
Tech
Claude Cowork is becoming shared workplace infrastructure
Claude Cowork is moving beyond early testing and into a wider role at work. On April 9, Anthropic said it became generally available on all paid plans for macOS and Windows, alongside a set of enterprise features meant to support larger rollouts.
That pairing matters more than the availability update by itself. Anthropic is tying the release to role-based access controls for Enterprise, group spend limits, usage analytics, expanded OpenTelemetry support, and tighter connector permissions, all aimed at making Cowork easier to manage across an organization.
Anthropic also made clear that Cowork is no longer being framed as a tool mainly for technical teams. It said most usage already comes from operations, marketing, finance, and legal, which helps explain why this release leans so heavily on governance and monitoring.
Why the oversight tools matter
The most important change is the management layer. Enterprise admins can now set access by provider, model, and feature, while group spending limits give companies a way to control usage across departments instead of leaving budgets to individual employees.

Anthropic is also widening the reporting view. Its dashboard metrics and Analytics API can track sessions, active users, connector activity, and adoption by team, while broader OpenTelemetry support is designed to feed Claude usage into existing monitoring systems.
Where Cowork fits at work
Anthropic’s larger message is about where Cowork fits inside a business. It said most use already comes from non-engineering groups handling project updates, research, and internal collaboration, not just code-focused work.

That shifts the product’s identity in a meaningful way. Cowork is being positioned less as a specialist assistant and more as a shared layer for everyday work that can draw from connectors, internal information, and team-specific workflows.
What happens next
The next test is whether companies treat Cowork as a standard workplace tool or keep it in a narrower lane. General availability gives Anthropic a stronger opening, but broader adoption will depend on whether admins see enough structure around access, costs, and integrations to support daily use.
For companies evaluating the launch, the real question is practical. If Cowork can help multiple departments while staying measurable and manageable for the people running the system, it has a stronger chance of becoming part of regular business operations rather than stalling at the pilot stage.


Get caught up on the latest technology and startup news from the past week. Here are the most popular stories on GeekWire for the week of April 5, 2026.
Sign up to receive these updates every Sunday in your inbox by subscribing to our GeekWire Weekly email newsletter.
Most popular stories on GeekWire

Tech Moves: Microsoft names corporate VP; Amazon exec departs for Google; Zoom names CPO
Microsoft names a corporate VP for Identity & Network Access, while a CVP of product management departed for Zoom. … Read More

Non-compete ban stirs optimism and uncertainty in Washington state — here’s what it means for tech
A new state law wipes out nearly all non-compete agreements in Washington, sparking debate across the tech ecosystem about innovation, talent mobility and employer rights. … Read More

Tech Moves: Microsoft leader jumps to Anthropic; Tagboard gets new CEO; Expedia names tech VP
— Longtime Microsoft leader Eric Boyd announced today that he has joined Anthropic to lead its infrastructure team. … Read More

Defense giant Anduril is quietly building autonomous warships on Seattle’s historic ship canal
With little fanfare, Anduril Industries spent tens of millions to revamp the old Foss Shipyard on the Lake Washington Ship Canal. … Read More

Plot twist in downtown Seattle: Barnes & Noble bookstore opening soon in Amazon’s backyard
The store will be a short walk from Amazon’s HQ campus. … Read More

Earthset and eclipse, oh my! NASA releases magnificent images from Artemis mission’s moon flyby
High-resolution views of Earth, the moon and a solar eclipse rekindle the spirit of round-the-moon missions from decades ago. … Read More

Golf star Bryson DeChambeau leads acquisition of Seattle-area startup Sportsbox AI
Bryson DeChambeau, the two-time U.S. Open champion, is leading a group of investors in the acquisition of Bellevue-based Sportsbox AI, the startup that uses AI and 3D motion capture to analyze golf swings from smartphone video. … Read More

Microsoft 365 Copilot and the end of the single-model era in enterprise AI
Microsoft’s decision to have GPT and Claude check each other’s work inside Microsoft 365 Copilot’s Researcher agent signals a broader shift: the single-model era in enterprise AI may be over. … Read More

Former Tableau product chief launches Golden Analytics, using AI to challenge the BI old guard
Francois Ajenstat, who spent 13 years at Tableau including more than seven as chief product officer, is launching Golden Analytics with $7M in seed funding to build an AI-native business intelligence platform. … Read More

