

Tech
Resolve AI says the AI coding boom is breaking production systems. It wants to fix that.


Resolve AI, the production-operations startup backed by Greylock and Lightspeed Venture Partners, today announced a sweeping expansion of its platform that introduces always-on background agents, a redesigned investigation architecture, and a shared workspace where engineers and AI agents collaborate in real time on live incidents.
The centerpiece of the release is a new multi-agent investigation system developed by Resolve AI’s in-house research lab. Instead of deploying a single AI agent to diagnose a production failure — analogous to a lone engineer pulling an on-call shift — the platform now dispatches a coordinated team of specialized agents that pursue multiple hypotheses in parallel, independently verify each other’s conclusions, and construct complete causal chains from root cause to symptom. The company says the architecture delivers more than a twofold improvement in root cause accuracy on its internal evaluation benchmarks compared to earlier versions of its platform.
“Think of a single agent being on call, the way a human would be,” Resolve AI CEO and co-founder Spiros Xanthos told VentureBeat in an exclusive interview ahead of the announcement. “We now have a team of agents that all work together, almost like a team of humans debugging an issue, and that has improved quality by 2x.”
The announcement arrives at a moment of acute tension in the software industry. AI-powered code generation has exploded in adoption, enabling engineering teams to ship dramatically more software than they could two years ago. But keeping that software running in production — debugging it when it breaks, monitoring it after deployment, auditing its health — remains overwhelmingly manual. For a company that raised a $125 million Series A at a $1 billion valuation earlier this year, Resolve AI is making a direct bet that the operational side of the software lifecycle is the next major frontier for AI investment.
What hundreds of real-world test cases reveal about the accuracy claim
Any accuracy claim from a startup warrants scrutiny, and Xanthos was candid about both the scale and limitations of the evaluation. The 2x figure comes from internal benchmarks, not a third-party audit, though the evaluation set was built to mirror the complexity that Resolve AI’s enterprise customers encounter daily.
“These are very hard, complex evals that we built over time to represent real-world examples,” Xanthos explained. “This is not customer data, but these evals represent difficult cases similar to what we’ve seen at some of the largest tech companies we work with.” He described the set as comprising hundreds of cases that reflect the kinds of production failures encountered at companies like Coinbase, Salesforce, DoorDash, and Zscaler — all named Resolve AI customers.
The practical impact of that accuracy gain is significant. Resolve AI’s agents now act as first responders for every on-call alert, typically triaging within five minutes before a human engineer even becomes involved. In previous public disclosures, the company has cited DoorDash reducing time to root cause by up to 87 percent. When asked to contextualize that figure, Xanthos described the typical baseline.
“When something goes wrong, it might take five to 10 minutes for a human to even get their laptop and connect,” he said. “The typical MTTR is in the tens of minutes, sometimes hours, depending on severity. So an improvement of 80-plus percent — four to five times faster — is actually huge. It’s something we’ve never achieved before with AI, tools, data, or observability.”
How AI agents fact-check each other to prevent hallucinated root causes
One of the core challenges in applying large language models to high-stakes production environments is their tendency to generate plausible-sounding but incorrect answers — a failure mode that, in the context of a live outage, could send an engineering team chasing the wrong fix while a service stays down.
Xanthos acknowledged this directly. “This is a very common issue with models out of the box,” he said. “They always try to give you an answer, and if they don’t have enough evidence, they’ll give you the best possible answer — which is likely to be wrong.”
Resolve AI’s countermeasure is a system of layered verification among its agents. Each agent investigating a hypothesis must cite every piece of evidence it relies on and present that evidence to another agent for independent review. The investigating agent must construct the full causal chain — from root cause to symptom — and peer agents actively attempt to disprove the theory by identifying gaps in the logic.
“Often, agents actually disprove those theories because they find gaps,” Xanthos said. “There are many layers of defense and agentic checks that allow Resolve to be very accurate and not mislead.”
Equally important, he said, is the system’s willingness to say it does not know. “The bar to actually saying ‘I have the answer’ is very high. In those cases, it will say, ‘This is the evidence I found. Here are three or four paths you can take from here, but I wasn’t able to fully prove that this is the problem.’ A system like this that operates in production cannot be a black box.” In domains where wrong answers carry operational consequences, calibrated uncertainty can be more valuable than confident outputs. For an AI system integrated into an incident-response workflow, confidently pointing engineers in the wrong direction during a customer-facing outage could compound the very harm it was designed to prevent.
Inside the new background agents that never go off-call
Beyond incident response, Resolve AI is introducing a new class of background agents designed to handle the continuous, often invisible operational work that engineering teams are expected to perform but struggle to sustain at scale.
These agents run on schedules or wake automatically in response to events — a new deployment, a fired alert, a merged pull request — and accumulate institutional knowledge from every investigation and human interaction over time. When an engineer opens the Resolve AI interface, agents have already been working: pre-investigating priority issues, monitoring deployments, auditing alert hygiene, flagging configuration drift, and surfacing cost anomalies.
Xanthos drew a distinction between background agents and the incident-response agents that have been Resolve AI’s primary offering. “You can now have these agents run in the background at all times — not only when a human asks an agent to debug a problem or when an alert fires,” he said. “A lot of our customers are now monitoring changes that land in production before they cause an issue. There’s an agent that monitors those all the time.”
He described these background agents as “general-purpose SRE agents that are available to every developer,” capable of handling tasks that range from monitoring infrastructure changes that might increase cloud costs to performing post-incident follow-up work like generating code fixes based on incident learnings. The concept addresses a structural problem in software operations: the daily tasks required to keep production systems healthy — monitoring deployments, investigating alerts, tracking changes across complex environments — are critical but reactive and manual. Engineering organizations know this work needs to happen, but it competes for attention with feature development. Automated agents that perform this work continuously could shift teams from reactive firefighting to proactive operational management.
The shared workspace where engineers and AI agents investigate together
The third major component of the release is what the company calls a shared investigation surface — a workspace where engineers and AI agents work from the same live evidence during an active incident. Reports update dynamically as investigations evolve. Every finding is inspectable. Engineers can explore side investigations without interrupting the primary workflow. Source queries are pullable and modifiable in place, evidence is embedded directly into the workspace, and remediation actions can be triggered from the same interface without switching tools.
“Think of it as an interface to all the production tools, but also an interface where humans and agents can collaborate with each other — or agents with agents,” Xanthos said. “That’s what gradually leads to more trust and more automation, because you work with the agent, you teach it, you see the results.”
The company is also making its platform available as a REST API and an MCP (Model Context Protocol) server, enabling engineering teams to integrate Resolve AI into broader agentic workflows and infrastructure. According to Xanthos, this is already happening in practice. “A general-purpose agent that a company has built — when it comes to debugging, that agent could invoke Resolve,” he said. “Or somebody works on their coding agent on the laptop, and Resolve shows up there as an MCP. If there is some production-related activity, the coding agent can invoke it.” The interoperability play signals that Resolve AI sees itself not as a closed system but as a specialized node in a broader ecosystem of AI agents that will increasingly hand off tasks to one another — a pattern Xanthos compared to the open architecture of the web rather than the walled-garden model of an app store.
Why Resolve AI says it can outperform Datadog, PagerDuty, and the cloud giants
The agentic operations space has become crowded in the past year. Datadog, PagerDuty, and major cloud providers have all announced AI-augmented operations capabilities. When asked what separates Resolve AI from these incumbents, Xanthos pointed to the depth of the company’s technical foundation.
“We’re operating at the frontier here. There’s no blueprint for how you build a system like Resolve,” he said. He noted that he and co-founder Mayank Agarwal co-created OpenTelemetry, the most widely adopted open-source project in observability, which now serves as the de facto standard for collecting metrics, logs, and traces from modern software systems.
Xanthos also highlighted the company’s recent AI Lab, led by a researcher he described as the former post-training lead for Meta’s Llama models. “He managed to combine deep expertise of production observability with AI and models, and I think that’s very unique,” Xanthos said. “I don’t believe any other company, whether it comes from an observability background or it’s a startup, has all of that together.”
The company’s structural defenses, according to Xanthos, include a full environment model that Resolve builds for each customer, a memory system that learns within the customer’s specific production environment, and its multi-agent architecture. The lab is now post-training frontier models on production-specific data — the kind of procedural knowledge that experienced engineers use to debug production issues but that does not appear in standard model training sets. This approach reflects an increasingly common pattern among AI application companies: using frontier foundation models as a base layer but investing heavily in domain-specific fine-tuning, retrieval, and agent architectures to achieve accuracy levels that general-purpose models cannot reach alone.
How outcome-based pricing changes the economics of AI in production
Resolve AI’s pricing model departs from traditional enterprise software licensing. The company sells credits that are consumed when agents perform work — an outcome-based approach that ties cost directly to value delivered.
“We’re not selling software,” Xanthos said. “The way you buy and use Resolve is by buying credits that are consumed when Resolve performs an action. It’s outcome-based. Only when Resolve troubleshoots an alert — that’s the only time that it consumes credits.”
He addressed the cost question head-on, arguing that Resolve AI is actually cheaper than the alternative of building a similar system from scratch using frontier models and MCP integrations. “If you were to take Opus or GPT-5.4 and try to build a solution like Resolve with MCPs, we measured — you actually end up consuming a lot more in tokens than what you have to pay Resolve, because our system is very optimized in terms of context, in terms of how it reads time-series data.”
As for the always-on background agents, Xanthos said their continuous nature does not inherently add to cost. “The background agent doesn’t mean it does intensive work all the time. It means that it can be there; you can give it any task you want. A lot of these tasks are triggered based on some action — an alert happens, somebody merges a PR, and you want to see if it has an impact on production.” For enterprise customers in regulated industries — the Coinbases and Zscalers of the world — data residency and security are non-negotiable. Resolve AI accommodates this with a flexible deployment model: the data plane sits wherever the customer’s existing tools already live, while the inference layer can run as a standard SaaS deployment or inside a customer-specific VPC. “We designed Resolve to work with the large enterprises where security standards are the highest,” Xanthos said. “There are many measures we take to ensure Resolve is secure, including not retaining data.”
Why engineering leaders are slowly learning to trust AI agents with production systems
The question of whether engineering teams will trust AI agents to take autonomous action in production — rolling back a deployment, adding capacity, generating a pull request — is one of the defining cultural challenges of this technology wave. Xanthos drew an analogy to autonomous vehicles.
“For us to allow a car to drive on its own on the street, we have to prove that it’s safer than a human. Agents in production is a very similar concept,” he said. He acknowledged that not every customer is comfortable with agents taking automated action, but described a gradient of trust that he expects to evolve rapidly.
“There is a set of actions that are relatively risk-free that most tech companies probably are comfortable having an agent take, and probably there is another set of actions for which the human has to approve,” he said. “But as quality keeps climbing the way we see at Resolve, I would say we’re going to cross the threshold this year where most of the actions will be taken by an agent automatically.”
He described the typical adoption arc: companies begin with agents providing recommendations, then a human decides whether to press the button. Over weeks or months, trust builds incrementally. “I don’t think this is a problem where we just let the agents run wild from the beginning,” Xanthos said. The incremental approach mirrors how enterprise technology adoption has always worked — from cloud migration to container orchestration, organizations move at the speed of trust, not the speed of capability.
The argument that AI-generated code is making the production crisis worse, not better
Perhaps the most provocative argument in Resolve AI’s thesis is that the explosion of AI-generated code is actually intensifying the production-operations problem. In a recent LinkedIn post, Xanthos framed the dynamic in stark terms, arguing that engineering leaders who celebrate faster code shipping without investing in production operations are effectively having their senior engineers “subsidize velocity” through increased incident-response burden.
In his interview with VentureBeat, he returned to this theme. “Now that coding agents are producing code, we produce a lot more code that we’re less familiar with — humans are less familiar with — so you need the AI to be the defense,” he said.
This framing positions Resolve AI not merely as a productivity tool but as a necessary counterweight to the AI coding revolution. As organizations deploy more code, written by tools that their engineers may not fully understand, running against production systems those engineers did not build, the argument is that the operational complexity — and the consequences of failure — will grow proportionally. On the Stack Overflow Podcast last October, Xanthos put numbers to this claim, estimating that engineers spend upwards of 70 percent of their time maintaining and troubleshooting production systems rather than building new features. “We’re facing a new crisis where we’re building faster than we can operate,” he said in that conversation.
Resolve AI was founded in early 2024 by Xanthos and Agarwal, who first met during their PhD programs at the University of Illinois and have worked together for more than a decade. Xanthos previously co-founded Pattern Insight (acquired by VMware) and Omnition (acquired by Splunk), where the pair helped create OpenTelemetry. The company raised a $35 million seed round from Greylock in 2024, followed by the $125 million Series A led by Lightspeed at a $1 billion valuation earlier this year. Named customers include Coinbase, DoorDash, MSCI, Salesforce, MongoDB, and Zscaler.
Xanthos’s long-term vision is expansive. “Over the long run, once agent ability surpasses that of a human software engineer, the end result is a lot more technology and a lot more software,” he said. “It’s not actually fewer people working on it. It’s technology becoming cheaper, becoming more accessible, producing a lot more technology for the benefit of the world.”
That vision will take years to realize. But the more immediate promise of today’s announcement comes down to something every on-call engineer understands viscerally: the 2 a.m. page, the scramble for a laptop, the frantic search through dashboards and logs for an answer that might take minutes or might take hours. Resolve AI is betting that the next time that alert fires, a team of agents will have already investigated, verified, and documented the root cause before the engineer’s phone even lights up. For a profession that has long measured its nights by mean time to resolution, the question is no longer whether AI can help — it is whether engineers will let it.


