
TL;DR
Canada’s Bill C-36 would replace PIPEDA, restrict surveillance pricing, and create a regulator that can fine companies up to C$25M or 5% of revenue.




The city that gave the world cloud computing just hit pause on the machines that power it.
The Seattle City Council voted unanimously Tuesday to impose a one-year emergency moratorium on new large data centers inside the city limits, responding to concerns about the implications of AI for the city’s power grid, water supply, utility rates, and economy.
The moratorium would take effect as soon as Mayor Katie Wilson signs it, temporarily halting projects like several large data centers that companies have approached Seattle City Light about building in the city. Those projects reportedly had a combined peak demand equal to about a third of Seattle’s average daily power consumption.
“This is Seattle’s position on AI and data centers,” said Councilmember Debora Juarez, who sponsored the council’s resolution on data center policy. She drew cheers from the audience at the meeting when she said she would halt AI and data center development entirely if she could.
It’s a major statement in a region that’s home to Amazon Web Services and Microsoft Azure, as well as engineering centers for Google, Oracle, Meta and other companies collectively spending hundreds of billions of dollars on data centers globally to meet demand for AI.
The moratorium puts Seattle among the largest U.S. cities to halt the industry’s buildout, joining Minneapolis, Denver, Baltimore, and Indianapolis in a wave of local pushback.
The council approved two measures: an ordinance halting applications for data centers with electrical capacity of more than 20 megavolt-amperes — enough power for thousands of homes — and a resolution committing the city to study their impacts as a precursor to permanent regulations.
The vote followed weeks of escalating public pressure. More than 50 people testified Tuesday, and not one spoke in favor of data centers. Many argued the moratorium doesn’t go far enough, calling for a permanent ban. Councilmembers said they received more than 98,000 emails on the issue.
Some of the most pointed testimony came from inside the industry.
Members of Amazon Employees for Climate Justice, who also testified at two meetings last week, urged the council to add renewable energy requirements and labor protections, and called for an end to what one AECJ member called the industry’s race “to build out as much compute capacity as they can, as fast as they can, before regulations can catch up.”
“It’s great to see this council choose to empower ordinary people and workers over those who see them as expendable,” said Srija Nagireddy, an AECJ member, citing layoffs this year at Amazon and Meta amid record earnings.
Councilmember Bob Kettle offered the closest thing to a defense of the facilities, distinguishing hyperscale projects from what he called “traditional data centers” — including one downtown that he said heats a half-dozen nearby buildings and supports the city’s first responders. His amendment to the resolution, adopted unanimously, specified that AI is driving demand for “hyperscale” facilities, and added the reliance of government, healthcare, and education on existing data centers to the city’s study list.
Notably, neither Amazon nor Microsoft operates data centers in Seattle itself. Kettle pointed out during the meeting that Amazon’s facilities cluster in Oregon, while Microsoft’s data center presence in the state is in Quincy, the central Washington town transformed by cheap Columbia River hydropower. That means the moratorium’s immediate effect falls on data center developers rather than the tech giants.
The ordinance exempts the roughly 30 smaller data centers already operating in Seattle, allowing each to expand by up to another 20 megavolt-amperes, which is the same amount as the threshold of the moratorium on new facilities.
Mayor Wilson, who first floated the idea of a moratorium in April, is expected to sign the legislation. City departments would then develop permanent data center regulations, with zoning legislation expected to reach the council by early 2027.
The fate of one project — Digital Realty’s proposed facility at 301 Virginia St., filed 11 days before the vote — remains unclear. Whether the moratorium can halt an application already in the pipeline is likely a question for permitting officials and possibly the courts.
The Trump “Department of Justice’s” “antitrust division” dumped its unsurprising approval of the terrible Paramount Warner Brothers merger late on Friday in the hopes people wouldn’t notice it.
As we’ve noted the $111 billion megadeal is a historically harmful mess. Backed by billions in Saudi and Chinese cash (raising all sorts of foreign media influence concerns), the giant deal will saddle the company with so much debt that mass layoffs, consumer price hikes, and quality erosion from corner cutting are guaranteed. This happens with every major media merger, but especially when Warner Bros is involved.
And that’s before you get to the problems with Larry Ellison and his Bari Weiss brigades trying to destroy what’s left of already soggy U.S. corporate journalism and replace it with right wing, oligarch-friendly agitprop.
Regardless, you’ll be comforted to know that the Trump Justice Department looked at the deal closely and found that not only does it not hurt competition, it’s going to improve competition:
“The evidence reviewed and carefully analyzed by the Division indicates that, post-merger, competition in SVOD is not likely to be harmed. To the contrary, the combined firm is likely to increase competition by offering consumers a more robust competitive alternative to the larger SVOD offerings.”
That is, again, not how any of this works.
The massive debt created by these deals always results in mass layoffs, higher consumer prices, and lower quality product due to corner cutting. It’s not debatable. Arguing against this is like trying to have a fist fight with a running river. You just have to look back at, well, every single major media consolidation effort in the last fifty years. Which the DOJ didn’t because, well, they didn’t care.
You’ll still have major competitors to Paramount like Netflix, Comcast/NBC, Apple, and Disney, but in a country obsessed with consolidation that no longer has functional regulators, there’s really nothing stopping any limit of predatory behaviors — and additional consolidation — moving forward. There’s ongoing pretense that our consumer and labor protections still function. They don’t.
The “funny” part is the Trump DOJ even acknowledges that the history of Warner Brothers has been pockmarked by all manner of terrible competition-eroding consolidation. They just pinky swear that this time will somehow be different. Based on… nothing:
“Warner Bros. has been a repeated acquisition target in the media and entertainment industry. It is thus familiar to the Division from prior investigations and enforcement actions, including AOL/TimeWarner (2001), AT&T/TimeWarner (2018), and WarnerBros./Discovery (2022). The legacy of these transactions illustrates the challenges that arise when the commercial rationale for a deal lacks clear alignment with competitive incentives of the acquiring firm or the competitive evolution of the marketplace. In technology-driven industries, the disruptors of the recent past may quickly become the entrenched monopolists of the present day. It is with this historical experience and present enforcement sensitivity to the contestability of dynamic markets that the Division conducted a thorough investigation of the proposed transaction to assess whether the proposed transaction presented any harm to competition. The extensive investigatory record reviewed by the Division suggests that the impact of the transaction will be to increase competition across the media and entertainment ecosystem, with benefits for American consumers and workers.”
Fun fact: Paramount’s top lawyer is Makan Delrahim, Trump’s “DOJ enforcer” from the first administration. Delrahim personally worked to make sure Sprint could merge with T-Mobile during the first term. They promised that deal would result in untold synergies and new competition. Instead, 8,000+ people lost their jobs and U.S. wireless carriers immediately stopped competing on price. It’s been memory holed.
As far as the inevitable layoffs that always result from these deals (recall that AT&T’s merger with Warner Brothers and DirecTV resulted in 50,000 lost jobs), the DOJ simply declares that won’t be happening this time. Why? Because Larry and David Ellison said they’ll keep pumping out brick-and-mortar movies at the same or greater pace (they won’t):
“While taking seriously the potential impact of the proposed transaction on the creative community and domestic labor groups, the substantial evidence does not suggest a likelihood of reduction in output. That is because the demand for creative workers and labor is correlated with the Parties’ incentives to maintain or expand output. Thus, the expressed labor concerns do not raise actionable antitrust concerns.”
In three years, after the resulting company has fired 10,000+ employees, consumers have been price gouged to reduce debt, and the resulting flailing mess is acquired for half (or less) of the price, all the folks involved with this will have moved on to hyping other terrible ventures. Nobody will own any of this or engage in a single moment of meaningful reflection. That’s how this always works.
And the corporate press (and pundits like Matt Stoller) will still try to tell you that Republicans are to be taken seriously on antitrust reform.
Granted DOJ approval of a terrible merger isn’t the final word. State AGs have hinted repeatedly at a looming collaborative antitrust lawsuit that, at a minimum, is likely to drag any integration out considerably. If that lines up with a potential AI bubble pop and economic reverberations, that massive debt load from gobbling up CBS/Paramount and Warner Bros will be an even larger albatross.
Filed Under: antitrust, competition, david ellison, doj, journalism, larry ellison, makan delrahim, media, media consolidation, mergers, streaming
Companies: paramount, warner bros.