‘Moon joy!’ Artemis 2’s crew sets a distance record, documents lunar far side and heads back toward Earth
The first humans to travel around the moon in more than 50 years experience hours of scientific wonder — and moments of deep emotion. … Read More

On today’s episode of You Asked: Sony’s new Bravia partnership with TCL raises big questions about pricing, quality, and data privacy. We break down what it means, whether a new QD-OLED is coming this year, and how anti-glare screens really perform in a dark room.
Sony and the new Bravia Inc

@charltonium4083 asks: Here’s one concern that isn’t discussed in the video or any of the comments: Which country will have primary jurisdiction over the new Bravia inc? Will it be China (TCL), or Japan (Sony)? Back in 2020, Homeland Security discovered that TCL may be directly sponsored by the CCP and that the TVs have backdoors to allow data to be breached by the government (thus allowing it to spy on customers). This has also been a more problem with other companies like TikTok and DJI, although a bit more publicized with them to the point where the USA has repeatedly threatened to ban all DJI products. If TCL owns 51% of the new Bravia inc, particularly in the manufacturing and business side, does that mean that it also has all of the customers’ data, and that the CCP could have more ability to spy on customers through the new Bravia TVs going forward? I’d be far less concerned if the customer data was actually handled by Sony (under Japan’s jurisdiction).
OK, quite a loaded question there with some implicit bias, to say the least. But we’re going to get into all of it.
First, Bravia Inc will be located in Tokyo, Japan within Sony’s headquarters. So that’s where the business will be. Manufacturing is likely to take place where TCL has its larger facilities, like China, Mexico, and Vietnam. One of their biggest advantages is large-scale production facilities that keep efficiency high and prices low.
As for your spying concerns, you might be surprised to know that just last month, March 2026, a Texas judge dismissed a lawsuit from the Texas Attorney General accusing TCL of tracking user habits without consent and selling that data to advertisers. So while our internet privacy remains an ongoing concern, TCL and Sony probably shouldn’t be a major concern. Personally, I’m more concerned about Meta, Google, Amazon, and hundreds of phone apps that have more access than a smart TV.
Either way, be sure to practice safe internet use. Read the user agreements when you register. Understand where your data is going, who it can be sold to, and how to limit what is tracking you with VPNs, ad blockers, and other tools.
Manufacturing and pricing strategy

@theGovnr1 asks: To me, it seems the new products will have the Sony technology and design but be manufactured by TCL.
And that’s my take as well. I think the goal is for manufacturing to become less expensive. There are several outstanding Bravia-branded TVs on the market, and most would tell you their picture quality is best in class. But if I’m not mistaken, they fall behind Samsung, LG, TCL, and Hisense in overall sales, likely due to price. So if having TCL handle manufacturing lowers the price while maintaining the image processing technology that makes Sony what it is, that’s a win.
Time will tell, and until the day comes when we have a TCL-manufactured Bravia TV to test, there’s really not much anyone can do to change minds. Based on comments, many of you have clearly decided that this is not for the better and the Bravia brand is doomed. Hopefully, you’re wrong, because then we can all get Sony-level TVs for less.
Sony OLED lineup outlook

@1.doubleyou asks: Will there be a new QD-OLED TV from Sony this year?
I’m leaning toward no, for a couple of reasons. One, they’re pouring a ton of resources and marketing into the release of their True RGB Mini LED TV. And two, they’ve been staggering their big TV updates every other year.
In 2023, we got the A95L QD-OLED. In 2024, we got the Bravia 9, their flagship Mini LED TV. Then in 2025, the Bravia 8 Mark II became the successor to the A95L in the QD-OLED department. And this year, probably sooner than later, we’ll have more details on this True RGB TV that will take over the flagship Mini LED role from the Bravia 9.
Not to mention, with the TCL merger, there may need to be some adjustments in how Sony’s OLEDs are manufactured before we get a new one.
Do anti-glare TVs fail in dark rooms?

@CoolVibe-w5f has a Samsung question in reference to their anti-glare screens, asking: How do the blacks look in a dark room compared to a glossy screen? From what I’ve read, the blacks are not quite 100 percent, especially next to a glossy screen.
A wise person once said: You can’t believe everything you read on the internet. What I’ve seen, take it or leave it, is very little to no difference in a dark room. If the only light being emitted in the room is coming from the TV, you will see pure black. I’m confident in that, and clearly Samsung is as well as they continue to expand that anti-glare panel into more TVs.
This year, it’s in the S95H as well as the S90H. Previous S90 models still had the glossy screen. The anti-glare panel is featured in several Mini LED TVs as well.
I don’t think they’d keep going all in on the technology if they weren’t sure it was delivering a viewing experience on par with the best from Sony and LG. We did a video a while ago putting the Samsung S95D next to LG’s flagship OLED in a dark room to show the difference. And I’ve seen others put their 2025 models, the S95F and S90F, side by side, and it’s very difficult to see a difference, if you can see one at all.