Most of us spend more time wearing headphones or earbuds than we realize, and I know I do. Between shuffling playlists during my daily commute, jumping on work calls, listening to podcasts while walking around the neighborhood, and winding down with a late-night binge session, audio has quietly become an essential part of everyday life.
Our listening needs, however, change throughout the day. The over-ear headphones I want for a long workday are not necessarily the same audio wearable I reach for when stepping outside. Yet many audio brands seem determined to convince us that a single expensive product is the ultimate solution.
In an era where new wireless gear launches every other week at eye-watering price tags, finding tech that genuinely balances comfort, performance, and value can feel like a challenge. That is exactly what drew me to JLab. Rather than relying on exclusivity or celebrity endorsements, the brand has built its reputation on creating practical tech designed for real people and real-world routines.
This approach is incredibly refreshing. By delivering high-tier features at an accessible price point, JLab leaves a lasting impression and emerges as a compelling choice for buyers. You don’t have to nuke your wallet to enjoy great sound in your everyday life. That idea has been distilled to the very core of two products in particular — the JBuds Lux ANC Wireless Headphones and the Epic Pods ANC True Wireless Earbuds.
JBuds Lux ANC For the Moments You Need to Lock In

There are times when I want to tune everything else out. Whether I am trying to focus on work in a buzzing cafe, settling into a long flight, or simply listening to a new album without distractions, there are times when noise isolation is as important as the raw depth of tunes blasting into your ear canals. This is where over-ear headphones often come to the rescue, offering a level of immersion that earbuds cannot quite match. The JBuds Lux ANC Wireless Headphones embody that scenario, and they have been accordingly designed to make those moments feel even more effortless.
Featuring Smart Active Noise Cancelling, they help reduce background distractions so you can stay focused on your music, podcasts, movies, or work calls rather than what is happening around you. The convenience extends beyond the bliss of noise cancellation. Bluetooth Multipoint connectivity allows you to stay connected to both your laptop and phone at the same time. You can seamlessly switch from a Zoom call on your computer to a playlist on your phone without ever needing to re-pair your devices.
That same focus on practicality carries over to the per-charge battery mileage, as well. With more than 70 hours of playtime, these headphones are built to keep pace with packed schedules, extended travel, and marathon listening sessions without the need for frequent recharging.
Just as important as battery life is how the headphones feel after hours of use. The over-ear design and Cloud Foam cushions are made for extended wear, making them an easy companion for long workdays, study sessions, and travel. Heading into the JLab App, users can also fine-tune their sound settings to match their listening preferences, helping ensure every playlist, podcast, and movie sounds just the way they like it.
Epic Pods ANC For the Moments You Are On the Move

Of course, life does not always happen at a desk. Some days are a constant cycle of commuting, unexpected errands, out-of-schedule workouts, and quick transitions between one activity and the next. Those are the moments when portability becomes just as important as performance.
The Epic Pods ANC True Wireless Earbuds are designed for the aforesaid kind of on-the-go lifestyle. Built for people who are constantly moving, they pack an impressive amount of technology into a compact form factor. Instead of relying on a single driver to do all the work, their hybrid dual-driver system handles audio output with a level of depth and clarity that is hard to find in this segment. A 10mm dynamic driver handles deep bass, while a specialized Knowles Balanced Armature focuses on crisp mids and clear highs. The result is a balanced listening experience where vocals and instruments remain clear without getting overshadowed by the low end.
If great sound matters to you, support for LDAC on Android and AAC on iOS ensures that your music comes through with greater detail, clarity, and depth, especially when streaming high-quality audio. The Epic Pods ANC also feature Adaptive Active Noise Cancelling that goes beyond simply switching on and off. From crowded subway commutes to quieter streets, the earbuds adjust noise cancellation on the fly, helping maintain the right balance between immersion and awareness without you having to tap a button.
But impressive audio performance means little if your earbuds cannot keep up with your active lifestyle. With more than 56 hours of total playtime and a quick charge feature that delivers up to 5 hours of listening from just a 10-minute charge, the earbuds are built to keep up with even the busiest schedules.
The Epic Pods ANC are designed with everyday use in mind. The secure fit design helps keep them comfortably in place during intense workouts, while IP55-tier ingress protection provides added protection against sweat and dust exposure. Bluetooth Multipoint further adds even more convenience by allowing seamless switching between multiple connected devices.
Why Get Personal Tech That Adapts With You
The biggest shift happening in personal audio right now isn’t just about pushing the boundaries for better sound quality, but rather about changing expectations and offering a holistic package that is practically rewarding in more ways than one. Audio wearable enthusiasts no longer want to feel forced into choosing between premium features and a reasonable price tag. Instead, they want gear that fits naturally into our daily routines, solves those annoying everyday frustrations, and delivers genuine value.
This is what makes JLab a compelling choice. Whether you prefer the immersive comfort and endurance of the JBuds Lux ANC Wireless Headphones or the flexibility of the Epic Pods ANC True Wireless Earbuds, both models reflect the very same philosophy. Personal tech should always adapt to your life, not the other way around. And while at it, great audio shouldn’t be reserved for just a few buyers. It should be accessible, practical, and ready for whatever your day has in store.