Canada’s Bill C-36 would replace PIPEDA, restrict surveillance pricing, and create a regulator that can fine companies up to C$25M or 5% of revenue.
The Canadian government introduced legislation on Monday to overhaul the country’s private-sector privacy laws, including new restrictions on businesses that use personal data to charge individual consumers higher prices. Bill C-36, the Protecting Privacy and Consumer Data Act, would replace the Personal Information Protection and Electronic Documents Act, a law first enacted in 1998 that has been widely criticised as outdated in the age of algorithmic pricing and large-scale data collection.
Artificial Intelligence and Digital Innovation Minister Evan Solomon said the bill targets so-called surveillance pricing, the practice of using a consumer’s browsing history, location, device type, or purchasing behaviour to set individualised prices. “Companies should not have the ability to use your behaviour, your location, your profile, your vulnerabilities, or your personal information to charge unfair prices,” Solomon told reporters. “Your personal information should not be used against you for price gouging.”
The bill does not ban surveillance pricing outright. Solomon said the legislation aims to bar the use of data to target consumers with individualised prices when the harms outweigh the benefits, but the government does not want to prevent companies from rewarding consumers with better prices through loyalty programmes or promotional discounts. Surveillance pricing is not specifically mentioned in the bill’s text, according to BetaKit, and Solomon will instead ask the new regulator to draft guidance on the issue once it is operational.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
That regulatory gap is significant. The bill creates a new body called the Digital Safety and Data Protection Commission to oversee compliance with both the privacy legislation and the proposed Digital Safety Act, which aims to safeguard children online. The Office of the Privacy Commissioner of Canada would retain responsibility for overseeing government compliance with federal privacy laws, but the new commission would handle the private sector.
The penalties are substantial on paper. The commission could impose fines of up to C$10 million ($7.1 million) or 3% of global revenue, whichever is greater, for non-compliance. The most serious offences could face fines of up to C$25 million or 5% of global revenue. Whether those penalties are ever applied will depend on whether the bill passes Parliament and how aggressively the commission interprets its mandate.
Beyond surveillance pricing, the bill introduces several consumer protections that bring Canada closer to the European Union’s General Data Protection Regulation. Canadians would gain the right to have their personal information deleted under certain circumstances. Organisations would be required to disclose more information about automated decisions affecting consumers. Children’s data would be classified as sensitive, requiring a higher standard of care from any business that collects it.
Canada is not moving in isolation. Manitoba’s provincial government introduced Bill 49 in March, which would prohibit retailers from using personal data to increase prices for individual consumers both online and in stores. In the United States, Maryland became the first state to enact a surveillance pricing ban when Governor Wes Moore signed HB 895, prohibiting food retailers with locations larger than 15,000 square feet and third-party delivery services from using personal data to raise prices on individual shoppers. That law takes effect on 1 October.
Public opinion in Canada strongly favours action. An Abacus Data poll conducted in early March surveyed 1,931 Canadians and found that 52% said surveillance pricing should be banned outright, while 31% said it should be allowed but more strictly regulated. The bill’s approach, restricting rather than banning, positions the government closer to the minority view, though Carney’s broader $2.3 billion national AI strategy had already signalled that new privacy legislation was coming without specifying how far it would go.
The privacy bill arrives less than two weeks after the AI strategy launch and days after Carney warned at the G7 about the systemic risks of AI dependence. The timing suggests the government is attempting to build a coherent regulatory framework across AI investment, data sovereignty, and consumer protection simultaneously. Whether those pieces fit together or contradict each other, spending $2.3 billion to accelerate AI adoption while restricting how AI-driven pricing can use consumer data, will depend on the details that the new commission eventually produces.
The bill still needs to pass Parliament. Canada’s previous attempt at modernising its privacy framework, the Artificial Intelligence and Data Act within Bill C-27, never made it through the legislative process and has not been revived. If Bill C-36 meets the same fate, the country will continue operating under a privacy law written before smartphones existed, while other jurisdictions move ahead with enforcement of their own digital protection regimes.
Modern sports clubs operate like most large businesses, and as such, they are targeted by cybercriminals – however, the risk surfaced by the use of AI is even more amplified in this industry, compared to others.
A new report from Darktrace examined how the security risk of AI is twofold: on one end, there are criminals using the new tool to create convincing phishing lures, deepfakes, spoof brands and imitate professional athletes. On the other hand, there are sports clubs themselves using AI without proper safeguards, creating an entirely new risk surface that can be exploited.
According to Darktrace, this risk is amplified in professional sports “where live events, high-value data, public pressure, fixed schedules, and large networks of partners and suppliers all intersect at once to offer attackers maximum publicity, profit, and potential impact.”
To create the report, Darktrace used telemetry data from sports organizations, as well as the results of a survey of 875 security decision makers and influencers at professional sporting organizations.
That being said, more than four in five (84%) of professional sports organizations experienced at least one cyber incident in the past 12 months, while more than half (57%) were struck multiple times. What’s more, 83% detected the use of AI in these attacks, and 72% believe AI will increase cyber risk over the next year.
When it comes to damages, a single incident now costs around $170,000. While that might not sound like much for a professional sports team with high earnings, it’s worth mentioning that 57% were hit more than once, and 43% reported between six and 10 incidents in a single year. Therefore, the cumulative annual cost can go to $1.7 million.

The best antivirus for all budgets

Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds.