For a brief moment, it looked like Apple’s long-awaited foldable iPhone had hit a classic case of “almost, but not quite.” Reports of manufacturing hurdles and testing issues had people bracing for a delay — some even pushing the deadline to 2027. Naturally, the internet did what it does best: panic and speculate. But it turns out, the situation may not be nearly as dramatic as it first seemed.
Not quite the crisis it was made out to be
Despite the noise, Apple doesn’t appear to be scrambling behind the scenes trying to fix a broken product. From what’s being heard, development is still very much on track, and the foldable iPhone is progressing without any catastrophic roadblocks. In fact, the company is still eyeing its usual September launch window — the same stage where the next wave of flagship iPhones is expected to debut. That’s a strong sign that things are moving along more smoothly than the rumors suggested. This is confirmed by Bloomberg’s Mark Gurman, so we shouldn’t expect any emergency brakes on this.
The stakes are high, so is the price
This isn’t just another iPhone refresh. The foldable model represents one of Apple’s biggest design shifts in years. Expectations are sky-high, and for good reason. A foldable iPhone is expected to sit comfortably in ultra-premium territory, with a price tag that could exceed $2,000. That alone makes it less of a mass-market device and more of a statement piece. But even as a niche product, it has the potential to push Apple’s average selling price higher, which, let’s be honest, is something the company wouldn’t mind at all.

However, availability might be the real catch. Even if Apple sticks to its launch timeline, getting your hands on one might not be immediate. Initial supply is expected to be limited, which isn’t unusual for a first-generation product with a complex design. Foldables are notoriously tricky to manufacture at scale, and Apple is unlikely to rush that process just to flood the market on day one. That said, the plan is still to make the device available alongside, or shortly after, the Pro iPhones. So while it may not be easy to buy, it shouldn’t be stuck in limbo either.
A moment Apple can’t afford to miss
This upcoming iPhone cycle is shaping up to be a big one. A foldable device, paired with the next generation of Pro models, could mark a significant shift in Apple’s smartphone lineup. Which is precisely why the delay rumors hit a nerve. But if current indications hold true, Apple seems ready to deliver on time. Just a very expensive, very anticipated new form factor making its debut right on schedule.

The foldable iPhone may not be facing the crisis it was briefly accused of. While challenges are inevitable with a product this ambitious, Apple appears to have things under control for now. So if you’ve been mentally preparing to wait another year, you might want to rethink that. Your wallet, however, may need a little more time.


The group responsible, ShinyHunters, says it didn’t breach Rockstar or its data-warehouse provider, Snowflake. Instead, it exploited access from Anodot, a SaaS analytics tool Rockstar uses to track cloud costs and performance. The attackers allegedly stole authentication tokens from Anodot’s systems and used them to gain unauthorized access to Rockstar’s…
Read Entire Article
Source link

Apple Glass will be a direct competitor to Meta’s Ray-Ban smart glasses, but it will be only a part of a larger three-pronged AI wearable strategy for the company. Here’s what’s coming.