The interests of Microsoft and graduates rebelling against AI are actually aligned.
That was one takeaway for Brad Smith, Microsoft president and vice chair, from a recent return to his alma mater, Princeton University, for its reunion weekend. Seniors wore class jackets labeled “100 percent cotton” and “100 percent human,” referencing allegations that an earlier design was created with AI — part of a broader backlash across campuses this spring.
In a blog post this morning, which he started drafting during that visit, Smith writes that graduates booing AI at commencements across the country are “telling us what we need to hear. He points out that Microsoft’s own future depends on people staying employed.
“Workers have been Microsoft’s lifeblood from the start,” he writes in the post. “If the world’s people don’t have jobs, then neither do we. And if we’re not doing our part to help people use technology to pursue better jobs, then we’re not doing the job we were born to do.”
Speaking with GeekWire this week, Smith acknowledged the tension between that message and job cuts across the tech sector, including at Microsoft. He addressed the issue in the post, as well, citing the industry’s desire to offset capital spending on AI, along with factors including geopolitical uncertainty, trade tensions, and a correction from earlier over-hiring.
“Our industry is going through one of the most extraordinary transformations in its history,” Smith said in the interview, while adding that the “expenses of capital expansion make it more difficult to afford the employment bubbles we’ve had, especially since 2020.”
Smith cited the automation of entry-level tasks among the challenges facing graduates, as well.
But he also took a larger view. Computer science jobs are changing, he said, not vanishing. Coding is becoming a smaller part of the work, while the roles around it — including designing software, managing product development, and reviewing code — are expanding.
In the post, Smith places AI in a longer line of technologies that reshaped work without ending it, from the camera to the spreadsheet to email. He calls AI the next “general purpose technology,” akin to electricity, and argues its spread will take decades, not years, because the limit is how fast people and institutions change, not how fast the models improve.
Some jobs go away, he writes, while new ones appear, and many are remade.
Smith’s advice to workers is to treat a job as a bundle of tasks rather than a title, sorting them into what AI can do, what a person can do with AI, and what only a human can do. For this, he takes inspiration from a new book by LinkedIn’s Ryan Roslansky and Aneesh Raman, “Open to Work,” and its list of durable human attributes: curiosity, creativity, compassion, communications, and courage.
The post also offers a clear message for companies, aligning with Microsoft’s own business interests. Smith says organizations need to build their own AI systems on top of frontier models, using their own data and what Microsoft CEO Satya Nadella calls a “hill climbing machine” of evaluations and steady improvement, rather than simply renting intelligence from someone else.
Smith cites intellectual property and data sovereignty as a central concern, arguing that firms must adopt AI without handing their hard-won expertise to a rival’s model.
In the interview, Smith said the blog reflects months of discussion among Microsoft’s senior leaders, including Nadella and Chief People Officer Amy Coleman, and that it’s intended to speak to the company’s own employees as much as to the outside world.
Asked what he would have told new college graduates had he been the speaker at a commencement ceremony this spring, Smith said he would have focused on the resilience of humanity more than advances in technology — urging them to speak up for the values they care about, help contribute to a better world, and go forward with hope and optimism.
“That doesn’t mean these challenges may not be significant,” he said, “but I personally believe that the human spirit is far greater than any artificial intelligence the world is likely to create.”

This article is brought to you by AGILINK.
Throughout the exhibition hall at the 2026 IEEE International Conference on Robotics (ICRA), in Vienna, one demonstration seemed to attract a disproportionate amount of attention.
Two robotic hands were making a balloon dog. Slowly and deliberately, the robot twisted a long balloon into loops, bends, and joints without popping it. Visitors stopped, watched, and often returned with colleagues to watch again.
 AGILINK’s balloon dog demonstration draws a crowd at ICRA 2026.AGILINK
AGILINK’s balloon dog demonstration draws a crowd at ICRA 2026.AGILINK
At first glance, the demonstration appeared almost playful. Among roboticists, however, balloon twisting is widely recognized as an unusually difficult manipulation task.
A balloon is lightweight, highly deformable, slippery, and extremely sensitive to force. Every twist changes its geometry and internal pressure, turning a seemingly simple activity into a continuously changing physical interaction problem.
Humans navigate those changes almost intuitively. While making a balloon animal, people rarely think consciously about force regulation, slip prevention, or contact stability. They simply adjust.
For robots, those adjustments remain remarkably difficult. The challenge is not merely moving fingers to the right positions. The harder part is maintaining stable interaction while the object itself is changing.
Highlights from AGILINK’s ICRA 2026 demonstrations, including visuotactile sensing, in-hand manipulation, balloon-animal shaping, and other contact-rich tasks enabled by the company’s latest OmniHand platform.AGILINK
That distinction helps explain why the balloon dog drew so much attention in Vienna. What appeared to be a dexterity demonstration was, in many ways, a demonstration about contact itself.
As robotic manipulation continues to advance, a growing number of researchers are arriving at a similar conclusion: many of the hardest problems in robotics begin only after contact occurs.
Balloon twisting combines two challenges that robotics has traditionally struggled to solve simultaneously: long-horizon task execution and contact-rich manipulation.
The first concerns motion.
A balloon dog is not created through a single grasp or twist. It emerges through a carefully ordered sequence of manipulations, each setting the conditions for what follows. A small rotational error introduced early may appear insignificant at first, yet several steps later it can prevent the final structure from forming altogether.
In that sense, balloon twisting is a long-horizon task. Success depends not only on performing individual actions correctly, but also on preserving the future feasibility of the entire manipulation process.
To address this challenge, AGILINK began by collecting demonstrations from professional balloon artists. Human actions were mapped onto robotic hands to establish an initial manipulation policy. But successful demonstrations alone were insufficient.
In practice, some of the most valuable learning occurred when execution began to drift toward failure. Whenever instability emerged, human operators intervened and corrected the manipulation in real time. Those interventions were recorded and incorporated into reinforcement-learning cycles, allowing the system to learn not only how successful demonstrations unfold, but also how experienced operators recover when things start to go wrong.
Through this process, the robot gradually acquired the capabilities required for long-horizon task execution—a collection of abilities that AGILINK groups under the term motion intelligence: the ability to generate actions, coordinate bimanual behaviors, and execute extended manipulation sequences under real-world uncertainty.
 OmniHand 3 Ultra-M on display at ICRA 2026.AGILINK
OmniHand 3 Ultra-M on display at ICRA 2026.AGILINK
Yet motion alone does not explain why balloon twisting remains difficult. The second challenge is contact.
The robot must continuously regulate force, adjust contact locations, and respond to subtle changes in the object’s state. These decisions are difficult to encode through explicit rules. Even skilled human operators often rely on tactile intuition developed through experience rather than consciously articulated strategies.
Analysis of those interventions revealed that many failures did not originate from incorrect action sequences, but from the breakdown of contact itself.
To better capture those interaction dynamics, AGILINK collected contact-centric intervention data and incorporated those interactions into reinforcement-learning training. Rather than learning only which motions to perform, the system also learned how humans maintain stability when contact conditions begin to deteriorate.
AGILINK describes this capability as contact intelligence: the ability to establish, maintain, and adapt physical interaction as force distribution, friction, deformation, and contact geometry continuously evolve.
The distinction between the two capabilities is subtle but important. Motion intelligence determines what the robot intends to do. Contact intelligence determines whether it can continue doing it. For balloon twisting, both are necessary. One provides the sequence of actions. The other keeps those actions physically viable.
 YouTuber KhanFlicks follows OmniHand’s motions while learning to fold a balloon dog at the AGILINK booth.AGILINK
YouTuber KhanFlicks follows OmniHand’s motions while learning to fold a balloon dog at the AGILINK booth.AGILINK
Between a balloon slipping away and a balloon bursting lies a narrow region of stability. Successful manipulation depends on finding that region—and remaining within it throughout the task.
Introducing the OmniHand 3 Ultra-M Dexterous Hand
The balloon dog demonstration showcased a manipulation capability. It also revealed a broader question. How much contact intelligence can be achieved through learning alone? A robot can only regulate what it can perceive. It can only respond as quickly as its hardware allows.
As manipulation tasks become increasingly complex, researchers are finding that progress depends not only on better policies, but also on richer sensing and faster physical response.
That realization formed the backdrop for AGILINK’s second major announcement at ICRA 2026. Alongside the balloon dog demonstration, the company introduced the OmniHand 3 Ultra-M.
 OmniHand 3 Ultra-M closely matches the size of an adult human hand.AGILINK
OmniHand 3 Ultra-M closely matches the size of an adult human hand.AGILINK
The two exhibits represented different stages of the same technological trajectory. If the balloon dog demonstrated what contact intelligence can already accomplish today, Ultra-M was designed to explore what contact intelligence may require next.
Building Hardware for Contact Intelligence
Roughly the size of an adult human hand, the OmniHand 3 Ultra-M integrates 20 active degrees of freedom within a human-scale form factor.
Its most distinctive feature is a fully direct-drive architecture. By adopting direct-drive actuation throughout the system, the hand is designed to enable faster and more transparent force regulation and higher force-control bandwidth, enabling faster response as contact conditions change. For contact-rich manipulation, responsiveness can be as important as sensing itself.
By adopting direct-drive actuation throughout the system, the OmniHand 3 Ultra-M is designed to enable faster and more transparent force regulation and higher force-control bandwidth, enabling faster response as contact conditions change.
The platform also incorporates tactile sensing across nearly the entire hand. Each fingertip contains a miniature vision-based tactile sensor, while more than 300 three-dimensional tactile sensing points are distributed throughout the palm. Together, they provide information not only about where contact occurs, but how contact is evolving.
The system is designed to estimate pressure distribution, shear forces, local deformation, slip tendencies, and other interaction dynamics that often remain invisible to conventional position-based control systems.
According to AGILINK’s tests, individual sensors achieve force resolution of approximately 0.005 N—roughly equivalent to detecting the weight of a sheet of paper resting on a fingertip. Spatial resolution reaches approximately 0.04 mm, while sensing density approaches 50,000 sensing points per square centimeter.
 OmniHand 3 Ultra-M recognizes feather texture through vision-based tactile sensing.AGILINK
OmniHand 3 Ultra-M recognizes feather texture through vision-based tactile sensing.AGILINK
For dexterous robots, contact has traditionally been a largely hidden process. Ultra-M is designed to make that process more observable.
Rather than simply detecting that contact has occurred, the system attempts to resolve where interaction is happening, how forces are distributed, whether instability is beginning to emerge, and how manipulation strategies should adapt in response.
The balloon dog offered a glimpse of what contact intelligence can already accomplish. Ultra-M explores a different question: what capabilities may be required to push contact intelligence further?
The Physical World Remains the Hardest Benchmark
The significance of contact intelligence extends far beyond balloon animals. Many tasks that continue to resist automation involve unstable or deformable interaction: cable insertion, garment handling, flexible packaging, delicate assembly, connector mating, tool use, and household manipulation.
These tasks are difficult not because robots cannot reach the correct location, but because maintaining stable interaction after contact begins remains extraordinarily hard.
For decades, robotics achieved many of its successes by reducing uncertainty. Factories were engineered to make robotic motion predictable, repeatable, and highly structured. The physical world behaves differently.
A growing share of robotics research is shifting toward interaction itself—understanding how robots can establish, maintain, and adapt physical contact within environments that remain fundamentally unpredictable.
Objects shift. Materials deform. Friction changes. Contact evolves. Real environments rarely follow scripts. Seen through that lens, the balloon dog was never really about the balloon dog. What attracted attention at ICRA was not simply a visually impressive demonstration, but what it revealed: intelligence in the physical world is ultimately measured through interaction.
As motion generation continues to mature, a growing share of robotics research is shifting toward interaction itself—understanding how robots can establish, maintain, and adapt physical contact within environments that remain fundamentally unpredictable.
For robots moving beyond structured environments and into less predictable real-world settings, managing contact may become as important as motion itself.