Tokyo-based AI startup Sakana AI has officially launched its first commercial product, Sakana Marlin.
Billed as a “Virtual CSO” (Chief Strategy Officer), Marlin is an autonomous, B2B research agent that deliberately abandons the instantaneous text generation of modern chatbots in favor of deep, long-horizon reasoning.
What sets Marlin apart from the current ecosystem of AI tools is its temporal scale: instead of returning an answer in seconds, it runs continuous, self-governing reasoning loops for up to eight hours at a time to deliver deeply researched, well cited, 100-page strategy reports and executive slides. The company posted sample reports generated by Marlin on its product website here.
Available immediately via the company’s website with pricing starting at a pay-as-you-go tier, the platform is designed strictly for enterprise use—specifically targeting corporations, financial institutions, and think tanks.
The generative AI hype cycle has largely been defined by speed. For the past two years, the industry standard has been the ability to generate a poem, a line of code, or a surface-level summary in mere milliseconds. But the enterprise frontier is rapidly shifting from shallow, rapid generation to deep, methodical reasoning.
With Marlin, major businesses are no longer asking how fast an AI can answer, but how deeply it can think.
What exactly is a business getting when they deploy Sakana Marlin? The workflow is fundamentally different from typical large language model (LLM) interactions. Rather than engaging in a tedious back-and-forth prompt engineering session, the user simply provides a core research topic. Following a brief initial exchange to sharpen the scope and direction of the investigation, the human steps away entirely.
For the next several hours, Marlin operates as a self-contained digital strategy team. It formulates its own initial hypotheses, navigates the web to gather data, cross-references sources to verify findings, and maps the causal dynamics within complex business environments. It is effectively searching for the “winning formula” within a sea of noise.
Think of it less like a search engine and more like a junior strategy consultant locked in a room with a whiteboard and an internet connection. You provide the strategic prompt in the morning, and by the end of the workday, the system delivers a comprehensive, professional-grade portfolio.
In Marlin’s case, the final output is not a generic text blob; it is a structured set of strategic options, complete with executive summary slides, appendices, references, and a deeply researched report.
The company highlighted several real-world use cases to demonstrate Marlin’s capacity for complex synthesis, including generating detailed resolution scenarios for a theoretical blockade of the Strait of Hormuz, mapping out the fragmented global AI regulation patchwork, and analyzing macroeconomic trends like the return of “bond vigilantes”.
Sakana says Marlin relies on multiple AI models, but did not provide specific model names or providers. I’ve reached out on X to find out more and will update when I receive a response.
VB Transform · July 14–15 · Menlo Park · LLMs, ops & evals
Standard benchmarks fail. Amazon and Waymo explain what they test instead.
The evals track goes deep on the four dimensions of reliability — consistency, robustness, predictability, safety — and how teams at Amazon and Waymo are operationalizing them in production.
Under the hood, Marlin is the commercial culmination of Sakana AI’s extensive laboratory breakthroughs over the past two years.
The product is powered by an exploration engine relying on Sakana’s own prior research breakthrough, Adaptive Branching Monte Carlo Tree Search (AB-MCTS), and leverages frameworks derived from “The AI Scientist,” an earlier Sakana AI research project featured in the journal Nature that successfully automated the scientific discovery process from ideation to peer review.
To understand how this works in practice, consider a real-world analogy: modern chess engines. When a computer plays chess, it doesn’t just look at the board and guess; it plays out thousands of potential future moves, evaluating the strength of each resulting position before committing to an action.
Marlin’s AB-MCTS engine does something similar for research.
The chronology of this technology traces back to June 2025, when Sakana AI first introduced the framework to the public alongside the research paper “Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search”.
At that time, to encourage developer experimentation with collective AI intelligence, the company released the underlying algorithm as an open-source software library called TreeQuest, distributed under the permissive Apache 2.0 license. This open-source milestone laid the technical foundation for what would eventually evolve into the proprietary, enterprise-grade Marlin product a year later.
Traditionally, when developers attempt to extract higher-quality reasoning from large language models, they rely on a brute-force method called “repeated sampling”—essentially running the model dozens of times in parallel and hoping one of the answers is correct. However, repeated sampling operates blindly; it cannot evaluate its own intermediate steps or pivot based on external feedback.
AB-MCTS replaces this paradigm with a principled, multi-turn approach driven by a Bayesian decision framework. As the AI constructs a strategy report, the system treats the research process as a branching tree of possibilities. At each node of the tree, the algorithm dynamically balances two distinct behaviors based on external feedback signals:
Going Wider (Exploration): Spawning entirely new, alternative hypotheses or candidate responses when the current path yields diminishing returns or unresolved contradictions.
Going Deeper (Exploitation): Methodically refining, auditing, and building upon an existing candidate solution that shows high strategic promise.
What transforms this from a laboratory experiment into a commercial engine is its extension into Multi-LLM AB-MCTS.
Sakana AI’s architecture introduces a critical third dimension to the search tree: the ability to dynamically choose which model to invoke for a specific sub-task, treating the industry’s leading frontier models as a plug-and-play collective intelligence network.
According to technical documentation published by the company, the engine can coordinate highly heterogeneous models—allowing an orchestration model to delegate initial ideation to one LLM, while utilizing a reasoning-heavy model to audit, verify, and correct intermediate errors generated earlier in the search tree.
By scaling up compute at inference time—leveraging the distinct “personalities” and strengths of multiple foundation models over thousands of automated cycles—AB-MCTS provides the mathematical guardrails Marlin requires. It ensures that the resulting 100-page strategy reports are not merely long-winded AI generations, but the highly vetted product of systemic, automated trial-and-error.
It is crucial to note that Sakana Marlin is distinctly not a general consumer tool; it is a commercial software-as-a-service (SaaS) offering restricted to corporate entities, organizations, and sole proprietors.
For enterprises, licensing and data handling terms are often the determining factors in software adoption. Unlike many consumer-grade AI tools that silently harvest user inputs and proprietary data to train future foundational models, Sakana Marlin operates under a strict, enterprise-grade data policy.
Neither Sakana AI nor its external AI service providers will use customer data or inputs for model training or fine-tuning unless the client provides explicit opt-in consent.
Even with consent, data is heavily processed to remove personally identifiable information. This closed-loop security is absolutely vital for companies handling sensitive M&A research, unreleased product strategies, or proprietary market analyses.
The commercial licensing is structured into tiered pricing models that reflect its enterprise nature:
Pay-as-you-go: Users can purchase credits on demand, with a single run costing 100 credits, and add-on credits priced at ¥98 ($0.61 USD) each.
Pro Plan: At ¥150,000 ($935.68 USD) per month, businesses receive 2,000 credits, bringing down the cost of add-on credits to ¥90 ($0.56 USD).
Team Plan: Geared toward larger departments, this ¥400,000 ($2,495.14 USD) per month tier includes 6,000 credits, lowering add-on costs to ¥85 ($0.53 USD) per credit.
Enterprise: Fully custom quotes with dedicated support and customized credit allocations.
Sakana AI’s transition into a commercial enterprise powerhouse is rooted in the pedigree of its founders, who famously helped spark the current generative AI boom.
Formed in Tokyo in 2023, the startup was co-founded by Llion Jones—a co-author of Google’s seminal 2017 “Attention Is All You Need” paper who coined the term “transformer”—and David Ha, a former Google Brain researcher and head of research at Stability AI.
The decision to build a new laboratory outside the Silicon Valley bubble was a deliberate rejection of the current AI ecosystem. At a TED AI conference in late 2025, Jones candidly expressed that he was “absolutely sick” of transformers, warning that the intense pressure from investors and the hyper-fixation on scaling single, monolithic models had calcified the industry’s creativity and blinded researchers to the next major breakthrough.
To break free from this “big company-itis,” Jones and Ha structured Sakana AI around principles of biomimicry and evolutionary computing.
The company’s name, derived from the Japanese word for fish, reflects its core technical philosophy: leveraging collective intelligence similar to schools of fish, ant colonies, or insect swarms. Rather than attempting to build one massive, do-it-all foundation model, Sakana’s research has consistently focused on deploying networks of smaller, specialized models that collaborate dynamically to adapt to complex environments.
This philosophy posits that by treating individual AI models as members of a “dream team” with complementary strengths, systems can achieve more robust and cost-effective reasoning than relying on sheer scale alone.
This nature-inspired approach quickly yielded dividends in rigorous, competitive testing. Sakana AI has made significant strides in “inference-time scaling”—allocating computational resources during the problem-solving phase to allow models to think, iterate, and refine their own answers over extended periods.
In early 2026, the company’s ALE-Agent took first place in the highly complex AtCoder Heuristic Contest (AHC058), a combinatorial optimization challenge, outperforming over 800 top-tier human programmers by autonomously rebuilding and testing hundreds of solutions over a four-hour window.
Similarly, Sakana introduced “RL Conductor,” a small 7-billion-parameter model trained via reinforcement learning specifically to orchestrate and delegate tasks among a diverse pool of worker models—ranging from GPT-5 to Claude Sonnet 4—achieving state-of-the-art results on reasoning benchmarks at a fraction of traditional computing costs.
Sakana’s rapid evolution from a disruptive research lab to a commercial software provider has attracted intense attention from global financial heavyweights.
By late 2025, the Tokyo-based startup secured a massive Series B funding round that pushed its post-money valuation past $2.6 billion, cementing its status as one of Japan’s most highly valued private tech companies. The firm boasts a sprawling roster of strategic investors, including early venture backers Khosla Ventures, Lux Capital, and New Enterprise Associates (NEA), alongside industry titans like Nvidia and Google.
As Sakana has expanded its focus toward mission-critical sectors like defense and finance, it has also drawn investments from major global banking institutions like Mitsubishi UFJ Financial Group (MUFG) and Citi, as well as enterprise tech giant Salesforce, positioning the startup to actively reshape corporate AI infrastructure from the ground up.
Sakana AI’s shift toward commercial, long-horizon agents did not happen in a vacuum. The company ran a rigorous closed beta test beginning in April 2026, putting the tool in the hands of approximately 300 professionals across financial institutions, consulting firms, and think tanks. The feedback underscores a stark qualitative difference between standard generative chatbots and Marlin’s autonomous, fact-driven approach.
A senior consultant at a major Tokyo consulting firm noted that the tool “exceeded expectations by discovering angles we hadn’t even imagined,” praising its ability to match human comprehensiveness while stripping away human bias. Meanwhile, a cybersecurity division at a major Japanese IT system integrator lauded the system for providing “a highly convincing report driven by high-quality, primary research,” rather than relying on recycled secondary sources.
On social media, the company’s announcement resonated with the broader tech community’s growing appetite for autonomous agents.
As the AI industry matures, the value proposition is clearly shifting. Tools that act as fast, conversational encyclopedias are becoming commoditized. With Sakana Marlin, the focus moves entirely to separating the heavy lifting of thinking from the final act of deciding. By delegating the exhaustive mapping of causal dynamics to an agent capable of sustained reasoning, human executives are free to do what they do best: take action.


