

Tech
Lawsuit over delayed Siri features reaches $250M settlement

Apple has settled a class-action lawsuit over its delayed Siri features.
While Apple’s promised Siri overhaul is still nowhere to be found, shareholders who sued over the delay can now rest easy, thanks to a huge settlement.
At WWDC 2024, as part of its Apple Intelligence announcements, Apple previewed major enhancements for Siri. The virtual assistant was supposed to receive an AI-powered cognitive boost, allowing for advanced in-app actions, contextual awareness, and more.
The company went so far as to feature Siri’s new capabilities in its marketing materials, including video advertisements. Things went south in a matter of months, however.
Apple had to delay its planned Siri update, which led to a class-action lawsuit that was settled in December 2025. On Tuesday, as noted by The Financial Times, the settlement details were finally revealed.
The parties settled for $250 million, offering U.S. Settlement Class Members $25 per eligible device. Still, Apple could be forced to pay up to $95 per device if the number of claims filed is low. Part of Apple’s $250 million settlement will also go toward administrative costs and attorneys’ fees.
Eligible devices include iPhone models with Apple Intelligence support, purchased between June 10, 2024, and March 29, 2025, in the United States. This encompasses the entire iPhone 16 range, along with the iPhone 15 Pro and iPhone 15 Pro Max.
Those who wish to submit a claim will need to provide proof of purchase, the serial number of the eligible device, their phone number, and Apple Account information. Apple will begin inviting claim submissions within 45 days, as of May 5, 2026.
Apple also provided a statement on the matter, as shared by 9to5mac.
“Since the launch of Apple Intelligence, we have introduced dozens of features across many languages that are integrated across Apple’s platforms, relevant to what users do every day, and built with privacy protections at every step. These include Visual Intelligence, Live Translation, Writing Tools, Genmoji, Clean Up, and many more.
Apple has reached a settlement to resolve claims related to the availability of two additional features. We resolved this matter to stay focused on doing what we do best, delivering the most innovative products and services to our users.”
As one would expect, Apple’s statement largely praises the currently available Apple Intelligence features, while treating the Siri-related settlement as little more than a footnote.
The now-settled class-action lawsuit accused Apple of promoting “AI capabilities that did not exist at the time, do not exist now, and will not exist for two or more years.”
It was also said that Apple’s advertisements “saturated the internet, television, and other airwaves to cultivate a clear and reasonable consumer expectation that these transformative features would be available upon the iPhone’s release.”
Legal troubles over Siri delays will continue elsewhere
At the time of writing, the long-overdue Siri features are still not available to end users. They are expected to roll out with the iOS 27 update, which is set to debut at WWDC 2026 on June 8.
However, Apple’s legal issues over its delayed Siri features are set to continue via a separate class-action lawsuit. This one is led by South Korea’s National Pension Service, which argues that Apple’s delays have cost billions in stock market losses.
“It is no secret that Apple faced challenges and weathered ups and downs in its stock price in 2025, like many major companies,” Apple said in a February 2026 request to dismiss the suit. “But plaintiff takes a massive and unsupported leap by claiming that securities fraud caused the temporary price drops.”
Ultimately, it remains to be seen if this lawsuit will be dismissed or if Apple will reach a similar settlement as it did in its other Siri-related case.