WTF?! Eye-catching battery claims are nothing new, but some deserve closer scrutiny. According to an investigation led by independent researcher Ziroth and supported by more than 20 battery experts, the much-hyped Donut Lab solid-state battery appears to be something far more familiar: a lithium-ion cell.
The conclusion doesn’t rest on speculation or anonymous sources. Instead, it comes down to how the battery behaves under testing. Data from Finland’s VTT, including voltage curves and expansion measurements, consistently points to lithium-ion chemistry rather than the sodium-ion solid-state design the company claimed.
Start with the voltage. At around 50% charge, the tested cell measures between 3.7 and 3.8 volts. That’s typical for lithium-ion batteries, particularly high-nickel NCM chemistries. Sodium-ion cells generally operate at lower voltages and do not reach that range under similar conditions. On its own, that discrepancy raises questions. Combined with the second line of evidence, it becomes much harder to dismiss.
The second clue is the cell’s physical expansion during charging. As ions move into the anode, the material expands in predictable ways. Lithium-ion batteries with graphite anodes exhibit a distinctive “kink” in the expansion curve midway through charging, reflecting how lithium ions arrange themselves within graphite’s layered structure. The Donut Lab cell exhibits the same pattern.
This detail is particularly significant because sodium ions are too large to intercalate into graphite in the same way. In other words, if the expansion curve matches that of a graphite anode, the underlying chemistry is almost certainly lithium-ion. As the investigation puts it, “it’s like we have a slightly noisy fingerprint and a picture of the suspect’s face. And yet again, it’s a match.”
The numbers reinforce that conclusion. Based on the test data, the cell’s energy density is roughly 298 Wh/kg – respectable for a lithium-ion battery, but well short of the 400 Wh/kg figure Donut Lab promoted.
The technical findings also trace the battery’s origins to CT Coatings, a German company described in the report as holding an unusual mix of patents, many of them unrelated to advanced battery technology. CT Coatings was presented as the technology provider, Nordic Nano as the manufacturer, and Donut Lab as the company bringing the product to market. According to the investigation, however, Nordic Nano has yet to manufacture a battery cell.

Some of the experts involved were blunt in their assessments. Julian Zanau of the Fraunhofer Research Institute told Electrek: “The first impression I got was that these people have no idea how a battery actually works. They were talking about no rare earth metals in their batteries and therefore no lithium, and to any chemist lithium has nothing to do with rare earth minerals.”
The report also raises questions about how the technology was vetted. Rather than relying on independent validation, Donut Lab appears to have conducted its own due diligence. That approach drew criticism from former Nordic Nano executive Lauri Peltola, who argued that neither company had the battery expertise needed to independently verify such claims.
Beyond the laboratory, the investigation points to inconsistencies in how the technology was presented publicly. Donut Lab said it had delivered a production vehicle in early 2026. However, internal communications cited in the report indicate that the first motorcycles were intended for Verge’s own fleet to refine manufacturing processes – a stage typically considered pre-production rather than customer delivery.
In later comments to Finnish media, CEO Marko Lehtimäki acknowledged that the cells tested by VTT were not the ones intended for customer vehicles. He also indicated that the headline performance figures had not yet been achieved by the batteries destined for production.

The financial side of the story adds another layer. Donut Lab raised about $25 million from more than 1,300 investors, many of them small shareholders who participated through earlier crowdfunding campaigns tied to Verge Motorcycles. After restructuring around its battery technology, the company’s valuation climbed sharply, reaching $1.25 billion following its CES debut.
Investor communications leaned heavily on the promise of a breakthrough battery, including projections of significant near-term returns. At the same time, internal emails cited in the investigation show the company asking its technology partner to provide evidence that those performance claims could be met.
Finnish authorities are now reportedly looking into the matter. For engineers and industry observers, it serves as a reminder that bold battery claims still have to withstand basic diagnostic testing – and in this case, the evidence points to a far more conventional technology.

It’s been, well, 3.5 years since the last World Cup, but the biggest football tournament returns, spanning three countries as the action takes places across North America from Mexico to the United States and Canada.
The tournament begins in Mexico City on the 11th June, and over the course of five weeks (37 days to be exact), 48 teams will take part in 104 matches, making this the biggest World Cup yet.
And unlike the Champions League Final, the World Cup will be free-to-air, and if you live in the UK, there are two ways that you can the action live.
We can confirm that unlike Euro 2024, this tournament will be viewable in 4K HLG HDR, if you’re catching the action on iPlayer.
How to watch every World Cup 2026 game live for free
The rights to the 2026 World Cup is shared between BBC and ITV, and matches will be broadcast both on linear TV (through an aerial broadcast) and OTT streaming via iPlayer and ITVX.
Fair warning though. With matches kicking off across several time-zones, depending on the team you’re watching, you may be staying up very late (or waking up early) to catch your national team.
Here are the fixtures for the first week of the tournament and which channel/streaming service they’re on.
11th June
- Mexico v South Africa, 8pm ITV/ITVX
12th June
- South Korea v Czechia, 3am ITV/ITVX
- Canada v Bosnia and Herzegovina, 8pm BBC/iPlayer
13th June
- Qatar v Switzerland, 8pm ITV/ITVX
- Brazil v Morocco, 11pm BBC/iPlayer
- USA v Paraguay, 2am BBC/iPlayer
14th June
- Haiti v Scotland, 2am BBC/iPlayer
- Australia v Türkiye, 5am ITV/ITVX
- Germany v Curaçao, 6pm ITV/ITVX
- Netherlands v Japan, 9pm ITV/ITVX
15th June
- Ivory Coast v Ecuador, 12am BBC/iPlayer
- Sweden v Tunisia, 3am ITV/ITVX
- Spain v Cabo Verde, 5pm ITV/ITVX
- Belgium v Egypt, 8pm BBC/iPlayer
- Saudi Arabia v Uruguay, 11pm ITV/ITVX
16th June
- Iran v New Zealand, 2am BBC/iPlayer
- France v Senegal, 8pm BBC/iPlayer
- Iraq v Norway, 11pm BBC/iPlayer
17th June
- Argentina v Algeria, 2am ITV/ITVX
- Austria v Jordan, 5am BBC/iPlayer
- Portugal v DR Congo, 6pm BBC/iPlayer
- England v Croatia, 9pm ITV/ITVX
How to watch World Cup 2026 – what do I need?
With the World Cup 2026 being streamed in 4K, to see the action in its very best, you’ll need a 4K HDR HLG capable device or a display.
All 4K TVs sold support HDR, and all are required to support HDR10 and HLG.
BBC’s iPlayer app supports HDR HLG but ITVX does not. If you want to watch the matches in 4K HDR, you’ll need a display or streaming device that supports HLG streaming on iPlayer.
The BBC has a help guide for 4K viewing here, but you can expect TVs and streamer sticks going back years to feature support for HDR at the very least.
Tech
Anthropic brings Mythos to the masses with Claude Fable 5, its most powerful generally available model ever
Anthropic today launched two new AI models — Claude Fable 5 and Claude Mythos 5 — marking the company’s first broad release of the powerful “Mythos-class” AI capabilities it previously made available only to participating organizations in its restricted cybersecurity program, Project Glasswing, which it announced two months ago.
The company says Fable 5, which is the version most users and developers will get starting today, exceeds every Claude model it has previously made generally available — featuring stronger performance across software engineering, knowledge work, vision, scientific research and long-running tasks.
It smashes the existing benchmarks and comes atop on nearly all of them, though the prior Claude Mythos Preview version of the model still takes the top spots on computer use and multidisciplinary reasoning (see benchmark chart below and here).