Websites are being redesigned for consumption by AI models, and now a coalition wants to extend the trend to digital documents.
The LF AI & Data Foundation, under the Linux Foundation, has formed a working group to steer the development of DocLang, an AI-friendly document format that aims to help enterprises feed their files to AI systems.
The DocLang group, founded by IBM, NVIDIA, Red Hat, ABBYY, HumanSignal, and Forgis, contends that existing formats like PDF, Markdown, HTML, and LaTeX are ill-suited for AI document parsing.
In late 2024, IBM developed an open source toolkit called Docling to facilitate AI document parsing, not unlike Microsoft’s MarkItDown or the Marker project. Docling provides a way to convert various file formats into structured AI-ready data. DocLang expands upon that foundation with a standard for exchanging structured output across different systems.
“DocLang is designed to solve one of the foundational problems in enterprise AI: documents were built for humans, not machines,” said Maxime Vermeir, VP of AI Strategy at AI automation biz ABBYY in a statement. “By introducing a minimal, standardized, and AI-native representation of document structure, layout, meaning and governance, DocLang creates a far more deterministic foundation for modern AI systems.”
The new DocLang format is necessary, the spec authors argue, because existing formats were designed for rendering and lose semantic information, structural relationships, or geometric context when AI models turn them into tokens. The specification explains that Markdown lacks sufficient scope, that HTML is excessively verbose, and that LaTeX allows too much ambiguity.
Essentially, DocLang is optimized for LLM tokenizers through markup that maps between DocLang elements and LLM tokens on a 1-to-1 basis. The spec relies on a limited XML vocabulary that aligns with LLM tokenizers to produce optimized prompts. It is lossless, so the AI conversion doesn’t do away with valuable info. It’s designed to support common graphical elements like tables, formulas, charts, and multimodal content. And it’s an open standard.
DocLang could also help keep costs under control. According to AI Cost Check, having an AI model conduct an OCR scan on a PDF requires about 1,200 input tokens and 150 output tokens as a baseline.
That’s inconsequential to corporate AI customers on a one-off basis but demands attention at scale. And because AI models have highly variable token costs, companies may find they are spending more than they anticipated to have their AI system ingest PDFs, particularly if the documents are long and complicated or an expensive frontier model is used.
“PDFs were designed for rendering, not understanding,” said Jon Knisley, AI Value and Enablement Lead at ABBYY, in an email to The Register. “Every time a PDF enters an AI pipeline, structure, meaning and layout get lost, so the model’s accuracy ends up bottlenecked by document quality rather than model quality. Teams compensate by building custom parsers at every integration point, which results in brittle, one-off work, and a new engineering sprint for every new document type.”
According to Knisley, that has measurable cost.
“Ambiguous structure forces the model into guesswork, which drives up hallucination risk and burns tokens deciphering layout instead of extracting meaning,” he explained. “With DocLang, customers can expect better accuracy, lower costs, fewer tokens consumed, faster performance and more consistent outputs. The exact savings depend on the use case and document complexity, but our initial benchmarks show 4x to more than 30x lower cost depending on the model evaluated.”
Knisley also cited governance advantages, noting that document provenance data and metadata can get stripped when documents gets moved. DocLang, he said, keeps that information attached.
ABBYY, which offers AI document processing, has created the DocLang Interactive Benchmark to illustrate the potential token savings of feeding DocLang documents to AI models. A PDF of IBM’s 2025 annual report, for example, results 8,421 input tokens and 512 output tokens while a DocLang version requires only 5,310 input tokens and 498 output tokens. What’s more, the DocLang version results in lower latency (2.7s vs 4.2s) and delivers better quality (the AI missed one subsection and mangled a table merger in the PDF).
“It’s still early, and we won’t overstate adoption,” said Knisley. “The standard is open and free to build on, and the group is actively inviting more technology providers and enterprises to join. The early response has been encouraging, and we’re optimistic about where it goes from here.” ®


Nearly 750 million people face hunger today, according to the U.N. World Food Program. And by 2050, global demand for food is expected to increase by 50 percent from 2010 levels, the World Resources Institute says.
A smart agriculture special-issue report recently released by the IEEE Smart Agri-Food Initiative says meeting the demand will require technology to expand food production. The report highlights research, case studies, and new ways of applying technology to inform farmers, engineers, and policymakers.
Leading the initiative is IEEE Fellow John Verboncoeur, chair of the smart-food program and professor of electrical and computer engineering at Michigan State University, in East Lansing.
“Food security is becoming a systems-engineering problem,” Verboncoeur says. “We’re no longer talking only about tractors and irrigation. We’re talking about sensing, communications, computation, automation, and sustainability all working together.”
Although not formally trained as an agriculture scientist, Verboncoeur’s first involvement with smart agriculture was as an undergraduate at University of Florida in 1985-86, where he helped develop an SmartAg aeroponics system for NASA for the International Space Station. It used mist to spray the plants’ roots and lightweight pneumatic structures to hold the vegetation in place.
He has also chaired the executive committee of Michigan State’s SmartAg Initiative since it launched in 2017. He chaired the program’s leading interdisciplinary efforts to apply engineering and digital technologies to farming and food systems.
Verboncoeur connects the shift of using engineering as a force multiplier for farming to lessons learned from the IEEE Smart Village program, which supports projects and organizations bringing electricity and educational and employment opportunities to remote communities. Agriculture, he argues, requires the same systems-level mindset.
“The challenge isn’t just inventing technology,” he says. “It’s making systems practical, affordable, and deployable.”
A central theme across the Smart Agri-Food Systems report is the convergence of automation, data analytics, and sustainability.
One paper, “Smart Agriculture, Precision Agriculture, Digital Twins in Agriculture: Similarities and Differences,” addresses the confusion regarding how researchers and practitioners define and apply the technologies to farming.
The paper was written by Dilan Onat Alakuş, a research assistant in the software engineering department at Kırklareli University, in Türkiye, and Ibrahim Türkoğlu, a software engineering professor at Fırat University, in Elazığ, Türkiye.
Unclear terminology can lead to inefficient investment and poor adoption of the technologies, the two authors say. They note that agricultural methods based on traditional practices and intuition lack a thorough analysis of their environmental and economic impacts.
They describe how three technologies can benefit farmers:
• Smart agriculture systems integrate sensors, artificial intelligence, robotics, and analytics to improve efficiency and sustainability at scale.
• Precision agriculture focuses on location-specific decisions. Farmers use GPS-guided equipment to map fields, deploy drones to monitor crop health, and install field sensors that track soil moisture and nutrient levels in targeted zones. The tools allow farmers to apply water, fertilizer, and pesticides only where needed—which can reduce waste and lessen environmental impact.
• Digital twins create virtual replicas of an agricultural area. The resulting models simulate the farmstead, crops, and irrigation systems, allowing growers to test scenarios and predict outcomes before implementing changes.
The authors emphasize that the categories overlap in practice. A digital twin might draw data from precision agriculture systems and feed recommendations into smart agriculture platforms.
Clearer distinctions help farmers select appropriate tools and avoid unnecessary complexity and costs, they say.
“This study contributed to conscious agricultural practices by differentiating agricultural technologies,” they wrote, adding that clearer definitions can increase productivity.
The report shifts from theory to application in a paper describing bustani, which means my garden in Arabic. The Bustanica project in Saudi Arabia is an automated hydroponic vertical farming system developed by researchers at the Prince Mohammad Bin Fahd University, in Al-Khobar, Saudi Arabia. The “Bustani: A Microcontroller-Based Automated Hydroponic Vertical Farming Solution” paper was written by Hussah Alotaibi, a computer engineer at Saudi Aramco, the country’s national oil company; Abul Bashar, Widad Karsou, and Shehvar Khan, researchers in the university’s computer engineering and computer science department; and Salahudean Tohmeh from the university’s robotics laboratory.
The Bustanica system combines hydroponics with aeroponics, in which plant roots hang in the air and receive nutrients through a misting system. Together, the approaches allow crops to grow in compact indoor environments, using far less water than traditional methods.
The method integrates IoT sensors that continuously monitor water chemistry and reservoir conditions.
The system grows crops in controlled indoor environments. A closed-loop design recirculates water to reduce waste. Sensors measure pH levels, nutrient concentration, and water levels. An Arduino Mega processes the sensor data. A NodeMCU ESP8266—a low-cost, open-source IoT platform—handles Wi-Fi communication and cloud connectivity.
The system sends the data through Google’s Firebase cloud platform, which acts as a real-time bridge between sensors and control systems.
A mobile app lets users monitor and control the system remotely. It displays real-time data on lighting, nutrient levels, and water pump activity. When conditions move outside optimal ranges, automated dosing pumps adjust the levels as needed.
Engineering can’t solve all the world’s problems. But it absolutely has a role to play in helping the world feed itself.” —John Verboncoeur, chair of the IEEE Smart Agri-Food initiative
The system operates as a feedback loop, collecting data, transmitting it to the cloud, analyzing the conditions, and automatically triggering adjustments.
LEDs simulate sunlight. Ultrasonic sensors measure water levels. Electrical conductivity sensors track nutrient concentration. During testing, the system maintained stable environmental conditions and adjusted dosing dynamically as readings changed.
The authors describe the outcome as “a fully functional and automated vertical sustainable farm that creates desirable growing conditions, along with an Android application that provides real-time monitoring and notifications.”
Beyond automation, bustani reflects a broader shift toward merging agriculture with consumer technology and smart-home systems. Future plans include integrating the Amazon Alexa virtual assistant and machine learning tools for plant disease detection and growth analysis.
The “Toward an Efficient Tomato Harvesting Robot” paper addresses autonomous harvesting, a long-standing challenge in agricultural robotics. Tomatoes in the field vary widely in size, shape, and ripeness, and they can bruise during handling. The paper was written by IEEE Senior Member Hyoung Il Son—a professor of biosystems engineering and robotics at Chonnam National University in Gwangju, South Korea—and his graduate students Jongpyo Jun, Jeongin Kim, and Jaehwi Seol.
The paper describes how robotics is increasingly being used to target crops once considered too delicate or variable for automation.
The researcher combined 3D machine vision, robotic arms, suction-based grippers, and rotating cutting tools to build a harvesting machine capable of operating in unstructured outdoor environments. The system aims to reduce reliance on manual labor while improving harvesting efficiency and consistency.
Verboncoeur says the developments highlighted in the papers reflect a broad transformation in how engineers view the agricultural industry.
“Agriculture used to be seen primarily as managing the challenges of planting, watering, and fertilizing plants, and using machines to make the process less labor-intensive,” he says. “Now it’s also a data problem, a communications problem, an energy problem, and a resilience problem.”
Another featured paper, “Sustainable and Smart Agriculture: A Holistic Approach,” examines how technology can address environmental and demographic pressures. The paper was written by Surender Singh and Sannihit , researchers at the computer science and engineering and the civil engineering departments at Chandigarh University, in Mohali, India.
Farmers must increase food production while reducing environmental damage from depleting water resources, overapplication of fertilizer, deforestation, and greenhouse gas emissions, the authors say. They describe smart farming as “a revolution in food production” that can allow farmers to generate higher yields from existing resources through connected technologies and data systems.
The authors highlighted the issue of rapid urbanization. By 2050, they report, nearly 70 percent of the global population will live in cities, increasing pressure on food supply chains and distribution systems.
Wireless sensor networks will play a central role in the transformation, the researchers say. The networks use small, connected devices to monitor soil moisture, temperature, humidity, light intensity, and crop conditions. The system transmits the data to cloud platforms, where machine learning models analyze trends and recommend actions.
The authors emphasize that decision support, not automation alone, drives the greatest value of crop harvest. Farmers can integrate the information into crop management strategies to improve productivity while reducing their environmental impact.
They also note increasing collaboration between industry leaders such as Caterpillar, CNH, John Deere, and Kubota and technology companies including Bosch, Google, Intel, and Microsoft. Challenges remain, however, in communication reliability, sensor cost, and scalable data infrastructure, the authors say.
The implications of the tech advances that make farming more efficient extend beyond agriculture. Many of the same technologies—remote sensing, wireless sensor networks, AI analytics, and cloud platforms—support transportation, energy, and industrial systems.
The convergence explains IEEE’s growing involvement. Modern agriculture now combines electronics, communications, computing, and control systems.
Agriculture requires that integration, Verboncoeur says: “The challenge isn’t just inventing technology. It’s making systems practical, affordable, and deployable.”
The special issue marks an early stage for the IEEE Smart Agri-Food initiative, which plans to develop standards; create structured ways for farmers, researchers, governments, and agribusinesses to work together; and devise deployment strategies for smart systems.
Future research is likely to focus on interoperability between platforms, data sharing, and scalable deployment models. Digital twins are expected to play a larger role as computing power and sensor density increase. Simulating agricultural systems before applying changes in the field will become commonplace, experts predict.
Adoption depends on more than technical capability, though. The central tension moving forward lies between innovation and practicality.
“Farmers face challenges in adopting such technology due to cost, electricity availability, communication infrastructure, and vulnerability of connected devices,” Singh and Sannihit wrote.
Smart agriculture offers improved efficiency, in addition to reducing the inputs of water, fertilizer, and time that would otherwise be spent on tasks machines can handle autonomously. But the benefits matter only if systems function reliably across diverse environments—from industrial farms to small, family-run operations in food-insecure regions.
For IEEE, agriculture now sits within core engineering domains. The stakes extend beyond technology itself, Verboncoeur says.
He adds that: “Food insecurity affects stability, health, education, and economic development. Engineering can’t solve all the world’s problems, but it absolutely has a role to play in helping the world feed itself.”
From Your Site Articles
Related Articles Around the Web