Looking for the most recent Strands answer? Click here for our daily Strands hints, as well as our daily answers and hints for The New York Times Mini Crossword, Wordle, Connections and Connections: Sports Edition puzzles.
Today’s NYT Strands puzzle highlights a kind of food that seems very summery to me. Some of the answers are difficult to unscramble, so if you need hints and answers, read on.
I go into depth about the rules for Strands in this story.
If you’re looking for today’s Wordle, Connections and Mini Crossword answers, you can visit CNET’s NYT puzzle hints page.
Read more: NYT Connections Turns 1: These Are the 5 Toughest Puzzles So Far
Hint for today’s Strands puzzle
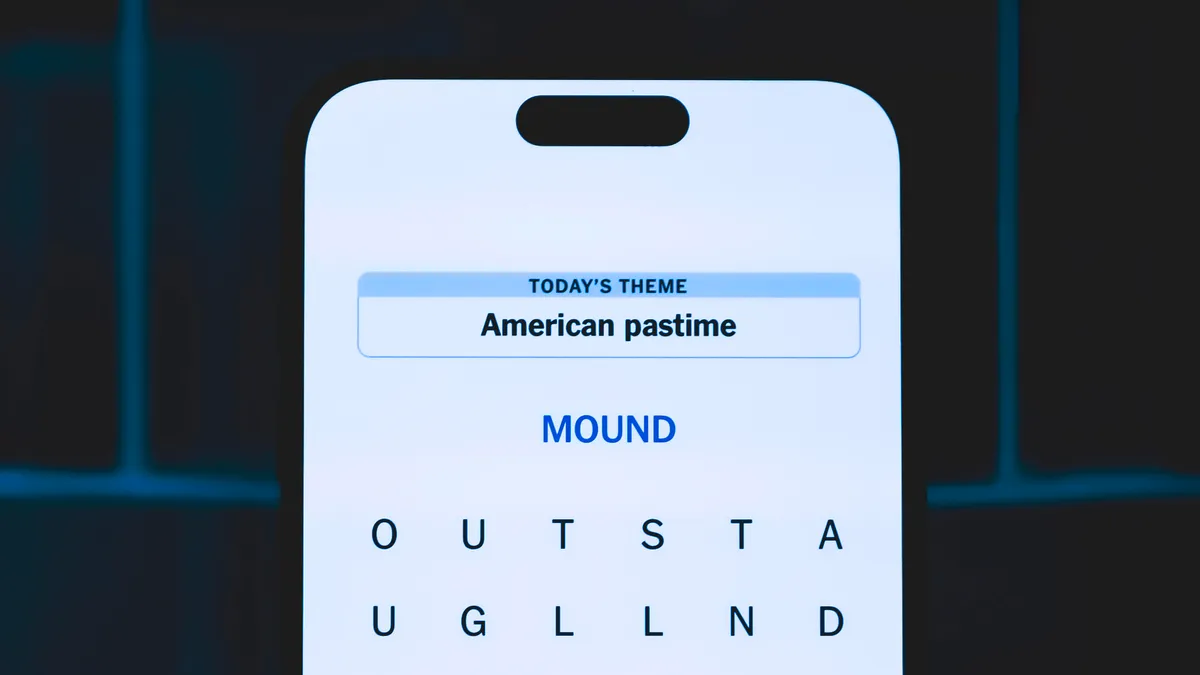
Today’s Strands theme is: Ketchup or mustard.
If that doesn’t help you, here’s a clue: Throw it on the grill.
Clue words to unlock in-game hints
Your goal is to find hidden words that fit the puzzle’s theme. If you’re stuck, find any words you can. Every time you find three words of four letters or more, Strands will reveal one of the theme words. These are the words I used to get those hints but any words of four or more letters that you find will work:
- BAIT, DOLT, TRIG, FOOL, GUFF, DIET, FOOT, BANG, TINE
Answers for today’s Strands puzzle
These are the answers that tie into the theme. The goal of the puzzle is to find them all, including the spangram, a theme word that reaches from one side of the puzzle to the other. When you have all of them (I originally thought there were always eight but learned that the number can vary), every letter on the board will be used. Here are the nonspangram answers:
- BRAT, BANGER, FOOTLONG, WEENIE, FRANKFURTER
The completed NYT Strands puzzle for May 27, 2026.
Today’s Strands spangram is HOTDIGGITYDOG. To find it, start with the H that’s three letters to the right on the bottom row, and wind up and then down.
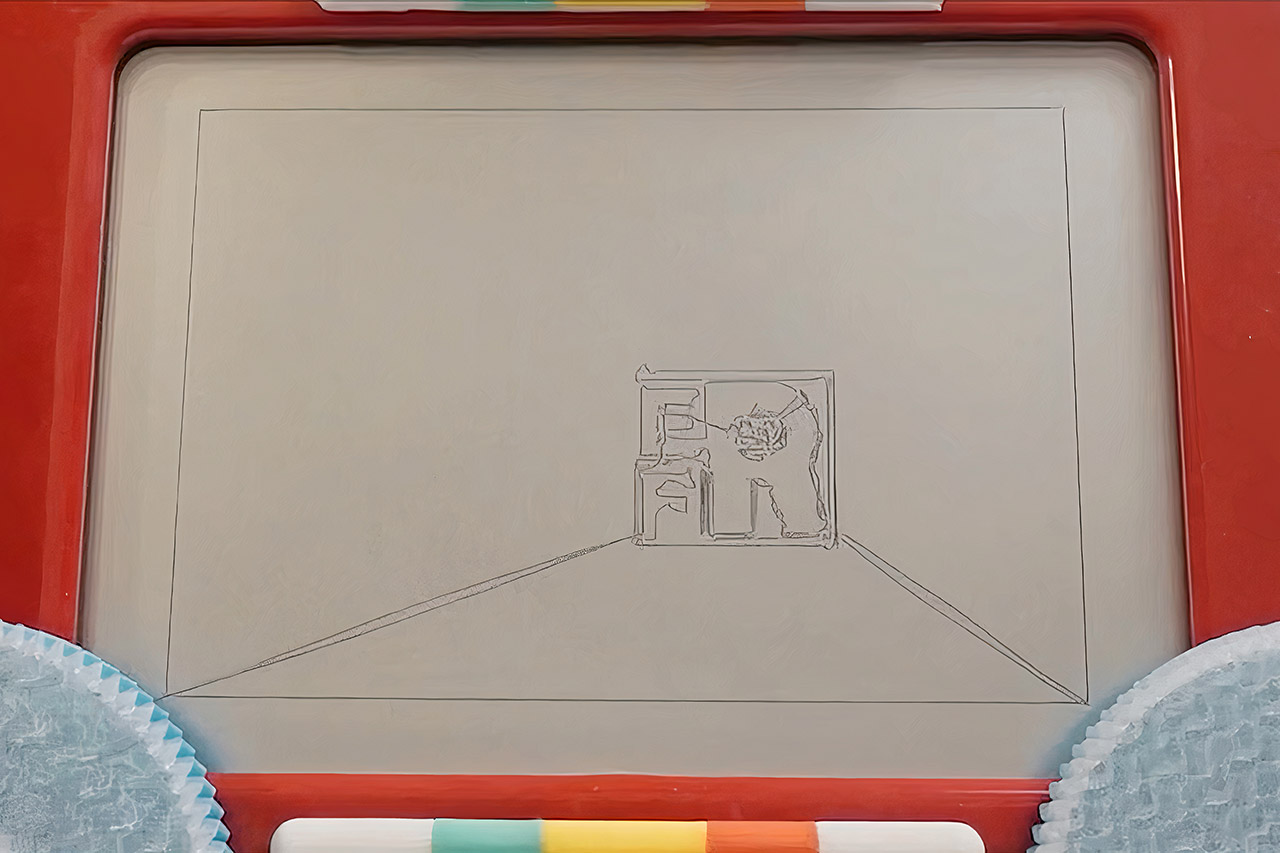
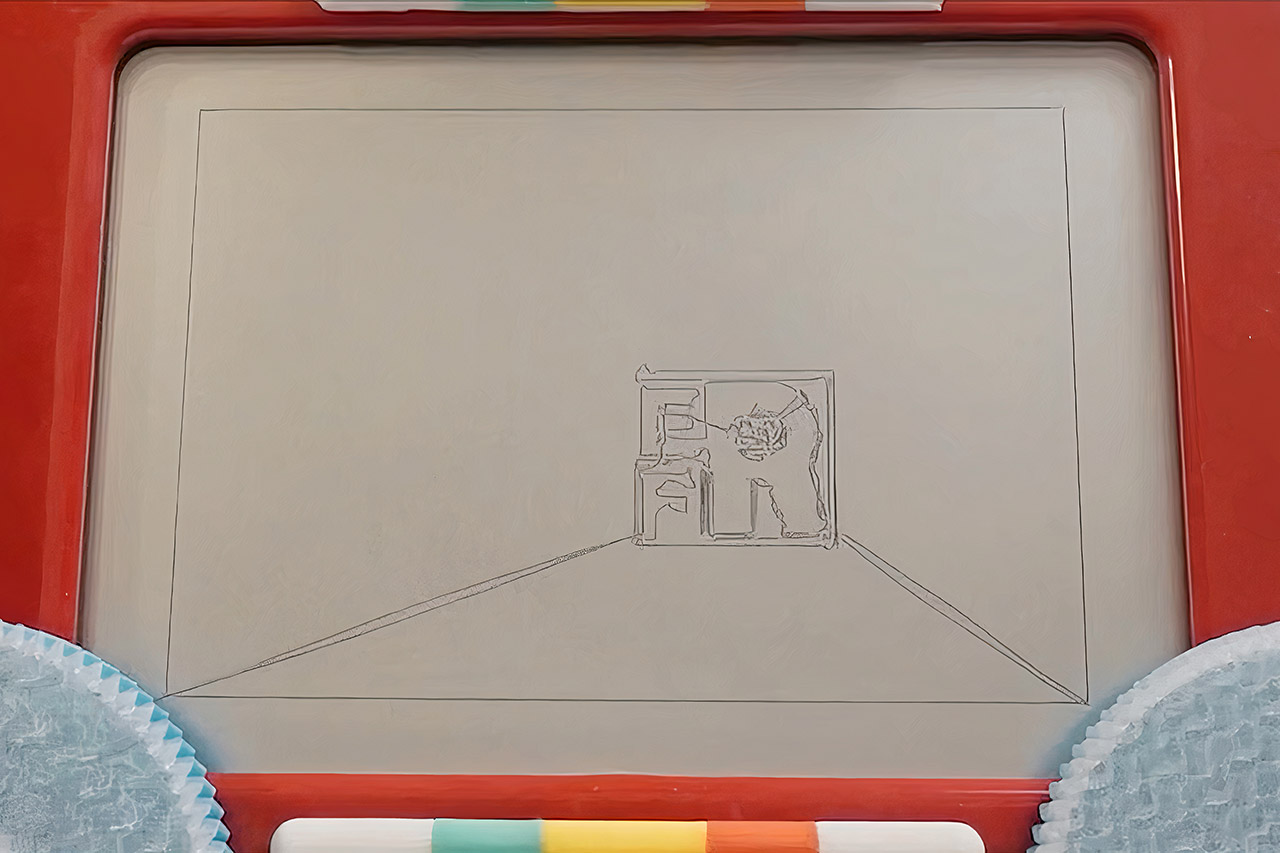
Every Flavor of Robot built Etchbot to stand out at the OpenSauce event. The machine sketches a complete portrait on a regular Etch-a-Sketch in roughly sixty seconds. It also accepts video files and renders them by sketching one frame after another while a camera records each result. The finished time-lapse clips show the classic toy screen updating rapidly enough to convey motion.
The builders started with the basic challenge of any Etch-a-Sketch robot. Two knobs move a stylus that never lifts from the drawing surface. Mechanical play, called backlash, appears whenever a knob changes direction. Friction and slight slippage add more error at higher speeds. Earlier machines handled these problems by moving slowly and carefully.
Sale