The new Claude Mythos 5, by contrast, is less restricted in its capabilities, but more restricted in its availability. It is an upgraded version of the prior, similarly capable but limited release Mythos Preview model. As such, it has certain safeguards lifted — but it’s only officially accessible to Anthropic-approved users, including Anthropic’s cybersecurity partners in its Project Glasswing effort, and select biology researchers.
The key difference is that the general purpose Fable 5 wraps the same underlying Mythos-class capability in new safeguards. Anthropic says requests involving certain high-risk areas — including cybersecurity, biology and chemistry, and model distillation — are automatically routed to Claude Opus 4.8, Anthropic’s previously flagship general model, instead, with users notified when that happens. That is not the case on Mythos 5.
The company says more than 95% of Fable 5 sessions run entirely on Fable 5’s own responses, with no fallback, and that internal and external red-teaming efforts found no “universal jailbreaks” after more than 1,000 hours of testing.
Anthropic says Fable 5 is available to the general public today through its website, apps, and API, but that Mythos 5 will initially only be made available to users who already have access to the older Claude Mythos Preview.

Pricing, access and a tricky rollout
Anthropic is pricing both Fable 5 and Mythos 5 at $10 per million input tokens and $50 per million output tokens. The company says that is less than half the price of Claude Mythos Preview, but still ranks as the most expensive of major AI models available globally.
|
Model |
Input |
Output |
Total Cost |
Source |
|
MiMo-V2.5 Flash |
$0.10 |
$0.30 |
$0.40 |
|
|
deepseek-v4-flash |
$0.14 |
$0.28 |
$0.42 |
|
|
deepseek-v4-pro |
$0.435 |
$0.87 |
$1.305 |
|
|
MiniMax-M3 |
$0.30 |
$1.20 |
$1.50 |
|
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
$1.75 |
|
|
Qwen3.7-Plus |
$0.40 |
$1.60 |
$2.00 |
|
|
MiMo-V2.5 |
$0.40 |
$2.00 |
$2.40 |
|
|
Grok 4.3 (low context) |
$1.25 |
$2.50 |
$3.75 |
|
|
GLM-5 |
$1.00 |
$3.20 |
$4.20 |
|
|
Kimi-K2.6 |
$0.95 |
$4.00 |
$4.95 |
|
|
GLM-5.1 |
$1.40 |
$4.40 |
$5.80 |
|
|
Grok 4.3 (high context) |
$2.50 |
$5.00 |
$7.50 |
|
|
Qwen3.7-Max |
$2.50 |
$7.50 |
$10.00 |
|
|
Gemini 3.5 Flash |
$1.50 |
$9.00 |
$10.50 |
|
|
Gemini 3.1 Pro Preview (≤200K) |
$2.00 |
$12.00 |
$14.00 |
|
|
GPT-5.4 |
$2.50 |
$15.00 |
$17.50 |
|
|
Gemini 3.1 Pro Preview (>200K) |
$4.00 |
$18.00 |
$22.00 |
|
|
Claude Opus 4.8 |
$5.00 |
$25.00 |
$30.00 |
|
|
GPT-5.5 |
$5.00 |
$30.00 |
$35.00 |
|
|
Claude Fable 5 / Claude Mythos 5 |
$10.00 |
$50.00 |
$60.00 |
For developers, Fable 5 is available through the Claude API as claude-fable-5. Anthropic says Fable 5 is fully available today on the Claude API and on consumption-based Enterprise plans.
For subscription users, the rollout is more complicated. Anthropic says Fable 5 will be included on Pro, Max, Team and seat-based Enterprise plans at no extra cost from today through June 22.
On June 23, the company plans to remove Fable 5 from those plans, after which using it will require usage credits. Anthropic says it aims to restore Fable 5 as a standard part of subscription plans as quickly as possible.
The difference between Fable 5 and Mythos 5
Anthropic is not presenting Fable 5 and Mythos 5 as two separate models in the usual “small versus large” sense. Instead, they appear to share the same base capability level. The difference is access control — that is, how easily it will be for users to get their hands on the models, and the guardrails embedded in each.
As previously mentioned Fable 5 includes a new safeguard layer that detects certain high-risk requests — including cybersecurity, biology and chemistry, and attempts to distill the model’s capabilities into other systems — and routes those requests to Claude Opus 4.8.
Mythos 5 lifts some of those restrictions for trusted users working in approved domains.
In practical terms, Mythos 5 is more powerful for sensitive cyber and biology work because it can answer in areas where Fable 5 falls back.
For most ordinary enterprise and developer tasks, however, Anthropic says Fable 5 performs effectively the same as Mythos 5.
The launch also signals how Anthropic plans to bring frontier models with dangerous dual-use capabilities into the market: not by releasing all capabilities to everyone, and not by simply refusing risky questions, but by routing some requests to a less capable model while keeping the stronger model available for the majority of everyday work.
A major improvement in autonomous coding
For enterprise buyers, the most immediate use case is likely software engineering. Anthropic says Fable 5 can work unattended for longer and with more independence than previous Claude models, which is exactly the capability enterprises need if they want AI agents to do more than autocomplete code or answer developer questions.
On SWE-bench Pro, which measures a model’s ability to complete difficult software engineering tasks, Anthropic says Fable 5 and Mythos 5 reach 80.3%, vastly outperforming OpenAI’s latest and greatest general model GPT-5.5, which scored 58.6%.
On Cognition’s FrontierCode Diamond benchmark, which tests high-quality, maintainable agentic coding, the models score 29.3%, compared with 13.4% for Claude Opus 4.8 and 5.7% for GPT-5.5, according to the benchmark table included in Anthropic’s materials.
Anthropic also says Fable 5 scores highest among frontier models on FrontierCode even at medium reasoning effort, suggesting the model may deliver stronger coding results without always needing maximum compute.
The most striking customer example comes from Stripe. Anthropic says Stripe tested Fable 5 in a 50-million-line Ruby codebase and found that the model completed a codebase-wide migration in one day that otherwise would have taken a team more than two months by hand. Stripe said, “Fable 5 compresses months of engineering into days. In our 50-million-line Ruby codebase, it did in a day what would’ve taken us more than two months by hand.”
Other early users describe the model as especially useful for long-horizon development tasks. Cursor said, “Fable 5 is the state of the art model on CursorBench. It’s opened up a class of long-horizon problems that were out of reach for earlier models.” Replit said Fable 5 is the highest-performing model it has tested on ViBench, its end-to-end “vibe-coding” benchmark, and that it builds apps in less time with fewer tokens. Figma said Fable 5 is “a clear step forward on agentic coding and prototyping.”
This is the enterprise shift Anthropic is trying to sell: AI coding systems that can take on larger units of work, not just individual tickets. That could include codebase migrations, app prototyping, pull request review, test generation, debugging across unfamiliar tools, user interface design and multi-step internal software projects.
Base44 said, “Fable 5 is much deeper and better at one-shotting full apps, and its tool calling is excellent.” Genspark said, “Fable 5 came out #1 on our evals, winning head-to-head against every model we tested. It was significantly stronger on the hardest tasks in the set — UI design and game coding.” Rakuten said, “At the highest effort, Fable 5 reflects on and validates its own work. For us, that’s what makes highly autonomous operations possible — the extra thinking pays for itself.”
For CTOs and engineering leaders, that suggests the model’s value may come less from raw code generation and more from sustained execution: understanding an intent, planning steps, calling tools, checking its own work and continuing through a task without constant human steering.
Knowledge work, finance, legal and operations
Anthropic is also positioning Fable 5 as a stronger model for enterprise knowledge work. On GDPval-AA, Anthropic reports a score of 1932 for Fable 5 and Mythos 5, compared with 1890 for Claude Opus 4.8, 1769 for GPT-5.5 and 1314 for Gemini 3.1 Pro.
On GDPpdf, a benchmark focused on visual document reasoning, Fable 5 and Mythos 5 score 29.8% without tools, compared with 22.5% for Opus 4.8, 24.9% for GPT-5.5 and 16.7% for Gemini 3.1 Pro.
That matters for enterprises because much of corporate work still lives in messy documents: PDFs, spreadsheets, charts, reports, contracts, filings, slide decks and screenshots. Anthropic says Fable 5 shows gains in document-based reasoning, chart and table interpretation and complex problem solving.
Hex said, “Fable 5 is the first to break 90% on our core analytics benchmark of complex, long-running analytical tasks — a 10-point jump over Opus. On the hardest questions, it shows strong judgment and attention to nuance.” Hebbia said Fable 5 was the highest-scoring model on its Finance Benchmark for senior-level reasoning, with double-digit gains in document reasoning, chart and table interpretation, and problem solving.
The finance examples are notable because they point to AI agents moving beyond summarization into higher-stakes analytical workflows.
IMC said Fable 5 “aced our trading-analysis evaluations nearly across the board: factual lookup, conceptual reasoning, root-cause analysis, expected-value analysis.” Optiver said the model was stronger than Opus 4.8 on its trading benchmark and “remarkably consistent,” scoring identically across repeated runs. Balyasny Asset Management said Fable 5 was the strongest finance-first model it had tested.
Legal and operations teams may also see immediate impact. Crosby Legal said, “Fable 5 feels materially different. In blind review, our lawyers found its redlines matched or beat our current model every time.” Notion said the model can take work “you’d chip away at all afternoon” and turn messy notes into a functioning project plan. Zapier said Fable 5 is the new leader on AutomationBench and is more autonomous than Opus 4.8: “Where Opus stops to ask, Fable 5 keeps looking.”
For enterprise software vendors, that points toward more capable embedded agents in workflow products: agents that can review a contract, update a project plan, assemble a spreadsheet, inspect a chart, file a ticket, run a query, call an internal API and keep going until the work is complete.
Vision and interface understanding
Anthropic says Fable 5 is also its strongest vision model. In its launch materials, the company says the model can extract precise numbers from detailed scientific figures and complete vision-based tasks such as rebuilding a web app’s source code from screenshots alone.
That has immediate implications for enterprise automation. Many business processes still depend on visual interfaces that are not cleanly exposed through APIs: dashboards, PDFs, forms, legacy apps, screenshots, scans and image-heavy reports. A stronger vision model could help agents operate across those environments with less custom integration work.
Anthropic also says Fable 5 needs less scaffolding than previous Claude models. As an example, the company says earlier Claude models struggled to play Pokémon FireRed even with extra tools, while Fable 5 impressively beat the game using a minimal vision-only harness. Anthropic posted a fast forwarded video of its playthrough to YouTube and in its blog post:
https://www.youtube.com/watch?v=CIQBP1w4B1M
The point is not gaming itself, but the broader agentic skill: reading a visual environment, remembering progress, deciding what to do next and executing over a long horizon.
In another internal test, Anthropic says it had the model play the deck-building game Slay the Spire with access to persistent file-based memory. The company says persistent memory improved Fable 5’s performance three times more than it improved Opus 4.8’s, and that Fable reached the game’s final act three times more often. For enterprise users, this suggests Fable 5 may make better use of notes, logs and stored context during multi-step work.