Microsoft CEO Satya Nadella published a sweeping essay on Sunday laying out what he describes as the defining economic challenge of the AI era: the risk that a handful of frontier models will absorb the expertise of entire industries and commoditize it, leaving businesses stripped of their competitive moats.
“The last thing any of us want is a world where every company across every sector is ceding value to a few models that eat everything they see,” Nadella wrote in the piece, titled “A frontier without an ecosystem is not stable,” which he posted on X. “If all the value is accrued by only a few models, the political economy will simply not tolerate it. There is no societal permission for an AI future that hollows out entire industries.”
The essay is unusually philosophical for a sitting CEO of a $3 trillion technology company. But it arrives at a moment when the theoretical risks Nadella describes are becoming tangible — and, critically, when Microsoft itself is grappling with the very dynamics he warns about.
At the center of Nadella’s essay sits a conceptual framework built on two pillars he calls “human capital” and “token capital.” Human capital, he writes, “comprises the knowledge, judgment, relationships, ingenuity, and pattern recognition of its people,” while token capital refers to “the firm’s AI capability it builds and owns.”
The two are not in tension, he insists. “Importantly, human capital does not become less valuable as token capital grows. It only becomes more valuable!” he writes. “I believe human agency will be the driver of token capital growth. Humans will set ambitious goals, connect dots across domains, build relationships, and recognize patterns that matter most. Without human direction, you have compute running in circles.”
This framing is a deliberate counterweight to the narrative that AI will simply replace human workers or, at the enterprise level, dissolve the intellectual property that differentiates one company from another. Nadella is arguing that the real danger is not AI’s capability but its tendency to centralize — and that the solution requires a fundamentally new architecture for how businesses interact with the technology.
He describes the real opportunity as “not in picking the best model but instead in building a learning loop on top of models where human capital and token capital compound.” The key test of a company’s sovereignty in this new era, he writes, is whether it can “switch out a ‘generalist’ model without losing the ‘company veteran’ expertise built into their learning system.”
This is the essay’s most actionable claim — and its most provocative. Nadella is telling enterprises they need to decouple their institutional intelligence from whatever frontier model they happen to be running, creating portable knowledge systems that survive vendor changes.
Nadella draws a pointed historical parallel to make his warning concrete. “Think about what happened in the first phase of globalization where entire industrial economies were hollowed out by outsourcing,” he writes. “The GDP numbers looked fine on the surface, but the displacement was real and the consequences are still being felt. Let us not bring that dynamic into the AI era, with a small number of AI systems capturing all the economic returns, while entire industries find their knowledge commoditized right out from underneath them.”
The globalization analogy is not accidental. It reframes the AI concentration debate from a narrow technology question into a political-economy argument — one that regulators, policymakers, and voters can grasp. By invoking the social costs of offshoring, Nadella is signaling that the stakes extend well beyond the enterprise technology stack. He is warning that if the AI industry fails to distribute value broadly, the political system will intervene to force the issue.
“In my view, our priority has to be building a frontier ecosystem, not just a frontier model, so value flows broadly across every company, every industry, and every country,” he writes. He grounds this in an older platform philosophy: “This is the ethos I’ve grown up with where platforms enable more value on top than is captured inside, and where every company can continuously innovate and build value of its own.” It is a direct echo of the Windows-era argument, updated for the age of inference — and it carries a similarly self-interested subtext, given that Microsoft’s cloud business sits squarely in that platform layer.
What makes Nadella’s essay so striking is its timing. He published it on a day when Reuters reported that Microsoft shareholders filed a proposed class-action lawsuit in Seattle federal court, accusing the company of inflating its stock price by failing to disclose slowing growth in its Azure cloud business and the need to spend billions of dollars on AI infrastructure. The suit names Nadella and Chief Financial Officer Amy Hood among the defendants.
As the Yahoo Finance report on the lawsuit noted, Microsoft allegedly “aggressively promoted its AI developments, specifically its ‘Copilot’ assistant and close financial alliance with ChatGPT creator OpenAI, to artificially boost investor optimism,” while understating infrastructure strain and capital risks. Microsoft also reported $37.5 billion of capital spending in its second quarter, up nearly 66% from a year earlier and above the $34.3 billion that analysts projected.
Microsoft’s internal cost pressures around AI have surfaced in other concrete ways this year. The company is canceling the majority of its internal Claude Code licenses in its Experiences and Devices division, effective June 30, 2026. Monthly usage rates reached 84 to 95% by April 2026, and per-engineer API costs ranged between $500 and $2,000 monthly, according to Windows Forum. The cancellation came after Microsoft exhausted portions of its annual AI budget due to token-based billing, as Fortune had reported in May.
The Claude Code episode illustrates, at the micro level, the exact dynamic Nadella describes at the macro level. When a company’s AI usage is metered by the token — the fundamental unit of compute that powers model inference — the more productive the tool becomes, the more expensive it gets. The term “token capital” in Nadella’s essay carries a double meaning: it refers both to a firm’s proprietary AI capability and, implicitly, to the actual tokens consumed in running it. Building a learning loop that compounds is aspirational. Paying the bills for that loop is operational reality.
Microsoft is not alone in this bind. Uber burned through its entire 2026 AI coding tools budget in just four months after incentivizing employees to adopt the technology through an internal leaderboard ranking teams by total AI tool usage. Uber has since instituted a monthly $1,500 cap per employee per agentic coding tool, according to TechCrunch. At Meta, an employee created a leaderboard called “Claudeonomics” to track which workers consumed the most AI tokens. Amazon, meanwhile, has pushed employees to “tokenmaxx” — use as many AI tokens as possible.
The emerging pattern is clear: enterprises adopted AI coding tools aggressively, saw genuine productivity gains, and then discovered that the consumption-based economics of frontier models created budget crises that traditional software licensing never would have. Bryan Catanzaro, vice president of applied deep learning at Nvidia, captured the tension bluntly in an interview with Axios: “For my team, the cost of compute is far beyond the costs of the employees,” he said.
These cost dynamics land differently in the context of Nadella’s essay. He prescribes a three-layer architecture — evaluation, reinforcement learning, and retrieval — designed to sit between a company’s workforce and whatever frontier model it subscribes to. Companies, he argues, need to build “private evals” that “capture whether a model is actually improving against outcomes that matter to the business (not just external benchmarks!),” alongside “private reinforcement learning environments” that “let models grow stronger on real traces from inside the organization” and a knowledge base that “makes institutional memory queryable and use of tokens more efficient.” He calls the resulting system “a hill climbing machine” that, “unlike most assets, it compounds.”
Nadella’s concerns do not exist in isolation. Other technology leaders have been raising similar warnings throughout 2026, though none have offered as prescriptive a response.
Snowflake CEO Sridhar Ramaswamy warned in a February podcast that the biggest software companies risk being reduced to mere data sources. “The big model makers want to create a world in which all of the data for all of the enterprises is easily available to them,” Ramaswamy said, describing everything else as “a dumb data pipe that feeds into that big brain.” He added that Snowflake needs to operate with a “fear” that enterprises would abandon software-specific AI agents in favor of all-inclusive agents that hoover up data from everywhere.
Box CEO Aaron Levie struck a similar note in a January LinkedIn post. AI models can now perform high-level knowledge work across nearly every profession, from law to strategy to scientific research, he argued. “The question that we will have to wrestle with is, in a world where everyone has access to the same expert intelligence, how does a company differentiate?” he wrote.
The combined effect of these statements is a shared diagnosis from three very different corners of the enterprise technology market: the current trajectory of AI development threatens to collapse competitive differentiation across entire industries. Nadella’s essay stands apart from the others because it moves beyond diagnosis and proposes a specific architectural remedy. But the prescription is impossible to separate from the prescriber’s interests.
Microsoft sits in precisely the platform layer that Nadella’s framework would make indispensable — the company builds its own frontier models, operates the cloud infrastructure those models run on, and maintains deep partnerships with the leading independent AI labs. A world in which every enterprise builds a proprietary learning loop on top of commodity foundation models is, conveniently, a world in which Microsoft sells the picks and shovels to all of them.
The essay also arrives just ten days after Nadella publicly rebuked one of his own executives for outlining a plan to “make people addicted” to a new AI tool called Scout.. Microsoft corporate vice president Omar Shahine had written an internal memo describing a three-phase plan to transform Scout “from addictive app to agentic platform,” with the first phase focused on features that “make people depend on it daily.” Nadella responded on an internal message board: “This is absolutely a non-goal! If anything we are doing the exact opposite. We want to make sure AI empowers and adds real value to human endeavor and broad economic growth!”
The Scout incident and Sunday’s essay together suggest Nadella is actively constructing a public philosophy of AI that emphasizes broad value creation over extractive engagement — whether or not every corner of Microsoft has internalized that message. One anonymous Microsoft employee told 404 Media, as the Post reported, that the leaked Scout document was “very troubling,” adding: “It feels like one of those ‘saying the quiet part out loud’ moments.”
For technical decision-makers evaluating Nadella’s essay, the practical implications are significant. He is arguing that choosing an AI model matters less than building the learning infrastructure around it. He is arguing that the ability to swap models without losing institutional intelligence is the critical test of AI sovereignty. And he is warning that companies that fail to build these systems will find their expertise absorbed and commoditized by the models themselves. “You can offload a task, or even a job, but you can never offload your learning,” Nadella writes. “The future of the firm is the ability to compound that learning across people and AI.”
Whether Nadella’s vision materializes depends on a question his essay carefully sidesteps: whether the platform providers who build and host the frontier ecosystem will resist the temptation to capture the value flowing through it. Nadella insists that “platforms enable more value on top than is captured inside.” But Microsoft’s own trajectory this year — the ballooning capital expenditures, the Claude Code budget crisis, the shareholder lawsuit alleging concealed costs, the internal memo about making users addicted — suggests the economics of restraint are harder than the philosophy of restraint.
Nadella ends his essay with the claim that broad value distribution “is the stable equilibrium we should build together.” He may be right. Ecosystems have historically outperformed walled gardens over long time horizons. But stable equilibria require every major player to forgo short-term extraction in favor of long-term compounding — and right now, the AI industry is burning through budgets in four months and spending 66% more on infrastructure than analysts expected. The CEO of the world’s most valuable technology company has written an eloquent argument for why the AI economy needs to work differently. The open question is whether his own company’s balance sheet will let him prove it.