Optimistic renders of what Apple Glass could look like – Image Credit: AppleInsider
Apple has long been working on its smart glasses, known as Apple Glass. What is anticipated to actually launch will be quite close to what the existing Meta Ray-Bans can already do.
In Sunday’s “Power On” newsletter for Bloomberg, Mark Gurman writes that the Apple Glass will be easily able to handle everyday uses, including photographs and video capture, dealing with phone calls, handling notifications from an iPhone, and music playback.
Rumor Score: 🤔 Possible
Continue Reading on AppleInsider | Discuss on our Forums
Data quality has always been an afterthought. Teams spend months instrumenting a feature, building pipelines, and standing up dashboards, and only when a stakeholder flags a suspicious number does anyone ask whether the underlying data is actually correct. By that point, the cost of fixing it has multiplied several times over.
This is not a niche problem. It plays out across engineering organizations of every size, and the consequences range from wasted compute cycles to leadership losing trust in the data team entirely. Most of these failures are preventable if you treat data quality as a first-class concern from day one rather than a cleanup task for later.
How a typical data project unfolds
Before diagnosing the problem, it helps to walk through how most data engineering projects get started. It usually begins with a cross-functional discussion around a new feature being launched and what metrics stakeholders want to track. The data team works with data scientists and analysts to define the key metrics. Engineering figures out what can actually be instrumented and where the constraints are. A data engineer then translates all of this into a logging specification that describes exactly what events to capture, what fields to include, and why each one matters.
That logging spec becomes the contract everyone references. Downstream consumers rely on it. When it works as intended, the whole system hums along well.
Before data reaches production, there is typically a validation phase in dev and staging environments. Engineers walk through key interaction flows, confirm the right events are firing with the right fields, fix what is broken, and repeat the cycle until everything checks out. It is time consuming but it is supposed to be the safety net.
The problem is what happens after that.
The gap between staging and production reality
Once data goes live and the ETL pipelines are running, most teams operate under an implicit assumption that the data contract agreed upon during instrumentation will hold. It rarely does, not permanently.
Here is a common scenario. Your pipeline expects an event to fire when a user completes a specific action. Months later, a server side change alters the timing so the event now fires at an earlier stage in the flow with a different value in a key field. No one flags it as a data impacting change. The pipeline keeps running and the numbers keep flowing into dashboards.
Weeks or months pass before anyone notices the metrics look flat. A data scientist digs in, traces it back, and confirms the root cause. Now the team is looking at a full remediation effort: updating ETL logic, backfilling affected partitions across aggregate tables and reporting layers, and having an uncomfortable conversation with stakeholders about how long the numbers have been off.
The compounding cost of that single missed change includes engineering time on analysis, effort on codebase updates, compute resources for backfills, and most damagingly, eroded trust in the data team. Once stakeholders have been burned by bad numbers a couple of times, they start questioning everything. That loss of confidence is hard to rebuild.
This pattern is especially common in large systems with many independent microservices, each evolving on its own release cycle. There is no single point of failure, just a slow drift between what the pipeline expects and what the data actually contains.
Why validation cannot stop at staging
The core issue is that data validation is treated as a one-time gate rather than an ongoing process. Staging validation is important but it only verifies the state of the system at a single point in time. Production is a moving target.
What is needed is data quality enforcement at every layer of the pipeline, from the point data is produced, through transport, and all the way into the processed tables your consumers depend on. The modern data tooling ecosystem has matured enough to make this practical.
Enforcing quality at the source
The first line of defense is the data contract at the producer level. When a strict schema is enforced at the point of emission with typed fields and defined structure, a breaking change fails immediately rather than silently propagating downstream. Schema registries, commonly used with streaming platforms like Apache Kafka, serialize data against a schema before it is transported and validate it again on deserialization. Forward and backward compatibility checks ensure that schema evolution does not silently break consuming pipelines.
Avro formatted schemas stored in a schema registry are a widely adopted pattern for exactly this reason. They create an explicit, versioned contract between producers and consumers that is enforced at runtime and not just documented in a spec file that may or may not be read.
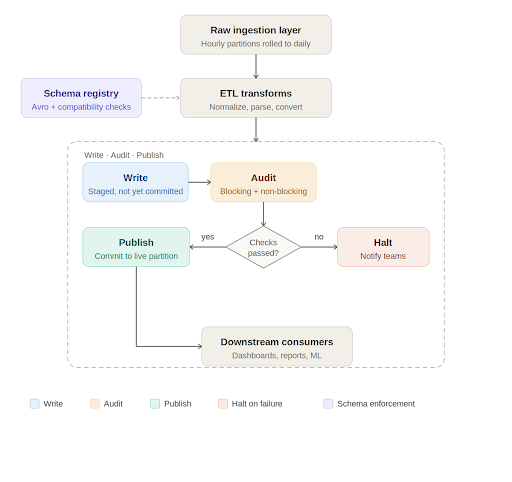
Write, audit, publish: A quality gate in the pipeline
At the processing layer, Apache Iceberg has introduced a useful pattern for data quality enforcement called Write-Audit-Publish, or WAP. Iceberg operates on a file metadata model where every write is tracked as a commit. The WAP workflow takes advantage of this to introduce an audit step before data is declared production ready.
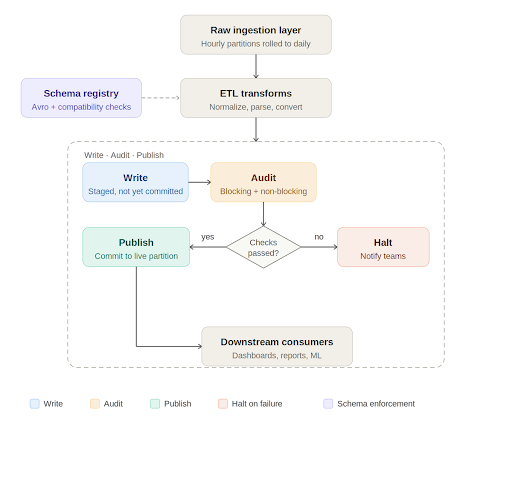
In practice, the daily pipeline works like this. Raw data lands in an ingestion layer, typically rolled up from smaller time window partitions into a full daily partition. The ETL job picks up this data, runs transformations such as normalizations, timezone conversions, and default value handling, and writes to an Iceberg table. If WAP is enabled on that table, the write is staged with its own commit identifier rather than being immediately committed to the live partition.
At this point, automated data quality checks run against the staged data. These checks fall into two categories. Blocking checks are critical validations such as missing required columns, null values in non-nullable fields, and enum values outside expected ranges. If a blocking check fails, the pipeline halts, the relevant teams are notified, and downstream consumers are informed that the data for that partition is not yet available. Non-blocking checks catch issues that are meaningful but not severe enough to stop the pipeline. They generate alerts for the engineering team to investigate and may trigger targeted backfills for a small number of recent partitions.
Only when all checks pass does the pipeline commit the data to the live table and mark the job as successful. Consumers get data that has been explicitly validated, not just processed.
Data quality as engineering practice, not a cleanup project
There is a broader point embedded in all of this. Data quality cannot be something the team circles back to after the pipeline is built. It needs to be designed into the system from the start and treated with the same discipline as any other part of the engineering stack.
With modern code generation tools making it cheaper than ever to stand up a new pipeline, it is tempting to move fast and validate later. But the maintenance burden of an untested pipeline, especially one feeding dashboards used by product, business, and leadership teams, is significant. A pipeline that runs every day and silently produces wrong numbers is worse than one that fails loudly.
The goal is for data engineers to be producers of trustworthy, well documented data artifacts. That means enforcing contracts at the source, validating at every stage of transport and transformation, and treating quality checks as a permanent part of the pipeline rather than a one time gate at launch.
When stakeholders ask whether the numbers are right, the answer should not be that we think so. It should be backed by an auditable, automated process that catches problems before anyone outside the data team ever sees them.