That could matter for internal agents that operate over days or weeks: sales operations agents that track account research, engineering agents that manage migrations, finance agents that update models, or support agents that remember what they tried across many turns.
From restricted cyber model to general-purpose enterprise AI
The announcement follows Anthropic’s April 2025 rollout of Claude Mythos Preview through Project Glasswing, a restricted program for cyber defenders, critical infrastructure providers and major software maintainers. Anthropic created Glasswing after internal evaluations showed Mythos-class models could find and exploit software vulnerabilities at a level that raised meaningful misuse concerns.
Following the debut of Glasswing and Mythos, U.S. officials and intelligence agencies began weighing how such models could reshape both cyber defense and offensive operations, while Sen. Mark Warner warned that AI-assisted vulnerability discovery should force industry to “accelerate and reprioritize patching.” Financial regulators also took notice: The Guardian reported that Mythos entered discussions among senior banking officials and regulators in the U.S. and U.K. because of fears that AI-accelerated cyberattacks could threaten payment systems and broader financial stability.
The reaction has not been limited to alarm. Governments also want access: Reuters reported that South Korea’s national internet security agency had secured Mythos access through Project Glasswing, reflecting a broader geopolitical race to use frontier AI for national cyber defense. At the same time, Anthropic has faced scrutiny over whether it can safely gate the very capabilities it says are too risky for general release. The Verge reported that unauthorized users accessed Mythos after its limited rollout, calling the incident damaging for a company that has built its brand around responsible AI.
Critics have also questioned whether Anthropic’s warning-heavy framing risks becoming a form of market positioning, since it casts the company as both the source of the new capability and the gatekeeper deciding which governments, companies and researchers get to use it.
With Fable 5, Anthropic is leaning into its gatekeeper role, attempting to separate the general enterprise value of a Mythos-class model from the riskiest parts of its capability profile. The company says Fable 5 can handle software engineering, research, visual reasoning, document analysis and long-running agentic workflows, while classifiers block or reroute requests that could provide what Anthropic calls “uplift” to malicious actors.
Those classifiers cover three main areas.
-
Cybersecurity, where Anthropic says Mythos-class models can discover and exploit vulnerabilities and perform broader “agentic hacking” tasks such as reconnaissance, discovery and lateral movement.
-
Biology and chemistry, where the company says the same reasoning that can help researchers design therapies could also help well-resourced malicious actors pursue dangerous biological work.
-
Model distillation, where Anthropic says users may try to extract Claude’s capabilities to train competing models, including models that could be released without similar safeguards.
When Fable 5’s classifiers detect one of those categories, the response is automatically handled by Claude Opus 4.8. Anthropic says users will be told when this happens. That is a notable product decision: rather than declining those requests outright, Anthropic is trying to keep the user experience functional while reducing access to the most capable version of the model in sensitive areas.
Anthropic says it red-teamed the new classifier system internally and externally. The company says an external bug bounty produced no universal jailbreaks after more than 1,000 hours of testing, and external red-teaming organizations also failed to find a universal jailbreak. One external partner found that Fable 5 complied with zero harmful single-turn cyber requests related to planning cyberattacks, exploit development or defense evasion, even when prompts used any of 30 public jailbreak techniques, according to Anthropic.
The company is still acknowledging tradeoffs. Anthropic says the safeguards are deliberately cautious and may sometimes trigger on benign requests. That could frustrate security professionals, biology researchers and advanced enterprise users whose legitimate work overlaps with the blocked categories. The company says it plans to reduce false positives over time.
Mythos 5 and the restricted frontier
While Fable 5 is the broad commercial launch, Mythos 5 is the model to watch for enterprises operating in security, critical infrastructure and life sciences.
The company says all users with Claude Mythos Preview access can upgrade to Mythos 5 beginning today. It plans to expand access through a trusted access program, in collaboration with the U.S. government.
The distinction is important for sectors where the blocked capabilities are not edge cases but core workflows. A security team may need to reproduce vulnerabilities, test exploitability, analyze lateral movement or simulate attacker behavior in a controlled environment. A biology research team may need to reason through molecular design workflows that would trigger general-use safeguards. Fable 5 is not designed to give every user unrestricted access to those capabilities; Mythos 5 is designed for vetted users who need them.
Anthropic says Mythos 5 has the strongest cybersecurity capabilities of any model in the world. In the company’s benchmark table, the model family scores 78.0% on ExploitBench, compared with 69.0% for Claude Mythos Preview, 40.0% for Opus 4.8 and 34.0% for GPT-5.5. On CyberGym, Anthropic’s chart shows Mythos 5 at 83.8%, slightly ahead of Mythos Preview at 83.1% and far above Opus 4.8 with default safeguards.
The company is making a similar argument in biology. Anthropic says Mythos-class models outperform dedicated protein language models on a task involving adeno-associated viruses, a delivery mechanism used in gene therapies. The company frames that as both promising and risky: the same capability that could help gene therapy research could also be misused in dangerous biological work.
Anthropic says its internal protein design experts used Mythos 5 to accelerate parts of the drug design process by about tenfold. In one example, the company says Mythos 5, using protein design and bioinformatics tools without human assistance, matched or beat skilled human operators by choosing binding sites, selecting and running tools, and recovering from failures. Anthropic says nine of 14 protein targets in the study produced strong candidates for drug design that it is now investigating.
The company also says Mythos 5 produced novel molecular biology hypotheses that Anthropic scientists preferred over Opus-class model hypotheses about 80% of the time in blinded comparisons. Anthropic says several of those ideas have advanced to experimental evaluation, and one hypothesis involving an E. coli protein was later corroborated by an independent lab working on the same problem.
Those claims are potentially significant, but they should be treated carefully until more details are published. Anthropic says it intends to publish additional results in the coming months. For now, the strongest enterprise implication is directional: the company believes its highest-end models can already perform parts of scientific research workflows with less human intervention than prior systems.
New, longer data retention requirement
The company also introduced a new data-retention policy for Mythos-class models. Anthropic says it will require 30-day retention for all traffic on Fable 5, Mythos 5 and future models with similar or higher capability levels, across both first-party and third-party surfaces. The company says it will not use that data to train new Claude models or for non-safety purposes, and says it has added privacy protections including logging human access and deleting the data after 30 days in almost all cases.
That policy may become one of the most important enterprise buying questions around Fable 5. Many businesses want frontier AI capability but also want strict control over data retention, especially in regulated sectors. Anthropic’s position is that stronger monitoring is necessary for models with this level of capability. Enterprise customers will have to decide whether the capability gain justifies the retention requirement.
Enterprise implications
The broader enterprise significance of Fable 5 is that Anthropic is trying to commercialize a more autonomous class of AI model without exposing all of its capabilities to every user. That could become a template for how frontier labs release increasingly powerful systems: one model family, multiple access tiers, and domain-specific restrictions depending on user trust and risk.
If Fable 5 performs as Anthropic and early customers describe, developers may hand off larger tasks: code migrations, refactors, UI builds, test writing, bug fixing, documentation, internal tooling and multi-step app creation.
For knowledge-work-heavy enterprises, Fable 5 could make AI more useful in workflows where earlier models were too brittle: finance research, spreadsheet analysis, legal redlines, procurement review, board materials, market research, sales operations and project planning. The main gain is not just better answers; it is fewer turns, fewer corrections and more ability to keep working through ambiguity.
For security teams, the launch is more complicated. Most organizations will get Fable 5, not unrestricted Mythos 5. That means they may see stronger general coding and analysis, but not full access to the cyber capabilities Anthropic considers risky. Trusted defenders inside Project Glasswing will get Mythos 5, giving them a more direct way to use the model for vulnerability discovery and defensive testing.
For life sciences companies, the pattern is similar. Fable 5 may help with general research, literature analysis, data interpretation and scientific reasoning, but the more sensitive biological capabilities will be restricted. Anthropic is effectively creating a separate access path for vetted researchers whose work requires capabilities that could be dangerous in the wrong hands.
The launch also raises competitive pressure across the AI industry. Anthropic is claiming state-of-the-art results across agentic coding, knowledge work, vision, cybersecurity, legal reasoning, spatial reasoning and health benchmarks. But the more strategically important claim may be that it has found a workable release mechanism for models above its Opus class. If Fable 5’s safeguards hold up under real-world use, Anthropic will argue it can bring more powerful models to market sooner without fully opening the riskiest capabilities.
That is still a large “if.” The enterprise market will test not only Fable 5’s benchmark performance, but also its reliability, false-positive rate, data-retention tradeoffs and cost at scale. A model that can complete more work autonomously can also burn more tokens, trigger more governance questions and create new review burdens for teams that must verify its output.
Still, today’s launch marks a clear shift in the Claude lineup. Opus is no longer Anthropic’s top commercial capability tier. Mythos-class models now sit above it. Fable 5 is the first version of that tier for general users; Mythos 5 is the restricted version for trusted high-risk work. Together, they show how Anthropic plans to push frontier AI deeper into enterprise workflows while trying to keep the most dangerous capabilities gated.