Two school days. That’s all it took.
In 2024, I chaperoned field trips two days in a row, for two different grade levels, and came back to roughly 450 ungraded assignments.
I knew what to do, I’ve done it before, mark them credit or no credit and move on. Students get something out of that. They did the practice. But if any of them were practicing it wrong, nobody catches it, nobody tells them, and the misunderstanding rides along into the next unit.
That pile of work led me to build an AI grading assistant. And this past April, I removed its most automated feature: the one that could return an AI-generated grade and comment to a student before I had reviewed it.
Building that feature was easy to justify. Removing it taught me which part of grading a teacher can’t hand off.
Most of what students turn in to me isn’t a clean essay. I teach engineering, and my students submit designs, schematics, code, and photos of physical work. That’s part of why many teachers I know still don’t grade with AI. They’ll use it to scaffold a unit or soften an email to a parent, but grading with it usually means pasting work into a chatbot one assignment at a time, which is so slow I can grade it faster myself. So, I built my own tool.
I teach mechatronics, and if mechatronics teaches you anything, it’s that efficiency matters. You optimize the system and eliminate friction. I brought that mindset to the product I built, and the logical endpoint was auto-return. The AI could evaluate the work, draft the grade and comment, and send it back to the student without another click from me, late submissions included. I had spent hours tuning it to grade against my assignment, handouts, instructions, and rubric.
Then a student came up to me one day, happy about the encouraging comment on an assignment. The comment had motivated him to redo the work and resubmit it.
When AI Takes Control
The problem was that I didn’t write the comment. I hadn’t even seen it.
If it had passed by my eyes and I’d confirmed it, edited it, or decided it belonged there, this would be a different story. But in that moment, the student thought the encouragement came from me, and I wasn’t actually in the exchange.
Nothing about the feedback was inaccurate. That almost made it harder to explain. After more than two decades in a classroom, I couldn’t put words to what felt wrong. I just knew it did. The issue wasn’t whether AI could draft useful feedback. It could. The issue was whether a student should receive a teacher’s judgment when the teacher hadn’t made one.
So, I removed auto-return, and the automatic grading of late work went with it. What replaced it is a review dashboard: the AI drafts every grade and comment against my rubric and lays it out in front of me. I can edit, override, reject, or return the feedback in one pass. It’s still fast. But now my eyes and my judgment touch every grade before a student sees it.
That changed how I think about human review. It can’t mean glancing at a score and clicking approve. It must mean checking the student’s work against the rubric and owning the result.
The software can propose a judgment. It cannot own one.
Policy is starting to move the same way. New York City’s public school guidance now says AI must not replace educator decision-making, and other states are weighing rules on human review and student data. The rules will keep changing. The principle shouldn’t; a student’s grade needs a person who is accountable for it.
When I walked one of my administrators through the tool, what he liked most wasn’t the time savings. It was that it requires a rubric. Teachers write rubrics for big projects, but the daily, low stakes work rarely gets one, and that’s exactly the work that gets marked credit or no credit and never comes back with feedback. The trade runs both ways: students get clearer expectations up front and comments on work that used to get a checkmark.
He had two concerns, both fair. Parents and students should know when an AI-assisted tool is grading, so it belongs in the syllabus. And if a student contests a grade, the teacher should re-grade it by hand. We agreed the second should happen anyway, with or without AI. Humans make grading mistakes too.
My students know I built the AI tool. What they care about isn’t the technology. It’s whether the feedback is fast, the rubric is clear, and the grade is fair. A few times the tool has docked points for work it missed, almost always because a screenshot cut off the edge of the page or the writing was too faint to read. Those students came up to me, I looked at the work, and I gave the points back. I want that. A grade should be something a student can question.
What surprised me is that a student will challenge the AI long before he’ll challenge me. A kid will walk right up and say, “The AI got this wrong, I should have full credit.” That same kid won’t tell me, to my face, that I made the mistake and owe him ten points. Both of us can be wrong, but the machine is easier to push back on than the teacher, and that’s good for the student. The grade still passes through me. The draft between us just makes it easier to speak up. If a grading system makes students afraid to challenge the result, the system is wrong.
AI Grading Advice
If your school is wrestling with AI grading, start with the disclosure. Don’t say “AI may be used.” Say what that means: comments and grades are drafted by AI and reviewed by the teacher. Then answer the harder questions. Where does student work go? Is it stored, or used to train models? How secure is the platform, and has anyone independent reviewed it?
We are teachers, not graders. We grade, yes, but we also sit in IEP meetings, call parents, design lessons, and try to notice the student who is quieter than usual. If a grading assistant hands me back the hours I spent marking daily work, and I spend them on better lessons and better feedback, everyone wins.
But when a student asks, “Why did I get this grade?” the answer cannot be, “Because the system said so.”
It has to come from me.
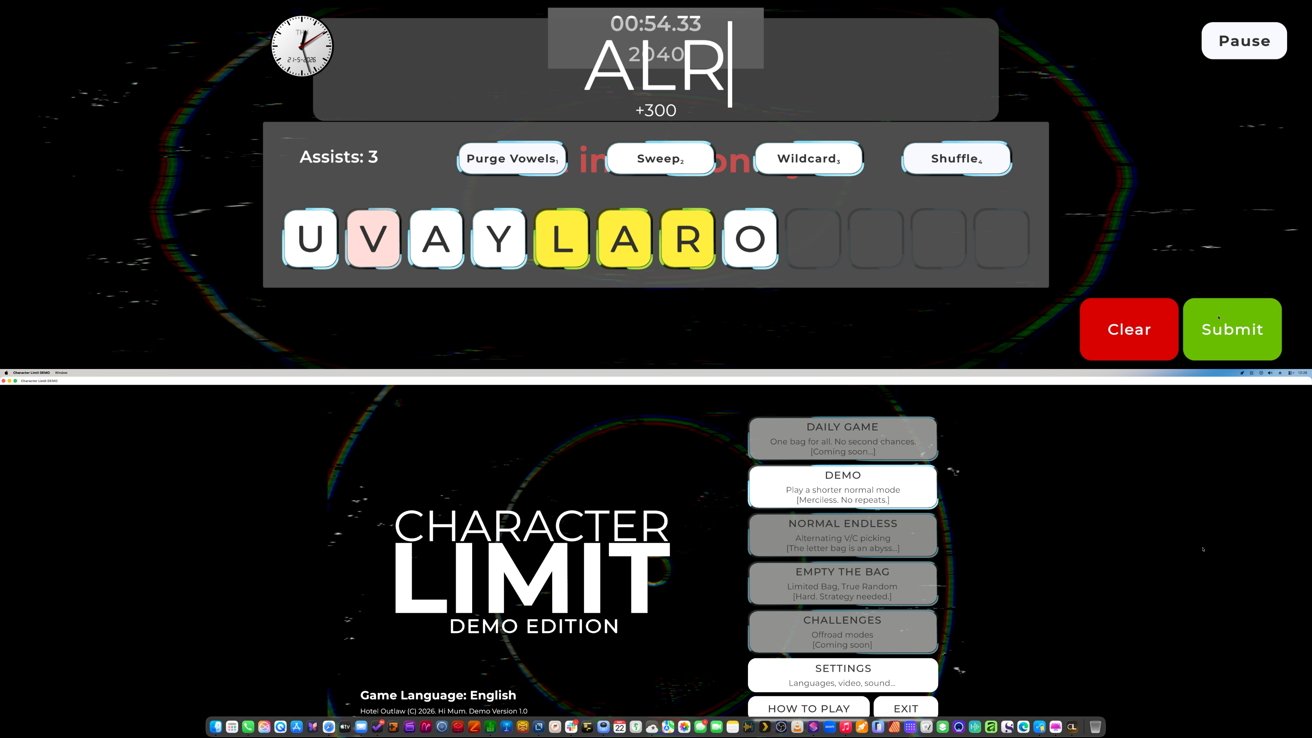
I slipped under the wire and got a demo of “Character Limit” submitted to Steam just in time. Now for the stressful part: It’s live in Steam Next Fest.
In April, the development of Character Limit had reached a point where it could be tested by actual players. It did fantastically well at Dreamhack Birmingham, and I had also started doing testing on iPhone and iPad with Testflight.
However, later that month, registration for something known as Steam Next Fest was coming to a close. It’s a promotional festival held a few times a year, focused on getting players to try out demos for games that have yet to be released.
Since I want the game to be completed long before the busy fall iPhone season, that meant the next Next Fest I could take part in was in the middle of June. I figured there was plenty of time to get the Dreamhack demo to a better and more robust state, so it could be downloaded to players’ computers to try out.
But, since WWDC was also happening the week before Next Fest, that meant I would face a busy time here at AppleInsider, which would impact any development.
So, the decision was made to leave the Testflight build ticking along on iPhone, and to return to it when the game is in a much better place. Instead, I allocated my time to focus just on the Mac and PC demo.
It was both a very good and very stupid decision.
Getting the demo working as perfectly as possible for Next Fest wasn’t just to ensure the game got more promotion through a major digital storefront. It also forced me into shoring up the demo so it could be used by the actual public.
So far, the game was made with my hardware and setups in mind. To make it work for practically any player in the world, I had to make sure anything that would break or be an edge case was handled gracefully, since any combination of hardware would be thrown at it.
Cue a few weeks of fixing bugs in number distribution, making an actual tutorial screen, and localization foibles that I had missed before.
It was then sent to some colleagues and friends for testing. And I’m glad that I did.