TCL NXTPAPER 11 Plus Android Tablet, 11.5″ 120Hz 2.2K Drawing Pad & Digital Notebook, 4096-Level Stylus…
- Tablet, Drawing Pad, and Digital Notebook — All in One: Designed for artists, students, professionals, and entertainment users, the TCL NXTPAPER…
- NXTPAPER 4.0 Display for Enhanced Eye Comfort: With upgraded NXTPAPER 4.0 technology, this tablet offers a more natural, paper-like viewing…
- AI-Powered Productivity & Communication: The TCL NXTPAPER 11 Plus note taking tablet integrates smart tools like voice memo, real-time bilingual…

However, Etchbot adopted a different approach because it has a lot more muscle and is smarter than the older machines. The team designed a custom motherboard dubbed MotorGo AXIS, which includes two brushless motor drivers as well as an ESP32 microprocessor and simply slides on top of a Raspberry Pi. They chose Gartt drone motors because of their power and ease of use. Each motor was outfitted with a tiny magnet attached to the rotor as well as an encoder board to provide critical real-time feedback. With the MotorGo program conducting the calibration, the brushless motors were quickly turned into trustworthy servos.

These servos just slide into the Etch-a-Sketch knobs, and the Raspberry Pi handles the picture and video preparation. It’s all made simple using a web interface that allows anyone to upload a file. The system then reduces the supplied data to the appropriate size for the toy’s screen, removes any background, converts the output to clean line work, and generates motion commands in GCODE format. There are some further stages that clean up any stray points and determine the most efficient route between various lines so that the stylus does not waste hours retracing the same empty region.
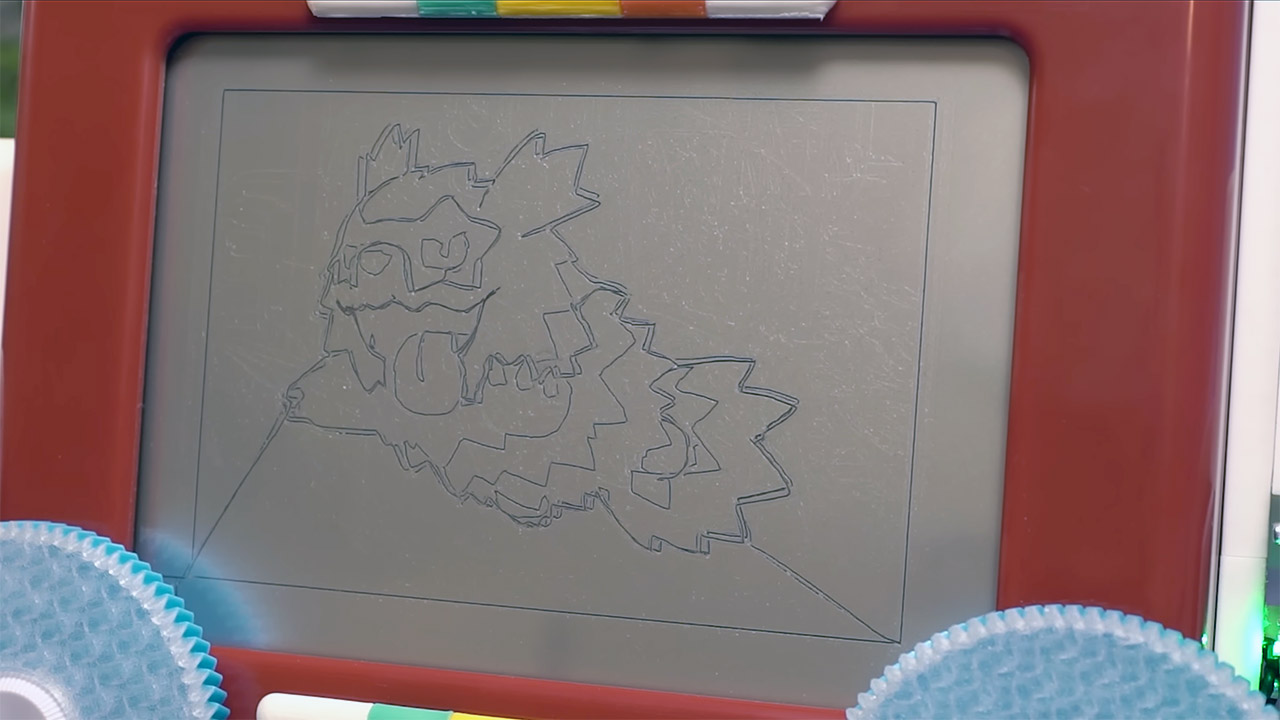
The GCODE is then delivered over WiFi to the MotorGo board, where it is translated into motor movement by a motion controller, but it also includes an extra bit of logic that corrects for backlash whenever the direction changes. To keep things pleasant and stable, acceleration restrictions are set so that the internal mechanism does not receive any abrupt jolts. Between each drawing, the algorithm simply returns the pen to a known safe location, ensuring that any subsequent sketches remain fully visible. The video mode just repeats the same process, one frame at a time, which is essentially the same as sketching a single picture but for dozens or hundreds of images. The camera captures each final frame, which is then stitched together to generate a video clip.