The Unlimited Day Pass could be a good option for weekends away or tourists.

If you’ve ever needed iPad data for a day or two without signing a contract or paying for an entire month, AT&T has a new option. The company’s Unlimited Day Pass offers 24 hours of unlimited wireless data to eligible iPad users for a flat $3 rate, without a contract, subscription or credit check. “AT&T is the first and only major U.S. wireless provider to give eligible iPad users (with eSIM capabilities) the freedom to buy on-demand connectivity when they need it,” the carrier said in a press release.
The plan is available to anyone (including non-AT&T customers), so it could be a good option for camping, weekends aways, or tourists. AT&T also notes that many folks with eSIM iPads have no cellular plan, so it could be a way to give your kid internet access when they’re using an iPad to study for exams. There’s no automatic renewal, so you’ll have no ongoing commitment or need to cancel.
If you sign up, the first day pass is complimentary, limited to one iPad per customer, then available at a flat daily rate via credit or debit card. To use it with any Wi-Fi + cellular iPad model, simply activate the plan from your iOS device settings, with no app or Wi-Fi connection needed. “Open the Settings app, tap Cellular Data [and] add AT&T Unlimited Day Pass,” AT&T explains. The 24-hour data activation will start shortly after purchase.
The new service is available for any eSIM equipped iPad dating back to 2019, including iPad, iPad Mini, iPad Air and iPad Pro models. Android and other tablets are not yet eligible. AT&T said it plans to expand the service to include “multi-day options such as weekend and week-long passes” in the future. The company notes that it may slow data speeds if the network is busy.
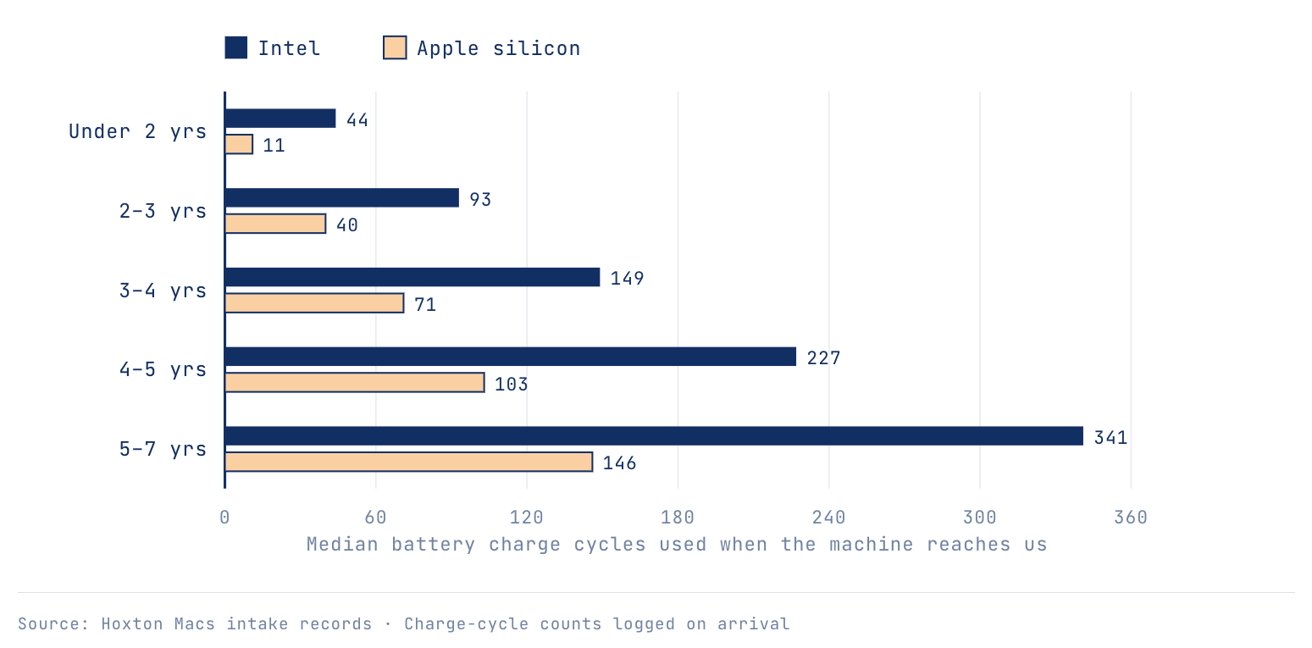
The numbers are in! Given the same amount of time in use, with data spanning more than a decade, Intel Macs come in for service at twice the rate that Apple Silicon Macs have.
When it comes to device longevity, Apple’s products tend to last quite a long time, if cared for properly. While this has been a consistent feature of Apple’s hardware, it seems that the chip being used plays a factor.
According to a June report from UK Apple refurbisher Hoxton Macs, it has found that Intel Macs it has sold is returned for a hardware fault at twice the rate of Apple Silicon models.
In its figures, it says that there was a 0.9% hardware fault rate for Apple Silicon Macs sold across 2025. This refers to the share repaired or replaced under warranty in the first year after sales.
However, an Intel Mac sold under the same circumstances doubles this rate. Crucially, this covers Intel Macs that are of the same age as the equivalent Apple Silicon model. For example, the data counts failures from a 2016 MacBook Pro through 2018, the same as it counts a M1 MacBook Air from 2020’s failures through 2022.
In the last three years, the company’s blended warranty-return rate for all Mac models it sells has more than halved. In 2023, there was a 2.9% return rate for faults, but by 2025, it was 1.1%
“Matched for age, an Intel Mac comes back for a hardware fault about twice as often as an Apple silicon one,” the company says. “The faults that matter most — logic-board and battery failures — run at roughly double the rate on Intel.”
This overall failure rate from Intel machines is consistent with what our own data from a few Apple Stores across the East Coast showed through the 2010-2020 period. The industry as a whole is skewing towards more failures, not less, like Apple’s trending.
Fewer long-term problems
When it comes to why there are fewer Apple Silicon-related fault issues, the retailer insists it’s because the chip switch changed what could go wrong.
During the Intel era, it is reported that batteries wore out faster due to the requirements of the chip. Batteries were replaced more frequently because they were more easily drained.
By contrast, the batteries in an Apple Silicon MacBooks use less power, reducing the cycle count and minimizing the need for replacement.

Battery cycle counts based on used Mac intake, based on device age. Image credit: Hoxton Macs
At all Mac ages, the Apple Silicon versions have less battery wear compared to their similar-aged Intel counterparts. A three-to-four-year-old Apple Silicon MacBook has about half the cycles of the Intel equivalent when it reaches the company’s restoration team.
There were also more reported issues with the USB Type-C ports on Intel Mac units, which also failed at a higher rate than on Apple Silicon machines.
The lack of a fan on the Apple Silicon MacBook Air is also helpful, unlike the fan-equipped Intel versions.
A fan moves air to cool the Mac’s components, providing a way for dust to be pulled inside. That dust then builds up and eventually clogs the airflow, preventing the thermal management system from working.
Since the Apple Silicon MacBook Air doesn’t use a fan for cooling at all, there are no blockage problems.
One theory is that the Apple Silicon design used fewer heat-generative components and has a cooler-running chip. Intel Mac faults clustered around the areas with high heat generation, including the separate graphics chip in some models.
Built a better MacBook reputation
The refurbishment repair report continues a trend for Apple, in being a very reliable manufacturer of computer hardware. It’s a reputation that it had for a long time, but it has seemingly improved further with the Apple Silicon era.
This is especially evident in annual surveys from the ACSI into customer satisfaction. In the September 2025 edition, Apple dropped from a score of 85 to 82, putting it narrowly in second place, behind HP.
With Intel hardware support finally dropped in macOS 27 Golden Gate, there’s now more of a reason for people still using Intel Macs to upgrade to Apple Silicon.
If they switch, it’ll be for a more hardy notebook than they’ve been using before.
AI vendors promote their enterprise products as if they’re turnkey solutions, but the chances are low that AI agents will hit the ground running right away. Unless you put in the effort to train a model on the specifics of your business, it’s unlikely to understand how your company, for example, defines revenue or knows who is allowed to see which file. That’s part of the reason why we’re seeing AI companies deploying engineers to help integrate their AI products into customers’ systems.
New York-based startup Jedify is attacking this very gap. The company says its platform connects to enterprises’ knowledge sources via APIs to build a “context graph” about their business that AI agents can use to work better. These sources can be databases, data warehouses and lakes, SaaS apps or BI tools, as well as unstructured sources such as reports, documentation, code bases, and even Slack channels and meeting recordings.
To build that out, Jedify has raised $24 million in a Series A funding round led by Norwest, TechCrunch has exclusively learned. The round saw participation from returning backers S Capital VC and Cerca Partners, as well as new investor Oceans Ventures. Data giant Snowflake also participated as a strategic investor and is integrating the startup’s tech with its AI products, such as its Cortex AI service, Semantic Views, and CoWork.
Jedify’s pitch is that to be useful within enterprises, AI agents need access to the relationships between entities, data, permissions, domain knowledge, workflows, operational assumptions, and company-specific terminology. This context, the company says, allows an AI agent to narrow its attention to the information that is relevant to a particular task instead of searching across everything a company has.
Co-founder and CEO Assaf Henkin (pictured above, on the far right) pointed to Kiteworks, a compliance company, as an example of how customers are using Jedify. Kiteworks connected Snowflake, Tableau, Notion, and internal playbooks, including documents and screenshots, to Jedify, then built agentic tools for different customer workflows.
“They wanted to arm their sellers and account teams with a sophisticated app — you can think of it as both like a dashboard application and a real-time conversational application. When they go into a customer conversation, Jedify builds for them, on the fly, everything they need to know. And during the conversation, they can, in real time, get very specific details surfaced proactively,” Henkin said.