An edge case I didn’t consider, and the fix. Image credit: William Gallagher
William Gallagher of this very site tried the game demo out. Partly because I had to work out how Xcode notarization worked, which was tricky but not difficult.
It turns out that William has an insane display ratio because he uses an ultrawide screen. Due to the way the game functioned, playing full-screen meant you missed the bottom and top sections of the interface.
For a word game, it helps if you can see the letters you’re turning into words. Or even just see the Quit button on the main menu.
This was fixed quickly by making a floating section of the interface that was the correct aspect ratio, that would be visible in the middle of the screen when viewed by an ultrawide. All the content of the game would then be put into that box, similarly anchored to the center.
This worked surprisingly well and was practically the last stumbling block for the demo itself.
While not everything has been fixed, it’s just got enough “done” to be usable as a proper demo.
As a consequence, I have many changes to transfer from the demo into the full game. It’s work I would’ve had to do anyway before release, so doing it all now rather than later was a good move.
While making the game and working with Apple’s Notarization system is one battle, Steam is quite another.
The tricky process of setting up a Steam page for the game has already been done. While you can set up a separate store page for a demo, you could also just add the demo download button to the main sales page.
There are reasons to go either way, but I went with the one main sales page approach. Partly because it would focus traffic onto that one page, partly from laziness.
However, for some reason, Steam requires you to submit effectively everything you would need for the separate store page for the demo, even if it doesn’t exist. That includes the text for the page, which I had to write.
Other elements make sense, like platform specifications, capsule art images, and the name, since they would be used elsewhere.
Then it came time to upload the demo, which led to a multitude of problems.
The first issue was administrative, as I previously had to transfer the game from one Steamworks account to another, due to having signed up wrongly to begin with.
A personal account and one owned by a limited company differ in many ways, which meant a second account had to be made and the store listing transferred over.
It turns out that you can transfer the game as one listing, but the demo is a separate listing and doesn’t necessarily get transferred over with the main title. I spent so long failing at uploading the demo because of this missing element, and then I had to wait most of a week for it to transfer.