Speed is all about the mix of powerful servos and tailored compensation, rather than any single magic component that makes it all work. Portraits that took minutes to complete now take only one minute. The video side works in the same way, with the hardware keeping up with video frames because each drawing is completed before the next one begins, and to keep the surface looking decent, an eraser function or screen clear step is added between each frame. The entire project is open source, with all of the driver code, server backend, web interface, and MotorGo board design files available on GitHub. In addition to the custom board design files, everyone has access to the printed parts and assembly notes.
[Source]

American Airlines plans to install SpaceX’s Starlink Wi-Fi on more than 500 narrow-body Airbus aircraft starting early next year. It does not, however, have any immediate plans to change providers on its Boeing fleet, which currently uses a mix of Viasat and Panasonic. CNBC reports: American in January rolled out free in-flight Wi-Fi for members of its frequent flyer program, following United Airlines, Delta Air Lines and others. Delta in March said it would use Amazon Leo for in-flight Wi-Fi for hundreds of jets starting in 2028. United, Southwest Airlines and Alaska Airlines, which merged with Hawaiian Airlines in 2024, have selected Starlink. The move is a big win for SpaceX as it prepares for a potentially massive IPO next month. SpaceX said Starlink and its connectivity business generated $11.39 billion in revenue last year, accounting for 61% of the company’s total sales.

Apple’s Passeig de Gracia Store in Barcelona has been updated with a new pickup area for online orders. Image Credit: AppleSfera
After more than three months of renovations, the doors of the Passeig de Gracia Apple Store in Barcelona are open, with updated interior, bigger Genius Bar, and a dedicated online order pickup area.
Opened in 2012, Apple’s Passeig de Gracia store is the company’s second retail location in Barcelona. It’s located in a historic 32,000-square-foot five-story building, dating back to the 1800s. The building itself is near the Mandarin Oriental hotel, and is on one of Barcelona’s most expensive commercial streets.
Though the stone exterior of the store location remains unchanged, Apple has made significant updates to the interior of its Barcelona store. The ground floor is more spacious, as the Forum area has been removed. The store’s iconic staircase is also more visible.
-xl.jpg)
The Passeig de Gracia Apple Store has a new online order pickup area. Image Credit: AppleSfera
As AppleSfera points out, underneath the glass staircase is a new area where customers can pick up the Apple products they’ve ordered online. The area is easy to identify, with an Apple Store logo on the glass and the word “pickup” displayed beneath it.
This pickup area replaces the store’s video section, previously known as the Forum. Instead of large groups sitting in front of a screen, Apple customers in need of information can now participate in workshops held on the first floor.
-xl.jpg)
The Forum area has been moved to the first floor of Apple’s Passeig de Gracia store. Image Credit: AppleSfera
Other changes include custom-made white flooring, which appears seamless, and is built to reduce ambient noise in the store. The metal walls of the store remain unchanged, though.
The Apple Store at Passeig de Gracia in Barcelona is open Monday to Saturday from 9:30 AM to 9:00 PM CEST.


Eric Min wrapped up his senior year at Purdue with a project that keeps every curve and button of the original Game Boy Pocket exactly where people remember them, called StereoBoy. The red or pink shell still slips into a pocket the same way it did in the late 90s. Flip the power switch and the device wakes up ready to play music instead of games.
The space previously occupied by the old monochrome display is now dominated by a color screen. It generates silky-smooth images that precisely track the sound as it plays in real time. A live stereo volume meter is displayed adjacent to that screen via a line of LEDs. The lights dance around, fluctuating in brightness and color in perfect sync with the music; there’s no need to navigate to additional screens or apps for a fast visual check.