The word clanker — a disparaging term for AI and robots — “has made its way into the Linux kernel,” reports the blog It’s FOSS “thanks to Greg Kroah-Hartman, the Linux stable kernel maintainer and the closest thing the project has to a second-in-command.”
He’s been quietly running what looks like an AI-assisted fuzzing tool on the kernel that lives in a branch called “clanker” on his working kernel tree. It began with the ksmbd and SMB code. Kroah-Hartman filed a three-patch series after running his new tooling against it, describing the motivation quite simply. [“They pass my very limited testing here,” he wrote, “but please don’t trust them at all and verify that I’m not just making this all up before accepting them.”] Kroah-Hartman picked that code because it was easy to set up and test locally with virtual machines.
“Beyond those initial SMB/KSMBD patches, there have been a flow of other Linux kernel patches touching USB, HID, F2FS, LoongArch, WiFi, LEDs, and more,” Phoronix wrote Tuesday, “that were done by Greg Kroah-Hartman in the past 48 hours….
Those patches in the “Clanker” branch all note as part of the Git tag: “Assisted-by: gregkh_clanker_t1000”
The T1000 presumably in reference to the Terminator T-1000.
It’s FOSS emphasizes that “What Kroah-Hartman appears to be doing here is not having AI write kernel code. The fuzzer surfaces potential bugs; a human with decades of kernel experience reviews them, writes the actual fixes, and takes responsibility for what gets submitted.”
Linus has been thinking about this too. Speaking at Open Source Summit Japan last year, Linus Torvalds said the upcoming Linux Kernel Maintainer Summit will address “expanding our tooling and our policies when it comes to using AI for tooling.”
He also mentioned running an internal AI experiment where the tool reviewed a merge he had objected to. The AI not only agreed with his objections but found additional issues to fix. Linus called that a good sign, while asserting that he is “much less interested in AI for writing code” and more interested in AI as a tool for maintenance, patch checking, and code review.