There’s a graphical SteamPipe interface for Windows, but you’re stuck with the Terminal on macOS for some reason…
The second problem is Steam’s uploading system. There is an option to do so from the website, but there’s no documentation explaining how to use it properly, so it was a no-go.
The usual way is a SteamPipe upload, using the Steam SDK. This is a process that involves a ton of work, including installing a command-line version of Steam, constructing a build and an upload script, and then setting the launch options.
I understand fully that this is a system designed more for the big developers with massive teams and people who truly know what they’re doing. For a first-time indie, this is massively intimidating.
That is, until you realize that the SDK download includes a graphical interface that does a lot of the heavy lifting for you. Except it’s Windows-only and not available on the Mac.
I had a Windows PC nearby, so it wasn’t a difficult procedure. But it is disheartening that there’s not a macOS graphical interface available from Valve.
After getting the game demo uploaded, both it and the store details were submitted for review. The demo was apparently fine and dandy, but the store section was not.
Apparently, while you’re encouraged to make the images of the capsule art be different so that players can tell the demo apart from the main game, you also cannot add more words to the art other than your game name.
They objected to me using the words “Demo Edition” in the art. Also, my logo was being covered by a demo corner banner that wasn’t really mentioned previously.
Sure, my mistake for not fully understanding. It meant some tweaks and a few more days of waiting for a re-review and eventually being accepted.
On June 9, the second day of WWDC, Steam’s email confirmed that the store page met its requirements, and that the demo could be published. That evening, Character Limit became available to play in demo form on Steam.
I have written before about how Steam is a big deal for me. As a gamer with a Steam account value that could buy a reasonably priced car at current prices, I am very familiar with Steam,a nd have used it for many, many years.
Registering and having a Steam listing for something that I made was an emotional experience. Just that hit hard.
I didn’t expect putting the demo live to hit even harder.
I can now open my Steam library on my Mac and see “Character Limit Demo” on the long list of (mostly unplayed) games. I can now click it and open the game on my Mac or my PC.
Seeing it on there did actually make me weep a little bit. A stupid little game that I have been noodling on for most of a year is now in an application I regularly open up.

Seeing the demo in Steam was a big deal.
It’s probably a feeling that authors get when they see their work on Amazon or in their local bookstore. Except it’s a game and I can’t walk into a physical location and hold the game in amazement.
After walking around the block for some air, I checked it ran OK, and it does.
This was an extremely big and happy moment for me. But it was cut short with the daunting realization that this isn’t the finish line.
The rest of the game has to be put into place for the final version. Research into more languages and modes for future updates, too.
Then there’s the ever-continuing slog of marketing and promotion before the game’s release. That’s an inevitability.
But, more immediately, there’s the fear that the demo will not be well received by anyone. The last thing anyone creating anything needs is for people to complain about your baby, even if it’s entirely justified.
Writing on the Internet for over a decade certainly gives you a thick skin for criticism of your words. But this is a level of apprehension and worry that I’ve not had to deal with in a very long time.
That’s not even taking into account the eventual battle to get the finished product in the App Store. That’s next.
Here’s hoping Gabe Newell’s money-generator audience is somewhat kind during this week’s all-important Steam Next Fest.


Xbox is preparing to shut down or sell at least three of its studios — Double Fine, Ninja Theory and Compulsion Games — according to reports from The Verge and Bloomberg on Monday.
Ninja Theory employees were informed on Monday that the studio would be closing, according to The Verge, but the team is attempting to find a buyer that can keep them operational. Ninja Theory is the studio behind the Hellblade series and it was featured in the recent Xbox Summer Game Fest showcase, revealing a new entry due in 2027.
Double Fine is the legendary studio behind the Psychonauts games, Brütal Legend, Broken Age, Keeper and all manner of LucasArts adventures, founded by Tim Schafer and friends in 2000. Double Fine leaders are in active negotiations to buy themselves back from Xbox rather than be closed altogether, Bloomberg said.
Compulsion Games is in a similar position, according to the report. Compulsion is the Montreal studio behind the uber-stylish games Contrast, We Happy Few and South of Midnight, the latter of which came out in April 2025.
Bloomberg reported that several other studios under the Xbox Game Studios banner are also negotiating for their futures and are at risk of being shut down. As it officially stands, the Xbox Game Studios umbrella covers dozens of studios, including Arkane, Bethesda, Halo Studios, id Software, Obsidian, Playground Games, ZeniMax and Activision Blizzard King. We have contacted Xbox for clarification on the reported closures and buyout talks.
Microsoft’s modern game-studio acquiring spree kicked off in 2018 with the purchase of Undead Labs, Playground Games, Ninja Theory and Compulsion Games, plus the formation of The Initiative. This momentum continued building at a concerning pace in 2020 and 2021, when Xbox acquired eight more studios under ZeniMax Media, including Arkane, Bethesda and id. Everything came to a head in 2022 with the announcement that Xbox planned to purchase Activision Blizzard for $69 billion, the largest acquisition in video game history. That deal finally went through at the end of 2023, after a lengthy battle with regulators.
Since the acquisitions, Microsoft has enacted multiple massive rounds of layoffs affecting thousands of employees in its gaming division, and also shuttered well-known studios, including The Initiative. Unfortunately, Double Fine, Ninja Theory, Compulsion and the other at-risk Xbox studios are in good company.
Longtime Xbox division head Phil Spencer stepped down this year and was replaced by new CEO Asha Sharma, alongside other executive-level changes. Also on Monday, Xbox Game Studios head Craig Duncan left the company; he first took the role in October 2024. Employees across Xbox are bracing for more layoffs in 2026 after an ominous public memo from Sharma dropped in mid-June, just as the glow of Summer Game Fest fully faded.




No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw


Oppenheimer backs SpaceX as $70 billion retail frenzy builds

Markets Rally as SpaceX IPO Looms Amid Iran Tensions and Inflation Surge


Weekend Open Thread: Tuckernuck – Corporette.com

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


The Ryan Gosling True Crime Thriller On Netflix That Gets Even Stranger, Stream It Now


NanoClaw integrates JFrog registries to secure AI agent downloads

Bangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News


Bitget enters Argentina’s regulated crypto market through PSAV registration


This Week In Security: Microsoft On Microsoft, Register Your Domains, Linux On ARM, And FreeBSD Joins The File Cache Club
Dutton Ranch star claims they ‘didn’t see any disruption’ on set following Chad Feehan’s exit from Yellowstone spinoff fueled by Taylor Sheridan clash rumors


El Nino has formed in the Pacific and could set records, forecasters say


Politics Home | Healey Resignation Is “Colossal Failure Of Government”, Says Former Labour Defence Secretary


Thailand Ranks Second Worldwide for AI Adoption Growth, Microsoft Reports

Donnie Wahlberg & More Heat Up Las Vegas at Circa’s Barry’s Downtown Prime


First Time Since 1971: Australia Register Historic Low In ODI Cricket

Opendoor Ends India Operations, Fueling a Bigger Conversation About AI and Outsourcing


Belfast burns, while Met chief points finger at Iran and Russia


FBI searches office of Ohio voter registration group


AT&T: Verizon's 27% Outperformance Sets Up A Solid Entry Point






You must be logged in to post a comment Login