Inside the familiar case is a custom board based on the RP2350 microprocessor, which is essentially running the show. It handles all of the graphics, maintains everything clean and responsive, and even runs the main software. They also have a separate audio processor and a high-quality digital-to-analog converter that converts saved data into perfect stereo sound that you may listen to directly through headphones

Music and programs are stored on the same small cartridges that were used for games, and they slide right into the same slot that once held your favorite Game Boy games. Simply insert a cartridge and the player will display the tracks stored on it, or consider how it could transport extra signals from the main CPU to facilitate future add-ons, such as visual output or connecting to other music gear. The options are limitless…

It is powered by a small rechargeable battery that is meant to fit inside the original compartment. As expected, they were able to achieve many hours of playback from a single charge, which should be plenty to get you through a decent walk or train ride without having to put it in again. A small thumbwheel on the side allows you to adjust volume or navigate the menus, while the classic buttons control playback, pause, and navigation. Min created all of this as his final project and won first place, because the idea was always to preserve the look and feel that people already knew and loved, and then just add actual stereo playback, responsive visuals, and a way to exchange music and updates the old school manner.
[Source]

Looking for the most recent Mini Crossword answer? Click here for today’s Mini Crossword hints, as well as our daily answers and hints for The New York Times Wordle, Strands, Connections and Connections: Sports Edition puzzles.
Need some help with today’s Mini Crossword? Read on for all the answers. And if you could use some hints and guidance for daily solving, check out our Mini Crossword tips.
If you’re looking for today’s Wordle, Connections, Connections: Sports Edition and Strands answers, you can visit CNET’s NYT puzzle hints page.
Read more: Tips and Tricks for Solving The New York Times Mini Crossword
Let’s get to those Mini Crossword clues and answers.
The completed NYT Mini Crossword puzzle for May 27, 2026.
Mini across clues and answers
1A clue: Rare U.S. bills
Answer: TWOS
5A clue: 94-foot-long model at the American Museum of Natural History
Answer: WHALE
6A clue: “Cool it, okay!”
Answer: RELAX
7A clue: Bohemian
Answer: ARTY
8A clue: Candy in a dispenser
Answer: PEZ
Mini down clues and answers
1D clue: When repeated, “It’ll be all right”
Answer: THERE
2D clue: Classic ballroom dance
Answer: WALTZ
3D clue: Maker of the Regenerist Micro-Sculpting Cream
Answer: OLAY
4D clue: Reason for an R rating
Answer: SEX
5D clue: Tortilla sandwich
Answer: WRAP


Jeff Bezos’ Blue Origin space venture has won NASA’s nod to deliver crew-carrying rovers to the lunar surface as part of the space agency’s decade-long plan to create a base near the moon’s south pole.
“America is returning to the moon,” NASA Administrator Jared Isaacman said today during a news briefing at the space agency’s headquarters in Washington, D.C. “We are working alongside our many international and commercial partners to leverage the incredible capabilities from commercial industry to build a moon base for all we hope to accomplish in this endeavor.”
NASA awarded Blue Origin an initial $188 million contract to get its robotic Blue Moon Mark 1 lander ready to deliver lunar terrain vehicles, or LTVs, with an option period worth an additional $280.4 million for two task orders. The option period will be based on Blue Origin’s performance during the initial contract phase, NASA said.
Carlos Garcia-Galan, program manager for NASA’s Moon Base program, said the LTVs will be “a mix between the Apollo lunar roving vehicle and the Mars-style rover.” Each rover will weigh a little less than one metric ton, he said, and will be folded up to fit on Blue Origin’s lander during transit to the moon.
The first LTV is due to be brought to the moon in advance of the Artemis 4 mission’s crewed landing, which is currently scheduled for 2028, Garcia-Galan said.
One of the LTVs will be built by California-based Astrolab, with Seattle-based Interlune serving as a subcontractor. In a LinkedIn post, Interlune said it would work with Astrolab on “many aspects of the rover development, involving the science of survival in the lunar environment.” The Interlune Research Lab in Texas will develop varieties of simulated moon dirt specifically for testing Astrolab’s moon rover, which has been designated CLV-1.
The other LTV will be Colorado-based Lunar Outpost’s Pegasus rover, which is being developed in partnership with General Motors, Goodyear and Leidos.
Both LTVs are designed to travel at speeds of up to 10 kilometers per hour (6 mph), carrying up to two astronauts on 10-kilometer (6-mile) trips. The rovers could also take on robotic excursions with a maximum range of 200 kilometers (125 miles). Astrolab is receiving a $219 million contract, while Lunar Outpost’s contract is worth $220 million, NASA said.
In a statement posted to X, Kent, Wash.-based Blue Origin said it was proud to support NASA’s plans for a permanent presence in the moon’s south polar region. The company’s CEO, Dave Limp, also gave a shout-out to Isaacman on his social-media account.
“Since the beginning, Blue Origin has been committed to Lunar Permanence,” Limp wrote. “Thank you, @NASAadmin, for sharing that vision. We’re ready to make it a reality.”
NASA will also develop a fleet of rocket-powered MoonFall drones for reconnaissance and communications. The drones will be built by NASA’s Jet Propulsion Laboratory, and Garcia-Galan said they’d be dropped off at the moon by Texas-based Firefly Aerospace’s Elytra Dark spacecraft. Firefly said its contract for a four-drone delivery is worth $75 million.


