The Ryan Gosling True Crime Thriller On Netflix That Gets Even Stranger, Stream It Now

Bangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News


NanoClaw integrates JFrog registries to secure AI agent downloads


This Week In Security: Microsoft On Microsoft, Register Your Domains, Linux On ARM, And FreeBSD Joins The File Cache Club


Bitget enters Argentina’s regulated crypto market through PSAV registration


Politics Home | Healey Resignation Is “Colossal Failure Of Government”, Says Former Labour Defence Secretary
Dutton Ranch star claims they ‘didn’t see any disruption’ on set following Chad Feehan’s exit from Yellowstone spinoff fueled by Taylor Sheridan clash rumors


El Nino has formed in the Pacific and could set records, forecasters say


‘This is Seattle’s position on AI’: City Council votes unanimously to pause big new data centers

Donnie Wahlberg & More Heat Up Las Vegas at Circa’s Barry’s Downtown Prime


First Time Since 1971: Australia Register Historic Low In ODI Cricket

Opendoor Ends India Operations, Fueling a Bigger Conversation About AI and Outsourcing


Belfast burns, while Met chief points finger at Iran and Russia


Thailand Ranks Second Worldwide for AI Adoption Growth, Microsoft Reports


FBI searches office of Ohio voter registration group







You must be logged in to post a comment Login