Henkin argues that Jedify’s context graph is different from the semantic layers, metadata catalogs, and knowledge graphs that companies already use because it is multi-dimensional, capturing relationships across entities, data, people, permissions, and customers. It’s also model-agnostic and updates in real time as information flows into and out of the systems it is connected to.
“When you want to enable an agentic solution to really be autonomous, to drive decisions across CRM data, Zendesk tickets, maybe telemetry data that’s coming in real time, that’s when a context graph is much better in terms of capabilities versus a semantic layer,” he said.
Permissions are an obvious hurdle here. It wouldn’t do for an agent to give an intern access to the CFO’s revenue projections, for example. Henkin said his platform works to address that by inheriting permissions from identity systems, file systems, SaaS tools, and databases, including row-, column-, and table-level access rules, then lets its customers create additional groups that define what and whom agents or workflows are allowed to reach. It also offers observability and governance tools to help customers ensure their AI agents are behaving as intended.
Jedify is currently targeting mid-market and large enterprise customers that have mature data stacks and multiple databases or data warehouses. Henkin said the company has between 10 and 20 early customers, one of which is The Weather Company, and is seeing interest from data-heavy sectors such as gaming, industrials, and consumer packaged goods.
Snowflake’s investment and partnership are notable because large data platforms are also trying to build similar capabilities. But Henkin argues that Jedify is complementary to such efforts because much of a company’s data, and most of its institutional knowledge, isn’t usually stored with a single cloud provider.
“[The large data companies] will tell you, ‘Oh yeah, just bring everything.’ But in reality, companies have multiple databases, and warehouses, and data solutions […] The big thing is that not all of your data is in those environments, and most of your knowledge is not there, so it’s a bit of a disadvantage that they actually have,” he said.
Henkin also noted that for companies trying to do this on their own, training an AI model to build a comparable context layer can be cost-prohibitive, especially as companies are scrutinizing and clamping down on their AI token usage.
And the rapid advances in AI model development play into the company’s broader bet: as models grow more capable and more interchangeable, proprietary context that helps those models work better within businesses could prove a valuable and durable moat.
The startup will use the fresh cash for product development, hiring, and go-to-market motion. It brings the firm’s total funding to about $33 million.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.


Two former executives from enterprise software giant Icertis have teamed up to launch a new Seattle startup aimed at a multi-trillion-dollar corporate headache.
Rivvun AI, which today is announcing a $7.55 million oversubscribed seed funding round from Sitara Capital and 3one4 Capital, is led by CEO Anand Veerkar and Chief Product Officer Niranjan Umarane.
Both spent the last decade as executives at Icertis, helping scale the contract intelligence platform to more than $350 million in annual recurring revenue. They are joined at Rivvun by co-founder and serial entrepreneur Patrick Linton.
Rivvun is tackling what the founders describe as an “execution gap,” a costly friction point between what a corporation contractually negotiates and what actually hits its books.
“The enterprise has spent a decade being told AI will transform how it operates,” said Veerkar. “What it needed was AI that creates direct, measurable impact on the P&L — not productivity narratives, not dashboards. Rivvun closes the gap between what was agreed and what was collected, recovering money that goes straight to the bottom line.”
Rather than building a conversational chatbot, a copilot or another analytics dashboard, Rivvun has built what it terms an “autonomous value execution layer.”
Rivvun’s agents sit on top of a company’s internal ERP, CRM and procurement databases — like SAP, Ariba and Salesforce — to catch commercial discrepancies and write corrective actions back into those systems.
It dubs these AI agents “stewards” (focused on money going out to manage invoices, suppliers, and leakage) and “sentinels” (focused on money coming in to track renewals and customer behavior).
It has also developed what it calls a “margin bridge”: a financial module that matches what you sell against what you spend to protect profit margins.
According to the company, these agents continuously monitor commercial events across corporate systems, apply governed playbooks and write corrective actions directly back into the systems while preserving an audit trail.
To address specific industries, Rivvun is building vertical-specific logic tailored to sectors like pharmaceuticals, healthcare, banking and retail.
For example, the company said that a large manufacturing company with $3 billion in spend may experience leakage across its disconnected systems, creating an invisible problem that financial dashboards and consultants may miss. In that scenario, Rivvun’s agents could run continuously across the data sources, recovering an estimated $110 million to $138 million annually.
The company is targeting Chief Financial Officers, Chief Revenue Officers and other C-level executives who oversee large budgets, noting that there’s no “rip-and-replace” as the agents tie directly into existing software systems.
Citing research from McKinsey, Rivvun said that companies lost an estimated 3 to 4 percent of their total external spend because of inefficiencies and non-compliance. That’s about $2 trillion when factored across the Fortune 2000 companies, which Rivvun said is money that basically “disappears in the gap between what was contractually committed and what enterprise systems were ever built to collect.”
In a statement, Anurag Ramdasan of 3one4 Capital said Rivvun is one of the strongest teams they’ve encountered.
“They are not pitching a horizontal AI solution and hoping for enterprises to extract value out of it,” Ramdasan said. “They are delivering ROI on AI for large enterprises from the first day of implementation, which is very critical for enterprise AI adoption.”
Similar to how Icertis grew over the past decade, Rivvun is taking a dual approach to its operations. It is headquartered in Seattle, with engineering operations in Pune, India. It employs 15 people, with plans to double this year.
The company plans to use the new seed capital to fund engineering, customer pilots and expand its enterprise global sales operations.

Thousands of drivers with 12 or more speeding points still driving

(VIDEO) Jennifer Aniston Styles Benny Blanco’s Curls in Playful LolaVie Video With Selena Gomez

AI Deepfake Election Ad Raises Transparency Concerns

HarrisX Poll Found 52% of Registered Voters Support the CLARITY Act

BloFin War of Whales 2026 Grand Prix opens registration for $5M trading championship

Blockchain.com files with SEC for U.S. IPO
Trade with Rs. 100 @deltaexchange || #trader #trading #bitcoin #cryptocurrency #deltaexchange

Important full form of Finance and Banking #fullform #shortfeed #shorts #youtubeshorts

Financial Accounting one shot || full syllabus of financial accounting ||Bcoc 131 IGNOU || #bcom#bba
-

 Fashion5 days ago
Fashion5 days agoWeekend Open Thread: Evereve – Corporette.com
-
 Crypto World5 days ago
Crypto World5 days agoJensen Huang Approves Samsung, SK Hynix, and Micron for NVIDIA (NVDA) HBM4 Memory Supply
-

 Crypto World2 days ago
Crypto World2 days agoAnatomy of the June crypto crash: Fed, Iran, Saylor
-
 Entertainment4 days ago
Entertainment4 days agoThe Best Mystery Series of All Time Is Surging on Streaming 30 Years After It Ended
-

 NewsBeat3 days ago
NewsBeat3 days agoAlexander Zverev wins the French Open to finally earn a 1st Grand Slam title
-

 Tech5 days ago
Tech5 days agoSuspicious Polyfill login prompts pop up on Toshiba, Muji websites
-
 Crypto World4 days ago
Crypto World4 days agoSenator Cynthia Lummis Calls CLARITY Act the Most Consequential Financial Legislation of This Generation
-

 Tech3 days ago
Tech3 days agoMicrosoft unveils seven homegrown AI models in new bid for ‘long term self-sufficiency’
-

 Tech5 days ago
Tech5 days agoMicrosoft launches MXC, an OS-level sandbox for AI agents, with OpenAI and Nvidia already on board
-

 Business5 days ago
Business5 days ago(VIDEO) Justin Bieber Delivers Surprise Happy Birthday Serenade to Diners at Los Angeles Mexican Restaurant
-
 Business4 days ago
Business4 days agoThe Pain Points Taking a Fragile Tech Rally Down a Notch
-
Crypto World5 days ago
LBank Surpasses 25 Million Users Worldwide as AFA Partnership Continues to Drive Global Growth
-

 Crypto World3 days ago
Crypto World3 days agoTrump’s AI Ownership Plan Could Benefit Anthropic at OpenAI’s Expense
-

 Tech5 days ago
Tech5 days agoMeta steals a tactic from Tesla and builds data centers in tents
-

 Tech5 days ago
Tech5 days agoVon der Leyen’s AI envoy pick draws conflict-of-interest fire
-
 Crypto World2 days ago
Crypto World2 days agoEli Lilly (LLY) Stock Surges 4% Following Breakthrough Sleep Apnea Trial Results
-
 Sports23 hours ago
Sports23 hours agoBangladesh beat Australia after 20 years in ODIs, register only their second win over six-time world champions | Cricket News
-

 Business2 days ago
Business2 days agoHigh Stakes for Wembanyama as New York Pushes for 3-0 Lead
-

 Tech4 days ago
Tech4 days agoHackers now exploit SolarWinds Serv-U flaw to crash servers
-

 Tech3 days ago
Tech3 days agoNotion restores access to Anthropic after service disruption
You must be logged in to post a comment Login