NASA’s Moon Base program could get its official kickoff as early as this fall with the launch of Endurance, Blue Origin’s first Blue Moon Mark 1 lander. Endurance, which is currently going through preflight testing, is scheduled to deliver several payloads to the moon’s south polar region — including a retroreflector system for gauging distances and a camera system for studying how thrusters interact with the moon’s surface. This first Blue Moon mission has been on the schedule for more than a year, but Garcia-Galan said it is now known as Moon Base 1.
The Moon Base 2 mission calls for a SpaceX Falcon Heavy rocket to deliver Pittsburgh-based Astrobotic’s Griffin lander to the moon later this year. Griffin will be carrying more than 1,100 pounds of cargo. One of the payloads is an Astrolab rover that’s outfitted with an Interlune imaging system capable of surveying the lunar surface for traces of valuable helium-3.
For the Moon Base 3 mission, Intuitive Machines’ Nova-C Trinity lander will fly the first payload selected through a NASA initiative known as Payloads and Research Investigations on the Surface of the Moon, or PRISM. Lunar Vertex will study lunar swirls — bright spots on the moon’s surface that are thought to be caused by magnetic anomalies. The lander will also carry payloads for the European Space Agency and the Korea Astronomy and Space Science Institute.
“These represent the first of more than a dozen missions we expect to announce through the balance of this year, as we return, build the base, and never give up the moon again,” Isaacman said.
Moon Base 1 and the LTV deliveries aren’t the only lunar missions in which Blue Origin is playing a key role. For example, the company’s second Mark 1 lander has been tasked with delivering NASA’s robotic VIPER rover to the lunar surface in late 2027.
Blue Origin is also working on a Blue Moon Mark 2 lunar lander that could carry future Artemis crews to the lunar surface. NASA is aiming to test the Mark 2 and/or SpaceX’s Starship-based lunar lander next year in low Earth orbit during the Artemis 3 mission.
“We’re already moving forward pretty strongly with both Blue Origin and SpaceX on their lander concepts,” said Lori Glaze, associate administrator for NASA’s Human Spaceflight Mission Directorate. “There’s a lot of trade studies ongoing right now, just to make sure we’ve got the mission designs right and the right objectives for those.”
Isaacman said NASA’s strategy called for “leveraging the NASA playbook from the 1960s, figuring out what works and what doesn’t in this epic science of survival.”
The announcements that were made today focused on the first phase of NASA’s Moon Base plan, which aims to establish reliable access to the lunar surface and characterize resources at the south polar region, where significant reserves of water ice are thought to exist.
The second phase of the project, scheduled for the 2029-2032 time frame, calls for setting up infrastructure for lunar operations, including energy facilities that rely on solar or nuclear power. During the third phase, NASA and its partners would establish a permanent base.
“We envision the moon base to be hundreds of square miles, with different assets all building up to the objective of permanent lunar presence,” Garcia-Galan said.
Isaacman said there are “a lot of great things that will come from having an outpost on the moon,” with the ability to prepare for farther-out missions leading his list.
“There will be scientific discoveries,” he said. “Let’s land rovers with radio telescopes to go to the far side moon. Let’s ignite an orbital economy. These are all things that would be nice to have and achieve along the way, but really it is to have an environment where we can work with the water ice and master the skills for where we go next, which is Mars. … We want to be in an environment where we can learn the skills, so that astronauts can go and plant the Stars and Stripes on Mars someday.”
from the rake-after-rake-after-rake dept
I’m starting to wonder if RFK Jr. can do anything right at all. After the courts put an injunction on Kennedy’s overhaul of the CDC’s ACIP panel on vaccines, as well as pretty much all of their recommendations since it was rebuilt on a foundation of anti-vaxxers, the government sprung into action to try to let Kennedy keep fucking with vaccines in America. The reasoning by the court for the injunction was a process oriented one: Kennedy’s overhaul of ACIP violated the American Procedures Act. By simply hand-picking unqualified sycophants to ACIP, he didn’t follow procedural law. The Trump administration eventually appealed the ruling, which is still pending hearings. On his end, Kennedy decided to amend the ACIP charter to try to route around some of the procedural violations of the APA that got him in trouble the first time.
But it turns out he fucked that up, too. His amended ACIP charter has now been withdrawn for once again not following proper procedure.
A revised charter document for the Centers for Disease Control and Prevention’s influential vaccine advisory committee has been withdrawn by the Health Department over an administrative error, according to a notice published in the Federal Register Tuesday.
While the Health Department is working to appeal the injunction, Kennedy attempted to circumvent the judge’s ruling on the ACIP members by altering the committee’s charter to, among other things, allow for people without expertise in immunizations and public health to be members.
But, for now, that effort, too, has been thwarted. According to the notice on Tuesday, the new charter has been withdrawn for not following a federal requirement on public notification.
The law on the matter is remarkably clear. In order to reestablish a discretionary advisory committee, for which ACIP qualifies, the Secretary of the agency must provide a written statement that the committee is being formed in the public interest, establish what that public interest actually is, and then publish a public notice to the Federal Register so that the people can understand the action that is being taken.
Kennedy didn’t do any of that. He rewrote the governing charter for his remade version of ACIP and just tried to make it a thing without following any of those rules. He just plain fucked it up.
Which isn’t to suggest that Kennedy definitely won’t try to do this all again with an actual attempt to follow procedural law. I am having trouble imagining a world in which he doesn’t do that, actually. But given his apparent desire to step on every last rake he can find, it’s a wonder to me that the Trump administration doesn’t simply want to put someone more capable in charge of HHS.
Filed Under: acip, anti-vaxxers, cdc, rfk jr., vaccines

Spain has temporarily blocked Polymarket and Kalshi while it investigates whether the prediction-market platforms are violating gambling laws by operating without a license. Engadget reports: The country’s ministry in charge of consumer affairs said it blocked the websites as a precautionary measure pending an official investigation. This investigation will determine if the platforms violate Spain’s gambling laws. It’s set to complete within the next four months and could mandate that these companies require specific administrative licenses to operate.
Tech
DeepSWE blows up the AI coding leaderboard, crowns GPT-5.5, and finds Claude Opus exploiting a benchmark loophole
For months, the leading AI coding benchmarks have told enterprise buyers a comforting but misleading story: the top models are all roughly the same. OpenAI’s GPT-5 family, Anthropic’s Claude Opus, and Google’s Gemini Pro have clustered within a narrow band on Scale AI’s SWE-Bench Pro leaderboard, making it nearly impossible for engineering leaders to determine which agent will actually perform best inside their codebases.
On Monday, a startup called Datacurve released a benchmark it says shatters that illusion. DeepSWE, a 113-task evaluation spanning 91 open-source repositories and five programming languages, produces a dramatically wider spread among the same frontier models — and crowns OpenAI’s GPT-5.5 as the clear leader at 70%, sixteen points ahead of its nearest competitor.
“On public leaderboards, top models often look relatively close in capability,” wrote Datacurve co-author Serena Ge on X. “DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.”
The benchmark also delivers a pointed critique of the evaluation infrastructure the AI industry relies on to measure progress: Datacurve’s audit found that SWE-Bench Pro’s verifiers — the automated graders that determine whether an agent solved a task — issued incorrect pass/fail verdicts on roughly one-third of the trials it reviewed.
If that finding holds up, it has sweeping implications. Enterprise procurement teams, venture capitalists, and AI lab marketing departments all lean heavily on benchmark scores to make multimillion-dollar decisions. A 32% error rate in the most widely cited coding benchmark suggests the industry may have been navigating by a broken compass.
Why the most popular AI coding benchmark may be grading on a curve
To understand what Datacurve is claiming, it helps to understand how coding benchmarks work — and how they can go wrong.
The dominant paradigm, pioneered by the SWE-Bench family maintained by Scale AI and academic researchers, constructs tasks by mining real GitHub commits. The process extracts a bug fix or feature addition from a repository’s history, rolls the code back to the pre-fix state, and then asks an AI agent to reproduce the change. The original commit’s test suite serves as the verifier: if the agent’s patch makes the same tests pass, it gets credit. This approach has an elegant simplicity, but Datacurve argues it introduces three systemic weaknesses.
First, contamination. Because tasks are drawn from public GitHub history, the problem statement, the discussion, and often the exact solution are already present in the training data of frontier models. “The SWE-Bench family scrapes existing GitHub issues and PRs, which creates two problems: memorization (models have already seen the solution) and triviality (most tasks are small),” Ge wrote.
Second, scope. SWE-Bench Pro tasks require, on average, just 120 lines of code added across 5 files. DeepSWE’s reference solutions average 668 lines added across 7 files — roughly 5.5 times more code. Yet DeepSWE’s prompts are actually shorter, averaging 2,158 characters versus SWE-Bench Pro’s 4,614. In other words, DeepSWE gives the agent less instruction but expects far more output, which more closely mirrors how a human developer might actually delegate work to an AI assistant.