The biotech industry’s engineered cells could become an $8 trillion market by 2035, notes Phys.org. But how do you keep them from being stolen? Their article notes “an uptick in the theft and smuggling of high-value biological materials, including specially engineered cells.”
In Science Advances, a team of U.S. researchers present a new approach to genetically securing precious biological material. They created a genetic combination lock in which the locking or encryption process scrambled the DNA of a cell so that its important instructions were non-functional and couldn’t be easily read or used. The unlocking, or decryption, process involves adding a series of chemicals in a precise order over time — like entering a password — to activate recombinases, which then unscramble the DNA to their original, functional form…
They created a biological keypad with nine distinct chemicals, each acting as a one-digit input. By using the same chemicals in pairs to form two-digit inputs, where two chemicals must be present simultaneously to activate a sensor, they expanded the keypad to 45 possible chemical inputs without introducing any new chemicals. They also added safety penalties — if someone tampers with the system, toxins are released — making it extremely unlikely for an unauthorized person to access the cells.
“The researchers conducted an ethical hacking exercise on the test lock and found that random guessing yielded a 0.2% success rate, remarkably close to the theoretical target of 0.1%.”


The long-rumored Nvidia N1 chip has been circulating in leaks and rumors for what feels like an eternity. But with a fresh leak, we may finally be getting our first proper look at it – and this time, it includes actual, high-quality images. From these, the product appears closer to…
Read Entire Article
Source link


In an official announcement translated by Automaton West, the two firms recently confirmed plans to strengthen their partnership to maintain the supply of Blu-ray discs and players in Japan. Verbatim and I-O Data acknowledged that, despite the rise of digital distribution, individuals and businesses still use optical discs for recording,…
Read Entire Article
Source link

Coach Daniel Japhet Leads Atlantic Business FC to First TCC Cup Glory

Week in Review: Most popular stories on GeekWire for the week of April 5, 2026

Asda launches new 24/7 washing machines at UK supermarkets






-

 Business7 days ago
Business7 days agoThree Gulf funds agree to back Paramount’s $81 billion takeover of Warner, WSJ reports
-

 Politics2 days ago
Politics2 days agoUS brings back mandatory military draft registration
-

 Fashion2 days ago
Fashion2 days agoWeekend Open Thread: Veronica Beard
-

 Tech5 days ago
Tech5 days agoHow Long Can You Drive With Expired Registration? What Florida Law Says
-

 Politics3 hours ago
Politics3 hours agoWorld Cup exit makes Italy enter crisis mode
-

 Fashion6 days ago
Fashion6 days agoMassimo Dutti Offers Inspiration for Your Summer Mood Board
-
 Sports2 days ago
Sports2 days agoMan United discover Nico Schlotterbeck transfer fee as defender reaches Dortmund agreement
-

 Crypto World3 days ago
Crypto World3 days agoCanary Capital Files SEC Registration for PEPE ETF
-

 Fashion5 days ago
Fashion5 days agoLet’s Discuss: DEI in 2026
-

 Business2 days ago
Business2 days agoTesla Model Y Tops China Auto Sales in March 2026 With 39,827 Registrations, Beating Cheaper EVs and Gas Cars
-

 Crypto World4 days ago
Crypto World4 days agoBitcoin recovers as US and Iran Agree a Ceasefire Deal
-

 Politics3 days ago
Politics3 days agoMalcolm In The Middle OG Turned Down ‘Buckets Of Money’ To Appear In Reboot
-

 Business2 days ago
Business2 days agoOpenAI Halts Stargate UK Data Centre Project Over Energy Costs and Copyright Row
-

 Business1 day ago
Business1 day agoIreland Fuel Protests Enter Day 5 as Blockades Spark Shortages and Government Prepares Support Package
-

 Tech6 days ago
Tech6 days agoItalian court says Netflix must refund customers up to $576 over price hikes
-

 Tech6 days ago
Tech6 days agoGamer Restores the Original PlayStation Portal From Two Decades Ago
-

 Tech6 days ago
Tech6 days agoHaier is betting big that your next TV purchase will be one of these
-

 Tech6 days ago
Tech6 days agoThe Xiaomi 17 Ultra has some impressive add-ons that make snapping photos really fun
-

 Tech6 days ago
Tech6 days agoSamsung just gave up on its own Messages app
-

 Tech6 days ago
Tech6 days agoSave $130 on the Samsung Galaxy Watch 8 Classic: rotating bezel, sleep coaching, and running coach for $369
You must be logged in to post a comment Login