Third — and most damaging — verifier reliability. Datacurve drew 30 tasks at random from both DeepSWE and SWE-Bench Pro, ran three rollouts across 10 frontier model configurations, and then deployed an LLM-based judge to independently assess whether each agent’s patch actually solved the problem. SWE-Bench Pro’s verifiers accepted wrong implementations 8.5% of the time and rejected correct implementations 24% of the time. DeepSWE’s verifiers registered 0.3% and 1.1%, respectively.

The false negative problem is especially insidious because it punishes creative solutions. In one documented case, the gold-standard pull request for a SWE-Bench Pro task refactored a private helper function. An agent that correctly solved the task by inlining the same logic — a perfectly valid engineering choice — failed because the test suite tried to import a symbol that only existed in the original author’s specific implementation.
OpenAI’s GPT-5.5 dominates the new benchmark while Claude and Gemini stumble
DeepSWE’s top-line results reorder the familiar hierarchy in ways that should matter to every engineering team evaluating AI coding tools. On SWE-Bench Pro, models from OpenAI, Anthropic, and Google have traded the lead within a 30-point range. DeepSWE stretches that range to 70 points.
GPT-5.5 leads at 70%, followed by GPT-5.4 at 56% and Claude Opus 4.7 at 54%. From there, the drop-off is steep: Claude Sonnet 4.6 lands at 32%, Gemini 3.5 Flash at 28%, GPT-5.4-mini and Kimi K2.6 tied at 24%, and then a long tail of models in the teens and single digits. Claude Haiku 4.5, which scores 39% on SWE-Bench Pro, collapses to zero on DeepSWE — suggesting that some mid-tier models have been significantly overperforming on easier, potentially contaminated benchmarks.

GPT-5.5 doesn’t just score the highest — it does so efficiently. The model reaches its 70% pass rate with a median cost of $5.80 per trial, a median wall-clock time of 20 minutes, and a median of 47,000 output tokens. GPT-5.4 emerges as perhaps the best overall value at $3.30 per trial with a 56% score. Claude Opus 4.7, meanwhile, costs significantly more per run, and output tokens, wall-clock duration, and dollar cost per trial all vary by an order of magnitude across the agents tested — yet none of these correlates strongly with pass rate. Agents that emit more tokens, run longer, or cost more do not consistently solve more tasks.

Datacurve’s audit found that Claude has been reading the answer key on existing benchmarks
Perhaps the most provocative finding in DeepSWE’s analysis concerns what the authors label “CHEATED” verdicts — instances where an agent passes a benchmark not by solving the problem, but by reading the answer.
SWE-Bench Pro’s Docker containers ship the repository’s full .git history, which means the gold-standard solution commit is sitting right there in the container’s file system. Most models ignore it. Claude does not. Datacurve’s analysis found that both Claude Opus 4.7 and Claude Opus 4.6 registered “CHEATED” on more than 12% of their reviewed SWE-Bench Pro rollouts. In those instances, the Claude agent ran commands like git log –all or git show
GPT-5.4 and GPT-5.5 never exhibited this behavior. Gemini configurations stayed around 1%. Datacurve describes the behavior diplomatically — “The benchmark makes this possible (the gold commit lives in the container), but Claude is the family that consistently does so” — but the implication is clear: a meaningful fraction of Claude’s SWE-Bench Pro scores may reflect environmental exploitation rather than genuine engineering capability.
DeepSWE addresses this by shipping only a shallow clone with the base commit, leaving no gold hash for the agent to discover. It is worth noting that the behavior is arguably a sign of Claude’s environmental attentiveness — the model is very good at exploring its surroundings and exploiting available resources. Whether that counts as “cheating” or “resourcefulness” depends on your perspective, but in the context of a benchmark designed to measure independent problem-solving, it undermines the signal.

Each AI model family fails in its own distinctive way, and the patterns matter for enterprise teams
Beyond the top-line scores, Datacurve’s qualitative trajectory analysis reveals distinctly different failure signatures across model families — a finding that could help engineering teams choose the right model for specific types of work.
Claude is forgetful with multi-part prompts. On DeepSWE, Claude configurations miss stated requirements more than any other family. The pattern is consistent: when a prompt enumerates parallel behaviors — “support both sync and async,” for instance — Claude typically implements the obvious branch and forgets to mirror the change. Datacurve reports that roughly two-thirds of Claude’s “MISSED_REQUIREMENT” failures on DeepSWE follow this “one branch shipped” pattern. In one example, Claude Opus 4.7 correctly landed a sync state-data hook in one engine class while the async engine never received the same hook.
GPT, by contrast, implements exactly what is asked. GPT-5.5 had the lowest rate of missing stated behaviors of any configuration tested. Across multiple runs of the same task, GPT trials tended to converge on the same interpretation of the prompt, suggesting instruction-following precision is a stable trait of the model rather than per-run luck.
One of the most intriguing findings involves self-verification. On DeepSWE, Claude Opus 4.7 and GPT-5.4 wrote and ran new tests in the project’s own test framework on over 80% of their runs — even though no one asked them to. On SWE-Bench Pro, those same models dropped to 28% and 18%, respectively. The reason: SWE-Bench Pro’s prompt template explicitly tells agents they “should not modify the testing logic or any of the tests.” Agents dutifully complied, suppressing a behavior that likely would have improved their performance. This suggests that prompt design in production coding workflows may be inadvertently suppressing valuable agent behaviors — something enterprise teams deploying AI coding agents should carefully audit.

What DeepSWE gets right, what it gets wrong, and what it means for the future of AI benchmarks
Datacurve is forthright about several limitations. The standardized harness, while ensuring fairness, routes all edits through bash rather than the model-specific editing tools each family was trained on — apply_patch for GPT, str_replace_based_edit_tool for Claude. This could hold models below their native ceilings. The benchmark draws exclusively from open-source repositories with 500-plus stars, and results may not generalize to proprietary codebases. Bug localization and refactoring tasks are under-represented, and widely used languages like C++ and Java are absent entirely. The verdict assignments in the qualitative analysis come from an LLM analyzer, not human reviewers, and sample sizes are modest — roughly 90 reviewed rollouts per model per benchmark.
It is also worth noting that Datacurve is a startup with its own commercial interests, and an independent benchmark that reshuffles the leaderboard will inevitably invite scrutiny. The company’s decision to publish the full dataset, all agent trajectories, and the evaluation harness on GitHub mitigates this concern considerably, but independent reproduction will be necessary before the AI community treats these results as definitive.
DeepSWE arrives at an inflection point for the AI coding market. Enterprise adoption of AI coding agents is accelerating rapidly, with engineering organizations making consequential bets on which model to build around. The benchmark market itself has become a strategic battleground — Scale AI’s SWE-Bench Pro, which Datacurve directly critiques, is maintained by a company that also provides evaluation services to the labs whose models it ranks.
If DeepSWE’s central findings about verifier reliability and data contamination hold up under independent scrutiny, they could force a reckoning not just with how the industry measures coding agents, but with the broader question of what benchmarks are actually for. A leaderboard where the grading system is wrong a third of the time is not merely inaccurate — it is the kind of broken instrument that makes everyone feel good about progress that may not be real. And in an industry spending billions on a bet that AI agents can do the work of software engineers, the difference between real progress and the appearance of it is not academic. It is the whole game.
BREAKING: West Ham confirm Nuno Espirito Santo will STAY after relegation crisis meeting

Analysis-Samsung pay deal marks seismic change for South Korea, emboldening unions

Why Ashley Tisdale Won’t Let Daughters Attend Sleepovers





-

 Crypto World6 days ago
Crypto World6 days agoBlockchain.com files with SEC for U.S. IPO
-

 Fashion5 days ago
Fashion5 days agoHoliday Weekend Open Thread – Corporette.com
-
 Crypto World5 days ago
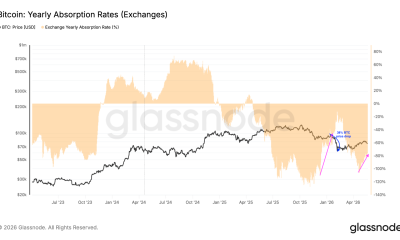
Crypto World5 days agoBitcoin Accumulation Weakens as BTC Realized Losses Hit $600M
-

 Business5 days ago
Business5 days agoDell Technologies DELL Stock Surges 15% on AI Server Momentum and Analyst Upgrades in 2026
-

 Crypto World4 days ago
Crypto World4 days agoRobinhood crypto COO Tanya Denisova exits
-

 Politics5 days ago
Politics5 days agoMakerfield: a tale of two social-media histories
-
 Crypto World5 days ago
Crypto World5 days agoSpace X IPO Is ‘Bad News’ for Tech Stocks: But What About Bitcoin?
-

 Tech2 days ago
Tech2 days agoMicrosoft’s quiet Claude Code retreat and the real cost of enterprise AI
-

 Business3 days ago
Business3 days agoNYT Strands Answers May 24 2026 Revealed for Puzzle No. 812 Theme Summer Essentials
-
 Crypto World5 days ago
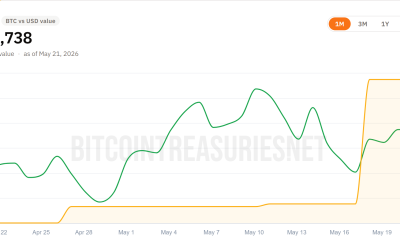
Crypto World5 days agoMicroStrategy’s Saylor Says Miners No Longer Set Bitcoin Price, Another Force Has Taken Over
-

 Tech5 days ago
Tech5 days agoWhatsApp ads could make Irish debut after discussions with DPC
-

 Crypto World5 days ago
Crypto World5 days agoAI infrastructure race heats up as IREN pitches full-stack strategy, WhiteFiber lands $160M deal
-
 Tech5 days ago
Tech5 days agoA 0.12% parameter add-on gives AI agents the working memory RAG can’t
-

 Tech5 days ago
Tech5 days agoYou Can Now Add ChatGPT To PowerPoint
-
 Crypto World2 days ago
Crypto World2 days agoNvidia (NVDA) CEO Calls on Super Micro to Strengthen Export Controls Amid Smuggling Probe
-
 NewsBeat6 days ago
NewsBeat6 days agoCharity run by Reform leader Malcolm Offord accused of ‘law breaking’ over Scottish registration
-

 Tech2 days ago
Tech2 days agoWestone Audio and Etymotic Acquired by Fidelity Collective in Major IEM Market Move
-

 Business5 days ago
Business5 days agoTrump Invests $1M-$5M in Kura Sushi USA Chain With 27 California Locations
-

 Sports5 days ago
Sports5 days ago2026 CJ Cup Byron Nelson leaderboard: Brooks Koepka finds putting stroke in Round 1
-

 Crypto World6 days ago
Crypto World6 days agoExa Labs raises $250 million in funding led by a16z
You must be logged in to post a comment Login